
面向文献评价的引文网络结构多样性研究
2024-03-05 08:33鲁英杰盛立琨张应龙
计算机应用研究 2024年2期
关键词:评价指标
鲁英杰 盛立琨 张应龙

收稿日期:2023-06-05;修回日期:2023-08-22 基金项目:国家自然科学基金资助项目(61762036);福建省自然科学基金资助项目(2023J01922,2021J011007,2021J011008,2022J01916)
作者简介:鲁英杰(1996—),男,江苏南京人,硕士研究生,主要研究方向为数据挖掘、机器学习;盛立琨(1979—),女,江西南昌人,馆员,硕士,主要研究方向为图书馆学;张应龙(1979—),男(通信作者),陕西绥德人,副教授,硕导,博士,主要研究方向为数据挖掘、机器学习(zhang_yinglong@126.com).
摘 要:鉴于从海量文献中寻找高质量文献的重要性,提出了一种文献评价指标——引文网络结构多样性。大规模数据集上的数据分析实验分析了该模型作为文献评价指标的可行性,并针对数据集引用关系存在缺失的情况提出改进模型,使之更加适用于引文网络分析。数据分析实验结果显示文献引文網络结构多样性与引用量显著线性相关,且引文网络结构多样性是影响文献发表后引用量变化趋势的重要因素。在引用量预测实验中,各结构多样性在85.8%的实验中提升了模型的预测性能,其中组合结构多样性在长期引用量预测实验中效果突出,对决定系数R2最高提升22.19%,平均提升14.55%,对均方误差MSE最高提升22.76%,平均提升17.34%。
关键词:结构多样性;引文网络;评价指标
中图分类号:G250 文献标志码:A
文章编号:1001-3695(2024)02-013-0408-07
doi:10.19734/j.issn.1001-3695.2023.06.0270
Research on structural diversity of citation network oriented to
evaluation of literature
Lu Yingjiea,b,Sheng Likunc,Zhang Yinglongb
(a.Department of Computer Science,b.School of College of Physics & Information Engineering,c.Minnan Normal University Library,Minnan Normal University,Zhangzhou Fujian 363000,China)
Abstract:In reiw of the importance of finding high-quality literature from massive literature,this paper proposed a literature evaluation index—citation structural diversity.It analyzed the feasibility of this model as a literature evaluation index through data analysis experiments on large-scale datasets,and then proposed an improved model to make it more suitable for citation network analysis.The data analysis results show that the structural diversity of citation network is significantly linearly related to the paper citation number,and the structural diversity of citation network is an essential factor affecting the citation number change trend after the publication of the literature.In 85.8% of the citation prediction experiments,structural diversity has improved the performance of models.The combined structural diversity has a prominent effect in the long-term citation prediction experiment,with a maximum increase of 22.19%,an average increase of 14.55% for the determination coefficient R2,and a maximum increase of 22.76%,an average increase of 17.34% for the mean square error MSE.
Key words:structural diversity;citation network;evaluation index
0 引言
学术文献是人类宝贵的大数据,长期以来都是人类思想与文化的核心,既保存学术成就的记忆,同时也是创新的源头。迄今为止,科技文献已经发展成为数量庞大、种类繁多、功能各异、内容丰富和互为补充的文献情报体系,是整个科学交流系统的重要组成部分[1]。科技文献爆炸式增长,其数量每九年翻一番[2],导致目前单纯依靠人力投入的研究模式出现了信息瓶颈、知识瓶颈、经验瓶颈等问题。在海量文献数据中寻找新颖的、与研究方向相关的重要文献,对于科学界的大多数研究者来说,已经成为一项挑战。同行评议和文献计量是评价学术文献的两种重要方式[3]。引文是学术论著的核心要素之一,引用关系构成了具有内在联系的文献引文网络[1],是一种重要的知识网络,体现了人类知识发展和演化的过程。相比于同行评议的主观性和较高获取难度,文献引用量已经成为评价文献学术价值的黄金标准[4]。
引文网络分析的内涵和方法也随着社会网络分析方法的发展得以不断丰富。鉴于从海量文献中挖掘潜在的高价值、高影响力文献的重要性,本文将社会网络中的结构多样性(structural diversity)[5]指标引入引文网络研究中,尝试探究其与文献引用量之间的关系。结构多样性从社会网络的拓扑结构特征出发,研究影响人类决策的机制[6]。大量实验表明结构多样性是衡量网络中节点影响力的重要指标[5,7~10]。文献发表后被更多不同学科方向的文献认可引用,显然具有更好的跨学科特性,创新性往往也更强,从而在一定程度上反映了文献质量。基于以上认知和前人工作的启发,本文提出了引文网络结构多样性模型,用以评价文献质量。本文主要贡献有以下三点:
a)首次将结构多样性理论及相关模型从社会网络引入引文网络,提出引文网络结构多样性模型,并针对引用缺失问题改进模型,使之适用于引文网络相关研究。
b)通过详细的数据分析實验,揭示了结构多样性与文献引用量的关系,并对文献发表后引用量变化趋势与结构多样性的关系进行实验研究,为未来引文网络研究提供新的重要指标和评价方法。证明了结构多样性指标用于评价文献质量的可行性。
c)在大规模真实引文数据集上进行文献引用量预测任务。在引用量预测模型对照实验中,添加结构多样性相关参数后的改进模型,大部分性能得到提升,证明了结构多样性指标用于引文网络分析的有效性。
1 相关研究
引文网络将文献视为节点,文献间的引用关系视为有向边,由于文献引用的特殊性,有向边具有单向性且不成环。引文网络是文献计量学的常用研究载体,是一个复杂的系统,它代表知识从一个研究者传递到另一个研究者。知识流可以促进学术创新,也可以用于设计评价指标,以评估作者和机构的贡献[11]。
1.1 文献评价指标
文献评价指标一直是文献计量学领域的重要研究方向,除了通过文献引用量,研究者还从作者权威性特征(如h-index[12] 、文献生产力[13] 、领域权威性[14])、作者社交性特征(如作者数量[15]、共合作关系[16]、跨团体影响力[17])、文献文本特征[18,19]、期刊会议权威性特征[20]、引文网络拓扑特征(如PageRank[21]、PaperRank[22])等对文献进行系统评价,以期挖掘出高质量、高创新度的潜在论文,本文所提结构多样性为引文网络拓扑结构特征。
1.2 结构多样性
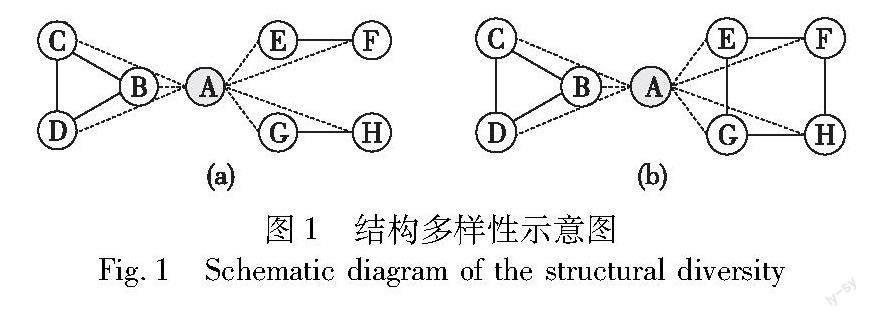
节点的结构多样性描述了节点的邻居节点中连通分量个数[5],如图1(a)所示,由节点A的邻居节点B-H及其边构成的子图中共有三个连通分支{B,C,D}、{E,F}、{G,H},则图1(a)中节点A的结构多样性为3,同理图1(b)中节点A的结构多样性为2。通常高结构多样性节点在网络中具有更高的影响力,在行为预测[7,23~25]、推荐系统[26~28]等领域有着重要应用,同时结构多样性是社会网络分析模型的重要特征[29~33],但也有研究发现在某些情况下低结构多样性节点具有更高影响力[7,34]。
2 引文网络结构多样性模型及改进模型
结构多样性模型在社会网络领域发展成熟,有着较为广泛的应用。节点的结构多样性描述了节点的邻居节点中连通分量个数,通常高结构多样性节点在网络中具有更高的影响力,在行为预测、推荐系统等领域有着重要应用,同时结构多样性是社会网络分析模型的重要特征。鉴于结构多样性在社会网络分析中的重要性,将其引入引文网络。
考察数据集[27]中发表于2012年的两篇文献,文献A(Yang W,Wang K Q,Zuo W M,Neighborhood component feature selection for high-dimensional data)和文献B(Alexander M R,Roi R,Michael C,Amir G,Improved parsing and POS tagging using inter-sentence consistency constraints)。其中文献A于发表后第三年被5篇文献引用,此时文献B引用量为18;但在2021年时文献A的引用量达到了69,而文献B仅为26。进一步用结构多样性思想研究其引用特点,发现文献A虽然在发表后第三年时引用量仅为5,但引用该文献的研究均来自不同领域,而引用了文献B的18篇文献间存在较多引用关系,来自相同研究领域。从结构多样性理论的角度解释,显然文献A在发表初期其引用文献结构多样性较高,而文献B与之相比要低很多,结构多样性高的节点在网络中具有更强的影响力,因此文献A在未来获得了更多引用。
上述案例也间接证明了将结构多样性思想引入引文网络的可能性,而引文网络与社会网络显著不同,具有有向性无回路等特征,因此需要依据引文网络模型构建面向引文网络的结构多样性模型。本节首先给出构建模型所需的基本定义,然后给出引文网络的结构多样性模型并分析其存在的问题,最后提出了三种改进的引文网络结构多样性模型。
2.1 基本定义
定义1 引文网络图。D=〈V,〉引文网络图,其中V为文献集合,有向边〈u,v〉∈表示文献u引用了文献v。
定义2 文献v的施引文献集。已知引文网络图D=〈V,〉,文献v∈V的施引文献集Iv={u|〈u,v〉∈}表示所有引用v的文献集合。
定义3 施引文献集Iv导出子图。 已知引文网络图D=〈V,〉,施引文献集Iv的导出子图D[Iv]n=〈V′,′〉,其中V′Iv,且u∈V′中的文献u均为文献v发表后n年内(包含n)发表,′={〈u,v〉|u,v∈V′∧〈u,v〉∈} 。
定义4 有向图D的基图。 用无向边代替该有向图中的有向边得到的无向图,记为G(D)。
定义5 连通分支数。 图G连通分支数表示图G的连通分支的数量,记为p(G)。
2.2 引文网络结构多样性模型
定义6 引文网络结构多样性。已知引文网络图D=〈V,〉,D[Iv]n为文献v的施引文献集Iv的导出子图,则文献v的引文网络结构多样性sd(v,n)为导出子图D[Iv]n的基图的连通分支数,即sd(v,n)=p(G(D[Iv]n))。
如图2所示,文献S发表后3年内,被文献C1、C2、C3引用;S施引文献集IS的导出子图D[IS]3=〈V′,′〉,为图2红色虚线标出部分,其中V′={C1,C2,C3},′=〈C3,C2〉;在有向图D[IS]3的基图中,C1独自属于一个连通分量H1,C3与C2 同属一个连通分量H2,此时文献S的引文网络结构多样性sd(S,3)=2。需要注意的是,本文所有结构多样性模型中,有向边只用于判断引用与被引用的关联关系,使用的是弱连通性法[34],且引用关系不可能出现强连通的情况,为方便计算忽略方向,故在有向图的基图中分析连通性可以准确地获得文献引文网络结构多样性值。
为了保证学术严谨性,一篇学术论文的发表周期并不短,所以处于同一时间段内其直接引用文献之间一般不会存在引用关系(如在同月发表的文献B、C同时引用了文献A,文献B、C之间几乎不可能存在引用关系);同时,数据集中也会存在引用缺失的情况,即本身应当存在的引用关系可能因为版权、数据库、编码格式等各种问题而丢失。但其本应存在较强联系,如同属一个研究领域、分支方向、强相关性研究等,根据结构多样性思想将其归为一个连通分量是十分合理的,而引文网络中的边缺失会令结构多样性模型失效,相关分析准确性降低。
考虑到上述可能出现的问题,本文结合引文网络中的重要概念文献耦合和文献共被引对原始结构多样性模型进行改良,提出了三种新模型使之与引文网络契合度更高。
2.3 改进的引文网络结构多样性模型
引文网络中存在边缺失问题,需要为可能缺失的边或关联性较大的节点间添加边。
Chakraborty等人[35]为邻居节点Jaccard相似度达到阈值的节点补充边后,获得了一个更加优秀的结构多样性模型用于社会网络分析。以此为鉴,考虑文献间引用的缺失,可以借助引文网络中近距离节点信息,为原本没有边的两个节点添加边。多篇文献同时引用了另一篇文献为文献间耦合,多篇文献同时被另一篇文献引用为文献间共被引。文献间的耦合与共被引常被认为是文献间有着较大关联的象征。
文献耦合反映了文献间思想的共享程度以及重合度,是一种静态关系,耦合结构多样性(coupling structural diversity)模型利用耦合关系为相关文献间添加边。
定义7 文献v耦合结构子图。已知引文网络图D=〈V,〉,施引文献集Iv,v耦合结构子图D[CPv]n=〈V′,′〉,其中V′Iv,且u∈V′中的文献u均在文献v发表后n年内(包含n)发表,′={〈u,v〉|u,v∈V′∧(〈u,v〉∈∨w∈V(〈u,w〉,〈v,w〉∈))}。
如图3所示,文献S发表后3年內,被文献C1、C2、C3直接引用,提取C1和C2的参考文献R11~R32,考虑到R12同时被文献C1和C2引用,即存在耦合关系,为C1、C2间添加有向边,得到文献S耦合结构子图(图3中虚线标出部分)。
定义8 耦合结构多样性。已知引文网络图D=〈V,〉,v耦合结构子图D[CPv]n,则文献v的引文网络结构多样性sd-cp(v,n)为导出子图D[CPv]n的基图的连通分支数,即sd-cp(v,n)=p(G(D[CPv]n))。
图3为耦合结构多样性模型示意图,文献S耦合结构子图的基图的连通分支数为2,那么文献S的耦合结构多样性sd-cp(S,3)=2。耦合结构多样性算法伪代码见算法1。共被引同样可以反映出文献间的强关联性,与文献耦合不同,共被引情况随时间变化会改变[26]。共被引结构多样性(co-citation structural diversity)模型利用文献间共被引关系为相关文献间添加边。
算法1 耦合结构多样性算法
输入:引文网络D=〈V,〉;年份控制参数n。
输出:V中所有节点vi∈V的耦合结构多样性sd-cp(vi,n)。
1 for each vi∈V do
2 提取vi施引文献集Ivi
3 for each vj∈Iv do
4 if yvj>yvi+n//yp表示文献p发表年份
5 then 从Iv中删除vj及与vj关联的边
6 else提取vj参考文献集Rvj
7 提取D由Iv诱导出的子图DIv
8 for each vm∈Iv do
9 for each vn∈Iv do
10 if Rvm∩Rvn≠ and vm与vn无边
11 then 向DIv中添加有向边mn:vm→vn
12 sd-cp(vi,n)←p(G(DIv))
13 return
定义9 文献v共被引结构子图。已知引文网络图D=〈V,〉,施引文献集Iv,v共被引结构子图D[CCv]n=〈V′,′〉,其中V′Iv,且u∈V′中的文献u均在文献v发表后n年内(包含n)发表,′={〈u,v〉|u,v∈V′∧(〈u,v〉∈∨w∈V(〈w,u〉,〈w,v〉∈)),文献w均在文献v发表后n年内(包含n)发表}。
如图4所示,文献C1和C2无引用关系,但两者被其他文献共同引用,得到共被引关系,如图中蓝色边(见电子版)。根据定义9,文献S的共被引结构子图为图4中虚线标出部分。需要说明的是,共被引是通过文献发表后后续文献的引用关系确定,与文献耦合的静态模型(一篇文献在发表后参考文献一般不会发生变化)并不相同,会动态变化,所以在提取引用文献时,C11~C32均发表于文献S发表后的n年(包含n)内(该例中n=3)。
定义10 共被引结构多样性。已知引文网络图D=〈V,〉,v共被引结构子图D[CCv]n,则文献v的引文网络结构多样性sd-cc(v,n)为导出子图D[CCv]n的基图的连通分支数,即sd-cp(v,n)=p(G(D[CCv]n))。详细算法伪代码见算法2。
在图4中文献S的共被引结构子图的基图的连通分支数为2,因此S共被引结构多样性sd-cc(S,3)=2。
组合结构多样性(combined structural diversity)模型则是同时考虑使用文献间的耦合关系和共被引关系为文献间添加边。
定义11 组合结构多样性。已知引文网络图D=〈V,〉,v组合结构子图D[COv]n=D[CPv]n∪D[CCv]n,则文献v的引文网络结构多样性sd-co(v,n)为组合结构子图D[COv]n的基图的连通分支数,即sd-co(v,n)=p(G(D[COv]n)),组合结构多样性算法伪代码见算法3。
算法2 共被引结构多样性算法
输入:引文网络D=〈V,〉;年份控制参数n。
输出:V中所有节点vi∈V的耦合结构多样性sd-cc(vi,n)。
1 for each vi∈V do
2 提取vi施引文献集Ivi
3 for each vj∈Iv do
4 if yvj>yvi+n//yp表示文献p发表年份
5 then 从Iv中删除vj及与vj关联的边
6 else 提取vj施引文献集Ivj
7 for each vk∈Ivj
8 if yvk>yvi+n
9 then 从Ivj中删除vk及与vk关联的边
10 提取D由Iv诱导出的子图DIv
11 for each vm∈Iv do
12 for each vn∈Iv do
13 if Ivm∩Ivn≠ and vm与vn无边
14 then 向DIv中添加有向边mn:vm→vn
15 sd-cc(vi,n)←p(G(DIv))
16 return
如图5所示,红色有向边代表来源于文献耦合,蓝色有向边代表来源于文献共被引(见电子版),共同组成了文献S的组合结构子图(图中虚线标出部分)。该组合结构子图的基图的连通分支数为1,故文献S的组合结构多样性sd-co(S,3)=1。
算法3 组合结构多样性算法
输入:引文网络D=〈V,〉;年份控制参数n。
输出:V中所有节点vi∈V的耦合结构多样性sd-cp(vi,n)。
1 for each vi∈V do
2 提取vi施引文献集Ivi
3 for each vj∈Iv do
4 if yvj>yvi+n//yp表示文献p发表年份
5 then从Iv中删除vj及与vj关联的边
6 else提取vj参考文献集合Rvj与vj施引文献集Ivj
7 for each vk∈Ivj
8 if yvk>yvi+n
9 then 从Ivj中删除vk及与vk关联的边
10 提取D由Iv诱导出的子图DIv
11 for each vm∈Iv do
12 for each vn∈Iv do
13 if Rvm∩Rvn≠ and vm與vn无边
14 then向DIv中添加有向边mn:vm→vn
15 if Ivm∩Ivn≠ and vm与vn无边
16 then 向DIv中添加有向边mn:vm→vn
17 sd-co(vi,n)←p(G(DIv))
18 return
3 实验
本文各结构多样性相关实验均在不同年份参数n(n=1,2,3,4,5)下进行过对照实验。随着n的增加,文献的结构多样性指标更加准确,实验结果更好,当n=3时已经可以获得较好的实验结果,且结果相似,为避免赘述,本文统一展示n=3情况下的实验结果。
3.1 实验数据集
本文使用数据集为国际公认权威科技情报大数据挖掘平台Aminer提供的计算机领域引文网络数据集DBLP-Citation-network V13[27],该数据集发布于2021年5月14日,引文信息主要来源于Database Systems and Logic Programming(DBLP)数据库。该数据集具有引文数据新、数据体积大、字段特征全等优点,可通过网站https://www.aminer.cn/citation直接获取。由于数据集中存在部分缺失发表年份、摘要、作者等重要特征的记录,所以需要对数据集进行清洗,表1为原始数据集及清洗后数据集基本情况,图6为清洗后数据集文献引用量分布情况,呈现标准的幂率分布。
3.2 文献评价指标(结构多样性)可行性实验
由于2000年以前文献样本数量较少且实验数据已不具备时效性,所以实验选取2000—2018年发表的所有文献,计算每篇文献在引文网络中的原始结构多样性sd(v,3),并按照sd(v,3)的数值进行分组,参照文献[3,28]的实验方法,选取每组文献引用量(于2021年统计)的中位数作为该组文献的质量评价指标,以结构多样性为横坐标,其对应文献质量(引用量中位数)为纵坐标,研究原始结构多样性与文献质量的关系,实验结果具有相似结论,故图7以六年为跨度展示2000—2018年的实验结果。
如图7所示,在不同年份的整体趋势实验中,皮尔森相关系数(Pearson correlation coefficient) r均大于0.9,文献质量随sd(v,3)取值增加而增加,这表明文献质量与结构多样性有着较强的线性相关性。此时,再考察第2章中案例文献A和B,文献A的sd(v,3)=4,而文献B的sd(v,3)=1,符合上述规律,结构多样性作为文献评价指标具有可行性。
为了更细致地观察结构多样性与引用量的关系,并且增加实验可信度,在每组实验中额外选取了中位数附近的20篇文献研究其与对应文献引用量的关系,实验结果见图8。
在图8中,每组实验所得皮尔森相关系数均大于0.88(且 值均小于0.001),再次证明了文献质量与结构多样性显著相关。其中2000年相关性实验中的皮尔森相关系数比其他年份小,可能是文献样本量不足导致,2000年文献样本仅有76 801篇,而其他年份的文献样本均超过了15万篇。
从结构多样性模型本身联系其社会学含义进行解释,若一篇文献具有高结构多样性,表明其发表后被更多分支学科或其他领域的学者认可参考,显然具有更好的跨学科特性,创新性往往也更强,即结构多样性在一定程度上反映了文献质量,可以成为文献质量的一个评价指标。
3.3 文献评价指标(改进结构多样性)可行性实验
从3.2节实验可知原始结构多样性与文献质量(引用量中位数)有着较强的线性相关性,但由于观察实验的弊端,并不能得出结构多样性与文献质量之间的直接因果关系——结构多样性高导致文献引用量高。因此,本节进行更细粒度的实验,探索结构多样性影响文献引用量的机制。
根据年份(2000—2018年)对文献分组,并在实验前统计了其发表后n年内引用量(n与计算结构多样性年份相同,即n=3),尽可能使每组的样本数量接近且每组中文献引用量接近,具体分组规则见表2。由于h组样本数量过少,且组内数据跨度较大,不具有代表性和普适性,所以不在实验结果中体现。分组后,每组均具有于发表后第3年时引用量相近的文献,但每篇文献的结构多样性并不完全相同,遍历计算出每篇文献的结构多样性sd(v,3)、耦合结构多样性sd-cp(v,3)、共被引结构多样性sd-cc(v,3)、组合结构多样性sd-co(v,3)。以各结构多样性的值为横坐标,该组文献于2021年的文献质量(引用量中位数)为纵坐标,探究结构多样性影响未来文献质量的机制。
本文首先通过实验研究了结构多样性与文献引用量的关系,于分组实验中发现在文献发表后第3年处于同一组的文献中,结构多样性与文献引用量没有相关性,这与3.2节结果不同,说明该模型在细粒度实验中准确性不够高。进一步选择改进模型进行实验时,获得了与3.2节相似的结果,更加严谨地证明了高结构多样性文献在将来具有更高质量的可能性更大,同时也证明了改进模型作为文献评价指标的可行性。实验结果见图9,由于实验结果具有相似性,为避免赘述仅展示2000年、2006年、2012年的实验结果。
首先,从图9中可以明显看出,即使在发表后第3年文献引用量近似(处于同一组),但随着结构多样性的增加,文献获得更多引用的可能性更高,这样的趋势在发表后短时间内就获得较多引用的组中(E~G组)更为明显。其次,组合结构多样性模型中会存在更多的边,这导致同一篇文献的组合结构多样性值只可能比耦合结构多样性和共被引结构多样性的值低,因此组合结构多样性模型中大部分代表性文献样本的引用量都要大于另外两个模型,而共被引模型中大部分代表性文献样本的引用量要小于另外两个模型,这说明该模型添加的边是最少的,这也为不同数据集提供了灵活的模型选择,当数据集中数据较为完整时可以选择原始结构多样性模型或共被引结构多样性模型,当数据集中引用信息缺失较多时可以选择耦合结构多样性模型或组合结构多样性模型。
3.4 结构多样性与文献引用量变化趋势关系实验
Cao等人[29]发现,若一组论文出版后四年内具有相近的引用量变化趋势,该组论文出版四年后的引用量变化趋势也会相近,因此一篇文献发表后四年内的引用量变化趋势可用于提升文献引用量预测模型的性能。文献[30~33]中也有類似结论,均利用期刊发表后的引用信息有效地提升了预测模型的精度。但上述研究均停留于现象表面,并没有深入研究其中机制。本节通过实验研究不同结构多样性文献的引用趋势,并利用结构多样性思想尝试解释。实验从不同期刊随机选取发表于不同年份(发表年份均小于2010年),且组合结构多样性sd-co(v,3)为1、4、7、10的文献各20篇,绘制其十年内被引用的趋势变化图。由于各样本实际被引量差距较大,而本实验仅针对引用趋势进行研究,所以使用比值C=yn/yi(yn为文献发表后第n年的被引量,i为实验中年份跨度,本实验中i=10)来表示被引量。实验结果见图10,每幅子图中灰色线为各文献样本发表后被引用量 随时间T(年)的变化趋势,加粗线为各组样本均值变化趋势,阴影部分为标准差误差带。
从整体来看,若一篇文献发表后第3年具有相同的组合结构多样性,其后续被引量C随时间T(年)的变化趋势相近。从部分来看,低组合结构多样性(sd-co(v,3)=1)文献往往在发表后第2年时C就超过了0.8,这说明参考了低组合结构多样性文献思想的工作主要集中在该文献发表后的前期时间段(3年内)。其次,随着组合结构多样性的增加,文献在前期时间段获得引用量占比逐渐减少,但依旧会在2~3年内出现引用平缓期。同时,相比低组合结构多样性,引文网络具有高组合结构多样性的文献在中后期会获得更多的引用,即高组合结构多样性文献的引用文献会随时间分布得更加均匀。
对于此,尝试使用社会网络中结构多样性理论的思想来进行解释。在引文网络子图中,每一个不连通的分量可以认为其拥有独立于其他分量的主题、研究分支或其本身就属于不同的学科范畴,若一篇文献引文网络的结构多样性较低,往往意味着该文献主题较为单一,跨学科性较差,则发表后受其影响的学科分支、领域也越少。其次,文献引用注重时效性,相关领域内研究者往往更加青睐热点方向,引用文献时也倾向于引用最新的科研成果[13],因此一篇低结构多样性文献的被引量主要来源于文献发表后的前期时间段。反观高结构多样性文献,其在短时间内影响了更多的领域、学科,拥有更强的创新性与颠覆性,知识扩散范围更广、速率更快,其在后续(发表三年后)获得更多引用的可能性也更高。以上分析也从理论层面合理地解释了文献[29]中的引用趋势近似现象在很大程度上是受到文献结构多样性的影响。同时,结构多样性与文献引用量趋势关联的特性也彰显了其作为文献评价指标的独特性与重要性。
3.5 结构多样性在文献引用量预测模型中的表现
为进一步探究各结构多样性在引文网络分析中的有效性,实验使用发表于2000—2008年的1 183 904篇文献样本作为训练集,发表于2009年和2010年的436 961篇文献样本作为测试集,选择五种经典引用量预测模型,在其中添加各结构多样性相关参数后进行回归预测实验,并与未添加相关参数的基线模型对比,其中LR[34]、kNN[34]、SVR[34]、CART[34]为直接选用文献特征进行回归预测的模型,遂直接在原模型上添加文献样本结构多样性特征,TPM[35]为分层学习预测模型,实验在回归预测阶段添加文献样本结构多样性特征。
实验选择相关研究常用评价指标,即决定系数R2和均方误差MSE(mean square error)。决定系数R2常用于评价模型预测结果与真实结果差距性能,R2∈[0,1],越接近1表示模型总体预测准确,R2可以表示数据的变化程度;MSE越小,则预测模型精确度更高。
R2=1-∑ni=1(Cp-CpEuclid ExtravBp)2∑ni=1(Cp-C)2(1)
MSE=1n∑ni=1(Cp-CpEuclid ExtravBp)2(2)
其中:Cp表示通过预测模型得到的文献p的引用量;C表示所有样本文献引用量的平均值;CpEuclid ExtravBp表示文献p的真实引用量。
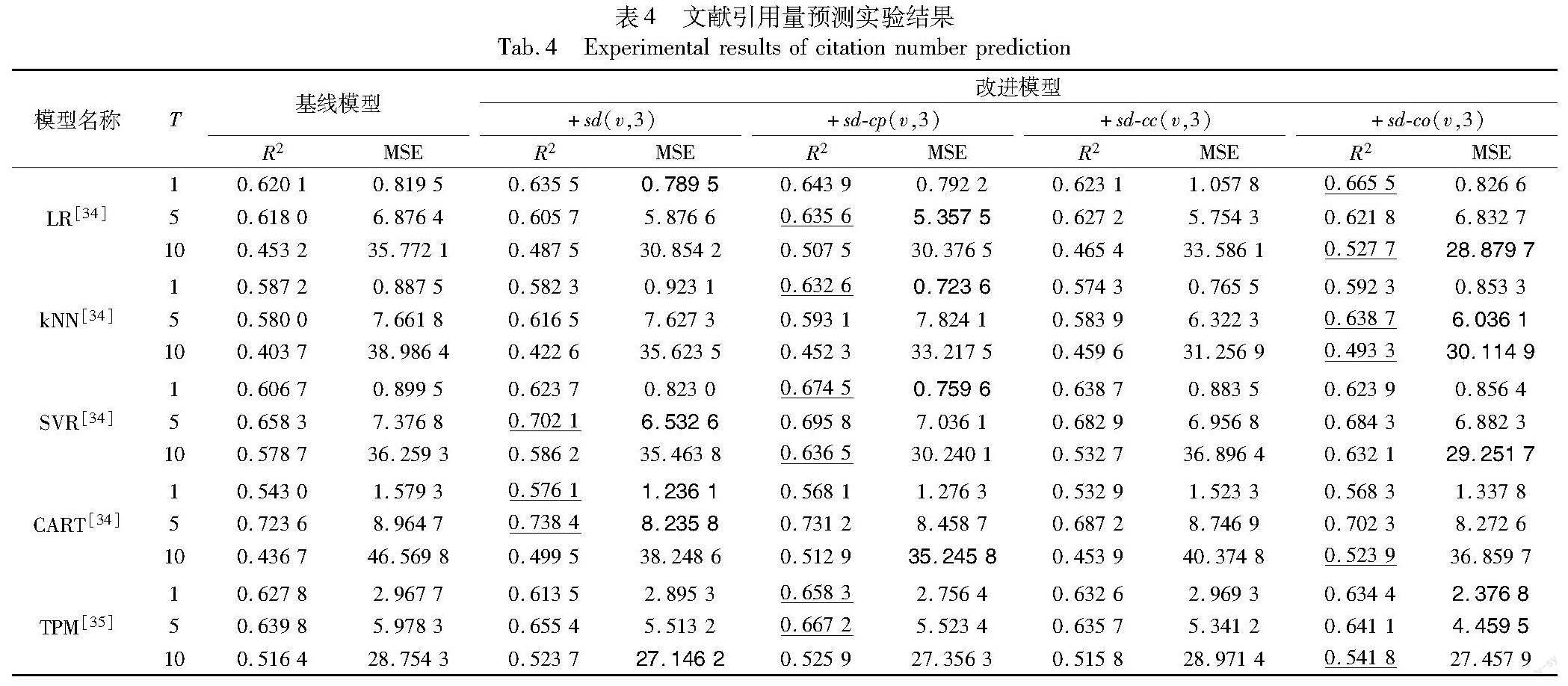
实验中机器学习模型选用sklearn-0.20.4版本,具体参数选择见表3,特征选择见参考文献,其余未列出参数均选用默认值,实验结果见表4,每组实验中预测性能最好的结果已分别用下划线(R2)和粗体(MSE)标记。
从表中可以看出,在85.8%的实验中,添加结构多样性特征均可以有效提升基线模型的预测性能。组合结构多样性后在各模型的长期引用量预测(10年)中具有较好的效果,R2最高提升22.19%,平均提升14.55%,MSE最高提升22.76%,平均提升17.34%;原始结构多样性和耦合结构多样性则在模型短中期引用量的预测(1年、5年)中效果较好;共被引结构多样性在大部分实验中表现不如其他两种改进模型,但比原始结构多样性模型略好。
4 结束语
本文首先提出了适用于引文网络的结构多样性模型;其次根据其原始模型在引文网络中的缺陷提出三种改进模型,并研究了各结构多样性与文献引用量的强关联性,并解释其机制;再次,通过实验证明了结构多样性可以提升文献引用量模型的性能;最后,提出以下未来工作供参考。
a)从结构多样性模型本身来看,本文所提出的结构多样性模型结合了引文网络研究中的重要概念耦合与共被引,但没有详细研究耦合强度与共被引強度对相关模型的影响,这是一个后续值得深入研究的点。其次本文结构多样性模型研究文献距离最大为2(两篇文献最多可经过两次引用或被引到达),适当扩大距离可能使相关模型效果更优秀。此外,可以尝试将结构多样性模型与不同的文献评价指标组合使用,从而挖掘出更符合预期的高价值文献。
b)从数据分析实验来看,本文只对结构多样性小于等于10的文献样本进行实验。对于更高结构多样性,由于样本数量过少,不足以得出普遍性规律,没有在实验结果中体现,后续可以选取合适数据集,针对高结构多样性文献进行专题研究。此外,实验仅选取了10年跨度研究文献被引趋势,而一些经典且具有奠基效应文献的被引趋势往往与普通文献不同,未来可以加大实验中时间跨度,探究此类特殊文献的被引用趋势,从而将结构多样性指标应用到特殊文献(如“睡美人”文献)的挖掘中。
参考文献:
[1]吕晓赞.文献计量学视角下跨学科研究的知识生产模式研究[D].杭州:浙江大学,2021.(Lyu Xiaozan.Research on the know-ledge production mode of interdisciplinary research from the perspective of bibliometrics[D].Hangzhou:Zhejiang University,2021.)
[2]Richard V N.Global scientific output doubles every nine years[J].Humanities and Social Sciences Communications,2021,8:article No.224.
[3]Wu Lingfei,Wang Dashun,Evans J A.Large teams develop and small teams disrupt science and technology[J].Nature,2019,556:378-382.
[4]肖學斌,柴艳菊.论文的相关参数与被引频次的关系研究[J].现代图书情报技术,2016,32(6):46-53.(Xiao Xuebin,Chai Yanju.Properties of scholarly papersand number of citations[J].New Technology of Library and Information Service,2016,32(6):46-53.)
[5]Ugander J,Backstrom L,Marlow C,et al.Structural diversity in social contagion[J].Proceedings of the Nationalacademy of Sciences of the United States of America,2012,109(16):5962-5966.
[6]鲁英杰,张应龙.基于社会网络的结构多样性研究综述[J].数据分析与知识发现,2022,6(8):1-11.(Lu Yingjie,Zhang Yinglong.Review of structural diversity studies on social networks[J].Data Analysis and Knowledge Discovery,2022,6(8):1-11.)
[7]Fang Zhanpeng,Zhou Xinyu,Tang Jie,et al.Modeling paying behavior in game social networks[C]//Proc of the 23rd ACM International Conference on Conference on Information and Knowledge Management.New York:ACM Press,2014:411-420.
[8]Zhang Shiqi,Sun Jiachen,Lin Wenqing,et al.Measuring friendship closeness:a perspective of social identity theory[C]//Proc of the 31st ACM International Conference on Information & Knowledge Management.New York:ACM Press,2022:3664-3673.
[9]Qiu Jiezhong,Li Yixuan,Tang Jie,et al.The lifecycle and cascade of Wechat social messaging groups[C]//Proc of the 25th International Confe-rence on World Wide Web.New York:ACM Press,2016:311-320.
[10]Su J,Kamath K,Sharma A,et al.An experimental study of structural diversity in social networks[C]//Proc of the International AAAI Conference on Web and Social Media.Palo Alto,CA:AAAI Press,2020:661-670.
[11]Yu Dejian,Pan Tianxing.Tracing knowledge diffusion of topsis:a historical perspective from citation network[J].Expert Systems with Applications,2021,168(2):114238.
[12]Tahamtan I,Afshar A S,Ahamdzadeh K.Factors affecting number of citations:a comprehensive review of the literature[J].Scientome-trics,2016,107:1195-1225.
[13]Sánchez-Arrieta N,González R A,Caabate A,et al.Social capital on social networking sites:a social network perspective[J].Sustainability,2021,13(9):5147.
[14]Aral S,Nicolaides C.Exercise contagion in a global social network[J].Nature Communications,2017,8(1):14753.
[15]Spiliotopoulos T,Oakley I.Understanding motivationsfor facebook use:usage metrics,network structure,and privacy[C]//Proc of SIGCHI Conference on Human Factors in Computing Systems.New York:ACM Press,2013:3287-3296.
[16]Dong Yuxiao,Johnson R A,Xu Jian,et al.Structural diversity and homophily:a study across more than one hundred big networks[C]//Proc of the 23rd ACM SIGKDD International Conference on Know-ledge Discovery and Data Mining.New York:ACM Press,2017:807-816.
[17]Huang Xinyi,Tiwari M,Shah S.Structural diversity in social recommender systems[C]//Proc of the 5th ACM RECSYS Workshop on Recommender Systems and the Social Web.New York:ACM Press,2013.
[18]Sanz-cruzado J,Castells P.Enhancing structural diversity in social networks by recommending weak ties[C]//Proc of the 12th ACM Confe-rence on Recommender Systems.New York:ACM Press,2018:233-241.
[19]Gao Shuai,Ma Jun,Chen Zhumin.Effective and effortless features for popularity prediction in microblogging network[C]//Proc of the 23rd International Conference on World Wide Web.New York:ACM Press,2014:269-270.
[20]Xu Wenzheng,Liang Weifa,Lin Xiaola,et al.Finding top-k influential users in social networks under the structural diversity model[J].Information Sciences,2016,355-356:110-126.
[21]Bao Qing,Cheung W K,Zhang Yu,et al.A component-based diffusion model with structural diversity for social networks[J].IEEE Trans on Cybernetics,2017,47(4):1078-1089.
[22]Backstrom L,Kleinberg J,Lee L,et al.Characterizing and curating conversation threads:expansion,focus,volume,re-entry[C]//Proc of the 6th ACM International Conference on Web Search and Data Mi-ning.New York:ACM Press,2013:13-22.
[23]Qiu Jiezhong,Tang Jian,Ma Hao,et al.DeepInf:social influence prediction with deep learning[C]//Proc of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining.New York:ACM Press,2018:2110-2119.
[24]Zhang Jing,Liu Biao,Tang Jie,et al.Social influence locality for modeling retweeting behaviors[C]//Proc of the 23rd International joint Conference on Artificial Intelligence.Palo Alto,CA:AAAI Press,2013:2761-2767.
[25]Zhang Yafei,Wang Lin,Zhu J J H,et al.The strength of structural diversity in online social networks[J].Research,2021,2021:article ID 9831621.
[26]Tan L P.Mapping the social entrepreneurship research:bibliographic coupling,co-citation and co-word analyses[J].Cogent Business & Management,2021,8(1):article No.1896885.
[27]Tang Jie,Zhang Jing,Yao Limin,et al.ArnetMiner:extraction and mining of academic social networks[C]//Proc of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York:ACM Press,2008:990-998.
[28]Akella A P,Alhoori H,Kondamudi P R,et al.Early indicators of scientific impact:predicting citations with altmetrics[J].Journal of Informetrics,2021,15(2):article No.101128.
[29]Cao Xuanyu,Chen Yan,Liu K J R.A data analytic approach to quantifying scientific impact[J].Journal of Informetrics,2016,10(2):471-484.
[30]Ma Anqi,Liu Yu,Xu Xiujuan,et al.A deep-learning based citation count prediction model with paper metadata semantic features[J].Scientometrics,2021,126:6803-6823.
[31]Abramo G,Dangelo C A,Felici G.Predicting publication long-term impact through a combinationof early citations and journal impact factor[J].Journal of Informetrics,2019,13(1):32-49.
[32]Bornmann L,Leydesdorff L,Wang Jian.How to improve the prediction based on citation impact percentiles for years shortly after the publication date?[J].Journal of Informetrics,2014,8(1):175-180.
[33]Kulkarni A,Busse J,Shams I.Characteristics associated with citation rate of the medical literature[J].PLoS ONE,2007,2(5):e403.
[34]Yan Rui,Tang Jie,Liu Xiaobing,et al.Citation count prediction:learning to estimate future citations for literature[C]//Proc of the 20th ACM International Conference on Information and Knowledge Management.New York:ACM Press,2011:1247-1252.
[35]Chakraborty T,Kumar S,Goyal P,et al.Towards a stratified learning approach to predict future citation counts[C]//Proc of the 14th ACM/IEEE-CS Joint Conference on Digital Libraries.New York:ACM Press,2014:351-360.
猜你喜欢
中国科技纵横(2016年20期)2016-12-28
经济研究导刊(2016年30期)2016-12-24
电脑知识与技术(2016年27期)2016-12-15
时代金融(2016年29期)2016-12-05
科学与管理(2016年5期)2016-12-01
中国市场(2016年40期)2016-11-28
商(2016年33期)2016-11-24
中小企业管理与科技·上旬刊(2016年10期)2016-11-15
中国市场(2016年38期)2016-11-15
中国市场(2016年33期)2016-10-18
