
基于大数据技术的电网输电负荷预测研究
2024-03-08 12:08:06云南电网有限责任公司文山供电局张兆阳申娟平赵晓寅赵树辉
电力设备管理 2024年2期
云南电网有限责任公司文山供电局 张兆阳 申娟平 杨 俊 赵晓寅 赵树辉
电网输电负荷预测主要是指针对性地预测馈线、大用户等负荷单元,为后期配电化状态预判提供重要的依据和参考。负荷预测结果是否准确,直接影响了电网输电精细化管理水平以及供电的可靠性[1]。对于电网输电而言,其应用范围较广的预测方式主要包含短期预测和中长期预测。本文结合这两种预测方式,利用基于大数据技术解决方案,对电网输电负荷进行科学化预测。
1 数据存储
在进行电网输电负荷预测时,要做好对负荷、气象、算法模型等数据的整合处理,同时,还要将这些数据划分为实测值、分析值。为实现对负荷数据实测值的精确化采集,需要借助用电信息采集系统,将采集好的信息导入指定的文件格式中,然后,通过执行后台服务程序,筛选出满足相关数据实测值的数据,并下载、解析处理这些数据。为实现对气象数据实测值的全面化采集,要利用电力气象平台,对其进行采集和整理,并利用后台服务程序,将气象数据直接传输到大数据平台中。在采集设备容量变化数据、有序用电数据时,要利用电网抢修系统,将所采集的数据安全、可靠地传输到大数据平台中。
2 数据预处理
对于电网输电二次系统而言,在具体建设期间,存在设备分布点过多、数据维护不全面、数据易丢失等问题。目前,比较常见的数据缺失类型主要包含随机缺失类型和非随机缺失类型。相关人员要做好对数据缺失问题的有效处理。在具体实践中,当处理的数据缺失量相对较少时,要做好对缺失量的删除,并插补处理数据。此外,在预测电网输电负荷时,要做好对平均值的采集和整理,并采用贝叶斯预测法,做好对多个插补值的有效采集,并结合当前信息变化情况,获得所需要的插补数据。
3 电网输电负荷分析
3.1 影响电网输电负荷因素筛选
影响电网输电负荷因素相对较多,主要包含温度、湿度、风力、日照、气压等因素,进行电网输电负荷分析时,要从高维数据中筛选出属性集,确保计算复杂度降到最低,使得模型训练得以大幅度提高。随机森林理论主要是指借助多棵决策树,训练并预测样本数据,对数据进行分类。在分类数据时,要结合不同属性评分结果,评估不同属性在数据分类中应用价值[2]。为保证影响因素筛选效果,需要利用数据集,形成相应的决策树,单棵树主要用于对小部分属性的训练,并对相关属性进行统计分析处理。
3.2 气象影响分析
气象变化,通常会对电网输电负荷产生直接性的影响,气象这一因素具有时间滞后性等特点,因此,仅仅运用全局回归的方法,无法对气象数据进行全面化描述,而自适应分段线性模型树的构建和应用,可以有效地分析气象因素。
该方法在具体应用时,要运用分治策,对全局回归进行优化处理,从而保证目标分段处理效果。通过运用回归树,对叶子节点进行统一化处理,使得拟合误差出现概率降到最低。为了提高最终拟合结果的精确性,需要精细化处理叶子节点[3],同时,还要拟合各叶子节点样本,使其拟合为相应的线性函数,从而实现对分段线性模型树的构建。
为保证模型训练结果精确性和真实性,要选用合适的算法,自动化生成相应模型参数,同时,采用自适应策略,对参数变化区间进行科学设置,并保证遍历循环效果,并结合最终模型误差评估结果,对相关参数进行科学设置。另外,向样本中分解相应的决策树,从而保证线性拟合处理结果的精确性和真实性,只有这样,才能确保气象与负荷定量两者之间形成较高的关联度。
4 预测算法及预测任务调度
4.1 动态自适应组合预测模型
对于预测模型而言,在进行自适应训练期间,为提升最终预测准确率,要优先构建和应用动态自适应组合预测模型,并对各个预测模型的历史准确率进行有效的评估和分析,从而实现对各模型权值比例系数的自动化修正。其中,在进行短期预测时,要并行运算指数外推模型、平均模型、决策树模型等;在进行中长期预测时,要综合运用线性回归模型、向量机模型、ARMA 模型等[4]。为保证最终预测结果的精确性和真实性,要结合预测日、工作日、节假日、双休日等日期类型,科学地评估和预测不同权重组合情况。
4.2 基于Spark 流计算的预测任务调度
在进行电网输电负荷预测时,计算效率提升,可以提高用户使用体验,保证高频次滚动计算效率。受计算资源的限制,需要在优化算法流程的基础上,将预测任务科学地分配到相应的节点中,使得计算效率得以显著提升[5]。此外,通过应用流计算技术,对数据进行转换,使其转换为无状态数据、有状态数据。在进行无状态转换时,仅仅用到当前批次数据;在进行有状态操作时,仅仅用到之前批次数据。运用电网输电负荷预测算法,对滑动窗口操作进行短期预测。
4.2.1 基于滑动窗口操作的短期负荷预测
为保证最终短期负荷预测结果的准确率,结合滑动窗口实际操作情况,综合运用历史数据、气象数据、检修数据等,开展相应的短期负荷预测工作,促使滑动窗口操作变得更加规范化、科学化。滑动窗口计算如图1所示。
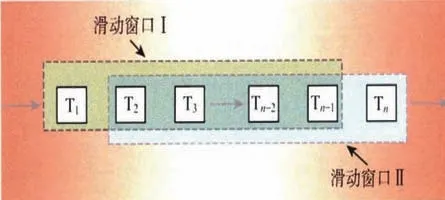
图1 滑动窗口计算
图1中T1-Tn代表各个批次所输入的负荷数据、气象数据等预测数据。通过对数据进行汇集,使其汇集到足够的窗口长度。在导入新批次数据时,需要筛选和剔除最早的数据,完成对批次数据集的组合和构建。预测触发在具体设计和实现时,需要科学地调整和控制滑动窗口时间间隔。这种预测方式的运用,可以提高数据查询效率,缩短数据查询所需时间,最大限度地提高最终计算效率。
4.2.2 基于无状态操作的中长期负荷预测
中长期预测模式存在计算强度大、触发频率低、计算资源浪费等问题。为实现对中长期负荷预测模型的精确化定义,除了要做好对预测日期范围的定义外,还要选用合适的算法。为保证中长期负荷预测结果的准确率,技术人员要重视对基于无状态操作实现方案的制订和使用,在运用该方案时,要做好对任务流的触发处理,当计算操作完成后,触发流程自动退出。当系统监听到人工制定的任务时,会向队列中添加适量的任务,同时,结合CPU 核数,分解和分配当前任务情况。
为进一步地提高中长期预测结果的精确度,简化计算任务的复杂度,避免因出现任务阻塞而降低其他计算任务处理效率,需要利用多线程技术,依次执行和处理多种不同的计算任务,并做好对执行情况的及时报告。
5 应用效果分析
5.1 计算效率提升效果分析
在进行最终计算效率评估期间,分别运用传统模式、微型机群、小型机群三种模式,对某省域电网输电负荷进行中长期预测,输入数据内容见表1。由于受某一条件限制,在以上三种模式下,计算资源配置与性能存在一定的差异,但并未影响最终结果。

表1 输入数据内容
总耗时计算时间对比结果见表2。

表2 计算时间对比
从表2中的数据可以看出,随着机群规模不断提升,计算效率呈现出不断增加的趋势,通过运用基于大数据技术预测方案,达到高效化计算的目的。
5.2 预测准确率提升效果分析
为保证预测准确率评估操作的有效性和可靠性,本文重点分析和对比传统预测方案、基于大数据技术预测方案所获得的预测准确率情况。
首先,采用随机抽取的方式,抽取出1000个负荷样本,并将执行时间控制为1个月,预测准确率对比结果见表3。在传统预测方案中,主要将指数外推法和ARMA 模型法进行有效地结合,滚动执行时间间隔为12h,每天滚动执行2次。在基于大数据技术预测方案,将指数外推法、ARMA 模型法和决策树模型法进行有效的结合,滚动执行时间间隔为4h,每天滚动执行6次。这表明,通过运用基于大数据技术预测方案,可以精细化、详细化呈现出影响因素计算结果,同时,还促使最终分析预测频次不断提升,确保最终预测准确率得以大幅度提高。

表3 预测准确率对比
6 结语
综上所述,大数据技术的出现和应用,为电网输电负荷预测提供重要的技术支持,通过应用该技术,进行数据存储、数据预处理、负荷分析、预测模型构建等环节,不仅提高最终预测结果的准确率,还确保负荷计算效率得以大幅度提高,完全符合实际应用需求,极大地提高用户的使用体验。因此,本文所提出的基于大数据技术的预测方案具有操作简单、实用性强、预测准确率高等特点,完全符合实际应用需求。
猜你喜欢
作文周刊·小学一年级版(2022年24期)2022-06-18 13:11:03
数学大王·趣味逻辑(2021年11期)2021-12-03 11:04:30
内蒙古气象(2021年2期)2021-07-01 06:19:58
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
心声歌刊(2019年5期)2020-01-19 01:52:52
中国交通信息化(2018年5期)2018-08-21 03:37:40
领导决策信息(2018年46期)2018-04-20 04:00:42
河南电力(2016年5期)2016-02-06 02:11:32
