
基于注意力机制的轻量化VGG玉米籽粒图像识别模型
2024-02-28 07:51孙孟研代东南穆春华马德新
中国粮油学报 2024年1期
孙孟研, 王 佳, 马 睿, 代东南, 刘 起, 穆春华, 马德新
(青岛农业大学1,青岛 266109) (山东省农业科学院玉米研究所2,济南 250100)
玉米是主要的农作物之一,也是工业生产中重要的原材料。近年来,玉米育种技术快速发展,导致品种数量迅速增长,种子市场由于大量假冒伪劣种子的出现而混乱,因此,探索出一种识别效率高的品种识别方法十分必要。
随着农业信息化的发展,大量的计算机技术在农业中得到了应用。特别是神经网络概念提出后,深度学习由此开始[1];随后AlexNet取得重大突破,以超对手15.2%的优势获得桂冠[2]。Yann等[3]进一步明确了什么是深度学习并指出了深度学习的定义。与传统的机器学习相比,深度学习能更有效地提取农业领域图像中的特征,识别效率也远高于传统的机器学习方法。农作物籽粒的品种识别是深度学习在农业应用领域中的一个重要方面[4-6]。Tu等[7]基于迁移学习VGG16对品种京科968进行识别,最终在测试集上的准确率能达到98%。王佳等[8]基于迁移学习选用5个网络模型进行测试,结果表明,ResNet的网络性能最高,在双面混合数据集上能达到99.91%。马睿等[9]采用ResNet等4个网络模型提出了基于迁移学习与CNN相结合的方法,对6个玉米品种的籽粒图像进行识别,结果表明,Xception的网络性能最高,在胚乳面数据集上识别准确率能达到95.55%。王玉亮[10]开发了玉米种子品种识别系统并提出多对象轮廓提取算法,对4个玉米品种的数据集进行测试,结果表明,该算法的最高准确率能达到100%。刘林[11]提出了基于深度学习的玉米品种识别方法,制作了登海518等3个品种的数据集,利用深度学习框架搭建了基于迁移学习的VGG19等3个网络模型,结果表明,3个网络模型的识别准确率均达到了99%。王佳等[12]以登海605品种为例,对VGG16采用不同的策略进行微调,结果表明,模型在3类数据集上的准确率都能达到100%。徐岩等[13]选取登海518等3个品种建立数据集,基于Keras深度学习框架建模,结果表明,在3类玉米品种上的平均识别准确率高达95.49%。吕梦棋等[14]基于残差网络进行建模,结果表明,优化后的ResNet网络模型对种子的识别准确率最高能达到96.4%。
本研究采用相机采集了胚面和胚乳面的双面混合图像并建立起数据集,基于VGG16[15]并对网络结构进行轻量化处理,仅保留6个卷积层,6个池化层,并在第1个和第2个卷积层后面引入注意力机制——SE模块,为了防止梯度爆炸或梯度消失以及减少过拟合发生的概率,在SE模块后面加入BN层[16]。通过对VGG16进行轻量化处理的方式建立起玉米籽粒品种识别模型,该方法简单高效、训练成本低且准确率高,为玉米品种的快速识别和保护提供了参考。
1 玉米籽粒图像分类识别模型
1.1 VGG16卷积神经网络模型
VGG16卷积神经网络该模型结构简单,主要由卷积层、池化层[17]等组成。与传统机器学习算法不同,CNN能自动学习到各层特征并应用于图像分类。卷积层的作用是在不改变图像大小的情况下提取图像中特征,主要实现降维处理和提取特征的目的。图像在经过卷积处理后,下一步进行池化操作。通过重复堆叠卷积层和池化层来实现输入数据的空间映射。而全连接层起的作用则是将前面各层提取到的特征进行加权合并,以实现对玉米籽粒图像的最终分类。
1.2 SE模块
标准的卷积操作以channel为基本单元对图进行特征提取,但难以捕获特征图通道之间的关系信息。为了补充这部分信息,Hu等[18]提出了SE模块。该模块结构简单,易于操作,能够很容易地嵌入到现有的主流卷积神经网络结构中。SE模块主要是学习了channel之间的相关性,筛选出针对通道的注意力,提高网络性能。
SE模块可以实现注意力机制的原因一是采用全连接,二是相乘特征融合。一个SE模块主要由Squeeze、Excitation两部分组成,详细结构如图1所示。W表示特征图的宽,H表示特征图的高,C表示channel的数量,输入特征图的大小为W×H×C。第一步操作为Squeeze[19]。使用全局平均池化进行Squeeze操作将全局空间信息压缩到信道描述符中。从形式上来说,统计量z∈RC是通过收缩U(每一层输入通过卷积操作得到的输出)的空间维度H×M所形成的,对于z的第c个元素进行计算。

图1 挤压激励模块
为了利用squeeze操作中聚合的信息,在Squeeze操作后执行Excitation[20]操作。为了限制模型的复杂性并帮助通用,excitation模块会在非线性周围形成一个由两个完全连接层组成的瓶颈来参数化选通机制,即一个降维比为R的降维层,一个ReLU,然后是一个回到转换输出U的通道维数的升维层。特征向量Z输入到excitation模块中,进行计算:
s=Fex(z,W)=σ[g(z,W)]=σ[W2δ(W1Z)]
(2)

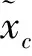
1.3 改进后的VGG16
VGG16的网络模型较为简单,也具有很强的拟合能力,但是模型拥有的参数数量较多,这代表着必须具有足够大的容量才能够对VGG16进行存储和训练。较大的体积不仅不有利于在服务器上进行部署,而且训练模型所需的较长时间也加剧了调整模型超参数的困难程度。基于这些问题,本文对VGG16原有的网络模型进行轻量化处理。处理后的模型由6个卷积层、6个池化层以及2个全连接层组成,并在第1个卷积和第2个卷积后面加入注意力机制——SE模块,并在SE模块后面加入了批量规范化层[21],新提出的网络模型记为L-SE-VGG,网络结构如图2所示。

图2 L-SE-VGG网络结构图
本文提出的L-SE-VGG与原有的VGG16相较,减少了卷积层的数目,使网络结构更加简洁,而且卷积层的减少也带来了卷积核数量的减少。虽然精简网络结构后的L-SE-VGG提取到的特征数量相较于VGG16较少,但是对于样本之间具有较小特征差异的玉米籽粒图像所取得的识别效果较好。
2 材料与方法
2.1 数据采集
选取5个品种的玉米籽粒进行识别研究,在照片拍摄之前,先由人工从众多玉米籽粒中挑出色泽度较好、外形饱满且完整无缺的玉米种子,为拍摄工作做准备。选用品种的详细数量以及产地如表1所示。在实验室自然光照条件下使用EOS80D型相机拍摄在黑色植绒布上摆放好的玉米种子,详细情况如图3所示。
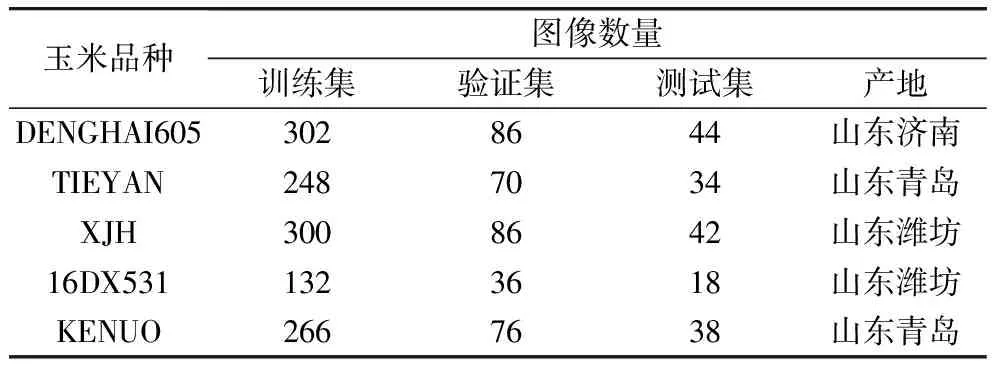
表1 玉米籽粒(双面混合)数据集

图3 多粒玉米籽粒图像
2.2 图像预处理
本实验拍摄的是一张照片中含有多个玉米籽粒的图片,但最终进行品种识别的是单个玉米籽粒。因此需对图像进行处理。主要步骤包括对多籽粒图像进行二值化处理,再利用轮廓检测算法提取单个玉米籽粒的轮廓;最终利用Python OpenCV 画框切割算法提取单粒玉米图像。图像处理过程如图4所示。
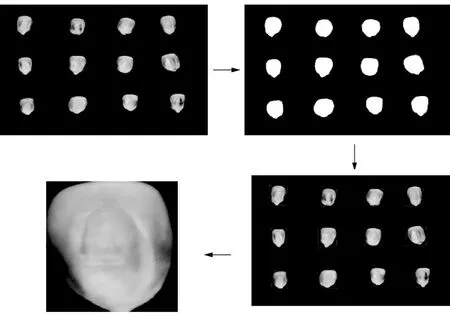
图4 图像处理过程图
2.3 实验超参数设置
本实验基于Tensorflow平台,采用Keras深度学习框架,使用Jupyter在GoogLeColabotory平台上搭建网络模型。具体参数配置如表2所示。
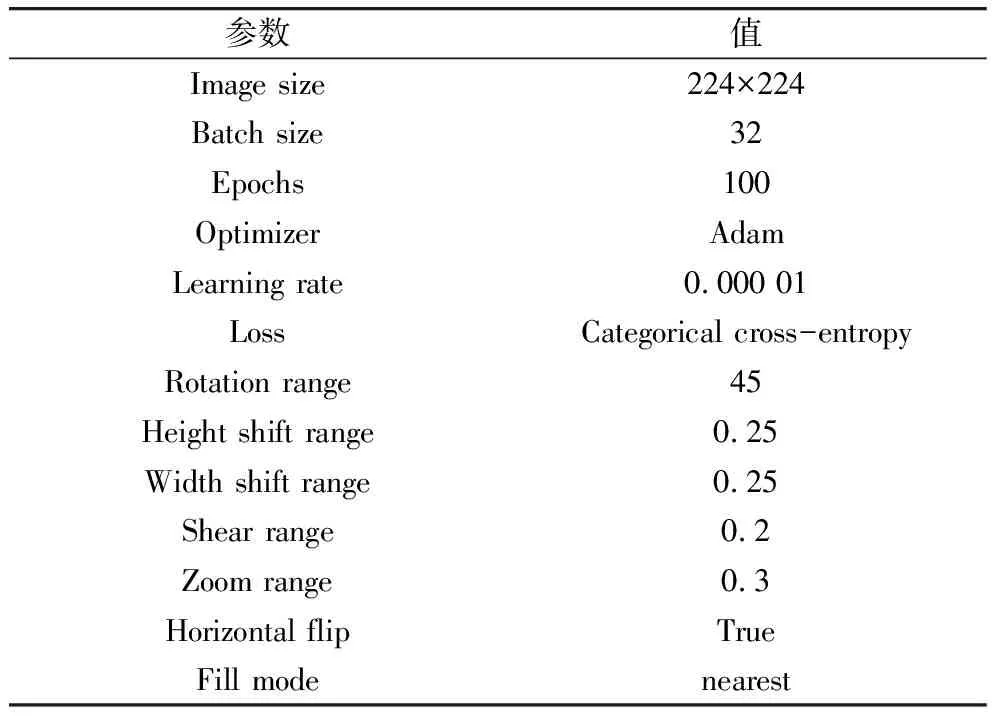
表2 实验详细超参数
2.4 数据集的划分与增强
针对样本小带来的模型泛化能力不足等问题,采用随机旋转,水平方向平移、翻转等操作增加训练集的数量,经过一系列操作后使现有的训练集数量是未进行数据增强之前的7倍。对验证集和测试集只进行归一化操作,经过数据增强操作后,能够提高模型的准确率,增强模型的识别能力。
2.5 模型性能评价指标
采用召回率、准确率、精确率、F1分数和混淆矩阵作为模型性能评价指标。




式中:TP为实际为正被预测为正的样本数量;FP为实际为负但被预测为正的样本数量;FN为实际为正但被预测为负的样本数量;TN为实际为负被预测为负的样本数量。
3 结果与分析
3.1 注意力模块数量对准确率的影响
为了探究引入注意力模块数量对模型准确率的影响,本实验设计了一组消融实验,SE模块添加的位置均在卷积层后面。例如,SE×1代表在第1个卷积层后面添加SE模块,SE×2代表在第1个和第2个卷积层后面分别添加SE模块,以此类推。消融实验结果如表3所示。

表3 消融实验结果
由表3所示,SE模块的数量对模型准确率影响很大。在前2个卷积层后面加SE模块时,模型的准确率高达98.86%,而如果在前4个卷积层后面加SE模块的情况下,模型准确率只有75%,远低于未预训练的VGG16和迁移学习VGG16的准确率。通过消融实验,本实验确定了只在前2个卷积引入SE模块,这样不仅能简化网络架构,而且在减少模型计算参数数量的情况下提升了准确率,节约了计算时间和成本。
3.2 L-SE-VGG对品种鉴定分析结果
使用测试数据集对L-SE-VGG模型进行评估,图5为L-SE-VGG在测试数据集中对玉米籽粒品种识别的混淆矩阵。在KENUO品种上有1个识别错误的图像,被识别成了XJH;在TIEYAN品种上也有1个被识别错误的图像,也被错误的识别成了XJH。这是因为KENUO和TIEYAN与XJH之间颜色非常接近,单凭肉眼很难去区分,而且这几个品种之间的差异十分细微。L-SE-VGG在测试数据集上的其他评价指标如表4所示。
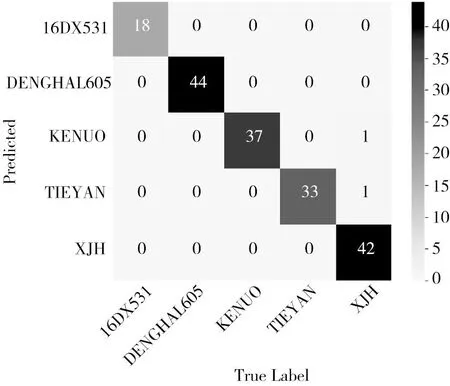
图5 L-SE-VGG混淆矩阵
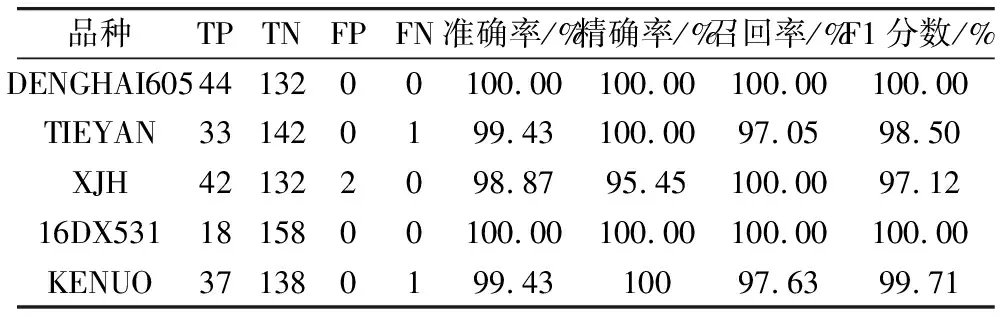
表4 L-SE-VGG其他评价指标
在测试数据集中,本研究所提出的L-SE-VGG对玉米籽粒品种的识别效果非常好。从单个品种的识别效果看出,该模型对5个玉米籽粒品种的识别准确率高于98.87%,精准率高于95.45%,召回率高于97.05%,F1分数高于97.12%。以登海605和16DX531这2个品种为例,准确率、精准率、召回率、F1分数均都达到100.00%。表明本研究提出的L-SE-VGG模型能够非常精准的识别测试集中的每个品种的玉米籽粒图像,为农业上的品种识别提供了很大的便利。
3.3 不同模型的鉴定结果比较
图6描述了未预训练VGG、迁移学习TL-VGG、不加SE模块L-VGG以及L-SE-VGG对双面混合数据集进行品种识别完成100轮的训练集上准确率的变化。由图6可知,未预训练VGG16模型准确率不仅上升速度慢,而且收敛能力也较弱。而L-SE-VGG与不加SE模块的L-VGG相比可明显看出加SE模块的L-SE-VGG在迭代10轮后就能达到接近90%的准确率,收敛速度也明显快于L-VGG,这证明了在经过轻量化处理后的VGG16里加SE模块的可行性。通过模型之间的对比,证明了本研究提出的L-SE-VGG模型能准确提取到玉米籽粒图像的特征并进行高效品种识别。

图6 不同模型的准确率对比
为了进一步评估本实验使用的模型,引入总体准确率,Kappa系数和模型大小作为评价指标,评价结果如表5所示。
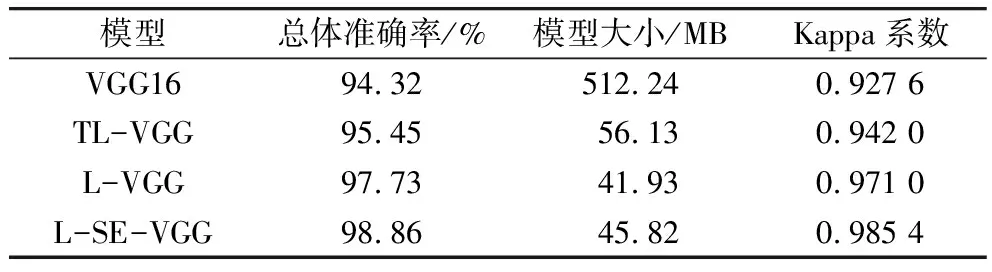
表5 不同模型定量评价结果
L-SE-VGG取得了最高总体准确率和Kappa系数,比VGG16准确率增加4.54%,Kappa系数增加0.057 8,并优于其他3种模型。对比未预训VGG16和迁移学习TL-VGG,L-SE-VGG模型大小明显要小很多,与不加SE模块的L-VGG相比只多了4MB,说明L-SE-VGG在提高模型准确率的同时并没有显著增加模型的大小,也代表了这个轻量化的L-SE-VGG模型适合在移动端的部署。
因此,通过对不同模型在测试数据集上的综合比较可知,本文提出的L-SE-VGG能准确识别玉米籽粒品种,为玉米籽粒品种识别提供了一种客观准确,高效无损且适合移动端部署的模型构建方法。
3.4 玉米籽粒品种识别结果可视化分析
3.4.1 不同玉米品种的可视化
通过对卷积层特征的直观分析,有助于了解卷积神经网络输入的转化过程,理解卷积神经网络各个滤波器的含义。5个品种玉米种子特征在不同卷积层中的可视化如图7所示。在第一层可以比较清晰地看到玉米籽粒的完整形态。随着层数的加深,激活逐渐变得抽象起来,这代表着层数越深,从特征图里提取到的视觉内容信息就越少,而能提取到玉米品种类别的信息就越多。

图7 不同玉米品种的可视化
3.4.2 卷积层的视觉比较
卷积神经网络提取的特征是判别性的特征,可以忽略玉米种子图像中不相关的背景,只提取关键的特征信息。通过可视化这些信息,可以清楚地知道网络在训练过程中是怎样“看待”输入的图像并识别有效内容的。特征可视化对我们深入理解神经网络的特征学习机制起着非常重要的作用,它直观清晰,细节丰富。通过比较L-SE-VGG16和VGG16的卷积层特征图(如图8所示),可以直观的看出L-SE-VGG16提取的特征比VGG16更加复杂,传统的VGG16提取的特征大多数为玉米种子的简单外部轮廓,而L-SE-VGG16不仅提取了更详细的轮廓特征,还包含更多的依靠人肉眼难以辨别的细微的纹理特征,可以清楚地看到玉米种子的具体纹理,特征提取更深刻,细节更丰富。

图8 卷积层的视觉比较
4 结论与展望
本研究对VGG16进行轻量化处理,提出了卷积神经网络与注意力机制相结合的新的玉米籽粒品种识别模型L-SE-VGG。该模型对5个玉米品种籽粒图像的平均识别准确率和精确率分别为99.54%和99.09%,在登海605和16DX531这2个品种上的准确率均达到了100%,除小金黄这一品种之外其他4个品种的精确率均为100%。与对比试验中未预训练VGG、迁移学习VGG以及不加SE模块的L-VGG模型相比,L-SE-VGG在各项评价指标上都具有很明显的优势。
L-SE-VGG能够为玉米籽粒品种的识别提供更先进的技术方案,为进一步实现简单高效、精确无损的玉米籽粒品种识别提供参考。在今后的工作进程中,准备采集更多品种的玉米籽粒图像来进一步丰富现有的数据集,并对拍摄背景进行改进,不再局限于黑色植绒布料,采集背景更加复杂多变的玉米籽粒图像,为进一步探索新的玉米籽粒品质识别算法提供数量多且品种丰富的数据基础;并将继续探索使用新的算法对模型进行创新,用目标检测算法实现玉米的定位检测与识别,将训练得到的模型部署在移动端上应用于实际场合。
猜你喜欢
现代畜牧科技(2021年4期)2021-12-05
现代畜牧科技(2021年10期)2021-11-19
北京航空航天大学学报(2021年9期)2021-11-02
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
电子制作(2019年11期)2019-07-04
中国交通信息化(2018年5期)2018-08-21
河北农业科学(2018年2期)2018-07-26
北京航空航天大学学报(2018年1期)2018-04-20
