
SDGs科研工作台架构设计与实现
2024-02-27 09:53陈灿朴英超
数据与计算发展前沿 2024年1期
陈灿,朴英超
中国科学院计算机网络信息中心,北京 100083
引 言
联合国大会2015 年9 月25 日第70/1 号决议通过了《变革我们的世界:2030 年可持续发展议程》,提出可持续发展目标(SDGs),旨在以人类发展史上迄今最为全面和综合的方式解决人类社会面临的社会、经济和环境三个维度的发展问题,全面走向可持续发展道路[1]。可持续发展目标应对我们面临的全球挑战,包括贫困、不平等、气候变化、环境退化、和平与正义[2-4],目标涵盖经济、社会和环境这三个关键发展支柱,以及体制一致性、政策一致性和问责制等促进因素[5-8]。
联合国为《2030 年可持续发展议程》制定了衡量框架[9],包括232个指标,旨在衡量17个可持续发展目标及其相应的169 项具体目标[10-12],这将是“面向行动、全球性和普遍适用的”,因此,量化实现可持续发展目标的进展对跟踪全球可持续发展努力和指导政策制定和执行至关重要。
2018年,中国科学院启动了战略性先导科技专项(A类)“地球大数据科学工程”(CASEarth),而利用地球大数据服务SDGs是该专项的一个重大目标[1,13]。依托专项支持,2021年,发布了可持续发展大数据信息平台系统,该系统基于对象存储系统和地球大数据平台的云服务,实现SDGs数据的统一存储、管理与计算服务,以及面向公众、科研人员和决策支持3类服务场景。为了让科研人员能够更便捷和高效地使用地球大数据平台中的资源和数据进行科学研究,本文设计和研发了一个一站式SDG科研工作环境。
1 现状分析和应对策略
截至2022年6月底,地球大数据平台系统的注册用户为692 个,课题组156 个,在线云主机1,035 台,使用vCPU 超1.1 万核,内存27.1TB。然而,在该专项支持的各项目之间,对于资源的占用量和使用率都存在一定的问题,主要包括:
(1)资源占用不均衡,很多学科研究人员依然使用自有资源和较传统的研究方式进行研究,由图1 可以看出,进行学科研究的五个项目(项目三-项目七),使用云平台的资源较少,图中横轴为项目,纵轴为截至2022年6月该项目占用的云主机数量;
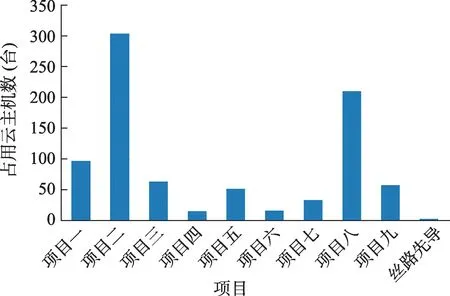
图1 资源占用情况(云主机数量-2022.06)Fig.1 Resource occupation(cloud hosts number-2022.06)
(2)资源使用率不高,各项目对已占用的CPU和内存的使用率均不高(图2),造成了一定的浪费,图中横轴为项目,纵轴为截至2022 年6月该项目占用的资源的使用率。

图2 占用资源使用情况(2022.06)Fig.2 Resource used number(2022.06)
上述两个问题出现的主要原因在于:(1)现有的云服务架构提供的是资源型服务,云服务使用者需要先在申请的资源上部署一系列基础软件,才能进行后续的科研分析工作,这导致了学科研究的五个项目直接申请使用资源较少;(2)现有的云服务架构无法对已分配的资源进行动态管理,用户在申请了资源后,即使长期闲置,系统也无法自动回收,这导致了资源的浪费。
针对上述两个问题,本文提出的解决思路是构建一个基于云原生[14]的一站式SDG 科研工作环境,使科研人员可以直接在线获取和处理数据、训练和使用模型、构建和部署应用,减轻科研人员搭建科研软件栈的工作负担,同时依托云原生的自动扩缩容能力,实现资源的均衡使用。
2 系统架构
云原生[14]技术使组织能够在现代动态环境(如公共云、私有云和混合云)中构建和运行可伸缩的应用程序。容器、服务网格、微服务、不可变基础设施和声明性api就是这种方法的例子。这些技术使松散耦合的系统具有弹性、可管理和可观察性。与强大的自动化相结合,它们允许工程师频繁地、可预测地以最小的工作量进行高影响的更改。
SDGs科研工作台构建在地球大数据科学工程基础资源之上,使用身份认证联盟系统提供的用户统一认证和API 统一认证进行用户和服务鉴权;基于构建的容器云平台和研发的基础服务,为科研服务开发者提供快速部署、全生命周期管理、动态扩缩的云服务集成服务,实现各类汇聚到地球大数据科学工程项目中的科研服务的动态集成,为最终用户提供一站式的服务快速发现、在线使用、管理等服务。在系统建设过程中,充分考虑系统的功能定位与数据资源情况,结合成熟开源产品及自主研发产品搭建进行系统的研发。面向需求,设计技术先进、逻辑一体、智能调度、安全稳定的系统架构以及开放融合的系统框架。在系统设计过程中,优先使用成熟先进技术,完善后期运维配置管理机制,建设高效、稳定的SDGs科研工作台。
SDGs 科研工作台容器云平台环境使用GlusterFS作为容器的持久化存储环境,基于Kubernetes 构建,为上层提供容器镜像、配置、编排和管理等服务;提供DevOps环境,方便开发者快速对应用进行部署,同时提供针对服务的多维度监控和日志查询收集,便于开发者管理服务;基于云原生提供数据库、搜索、消息队列等服务开发过程中必须的基础PAAS 服务;以WEB 服务形式,为最终用户提供一个包含服务注册、发现、使用等功能的平台系统。整体架构如图3所示。
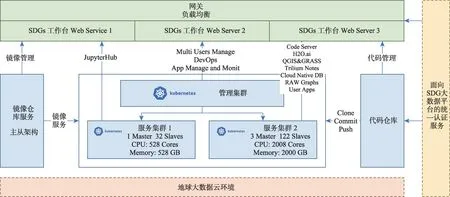
图3 SDGs科研工作台架构Fig.3 Architecture of SDGs workbench
从系统功能的层次划分出发,整体功能架构图如图4所示。
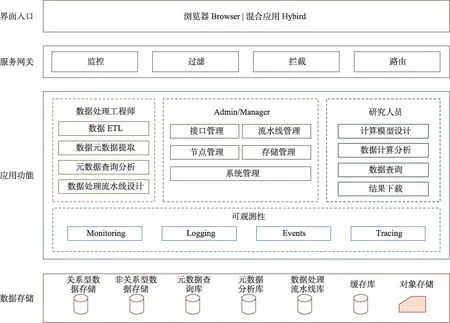
图4 系统功能架构图Fig.4 System function architecture
系统对用户相关数据、管理相关数据、各类操作事件、日志、跟踪、搜索历史进行存储,同时将相关数据加入缓存;在应用功能层面,为三类用户(应用开发者、系统管理员、普通用户)有针对性地提供不同的系统功能,同时,为三类用户提供必须的可观测性相关功能(Monitoring,Logging,Events,Tracing);在服务网关上进行监控、过滤、拦截和路由。
从系统使用的技术视角出发,整体技术架构图如图5所示。

图5 系统技术架构图Fig.5 System technical architecture
在基础设施层,Kubernetes 多集群部署在地球大数据云平台支持的多种基础设施上;系统层面,分为前后端,前后端之间使用Restful API 进行交互;系统后端包括存储、网络、安全、监控、日志、DevOps、微服务、消息、数据存储、上层服务、KS System 等多个模块;系统前端使用现代前端技术栈构建。
从业务功能角度,SDGs 科研工作台主要包括以下功能模块,如图6所示。
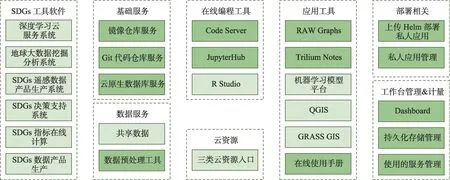
图6 系统业务功能模块Fig.6 System function module
其中,SDGs工具软件主要面向SDGs科学研究提供便捷的指标在线计算、数据产品按需生产、决策支持、数据挖掘分析和深度学习云服务系统等应用服务。基础服务部分基于基础服务子系统,提供镜像仓库、Git代码仓库和云原生数据库服务等功能。数据服务部分提供了包括共享数据模块及数据预处理工具服务。另外,SDGs 工作台根据系统需求,提供了包括云服务基础资源申请、在线编程工具环境、通用的应用工具软件及部署应用和管理计量等业务功能,力求为SDGs科研工作者提供一个一站式在线分析工具科研工作平台。
3 应用案例
SDGs研究相关科研人员可基于对象云存储系统中的共享数据资源,集成调用或在线研发模型算法,实现SDGs 指标的在线分析计算。计算分析流程可完全发生在云端,无需下载数据到个人电脑,也不需要安装配置所需的软件工具,全流程由科研人员完全在线自助实现。以SDG15.1.1 森林覆盖计算分析为例,基于共享遥感影像数据、训练样本数据,集成调用森林覆盖分类算法和基础遥感数据产品,实现研究区域森林覆盖区域的计算分析。图7 左侧为未使用工作台时科研人员进行计算分析的流程,右侧为使用工作台的计算分析流程。与传统方式相比,使用工作台开展分析计算研究具备以下优势:
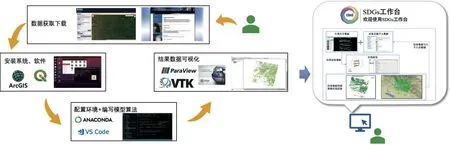
图7 应用案例Fig.7 Use case
(1)无论是遥感影像数据或是训练样本数据,都是基于RestAPI 方式调用工作台中对象存储中的共享数据和个人数据。无需通过传统方式寻找数据源自行下载数据,极大地节省了数据获取时间。
(2)通过构建Jupyterhub 容器环境进行分析计算,环境已自动配置研究相关的python 库,节约了软件和环境配置时间,通过分布式计算的方式相比单机计算方式可进一步提升计算效率。
(3)采用工作台中的团队协作方式,团队同步开展分析研究工作,并利用在线部署发布的功能将森林覆盖计算分析发布为应用服务提供给其他用户,对应用的宣传和推广具有重要意义。
4 结论与展望
基于云原生的技术架构构建SDGs科研工作台,旨在为科研人员提供一站式数据、计算、分析和应用环境。该系统的架构具备以下技术和服务优势:(1)使用同一种环境支持各类型应用的部署,无论是使用何种语言开发的应用,打包成容器后,都可以在容器云平台中运行和监控。(2)高效地利用资源。相比于原有模式,分配后的云主机无法进行复用的情况。容器云环境在发现有节点工作不饱和,会重新分配运行pod,高效利用内存、CPU等资源。(3)更高的部署效率。打包后的容器可以一键部署。(4)开箱即用的自动缩放能力。容器云环境提供了开箱即用的网络、负载均衡、复制等特性。(5)提供应用版本的滚动更新。容器云环境提供了实施智能流程和方案,使开发者和管理员可以滚动更新应用而无需停止服务。(6)更高的容错性。当容器或运行节点发生故障,容器云环境将在运行状况良好的节点上重新调度资源。(7)一站式服务发现、使用。(8)完善的服务计量:服务对资源使用量的计量、服务被使用量的多维度统计。希望通过SDGs科研工作台的建设和投入使用,能形成云服务从研发、测试、部署、版本更新到使用的应用生态,形成面向数据驱动的SDGs科研新范式。
下一步,本文将构建一个面向SDGs 的数据湖平台,其架构如图8 所示。针对SDGs 研究中的结构化、半结构化、非结构化数据,提供统一的数据存储环境,包括对象存储、关系型数据库、非关系型数据库、元数据存储查询和分析环境;基于开源和自研的针对不同数据源的数据ETL 工具对各类数据进行导入和元数据提取操作;使用大数据调度管理系统对数据处理流程进行自动化管理;面向地球大数据资源中数据量较大的遥感数据,提供遥感数据生产工具和遥感数据元数据提取工具;基于开源软件实现全部数据的元数据管理、查询和关联分析;在数据存储环境和元数据管理系统的基础上,构建统一的、包含不同类型的计算引擎环境,方便科研人员直接使用计算引擎读取数据进行各类研究工作。

图8 面向SDGs的数据湖平台Fig.8 Data lake for SDGs workbench
利益冲突声明
所有作者声明不存在利益冲突关系。
猜你喜欢
现代经济信息(2022年22期)2022-11-13
阅读(快乐英语中年级)(2022年11期)2022-05-30
今日农业(2021年19期)2021-11-27
家庭医学(下半月)(2020年3期)2020-05-30
广东公安科技(2020年4期)2020-03-17
读者·校园版(2019年24期)2019-12-10
制造技术与机床(2019年7期)2019-07-22
制造技术与机床(2019年7期)2019-07-22
制造技术与机床(2017年8期)2017-11-27
邢台学院学报(2016年4期)2016-02-28
