
基于双维压缩与综合活性的案例知识进化研究
2024-03-04 12:32张建华张淑唯贺龙飞李良辰
科技管理研究 2024年2期
张建华,张淑唯,贺龙飞,李良辰
(郑州大学管理学院,河南郑州 450001)
0 引言
知识逐渐成为核心生产资料与价值创造的主体来源,企业通过知识管理培育以知识为中心的核心竞争力,实现可持续发展[1]。知识生命周期呈现加速缩短趋势,致使知识冗余现象愈发严重,限制了知识效用的发挥,故需在知识链高端加入知识进化环节,确保知识质量和存量的协同发展,提高知识传播、共享、应用与创新效益。知识进化基于知识全生命周期原理,对组织中的知识进行持续审视与动态评估,并对活性不足的知识进行更新或淘汰处理,降低知识冗余、提升知识活性,从而确保知识库的整体性能及运行效率。
1 文献综述
国内外学者从不同方面对知识进化展开研究,并将其应用于医疗、组织管理、社交网络分析、灾害学等领域,如Khakimova 等[2]、Coulet 等[3]、Krafft 等[4]、赵积强等[5]的研究。而对知识进化方法的研究主要有:张凌志等[6]提出了生物进化模式下的知识进化理论;严太山等[7]针对知识进化算法进行研究,利用适应度评价函数和关键算子实现知识进化;刘纯青等[8]根据卡尔波普尔理论,通过假说集与知识集的协同进化得到最优解;张建华[9]在多角度剖析知识活性的内涵和活性测度意义的基础上,提出了活性测度模型与学习阈控策略;张萌萌[10]进一步研究了隐性知识外显案例的进化,详细论述了周期型进化和应用型进化的机制,并通过实验验证了进化方法的有效性。
基于案例推理(case-based reasoning,CBR)是将隐性知识通过案例形式外显化的一种自学习技术。案例库维护(case-based maintenance,CBM)作为CBR 研究的分支,与知识进化存在相通之处。国内外学者对案例库维护策略的研究主要分为3 类:(1)基于聚类的案例库维护策略,如严爱军等[11]通过蚁狮算法来分配权重,采用高斯混合模型的期望最大化算法案例库维护策略;Djebbar 等[12]提出将案例库聚类后产生的边缘化案例视为错误分类的案例删除策略;Ayed 等[13]在维护案例库和词汇知识容器时提出,在聚类中使用信念函数管理不确定性。(2)基于评估指标的案例库维护,如张春晓等[14]提出改进记忆和遗忘策略的案例库维护方法,选择性地保存新案例,有意识地删除旧案例;柳玉等[15]针对案例库维护指标受主观因素影响的问题,以覆盖性和可达性为基础建立综合相关性评价模型。(3)混合案例库维护方法,如胡爱策[16]从案例库分层和性能两方面展开研究,采用改进聚类方法构建分层结构,并利用相似度计算处理冗余案例;周三三[17]引入社交网络度中心性思想,通过改进聚类更好地识别噪声案例、特殊案例,采用效用值的概念计算个案价值,得到KUCBM 案例维护方法;杨云涛[18]将CBR 技术应用于轨道运行案例库维护中,对有噪声的基于密度的聚类方法(DBSCAN)调整和冗余删除两方面进行研究,采用高维相似度解决结果区分度过低问题并构建删除函数;Lupiani 等[19]在案例库维护度量中引入多目标优化问题的适应度函数。
综上,目前关于知识进化的相关研究,在一定程度上通过聚类等技术减少冗余知识,实现了知识库优化。不过,既有研究尚存在以下不足:一是对进化效率的改进不足,聚类只能完成进化空间横向压缩,而传统粗糙集也只适用于离散型属性约简,未考虑具有连续型属性案例库的纵向压缩;二是知识活性评估指标完备性不足,忽略了时效性等因素的影响,且进化操作缺乏多样性,仅有保留和删除两种操作,非此即彼,容错能力较差,易造成有效资源流失。有鉴于此,本研究提出一种基于双维空间压缩与综合活性测度的案例知识进化方法,具体通过完成案例库的纵向和横向压缩以及测度待进化实施案例等操作,降低案例冗余水平、提高案例库质量及运行效率。
2 相关概念
2.1 邻域粗糙集
针对不精确和模糊问题,传统粗糙集(rough set,RS)理论将客观世界抽象成知识表达系统[20],但它在处理连续性数据时存在一定的局限性,需先将数据离散化再计算分析,而此过程难免造成信息丢失。邻域粗糙集(neighborhood rough set,NRS)通过条件属性信息计算距离并利用邻域处理数据,可弥补前述RS 之不足。故借鉴段洁等[21]的做法,采用NRS 实现对连续型条件属性约简,剔除冗余属性。
基于属性重要度指标构造贪心式属性约简算法,以空集为起点,采用向前搜索方法将重要度最大的属性依次加入约简集合,直到加入任何新属性系统依赖性不再变化为止,确保系统不损失重要属性[23]。
2.2 向量相似度
2.3 熵权法
熵权法作为客观赋权方法,具有较高的准确性和区分度。它基于信息熵原理,根据各指标所提供的信息量大小确定客观权重,提供的信息越多其离散程度越大、熵值越小,则权重越大;反之,则权重越小[24]。假设指标初值为,则其标准化值为:
Pab为第a个样本在第b个指标中的比重;Eb为指标信息熵且。计算公式分别为:
2.4 C4.5 决策树
决策树是一种可解释性强、常用于分类预测的机器学习算法。其中,C4.5 算法计算复杂度较低、计算效率较高,采用信息增益率选择节点属性[25]。该算法的具体步骤为:首先,实施数据预处理,将连续型属性值离散化处理形成训练集;其次,计算每个属性的信息增益和信息增益率,根节点属性每个取值对应一个子集,对样本子集执行上一步,至划分每个子集数据分类属性取值相同,生成决策树;最终,基于决策树提取规则,分类新数据[26]。
3 基于双维空间压缩与综合活性测度的知识进化机制
基于双维空间压缩与综合活性测度的知识进化机制主要包括三部分:(1)对案例库进行预处理,构建知识表达系统,通过C4.5-NRS 方法实现连续型数据集属性约简,去除案例库冗余属性的影响,并结合改进K-means 聚类完成进化空间的双维压缩,改善知识进化效率,而后基于信息熵原理圈定待进化的簇;(2)建立案例知识活性综合测度模型,从环境适应性、应用价值、冗余度和信息量维度分别拟定案例时效活性、应用活性、稀缺活性、熵活性4 项指标,并基于向量相似度和视图相似度计算,将其加权融合形成综合活性;(3)基于案例知识综合活性测度进行待进化案例活性测度、设定阈值,并据此完成进化操作。
3.1 基于C4.5-NRS 和K-means 聚类的双维空间压缩
对于体量较大的案例知识库,直接实施知识进化效率低下,因此,一般通过聚类或属性约简压缩计算空间,实现进化效率的提升。在空间压缩过程中,为最大限度保留案例信息,采用“先纵后横”的降维顺序,即先约简案例集属性再进行聚类。知识进化前,将案例库预处理成知识表达系统,其中每个属性方面特征映射到向量空间中。如表1 所示,利用向量表示第q个案例知识,其中 表示第q个案例知识的第m个属性值。
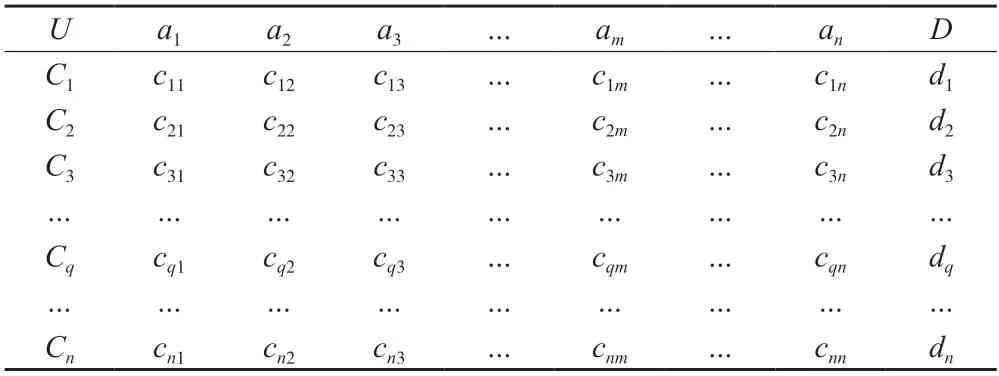
表1 知识表达系统
因不同属性的量纲存在差异,对其进行归一化处理:
对于案例知识库的冗余属性问题,传统方法一般采用粗糙集理论应对,但当案例知识属性集为连续型时,传统粗糙集方法失效。邻域粗糙集基于传统粗糙集理论,通过条件属性信息计算距离并利用邻域处理数据,可用于处理连续型属性问题。基于上述分析,利用邻域粗糙集方法实现案例库知识的属性集约简:如式(1)~(7)所示,依据最大依赖度原则实现最优约简,从案例条件属性集中提取最优属性子集,完成对待计算案例库的纵向压缩,从而减少后续知识进化的计算复杂度。
邻域粗糙集属性约简效果主要取决于邻域半径的参数选取。C4.5 决策树分类学习算法通过信息增益选择节点属性,对应条件属性相较于决策属性的重要度,可反映属性约简效果优劣,鉴于此,为有效确定参数邻域半径r,引入C4.5 决策树算法。其常用评价指标为分类准确率,由此将可行参数范围内的约简结果导入C4.5 决策树算法进行分类学习与测试,选取准确率达到最高时的结果对应的r值,以此确保约简效果。
当案例知识库规模较大时,直接测度所有案例活性会导致进化效率低下,可通过聚类缓解此问题。传统K-means 聚类因其易于实现、效率高而被广泛应用于大规模数据的情况下。其将数据集X分为k个簇,经过数次迭代,最终使每簇中所有数据点到该簇聚类中心点的距离最小、簇心不再改变,以达到最优聚类效果。但K-means 聚类也存在不足,主要体现在需要预设对聚类结果影响较大的k值,且初始中心的选择可能使结果陷入局部最优。
萤火虫算法(firefly algorithm,FA)是一种结构简单、性能良好的群智能优化算法,适用于K-Means聚类过程中的参数寻优。其通过萤火虫的发光和移动搜索空间中所有可行解进行寻优,可加快算法收敛,提高获得最优解的概率。萤火虫间的吸引度β随着距离的增大而减小,具体表现如下:
式(18)中:β0为光源萤火虫在当前位置的吸引度(与其亮度有关);为光强吸收系数;表示光源萤火虫与被吸引萤火虫间的距离。
萤火虫g被吸引向更亮的个体移动,分别以和表示其位置,加入步长因子和随机因子作为扰动项,避免结果过早陷入局部最优,则萤火虫g移动后的位置表示如下:
因此,利用萤火虫算法优化聚类,首先将K-means 算法初始中心作为初代萤火虫位置,然后根据当前位置计算亮度(即K-means算法聚类结果),从而确定萤火虫间的吸引度及移动准则,以此形成循环直至满足条件结束,选择亮度最优的个体位置作为输出,实现初始中心的变化和寻优。同时,利用手肘法确定K值,其中SSE 指标计算如下:
至此,采用改进K-means 聚类算法将案例库分簇,以降低计算复杂度,案例库经由前述聚类过程被分成若干簇。信息熵是案例包含信息量的度量,可作为知识活性的初步评估,案例信息熵越大代表其活性越高,反之则越低。由于K-means 聚类呈现簇内紧凑、簇间稀疏特征,故以簇中心案例活性表征该簇平均活性水平,直接计算其信息熵:
3.2 基于视图相似度的案例知识综合活性测度
随着时间维度的延伸,知识的应用环境持续发生变化,与知识产生时的初始环境间出现差异且持续增大,导致知识内容与其应用环境之间的匹配性持续降低,从而缩短知识生命周期、降低知识效用的实现水平,因此,适时、有效的知识进化可扭转前述知识活性单向递减趋势,延长知识生命周期,改进知识应用与创新的实效水平。
知识进化的核心是知识活性测度。知识活性表征其与应用环境之间的匹配程度,以及对知识需求的满足程度,通常基于知识价值实现测度。知识价值是联系知识主体与知识客体的纽带,其值越大表明知识活性越高,反之则越低。既有研究往往仅从知识客体角度出发,采用单一指标评估知识价值,缺乏考虑知识主体、知识应用环境等因素。由此,本研究从多元视角出发,将不同知识价值测度理论相融合,构建知识活性综合测度模型。基于时效分析的基本思路,将知识表达系统对应的知识特征与测度时点的环境特征相比较,其间差异越小代表知识活性越高。利用向量空间模型(vector space model,VSM)思想,可将案例知识对应的属性特征与测度时点的环境特征相比较,其间差异越小代表知识时效性越高,即将新案例的时效性量化为由前述两组特征值组成的向量之间的相近程度。其中,VSM 模型的特征项ti由案例库属性组成,特征项权重采用之前信息增益法的计算结果,构成特征向量空间以此计算案例时效性。
向量相似度同时测度空间向量间距离与方向两方面差异,计算结果更加准确可信,因此,采用向量相似度计算案例时效活性。将案例用向量表示,将环境抽象映射到同一向量空间中,而后计算环境向量与案例向量间的相似度:
通常,高活性知识被应用的频率也高,因而既定时域内案例被检索次数能体现其活性。显然,相对被检机会越多,则表示该案例知识的生命力越旺盛,知识活性越高。将案例被检率作为应用活性:
式(24)中:Ar为应用活性;ri表示个案被检次数;l为案例库中案例总数。
资源的稀缺性越高则其价值越高,可将其作为活性测度指标之一。知识稀缺性通过与其他知识间的视图相似度来衡量,相似度越低表示该知识稀缺性越高、活性也越高。知识视图相似度(knowledge view similarity,KVS)抽象描述了不同知识在同一视图下的相似程度[27]。各知识主体存在不同的需求视角,对同一知识的视图界定也有所不同。知识视图包含两层含义:一是知识主体将各知识属性综合,并选择合适的特征属性;二是通过权重向量表征视图中各属性对知识主体的重要程度。若知识视图T中包含u个属性,其中知识属性的权重为,各属性权重组成权重向量则知识K1和K2的视图相似度计算式子如下所示:
将待活性测度案例与既有其他案例的平均视图相似度定义为覆盖度:
式(30)中,融合系数w1、w2、w3、w4通过熵权法计算。
3.3 案例知识进化过程
知识进化操作基于知识综合活性测度结果实施,设置案例进化阈值为v1、更新阈值为v2,则当被测案例满足时,将其标定为“保留”状态,留在运营库不实施进化操作;当满足时,将其标定为“待更新”状态,留待后续知识适配与修正;当满足时,则将其标定为“休眠”状态,并转入休眠库。休眠库中的案例活性用act 表示,计算方式同Act。设置休眠案例激活阈值u1、淘汰阈值u2:当休眠案例满足条件时,从休眠库中删除此案例;当满足条件时,将其继续保留在休眠库中;当满足条件时,则将其激活并转入运营库。
综上,案例库进化流程如图1 所示。首先,构建知识表达系统,形成案例知识集;而后,依次进行邻域粗糙集属性约简和K-means 聚类分簇,完成对计算空间的双向压缩,并根据聚类中心的信息熵设定阈值,标定各案例簇为“正常”或“待进化”;最后,将待进化案例基于时效活性、应用活性、稀缺活性、熵活性4 项指标加权融合测度综合活性,并按照阈值将案例状态标定为“保留”“待更新”或“休眠”,并执行后续相应进化操作,即被标定为“保留”的案例原样留在运营库,被标定为“等更新”的案例经案例适配操作后交还运营库,被标定为“休眠”的案例则将其转入休眠库;同时,对休眠库内既有案例进行活性测度,并依据其与既定阈值的比较关系执行相应的案例操作,进行激活(转入运营案例库)、保留或删除。
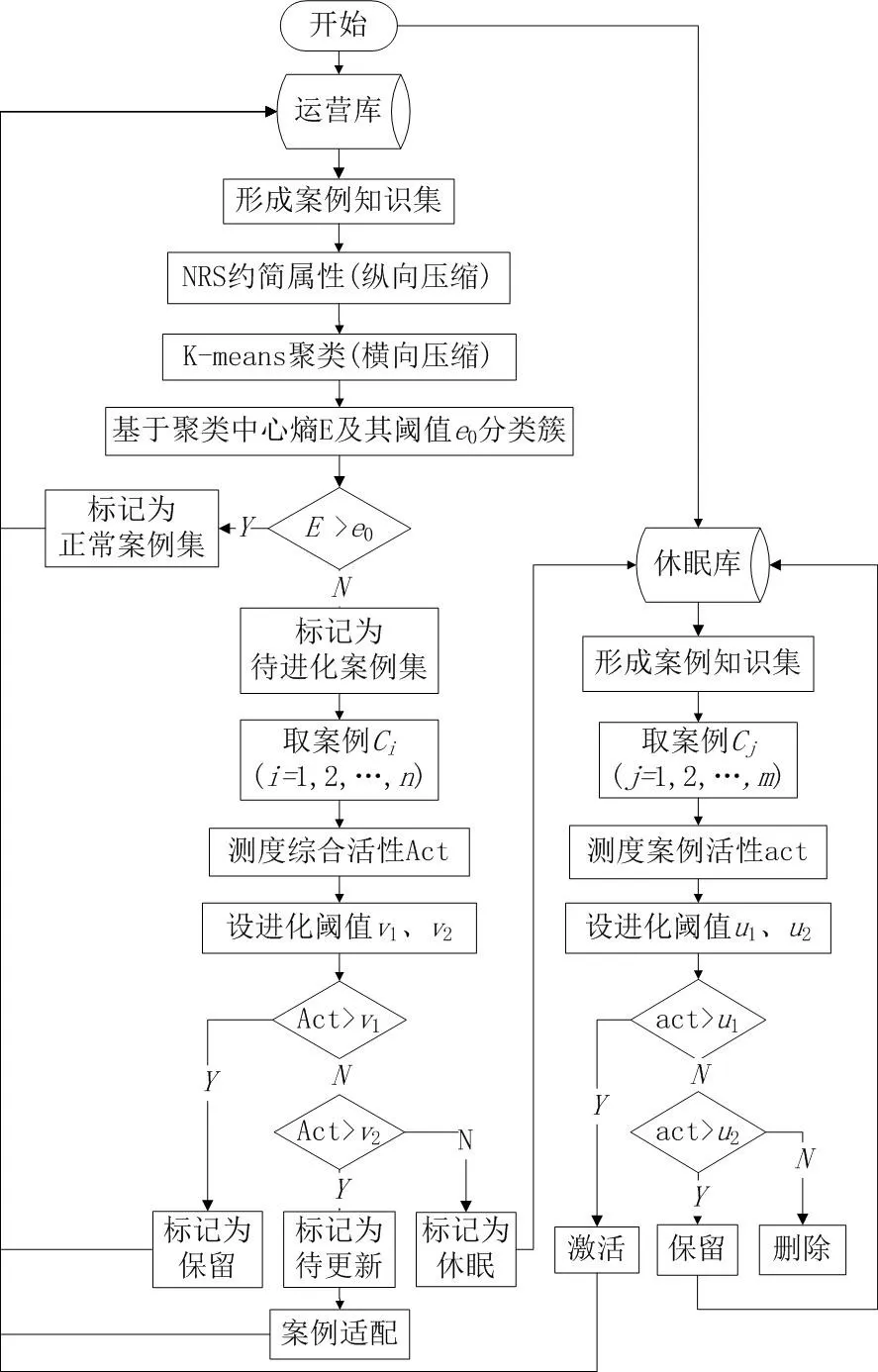
图1 知识进化流程
4 实验分析
4.1 数据集
选择加州大学欧文分校UCI 数据库中的winequality-white 数据集进行仿真实验,以验证本文所提知识进化方法的有效性。该数据集包含由多条件属性与单一决策属性组成的案例,且其条件属性为连续性变量、决策属性为离散型变量。本实验选取数据集中决策属性值为4 和8 的案例,其中300个作为案例库样本,38 个作为测试样本,具体信息如表2 所示。

表2 实验数据信息 单位:个
4.2 基于双维压缩与活性测度的知识进化
为去除案例库冗余属性,利用邻域粗糙集方法完成连续型属性约简,邻域半径r根据C4.5 决策树算法确定,选取可行范围内的r值(0.05~0.15),得到的分类准确率结果如图2 所示。在r=0.13 时,准确率达到最高值0.86,其余准确率在0.59~0.77范围内,故将邻域半径r设置为0.13,此时原11 个条件属性被约简为8 个。通过实验可知,未对数据集约简时的分类准确率仅为0.67,约简后的分类准确率明显提高,验证了属性约简的必要性。

图2 邻域半径参数r 的确定
采用熵权法确定条件属性权重,结果如表3 所示,属性权重集具有良好的区分度,其中属性a2、a4、a5、a6的权重较大。

表3 条件属性权重计算结果
实施案例聚类前,通过手肘法确定聚类中心个数,如图3 所示,当K值从1 增大到7 时SSE 下降较为剧烈,而后SSE 下降变得缓慢,即SSE 拐点处(K=7)聚类效果最佳。

图3 聚类参数与SSE 的关系
设定聚类数为7 并实施K-means 聚类,得到各簇的聚类中心与案例数N,分别计算其信息熵E,结果如表4 所示。设信息熵阈值e0=0.9,划分各案例簇状态为“正常”或“待进化”,结果簇1、2、3 和6 为待进化案例簇,内有案例243 个。

表4 实验数据集聚类及信息熵分类结果
分别测度待进化案例的时效活性、应用活性、稀缺活性及熵活性。取环境向量为正常案例向量平均值,计算其与待测度案例的向量相似度从而得案例的时效活性。采用测试案例对运营案例进行检索模拟,若被检案例的视图相似度达到阈值(取拐点值0.86),则添加1 次检索次数,由此得到运营案例的被检次数,进而计算应用活性。此外,依以上计算案例稀缺活性及熵活性,而后采用熵权法计算各指标权重,结果如表5 所示。其中,W1、W2分别为待进化案例集与休眠案例集中的权重,可见各指标对不同案例集的重要度不同,在本研究中应用活性与稀缺活性较为重要。

表5 实验数据集指标权重活性测度结果
表6 是待进化案例活性测度计算结果及操作的部分展示。

表6 实验数据集待进化案例活性测度结果(部分)
对应的进化提交与对应的案例数目如表7所示,其中案例保留48 个、待更新(留待适配与修正)135 个、休眠60 个。

表7 实验数据集待进化案例进化条件及结果
表8 是休眠案例活性测度计算结果及操作的部分展示。此操作与运营库进化操作之间存在时间差,对应的进化提交与对应的案例数目如表9 所示。其中激活案例4 个,继续保持休眠状态的案例53 个,删除案例3 个。

表8 实验数据集休眠案例活性测度结果(部分)

表9 实验数据集休眠案例进化条件及结果
4.3 结果评价
为验证本研究方法的有效性,将案例库进化前后的各项指标进行对比,结果如表10 所示,进化后总案例数稍有减少,其中运营库案例数大幅减少,但平均知识活性提高24.52%。此外,为验证进化前后案例库的性能变化,采用测试案例开展运营库检索测试发现,知识进化实现了在检索准确率仅降低2.36%的情况下将检索效率提升了21.20%。

表10 实验数据集案例库进化前后效果对比
图4是运营库在知识进化前后的整体活性对比,可见其活性呈现稳步提升趋势,且知识进化对高活性案例的改进较少,而对低活性案例改进显著。图5 是案例库进化前后案例匹配结果的对比,说明经知识进化案例库的匹配能力有所提升,面向用户需求可以检索到更为相似的案例。
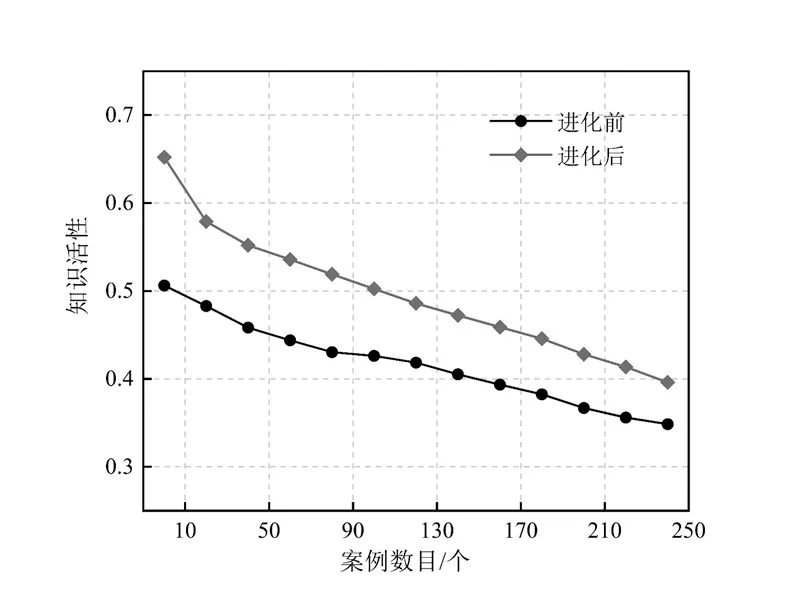
图4 进化前后案例知识活性对比

图5 案例匹配相似度结果对比
相比于既有研究,基于活性测度的案例知识进化方法具有以下优点:
(1)对进化空间实施双维空间压缩,提高了计算效率。基于传统RS 之不足,本研究通过C4.5-NRS 实现对连续型属性集约简,实现计算空间的纵向压缩;同时,利用改进K-means 聚类横向压缩计算空间。
(2)相较于传统研究的单一视角,本研究融合多元视角建立案例知识综合活性测度模型。该模型综合考虑知识的环境适应性、应用价值、冗余特性及所含信息量,相应得到时效活性、应用活性、稀缺活性和熵活性,并利用熵权法加权融合得到案例知识综合活性测度结果。
(3)相比于既有研究仅有的保留和删除二元化操作,本研究增加更新、休眠操作,从而使活性中等的案例增强活性;同时,对休眠库通过“休眠—激活”序列避免知识资源的机会损失,通过“休眠—删除”序列实现知识劣汰。这般相对完备的案例知识进化操作,能够确保案例库的存量与质量的协同发展。
5 结论
在知识经济时代,知识创造被持续提速,然而知识生命周期却在加速缩短,实施知识进化方能确保知识存量与质量高效地满足知识应用与创新需求。为此,本研究提出基于双维空间压缩与综合活性测度的案例知识进化方法,解决既有研究方案效率低下以及活性测度视角、知识进化操作不完备的问题。该方法将C4.5-NRS 算法与改进K-means 聚类相结合,实现计算空间的双向压缩,从而提高进化效率;同时,融合时效活性、应用活性、稀缺活性和熵活性,构建案例知识综合活性测度模型,并基于活性测度完成进化判定。实验结果表明了本研究提出的进化方法的有效性,后续研究可在此基础上对进化周期的确定以及相关进化阈值的灵活调整机理。
猜你喜欢
中国毕业后医学教育(2022年4期)2022-11-29
水上消防(2021年4期)2021-11-05
内蒙古教育(2021年2期)2021-02-12
吉林大学学报(理学版)(2020年3期)2020-05-29
成都信息工程大学学报(2019年2期)2019-08-28
自动化学报(2018年7期)2018-08-20
自动化学报(2018年2期)2018-04-12
韩国语教学与研究(2017年1期)2017-11-12
成都信息工程大学学报(2017年1期)2017-07-21
周口师范学院学报(2016年5期)2016-10-17
