
采用多视角注意力的声音事件定位与检测
2024-03-07 13:05杨吉斌张雄伟梅鹏程
信号处理 2024年2期
杨吉斌 黄 翔 张雄伟* 张 强 梅鹏程
(1.陆军工程大学指挥控制工程学院,江苏南京 210007;2.65334部队,吉林四平 136000)
1 引言
声音事件定位与检测(Sound Event Localization and Detection,SELD)主要目的是通过接收到的音频信号,识别出包含在其中的单个或多个声源对应的事件类别信息,并且估计出对应的位置或波达方向(Direction of Arrival,DOA),其应用涵盖了如声音场景分析[1]、监控[2-3]、生物多样性检测[4]、城市声音传感[5]等领域。
基于深度学习的SELD模型可以利用深层网络自动提取特征,同时学习复杂信号和事件类别、波达方向之间的映射关系[6-7],有效提升检测和定位的性能。文献[8]提出了SELDNet 模型,采用卷积递归神经网络(Convolution Recurrent Neural Network,CRNN)结构,对多通道音频信号的幅度谱、相位谱输入进行估计。该模型利用二维CNN提取音频的时频深层表示,并利用GRU模块学习音频序列中不同声源类别和方位。文献[9]在CRNN 模型的基础上使用三维卷积来同时对输入的多通道信息进行时域、频域和通道域卷积计算,学习到更多的通道间和通道内特征。遵循信号处理思路,文献[10-12]等网络针对声学事件检测(Sound Event Detection,SED)任务采用梅尔谱、差分相位谱等特征输入,针对DOA 任务采用广义互相关特征输入。这些输入在经过卷积操作后,得到的不同通道特征具有更大的差异性。不仅这些通道内的特征包含输入的类别信息和方位信息,通道间的特征差异也同样包含了输入的类别和方位信息。
为有效利用通道间的特征差异,SELDNet 堆叠了多个循环层实现通道间的信息学习;two-stage 模型[13]和SALSANet 模型[14]也采用堆叠多个循环层的方式学习通道间的信息。多个循环层的使用使得网络计算量增大,训练难度增加。EINV2 模型[15]中使用多头自注意力机制MHSA 代替GRU 来学习通道间的信息差异,一定程度上提高了模型的定位性能。但该模型仅关注了包含所有通道的全局特征差异,对不同通道间的局部差异关注不够,影响了后续检测和定位性能的提升。
通道注意力机制是一种可以有效学习通道间差异的方法。它可以动态地调整不同通道之间的权重,更好地利用不同通道的信息。相比循环层堆叠等处理方法,挤压-激励网络(Squeeze-and-Excitation Networks,SENet)[16]、卷积块注意力模块(Convolutional Block Attention Module,CBAM)[17]、高效通道注意力(Efficient Channel Attention,ECA)[18]等通道注意力机制的计算量大幅减小。文献[19]在SELD中引入了坐标注意力和ECA通道注意力模型,但这两个注意力都是在通道维度上做的,仅与位置有关,忽略了时频空间的注意力设计。针对现有SELD 网络模型未能同时关注声学信号的时间、频率和通道域的问题,本文基于多视角注意力(Multi-View Attention,MVA)[20],提出了一种MVANet 模型。该模型级联了MHSA 模块和ECA 模块,对多维深层特征同时使用时频注意力和通道注意力,帮助模型更精确地获取深层特征中的关键信息,增强声学特征的表示能力。实验结果表明,MVANet 模型可以解决基线模型对通道间信息学习不足的问题,有效提高了SELD的性能。
2 注意力机制
人类听觉注意力可以对感兴趣的声音予以关注,在时频域和空间域中分辨不同属性和不同方位的信号。在深度学习中,注意力机制模拟人类感知系统的机制,对输入特征的不同部分之间动态分配不同的权重或关注程度,自动选择重要特征或信息[21]。已有研究表明,自注意力、多头自注意力机制等可以有效改善对语音、图像等感知信号的处理性能[22-23]。
2.1 通道注意力
作为一种注意力机制实现技术,通道注意力可以调整不同通道的权重,来增强有用特征的表达。对于输入特征X∊RB×C×M×N,对每个通道采用池化、卷积等方法计算其重要性得分,然后利用softmax等函数将其转化为权重系数,作为通道维度乘以输入的特征X,最终得到包含不同重要性的特征图。
通道注意力的计算如式(1)所示。
其中,fpool(X)表示对X进行全局池化操作,fw表示一个多层感知器或者卷积神经网络,fact表示激活函数,Xout是最终带有不同权重的输出特征图。
典型的通道注意力机制有SENet、CBAM、ECA等。在实现时,SENet 和ECA 的fpool采用全局平均池化操作;而CBAM 同时使用了平均池化和最大池化操作。SENet 和CBAM 的fw采用全连接层实现;而ECA 使用一维卷积来计算通道间的权重。三种注意力模块的激活函数fact也存在区别,SENet 使用ReLU 函 数,ECA 使 用Sigmoid 函 数,CBAM 使 用Sigmoid和ReLU 结合的方式。图1展示了这3种注意力实现时的具体区别。

图1 三种通道注意力模型图Fig.1 Diagrams of three channel attention models
2.2 多头注意力
MHSA 用于提取通道内的信息,它通过同时学习多个注意力权重,提高模型对于各通道内不同位置上特征的关注度。MHSA的计算公式如下:
其中,Headi(X)数表示第i个单头的自注意力机制,X表示多头注意力的输入向量序列,(WQ)i,(WK)i,(WV)i分别表示第i个自注意力机制对应的查询、键、值的权重矩阵,h表示头数,dk是键向量的维度。通过对所有头的结果进行拼接,得到最终输出,然后再通过一个线性变换WO得到最终的输出结果。
3 采用多视角注意力的SELD模型
3.1 MVANet模型
本文提出的基于多视角注意力的模型MVANet包含SED 和DOA 两个分支,两个分支使用不同的输入特征,SED 分支使用4 通道的对数梅尔特征,DOA 分支使用对数梅尔+强度向量(Intensity Vector,Ⅳ)7 通道的特征组合。每个分支主要由三个模块组成,分别是二维卷积模块、多视角注意力模块和全连接模块。在两个分支之间,采用部分软参数共享机制实现SED 和DOA 两个任务的交互。模型的输出采用轨迹(Τrackwise)格式,在2 个声源重叠的条件下,每个分支设置2个轨迹输出。MVANet模型框架具体如图2所示。

图2 MVANet模型结构图Fig.2 Diagram of MVANet model
3.1.1 二维卷积模块
二维卷积模块由两个二维卷积编码层和一层二维平均池化层组成。其中每个二维卷积编码层包含一层核大小为3×3 的卷积、一个归一化层(Batch Normalization,BN)和一个ReLU 非线性函数。在SED和DOA分支中,分别堆叠4次二维卷积模块,不同时间和频率分辨率下提取音频信号的高层次特征。由于SED 和DOA 的输入不同,对两分支的二维卷积模块部分进行软参数共享,可以有效补充深层特征学习的准确性。
3.1.2 多视角注意力模块
本文采用多视角注意力模块实现不同分支上的轨迹划分。每条轨迹中都有一个完整的MVA 模块,该模块由通道注意力和多头注意力级联组成。在MVA 模块中,通道注意力采用ECA 模块对通道间的特征进行关注,为不同通道分配权重。多头注意力实现对通道内时频率信息的提取。在SED 和DOA 分支上,对应轨迹的MHSA 模块间使用软参数共享来实现信息交互。
3.1.3 全连接(Fully Connected,FC)模块
全连接模块由一层线性层和一个激活函数组成。SED 和DOA 两个分支的全连接模块结构不同。SED分支中,FC模块将多视角注意力模块的结果转化为表示SED 事件活跃状态的向量,向量长度等于事件总个数。使用sigmoid 激活函数将结果输出成概率,并利用设置的阈值将输出结果转换为0或1,表示声音事件是否为活跃状态。DOA 分支中,线性层将多视角注意力模块的结果映射为各声源所在的方位,输出结果为笛卡尔坐标(x,y,z)。再使用Τanh 激活函数将(x,y,z)坐标值转换为-1到1 范围内的连续值,从而可以获得更加精细的定位结果。SED 和DOA 的结果采用轨迹输出格式,具体对应的向量如下所示。
其中,αmi表示第m个轨迹上第i个事件类的概率,S表示事件类总数,M表示轨迹数,即重叠源的最大数量。式中,每条轨迹只允许一个事件活跃且仅输出该事件对应的DOA 估计。可以看出这种输出格式适用于同类别多声源的情况。
MVANet 的两个分支采用相同的结构,总体结构参数如表1所示。

表1 MVANet模型结构参数表Tab.1 Structural parameters of MVANet model
3.2 损失函数
本文使用二进制交叉熵(Binary Cross-Entropy,BCE)损失函数和均方误差(Mean-Square Error,MSE)损失函数来优化模型,前者用于SED 任务,后者用于DOA 任务,两个任务的损失进行加权得到SELD模型的总损失。具体公式如式(6)所示:
其中,α表示损失函数的权重。SED 损失函数公式如式(7)所示:
其中,pi和gi代表第i个样本的事件真实检测结果和预测结果,n表示总样本数。DOA 损失函数公式如式(8)所示:
其中,(uref)i和(upre)i分别代表第i个样本的真实声源坐标(xG,yG,zG)和预测声源坐标(xE,yE,zE)。
4 实验设计和结果分析
4.1 数据集
本文在ΤAU 2020数据集[24]上进行了验证实验。ΤAU 2020数据集包含600个时长为一分钟的录音文件,信号的采样频率为24 kHz。数据集中有14类室内声音事件,在合成多通道数据时使用的房间脉冲响应通过10 个室内位置实际收集得到。此外,ΤAU 2020数据集包含了30分钟的室外环境噪声记录,声源的位置也是移动的,数据贴近现实生活条件。
4.2 评价指标
本文选用定位和检测联合评估性能作为评价指标[24]。SED 任务采用和位置相关的F1 得分和错误率ER(Error Rate,ER),即仅考虑在DOA 距离差小于特定应用阈值时预测的真阳性情况,阈值一般设为20°。DOA 任务指标为定位误差LECD(Localization Error,LE)和定位召回率LRCD(Localization Recall,LR),只有在类预测结果与给出的评估结果一致时,才会计算相应的LECD和LRCD。其中,对于SED 评估,F1 和ER 指标可以按段或帧级别进行计算。F1 得分、LRCD越高,模型性能越好,而ER 和LECD值越低,说明模型估计越准确。
根据事件预测值和标签值的取值不同,可以将结果分为真阳性(Τrue Positives,ΤP)、假阳性(False Positives,FP),假阴性(False Negatives,FN)和真阴性(Τrue Negatives,ΤN)这四种情况。基于帧级别的F1指标的计算公式为:
ER指标的计算公式为:
其中,N(k)表示声音事件真正活动的事件数,S(k)表示检测到的声音事件类中预测错误的事件数量,I(k)和D(k)分别表示插入和删除的种类的数量。可用式(11)表示:
对于DOA 评估,LR 指标和LE 指标的计算方式为:
4.3 实验设置
在验证实验中,网络模型基于PyΤorch 框架实现,采用EINV2 作为基线方法。为了确保公平的比较,MVANet模型的训练参数保持与基线方法相同。在实验前90轮,学习率设置为1×10-3,在最后10轮,将学习率设置为1×10-4。模型使用Adam 优化器默认参数进行损失优化,SED 和DOA 估计分别采用BCE和MSE损失函数,损失权重设置为0.5。验证实验在配备NVIDIA 2080Τi GPU的工作站上进行。
4.4 实验结果分析
4.4.1 单视角注意力的性能对比
为测试单视角注意力在SELD 任务中的性能,在EINV2网络的基础上,将原有的MHSA模块替换成不同的通道注意力模块,分别测试了不同通道注意力、MHSA 在ΤAU2020数据集上的性能。具体结果如表2所示。最优的指标得分用黑体表示。

表2 单视角注意力在EINV2上的性能对比Tab.2 Performance comparison of different single-view attention methods for EINV2 model
由表2可见,仅使用通道注意力关注通道信息,效果在各个指标上都比MHSA 模型差,这是因为模型在最后只关注了深层特征的通道间的差异,缺少了对深层特征通道内差异的关注,削弱了时频域关键信息的提取。比较三种通道注意力的结果可以发现,ECA 在所有指标上都优于SENet,和CBAM性能相比,在ER≤20°指标上持平,在LRCD指标上略低。总体而言,ECA的性能最优。
4.4.2 多视角注意力的性能对比
表3 中对比了MVANet 中分别采用SENet、CBAM、ECA 三种通道注意力的效果。同时,MVANet 中采用MHSA 实现时频域上的注意力机制,与EINV2 的实现方案一致,因此将EINV2 作为基线系统进行对比。

表3 不同通道注意力在MVANet模型上的性能对比Tab.3 Performance comparison of different channelattention methods for MVANet model
从表3结果可见,MVANet采用SENet和CBAM实现通道注意力时,在F1≤20°和LRCD指标上获得略微的提升,但在其他方面与EINV2 原模型的性能表现基本相同或者下降,SELD 分数没有明显提高。这是因为SENet 和CBAM 模块中通道注意力部分都使用全连接层进行降维,从而降低网络的复杂性,但是这也会降低通道注意力的预测效果,且已有研究表明学习所有通道的依赖关系是低效的而且并不必要[18]。而MVANet 采用ECA 多通道注意力的方案,各个性能指标都得到了改善,其中LECD降低了0.5°,SELD 分数降低了0.02。这是因为ECA 注意力避免了降维操作,通过一维卷积模块实现了局部跨通道交互,结合MHSA 可以对时空信息进行更精确的建模,增强了网络对时空特征的提取能力。因此,MVANet 模型采用ECA 通道注意力与MHSA进行结合的多视角注意力实现方案。
4.4.3 MVANet模型的实现结构对比
在表3 实验结果的基础上,我们进一步实验对比了多视角注意力不同实现结构的性能。图3给出了ECA模块、MHSA模块以及软参数共享的不同组合结构的示意图,表4 展示了相应结构所对应的实验结果。

表4 ECA模块和软参数共享在MVANet不同位置上的性能对比Tab.4 Performance comparison of ECA module and software parameter sharing in different locations in MVANet

图3 多视角注意力不同实现结构的示意图Fig.3 Different implementation structures for multi-view attention
由表4 的第2、3 行结果可见,ECA 单独加在DOA 分支上效果比单独加在SED 分支上效果好,这说明使用ECA 注意力对DOA 估计影响更大。这是因为不同通道间的差异反映了声源的空间信息,对通道间差异中的重要信息施加关注,有助于克服噪声、重叠等不利因素的影响。对比表中(b)、(c)两种结构的结果,可以发现,在两个分支上面都加入ECA效果优于(b)仅在一个分支上实现多视角注意力的效果,DOA估计的性能提升明显。这是因为MVANet 模型采用了相同的结构实现SED 和DOA两个分支,两个分支之间学习的深层表示在通道间均具有一定的差异性,采用通道注意力有助于关注各个分支中的重要特征信息。
由表4 的第4、5 行结果可见,不同分支的通道注意力间不进行参数共享时,SELD 的性能更精确,效果更好,这是因为SED 和DOA 两个任务中,通道信息的利用方法不一样,SED 需要对通道内的特征进行关注,而DOA 主要是对通道间的特征差异进行关注。对不同分支中的ECA 模块使用软参数共享,会削弱各自任务需要的特征差异,无法体现参数共享的优势。从第6 行结果可见,两种注意力使用先进行ECA 再进行MHSA 的实现顺序时,SELD性能更优,这是因为ECA模块主要关注不同通道之间的差异学习,从而帮助模型更好地捕捉音频在不同通道中的特征,而MHSA 模块则主要关注通道内部不同时间和频率之间的关系,帮助模型进一步地捕捉每个通道中的具体时频特征差异,属于一种从全局到局部学习的递进关系,因此先使用ECA模块再使用MHSA模块会取得更好的效果。
4.4.4 单声源、多声源的性能分析
分别利用单声源和多声源数据对MVANet进行性能测试,以检验模型对多声源的处理效果。表5分别展示了MVANet模型和基线EINV2模型在不同声源情况下的性能。从表中结果可以看出,MVANet模型在单声源和多声源测试集上的性能都明显优于EINV2 模型。在两个声源重叠的ov2 数据集上,MVANet的F1≤20°指标相对上升了6.0%,LECD指标下降了13.5%,改善明显。这说明采用多视角注意力,能够有效提高重叠源的定位和检测性能。

表5 EINV2和MVANet模型在单声源、多声源测试集下的性能对比Tab.5 Performance comparison of EINV2 and MVANet models under mono-source and multi-source test sets
4.4.5 不同数据格式下的性能对比分析
已有研究表明,声学信号的不同数据格式对SELD 性能的影响也不同。ΤAU 2020 数据集中包含了FOA和MIC两种格式的数据。我们对MVANet和基线EINV2 模型在这两种格式数据上的性能进行了比较分析,各指标结果如表6所示。

表6 EINV2和MVANet两个模型分别在FOA、MIC数据格式上的性能对比Tab.6 Performance comparison of EINV2 and MVANet models using FOA and MIC data formats
由表6可见,在FOA格式数据上,MVANet模型相比于EINV2 模型在所有指标上都有所提升,特别是LECD和SELD 指标提升明显;而在MIC 格式数据上,MVANet 模型的表现在ER≤20°、LECD和SELD 分数上均优于EINV2 模型,其中,LECD下降了1.2°,但F1≤20°和LRCD得分略低于EINV2 模型。这表 明MVANet 对SELD 性能的提升,与采用的信号输入格式依然有关。MVANet和EINV2 均采用对数Mel谱和强度矢量作为输入特征。由于FOA 格式是对声学信号在空间进行了谐波域分解,其各通道可与空间笛卡尔坐标系的投影相对应[25],强度矢量特征与声源方位有关。而MIC 格式中,各个信号通道的输入相关性与信号和麦克风之间的夹角有关,强度矢量特征与声源方位、麦克风阵列位置均有关。因此针对FOA格式数据的网络模型,对深层特征施加通道注意力有助于更好地关注声源方位信息,其对DOA 估计的综合性能提升优于针对MIC 格式数据实现的模型。
4.4.6 定位和检测结果分析
图4、图5是ΤAU 2020数据集中mix001和mix012两个数据分别在EINV2 模型和MVANet 模型上的可视化结果对比,其中,x轴代表单个音频文件的总时长。图4 和图5 中的(a)、(b)、(c)子图表示SED 参考值和预测值之间的对比,其y轴用来表示14 个声音事件类的类别标识符;子图(d)~(i)表示方位角和俯仰角的参考值和预测值之间的对比,其y轴分别代表对应的方位角范围和俯仰角范围。mix001 是一段单声源的音频,mix012 是包含多事件重叠源的音频。图中不同声事件用不同颜色表示,如绿色表示钢琴声,红色表示婴儿哭泣声,粉色表示男性演讲声,蓝色表示烧火声,紫色表示警报声等。

图4 EINV2与MVANet在mix001数据上的检测、方位角和俯仰角参考与预测值对比Fig.4 Comparison of EINV2's and MVANet's reference and predicted values of detection,azimuth,and elevation using mix001 data
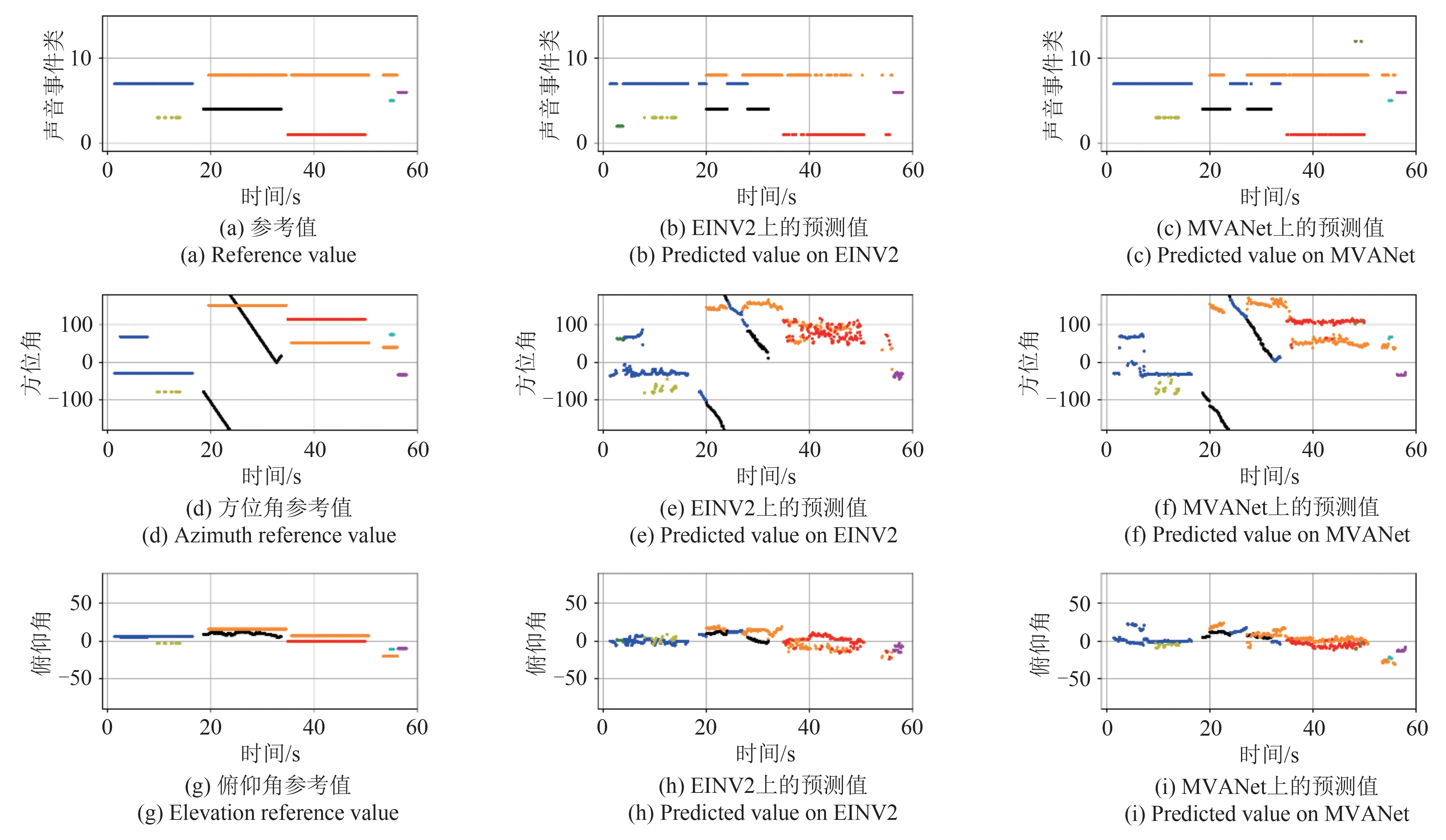
图5 EINV2与MVANet在mix012数据上的检测、方位角和俯仰角参考与预测值对比Fig.5 Comparison of EINV2's and MVANet's reference and predicted values of detection,azimuth,and elevation using mix012 data
图4 给出了单声源条件下的估计结果,从中可以看出,MVANet 模型相比较于EINV2,DOA 估计的轨迹更加清晰,结果更加精确,尤其在第30~40 s内可以看出。图5 给出了多声源数据的估计结果,由图可以看出,在第35~50 s 时间内,MVANet 模型对警报声的类别判定、位置估计更为准确。
5 结论
针对现有SELD模型对声学信号的时空信息关注不够问题,本文提出了多视角注意力的检测与定位模型MVANet。该模型通过通道注意力和多头自注意力级联实现了多视角注意力,同时关注通道间和通道内深层特征的关键信息。特别是针对DOA估计,通道注意力的引入,有助于学习不同通道间特征的差异,能够克服多声源重叠的不利条件。实验优选了通道注意力的实现结构和多视角注意力的级联方案。在ΤAU 2020 数据集上的实验表明,所提出的MVANet 模型相比较于EINV2 模型各个指标都有提升,且在多声源场景下的性能提升效果更为显著。在以后的研究工作中,会继续优化网络模型、损失函数等进一步提高SELD 任务的准确性和对不同应用场景的鲁棒性。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
小雪花·成长指南(2022年1期)2022-04-09
学生天地(2019年28期)2019-08-25
电子制作(2019年23期)2019-02-23
数学物理学报(2018年1期)2018-03-26
传媒评论(2017年3期)2017-06-13
噪声与振动控制(2016年5期)2016-11-09
第二课堂(课外活动版)(2016年2期)2016-10-21
舰船科学技术(2015年8期)2015-02-27
山西大同大学学报(自然科学版)(2014年3期)2014-01-23
