
联合傅里叶卷积与通道注意力的光场角度重建
2024-02-28 10:58陈晔曜蒋志迪蒋刚毅
光学精密工程 2024年3期
周 涛, 郁 梅*, 陈晔曜, 蒋志迪, 蒋刚毅
(1. 宁波大学 信息科学与工程学院,浙江 宁波 315211;2. 宁波大学科学技术学院 信息工程学院,浙江 宁波 315212)
1 引 言
区别于传统成像只能在单个方向上捕获三维空间的光线信息,光场成像技术能够同时记录场景中光线的强度和方向信息。基于光场成像的光学仪器(即光场相机)也被开发以获取更丰富的场景信息。许多光场应用也随之产生,如深度感知[1]、反射率估计[2]、视图渲染[3]、前景去遮挡[4]等技术。通过在主镜头和成像传感器之间插入微透镜阵列等光学组件,光场相机可以通过单次曝光同时采集空间信息和角度信息。但受限于传感器的尺寸,密集的空间采样会导致稀疏的角度采样,这严重阻碍了光场成像的实际应用。
为了解决这个问题,基于卷积神经网络(Convolutional Neural Network,CNN)的光场角度超分辨率算法被提出。但由于光场图像的四维 (4-Dimensions,4D)结构限制,其空间信息与角度信息高度耦合,给卷积神经网络的光场应用带来了挑战。现有的基于卷积神经网络的方法通过直接生成或者间接生成两种方式来获得密集的光场图像。
直接生成法先从稀疏光场图像中建模空间和角度信息的相关性,再沿角度维上采样重建光场。Yoon 等[5]首次用CNNs 对光场图像建模,通过邻域视图建模的方法从相邻的两个子孔径图(Sub-Aperture Image,SAI)中生成中间视图。Yeung 等[6]提出空间角度可分离卷积来代替4D卷积提取光场4D 结构信息。Wu 等[7]将极平面图像(Epipolar Plane Image,EPI)视为光场图像的基本单元,提出基于EPI 的重建网络,但因EPI本身分辨率的问题,该网络在低角度分辨率作为输入的情况表现欠佳。Wang 等[8]提出一个端到端的伪4D CNN,将二维(2-Dimensions,2D)EPIs堆叠成三维(3-Dimensions,3D)形式作为输入进行角度重建。Wang 等[9]将光场图像视为宏像素图像阵列,并设计了一种解耦机制来充分利用光场的角度信息。间接生成法大多通过生成一些中间输出,通过中间输出与输入的操作来重建光场图像。Kalantari 等[10]提出一个端到端的两阶段网络,将角度重建看作视差估计和色彩估计两部分,在生成中间输出视差图后,根据输入与视差图绘制出粗糙结果,后续进行色彩补偿。Wu等[11]通过预移位的EPIs 隐式地估计场景深度,并提出一种克服EPI 不匹配的CNN 重建网络,可实现更大视差范围下的光场重建。除此之外,Jin 等[12]提出一个能从非结构化稀疏光场输入重建出密集分布的两阶段网络。上述直接和间接方法都只能生成密集分布的光场图像,无法从稀疏分布的光场图像中重建出任意角度位置的新视图。近期,Han[13]等提出一个基于变分自编码器的间接生成网络,它能够从稀疏分布的光场输入图像中为每个参考视图生成一组非共享卷积核,通过与参考视图的卷积可以灵活地得到任意角度位置的新视图。但它与其他角度超分方法存在一样的问题,即特征提取时受限于感受野,在更大尺寸光场图像上对空间和角度信息的相关性建模不充分。
为了解决上述问题,本文提出了一个简单有效的方法来调整光场空角相关性建模时的感受野。鉴于频域上的一点能影响空域上的全局信息、频域的全局信息与空间上局部信息存在相关性,基于快速傅里叶卷积[14]提出了一个密集快速傅里叶卷积残差(Dence Fast Fourier Convolutions Residual,DFFCR)块来更有效地建模光场的空间和角度相关性。该模块分别在频域和空域上进行了卷积操作,以提取场景的全局和局部信息。同时,通过引入基于全局响应归一化(Global Response Normalization,GRN)[15]的通道注意块,能够将全局信息与局部信息进行通道级融合,更有效地利用光场图像的空间和角度信息。其次,提出了一种视点加权的间接合成(Viewpoint Weighting Indirect View Synthesis,VWIVS)块,该块能结合多个参考视图以生成最终结果。为每个参考视图生成置信图,并根据置信图来决定每个参考视图生成结果的权重。将每个参考视图生成结果进行融合后,得到最终输出。这一策略能够保留更多的细节信息,增强生成结果的可视化效果。
2 原 理
基于双平面光场参数化模型[16],光场图像通常表示为一个4D 函数L(u,v,s,t)∈RU×V×S×T,其中U和V表示角度维度,S和T表示空间维度,在 角 度 位 置 (u,v) 上 的 SAI 表 示 为I(u,v)(s,t)∈RS×T,与自然2D 图像具有相似的风格。
本文旨在从稀疏分布的参考子孔径图重建出新角度位置上的SAI,使其尽可能接近真值。即给定输入参考子孔径图Lref和目标角度位置ptar,该问题可以表示为:
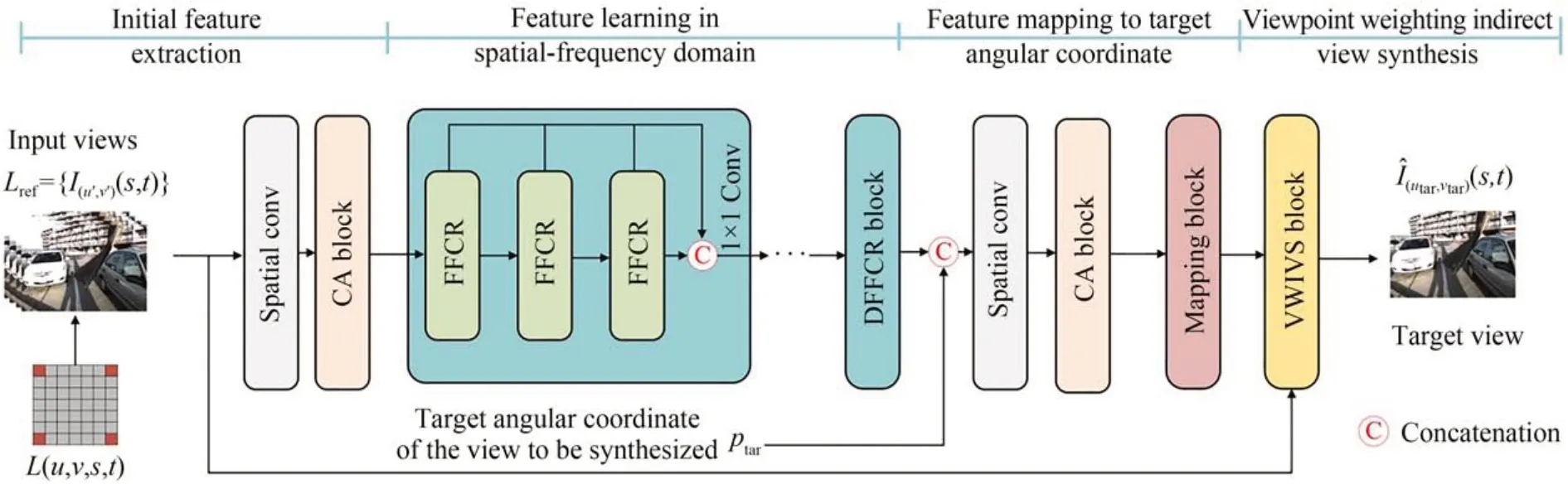
图1 联合傅里叶卷积与通道注意力的光场重建方法的总体框图Fig.1 Framework of light field reconstruction method with joint Fourier convolution and channel attention
图1 为所提方法的整体框架。重建过程主要包括初始特征提取模块、空频域特征学习模块、目标角度位置特征映射模块和视点加权的间接视图合成模块4 个模块。首先,利用初始特征提取模块结合通道注意块初步提取参考子孔径图的空间信息。之后结合空域和频域上的卷积对参考子孔径图的空间和角度信息进行融合。结合目标角度位置后,将融合后的特征映射至目标角度位置,利用带有目标角度信息的特征通过映射模块为每个参考子孔径图的每个像素生成非共享卷积核,最后用该卷积核和参考子孔径图间接合成高质量且细节丰富的目标角度位置子孔径图。
2.1 初始特征提取
首先,使用由少量3×3 卷积加上激活层构成的Spatial Conv 块将参考子孔径图映射至特征维度,如图2(a)所示。为了在空间维度上更好地融合参考子孔径图之间的信息,结合基于GRN 的通道注意块进一步融合参考子孔径图间的信息,以便在不产生额外参数的情况下增加通道间的对比和选择性,如图2(b)所示。其中,使用K个级联的ConvNeXt v2[15]块来实现对参考子孔径图在特征域中的信息融合。初步提取的特征表示为F∈RC×S×T,其中C表示通道维度。
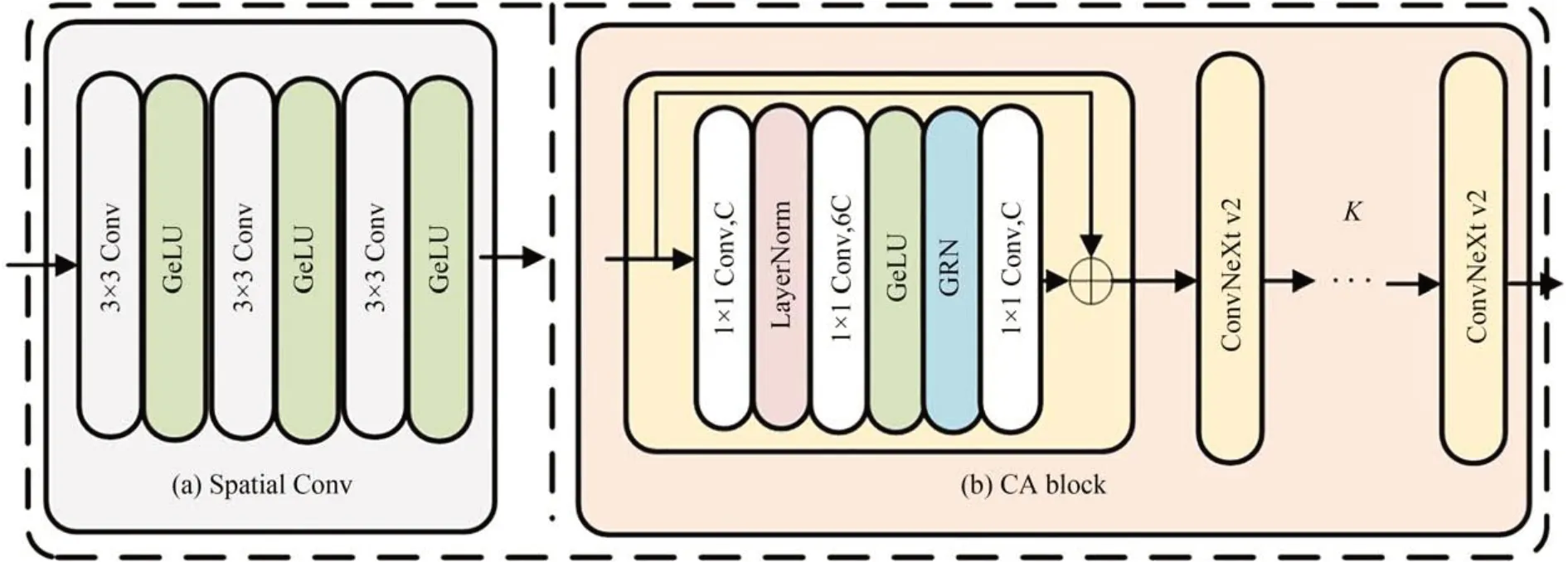
图2 初始特征提取模块示意图Fig.2 Schematic diagram of initial feature extraction module
2.2 空频域特征学习
为整合多级特征学习与傅里叶卷积,设计了DFFCR 块以提取子孔径图间的空域和频域信息。如图1 所示,每个DFFCR 块由3 个级联的快速傅里叶卷积残差(Fast Fourier Convolutions Residual,FFCR)块和一个1×1 卷积块组成,前两个FFCR 块的输出会拼接至最后一个FFCR 块,并通过1×1 卷积块进行融合。假定表示第s个DFFCR 块内的第l个FFCR 的输出,那么第s个DFFCR 块的输出可以表示为:
如图3 所示,每个FFCR 块包含两个快速傅里叶卷积(Fast Fourier Convolution,FFC)块。FFC 块是基于通道级的快速傅里叶变换,它将输入特征沿着通道维度划分为局部和全局两个部分分别进行处理。局部分支使用普通的卷积来捕获局部特征;全局分支则利用一个频域变换块,在频域上考虑图像的全局结构并提取非局部信息。最终两个分支的输出堆叠在一起进行输出。频域变换块使用傅里叶卷积单元来提取全局信息。傅里叶卷积单元中主要使用Real FFT2d 将输入从空域变换至频域中,然后在频域上进行卷积操作,最后使用Inverse FFT2d 将特征恢复至空域。
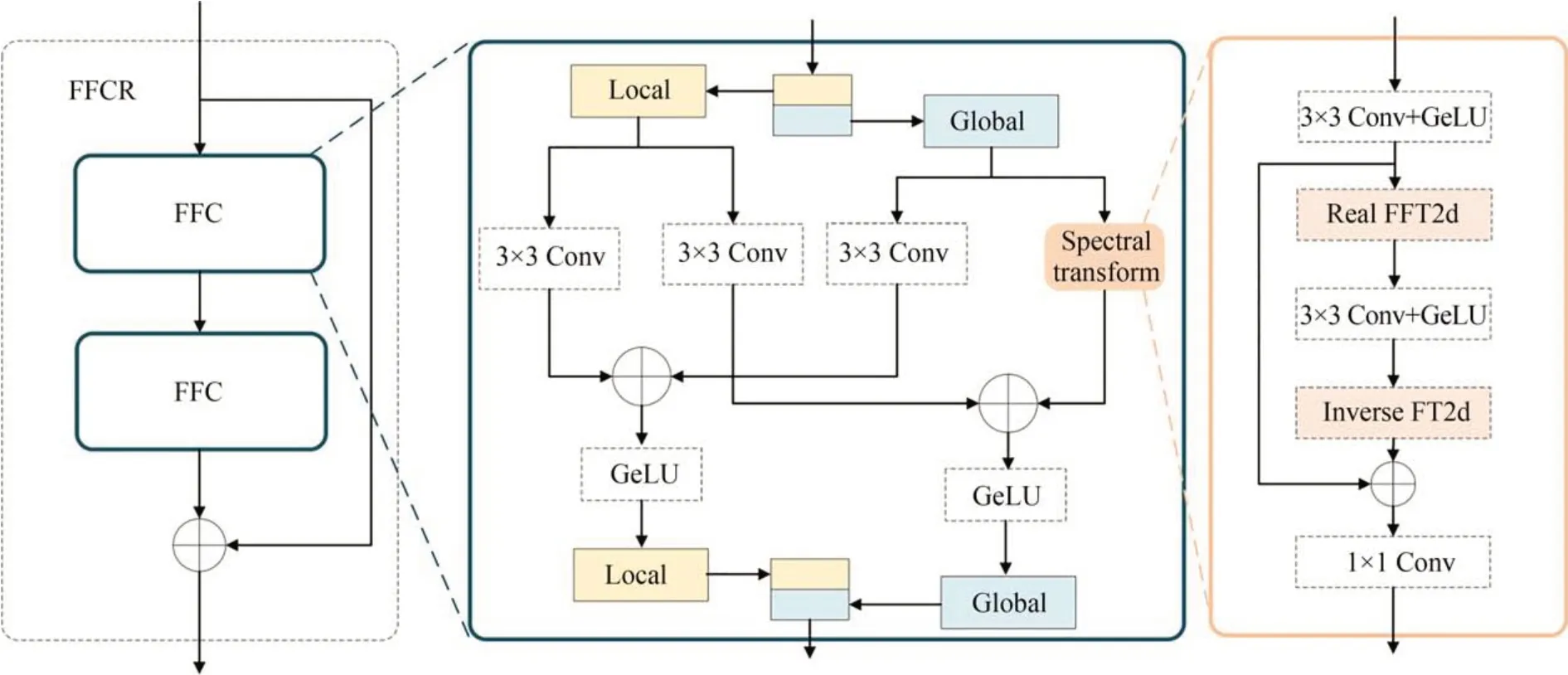
图3 快速傅里叶卷积残差块示意图Fig.3 Schematic diagram of FFCR block
2.3 目标角度位置特征映射
经过空频域特征学习后的输出特征只是对输入的参考子孔径图的空间和方向信息建模,还需要将它映射至角度位置。因此,对于给定目标角度位置Ptar,使用一个空间卷积块卷积Wsc进行初步融合。融合角度过程可以表示为:
其中,Ffused∈RC×S×T表示初步融合角度后的输出,FDFFCR∈RC×S×T表示DFFCR 输出的特征。由于DFFCR 块和角度融合都是通道级别的,需要解决如何在模型稳定的情况下,有效地融合目标角度位置和所提取特征的问题。为此,采用一个与初始特征提取过程相同结构但不共享权重的通道注意力(Channel Attention,CA)块,稳定地融合提取特征和目标角度位置。参考现有的光场灵活角度位置重建工作[14],使用残差密度块(Residual Dense Block,RDB)[17]将输入映射至目标卷积核。
2.4 视点加权的间接视图合成
现有的光场间接视图合成方法[13]先用自适应卷积[18]得到参考子孔径图的合成结果,再用相加的方式得到最终的子孔径图。这种融合方式不能保留真实的细节。本文借鉴立体匹配研究[19],在最终融合过程中加入一个中间操作,通过置信图的方式调整参考子孔径图合成结果间的关系,以获得更真实的图像。
图4 为每个参考子孔径图自适应卷积融合的结果分配一个像素级的置信图,在最终融合的过程中通过加权每个参考子孔径图的结果,辅以全局残差得到最终的目标子孔径图。考虑到l1损失函数对异常值稳定,采用l1损失函数来最小化重建子孔径图与真值(Ground Truth,GT)之间的平均绝对误差:
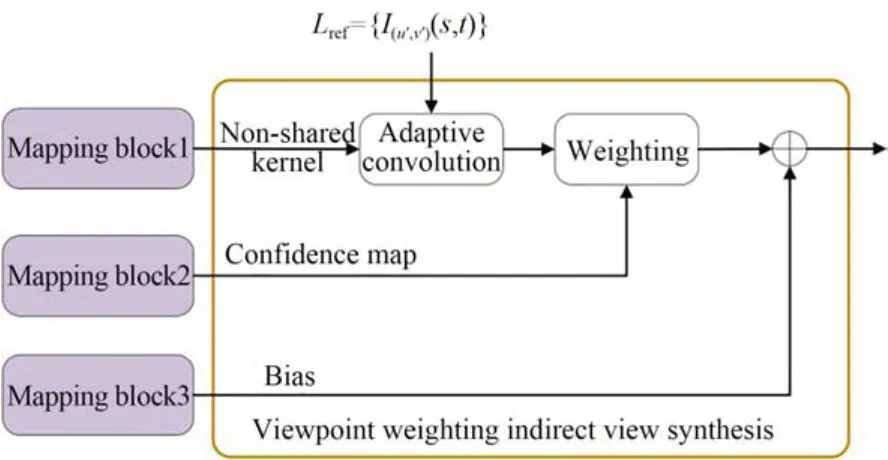
图4 视点加权的间接视图合成示意图Fig.4 Schematic of viewpoint weighting indirect view synthesis module
其中:n表示图像的像素总数,Igt代表GT 子孔径图表示网络重建的子孔径图。
3 实验结果与分析
3.1 数据集及实现细节
基于文献[9]中的策略,使用自然光场数据集30Scenes[10],STFlytro[20]进行实验。自然光场图像通常具有较小的基线,即相邻子孔径图视差较小,所有场景的光场图像的角度分辨率为14×14,空间分辨率为376×541。由于光场相机成像特性,光场图像的边缘子孔径图通常并不完整,因此,所有的光场图像都取其中心7×7 的子孔径图作为参考的高角度分辨率光场图像。对于每个光场图像,选择2×2 的角子孔径图作为输入的低角度分辨率光场图像。训练集和测试集划分如表1 所示,使用30Scenes 数据集中的100 个自然光场图像用作训练。测试集则由30 个选自30Scenes 数据集的光场图像以及STFlytro 数据集的15 个Reflective 场景和25 个Occlusion 场景的光场图像构成,训练集和测试集互不相交。在训练过程中,每个子孔径图被裁剪成64×64 的图像块。测试则使用完整子孔径图。
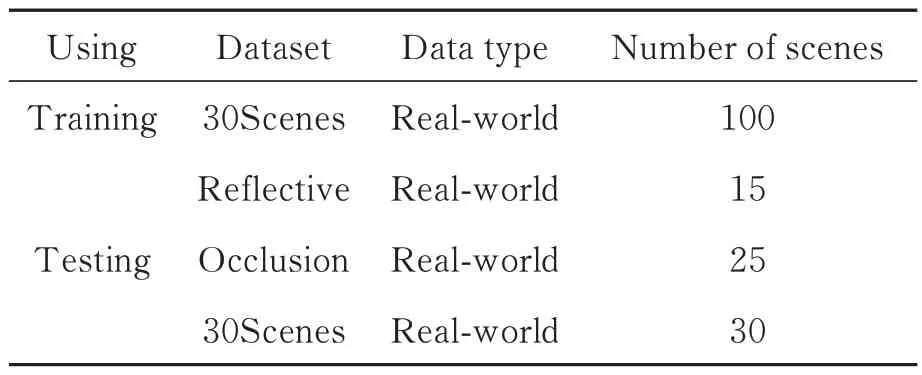
表1 实验所用训练和测试集划分Tab.1 Partition of training and testing sets in experiments
采用YCbCr 颜色空间中Y 通道的峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)和结构相似度(Structure Similarity Index Measure,SSIM)来衡量合成结果的客观质量。由于所提出的方法能够合成任意角度位置的新视图,首先计算所有位置的合成结果(即由光场图像2×2 边角位置的SAIs 生成的7×7 共45 个新视图)的PSNR 和SSIM,然后取其平均值作为该光场图像的客观结果。此外,数据集的PSNR 和SSIM 是所有光场图像结果的平均值。
所有实验基于Pytorch 深度学习框架完成,实验环境配置为24 vCPU Intel(R) Xeon(R)Platinum 8255C CPU @ 2.50GHz,两张RTX 3090(24GB)显卡。采用Adam 算法作为优化器,初始学习率设置为0.000 2,并采用周期为60ep-och 的余弦退火优化策略。训练和测试过程与文献[14]一致。
3.2 与现有方法在基准数据集上的比较
为验证所提方法的有效性,采用ShearedEPI[11],Yeung[6],LFASR-geo[21],FS-GAF[12],DistgASR[9]和IRVAE[13]等进行对比实验。其中,IRVAE 和所提方法均为灵活角度位置的重建方法。公平起见,所有方法都是在相同的数据集上进行训练。表2 给出了对比实验结果,其中最好的性能指标用粗体标记。
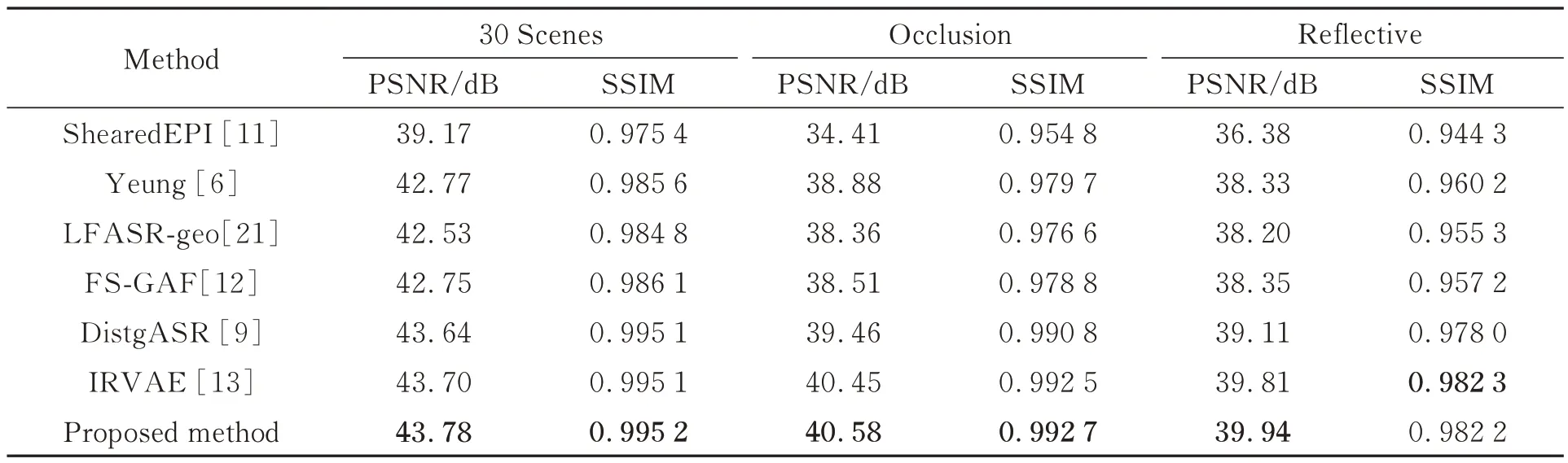
表2 不同光场角度重建方法在2×2→7×7 任务上的PSNR 和SSIM 值Tab.2 PSNR and SSIM of different light field angular reconstruction methods on task of 2×2→7×7
由于稀疏光场图像的EPI 仅包含2 个像素行或像素列,很难重建光场图像中间的线性结构,因此如表2 所示,基于EPI 的方法[11]性能不如其他方法。相比之下,基于深度估计的方法如LFASR-geo[21]和FS-GAF[12]取得了优于基于EPI 方法的性能。DistgASR[9]通过将光场结构解耦成4 个2D 分支进行多维信息融合直接重建缺失的视图,在真实场景上取得了比基于视差估计方法更好的性能。IRVAE[13]通过变分自编码器生成非共享卷积核间接合成任意缺失视图,取得比前两类方法更好的性能。所提出的方法通过结合光场的空频域信息学习光场的空间角度相关性以重建缺失的视图,在真实场景的所有数据集上取得了最好的性能指标。
图5 展示了不同方法重建的缺失视图的主观视觉效果,重建视图在光场图像中的角度位置如图5(a)所示。图5(a)表示30Scenes 数据集中的IMG_1554(上)和IMG_1541(下)光场图像重建视图对应角度位置的真值视图,图5(b)~5(e)给出了用不同方法重建的视图相对于真实视图的误差图,同时也给出了对应的2 处局部放大结果以及一幅EPI 图像。从误差图可以看出,所提方法相比其他方法更接近真值,能够很好地还原场景的细节结构,如IMG_1541 场景中草尖的轮廓形状。如图5 局部放大图所示,该方法可以较好地从参考视图恢复出目标视图的颜色以及纹理细节,而对比方法在这些细节处产生失真。
为了展示密集分布光场图像的重建方法与灵活位置光场图像的重建方法的差异,图6 进一步展示了DistgASR 与所提方法在数据集30 Scenes 上重建的各个SAIs 的PSNR 分布图。DistgASR 为当前性能最好的密集分布光场图像的重建方法,方格中的数字代表对应角度位置上所有场景的光场SAI 重建结果与其GT 之间的平均PSNR。由图可以看出,DistgASR 与所提方法在距离参考视图近的角度位置重建性能较好;而距离参考视图较远的位置如中心SAI,两种方法的重建性能相对略差,但也在42.7 dB 之上。所提方法的重建性能在除少数距离参考试图较近的位置外均优于DistgASR,这说明它能更好地建模光场图像的空间和角度相关性。
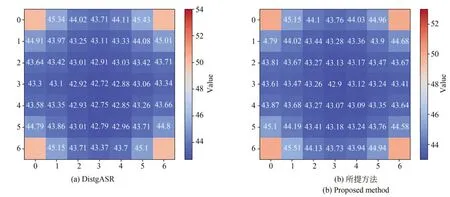
图6 2×2→7×7 任务上DistgASR [9]和所提方法在数据集30 Scenes 上重建的SAIs 的PSNR 分布Fig.6 PSNR distribution of SAIs achieved by DistgASR[9] and proposed method on 30 Scenes dataset on task of 2×2→7×7
3.3 消融实验
选择性地从所提方法中删除DFFCR,CAB和VWIVS 块,以验证各个块的有效性。表3 为消融实验结果。如表3 所示,对于前二者而言,缺少其中任意一个均会造成模型性能的下降,这归因于DFFCR 块是通道级的,缺少CAB 块的通道级特征融合会导致光场图像特征利用不充分;也证明DFFCR 块融合空频域特征的有效性。其次,缺少VWIVS 块会导致模型在所有数据集上的性能略微下降,说明联合参考视图进行融合会带来更好的结果。此外,通过对比所提方法是否包含DFFCR 块来验证空频域信息充分结合对光场空间和角度信息建模的有效性。图7 给出了所提方法中空频域特征学习模块对重建视图的影响。这里展示了重建出的中心子孔径图的误差图以及两个局部放大图。由图可知,带有DFF-CR 块的方法相比不带DFFCR 块的方法的误差更小。
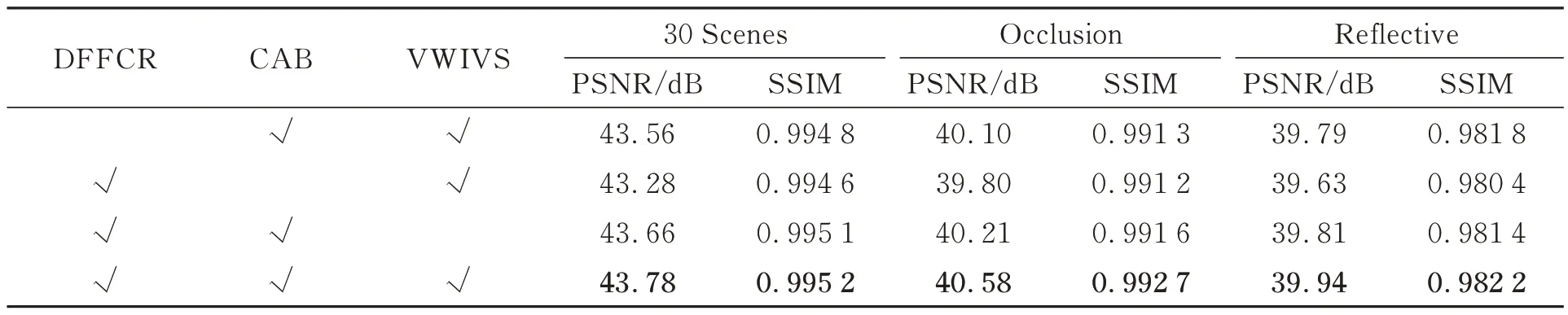
表3 所提方法在2×2→7×7 任务上的消融实验Tab.3 Ablation experiments of proposed method on task of 2×2→7×7

图7 所提方法的DFFCR 块在光场图像IMG_1743 上的有效性视觉验证Fig.7 Visual verification of validity of DFFCR block in proposed method on light field image IMG_1743
4 结 论
本文提出了一种联合傅里叶卷积和通道注意力的间接视图合成方法,通过合成任意角度位置的新视图间接进行光场角度重建。该方法包括初始特征提取、空频域特征学习、目标角度位置特征映射和视点加权的间接视图合成,获得了比一些先进方法更真实的结果和富有高频信息的结构。实验结果表明,相比IRVAE,所提方法的重建光场图像质量在自然光场数据集30Scenes,Occlusion 和Reflective 上的平均PSNR 分别提升了0.08,0.13 和0.13 dB,综合性能优于现有方法。所提出的方法在保证光场角度一致性的前提下取得了清晰的重建结果。但本文只能从固定分布的参考子孔径图重建任意角度位置的新视图,在面向灵活输入分布、灵活输入数量重建问题时无法以单模型应对。在未来的工作中,将研究有效结合空频域信息对光场图像进行更合理建模的方法,以及面向光场可伸缩编码的更灵活的光场重建方法。
猜你喜欢
舰船科学技术(2022年22期)2022-12-13
科学(2020年5期)2020-01-05
雷达学报(2018年3期)2018-07-18
中学生数理化·中考版(2017年6期)2017-11-09
非公有制企业党建(2017年10期)2017-11-03
常州工学院学报(2017年3期)2017-09-16
现代兵器(2017年4期)2017-06-02
现代兵器(2017年4期)2017-06-02
火控雷达技术(2016年1期)2016-02-06
电测与仪表(2015年3期)2015-04-09
