
改进残差网络与峰值帧的微表情识别
2024-02-28 11:45:06陈新泉王岱嵘陈新怡
重庆工商大学学报(自然科学版) 2024年1期
任 宇, 陈新泉, 王岱嵘, 陈新怡
安徽工程大学 计算机与信息学院, 安徽 芜湖 241000
1 引 言
微表情是人们内心情感通过不受控制的面部活动露出的面部表情。这种自发产生的面部表情因其不可控性而难以克制,可以将内心的情感更直观地表达出来。微表情通常发生在1/25~1/3 s内,且在幅度很小的特定面部区域运动[1]。因此在生产生活中微表情识别被广泛应用于评估情绪状态、谎言检测、商务谈判等领域[2]。
最初的微表情识别是由有经验或受过专业训练的心理学家和专业人士完成,但是由于时间表现上的压缩以及理解上的困难[3],识别效率与准确度较低。随着机器学习与深度学习等方法的发展,现有的识别方法可分为基于手工描述特征的微表情识别算法与基于深度学习的微表情识别算法[4]。目前,微表情识别步骤大致可分为预处理、特征提取、分类。
较早提出的是基于手工描述特征的微表情识别方法。局部二进制模式(Local Binary Pattern, LBP)是基于方向梯度直方图[5]算法早期提出的手工描述特征的微情识别算法。Li等[6]提出了三正交平面局部二进制模式(LBP from Three Orthogonal Planes, LBP-TOP)进行微表情识别。Huang[7]提出了时空全局部量化模式(Spatial Temporal Completed Local Quantized Pattern, STCLQP),有效地避免了LBP-TOP特征仅考虑局部外观和运动特征的局限性。Wang等提出了六交点局部二值模式(LBP with Six Intersection Points, LBP-SIP)方法[8]和平均正交平面二进制模式(LBP Mean Orthogonal Planes, LBP-MOP)方法[9]。Xu等[10]提出面部动态图(Facial Dynamics Map,FDM)方法,Liu等[11]提出计算面部肌肉运动的主方向平均光流,这两种都是基于运动信息的光流特征来进行识别。FDM通过将人脸进行定位,之后将每个微表情进行人脸对齐和剪裁,再把抽取出来的光流场进行分割,最后抽取分割出的立方体主方向。上述基于手工描述特征的微表情识别算法可以大致分为外观特征和几何特征:LBP及其衍生的方法是较为典型的外观特征方法,而利用光流特征或是动态特征则是几何特征的方法。基于这两种特征的算法,可以将微表情内在特征更加直观地表现出来,同时对一些微小的特征进行放大,从而更加容易地进行微表情识别。但是由于其方法的局限性,而导致需要大量的计算和繁琐的参数调整,同时泛化能力与鲁棒性都比较低,难以处理复杂情况下的微表情识别,降低识别准确率[12]。
随着神经网络的发展,深度学习的方法在图像分类、人脸识别、语音识别[13-14]等方向取得了巨大的突破,基于深度学习的微表情识别方法也开始逐渐被提出。Patel等[15]使用深度学习方法,利用卷积神经网络用深层特征方式对微表情特征进行提取,减少了特征信息的冗余度,再使用传统的分类方法进行表情的分类。Peng等[16]提出了双时域尺度卷积神经网络(Dual Temporal Scale Convolutional Neural Network, DTSCNN),每条流都由独立的浅网络组成,同时注入光流序列获取更高层次的特征避免过拟合问题。Khor等[17]提出了一个增强的长期递归卷积网络(Enriched Long-term Recurrent Convolutional Network, ELRCN),该网络结合卷积神经网络和长短期记忆网络分别提取空间信息和时空信息。Cai等[18]将DenseNet网络用于微表情的识别,DenseNet以其独特的连接方式可以缓解常见的梯度消失的问题,从而提高了准确率。对比手工描述特征的方法,深度学习的方法可以更好地专注于微表情特征的提取,从不同的角度提取视频序列的信息,最后将这些信息用于识别任务,提高了模型识别的泛化能力与鲁棒性。
以上的研究方法都是将微表情视频片段从起始帧到终止帧所有帧送入模型进行训练与识别。微表情视频序列一般包含微表情开始的起始帧(Onset frame)和结束的终止帧(Offset frame),在起始帧与终止帧中间变化最为明显的一帧称为峰值帧(Apex frame)[19]。但是除了峰值帧之外,其余帧包含了较多无用信息,而使用峰值帧进行微表情的识别可以降低无用信息的干扰。因此本文首先对峰值帧进行提取,其次将改进的残差网络ResNeXt-50[20]模型用于微表情识别,可以使结构更加简化,减少参数数量,提升了识别效率,同时使用SE模块可以更好地学习特征中的关键信息,抑制无用信息,形成用于微表情识别的SE-ResNeXt-50模型[21]。最后在CASMEⅡ微表情数据集上完成模型训练与实验,实验结果表明,本文提出的方法与其他的微表情识别方法相比,识别准确率与F1值得到提升,可以取得较好的识别效果。
2 模型结构框架
本节将介绍残差网络的残差模块与改进的残差模块、SE模块相关内容及其最后使用的整体模型结构框架。
2.1 残差模块
为了缓解在深度神经网络中增加深度带来的梯度消失问题,同时用更深更宽的网络框架提取到更加丰富的特征信息和语义信息,He等[22]在模型中加入残差模块从而提出了ResNet模型。所提出的残差模块可以定义为如式(1)所示:
xi+1=F(x,Wi)+xi
(1)
式(1)中,F(x,Wi)为网络中的残差映射;xi+1为残差模块的输出;xi为残差模块的输入。
残差模块引入了一个恒等映射,其内部的残差块使用了跳跃连接, ReLU函数作为激活函数。原本的恒等映射H(X)=X直接去拟合是一件比较困难的事,但是如果将原本H(X)=X转换成为如图1所示的H(X)=F(X)+X,当F(X)=0时就形成一个残差的恒等结构,用这种残差形式去拟合会更加容易。残差模块的加入可以避免梯度消失问题,进一步提高模型的拟合能力,减轻网络层数增加带来的影响。
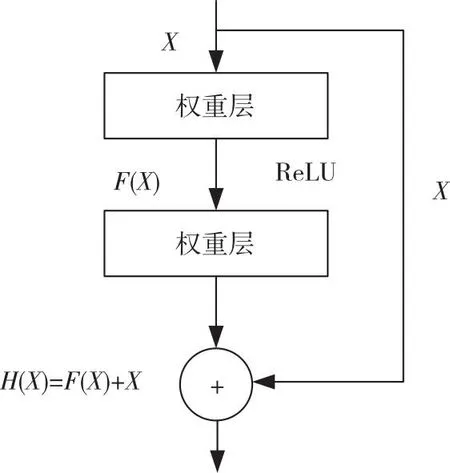
图1 残差模块结构
ResNet模型对残差模块的结构进行了优化,降低因为深层次的网络模型而带来的计算成本相对较大的大问题。将原结构中2个3×3的卷积层替换为图2(b)所示的只保留一个3×3卷积层,但是在这个3×3卷积层前后各添加一个1×1的卷积层分别进行降维操作与升维还原的操作的新结构,同时在三个卷积层中间也将使用线性整流单元作为激活函数。这种优化以后的残差结构相比较未优化的残差结构,既减少了参数量降低了计算成本也保持了模型精度。
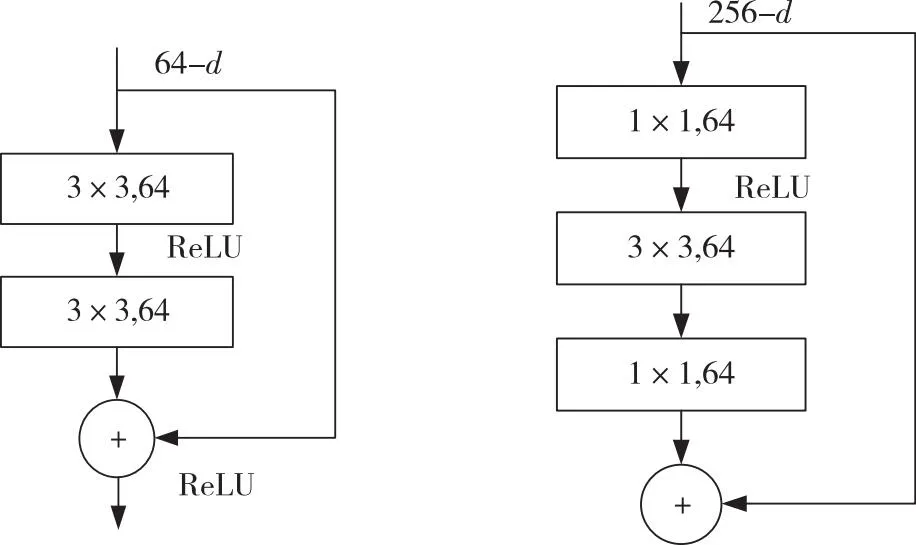
(a) 残差模块结构 (b) 优化后残差模块结构
ResNeXt模型借鉴了GoogLeNet模型[23]中提出的Inception多尺度处理模块的思想对残差模块进行了改进,将原本的卷积结构进行分组,用稀疏结构取代密集结构,这样可以融合不同尺度的信息,避免因提高模型性能而加大模型的规模所带来的过拟合与大量参数计算浪费计算资源的问题。与Inception模块不同,ResNeXt分组卷积层使用了相同结构,将原本图3(a)中的卷积层进行分组,分解成32组,形成图3(b)中的网络结构,之后再融合各个组的结果。这种使用相同分组结构的卷积层使网络设计更加的简化,从而可以避免参数的迅速膨胀。同时ResNeXt网络引入了表示残差结构中卷积层的分组数量的新超参数“Cardinality”。图3(c)所示的是分组卷积的简易表达形式,如图3(c)中使用的是分组数量为32个输入输出维度为4维的3×3卷积层。

(a) 普通模块 (b) 分组卷积 (c) 简易形式
2.2 SE模块
SE(Squeeze and Excitation)模块是一种从特征的通道维度上面考虑的注意力机制。SE模块由两部分组成,压缩(Squeeze)部分和激励(Excitation)部分,每个卷积操作实际上是在输入的空间维度和通道维度上面进行的乘加操作。SE模块的大体结构如图4所示。

图4 SE模块结构
Squeeze部分通过一个全局平均滤波实现全局信息的获取,如式(2)所示:
(2)
其中,uc为由输入X经过分离卷积U=[u1,u2,…,uC]得到的特征中第c个特征图,C为通道数;H与W是U的空间维度,Fsq(·)为压缩操作。
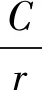
s=Fex(z,W)=σ(g(z,W))=σ(W2δ(W2z))
(3)
其中,σ为Sigmoid激活函数;δ为ReLU线性激活函数;Fex(·,W)为激励操作;W1与W2是两个全连接层参数。
Squeeze部分和Excitation部分进行完以后,之后进行scale操作。将SE模块计算出来的各通道权重值S分别和原特征图对应通道相乘,得出的结果进行输出,如公式(4)所示:
(4)

SE block可以嵌入到目前提出的所有经典的网络结构中,实现模型的改造。将SE模块加入ResNeXt模型中,如图5所示。对比原始的残差模块结构,加入了SE模块新的残差结构中为了计算每个通道权重值s,在残差结构的后面添加了一条新路径。在新的路径中为了进行每个通道中的Excitation操作,在残差模块之后加入了全局平均池化层进行Squeeze操作,在第一个全连接层中加入降维压缩操作,然后使用ReLU激活函数,之后再加入一个全连接层进行还原后使用Sigmoid激活函数,最后将每个通道的信息进行权重融合计算。把SE模块加入到残差模块后可以更好的将一些没有用的信息进行抑制,突出特征中信息量大和需要注意到的特征,从而提高模型最后的识别精度。

(a) 原始结构 (b) SE残差结构
2.3 整体模型结构框架
本文使用SE-ResNeXt-50模型,即在ResNet的改进网络模型ResNeXt上加入SE模块。整个网络由卷积层、池化层、残差模块和全连接层构成,模型结构如表1所示。

表1 SE-ResNeXt-50架构
表1展示的网络结构中,残差模块采用的是32×4分组卷积结构,括号外部参数表示残差模块重复堆叠的数量,括号内是残差模块的构建参数和结构。为了适用微表情识别的任务,将原本在原始网络架构中经过全局平均池化层输出,全连接层输出维度为5,将Softmax函数用于最后分类。同时为了更好地平衡精确度与复杂度之间的关系,将其中SE模块的降维压缩比例r值设置为16。
3 实验及结果分析
3.1 实验数据集
本文实验使用CASME Ⅱ数据集[24]。CASME Ⅱ数据集是中国科学院心理研究所创建的自发式微表情数据库。CASME Ⅱ数据集使用200 fps的高速摄像机拍摄,分辨率为280像素×340像素。该数据集收集了平均年龄在22.03岁左右亚洲人脸的微表情数据,这些表情都是在一个控制良好的实验室环境下激发出来的。CASME Ⅱ要求26个受试者观看基于厌恶、高兴、压抑、惊讶、悲伤、恐惧及其他这7种基本情感的短片进行情感诱发,最后得到共包括这些基本情感的255个微表情样本,其中包括其他类型99个样本、厌恶类型63个样本、高兴类型32个样本、惊讶类型28个样本、压抑类型27个样本、悲伤与恐惧类型分别4个和2个样本。如表2所示,在一些3分类实验中,会将数据集统一分为消极,积极,惊讶3种类型,其中厌恶、压抑、悲伤、恐惧统一归为消极样本,高兴为积极样本,惊讶保留为原有的惊讶样本。在进行5分类实验中,由于悲伤和恐惧两种类型的样本数量过少,不能更好地训练其中的特征,因此本实验仅使用其余5类共249个样本实验。

表2 CASME Ⅱ数据集分类与数量
3.2 数据集预处理
数据集的预处理包括峰值帧的提取和人脸的对齐剪裁。微表情序列是从表情的起始帧开始,到达具有最大面部信息的峰值帧,最后在终止帧结束。峰值帧的提取使用的是Quang等[25]提出的峰值帧查找算法。该算法使用开源工具包根据面部68个特征点,定位10个微表情肌肉移动发生频繁的区域。如图6所示。

图6 定位点与特征区域
为了确定序列中的峰值帧,计算当前帧与在这10个区域中的起始帧和偏移帧之间的绝对像素差。
同时将两个差值的和除以所考虑的帧与其连续帧之间的差值进行归一化,从而减少环境噪声。之后可以得到微表情序列中每一帧的每像素平均值Mi,Mi如式(5)、式(6)所示:
(5)
Mi=f(framei,frameoneset)+f(framei,frameoffset)
(6)
最后遍历计算对应帧的变化强度Mi,取值最大的一帧作为Apex帧。将峰值帧提取出之后,对峰值帧进行对齐裁剪,同样使用开源的工具包对人脸68个关键特征点检测并进行标注,最后裁剪掉没有意义的背景部分,去掉背景的干扰信息,通过人脸对齐裁剪后使之更符合微表情识别的需求,如图7所示。

(a) 原始峰值帧
3.3 数据增强
数据增强可以运用在深度学习的各个领域。当进行实验时出现数据量较小的问题,可以使用数据增强来增加样本的数量,让模型泛化和拟合的能力得到提高,从而增加模型的性能,同时这些变化并不会影响神经网络对特征的提取。本文使用数据增强方法包括灰度化、水平翻转、随机旋转。详细来说,灰度化就是将彩色图片变为灰度图片,随机旋转是将图片在15°内的小角度之间随机旋转,水平翻转是指将图片翻转为镜像图片。
3.4 实验设置
为了验证SE-ResNeXt-50模型在针对峰值帧微表情识别的有效性和适用性,本实验在Windows10系统环境下,模型的训练和测试均在深度学习框架PyTorch下完成神经网络的模型搭建。实验硬件为Intel Core i7-6700HQ,内存16 GB,显卡型号为NVDIA GeForce GTX 960。实验的软件环境为Python 3.7;NVDIA CUDA框架10.1;cuDNN 7.6 库。
实验中各项设置如下:使用Adam方法;学习率设为0.000 1;训练时批处理数量为2,epoch为100,训练测试过程中损失函数为Focal Loss函数[26]。Focal Loss函数可以更好地解决图像领域数据不平衡造成的模型性能问题。
3.5 对比实验结果分析
本文采用留一交叉验证法作为微表情识别的评估方法。每次用1名受试者的微表情样本作为测试集,其余为训练集,最后将所有的测试结果合并作为最终的实验结果[27]。这样有利于在小样本的微表情中经行验证,可以最大程度保证训练和评估模型的客观性不受个体影响。
通过准确率(Accuracy)和F1值作为评估模型识别效果的指标,并与其他算法的结果进行对比。准确率和F1值可以公平地客观地评估模型在微表情识别中的表现。
准确率如式(7)所示:
(7)
其中,N为样本的总数量;T为样本中预测正确的数量。
F1值使用的是未加权F1值。未加权F1值在多分类评估中是一个很好的评判标准,它不会受类别数量所影响,对于每个类别都平等对待。F1值如式(8)所示:
(8)
其中,TPk、FPk、FNk分别为类别k中真正、假正和假负的数量,对K个类别的比值求平均得到未加权F1值。
使用本文提出的网络结构SE-ResNeXt-50模型,在CASME Ⅱ数据集中得到的峰值帧上进行5分类实验。得到的准确率与未加权F1值如表3所示,对比其他几种微表情识别的算法在CASME II数据集上进行5分类实验的实验结果,可以发现本文提出的网络结构实验结果要优于其他现有方法。
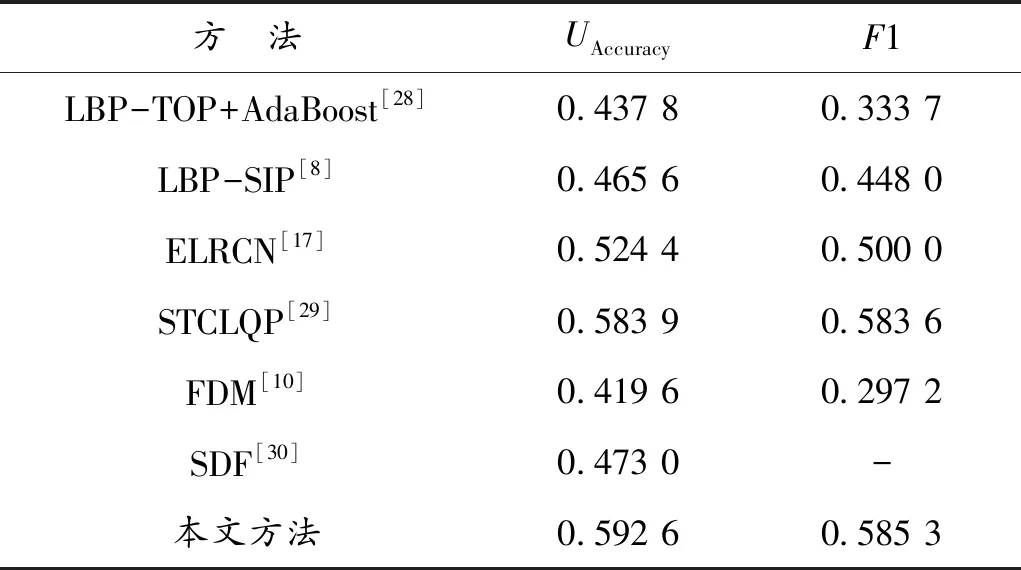
表3 结果比较
本文模型基于改进的残差网络并将注意力机制运用到改进的残差网络中,使用含有更多面部信息的峰值帧。将峰值帧的特征赋以不同权重,突出重要信息,抑制无用信息,同时由于ResNeXt-50本身的特性,由稀疏结构代替密集结构,避免了大量参数计算的问题,更好地融合不同尺度的信息。使用Focal Loss函数作为损失函数,将较难分类的样本较大的权重,使得模型在面对较难的样本时,可以更好地对较难样本的特征进行提取,从而在进行类似于微表情分类这种数据集较少且分布不平衡的训练任务时,降低因数据集的问题带来的影响。由表3可以看出,在5分类实验中,各个方法的准确率都是相对较低,说明微表情本身细微的表情变化和微表情数据集数据的不平衡给识别工作带来了一定的影响,并且未加权F1值也同样处于较低的水平,说明现有的微表情识别方法在不同类别上的表现差异相对较大。使用本文提出的方法,准确率达到了0.592 6,未加权F1值也达到了0.585 3,在所有展示方法中实验效果最好,同时也说明本文方法改善了在不同类别上的表现差异较大的问题。实验结果说明本文提出的微表情识别方法具有较好的效果,对于样本数据较少的问题也有着良好的拟合效果,数据不平衡问题也在一定程度上得到了解决。
3.6 消融实验结果分析
3.6.1 验证SE-ResNeXt-50的有效性
为了进一步验证SE模块与改进的残差网络ResNeXt-50在实验中的性能与有效性,在数据集上进行消融实验。这里进行3组实验,分别是不使用SE模块只使用初始的ResNet-50进行时实验;不使用SE模块只使用改进的残差网络ResNeXt-50进行实验;使用本文提出的同时使用SE模块和改进的残差网络SE-ResNeXt-50进行实验。
不同方法在CASME Ⅱ数据集上的精确度与未加权F1值实验结果对比如图8所示。由图8中的信息可以知道,使用SE模块和改进的残差网络SE-ResNeXt-50进行实验比不使用SE模块只使用初始的ResNet-50进行实验准确率提升0.111 2;比不使用SE模块只使用改进的残差网络ResNeXt-50进行实验的准确率提升了0.037 0。对于未加权F1值,本文提出的方法较另外两种方法分别提升了0.079 4和0.125 4。实验结果表明同时使用改进的残差网络和SE模块要比单独使用或者不使用的准确率与F1的实验结果要有所提升。通过使用改进的残差网络可以较好地提高微表情识别的性能与精度。此外由于SE模块的加入,模型可以更好地学习峰值帧的中的关键信息,进一步地提高模型的识别准确度。改进的残差网络SE-ResNeXt-50通过将SE模块与ResNeXt-50相结合,用分组卷积的方式可以在不明显增加参数的情况下提升准确率,进而使网络结构也更加的简单,进一步利用注意力机制关注更有用更需要学习的信息,使得准确率得到提升,通过实验验证了其有效性。

图8 不同网络结构对比
3.6.2 验证峰值帧的有效性
为了进一步验证峰值帧在实验中的性能与有效性,在数据集上进行消融实验。进行两组实验,分别是使用峰值帧对网络进行训练和不使用峰值帧对网络进行训练,其中非峰值帧的选取方式为初始帧到峰值帧中间的一帧。对于不使用峰值帧的实验,也使用上一节实验所使用的实验方式,进行3组对比实验,即不使用SE模块只使用初始的ResNet-50进行时实验;不使用SE模块只使用改进的残差网络ResNeXt-50进行实验;使用本文提出的同时使用SE模块和改进的残差网络SE-ResNeXt-50进行实验。通过不同的组合实验,综合多种原因对比峰值帧的有效性,使实验的结果更加客观。
如表4所示,展示了是否使用峰值帧的实验结果对比。从表中可以看出使用峰值帧的实验结果要好于未使用峰值帧的实验结果。使用本文提出的方法,采用峰值帧的准确率与F1值比不采用峰值帧分别提升了0.071与0.084。使用ResNet-50与ResNeXt-50的方法,采用峰值帧的准确率与F1值比不采用峰值帧也有所提升。实验结果证实了峰值帧可以提升微表情识别的准确率与F1值,对于微表情识别具有一定的有效性。使用峰值帧的实验结果提升主要是因为峰值帧包含了更多微表情识别所需要的关键表情信息,相对于其余帧这些信息更加的紧凑。同时峰值帧的无用信息也更少,可以减少无用信息对于识别的干扰,进一步帮助模型更好地学习与挖掘到识别时所需要的更深层次的信息。

表4 使用峰值帧结果比较
4 结论与展望
4.1 结论
本文提出了一种基于改进的残差网络与峰值帧的微表情识别算法。在微表情数据集CASME Ⅱ上进行了仿真实验,根据相同评价指标对比各类微表情识别方法,可以发现改进的残差网络与峰值帧的微表情识别的准确率达到0.592 6,未加权F1值达到了0.585 3。进一步进行消融实验,在不同的方法中也可以发现同时使用改进的残差网络与峰值帧相较于不使用的方法提高了准确率与F1值。改进的残差网络与峰值帧可以降低数据集较少所带来的影响,数据不平衡问题在一定程度上得到了解决,模型有着良好的拟合效果,同时改善了在不同类别上的表现差异较大的问题,提升了微表情的识别准确率,对于微表情有着更好的识别性能。
4.2 展望
本文针对微表情识别提出了一种深度学习的方法,首先提取微表情CASME Ⅱ数据集的峰值帧;对峰值帧预处理后,使用改进的残差网络ResNeXt-50,同时加入SE模块形成SE-ResNeXt-50模型,用于微表情识别。ResNeXt网络通过分组卷积的方式用稀疏结构取代密集结构从而使结构更加简化,融合不同尺度的信息,减少参数数量,提升了识别准确率;SE模块可以更好地增强有用的特征,在更好地利用这些特征时,抑制一些无用的特征,进一步提升模型的性能;使用Focal Loss函数可以更好地解决图像领域因数据不平衡而引起的模型性能问题。由于现有的微表情数据集的样本数量太少,网络无法学习到更多的信息,所以识别的效果仍有较大的提升空间。后续计划收集更多的年龄、种族跨度更大的微表情数据,优化提升模型的性能与鲁棒性,建立端到端的实用型微表情识别系统,提高其实用价值。
猜你喜欢
少先队活动(2022年9期)2022-11-23 06:55:52
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
自动化学报(2019年6期)2019-07-23 01:18:32
中国交通信息化(2018年5期)2018-08-21 03:37:40
通信电源技术(2016年6期)2016-04-20 06:21:16
通信电源技术(2016年5期)2016-03-22 01:09:44
