
基于深度学习的盲道和盲道障碍物识别算法
2024-03-07 06:37:58马文杰张轩雄
电子科技 2024年3期
马文杰,张轩雄
(上海理工大学 光电信息与计算机工程学院,上海 200093)
视觉是人类重要的感官之一,缺失视觉感官对盲人的生活受到较多限制。据统计,中国视障人数目前已超过1 731万人,随着盲人数量的增加以及交通的快速发展,其出行问题越来越受到社会的关注。目前盲人主要的出行方式是借助导盲拐杖、盲道和导盲犬。由于部分盲道不规范、盲道占用以及交通环境复杂等原因,导盲杖和盲道在某些情况下并不能较好地发挥作用,而且导盲犬的数量也较少,无法满足大部分盲人的需要。所以确保盲道位置以及盲道是否有障碍物对盲人出行安全较重要。
随着科学技术迅速发展,越来越多的新技术应用于导盲领域。在盲道分割方面,文献[1]提出一种基于颜色信息的提示盲道检测算法。文献[2]提出了利用Gabor特性来实现盲道的划分。传统的图像处理方法因其色彩多样、纹理多变导致准确率低且速度慢。因此,基于深度学习的盲道分割技术应运而生。文献[3]对SegNet网络进行了改进,并给出了盲道分割的模型。文献[4]设计了一个轻量级语义分割网络用于盲道和人行横道快速检测。
关于盲道障碍物检测,包括超声波、红外线以及GPS(Global Position System)等方法。文献[5]使用飞行时间和触觉反馈设备为视障用户提供安全的本地导航。文献[6]设计了一种基于视觉标记和超声障碍物检测的盲人用户可穿戴式室内导航音频辅助设备。文献[7]设计了一种基于GPS和超声波的导盲拐杖。随着机器视觉和深度学习的出现,盲道障碍物检测也有了新方法。相较于传感器的方法,图像可以获得更多有效信息。目标检测的网络较多,有R-CNN(Regional-Convolutional Neureal Networks)[8]系列(R-CNN, Fast R-CNN, Faster R-CNN, Mask R-CNN)、YOLO(You Look Only Once)[9]系列以及SSD(Single Shot MultiBox Detector)[10]等模型。文献[11]等通过YOLOv4算法对盲道障碍物进行检测。文献[12]提出了一种基于YOLO的机械导盲犬视觉识别算法,可以检测道路中存在的障碍物。
目前的研究局限于盲道分割或盲道障碍物检测其中的一种,但对于盲人来说两者缺一不可。单独实现这两个任务需要较长时间以及更多的资源,并且这两个任务具有较多相关信息,所以多任务网络更适合这种场景,原因主要有:1)可以一次处理多个任务而非逐个处理,可以加快图像处理进程;2)多个任务间可进行信息共享,从而提高了工作效率[13]。本文提出一种可以同时完成盲道分割和盲道障碍物检测的多任务网络模型。该模型由公共特征提取网络、特征融合网络、盲道分割网络和盲道障碍物检测网络组成,同时改进损失函数,引入修正损失函数(Rectify_Loss),可以让盲道分割更加平整、精确。为了提高障碍物检测召回率,将检测网络的NMS替换为Soft-NMS。
1 相关理论
1.1 SegFormer网络
SegFormer[14]是一个将Transformer与轻量级多层感知器(Multilayer Perceptron,MLP)解码器统一起来的语义分割框架,网络框架如图1所示。

图1 SegFormer网络结构Figure 1. The SegFormer network structure
SegFormer由Encoder和Decoder2个主要模块组成。1个分层的干网络骨(Transformer Encoder)用于生成高分辨率的粗特征和低分辨率的细特征,1个轻量级的分割网络(All-MLP Decoder)融合多级特征,产生最终的语义分割掩码。
SegFormer的优势在于:1)SegFormer设计了1个新颖的分级结构Transformer Encoder,输出多尺度特征。它不需要位置编码,从而避免了位置编码的插值(当测试分辨率与训练分辨率不同时会导致性能下降);2)SegFormer避免了复杂的解码器。SegFormer中的All-MLP Decoder从不同层聚合信息,从而结合局部关注和全局关注来呈现强大的表示。
1.2 RetinaNet网络
RetinaNet[15]算法是一种基于锚点(Anchor)的单阶段目标检测模型,即直接对图像进行计算生成检测结果。其网络结构如图2所示。
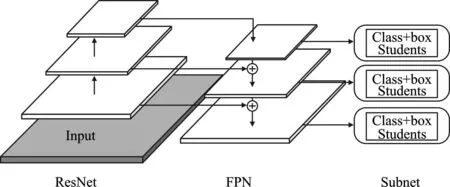
图2 RetinaNet网络结构Figure 2.RetinaNet network structure
RetinaNet检测网络由1个主干网络(Backbone)和2个子网络(Subnet)组成。其中,Backbone由ResNet[16]和特征金字塔(FPN)[17]共同组成,有ResNet-50-FPN和ResNet-101-FPN这2种形式,区别在于网络的深度不同。通过命名形式可以发现,Backbone由ResNet和FPN这2个网络共同构成,FPN通过利用自上而下的路径和横向连接的方式扩展了ResNet。因此,RetinaNet可以有效地对输入图像构建丰富的多尺度特征金字塔,金字塔中的每一层都可以用来探测不同尺度的物体。
2 本文网络结构
本文提出一种简单高效的多任务网络,可以同时完成盲道分割和盲道附近障碍物的检测任务。在减少推理时间的同时提高了每项任务的性能,网络结构如图3所示。

图3 本文网络结构Figure 3. The proposed network structure
网络组成:1)SegFormer网络的Transformer Encoder作为整个网络的Backbone部分,负责整个网络共享的特征提取;2)本文网络的Neck主要由空间金字塔(SPP)[18]和特征金字塔(FPN)[17]组成,用于网络的特征融合;3)分割头由SegFormer网络的All-MLP Decoder构成;4)检测头由RetinaNet网络的FCN(Fully Convolutional Networks) Detection Head组成。两个任务共用一个特征提取器,减少了参数量和计算量。然后改进分割网络和检测网络的损失函数,将检测网络的NMS替换为Soft-NMS,进一步优化分割和检测效果。
2.1 骨干网络(Backbone)
Backbone网络用于提取输入图像的特征。由于Transformer Block引入自注意力机制,其相比于CNN,可以更好地抓住全局特征,所以本文使用SegFormer网络的Transformer Encoder作为本文网络的主干。Transformer Encoder是一个分层的Transformer编码器,可以生成高分辨率的粗特征和低分辨率的细特征(可用于解码阶段的融合)。对于给定图像,首先将其划分为多个较小的Patch,然后输入到分级Transformer编码器,以获得原始图像分辨率的(1/4,1/8,1/16,1/32)的多级特征[14]。
Transformer Block采用多个叠加的Efficient Self-Attention和Mix-FFN(Feed Forword Networks)加深网络深度,以提取丰富的细节和语义特征。每一个尺度都在Efficient Self-Attention中进行了自注意力计算。Transformer Block的构成如图4所示。
Overlapped Patch Embeddings:在VIT(Vision Transformer)中将1个输入N×N×C的Image,合并为1×1×C的向量。利用这种特性将特征图的分辨率缩小2倍。由于这个过程不能保持Patch周围的局部连续性,所以使用Overlapping的图像来融合,可保证Patch周围的局部连续性[14]。为此设置3个参数K、S、P。K是Patch Size,S是Stride,P是Padding。在实验中分别将K、S、P设为(7,4,3)和(3,2,1)来执行Overlapping的图像的融合过程并得到和Non-overlapping图像融合一样大小的Feature。
Efficient Self-Attention:将K和V的特征维度进行缩减。先将K进行Reshape,然后再用Linear做一个特征映射。计算式如下
(1)
(2)
可以把时间由O(N2)缩短到O(N2/R)。
Mix-FFN:采用3×3卷积来学习Leak Location Information,并且采用Depth-Wise卷积来减少参数和计算量,计算式如下
Xout=MLP(GELU(Conv3×3(MLP(Xin))+Xin
(3)
其中,Xin是自注意力模块的特征。
Mix-FFN的结构如图5所示。

图5 Mix-FFN结构Figure 5. Mix-FFN structure
本文模型的编码器采用MiT-B3,主要的参数如表1所示。

表1 MiT-B3主要参数Table 1. MiT-B3 indicates the main parameters
其中,K是Patch Size,S是Stride,P是Padding,C是每个特征维度,R是每个自注意力机制的缩放因子,N是自注意力机制的Head数量,E是前馈层的膨胀率(MLP中间层维数的缩放系数,后面代码的mlp_ratios参数,中间层的维数大小为mlp_ratios×embed_dims),L是每个Transformer Block中Encoder(Efficient Self-Attn和Mix-FFN)数量。
2.2 特征融合网络(Neck)
高分辨率(低层)特征相对与低分辨率(高层)特征有更多的细节信息以及较少的语义信息。为有效利用两者的信息,本文设计了Neck特征融合网络,用于融合Backbone产生的不同层次的特征。本文的Neck主要由空间金字塔池(SPP)模块和特征金字塔网络(FPN)模块组成,网络结构如图6所示。
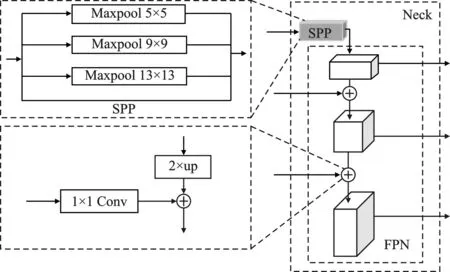
图6 Neck网络结构 Figure 6. Neck network structure
本文将SPP模块引入到网络特征进行池化合并,然后将全局和局部多尺度特征结合起来提高模型的精度[18]。在Backbone输出的最后一个特征层进行4次不同尺度的最大池化处理,最大池化核大小分别为9×9、5×5、3×3、1×1(1×1即无处理)。SPP能够增加感受野,丰富图像的表达能力,对网络精度有一定的提升。
本文的FPN网络主要是将特征提取网络的最后3层特征通过自顶向下的方法,对上层特征图进行2倍上采样后生成与下层大小相同的层,再将横向连接的特征图经过1×1的卷积后与上采样的结果相加,融合不同语义层次的特征,使得生成的特征包含多尺度、多语义层次的信息,采用串联的方法来融合特征[19]。
2.3 盲道分割
2.3.1 盲道分割网络
分割部分使用All-MLP Decoder。本文网络的解码器是将Backbone第1层的输出和Neck特征融合后的3个输出(高和宽分别为原图1/4,1/8,1/16,1/32大小的特征图)作为输入,然后经过MLP操作,再进行融合[14],主要包含以下4步:
步骤1将输出的4个特征图统一维数;
(4)
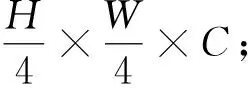
(5)

(6)
步骤4使用MLP层进行分类。
M=Linear(C,Ncls)(F)
(7)

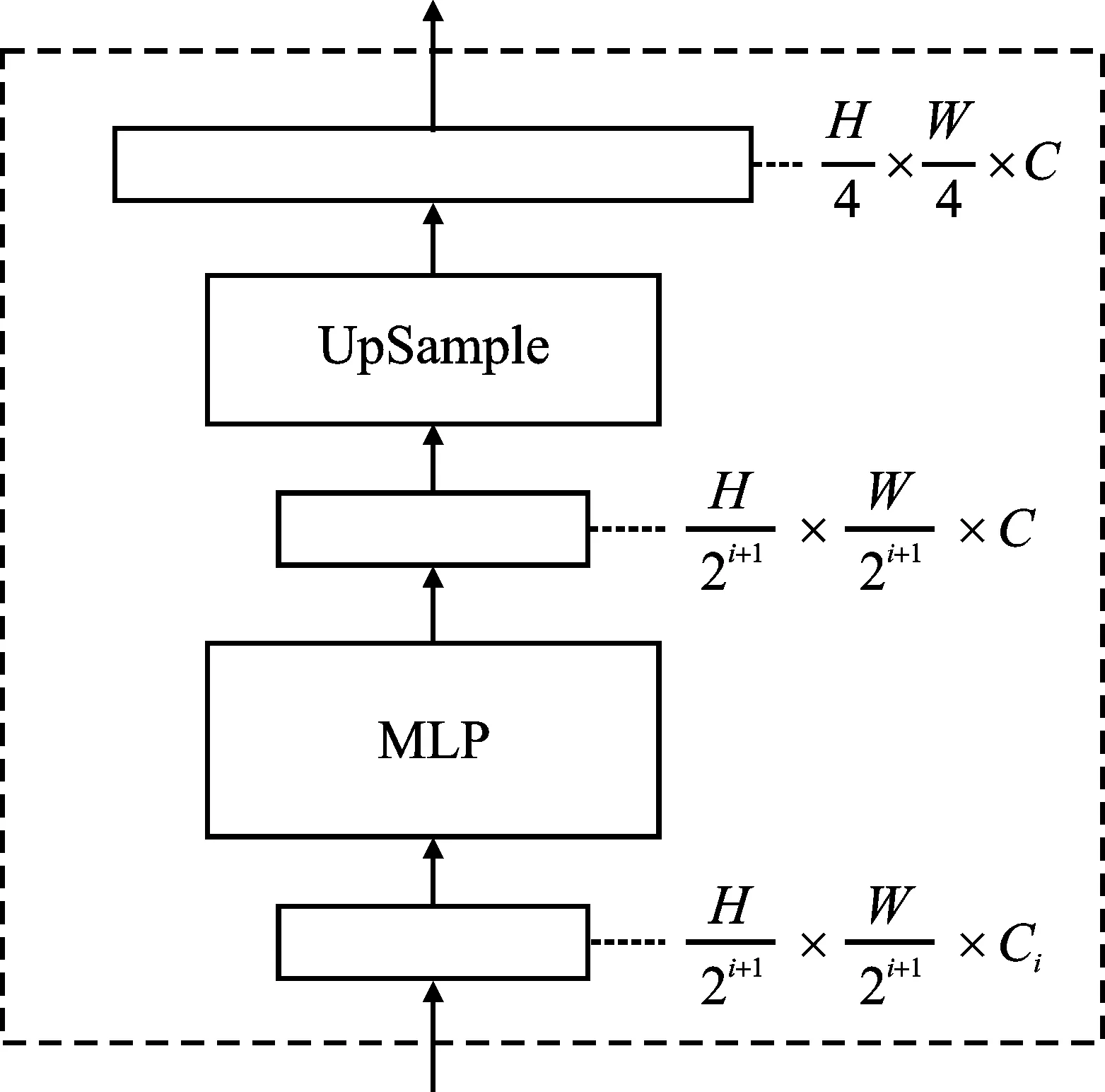
图7 MPL结构 Figure 7. MPL structure
2.3.2 交叉熵损失
分割网络采用基于深度学习的图像语义分割领域常用的交叉熵(Cross Entropy,CE)函数作为损失函数,测量预测值和真实标签之间的相似度,计算式如下
(8)

2.4 盲道障碍物检测
2.4.1 盲道障碍物检测网络
障碍物检测部分使用全卷积预测头。预测头分为2个分支,分别预测每个Anchor所属的类别以及目标边界框回归参数。在最后的KA中,K是检测目标的类别个数;A是锚点数目。
Subnet对由Backbone得到的特征图(Feature Map)进行操作,由两部分组成:一部分负责对目标进行分类,另一部分负责对边界框进行回归。其中,分类子网连接FPN中每层的全卷积网络(FCN),参数在金字塔层间的分类子网中共享,使用4个3×3的卷积层。每个卷积层后接一个ReLU(Rectified Linear Unit)层,之后是通道数为KA的3×3卷积层,最后使用Sigmoid函数进行激活。边界框回归子网结构与分类子网基本一致,差别在于最后的3×3卷积层的通道数为4A[15]。Subnet结构如图8所示。

图8 Subnet结构Figure 8. Subnet structure
2.4.2 盲道障碍物检测损失函数
本文盲道障碍物检测使用Focal Loss作为分类损失函数。Focal Loss通过降低简单样本和负样本的权重可解决正负样本不均衡问题。本文盲道障碍物检测损失函数如下所示:
1)分类损失CLS_Loss计算式
(9)
其中,N表示检测出来的物体个数;通过αt可以抑制正负样本的数量失衡;通过γ可以控制简单/难区分样本数量失衡。在实验中γ=2,αt=0.25,此时表现最好。
2)回归损失REG_Loss计算式
(10)
其中,I为指示函数;tx、ty是真实目标中心在水平和垂直方向的平移量;px、py是预测的目标中心在水平和垂直方向的平移量;th、tw是真实检测框的高度和宽度;ph、pw是预测检测框的高度和宽度;SmoothL1损失函数计算式如下
(11)
3)总的检测损失函数DET_Loss计算式
DET_Loss=CLS_Loss+REG_Loss
(12)
2.4.3 引入Soft-NMS
本文实验的数据集中存在多个同类别距离过近的情况,使用传统的非极大值抑制(NMS),这些目标置信度低于最大置信度而被抑制可能出现漏检的情况,对盲人造成安全隐患。为了解决该问题,本文引入Soft-NMS[20]来提高检测算法的精确度。对于一个与得分最大框的交并比(Intersection over Union,IoU)大于阈值的框,Soft-NMS算法不是将其删除,而是用较低的分数取代原来较高的分数,取得更好的效果。计算式如下(本文采用高斯加权)
(13)
其中,Si表示保留的预测框结果;A表示得分最大的预测框;Bi表示与得分最大预测框相近的预测框;IoU表示交并比;σ表示标准差;e表示欧拉数。
2.5 改进分割损失函数
经过分割后的盲道区域存在较多凹凸不平的瑕疵区域,导致分割出来的效果并不平整,需要进一步加工。考虑到盲道区域为规整直线组成的区域,可以根据实际框的斜率作为参考,利用SmoothL1损失函数结合Dcie损失函数和原来的交叉熵损失函数形成新的分割损失函数,可以对规整的盲道边缘做出更精确地分割。
1)修正损失函数Recitify_Loss计算式如下
(14)
其中,I为指示函数;j为分割框的边缘采样边;kj表示采样边的斜率。对于一个采样边,均匀采样4个点,并在原分割框边缘中找到和它们对应的最近4个点d1、d2、d3、d4,k1、k2、k3、k4分别为d1、d2、d3、d4所在边缘所对应的斜率。
2)交叉熵损失,计算式如下
(15)
3)Dice损失函数,计算式如下
(16)
4)总的分割损失函数Seg_Loss,计算式如下
Seg_Loss=Rectify_Loss+CE_Loss+Dice_Loss
(17)
应用改进的损失函数前后分割效果对比如图9所示。

图9 应用损失函数前后对比(a)原图 (b)原Loss (c)改进后的LossFigure 9. Comparison before and after application of loss function(a)Original image (b)Original Loss (c)Improved Loss
3 实验与结果分析
3.1 实验数据集
3.1.1 数据来源
由于并没有可以直接使用的公开数据集,本文通过相机拍摄和网络爬取两种方式一共获取到1 943张盲道(包含盲道障碍物)图片建立数据集,数据标注通过Labelme软件进行标注,部分数据集如图10所示。

(a)
由于本文网络需要更多的数据集,但数据获取有限,不能较好地满足网络训练要求,并且数据获取较为随机,图片中障碍物分布不均衡,所以本文针对数据集偏少、障碍物分布不均问题对数据集进行数据增强。
3.1.2 数据增强
针对盲道数据集偏少问题,本文通过翻转、旋转、移位、裁剪、融合、变形、缩放等几何变换方法对原有盲道数据集进行数据扩充,部分效果如图11所示。

图11 盲道数据集部分扩充Figure 11. Partial expansion of the blind roads dataset
针对障碍物分布不均问题,本文通过对障碍物进行复制粘贴、旋转、缩放以及MIXUP等数据增强方法融合到其他图片中生成新的数据集的方法来解决,部分效果如图12所示。

图12 障碍物数据集部分扩充Figure 12. Partial expansion of obstacle dataset
最终通过数据增强一共得到3 198张512×512分辨率的数据集。
3.2 实验环境
本文实验采用Pytorch深度学习框架搭建网络模型,CPU(Central Processing Unit)采用Intel(R) Core(TM) i7-10700k,GPU(Graphic Processing Unit)采用Nvidia GTX 3090,操作系统为Ubuntu16.04,开发软件为Pycharm。训练流程:初始学习率为 1×10-5,之后学习率逐渐预热到1×10-3。在前5个epoch中不使用Rectify-Loss。使用Step方式在第24个epoch和32个epoch学习率分别设置为1×10-4和1×10-5。总共36个epoch。
3.3 评价标准
3.3.1 分割指标
本文分割效果评价标准选择交并比(MIoU)和类平局像素准确度(MPA),计算式如下:
(18)
(19)
其中,k+1表示类别总数;pii表示i类的像素预计属于i类的个数,即真正;pij、pji分别表示假正和假负像素的个数。
3.3.2 目标检测指标
本文目标检测评价标准选择平均精度(Average Precision,AP),并利用mAP,即所有目标类的AP平均值来衡量目标检测部分的性能,计算式如下
(20)
(21)
(22)
(23)
其中,n表示检测目标类别数;R为召回率(Recall),表示样本中正样本被预测正确;P为精确度(Precision),表示预测为正的样本中数量真正的正样本数量;TP则为被预测正确的正样本数量;FN为把正样本错误预测为负的数量;FP表示把负样本错误预测为正的数量;TP+FN为全部正样本数量;TP+FP为全部被分为正样本的数量。
3.4 实验结果与对比
3.4.1 盲道分割结果对比
为了验证本文模型的有效性,盲道分割部分分别与FCN、Unet、DeepLab V3+和SegFormer在本文自建数据集中进行对比实验,同其他网络对比结果如表2所示。

表2 不同算法盲道分割结果对比Table 2. Comparison of blind roads segmentation results of different algorithms
由表2可知,改进后的算法盲道分割MIoU可以达到93.25%,MPA可以达到95.29%。相比于直接使用SegFormer,本文的MIoU、MPA分别提高了1.60%、1.66%,相较于其他算法也有一定提升。
3.4.2 盲道障碍物检测结果对比
盲道障碍物检测部分分别与Faster R-CNN、SSD、YOLOV3、RetinaNet(Backbone=ResNet-50)、RetinaNet(Backbone=Transformer)进行对比实验,同其他网络对比结果如表3所示。
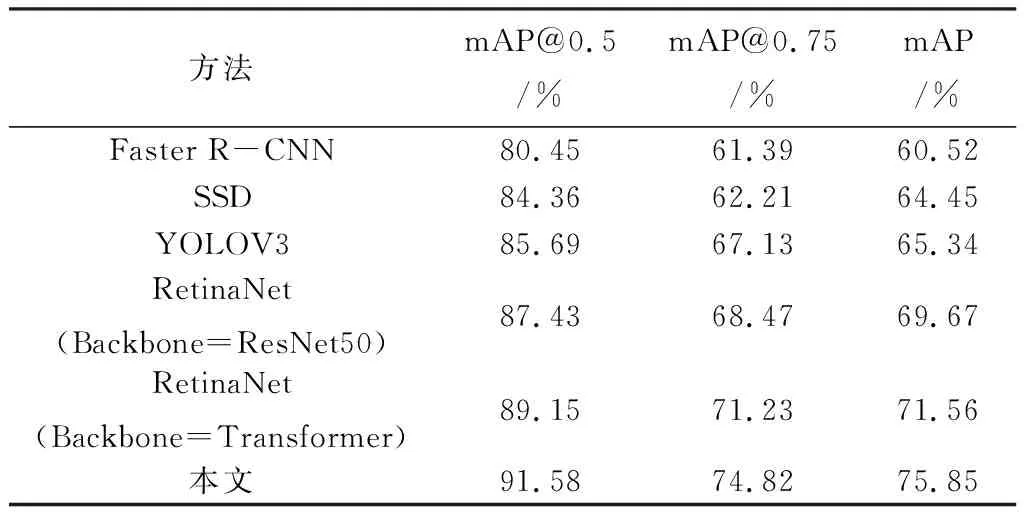
表3 不同算法障碍物检测结果对比Table 3. Comparison of obstacle detection results of different algorithms
由表3可知,本文的盲道障碍物检测算法mAP@0.5可以达到91.58%,mAP@0.75可以达到74.82%,mAP可以达到75.85%。相比于直接使用RetinaNet(Backbone=ResNet50)网络,本文网络的mAP@0.5、mAP@0.75、mAP分别提升了4.75%、9.27%和8.87%,相较于其他算法也有一定提升。
由上述对比结果可知,在盲道分割和盲道障碍物的检测方面,相较于对比算法,本文提出的多任务网络模型在精确度上有一定提升。除此之外,在本文的实验环境中,相较于分别使用SegFormer算法分割盲道、RetinaNet算法检测盲道障碍物,本文的多任务模型预测速度可以提高73.72%,FPS达到18.52。实验结果如图13所示。

(a)
4 结束语
为了解决独立的分割网路和检测网络不能同时满足盲人在出行时对盲道分割和盲道障碍物检测需求的问题,本文提出了以Transformer Encoder为网络主干、SPP和FPN作为特征融合网络、All-MLP Decoder作为盲道分割网络、FCN Detection Head作为盲道障碍物检测网络的多任务识别算法。相较于两个独立的分割和检测网络,由于共享同一个特征提取器,减少了推理时间,显著节省计算成本,并且加入特征融合网络融合多尺度的特征,该算法拥有良好的预测效果。同时改进损失函数,引入修正损失函数(Rectify_Loss),可以使盲道分割更加平整、精确。为了提高障碍物检测召回率,将检测网络的NMS替换为Soft-NMS。经过实验验证,相较于其他对比方法,本文方法在速度和精度方面都有较大的提升,为盲人出行安全提供了新的解决方案。
通过实验分析,本文提出的方法在盲道附近区域颜色和纹理区分不明显的情况下,分割效果会出现一些不足。未来的研究重点在于提高上述特殊情况下的盲道分割精确度,同时本文算法在速度上还需要进一步提升。
猜你喜欢
江西教育·职教版(2022年9期)2022-04-29 00:44:03
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
动漫界·幼教365(中班)(2020年3期)2020-04-20 11:03:27
铁道通信信号(2020年9期)2020-02-06 09:15:54
青少年日记·小学生版(2019年2期)2019-09-02 13:37:38
今日农业(2019年15期)2019-01-03 12:11:33
小主人报(2016年2期)2016-02-28 20:46:28
广西民族大学学报(自然科学版)(2015年3期)2015-12-07 00:56:05
小学生作文·小学低年级适用(2014年7期)2014-09-10 15:45:50
城市道桥与防洪(2014年5期)2014-02-27 07:26:44
