
基于改进MobileNet V3 的矿物智能识别模型
2024-03-02 13:01张金艳屈娟萍张崇辉薛季玮卜显忠
金属矿山 2024年1期
宛 鹤 张金艳 屈娟萍 张崇辉 薛季玮 王 森 卜显忠
(1.西安建筑科技大学资源工程学院,陕西 西安 710055;2.奥卢大学奥卢矿业学院,芬兰 奥卢 FI-9004)
矿物识别是采矿工程、选矿工程等学科研究的基 础[1-3]。 目前,国内矿物识别与分类主要依据人工经验,工作人员通常根据颜色、纹理、硬度等物理特征,并借助激光诱导击穿光谱、显微光学观察、能量散射光谱等设备来判断矿物种类[4-9],然而,这些过程对工作人员的专业素养要求较高,分析步骤也较为复杂,导致整体识别效率偏低。 近年来,为提高矿物识别效率并解决识别准确率低的问题,以深度学习为代表的矿物智能识别模型成为研究热点。
随着视觉检测技术的高速发展,学者们已经建立了多种基于图像识别的矿物分类模型。 IGLESIAS等[10]利用深度残差模型(Deep Residual Network,ResNet18)对5 种矿物的偏光显微镜图像进行了分类,其准确率为89%。 SU 等[11]对LeNet-5 模型的输入样本、激活函数等模块进行改进,实现了煤和矸石的有效分类。 白林等[12]利用Inception-V3 模型对15种矿物进行分类,其测试精度为63%,该研究表明,深度学习对于提取部分岩石矿物特征信息具有明显效果。 LIU 等[13]通过对支持向量机(Support Vector Machines,SVM)模型、随机森林(Random Forest,RF)模型、基于深度学习模型和颜色特征模型耦合的综合识别模型进行对比分析,证明了耦合模型的良好性能。 李明超等[14]基于Inception-V3 模型,利用矿物图像强化后的纹理特征以及由K-means 算法得到的颜色特征,建立了一套可区分19 种不同矿物的耦合分类方法。 ZENG 等[15]利用EfficientNet-b4 模型实现了对36 种矿物的分类,但其准确率仅为71.2%,当其将矿物莫氏硬度特征与图像特征耦合时,模型准确率可达到90.6%。 LIANG 等[16]通过将图像切割方法、SBV 算法与各模型相结合,使矿物图像准确率比原模型ResNet-50、ViT (Vision Transformer)、EfficientNet-B0 分别提高了34.38%、18.75%和43.75%。 在深度学习中,充足的数据样本是保证模型训练成功的关键。 然而,由于矿物种类繁多,且样本数量较少,因此尚未建立标准的矿物数据集。 已有研究发现迁移学习[17-18]可有效解决这一问题。 PU 等[19]采用VGG16(Visual Geometry Group,VGG)迁移模型实现对煤和煤矸石分类,准确率为82.5%。 王李管等[20]研究发现:Wu-VGG19 迁移模型对黑钨矿石与围岩的识别效果最优,识别率为97.51%;Wu-v3 迁移模型对石英脉石的识别效果最佳,其识别率为99.6%。 张野等[21]以Inception-v3 模型为基础,结合迁移策略实现了对花岗岩、千枚岩和张角砾岩的有效分类。 ZHOU等[22]基于MobileNet 模型,结合迁移学习与SE(Squeeze-and-Excitation)注意力机制,使得7 种矿物分类准确率达到96%。
上述研究表明,基于深度学习的矿物识别可以较好地解决传统方法中效率偏低的问题,并具有较高的准确率。 然而仍存在一些问题,例如当矿物识别种类较多时,模型准确率会显著下降,特别是当仅有矿物图片数据时,现有的矿物识别模型准确率不佳,且模型过多的计算量和内存需求使矿物检测模型难以在手机、树莓派等小型终端设备上实际应用,极大地限制了矿物识别与分类技术的推广和应用。 为解决上述问题,本研究以19 种矿物图像作为输入,提出一种基于改进的MobileNet V3 矿物图像智能识别模型。针对MobileNet V3 模型中的SE 注意力机制存在无法提取空间信息的问题,引入协调注意力机制,以增强模型对矿物特征的学习能力,并全面捕捉矿物关键信息。 同时,采用迁移学习方法加速模型收敛速度、提高模型泛化性。 最后,使用t-SNE[23]方法对其分类结果进行可视化分析,进一步验证新模型的有效性。 本研究旨在有效提高矿物识别准确率和模型泛化性,显著降低计算量和内存需求,从而实现对不同矿物的准确高效识别。
1 MobileNet V3 模型概述
在计算机视觉领域发展过程中,为解决传统模型存在的复杂度高、参数量大、应用部署环境要求高等问题,轻量化模型应运而生。 MobileNet 系列模型包含MobileNet V1、MobileNet V2、MobileNet V3 这3 种模型。 MobileNet V1 模型主要由深度可分离模块叠加而成;MobileNet V2 模型在MobileNet V1 模型基础上引入倒残差和线性瓶颈层模块,即瓶颈残差模块;MobileNet V3 模型引入了MobileNet V1 模型的深度可分离卷积模块和MobileNet V2 模型中的瓶颈残差模块。 同时,MobileNet V3 模型添加了SE 注意力模块,并引入一种新的激活函数h-swish(x)。 SE 模块通过学习通道特征关系增强网模型学习能力,而hswish 函数具有强大的非线性表达能力和渐进饱和特性,适用于深度神经网络中的卷积层和全连接层,可为模型提供更好的梯度流动和优化性能,从而提高模型的准确性和训练效率。 MobileNet V3 模块如图1所示。
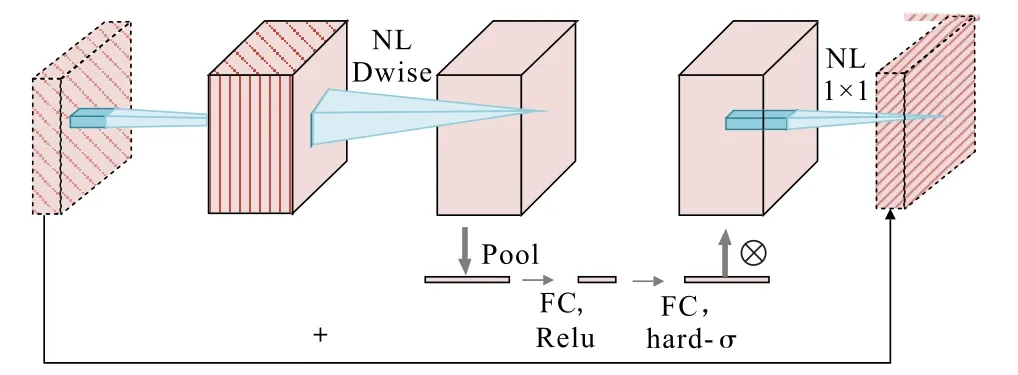
图1 MobileNet V3 模块Fig.1 MobileNet V3 block
MobileNet V3 模型根据计算复杂度的不同,共有MobileNet V3-Large 和MobileNet V3-Small 两个版本,本研究综合考虑矿物类别与数量,选取MobileNetV3-Small 版本,模型具体结构见表1。 首先,将大小为2242×3(高度与宽度大小为224,通道数为3)的图像作为输入,经过一系列瓶颈残差模块及融合SE 结构的瓶颈残差模块操作,输出大小为72×576 的特征图,然后通过全局平均池化(Pool)、全连接层等操作,最终得到大小为1 000 的分类结果。

表1 MobileNet V3-Small 模型结构Table 1 Structure of the MobileNet V3-Small model
2 CA-MobileNet V3 模型构建
2.1 迁移学习
在训练数据充足的情况下,深度学习能够从图像中提取多层次特征,以捕捉物体之间的微小差异。 然而在实际应用中,部分研究对象(如矿物图像)训练数据难以搜集,导致模型训练无法取得理想结果。 为解决数据稀缺问题,研究者通常采用迁移学习策略,并使用大规模数据集(如ImageNet)进行预训练。 迁移学习在缺乏大规模训练数据的情况下,能够利用已有模型在其他任务学习到的特征辅助目标任务学习;ImageNet 中庞大的数据基础使其迁移效果总是优于其他数据集,这有助于在降低模型训练成本的同时避免过拟合。 迁移学习为解决实际应用中数据不足问题提供了一种有效途径,使深度学习模型在训练数据不足时仍能达到目标要求。
鉴于本研究涉及的矿物种类繁多且数据集规模有限,同时ImageNet 数据集中存在与矿物接近的地质类数据,故采用迁移学习方式,将MobileNet V3 原模型与矿物识别模型之间实现参数共享,从而降低训练成本,并提高矿物智能识别模型的泛化性。
2.2 协调注意力机制(Coordinate Attention Mechanism)
MobileNet V3 模型的SE 注意力机制主要关注内部通道信息,而未考虑位置信息影响。 相比之下,CA注意力机制[24]通过将位置信息嵌入通道注意力中,既避免引入过多计算量,又能使模型获取更丰富的信息。 CA 注意力机制的实现主要包含两个过程,即协调信息嵌入和协调信息生成。 在协调信息嵌入阶段,采用全局池化方法导致全局空间信息压缩至通道信息中,位置信息难以保存。 为了促使注意力模块能够捕捉具有精确位置信息的特征数据,CA 注意力机制对全局池化进行分解,并转为一对一维特征编码操作。 给定输入X,并应用尺寸为(h,1)和(1,w)的池化核,分别对水平及垂直方向的每个通道进行编码,如式(1)、式(2)所示。 在此转换过程中,特征分别沿水平和垂直方向进行聚合,用以捕捉远距离的相互关系和位置信息。 这使得注意力模块在空间方向上能更好地捕捉目标之间的关联,同时在另一个方向保留位置信息,从而提高模型对目标的准确定位能力,增强特征提取效果。 在协调信息生成阶段,涉及将具有精确编码信息的特征层与原始特征图合并,形成包含水平和垂直位置信息的中间特征。 该中间特征被用于最终的协同注意力层,为模型提供更全面和准确的信息,使模型在处理复杂任务时更加精确和高效。 整个过程通过对空间位置的细致处理,有效增强了模型的感知能力和任务处理能力。
式中,h、w分别为输入图像的高度和宽度;分别为沿水平方向和垂直方向进行平均池化操作得到的输出结果。
CA 注意力机制在本研究模型中的具体实现流程如图2 所示。 步骤为:① 输入大小为C×H×W(即通道数为C,高宽为H×W)的矿物图像特征图;② 通过使用不同池化核(H,1)和(1,W)沿着输入特征图的2个方向进行池化,对得到的2 个嵌入特征图沿空间维度进行拼接(Concat);③ 经过1×1 卷积(Conv2d)变换后,应用激活函数对其进行激活(BatchNorm+Nonlinear);④ 沿空间维度进行拆分操作(Split),将特征图分为2 个独立部分;⑤ 对分离特征图进行transform 和Sigmoid 操作,并将得到的特征图通过广播机制与输入特征图进行逐元素相乘操作(Re-weight),进而得到矿物图像特征权重。 通过利用池化、卷积、激活函数、分割、逐元素相乘等方法,实现对输入特征图的精细加工。 这样的处理使得模型能够准确捕捉图像特征之间的关联性,并为不同部分赋予合适权重,从而提高模型对矿物图像特征的准确表达和理解能力。
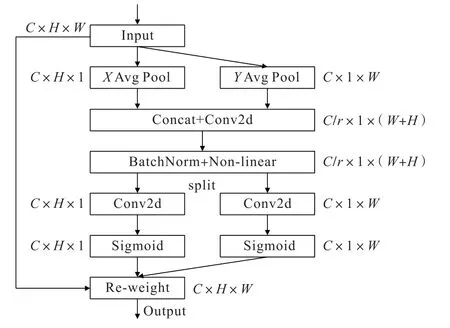
图2 CA 注意力模块Fig.2 Coordinate Attention block
2.3 矿物智能识别模型
针对当前矿物图像分类模型搭载设备计算量大及准确率较低的问题,本研究以MobileNet V3 模型为基础,采用迁移学习策略并嵌入CA 模块,构建了矿物分类模型,命名为CA-MobileNet V3 模型。 矿物智能识别模型整体结构如图3 所示。 具体流程如下:

图3 矿物智能识别模型流程Fig.3 Workflow of the mineral intelligent recognition model
(1)采用已在ImageNet 预训练的MobileNet V3模型,并经微调处理后,通过迁移学习方式将其加载至矿物分类模型框架中。 利用ImageNet 大规模数据训练得到的通用特征,提高模型对矿物图像的学习能力。
(2)将MobileNet V3 模型中的SE 模块更换为CA 模块,利用CA 模块捕捉图像特征之间的关联性,实现对多特征信息的有效融合,从而提高模型对矿物图像的表达能力。
(3)通过全局平均池化等操作实现对矿物图像的识别分类。 该结构设计使得模型更好地适应矿物图像分类任务,充分发挥MobileNet V3 模型的轻量级优势。 同时,引入CA 模块提升对图像特征的捕捉和表达能力。 通过对19 种矿物图像数据进行一系列试验验证后,本研究构建的CA-MobileNet V3 模型在矿物分类准确率和模型性能方面均得到显著提升,相较于现有的主流模型具有更为出色的性能。
3 试验分析
本次试验采用Pytorch 框架对迁移模型进行搭建和测试,该框架可快速灵活地构建神经网络模型,是理想的试验工具。数据预处理和模型训练的硬件环境为:Intel(R)Core(TM)i7-9700 CPU@3.00 GHz 处理器,64 GB 内存,NVIDIA GeForce GTX 1660 Ti。 经过测试,最优试验参数取值为:衰减策略采用固定步长衰减法(StepLR),gamma系数设置为0.5;模型训练中采用带动量的Adam(Adaptive Moment Estimation)方法,动量因子设置为0.1;损失计算方式为交叉熵计算方法;每个batch 训练样本数量(batch_size)设置为32,训练周期epochs设置为60 轮。
3.1 试验数据及评价指标
本研究矿物数据集中的图片来源于mindat. org网站及自行拍摄,共19 种矿物图像,各种矿物及数量见表2。 鉴于数据相对有限可能会导致模型出现过拟合现象,本研究选取旋转、垂直变换等数据增强手段将每种图像增加至2 000 幅左右[25-26],以确保模型在训练过程中能更好地学习并泛化到不同的数据情况。 为对模型进行有效评估,将数据集按照8 ∶1 ∶1 划分为训练集(train)、验证集(val)、测试集(test)。 同时将数据集像素统一压缩为224×224,以提高模型的准确率及计算效率,并适应不同模型的输入。

表2 矿石种类及其数量Table 2 Mineral types and quantities 幅
在实际分类任务中,预测值与真实值的吻合情况见表3。 其中,TP表示真实值为正,预测值为正;FP表示真实值为正,预测值为负;FN表示真实值为负,预测值为正;TN为真实值为负,预测值为负。

表3 分类指标Table 3 Classification index
本研究模型训练及测试结果依据准确率(accuracy)、f1-score 等指标对各矿物的识别模型进行性能评估,计算公式如下:
式中,precision为精确率;recall为召回率。 可分别进行如下计算:
3.2 不同模型对比试验分析
各模型训练损失曲线,以及验证集损失值、准确率、f1-score 值变化曲线如图4 所示,其中mobilenet v3为未经迁移学习模型,MobileNet V3 为经迁移学习的模型,CA-MobileNet V3 为本研究改进模型,ShuffleNet V2、EfficientNet V2 为CA-MobileNet V3 的对比分析模型。 由图4(a)可知:经过迁移学习后的各模型均较快进入收敛状态且稳定趋于0,未经迁移学习的mobilenet v3 模型则相对较慢进入收敛状态且收敛于0.5,这表明迁移学习对模型训练起到积极作用。 由图4(b)、图4(c)、图4(d)可知:在模型训练过程中,CA-MobileNet V3 验证集损失值最低,且准确率及f1-score 值均优于mobilenet v3、MobileNet V3、ShuffleNet V2、EfficientNet V2 模型,表明改进模型的CA 注意力机制将各矿物图像的位置信息有效嵌入通道注意力中,并对矿物图像特征进行了有效提取。 因此,CAMobileNet V3 模型更适合应用于矿物图像分类。

图4 各模型性能曲线Fig.4 Performance curves of various models
将训练后的模型应用于测试集,得到各模型的相关评价指标见表4。 由表4 可知:经过训练的3 种迁移模型在测试集准确率(testaccuracy)和测试集f1-score(testf1-score)方面均达到80%以上,表现出良好的类别预测一致性。 相较之下,未迁移学习模型mobilenet v3 的准确率仅为51.42%,突显了基于迁移学习的轻量型模型在矿物分类中的有效性。 ShuffleNet V2 和EfficientNet V2 迁移模型测试集Top1-准确率均为81.61%,但模型大小均超过20 MB。 相比之下,准确率为93.90%的CA-MobileNet V3 迁移模型在保持高性能的同时,其模型大小仅为4.64 MB,且比准确率为88.67%的MobileNet V3 模型小22.80%。 对比可知,CA-MobileNet V3 迁移模型测试效果最为出色,Top1-准确率为93.90%,f1-score 值为93.89%,Top2-准确率达到98.58%。 这表明引入的CA 注意力机制可有效提升模型特征提取能力,在矿物分类方面性能提升显著。 综上所述,CA-MobileNet V3 迁移模型不仅具有较高的矿物分类准确率,而且其模型较小,相比mobilenet v3、ShuffleNet V2、EfficientNet V2 及MobileNet V3 模型优势显著,是本研究最佳模型。
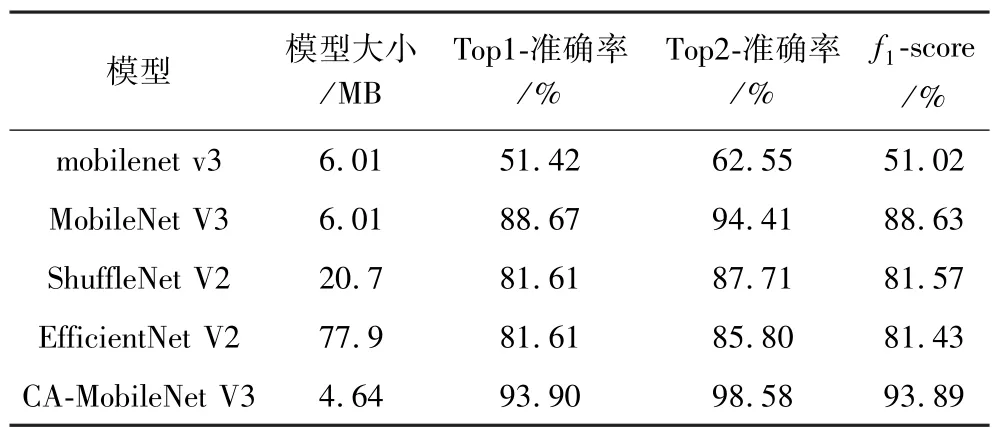
表4 不同模型测试结果Table 4 Test results for different models
CA-MobileNet V3 模型部分测试集的分类识别效果如表5 所示。 由表5 可知:在前3 幅矿物图像中,模型的预测种类与实际种类一致,突显了CA-MobileNet V3 模型在面对不同类型矿物时的出色分类识别能力,反映出该模型在多类别矿物分类中的鲁棒性。 对于第4 幅矿物图像,模型将菱铁矿预测为磷灰石,预测出现偏差。 观察图5 中菱铁矿和磷灰石矿物图像可发现,两者在颜色、纹理等方面存在相对接近现象,从而导致模型发生误识别。

表5 部分识别结果Table 5 Part of the recognition results

图5 矿物图像Fig.5 Mineral images
3.3 t-SNE 可视化分析
为更直观地展示分类效果,本研究采取t-SNE 方法对高维数据进行降维表达,以便将数据分布规律进行可视化展示。 对各模型最后一层全连接层进行测试集语义特征提取,所得二维平面效果如图6 所示。

图6 各模型t-SNE 可视化结果Fig.6 Visualization results of t-SNE for each model
由图6 可知:测试集准确率仅为51.42%的mobilenet v3 模型的t-SNE可视图中,各类数据混乱无序,没有形成清晰的簇结构。 在ShuffleNet V2 和EfficientNet V2 模型的二维映射中,虽然形成一部分簇结构,但各簇之间交叉过多,模型对各类矿物种类的特征区分效果不理想。 与之相比,MobileNet V3 模型的二维语义特征映射效果显著提升,相对而言CA-MobileNet V3 模型中各类矿物之间的特征间隔更为明显。 通过t-SNE 可视化对比分析可知,CA-MobileNet V3 模型在各类矿物分类中表现最佳,具有出色的分类效果,与数据分析结果一致,进一步验证了该模型的可靠性。
4 结 论
(1)本研究提出了矿物智能识别模型CA-MobileNet V3。 该模型以构建的19 种矿物图像数据集作为研究对象,以轻量型模型MobileNet V3 为基础,通过可融合多特征的协调注意力机制更换原有的SE注意力机制,并采用迁移学习方法对CA-MobileNet V3 模型进行训练,提升了模型中矿物图像特征融合能力及模型收敛速度。 同时,利用t-SNE 可视化方法进一步验证了模型可靠性。
(2)针对19 种矿物图像,将CA-MobileNet V3 模型与mobilenet v3、MobileNet V3、ShuffleNet V2、EfficientNet V2 模型进行对比,反映出迁移学习模型收敛速度优势明显。 其中,CA-MobileNet V3 模型在训练过程中准确率最高,且模型大小显著低于其他模型,满足模型轻量化要求。 同时,t-SNE 可视化方法清晰展示了CA-MobileNet V3 模型在矿物分类任务中具有良好效果,进一步证明该模型在矿物识别方面具有显著优势。 可见,协调注意力机制可有效融合通道及空间信息从而提升模型准确率。
(3)本研究模型在矿物特征相似程度较高的情况下,识别效果不佳。 在后续研究中,考虑引入更为精细的特征提取方法或模型优化策略,提高模型对于细微差异的敏感性。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
矿产综合利用(2020年1期)2020-07-24
山东国资(2020年4期)2020-06-10
中国交通信息化(2018年5期)2018-08-21
中成药(2018年2期)2018-05-09
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
