
基于StarGAN 的多属性风格图像生成的轻量化网络
2024-03-04 09:06:32孙志伟曾令贤马永军
天津科技大学学报 2024年1期
孙志伟,曾令贤,马永军
(天津科技大学人工智能学院,天津 300457)
深度生成视觉是计算机视觉领域的一个重要研究方向,它将人工生成的过程转化为智能生成的过程,以大幅减少重复性的人工劳动,甚至可以进行创造性的智能创作[1]。生成对抗网络(generative adversarial network,GAN)由Goodfellow 等[1]在2014 年提出,是实现计算机深度生成视觉的主要技术之一,随后发展并衍生了许多变体,如生成器和判别器上都增加约束条件的条件生成对抗网络CGAN[3],生成器和判别器均采用深度卷积的DCGAN 模型[4]。为了解决生成对抗网络长期以来的训练不稳定和模式坍塌的问题,Arjovsky 等[5]提出了 WGAN 模型,使用 W(Wasserstein)距离代替 JS(Jensen-Shannon)散度计算生成样本分布与真实样本分布间的距离,但是WGAN 模型依然存在训练困难,收敛速度慢的问题。Gulrajani 等[6]提出的WGAN-GP 直接将判别器的梯度作为正则项加入判别器的损失函数中。Zhang等[7]将自注意力模块与GAN 的思想相结合提出的SAGAN 模型,为图像生成任务提供了注意力驱动的长距离依赖的模型。
以上GAN 的衍生模型都是通过网络结构、损失函数等的改变,提高GAN 的性能和稳定性。这些GAN 的衍生模型被用在图像任务中,如用于解决图像修复的超分辨率重建SRGAN[8]、IIZUKA[9]等方法。
随着图像到图像翻译任务的发展,对GAN 所生成图像的要求也越来越多,如两个图像领域的转换问题(cross-domain)、属性编辑问题等,出现了能进行多领域图像转换的 CycleGAN[10]、DualGAN[11]、DualStyleGAN 等[12]方法。CycleGAN 主要是解决pix2pix[13]中进行风格转换时需要成对数据的问题,使用两个生成器和两个判别器分别处理源域到目标域的转换,并且提出了循环一致性损失进行控制,但仍然存在生成器数量和域数量一对一的问题。DualGAN 主要受自然语言翻译任务中对偶学习的启发,使图像翻译器能够在两个无标签的图像域中学习,但是也存在生成器过多的问题。在单属性编辑任务中已有的模型不能很好地完成多属性的转换,往往在k 个属性之间相互转换时,需要k×(k-1)个生成器,并且由于是一对一的属性变换并不能有效学习到全局特征以及充分利用全部训练数据[14],多属性风格变换有助于拓展属性变换任务需求。Choi 等[14]提出的StarGAN 解决了1 个生成器只能处理单一属性的问题,生成器的形状像星星一样,可以根据不同的输入属性要求产生不同的输出,在人脸数据集上取得了很好的效果。
StarGAN v2[16]是基于StarGAN[14]跨域的多样性图像生成网络,其多样性在于通过最大化两个风格编码所生成图像的距离控制生成图像的多样性,但是不同于多属性生成,模型能够生成某一个域多样性的图像,而不是具体的多属性转换。
多属性图像生成网络在很多场景下具有重要的应用价值,然而该模型结构复杂、计算量大。轻量化的目的是在保持模型精度基础上减少模型参数量和复杂度,轻量化网络既包含了对网络结构的探索,又有知识蒸馏、剪枝等模型压缩技术的应用,推动了深度学习在移动端和嵌入式端的应用落地,在智能家居、安防、自动驾驶等领域都有重要贡献。传统的模型压缩方法很难对生成模型进行压缩,主要原因包括:生成器需要大量的参数建立潜在向量到生成图像的映射关系,这种极度复杂的映射结构相较于图像识别任务更难确定冗余的权重;目标检测和图像分割等其他视觉任务都是有标签的训练数据,而GAN 中的很多任务并没有任何标签用来评判生成的图像,如超分辨率重建和风格迁移。
为了解决上述问题,Aguinaldo 等[17]提出一种压缩和加速GAN 训练的网络框架,利用知识蒸馏技术以均方误差(MSE)损失最小化学生网络和教师网络的距离,但是该方法仅能应用于噪声到图像的网络架构,而如今GAN 的应用主要是图像到图像[17]。为了解决这些问题,Chen 等[18]以CycleGAN[10]为基准提出了一个新的基于知识蒸馏的小型GAN 的框架,在像素层面上最小化学生网络和教师网络生成图像的距离,教师网络生成的图像对学生判别器而言是真实样本,因此设计了学生判别器。但是,该方法只能进行单一图像域的转换,而不能进行多属性的图像生成任务。
由于实际场景中实际采集样本的各属性分布不均,多属性生成是目前的研究重点之一,然而现有的模型较为复杂,计算量大,而且图像生成的效果需进一步提高,因此本文提出了一种基于StarGAN 的可进行多属性风格图像生成的轻量化网络。
1 相关工作
1.1 StarGAN
本文模型是以StarGAN 为基准模型设计的多属性风格图像生成的轻量化网络。StarGAN 作为跨多领域的图像到图像翻译任务的生成对抗网络,其结构为1 个可以生成多属性的条件生成器和1 个判别器。生成器包括下采样模块、特征提取模块和上采样模块,生成器接收原图像以及目标属性条件作为输入,生成同样尺寸的目标属性图像。判别器接受生成器生成的图像或者真实图像作为输入,但是判别器有两个输出,一个是二分类的输出,判断图像是来自真实样本还是生成器生成样本;另一个是类别输出,判别图像的属性类别。
1.2 知识蒸馏
Hinton 等[19]提出知识蒸馏用于模型的轻量化过程,主要是设计学生网络,让小型的学生网络学习大型教师网络的低层特征和高层语义信息。知识蒸馏及其变种主要研究教师网络向学生网络传递知识的连接方式,最初的蒸馏对象是logit 层,让学生网络和教师网络的logit KL 散度尽可能小。FitNets[20]出现开始蒸馏中间层,一般使用MSE 损失函数,使学生网络和教师网络特征图尽可能接近,如图1 所示。Zagoruyko 等[21]提出的Attention Transfer 进一步发展了FitNets,提出使用注意力图引导知识的传递。Tian等[22]在FitNet 基础上引入对比学习进行知识迁移。
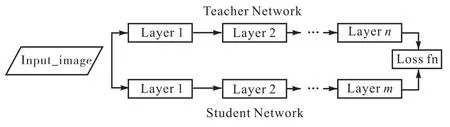
图1 蒸馏网络示意图Fig. 1 Diagram of distillation network
这些模型多数用于CNN 等神经网络,很少有对生成网络GAN 的蒸馏,主要在于GAN 学习的是很复杂的从噪声向量到生成图像的映射关系,而且GAN 多数是没有标签的数据,导致网络学习到的知识很难衡量,难以确定冗余权重。pix2pix[13]在论文中提供了成对的数据集,Chen 等[18]基于这个成对有标签数据集对pix2pix 蒸馏,用判别器衡量标签的图像、学生生成器以及教师生成器生成的图像三者之间的距离训练学生生成器,并且在CycleGAN[10]上有较好的效果,主要是其对判别器也同时进行了蒸馏,让学生判别器对教师生成器的输出判定为真,使教师网络和学生网络的判别器接近教师生成器的结果。
1.3 深度可分离卷积
深度可分离卷积是一种广泛应用于卷积神经网络模型结构中的模块,可以取代传统的卷积操作,用于提取图像特征。传统的卷积神经网络,一个卷积核对输入特征图的所有通道进行卷积,卷积核的通道数为输入通道数,卷积核的个数为输出通道数,而深度可分离卷积将卷积过程进行分解,卷积核的个数分别由输入通道数和输出通道数决定。
深度可分离卷积示意图如图2 所示,核心思想是将卷积分成了逐通道卷积(depthwise convolution)和逐点卷积(pointwise convolution),前者对输入特征图的每一个通道进行卷积,卷积核个数等于输入通道数;后者主要指1×1 的卷积[23],在不改变特征图尺寸的情况下加深特征图的通道数,能够进行跨通道的特征融合,卷积核个数等于输出通道数。
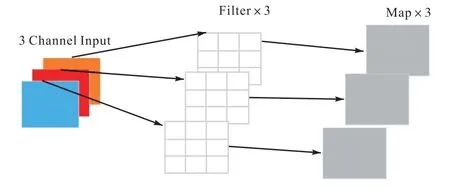
图2 深度可分离卷积示意图Fig. 2 Diagram of depth separable convolution
1.4 内容损失函数
在图像到图像转换的早期任务中,如将一张图形的风格转换到另一张内容图像上的风格迁移。内容损失和风格损失比较示意图如图3 所示。为了确保迁移图像的风格和风格损失函数控制,而使生成的图像和原内容图像的结构等信息不变,则用内容损失函数控制。在Yang 等[24]提出的L2M-GAN 模型中,内容损失函数在潜在空间中对人脸的语义信息获取有提升作用。
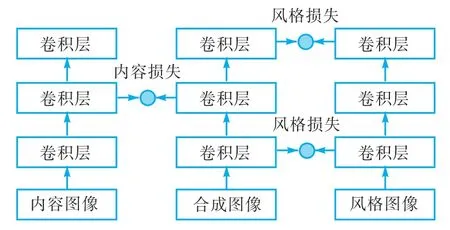
图3 内容损失和风格损失比较示意图Fig. 3 Diagram of content loss and style loss
2 本文方法
本文是对StarGAN 进行轻量化,提出了能够生成多风格属性图像的学生网络(student network based on StarGAN,stuStarGAN),在保证生成图像质量的前提下,减少网络的参数量,降低了模型的复杂度。
由于跨域的生成模型,StarGAN v2 等[16]只能生成属于该图像域的整体变换,主要建立两个数据集之间的映射关系,而不能生成确定属性和多属性风格图像,并且其中的多样性损失与蒸馏损失发生冲突,故本文以StarGAN 为教师网络和基准模型。
模型包括以下过程:首先使用知识蒸馏技术降低参数量,提出进一步采用学生判别器蒸馏损失提升性能;然后为了保证生成图像质量,采用skip-connection提供跨模块的连接;使用内容损失,确保不改变原始图像的内容信息;最后用深度可分离卷积取代普通卷积,进一步降低参数量并提高图像生成质量。
2.1 蒸馏生成器
为了让学生生成器学习教师生成器的知识,直接最小化两个生成器生成的图像的欧氏距离,为
式中:GT表示教师生成器,GS表示学生生成器,其中表示L1 正则化。通过最小化式(5),学生生成器的结果可以从像素层面上与教师生成器相似,L1 损失的目标只是最小化平均合理的结果。由于生成器的训练是伴随着判别器的,因此只蒸馏生成器对学生生成器的学习是不够的。教师判别器与生成器任务高度相关,要求教师判别器能够评估学生生成器是否像教师生成器那样生成了高质量的图像,即生成器的感知损失,为
式中:TD表示教师判别器,同时生成器的输入中省略了属性标签信息。
因此,生成器的蒸馏损失为
其中γ是平衡两个损失函数的超参数。
2.2 蒸馏判别器
Aguinaldo 等[17]对生成式网络压缩时,没有利用教师判别器对学生判别器蒸馏,而判别器对GAN 的训练也很重要,本文首先设计学生判别器,然后对学生判别器进行蒸馏。
学生判别器用来协同学生生成器训练,同时用教师判别器进行蒸馏,在蒸馏过程中,使用了与蒸馏生成器相同的方法(L1 损失),判别器的蒸馏损失为
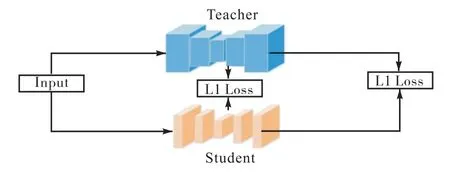
图4 整体蒸馏网络模块示意图Fig. 4 Diagram of whole distillation network module
此外,本文采用了教师网络和学生网络的对抗学习,教师网络经过训练,学生判别器在教师网络的监督之下训练,通过教师生成器生成的图像应该被学生判别器判别为真,损失函数定义为
2.3 Skip-connection
StarGAN 网络包括下采样模块、骨干网络以及上采样模块。在生成模型中,下采样主要用于编码功能,完成对潜在向量的编码,骨干网络主要提取图像特征,而上采样模块主要用于解码,还原为图像。在学生网络设计中,骨干网络选择与教师网络相同,都是ResNet 模块,在下采样和上采样之间使用skipconnection 提供跨模块的连接。跨模块连接示意图如图5 所示。在学生网络中将具有同样尺寸的上采样和下采样中的模块进行skip-connection,连接的过程不是简单的求和,而是通道的叠加,尽可能地保留低层的信息。
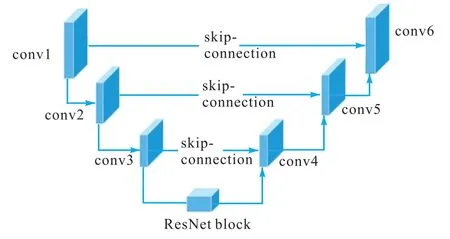
图5 跨模块连接示意图Fig. 5 Diagram of skip-connection
2.4 内容损失函数
在图像的风格变换后,为了使与风格无关的信息能够保留下来,而对生成图像和原图像作内容损失。本文中图像的属性改变,但是不希望与属性无关的其他信息,如结构、背景等发生变化,本文采用内容损失函数,在消融实验中验证其有效性。
内容损失函数通过1 个预训练好的网络作为特征提取器,由于模型高层的输出是高维的语义特征,包含更多具体的内容信息,因此本文采用ResNet-18模型的最后1 个卷积层的输出作为特征提取器。分别提取原图像和学生网络生成器生成图像的特征,在像素层面上作L1 损失,为
其中:c表示x要转换的目标属性类别,生成器以原图像和目标属性类别作为输入;F则是1 个预训练好的ResNet-18[25]模型。
2.5 深度可分离卷积
在学生网络设计中,替换掉骨干网络ResNet 模块中的普通卷积,改为深度可分离的卷积,进一步减少模型计算量,降低网络复杂度。Google 公司的MobileNet[26]证明了深度可分离卷积的性能,相较于普通卷积,它能极大降低计算量。
假定输入通道数为M,输出通道数为N,标准卷积的卷积核大小为DK·DK,特征图大小为DF·DF,则采用标准卷积计算量为
若采用深度可分离卷积,计算量为
联立二者,可得出其比值为
3 实验与分析
3.1 数据集
为了对所提学生网络的轻量化和性能进行验证,本文首先在CelebA 上做消融实验验证模型不同部分的有效性,然后进一步在CelebA 和Fer2013 数据集上进行算法对比实验。
CelebA 数据集是人脸识别和人脸表情研究领域具有权威性和完整性的名人人脸属性数据集,包含202 599 张人脸图像,图像大小为128×128,在原始数据集中每张图像都有40 个属性标注。以20%作为测试集,即40 000 张图像,其余为训练集。
Fer2013 数据集是一个灰度图像数据集,主要用于人脸表情变化的研究,该数据集共有7 种表情,分别对应数字标签0~6,这7 种表情图像共有35 886张,其中训练集包含28 708 张,其余为测试集7 178张。每张图像的大小为48×48,以csv 格式的文件存储像素值表示。
3.2 实验细节及评价指标
实验以PyTorch 框架在Nvidia GeForce RTX 3060 上实现,显存为12 GB。在训练过程中,将学生网络输入和教师网络输入尺寸固定一样,参数设置:批大小(batch size)为8,迭代次数200 000 次,生成器和判别器的学习率均为0.000 1,每1 000 次时更新1次,在每更新5 次判别器时更新1 次生成器。部分损失函数权重与教师网络保持一致,类别损失函数的权重为1,重构损失权重为10,梯度惩罚权重为10,生成器和判别器蒸馏损失均为1。
为了衡量网络的轻量化,本文以网络参数量和浮点数运算次数(GFLOPs)作为评价指标。此外,图像风格转换任务常用指标包括图像信噪比(PSNR,用符号RPSNR表示)、原图像和生成图像的结构相似性(SSIM,用符号SSSIM表示)、生成图像质量弗雷歇初始距离(FID,用符号DFID表示)。在SRGAN[8]中,由于PSNR 定义在像素级别的图像区别上,不能很好地表示图像的高维细节,本文只在消融实验中进行了PSNR 指标的对比,在算法对比实验中不再对比这个指标,只给出FID 和SSIM 的数据。
PSNR、SSIM 和FID 指标计算公式分别为
式中:Pmax为图像像素理论最大值;EMSE为两张图像的均方误差;u表示均值;σ表示方差;C表示常数;tr表示矩阵对角线上元素的综合,即在矩阵论中称为矩阵的迹;r 和g 表示真实的图像和生成的图像;∑是协方差矩阵。
3.3 实验结果
stuStarGAN 在CelebA 数据集上的生成效果如图6 所示,其中第1 列为原始图像,后面5 列依次对原图像属性进行更改,分别为黑发、金发、棕发、性别以及年龄。图中第2 行第3 列肤色有些变化,可能是在变换黑色头发时,对黑色肤色产生了影响。

图6 stuStarGAN在CelebA数据集上的生成效果Fig. 6 Diagram of result of stuStarGAN on CelebA
stuStarGAN 在Fer2013 数据集上的生成效果如图7 所示,图中第1 列为原始图像,第1 列至第7 列分别表示该数据集中存在的 7 种表情,分别是neutral、anger、fear、disgust、happy、sad、surprised。stuStarGAN 模型依然能很好地改变图像的表情属性,而不改变其他部分。

图7 stuStarGAN在Fer2013数据集上的生成效果Fig. 7 Diagram of result of stuStarGAN on Fer2013
模型在CelebA 数据集上进行多属性风格图像生成的结果如图8 所示。

图8 多属性的改变示意图Fig. 8 Diagram of change of multi attributes
图8 中第1 列表示原图像,第2 列改变头发颜色以及性别,第3 列改变了头发颜色以及年龄两个属性。结果表明生成器能对图像进行单属性和多属性转换。
3.4 消融实验
为了确保学生网络在轻量化之后仍然能有很好的图像质量,本文以教师网络为基准模型进行消融实验,在评价指标上评估各个模块或损失函数对性能的影响,结果见表1,其中U 表示使用U-net 的skipconnection,CL 表示使用内容损失,DP 表示将普通卷积更换为深度可分离卷积,DL 表示蒸馏生成器同时新增判别器蒸馏损失。
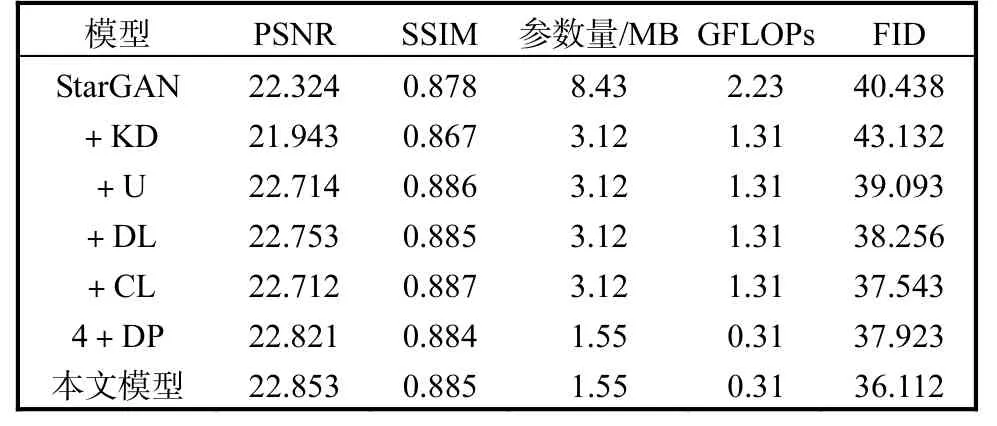
表1 在CelebA数据集上不同模块的对比Tab. 1 Comparison of different modules on CelebA
在表1 中,第1 行为教师网络,KD 表示知识蒸馏,第2 行+KD 表示只对教师网络进行知识蒸馏的结果,以后的每一行都是在前面的基础上进一步改进学生网络,如第3 行是在第2 行的基础上采用skipconnection。比较第1 行和第2 行,只对StarGAN 蒸馏,模型虽然显著降低参数量,但性能却有所下降。学生网络在使用skip-connection 之后效果有改善,表明模型的底层信息正确地传递给了上层神经元。
比较第3 行和第4 行,其中DL 表示对学生判别器采取的蒸馏损失,也就是直接比较教师和学生判别器的输出,包括真假概率输出和属性类别输出,可以看出使用DL 后确实提高了学生网络的效果。
第5 行在前面基础上采用内容损失,SSIM 进一步提高,说明生成图像很好地保留了原图像的结构信息,而PSNR 相较第4 行有明显下降。推测其原因主要在于引入内容损失后,为了保证图像主体结构信息不变,生成图像在其余部分引入噪声,使得图像信噪比下降,即PSNR 降低。第6 行4+DP 是指在第4 行的基础上引入DP,结果表明CL 确实影响了PSNR指标,然而引入DP 之后PSNR 有明显提升,但是SSIM 相较第4 行有所下降。比较第4 行和最后一行,虽然SSIM 有些许降低,但是深度可分离卷积大幅降低了网络的参数量和计算量,并提升了网络模型的FID。因此,根据PSNR 和SSIM 有些许变化以及FID 进一步提高的情况,本文选择了参数量和计算量更少的模型作为最后的stuStarGAN 模型。第5 列浮点数运算次数表明本文模型有更少的运算量,说明模型确实降低了网络的计算量。
表1 中参数量只包括生成器参数,因为判别器只在训练阶段起作用,最终也只需部署生成器。
3.5 对比实验
将不同算法在CelebA 以及Fer2013 两个数据集上进行对比实验,结果见表2 和表3。
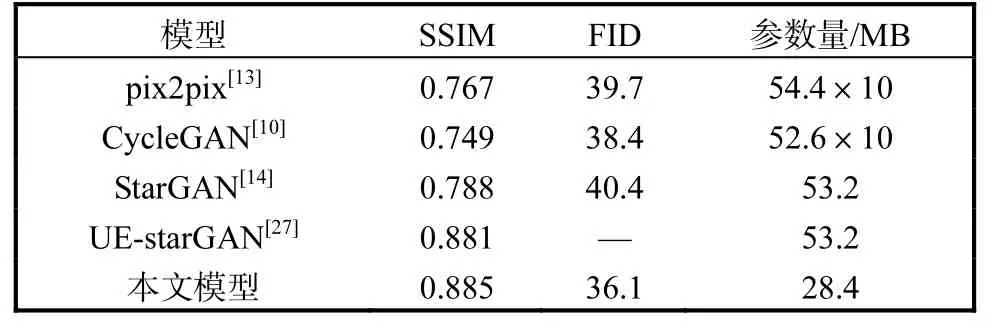
表2 不同算法在CelebA数据集上的性能比较Tab. 2 Comparison of different methods on CelebA
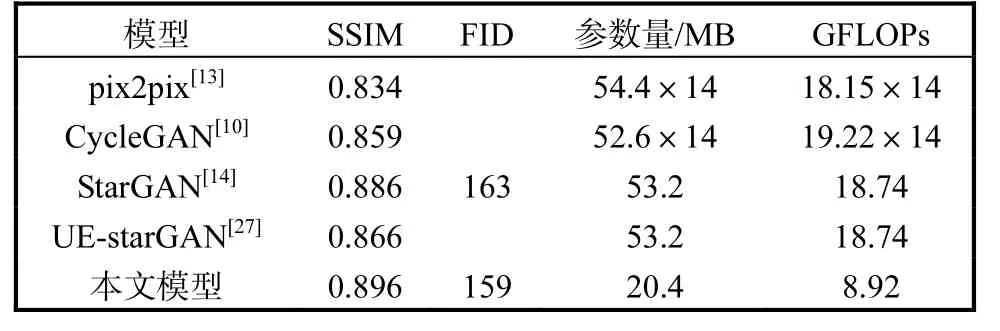
表3 不同算法在Fer2013数据集上的性能比较Tab. 3 Comparison of different methods on Fer2013
在CelebA 数据集上,本文模型与近年来的一些在图像翻译领域的先进模型进行比较,包括pix2pix、CycleGAN、StarGAN、UE-StarGAN 等。从表2 中可以看出,在CelebA 数据集上,从SSIM 和FID 两个指标上看,本文模型都有较好的性能。本文主要设计能生成多属性风格图像的轻量化学生网络,在保证生成质量的前提下降低模型复杂度,在考虑了判别器参数的情况下,参数量依然小于最少参数量的50%,其中CycleGAN 的参数量中的×10 是因为CycleGAN的1 个生成器只能转换原图像的1 种属性值,而StarGAN 可以1 个生成器转换多种属性值。
在表3 中,从第2 列可以看到本文模型可以保证很高的结构相似性,并且参数量和GFLOPs 有较大降低,相较其他模型在性能接近的情况下,计算量更少,结构复杂度更低,表明了本文模型的有效性。
4 结 语
本文基于StarGAN 设计了1 个能生成多属性风格变化的轻量化网络stuStarGAN。模型首先应用知识蒸馏技术降低教师网络参数量;然后为了确保生成图像质量,采用skip-connection 提供跨模块的连接,使用内容损失确保生成图像和原始图像的内容信息一致,在蒸馏生成器的同时新增判别器蒸馏损失以提高生成器性能;将普通卷积替换为深度可分离卷积,进一步降低参数量并提高图像生成质量;最后将模型在两个数据集上进行实验,给出了单属性和多属性的生成效果;并与其他模型进行比较,在保证生成图像质量的基础上极大地降低了参数量和计算量,可以应用于实际场景采集数据不足和数据分布不均需要扩充数据集以及某些实时应用场景中,如监控行人数据集样本分布不均、社交网络更改头像保护隐私、游戏角色变化头像等具体场景中。由于学生网络生成图像的多样性不足,在后续研究中会考虑并继续完善模型,做好效率和精度之间的平衡。
猜你喜欢
江西教育·职教版(2022年9期)2022-04-29 00:44:03
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
电子制作(2019年11期)2019-07-04 00:34:38
今日农业(2019年15期)2019-01-03 12:11:33
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
数学物理学报(2017年5期)2017-11-23 07:51:31
广西民族大学学报(自然科学版)(2015年3期)2015-12-07 00:56:05
