
钢纤维混凝土抗压强度预测方法研究
2024-03-04 03:53:38刘圣超左永越
四川水泥 2024年2期
刘圣超 左永越
(1.山东省建筑设计研究院有限公司,山东 济南 250001;2.山东建筑大学设计集团有限公司,山东 济南 250013)
0 引言
钢纤维混凝土因其出色的抗拉能力、良好的稳定性等优点,成为应用广泛的纤维混凝土之一[1]。由于钢纤维和混凝土之间复杂的非线性作用,传统的理论模型难以很好地预测其抗压强度,导致理论模型预测结果具有较大的离散性,如果通过大量实验来确定钢纤维混凝土强度,实验过程繁琐且需要大量的成本开支。
现今机器学习领域取得了很大的进展,机器学习的兴起为这一难题提供了新的解决思路。尤其是集成机器学习算法,该方法基于大量的实验样本,可以直接挖掘钢纤维混凝土数据样本中输入(钢纤维混凝土基本设计变量)与输出(钢纤维混凝土力学基本性能)间的映射关系,从而建立精确、稳定的预测模型。在各种集成学习算法中,极端提升树[2]和随机森林[3]在各类预测任务中都表现出极其出色的优势。因此,本文提出采用机器学习算法来预测钢纤维混凝土的抗压强度。
1 机器学习预测模型原理
1.1 决策树
决策树[4]是一种单一的机器学习预测模型,其本质是将特征空间划分为几个单元,每个单元均有对应的输出结果,对每个节点进行是与否的判断。任何测试集中的数据都可以根据其特性归于一个单元,从而得到相应输入结果。决策树算法优点是易于理解和实现,并且对于决策树而言,算法对数据的要求比较简单,尤其是可以同时处理任何的数据型。
1.2 随机森林
随机森林是一种集成了多棵决策树的机器学习算法。随机森林由三个部分组成:决策节点、叶节点和根节点。决策树算法将训练数据集划分为分支,这些分支进一步划分为其他分支,此序列会一直持续到获得叶节点为止。当呈现一组输入变量值时,每个决策树预测因子都能够产生响应,通过训练算法引导聚合使这些决策树便生成了随机森林。
1.3 RF模型流程
RF模型的流程图如图1所示,RF将所有结果集成到一起并投票,最终将票选最多的类别作为结果输出。若是解决回归问题,则可以对RF模型训练后通过对所有单个回归树的预测结果求平均值来实现基于向量对的最终预测结果输出。

图1 RF模型流程图
1.4 极端提升树
XGBoost 属于提升学习算法(Boosting)。Boosting指的是一种通用的集成方法,通过从一个模型到下一个模型的顺序拟合,实现从多个基础弱学习器生成一个强大的学习器,从而提高算法的性能。该集成方法与Bagging 方法的主要区别在于,基础弱学习器都是以顺序的方式进行构建,而每个后续的模型均会通过尝试纠正先前模型中的误差进行构建。图2给出了Boosting树集合的示意图。从图中可知,该集成模型中涉及一个迭代过程,在该过程中,每个学习器都被拟合到前一个学习器的负梯度(残差),以此来优化目标函数,实现输出结果的预测。

图2 Boosting算法示意图
2 机器学习预测模型的数据集收集和流程
2.1 收集数据集
为进一步确定各参数对纤维混凝土力学性能影响,本研究旨在通过机器学习对收集到的实验数据库中的混杂纤维进行建模分析,该数据库包含Kobayashi[5]、马恺泽[6]、丁一宁[7]、刘朝正[8]、徐佳兴[9]、张紫键[10]等人99组不同纤维含量的实验数据。选择6个参数作为模型输入:水泥含量(kg/m3)、水含量(kg/m3)、粗骨料含量(kg/m3)、细骨料含量(kg/m3)、截面尺寸(cm)、钢纤维掺量百分比(%)。
2.2 机器学习预测模型的建立流程
机器学习模型预测钢纤维混凝土抗压强度主要包括三个方面:数据收集、机器学习模型训练和优化计算,具体流程如图3所示。需要指出的是,为了保证对比模型效果的公平性,在本研究中,使用网格搜索法进行超参数优化,确定最佳超参数。其中网格搜索优化技术是考虑用户定义的超参数的所有组合,遍历搜索确定最优超参数组合。此外,开发可靠的模型需要通过外部数据对模型进行验证,以解决过拟合问题。

图3 机器学习模型的建立流程
3 获取机器学习预测结果
3.1 模型验证指标
根据R2(决定系数)、MAE(平均绝对误差)以及RMSE(均方根误差)对所开发的模型性能进行评估。MAE通过取实际值与预测值之间绝对差值的平均值来评估性能指标,按照以下公式(1-3)进行计算:
根据上述定义可见,RMSE、MAE值越小,R2值越大,代表模型的预测精度越高。
3.2 获取模型预测结果
将获得的机器学习最优超参数和训练样本,分别代入随机森林、决策树、极端提升树三个机器学习模型,基于训练好的三个机器学习模型代入测试数据集验证模型表现。机器学习模型结果对比见图4。

图4 机器学习模型结果对比
模型预测结果分别如表1所示,可以看到,对于验证实验数据集极端提升树模型的MAPE(平均绝对百分比误差)和RMSE较其他模型均更小,具有更加精确的预测结果。表明在抗压强度预测问题上,极端提升树模型相比于其他机器学习模型预测效果更好,更加适用于预测该类问题。如图4所示,机器学习预测结果均位于10%误差线之内,说明模型预测结果具有鲁棒性。观察到训练集和测试集的精度差异微小,可以认为过拟合的程度有限,模型预测结果是可靠且准确的。同时可以看出,极端提升树和随机森林具有相似的预测精度,并且明显高于决策树模型。说明集成机器学习算法在预测钢纤维混凝土抗压强度方面具有优越性。
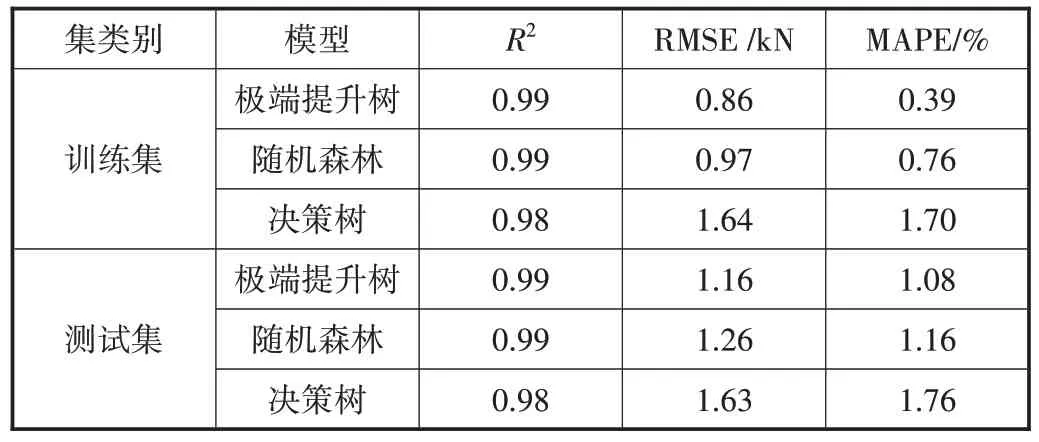
表1 机器学习模型预测结果
4 结束语
通过机器学习算法建立钢纤维混凝土抗压强度预测模型。采用集成机器学习算法,通过集成多个弱学习器来构造一个强学习器,从而找到钢纤维混凝土设计参数和其抗压强度之间的映射关系。预测误差较小的弱学习器权重较大,可提高机器学习模型的整体精度。从现有文献中共收集99组钢纤维混凝土抗压强度实验数据,用来训练集成机器学习模型,其中以钢纤维混凝土成分(例如粗/细集料、水泥、水、钢纤维掺量等)作为输入数据,以抗压强度值作为输出数据。模型验证测试数据集的结果表明,所采用的集成机器学习模型对预测钢纤维混凝土抗压强度的预测精度很高(MAPE=1.16%),并且高于传统的单一机器学习预测模型(MAPE=1.76%)。
本课题的研究说明:
(1)根据已有的钢纤维混凝土抗压强度预测的集成机器学习模型数据,证实了集成机器学习模型用于钢纤维混凝土强度预测的准确性和鲁棒性。
(2)当钢纤维混凝土的设计参数发生变化时,本文所建立的机器学习预测模型可以快速预测其抗压强度,并且预测结果具有很高的精度,能够满足工程需要。
(3)本文所提出的集成机器学习模型,相比于单一机器学习模型,预测精度进一步提高,表明该方法的有效性。
猜你喜欢
环球时报(2022-07-13)2022-07-13 17:18:39
环球时报(2022-03-14)2022-03-14 18:19:44
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年16期)2018-09-26 03:27:06
电影(2018年8期)2018-09-21 08:00:06
上海公路(2017年2期)2017-03-12 06:23:31
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
小猕猴智力画刊(2015年4期)2015-04-28 23:55:53
建筑材料学报(2015年3期)2015-02-28 02:36:30
建筑材料学报(2015年3期)2015-02-28 02:36:28
