
网络异常检测领域概念漂移问题研究综述
2024-02-27 09:54:18杜冠瑶郭勇杰龙春赵静万巍
数据与计算发展前沿 2024年1期
杜冠瑶,郭勇杰,2,龙春*,赵静,万巍
1.中国科学院计算机网络信息中心,北京 100083
2.中国科学院大学,北京 100190
引 言
随着互联网和大数据的快速发展,网络异常检测作为保护网络安全和维护系统正常运行的手段变得越来越重要。网络异常检测往往依靠日志或流量等网络数据,而这些数据发生概念漂移会对网络异常检测的准确性和可靠性产生较为严重的影响。因此,近年来针对网络异常检测领域的概念漂移检测研究也引起了广泛关注。概念漂移是指随着时间推移,流数据的分布发生变化的情况,这种变化可能由外部或内部因素引起[1]。
网络异常检测领域常用到的数据有日志数据和流量数据等,本质上也是流数据。因此,已有的针对流数据的概念漂移检测方法也适用于网络异常检测领域。为了解决网络数据中的概念漂移问题,研究人员提出了各种检测方法[2],主要可以分为监督学习和无监督学习两大类。监督学习方法通过使用已标记的漂移样本进行训练,并通过分类器的输出来检测概念漂移。无监督学习方法不需要标记样本,它们基于数据分布的统计特性来检测概念漂移,通常使用聚类、密度估计和滑动窗口等技术来识别数据中的潜在模式变化。
尽管针对网络数据异常检测领域已经有许多概念漂移检测方法被提出,但仍然面临着一些挑战。首先,概念漂移的定义本身缺乏统一标准,不同研究者对概念漂移的理解和定义存在差异[3],这导致了不同方法之间的比较以及评估困难。其次,由于概念漂移的多样性和复杂性,单一的网络数据异常检测方法往往无法适用于所有情况[4],因此,设计具有鲁棒性和适应性的多模型融合方法是一个具有挑战性的任务。
本综述更聚焦于网络异常检测领域,旨在系统性地阐述该领域概念漂移的定义和类型、总结概念漂移的最新研究进展,并分析对比现有方法的优缺点。同时,本文将讨论概念漂移检测领域面临的机遇与挑战,并提出未来可能的研究方向。本文通过深入探讨概念漂移,可以为科研人员提供一个较为全面的视角,促进概念漂移在网络异常检测领域的发展。
本文的主要贡献如下:(1)针对当前网络异常检测领域概念漂移的定义和类型进行了系统性的阐述,并对当前网络异常检测领域概念漂移的划分标准进行了归纳和总结;(2)针对当前网络异常检测领域主流的概念漂移模型和方法进行了归纳与总结,并分析和对比各方法的优缺点;(3)针对目前网络异常检测领域中概念漂移检测所面临的问题进行了总结分析,并提出下一步研究方向。
通过以上工作,本文为网络异常检测概念漂移的研究提供了重要的理论和实践基础。本文工作不仅深入探讨了概念漂移的特征和分类方法,还为研究者提供了对现有方法较为全面的介绍和评估,从而为进一步改进和发展概念漂移异常检测算法奠定了坚实基础。
1 概念漂移概述
概念漂移现象普遍出现在各种数据集和系统中,涉及多个领域和应用场景,其对数据分析和模型应用带来了巨大的挑战。特别是在网络异常检测领域中,随着时间的推移,网络数据特征概念可能会发生漂移,从而导致现有的异常检测模型失效[5]。因此,本文旨在探索和检测网络异常检测领域中概念漂移现象,以提供更准确和更可靠的网络异常检测方法。
1.1 概念漂移定义
概念漂移(Concept Drift)是指在数据生成过程中,数据的统计特性或关系随时间发生变化的现象。然而,对于概念漂移的定义目前并不统一,存在多种观点和说法。当前被普遍认同的定义是:在机器学习和数据挖掘领域中,模型在时间或者环境改变的情况下,对于输入数据的理解和预测能力发生变化的情况。这种变化可能是由于外部环境的变化、数据生成过程的演化、观察偏差或噪声引起的[6]。因此,在概念漂移的分析中,需要考虑各种类型的数据以及潜在的漂移原因。
为了应对概念漂移,研究者提出了各种方法和技术,其中包括概念漂移检测算法[7]、在线学习方法[8]、集成学习方法[9]等。这些方法旨在识别和理解概念漂移的发生机制,并采取相应措施来保持模型的性能不下降。
1.2 概念漂移的产生原因
数据发生概念漂移的原因可能有多种:
(1)数据内部变化(Internal Data Changes)[10],例如邮件系统、社交网络中,用户的行为可能会随时间改变,导致数据分布发生变化。
(2)外部环境变化(External Environmental Changes)[11],随着时间的推移,数据生成的环境可能会发生变化,例如新的技术工具和平台的出现、过滤器的改进等。
(3)数据收集过程的变化(Changes in Data Collection Process)[12],数据的收集方式或过程发生变化,例如更换了不同的记录系统、修改了数据抽取规则等。
因此,概念漂移的产生是一个复杂的过程,受到多个内部和外部因素以及数据收集过程中各种因素的综合影响。
1.3 概念漂移的影响
概念漂移对模型造成影响主要是因为它引起了数据分布的变化,当数据分布发生变化时,模型在面对新的数据分布时可能无法有效地捕捉到新的异常模式或变化,这导致了以下几个方面的影响:
(1)模型退化(Model Degradation)
概念漂移意味着数据的统计特性和关系发生了变化。当数据分布发生变化时,模型在面对新的数据分布时可能无法捕捉到新的异常模式或变化,从而导致模型退化[13]。模型退化会使得模型的准确性下降,无法有效对新的网络数据进行异常检测和预测。
(2)决策偏差(Decision Bias)
概念漂移还可能会引起模型的决策偏差[14]。当数据分布发生变化时,模型在进行决策时可能偏向于过去的数据分布,而忽视了新的数据分布中出现的新模式和异常行为。这种决策偏差可能增加模型在各种异常检测任务中的误报和漏报现象。
(3)模型更新困难(Difficulty in Model Updating)
受概念漂移影响,模型更新变得困难[15]。当数据分布发生变化时,为了适应新的数据分布,模型需要进行更新或重新训练。然而,在在线系统或实时应用中,模型更新需要在运行过程中进行,这可能会涉及到计算资源和时间的限制。此外,如果训练数据的标签信息不完全或不准确,模型更新过程中的监督学习可能会受到困扰。
因此,及时检测概念漂移的发生,缓解概念漂移对模型的影响非常重要。
2 概念漂移分类
为了更好地解决网络数据中的概念漂移问题,需要深入了解概念漂移的不同类型。本节将分别从真伪概念漂移、漂移的速度以及漂移的空间分布3 个维度对概念漂移进行分类。通过对不同类型概念漂移的细致分类和理解,能够更好地应对网络数据中的概念漂移问题,为后续异常检测和模型更新提供更多解决途径和选择。
2.1 按概念漂移真伪性分类
在研究概念漂移领域中,一种常见的分类方法是根据真伪概念漂移对其进行划分,以更好地理解漂移的本质和影响。真伪概念漂移的分类基于网络数据中的变化是由真实的概念漂移引起还是由噪声、异常或误差等非真实因素引起[16]。
(1)伪概念漂移(Pseudo Concept Drift),指数据变化不是由数据本身变化所引起的,而可能是由于噪声、异常值、数据收集或处理错误等非真实因素所导致的。伪概念漂移可能会误导模型,并产生错误的漂移检测结果。
(2)真实概念漂移(Real Concept Drift),指数据变化是由于数据本身实际变化所引起的,这种漂移可能是由网络外部环境的变化、用户行为的改变或系统演化等因素导致的。真实概念漂移反映了数据生成过程的实际变化,对模型的性能产生较大的影响。
图1给出基于真伪概念漂移的抽象化描述,可以看出真实概念漂移是由于目标概念本身变化而导致的数据分布变化,而伪概念漂移是由于数据采样或标注错误等因素引起的误导性数据分布变化。了解真伪概念漂移的区别可更准确地判断网络异常检测中概念漂移的源头,从而采取适当的措施来应对网络数据不同类型的漂移,确保异常检测模型的准确性和鲁棒性。

图1 基于真伪的两种概念漂移抽象化描述Fig.1 Abstract descriptions of two types of concept drift based on veracity
2.2 按漂移速度分类
概念漂移的变化方式和因素可以以不同的速度发生,这与数据的统计特性和关系的变化密切相关。这些不同类型的概念漂移由各种事件、行为、环境和因素引起,从而使得网络异常检测领域数据的统计特性和关系随时间发生变化,进而影响机器学习模型在不同时间段的准确性和适应性[17]。
(1)突变漂移(Sudden Drift)
突变漂移指的是概念在某个时间点上突然发生变化的情况,导致数据的统计特性和关系在短时间内突然改变。例如,网络异常检测中突然出现新的技术或突发事件可能导致不同类型的数据特征突然变化。
(2)渐进漂移(Gradual Drift)
渐进漂移是指数据分布的逐渐变化,主要强调变化的速度逐渐加快,可能是非线性的。例如,网络系统升级、用户群体变化、法规政策调整等因素可能导致各种类型数据特征发生偏移。
(3)渐增漂移(Incremental Drift)
渐增漂移也是指数据分布的逐渐变化,但与渐进漂移略有不同,渐增漂移变化是缓慢的、线性的,并且相对较为平缓。例如,随着时间推移,发送者可能会逐渐改变其行为策略,采用新的方法或策略,导致各种类型数据特征分布逐渐变化。
(4)复发式漂移(Seasonal Drift)
复发式漂移指的是数据的概念变化与时间的变化相关。例如,在特定的季节,如节假日季节,人们使用网络行为模式可能会发生变化,从而导致数据中对应的特征分布发生变化。
图2提供了对概念漂移按速度进行分类的4种抽象化描述,可以明显看出,突变漂移是突然且明显的数据变化,渐进漂移是渐进性的数据变化,渐增漂移是数据变化逐渐增加的趋势,复发式漂移是周期性的数据变化。虽然这4 种类型漂移发生方式和模式并不相同,但它们都代表了数据分布变化。
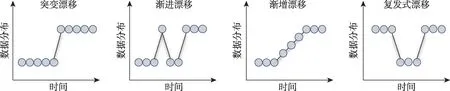
图2 基于速度的4种概念漂移抽象化描述Fig.2 Abstract descriptions of four types of concept drift based on velocity
2.3 按漂移的空间分布分类
在网络数据研究领域,对漂移空间分布进行分类是一项重要任务,可根据概念漂移完成后网络数据全局分布是否发生变化来对漂移进行划分,即局部概念漂移和全局概念漂移[18]。另外,根据漂移发生的空间特征,可以将漂移划分为连续的概念漂移和非连续概念漂移。
(1)局部漂移(Local Drift)
局部漂移仅发生在数据局部区域,而其他区域保持稳定。这种漂移模式可能由特定数据子集变化引起,例如,在在线购物平台中的局部漂移场景中,数据的局部区域可能会发生漂移,而其他区域保持稳定。
(2)全局漂移(Global Drift)
全局漂移发生在数据的整体分布上,涉及到整个数据集或大部分数据。这种漂移模式可能由整体环境的变化、数据源的更改或广泛影响的外部因素引起。例如,在一个电子商务平台上,某一时期整个平台的用户开始偏好购买环保和可持续发展的产品,而不再关注传统的大品牌商品。
(3)连续漂移(Continuous Drift)
连续漂移在空间上是连续的,即漂移发生区域之间没有明显的边界或过渡区域。这种漂移模式可能由渐进性数据变化、复发式变化或渐进的系统演化引起。例如,在一个在线气候数据收集系统中,温度数据呈现出连续漂移。随着时间的推移,数据显示温度逐渐上升,反映出气候变暖的趋势。
(4)非连续漂移(Discontinuous Drift)
非连续漂移在空间上是间断或不连续的,即漂移发生区域之间存在明显的边界或过渡区域。这种漂移模式可能由系统变更、数据源切换或特定事件发生引起的。例如,一个社交媒体平台引入了新的算法和界面设计,导致用户群体的行为发生了明显的变化。
图3展示了基于空间概念漂移的抽象描述,可以看出局部概念漂移是数据中特定区域的变化,而全局概念漂移是数据整体分布的变化。通过对漂移的空间分布进行分类,研究者可以更深入地了解漂移的发生模式,并选择合适的建模方法和策略来处理不同类型的漂移。
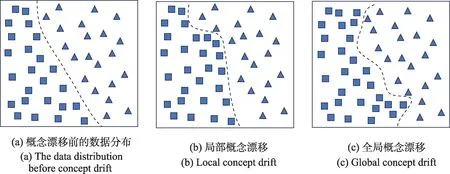
图3 基于真伪的两种概念漂移抽象化描述Fig.3 Abstract descriptions of two types of concept drift based on veracity
3 概念漂移检测方法
概念漂移是异常检测领域的重要研究方向,已经涌现出多种方法用于检测概念漂移。图4是一些常见的概念漂移检测方法总结。
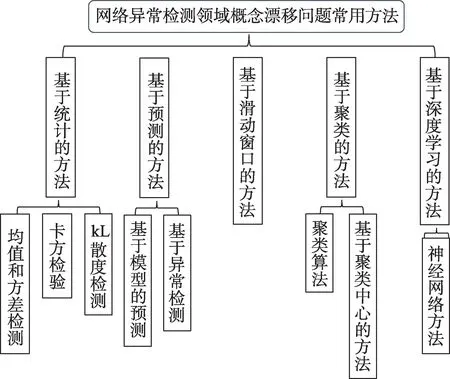
图4 常见的概念漂移检测方法总结Fig.4 Summary of common concept drift detection methods
3.1 基于统计的方法
(1)均值和方差检测(Mean and Variance Detection)
通过比较数据的均值和方差来检测数据分布的变化。Dries 等人[19]提出了3 种新的网络数据漂移检测方法,这些方法可以动态调整以匹配已有的实际数据。第一个是基于数据二进制表示的密度估计秩统计,第二个是比较1范数支持向量机(SVM)引起的线性分类器平均裕度,第三个是基于SVM分类器的平均0-1、S形或逐步线性误差率,这几种方法进行结合可以对网络异常检测数据中的多变量数据进行概念漂移检测。Liu 等人[20]在协变量漂移或偏移的情况下,使用数据分布之间的均值和方差度量数据漂移或者偏移的幅度,从而准确的估计数据样本之间是否发生概念漂移现象。Baidari 等人[21]提出了一种基于Bhattacharyya 距离的概念漂移检测方法,该方法使用均值和方差来辅助判断分布中渐变或突变型漂移。具体地,该方法通过计算连续数据窗口内均值和方差,并与先前参考窗口进行比较,来评估数据分布的变化情况。当均值和方差超过预定的阈值时,就会判定发生了概念漂移。
(2)卡方检验(Chi-Square Test)
基于卡方统计量来比较观察值和期望值之间的差异,从而检测漂移的发生。Nishida等人[22]提出了一种基于元学习的在线数据主动漂移检测(Meta-Add)框架,该框架通过跟踪错误率的变化模式来学习分类概念漂移。在训练阶段,根据各种概念漂移的错误率提取元数据,然后使用卡方检验来判断这些错误率是否存在显著的差异,从而检测概念漂移的发生。在检测阶段,通过基于流的主动学习,利用元测试器调整模型以适应不同的网络数据,从而实时监测和适应概念漂移。Liu等人[23]提出了一种基于聚类的直方图方法,称为等强度k均值空间划分(EIkMeans)用于检测概念漂移,并介绍了一种提高漂移检测灵敏度的启发式方法。在该方法中,皮尔逊卡方检验被用作统计假设检验,确保检验统计量与样本分布无关,为了实现概念漂移检测,该研究开发了3 种算法:包括贪婪质心初始化算法、聚类放大收缩算法和漂移检测算法,结果证明了EI-kMeans方法的优势,并展示了其在检测概念漂移方面的有效性。Kabir等人[24]采用了经验证明的方法DDM(漂移检测方法)的策略,并使用带有Yates 连续性校正的卡方检验来评估其统计显著性。目标是根据经验确定概念漂移,并相应地校准基础模型。实证研究表明,软件缺陷数据集中会出现概念漂移,其存在会降低预测模型的性能。在所研究的软件缺陷数据集中,使用带有Yates 连续性校正的卡方检验有效的识别了两种类型的概念漂移(渐进漂移和突然漂移)。
(3)KL散度检测(KL Divergence Detection)
通过计算两个概率分布之间的KL 散度来度量数据分布的变化。Wang等人[25]为了建立一个有效的模型,采用K-L散度来表示垃圾邮件分布,并使用多尺度漂移检测测试(MDDT)来定位其中可能的漂移,然后基于检测结果对基础分类器进行再训练,以获得性能改进。综合实验表明,当漂移发生时,K-L 散度在特征之间具有高度一致的变化模式。Hayat等人[26]提出了一种基于KL散度的自适应垃圾邮件过滤系统,该系统利用计算电子邮件内容分布的偏差来检测概念漂移。该方法可以与各种分类器结合使用,本文中采用了朴素贝叶斯分类器。通过使用安然公司的数据集进行评估,结果表明该方法在检测概念漂移方面具有有效性,并且在准确度方面优于朴素贝叶斯分类器。Goldenberg等人[27]通过调查距离测量方法在估计数字数据样本之间的漂移和偏移幅度方面的适用性,使用了KL散度来检测概念漂移,部署的机器学习系统从网络日志中学习历史数据,并在当前数据上应用,使用KL 散度作为一种距离度量,可以较好地检测出当前数据是否发生概念漂移现象。
(4)其他方法(Other Methods)
张育培等人[28]提出了一种首先综合考虑数据分布质心和半径改变引起概念的漂移,提出有效的相异度量方法,然后对网络数据采用双向统计的方法更准确地标识数据分布并映射到均匀分布序列,最后计算双重随机幂鞅的均值,并利用停时定理来判断网络数据中是否有概念漂移发生的检测方法。胡阳等人[29]提出了一种基于McDiarmid 边界的自适应加权概念漂移检测方法。该方法利用McDiarmid 不等式得到加权分类正确率的置信边界,在检测到分类正确率下降超过置信边界时调节衰减因子,实现权值的动态改变。
基于统计的概念漂移检测方法包括均值和方差检测、卡方检验、KL散度检测等。这些方法的特点是简单直观、计算高效,并且适用于各种数据类型和领域。其优势在于实时性高、独立于具体模型、相对稳定;然而,不足之处在于对假设的依赖、维度灾难和复杂分布的处理困难。
3.2 基于预测的方法
(1)基于模型的预测(Model Based Prediction)
使用建立的模型对未来数据进行预测,并比较预测结果与实际观测值,以检测漂移的发生。Masud 等人[30]通过使用基于模型的预测来检测概念漂移,并解决了网络异常检测中新类数据到达的问题,将新类检测机制集成到传统分类器中,使其能够在新类实例的真实标签到达之前自动检测新类。在概念漂移情况下,当底层数据分布在流中演变时,新类检测变得更具挑战性。为了确定实例是否属于新类,分类模型需要等待更多测试实例以发现它们之间的相似性。Masud 等人[31]使用基于模型的预测来检测概念漂移,特别关注概念进化中的循环类情况,循环类是概念进化的一个特例,即一个类在流中出现、消失一段时间后再次出现,为解决这个问题,文章提出了一种更现实的新颖类检测技术,该技术可以记住一个类,并在其长时间消失后再次出现时将其识别为“不新颖”。该方法相较于最先进的流分类技术,在分类误差方面显著降低。Saurav 等人[32]描述了一种基于递归神经网络(RNN)的时间模型,用于时间序列异常检测,以应对正常行为的突然或规则变化带来的挑战。随着新数据的可用,该模型将逐步进行训练,并且能够适应数据分布的变化。RNN 用于对时间序列进行多步预测,预测误差用于更新RNN模型以及检测异常和变化点。
(2)基于异常的检测(Anomaly Based Detection)
通过检测数据中的异常模式或异常点来间接判断是否发生概念漂移。Jain 等人[33]研究了基于分布式机器学习的集成技术,以检测网络流量中概念漂移的存在,并检测基于网络的攻击。这项工作分为3个部分。第一,随机森林和逻辑回归两个分类器被用作0级学习器,支持向量机被用作1级学习器。第二,为了处理概念漂移的过程,使用了基于滑动窗口的K-means 聚类。第三,用于检测流量中基于集成的攻击技术。实验结果表明,该方法在检测网络中的异常行为和适应概念漂移方面表现出良好的性能和鲁棒性。Qiao 等人[34]设计了机器人物联网子数据集,以确保最终完成概念漂移发生。与没有概念漂移分析的分类模型相比,检测准确率有显著提高,当概念漂移分析正在进行时,还通过比较混淆矩阵获得了优越的性能结果。文章还提出了一种基于残差投影的动态滑动窗口技术来进行概念漂移分析。在网络数据中寻找概念的过程中,通过将残差投影方法在当前窗口中获得的异常量与先前的异常量进行比较,来动态更新样本数。Yang等人[35]提出了一个名为性能加权概率平均集成(PWPAE)框架,用于异常的预测来检测概念漂移,并应用于物联网数据的异常检测。PWPAE框架通过集成多个基于异常的预测模型,利用它们的性能权重和预测概率进行漂移自适应。通过在两个公共数据集上进行实验,研究结果表明,相较于最先进的方法,文章提出的PWPAE方法在物联网数据漂移自适应异常检测方面是有效的。
(3)其他方法(Other Methods)
Klinkenberg 等人[36]提出了一种使用支持向量机(SVM)来检测周期性概念漂移的方法。作者利用SVM 模型对网络数据进行建模,并根据模型预测结果变化来检测概念漂移。这种方法可以帮助识别出重复出现的概念漂移模式。Seeliger等人[37]使用图指标来检测网络数据中的概念漂移,这些网络数据可以表示为图流。崔泽林[38]提出了一种基于密度网格数据概念漂移检测框架,该框架利用网格技术,进而使得其适用于一般数据。在解决滑动窗口中多概念问题上,在在线处理阶段中创建一个临时密度网格和一个历史密度网格,根据数据集到达时间给网格赋予一个权值扩展了DCDA 检测模型,计算临时密度网格和历史密度网格的距离检测概念漂移。
基于预测的概念漂移检测方法包括基于模型的预测和基于异常检测。基于模型的预测方法的优点是可以利用模型对新样本进行快速预测,并且可以适应各种数据类型和模型类型。然而,它的缺点是高度依赖于模型的准确性和鲁棒性。基于异常检测方法的优点是可以自动发现与历史数据分布差异较大的样本或预测错误较大的样本。然而,它的缺点是对异常检测算法的选择和参数设置要求较高,可能存在误报或漏报的风险。
3.3 基于滑动窗口的方法
(1)滑动窗口技术(Sliding Window Technology)
使用滑动窗口技术来监测数据分布的变化,例如EWMA (Exponentially Weighted Moving Average)、CUSUM (Cumulative Sum)等方法。Liu等人[39]提出了一种基于区域密度估计漂移检测方法,称为基于最近邻密度变化识别(NN-DVI),并将其应用于基于滑动窗口的概念漂移检测。该方法由3个主要组成部分组成,首先通过基于k近邻的空间划分模式(NNPS),将离散的不可测量数据实例转换为一组共享子空间,用于进行密度估计。Ross等人[40]提出了一种基于滑动窗口的概念漂移检测方法,使用指数加权移动平均(EWMA)图来监测流分类器的误分类率,该模块化的方法可以与任何底层分类器并行运行,从而提供额外的概念漂移检测层,并且该方法与许多现有的概念漂移检测方法不同,该方法允许控制假阳性检测率,并且可以随时间保持恒定,从而提供更稳定的漂移检测性能。Hoens 等人[41]系统性概述了类不平衡和概念漂移问题的挑战性,并全面回顾了近期为制定一个整体框架以解决这些问题而进行的研究。这包括探讨如何使用基于滑动窗口方法来检测概念漂移,以及如何应对类不平衡问题和非平稳环境中的学习需求。
徐清妍等人[42]针对大多数概念漂移检测算法时延高、对噪声过于敏感的问题,提出了一种基于四分位区间重叠滑动窗口的概念漂移检测方法,该方法利用四分位窗口中的样本和改进的Hoeffding不等式来检测概念漂移。为了避免噪声对分类器性能的影响,在Hoeffding 不等式中引入了基于当前样本分类精度的动态系数。朱群等人[43]提出一种新的基于双层窗口机制的网络数据分类算法,该算法采用随机决策树模型构建集成分类器,利用双层窗口机制周期性地检测滑动窗口中网络数据分布的变化,并动态地更新模型以适应概念漂移。
综合上述内容,通过使用滑动窗口技术能够实时监测网络异常检测领域数据分布发生的变化,从而及时发现概念漂移。由于滑动窗口只保留最新的一部分数据,不需要在内存中存储所有历史数据,从而降低了存储需求。这种轻量级的存储方式使得滑动窗口方法能够适应高速网络数据异常检测,并且具有较低的计算成本。然而,滑动窗口方法也存在一些限制和挑战,例如窗口大小选择对于滑动窗口方法的性能至关重要,以确保滑动窗口方法的准确性和性能。
3.4 基于聚类的方法
(1)聚类算法(Clustering Algorithm)
通过对数据进行聚类分析,监测聚类结果的变化来检测数据概念漂移。Jain 等人[44]提出了基于错误率和基于数据分布的概念漂移检测方法,并研究了它们的影响。此外,基于滑动窗口的数据捕获和漂移分析与K-Means 聚类相结合,用于减少数据大小和升级训练数据集。使用支持向量机(SVM)分类器进行异常检测,并在统计测试的基础上启动了模型的再训练。Sakamoto 等人[45]提出了一种基于聚类的概念漂移检测方法,通过结合漂移检测方法和Page Hinkley 检验,利用统计变化检测来监测网络数据中的概念漂移。该方法的独特之处在于,它允许用户对聚类结果进行注释,而无需为每个输入构建漂移检测模型。通过使用合成数据进行实验,研究者评估了该方法的检测延迟和错误检测性能,并揭示了方法参数与漂移程度之间的关系。Sousa等人[46]提出了一种基于聚类的概念漂移检测和定位集成方法,旨在适应复杂的业务流程环境并提供灵活性。该方法将两个任务集成为一个解决方案。实验结果表明,该方法可以有效地检测和定位概念漂移,通过使用合成事件日志,模拟了具有不同类型控制流变化的情况。
(2)基于聚类中心的方法(A Method Based on Cluster Centers)
比较聚类中心之间的距离或相似性来判断漂移。Fanizzi 等人[47]提出了一种基于聚类中心的方法,用于概念漂移的检测。这种方法通过使用语言无关的半距离测量,基于资源的基本语义以及与一组概念描述相关的多个维度(区分特征),为个体提供了简单但有效的特征表示。聚类算法基于概念中的medoids(即采用的半距离测量)进行分段处理,最终生成由个体群体组成的层级组织。该方法还可以应用于检测概念漂移或新颖性。Yuan等人[48]提出了一种基于聚类中心的无监督概念漂移检测算法,通过多尺度滑动窗口和k均值聚类方法来计算总平均距离,并将其作为概念漂移的检测指标。进一步,通过统计过程控制系统确定了指标阈值的范围。通过对不同维度的数据集进行实验,验证了该算法在检测渐变和突变概念漂移方面的有效性。Ren 等人[49]提出了一种名为梯度重采样集合(GRE)的集合分类器,用于处理表现出概念漂移和类别分布不均衡的网络数据。利用DBSCAN 聚类方法可以发现异常点,避免了小簇和异常值对相似性评估的干扰。只有与当前多数类集合重叠较低的少数类实例才会被选择用于对当前少数类集合进行重新采样。
基于聚类的概念漂移检测方法包括聚类算法和基于聚类中心方法。聚类算法的优点是可以适应数据分布的变化,能够发现新聚类簇或不同的数据分布。然而,它的缺点是对数据的聚类结果较为敏感,可能会受到噪声和异常值的影响。基于聚类中心方法的优点是计算简单,不受数据规模影响,对离群值和噪声较为鲁棒。然而,它的缺点是对聚类中心的选取和距离度量方法有一定要求,可能会受到聚类算法的限制。
3.5 基于深度学习的方法
(1)神经网络方法(Neural Network)
建立神经网络模型来学习数据分布,并监测网络输出的变化来检测概念漂移。Elwell 等人[50]提出了一种名为Learn++.NSE 的基于分类器集合的概念漂移增量学习方法,用于处理非平稳环境(NSE)下的网络数据。Learn++.NSE算法能够从连续批次的数据中学习,而不对漂移的性质或速率做出任何假设,适用于各种类型的漂移环境。该算法属于增量学习范畴,不需要访问以前的数据。Learn++.NSE 在接收到每个批次数据时训练一个新的分类器,并使用动态加权多数投票将这些分类器组合在一起。
Guo 等人[51]提出了一种基于选择性集成的在线自适应深度神经网络(SEOA)来解决概念漂移问题。首先,通过将浅层特征与深层特征相结合来构建自适应深度单元,并根据相邻时刻网络数据的变化自适应地控制神经网络中的信息流,从而提高了在线深度学习模型的收敛性,将不同层的自适应深度单元作为基础分类器进行集成,并根据每个分类器的损失进行动态加权,以更好地检测概念漂移。Yang 等人[52]提出了一种新的网络数据概念漂移检测方法,基于:1)在线序列极限学习机(OS-ELM)的开发和持续更新;2)量化更新后的模型被新收集的数据修改了多少。所提出的方法在两个关于不同类型概念漂移的综合案例研究中得到了验证,结果表明,与其他最先进的概念漂移检测方法相比,该方法具有优越性。
神经网络方法在概念漂移检测中具有以下优点:神经网络能够建模和学习复杂的非线性数据关系,适用于各种复杂的数据模式和问题领域。神经网络结构的灵活性使其能够适应不同的数据和任务,可以通过调整网络结构和参数来应对不同类型的概念漂移。然而,它的缺点是通常需要大量的训练数据和计算资源,训练过程较为耗时。需要调整网络结构和参数,对网络的选择和调优要求较高,并且对大量标记数据的依赖性较高,如果数据不充分或标记不准确,可能影响模型的性能。
概念漂移检测方法总结如表1所示,可以看出这些方法各有优缺点,分别适用于不同类型的数据特征和漂移情景。在实际应用中,常常需要结合多种方法或根据具体情况检测概念漂移。此外,还有一些新的方法和模型不断涌现,以应对不断变化的漂移检测需求。
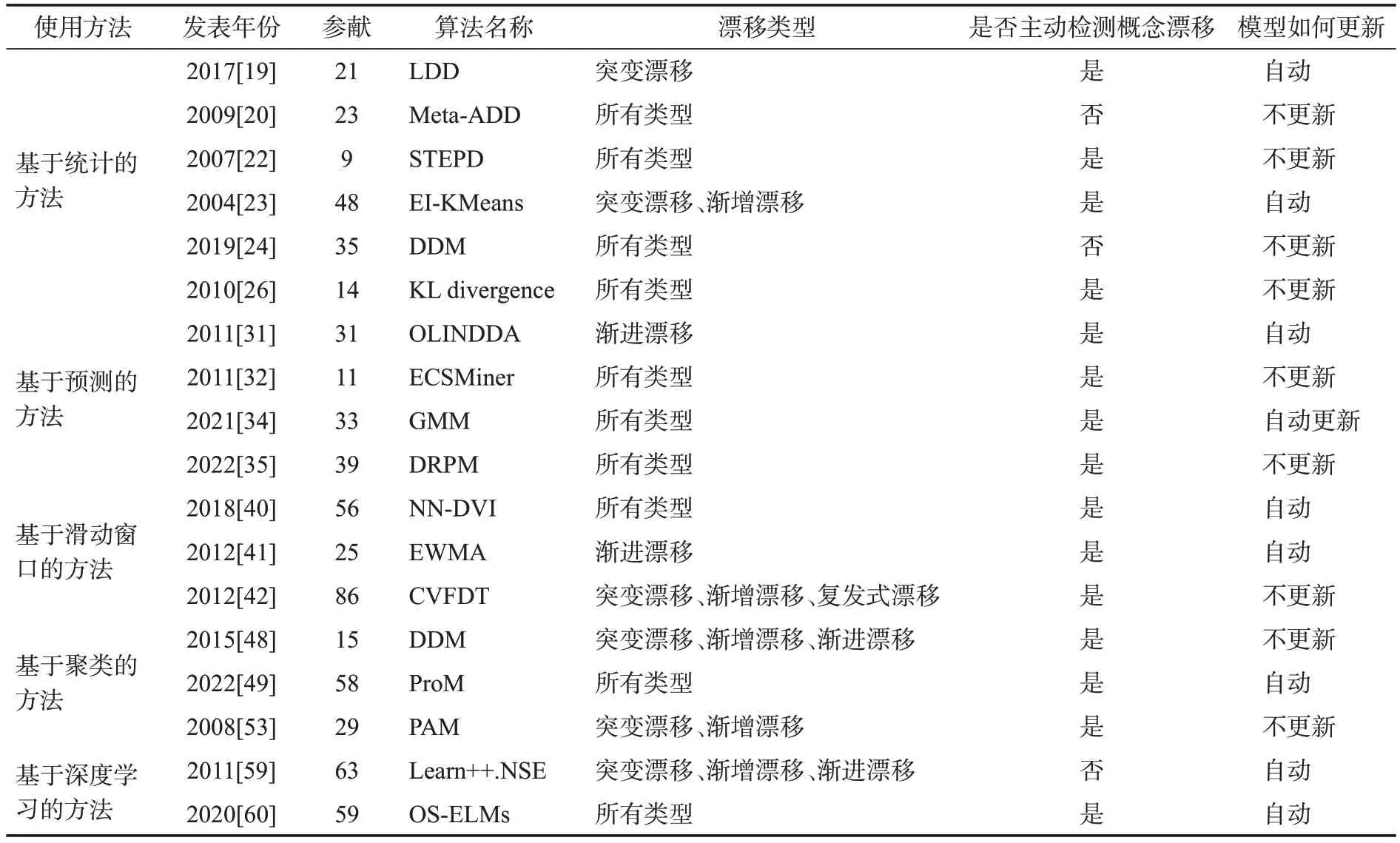
表1 概念漂移检测方法总结Table 1 Summary of concept drift detection methods
4 常用公开数据集
使用公开数据集在概念漂移检测领域变得越来越流行。公开数据集具有广泛可用性,同时可以避免真实数据中存在的隐私和伦理问题及不同领域的需求,成为概念漂移检测算法的评估基准。目前,网络异常检测领域概念漂移检测常用公开数据集如表2所示。

表2 概念漂移检测常用公开数据集Table2 Commonly Used Datasets for Concept Drift Detection
这些数据集特征多样性反映了真实世界中概念漂移的复杂性,并为解决概念漂移问题提供了丰富的实验场景。
5 如何缓解概念漂移的影响
提高网络异常检测系统的准确性和适应性可以通过减轻概念漂移的影响来实现,以下是以下常见的缓解概念漂移的方法:
(1)实例选择(Instance Selection)
实例选择方法是通过选择最具代表性和有价值的实例来缓解概念漂移对模型的影响。Gama等人[53]提出了一种使用基于实例选择的方法来抵御概念漂移的方法,其核心思想是通过控制算法的在线错误率来检测实例概率分布的变化。算法定义了警告级别和漂移级别,当一系列示例中的错误率增加到警告级别和漂移级别所定义的阈值时,就会宣布示例的分布发生了变化。在这种情况下,算法仅使用自警告级别之后的示例来学习新的模型。
(2)实例加权(Instance Weighting)
通过在训练模型时对不同的网络数据实例进行加权,以更好地适应新的数据分布。Schlimmer 等人[54]提出了一种基于实例加权的学习方法STAGGER,用于处理复杂环境下的概念漂移。该方法能够在容忍噪声和漂移的情况下学习复杂的布尔特征,并通过实验证明了其跟踪概念变化的能力。
(3)集成学习(Ensemble Learning)
通过结合多个基础模型预测结果来提高整体性能和鲁棒性。Susnjak等人[55]提出了一种用于增强系综级联的自适应学习算法,该算法旨在处理非平稳环境中的概念漂移问题,该方法的独特性体现在两个方面:第一种是在训练期间对集合的每个级联层中的各个弱分类器进行聚类并分配能力值的方式,第二种是在运行时学习最优级联层阈值想法,这使得能够快速适应动态环境变化。
(4)聚类(Clustering)
聚类方法在一定程度上可以帮助抵御概念漂移,但它们并不能完全解决概念漂移问题。Spinosa等人[56]提出了一种新颖检测方法OLINDDA,该方法将其作为连续学习场景中识别新概念的问题,作为单类分类问题的扩展。OLINDDA 使用高效的标准聚类算法在当前已知概念未解释示例中连续生成候选聚类。符合考虑凝聚力和代表性的验证标准的集群最初被确定为概念。通过合并类似的概念,OLINDDA可以在以无监督方式描述新兴概念最终目标过程中增强一些概念的表示。
(5)采样(Sampling)
采样方法可以根据具体的情况选择合适的样本,以便更好地适应网络数据中新的概念和数据分布。Yang 等人[57]提出了一种新系统CADE,旨在检测偏离现有类别漂移的样本和解释检测到漂移的原因,与传统方法(需要大量新标签来统计确定概念漂移)不同,该方法是在单个漂移样本到达时识别它们,将数据样本映射到低维空间,并自动学习距离函数来测量样本之间的相异性。
6 概念漂移检测性能评估
概念漂移检测方法的性能评估是确保其实际应用可行性的关键一步。在本节中,将探讨当前概念漂移检测性能评估的常见方法、关注点以及未来需关注的方向[58]。
6.1 当前的概念漂移检测性能评估方法
当前,衡量概念漂移检测性能的方法主要集中在几个方面[59]。其中,常见的方法包括:
(1)准确率(Accuracy):准确率是评估模型预测的正确性与总样本数量之比。它是一种直观的性能度量,但在类别不平衡的情况下可能会出现偏差。
(2)召回率(Recall):召回率衡量了模型正确识别正例的能力,对于概念漂移检测来说,高召回率意味着模型能有效捕捉到概念漂移事件。
(3)F1 Score:F1 Score是准确率和召回率的调和平均,综合考虑了两者之间的平衡。
6.2 当前概念漂移检测性能的重要关注点
在概念漂移检测性能方面,有以下重要关注点[60]:
(1)实时性:在实际应用中,模型的实时性变得至关重要。这意味着模型需要能够迅速检测到概念漂移的发生,以便及时采取必要的措施。实时性是确保模型在动态环境下保持高性能的关键因素之一。
(2)快速检测:快速检测概念漂移是与实时性密切相关的关注点。模型需要能够迅速识别概念漂移事件,以防止对系统或业务造成不必要的影响。在某些情况下,延迟甚至数秒的差异都可能对决策产生重大影响。
(3)适应性:模型的适应性是指其能够在概念漂移发生后自动调整,以适应新的数据分布。这种自适应性对于保持模型的性能至关重要,而不仅仅是在训练期间达到高准确率和召回率。
(4)可解释性:模型的可解释性是指能够解释其决策过程和预测依据。在实际应用中,决策者需要理解模型的工作原理,以便对模型的建议或决策产生信任。可解释性有助于提高模型在实际应用中的可信度,并支持决策制定。
这些关注点共同影响着概念漂移检测模型在实际应用中的性能和有效性。在选择和评估概念漂移检测方法时,综合考虑这些因素可以帮助确保模型在动态环境中表现出色,同时满足实际需求。
6.3 未来的概念漂移检测性能的研究方向
目前,概念漂移检测领域在性能方面仍存在一些挑战。在处理高维度、大规模数据集时,现有方法可能面临效率和计算资源的限制。未来的研究需要关注如何优化算法,以在实际应用中快速检测概念漂移。另外,随着数据不断演化,模型的持续适应能力也变得至关重要。研究人员需要探索增量学习、在线学习等技术,以实现模型的持续性能提升[61]。
总之,概念漂移检测的性能评估涉及多个指标和关注点,未来的研究应聚焦于优化模型的准确性、实时性、可解释性以及持续适应性,以满足实际应用的需求。
7 未来研究工作
尽管已经提出了许多方法来检测概念漂移的发生,以及降低概念漂移的影响,但现有方法中仍存在一些局限性,限制了它们在实际应用中的适用性。也为未来概念漂移的研究提供了一些可能的方向:
(1)复杂网络数据中的概念漂移检测:现实世界的网络数据通常更为复杂和动态,而现有方法大多基于简单和平稳的网络数据假设。因此,未来可以关注如何在复杂网络数据中准确检测和适应概念漂移,以应对更为复杂的数据变化情况。
(2)含概念漂移的多类不平衡网络数据分类:在实际场景中,网络异常检测数据往往存在类别不平衡情况,而概念漂移可能进一步增加类别不平衡的挑战。因此,需要研究如何在含有概念漂移和类别不平衡网络数据中进行有效的多类别异常检测,以提高模型的泛化能力和鲁棒性。
(3)多标签中类不平衡网络数据分类:某些应用中,数据实例可能涉及多个标签,并且这些标签之间也可能存在不平衡的情况。针对这种多标签、类不平衡的网络数据,如何有效处理概念漂移并准确地进行异常检测是一个具有挑战性的问题,可以进一步研究。
(4)特征演化中网络数据的新类探测:在某些场景中,随着时间推移,新的类别可能逐渐出现,这被称为特征演化。如何在特征演化网络数据中及时发现和适应新类别的出现,并准确地进行异常检测,是一个重要的研究方向。研究人员可以探索如何利用增量学习、自适应模型更新等技术来解决这一问题。
(5)检测性能的研究:虽然已经提出了多种方法来检测概念漂移,但仍需要更深入地研究这些方法的性能。未来的研究可以着重于开发评估框架和度量标准,以全面衡量不同概念漂移检测方法的性能。这包括准确性、召回率、特异性以及实时性等关键性能指标的评估。此外,还可以研究如何优化这些方法,以平衡性能和计算资源的利用,使其在大规模和高维度数据集上更加高效。检测性能的提升对于将概念漂移研究应用到实际网络异常检测中至关重要。
通过进一步研究上述挑战和问题,可以为概念漂移异常检测方法的改进和应用提供新的思路和解决方案,推动该领域的发展和广泛应用。在克服当前方法的局限性和挑战的过程中,概念漂移异常检测的性能和效果将得到进一步提升,为实际应用带来更大的价值和好处。
8 总结
本篇综述全面介绍了网络异常检测领域的概念漂移问题,着重关注了未来研究工作中的检测性能问题。首先,明确定义了概念漂移,并强调了其在数据异常检测中的至关重要性。在深入讨论概念漂移的分类和分析时,本文以多维度、全面的方式介绍了不同类型的概念漂移。在探讨概念漂移检测方法时,本文系统梳理了基于机器学习和深度学习的检测方法,包括方法原理、优劣势以及适用范围。此外,本文还深入研究了应对概念漂移的方法,其中包括监测和适应策略、模型更新以及增量学习技术等手段,以提升模型性能和鲁棒性。最后,着眼于未来的研究工作,本文提出了一系列可能的研究方向,包括复杂网络数据中的概念漂移检测、处理含漂移的多类不平衡网络数据分类、多标签中的类不平衡网络数据分类,以及特征演化网络数据中的新类别探测等。这些方向为网络异常检测领域未来的概念漂移研究提供了有力的引导,特别是在提高检测性能方面的探索。
利益冲突声明
所有作者声明不存在利益冲突关系。
猜你喜欢
数码设计(2020年16期)2020-12-08 02:12:05
电子测试(2018年1期)2018-04-18 11:52:35
电子测试(2017年15期)2017-12-18 07:19:27
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
电子技术与软件工程(2016年8期)2016-07-10 08:07:53
中兴通讯技术(2016年2期)2016-03-24 00:14:53
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
北方经贸(2014年8期)2014-09-21 20:32:16
