
机器学习在食品工业中的应用
2024-02-23 07:36:34姚仁朋孙玉敬孟瑞锋
中国食品学报 2024年1期
姚仁朋,孙玉敬*,赵 圆,孟瑞锋
(1 浙江工业大学食品科学与工程学院 杭州310014 2 内蒙古工业大学航空学院 呼和浩特 010051)
随着人口增长以及人们对健康食品的需求日益增加,食品加工中的质量安全问题越来越受到重视。食品加工是指将天然的动、植物等原料加工为食品,或将一种形式的食品加工为更适合现代人饮食习惯的其它形式的食品。据联合国粮食及农业组织(FAO)的数据显示,到2050 年,全球人口可能增长到91 亿左右[1]。为了满足日益增长的人口对多种食品的需求,将新型的技术应用于食品领域的研究必不可少。
使用人工智能机器取代人类劳动一直是科研人员研究的目标。如今,具有执行复杂任务能力的智能机器正逐渐取代人类的工作。这些机器被训练成能够通过视觉、语音识别等接受并处理信息,然后做出有用的决策[2]。人工智能领域涵盖机器学习、自然语言处理、视觉、机器人和自动驾驶车辆等。人工智能领域中,实现食品加工领域智能化的两种主要算法是机器学习(ML)和深度学习(DL)。ML 和DL 技术都已成为食品加工过程中的有效工具,包括食品分级、分类、预测、质量评价等。目前机器学习等人工智能算法和技术是国内外食品学术界和企业界关注的热点,并在短期内取得了一定的进展,而尚无相关的综述报道。本文将系统总结机器学习与深度学习模型,并详细阐述机器学习在食品领域,诸如图像识别、分级、质量检测和食品产业链中的应用,旨在为人工智能在食品工业中的应用提供理论指导。
1 机器学习的理论及方法
机器学习和人工智能的具体方法是指计算机操作系统借助获取的数据库数据得到一定的三维图,并继续借助这个三维图进行预测的方法。这种特殊的方法使用密集的训练样本来立即找出选择模式,最终获得更准确和可预测的未来数据库数据或趋势[3],其核心是借助最小二乘法对数据库中的数据进行分析,并从中学习,然后在数据库的新数据中进行决策或预测。机器学习和人工智能的具体方法分为传统的机器学习和深度神经网络,它们有可能用于更复杂的分布式系统和改进的数据统计分析。下文将重点介绍传统机器学习方法和深度学习方法的主要算法。
1.1 传统的机器学习方法
传统的机器学习涉及在小样本集上手动提取特征,以平衡学习结果的有效性和学习模型的可解释性,在有限样本的特定情况下,如何解决学习问题的结构框架[4]。传统机器学习和人工智能是指结合强化训练的具体方法,以及强化训练数据库数据是否有标签,可分为监督学习、无监督学习和强化学习。相关算法包括线性回归算法、逻辑回归算法、贝叶斯网络、K-邻近算法、K-平均算法、决策树算法、随机森林、支持向量机、降维方法等。
传统的机器学习方法通常是监督学习与无监督学习,其中监督学习方法通过对已知数据样本进行学习和训练,以预测新数据的结果[5],该方法通常应用于分类和回归问题。而无监督学习则主要应用聚类与降维,不需要对数据某些结果的影响进行分析[6]。在无监督学习中,数据虽没有标记,但会形成聚集结构,相似数据会归为一组,这些未标记数据的分组被称为聚类。而降维则是指在一定条件下将随机变量数量减少[7],它包含变量选择和特征提取两种方法。目前在食品加工行业中应用最多的机器学习方法便是监督学习与无监督学习,通过这两种方法可以提取样品的特征值,筛选出更为关键的特征变量,保持对原始数据准确和完整的描述。此外,随着技术的不断发展,一些新的更加复杂的学习方法应用到食品加工行业中,最有代表性的便是强化学习。强化学习更加强调系统与外界不断的交互反馈,它是以试错的方式来学习[8],通过与环境不断交互来获得环境的反馈(奖励),然后不断优化状态-行为的对应关系。它主要是针对流程中需要推理的场景,更多关注的是模型的性能。图2 展示了机器学习的几种主要的学习方法。
1.1.1 相关算法 线性回归算法(Linear regression):在线性回归中,其中一个变量的变化是由另一个变量的变化引起的[9]。因此,线性回归既为几个变量之间的关系,其中一个变量的增加会影响另一个变量按比例增加或减少。与之相对应的还有逻辑回归算法(Logistic regression),该算法是机器学习领域的一种技术,适用于二分类问题[10],尤其适用于需要精确输出的场景,例如预测某些事件的发生(是否会下雨)。一般情况下,逻辑回归会采用某一函数对概率值进行限制,从而输出预测事件发生与未发生的概率比例,对于二分类问题极为有效。
在食品供应链污染暴露预测中,贝叶斯网络(Bayesian network)得到了广泛的应用,该算法的运算过程基于先验信息、总体分布信息以及样本信息计算得出后验分布信息[11]。而在食品的分类任务中最常用的两种方法便是K-邻近算法(Knearest neighbors,KNN)与K-平均算法(Kmeans)。其中K-邻近算法通过确定样本最近的K个邻居来预测未知数据的分类(K 为一个小于20的整数,而且该算法中的邻居K 必须是已正确分类的对象),并将其归为相应的类别[12]。而K-平均算法是通过定义K 个中心,每个中心聚集一个类别的数据,使每个数据都属于离它最近的中心,然后将数据划分为若干个类别。
在预测一件事情发生的概率,即二分类问题中,最常用的算法则是决策树算法(Decision tree),决策树是监督学习的一种,是一种树形结构,以树的形式来表示选择和结果,用来辅助决策[13]。图3 展示了一个简易的决策树模型,树包含节点和分支,节点代表对象或选择,分支代表判断结果输出,最终分类结果表示为树的叶节点。随后在1995 年,贝尔实验室在决策树算法的基础上提出随机森林算法[14]。它可以看作是由多个决策树组合而成,并且每一个决策树之间没有相关性。在运行中,每个决策树都将独立进行决策,最后在所有的决策结果中选择一个出现次数最多的决策当作最终的选择结果。
除了上述的机器学习算法之外,还有两种较为复杂而应用非常广泛的算法。支持向量机算法(Support vector machine,SVM)是一种监督学习的分类型算法。它通过找到符合分类要求的超平面对数据进行分类,使得训练集中的样本尽可能地远离超平面[15]。算法中的超平面是对所输入变量进行划分的一个平面。在二维空间中,可以将其想象成一条直线,假设所有输入的数据都可以被超平面完全地划分开来。SVM 学习算法的目标是寻求一组系数,以便通过超平面最终获得最佳类别分割[16]。此外在实际运用中,当特征数据的量增加到某个临界点时,分类器的性能便会下降,这个问题就是“维数诅咒”。因此需要用降维方法(Dimensional reduction methods)对数据的特征进行降维。最常用的方法便是主成分分析(Principal component analysis,PCA)与线性判别分析(Linear discriminant analysis,LDA)[17]。主成分分析是一种无监督降维方法,通过在大量数据中找出数据的主要成分,找出的主要成分称为K,用来表示数据,从而达到降维的目的。而线性判别分析则是有监督的方法,可以理解为寻找一条直线在低维空间中,将高维空间的样本点投影到该直线上,确保同类样本点靠近,异类样本点远离,从而达到降维的目的。
1.2 深度学习
深度学习是机器学习的一个子集,它使用多层神经网络来提取具有多个抽象层次的复杂特征代表[18],是传统机器学习的增强方法。可以将深度学习理解为是一种由多层神经元(非线性模块)组成的深度神经网络,用来细化多级表示的一种学习方法。因为深度学习具有从原始数据中自动提取特征的强大学习能力,可以快速解决许多复杂的问题,因此近几年深度学习的应用日益增加。
深度学习算法在分类以及回归问题上表现出了强大的优势,然而该算法需要大量的精准数据作为支撑,获得一个丰富且准确的数据集可能是深度学习的一大难题。近几年,深度学习方法已经开始应用于食品科学领域,主要涉及食品类别识别、食品中的异物检测、果蔬品质检测、食品卡路里估计等领域。深度学习涉及到的主要算法有:人工神经网络(Artificial neural network,ANN)、卷积神经网络(Convolutional neural networks,CNN)、递归神经网络(Recursive neural network,RNN)、反向传播(Back-propagation,BP)、自编码器(Auto-encoder,AE)等。
1.2.1 相关算法 在食品加工的深度学习领域,应用最多的学习算法是人工神经网络及其基于该网络结构的优化算法,如反向传播网络与卷积神经网络。人工神经网络是一种结构相对简单的深度学习神经网络之一。该网络由3 层结构组成,每层包含多个节点(神经元),层间通过连接神经元来实现[19-20]。其中第1 层为输入层(用来接收外部输入的数据,并将外部世界的数据转化成图像的像素特征或者其它可以通过数学模型进行量化的特征),第2 层为隐藏层(用来处理输入层输入的数据,且隐藏层的每一个神经元只与上一层的所有神经元相连),最后一层为输出层(用来输出所获得的概率预测结果)。随后为了优化模型的性能,研究者们提出了更加高效的模型:反向传播。反向传播神经网络是一种多层前馈神经网络,通常采用误差反向传播算法进行训练。该方法计算神经网络中权重的损失函数的梯度,而后将梯度反馈给优化算法以更新权重[21]。与ANN 相比,该模型可以预设误差值,结果传到输出层后再次反向传递给输入层,达到预设的误差值时停止传播,从而达到预期效果。
在随后的研究中,食品图像的识别与分类成为研究热点,上述的两种模型性能已经明显欠缺,因此卷积神经网络随之应用到食品加工行业中。卷积神经网络具有6 个主要结构:输入层、卷积层、激活层、池化层、全连接层和输出层[22-23]。其卷积层是卷积神经网络结构中最为关键的部分,它由一组卷积内核来构建,卷积操作也是由遍布在卷积层内的卷积内核通过矩阵计算完成。经卷积层提取特征将结果输入到池化层进行二次采样,然后重复卷积操作。最后由一组完全链接的神经元组成全连接层,一般放置在池化层后,对结果进行输出。虽然CNN 模型的性能十分优益,但是该模型不能够处理数据的时间先后问题,这对于那些对出现时间要求特别高的数据(如手写体识别、菜肴制作等)是致命的缺陷。为了解决时间问题,科研工作者便提出了递归神经网络模型。该模型是通过循环连接来扩展卷积神经网络,从而处理数据的输入先后问题。一种典型的递归神经网络模型[24]如图7 所示。
随着食品数据库的不断发展,用来解决数据过多、过于复杂的模型也应用到食品加工行业中。自编码器是一种无监督学习模型,其作用与主成分分析相似,不过主成分分析处理的是线性问题,而自编码器解决的是非线性问题。输入层的神经元数量大于隐含层的神经元数量,便可以实现将数据从高维到低维的转换,然后利用低维的特征向量重构原始的数据,从而解决数据冗杂的问题。一种基于自动编码器模型的框架结构[25]如图8 所示。
2 机器学习在食品工业中的应用
食品工业是传统的劳动密集型产业,随着劳动力人口的减少,以及消费者需求的多样化,在食品产业链的整个过程实施智能化加工是必需的。智能化加工不仅满足了消费者的需求,同时生产了高质量以及相对价格较低的产品,实现了智能化从农田到生产者到销售商再到消费者的全过程。
用机器来替代人类处理一些复杂费时的事情是未来的发展方向,如今经过训练后拥有可以处理复杂任务能力的智能机器设备正在取代人工,这些机器经过训练,可以接收到视觉、语音、环境等给予的信息与反馈,并做出有用的决定。在食品工业领域,人工智能已被用作数据分析工具,用来解决食品领域的大多数挑战,例如食品分类与分级、卡路里估算、农产品、肉鱼等食品的质量检测以及食品产业链上包装检测与异物检测等领域。智能化生产不仅减少了人们的工作量和错误,而且确保了整个食品行业的最大生产效率与安全性[26]。该节主要介绍机器学习在食品工业的一些最新研究进展。
2.1 机器学习在食品识别上的应用
食品的识别与分类是帮助人们记录日常饮食的一项重要任务,由于食品图像的识别在食物质量评估以及智能厨具等领域具有重要的应用价值,目前关于食品图像识别的技术引起了大部分学者的关注。通过识别食品图像来获取食品主要特征是获取食品信息的主要手段,目前随着卷积神经网络的发展,人们用来识别和分类食品图像的方法大部分为卷积神经网络模型[27-30],这为识别食物和分析食物的营养成分提供了一种快速准确而且低成本的分析方法,已经广泛应用于食品的图像处理上。然而对于食品行业来说,食品的多样性(如食品质地、颜色、形状、成分等)也成为了图像处理的一大难题[31]。
2.1.1 食品101 数据库 常用的食品图像分类方法有机器学习方法以及深度学习方法,而传统的机器学习方法依赖于手动提取特征,会受到多种不确定因素的限制,导致很难解释食品图像的真实含义,导致分类的准确性偏低。因此为了达到更高的分类准确性,研究者开始使用深度学习方法对食品图像进行分类。食品图像识别技术的迅速发展可以追溯到2014 年Bossard 等[32]创建的食品101 数据集。随着食品101 数据库的发布,一些较大规模的食品图像基准库也不断发布,这大大推动了食品图像识别技术的发展。Bossard 等[32]使用传统的机器学习方法对食品101 数据库中的食品进行分类,实现了平均50.76%的分类准确性。该数据库包含了101 类食品,每一类食品拥有1 000种食品图像,是食品领域常用的数据集。
后来许多学者又针对101 数据库进行了一系列的基于深度学习方法的分类器训练,其中在分类任务中应用最广的评价指标是前1 名分类准确率(Top-1%)与前5 名分类准确率(Top-5%)。对于前者,分类器将输出正确概率最大的一个作为预测结果,如果预测结果中最可能的食品分类正确,则预测结果正确;对于后者,它预测最大概率结果的前5 个,只要5 个里面有1 个是正确的,就是预测正确。在先前研究的基础上,对3 个数据库(食品101 数据库、UECFood-256 数据库以及UECFood-100 数据库)上研究者所做的食品识别研究做出了归纳,如表1 所示。其中食品识别的最高准确率是Martinel 等[33]开发的一种新的卷积神经网络模型,称为WISeR,专门用于食品图像的识别,该模型在UECFood-100 数据库获得了最高的识别精度,Top-1%与Top-5%分别为89.58%与99.23%。

表1 基于CNN 的方法在3 个基准数据库上实现的性能[28-30,33,36-41]Table 1 Performances of CNN-based approaches achieved on three benchmarked databases[28-30,33,36-41]
随后,研究者将更多先进的技术应用到机器学习中,以增强模型的性能,例如Srigurulekha等[27]应用了MAX 合并技术与CNN 相结合,用于从关键图像中分离和制备模型。在该方法中,模型对FOOD-101 数据集实现了86.85%的准确度。Zhang 等[34]设计了一种具有13 层卷积层的卷积神经网络,并使用了3 种类型的数据增加方法:图像旋转、伽马校正和注入噪声。该模型与其它的水果识别模型相比,准确性达到94.94%,至少比其它最先进的模型识别准确率高5%。Xu 等[35]对亚洲食品数据集使用了Mixup 数据增强预处理,使用了3 种神经网络模型分别为:VGG-16、MobileNetV2、ResNet50,并使用CBAM(卷积块注意模块)来改进这3 种基线卷积神经网络。最终这3种卷积神经网络模型达到的最好分类精度分别为:Top-1%与Top-5%为85.15%与97.11%,Top-1%与Top-5%为86.28%与97.11%,Top-1%与Top-5%为87.33%与97.33%。他们的方法验证了CBAM 注意机制和Mixup 数据增强算法能有效的提高食品图像分类的准确性。
2.1.2 菜肴识别 与传统的食品图像相比,菜肴图像的识别更为困难,因为菜肴图像的关键特征不容易被捕捉到,而且每一种菜肴都是混合了多种食品制作而成,因此分割菜肴食品图像并找出其关键特征成为了一个难以解决的问题。目前的研究,大都致力于在不同环境下稳定的识别菜肴图像,开发移动端程序来方便用户进行食品识别。多是将菜肴图像分割成许多的小块然后利用CNN 或者性能更好的深度学习模型来提取图像特征,最后做出预测,一些性能更好的复杂网络模型可能对识别菜肴具有更良好的性能。
目前对于食品菜肴识别技术多是应用食品图像分割技术以及特征识别技术[40,42-43],然后把图像传回云端进行分析,从而识别图片的类型。Ciocca等[42]开发了一种基于CNN 的野外食品识别系统,称为IVLFood-WS,其工作示意图如图9 所示。该程序可以将使用者上传的食物图像进行分析,然后通过云端分析,最后将食物的信息反馈给用户。可以帮助用户鉴别食物以及提供其中的过敏原信息、菜肴的食品配比以及预测该食品的卡路里含量。Liu 等[43]提出了一种基于人工智能的多菜食品识别模型,该模型使用Efficient Det 深度学习模型,能够有效的识别台湾地区菜系的单菜以及混合菜,有助于人们正确的决定健康饮食的摄入量。该试验对获得的2 517 家餐厅的数据集进行训练和测试,并使用了多种食品图像数据集,最后该模型在菜肴识别的精度上达到了准确性87%与召回率97%的高准确性结果。
2.2 机器学习在食品分级上的应用
农作物的分级与分选往往关系到农产品的收成与销售,在以往的食品工业中,农作物分拣分级往往都依赖于人工。手动分拣和分级基于人工操作,这不仅繁琐、耗时而且分拣出来的产品质量不一,目前食品行业已经通过机器视觉进行分选和分级,实现了高效、一致、优秀的分选速度与准确率。目前机器视觉系统与机器学习已应用于食品工业中新鲜产品的分级、分类,检测新鲜水果和种子上的裂纹、黑斑和擦伤缺陷等领域。然而图像分析、机器学习以及机器视觉等新技术在动物产品分级以及食品工业机械自动化上的研究较少,缺乏相关的报道。
2.2.1 种子分级 粮食以及农产品的多样性是农业系统的一个重要方面,为了获得更高的作物产量和预期的产物质量,种子品种的鉴定与分级是最为关键的。农作物种子与上述菜肴所不同的是:种子质量鉴定与分级往往更加复杂,它无法像菜肴一样根据食物的表面特征就得出结论,种子的质量定级还需要评估许多内部因素,因此许多研究者将不同的成像技术与机器学习模型相结合,对农作物种子进行分级与分类[44-45]。例如,Wu 等[44]提出了一种基于高光谱成像(HSI)和深度卷积神经网络(DCNN)的燕麦种子品种识别方法。该试验开发了一种端到端学习方法训练的深度卷积神经网络,并与传统的3 种分类器(逻辑回归、径向基函数支持向量机和线性支持向量机)进行结合和比较,最终的研究结果表示,基于深度卷积神经网络的模型优于传统的分类器,在测试集上达到了99.19%的最高准确率。Nie 等[45]将近红外高光谱成像技术与深度学习相结合,用来分类杂交丝瓜种子与杂交秋葵种子。该试验采用偏最小二乘判别分析、支持向量机和深度卷积神经网络来建立判别分析模型,并将3 种模型进行比较。结果表明,深度卷积神经网络模型获得了最高的分类准确性,在测试集上,分类杂交丝瓜种子与杂交秋葵种子分别获得了95.93%与98.24%的高分类准确率,并且随着数据的增加,DCNN 模型的性能保持稳定并上升,而且解决了数据过拟合的问题。
2.2.2 水果分级 对于水果等产品分级是一个至关重要的过程,因为它极大地影响着产品到达市场时消费者的偏好和满意度。并且将果实进行分类有助于挑选出不同质量的水果并将其分级,便于后续的运输与销售。近几年随着深度学习模型的不断发展,许多应用在水果分级上的模型都取得了良好的分类精度。例如Unay 等[46]提出了一种基于二维卷积神经网络(CNN)的苹果多光谱图像分级方法。对于苹果的二类分类(即将苹果分为有缺陷和健康),该模型的分类准确性达到了95.6%;在多类分类中(将苹果分为健康、碰伤苹果、有缺陷导致拒收的苹果、有严重缺陷的苹果)的分类精度达到了87.1%。Helwan 等[47]设计了一种基于剩余学习网络(ResNet-50)的深度学习方法水果智能分级系统。该系统利用迁移学习来实现水果分级,旨在将水果,特别是香蕉分类为健康或有缺陷的类别。该模型在香蕉的二类分类中获得了99%的高准确率。
在多类分类任务中,研究者多使用一些成像技术与机器学习相结合进行分类,然而模型的性能与二分类任务相比仍然较差。例如Mesa 等[48]将香蕉分为三级并开发了一种多输入模型,给香蕉进行分级。该模型利用了RGB、高光谱成像以及深度学习技术,利用两种成像技术来提取香蕉的尺寸以及纹理等特征,然后做为学习数据输入到CNN 中实现对香蕉的分级。作者对多输入模型与仅使用RGB 或高光谱成像以及传统的机器学习方法进行了比较,最终的结果显示混合输入模型获得了最高的准确性为98.45%,同时召回率也达到97.43%。Ganguli 等[49]使用基于预先训练的ImageNet 模型的深度卷积神经网络,并使用MLP 网络来分析所提取的香蕉分类和数字信息,并将RGB 与高光谱成像技术相结合应用于该模型中,获得了更高的分类精度(98.4%)。Bhole 等[50]设计了一种以深度学习为中心的芒果无损分类和分级系统,将芒果分为三级。该模型使用了基于转移学习的预训练SqueezeNet 模型,通过识别芒果的缺陷、形状、大小和成熟度来对芒果进行分级,最后该系统的分类精度为93.33%。
目前的研究大多都是将产品质量分为二类与三级,且取得了较好的分类精度。然而在多类分类任务中,模型的准确率明显要低于二类分类,这可能是由于分类任务的复杂性导致,在质量的多类分类任务中,模型的性能有待改善。
2.3 机器学习在食品质量检测上的应用
外部质量属性与产品外观相关,包括颜色、形状、尺寸和无表面缺陷等特性。它们决定了消费者的购买行为,因为这些属性可以很容易地用眼睛检查。食品的质量是现代食品产业的一个关键因素,高质量的产品更容易在市场上取得成功。而在传统的食品工业中,产品的质量评价仍然大量的依赖人工检测,这种方法不仅费时、成本高,而且极易受到外在因素的影响。为了满足消费者日益增长的食品安全意识,研究者们已经将计算机视觉技术结合机器学习应用到食品的质量评价中。该技术可以客观、快速、无接触的对产品进行质量检测,近年来受到食品行业广泛的关注,并得到迅速的发展。
2.3.1 果蔬质量检测 果蔬中含有人体所必需的、丰富的营养物质,是人体健康饮食的重要组成部分。然而在运输、采摘、储藏等过程中,极其容易受到病虫害、外力损伤等影响,影响果蔬本身的营养价值,严重时甚至会损害消费者的健康。果蔬与其它类型的食品相比,其内在的相似性与独特性更为明显,这也为果蔬质量检测提供了更多的挑战。目前关于果蔬质量检测的研究大多都集中在农业与健康领域[24,51-55],且目前关于果蔬质量检测的研究大多采用CNN 网络模型以及其改进模型,并没有应用更复杂的模型,而且也没有将果蔬自身的特征、形态与模型结合,因此关于果蔬质量分级的研究还有较大的空间。
在检测中,对于病虫害的检测尤为重要,因为这直接关系到该产品是否可以进入市场进行销售。病虫害的检测需要一种成熟的成像技术将水果图像呈现出来,供机器对水果质量进行分级检测,最近的研究已经将机器学习与光谱技术相结合来评价水果的质量等级。例如Rahamathunnisa等[52]提出了一种蔬菜病害检测系统,用于检测蔬菜的病害。蔬菜的识别基于诸如形状、颜色、大小、质地等特征。并且系统使用了K-Means 聚类算法来对所捕获的图像进行分割,以及使用支持向量机来进行有监督的分类学习。Liu 等[53]开发了一种基于高光谱成像的黄瓜缺陷检测分类方法,该方法使用堆叠自动编码器与卷积神经网络相结合,该模型先使用CNN 扫描整个黄瓜图像,确定黄瓜的缺陷图像,然后再传输到堆叠自动编码器对黄瓜的缺陷特征进行深度学习,最后模型的准确率为91.1%。Tan 等[55]将卷积神经网络应用于红外传感器网络采集的苹果果皮病变图像的识别,旨在实现基于机器学习的苹果病虫害检测系统。作者使用了主成分分析对所采集到的苹果图像进行降维,然后用五层CNN 模型对经过处理的图像进行训练。最后与传统的多层感知器与ANN 等神经网络模型进行比较,该网络模型具有最高的分类准确性,为97.5%。
感官品质的检测也是果蔬质量检测中重要的一环,这关系到果蔬在货架上的等级分类以及消费者的购买体验。Kaur 等[51]提出了一种基于人工神经网络的图像处理技术,用来对蔬菜进行分类与质量检测。该技术首先使用相机捕捉蔬菜的图像,然后从采样图像中有效地提取特征。所提取的特征有诸如颜色、形状和大小的参数,最后采用人工神经网络技术对质量进行检测。最后作者对4种不同颜色、大小、形状的蔬菜进行分析,并且取得了良好的结果。Azizah 等[54]提出了一种使用卷积神经网络模式的深度学习模型来检测山竹的质量。为了验证数据的准确性,作者使用了四重验证交叉来运行该CNN 方法,最终的研究结果显示山竹果实的缺陷检测效率为97%。Rodriguez 等[56]使用深度学习技术研究李子品种在早期生长阶段的鉴别。作者采集了不同品种李子以及不同成熟度的李子图像来构建数据集,对采集的图像进行分割以去除不需要的背景,然后使用AlexNet 体系结构作为CNN 模型,最后模型获得的分类准确度范围为91%~97%。Zhang 等[24]总结了基于深度学习的食品和农产品定量分析,作者总结了水果以及农作物的质量分析以及所使用的光谱数据,具体分析见表2。
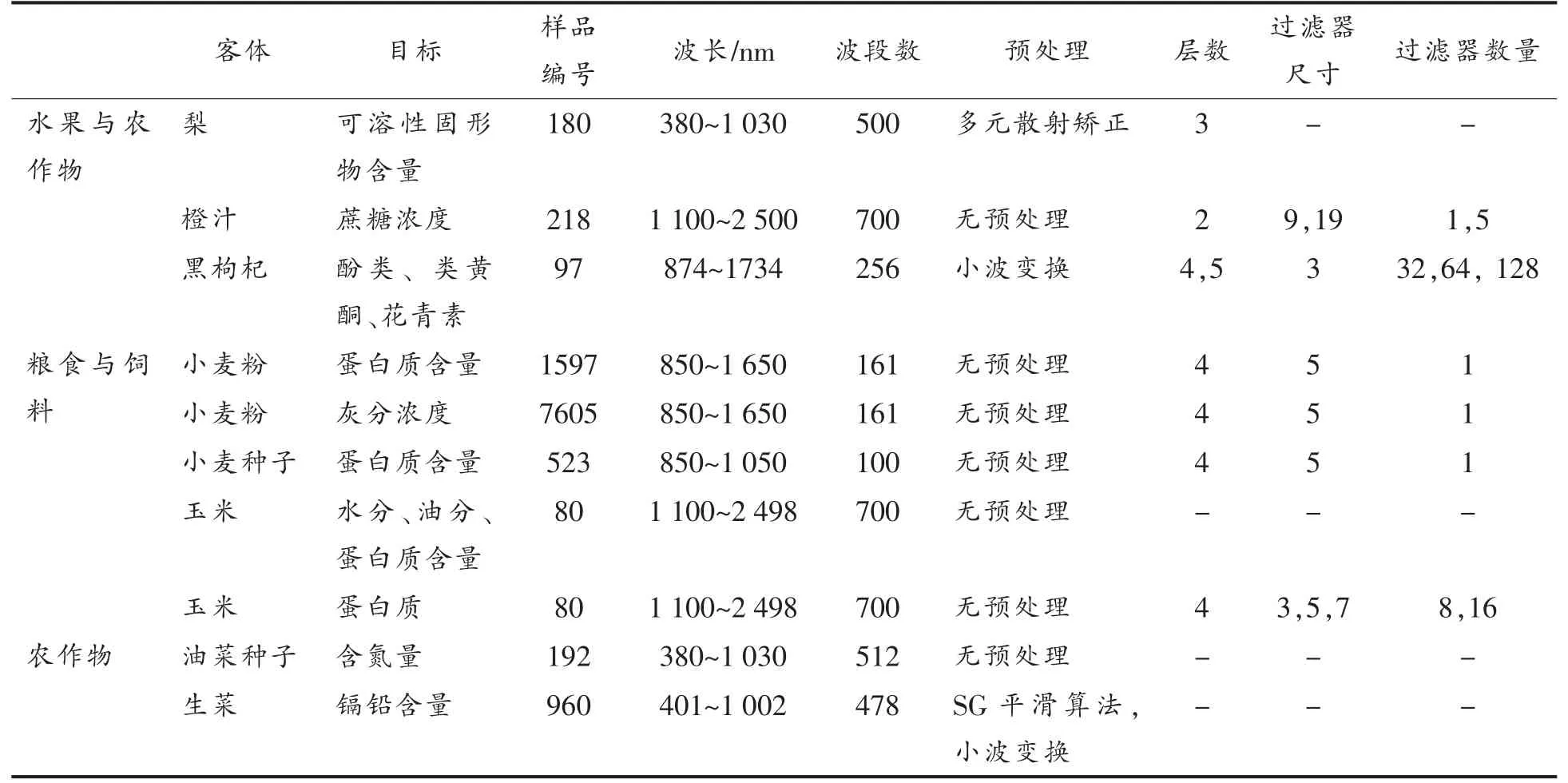
表2 基于深度学习的食品和农产品定量分析[24]Table 2 Deep learning-based quantitative analysis of food and agricultural products[24]
咖啡作为世界上最畅销的饮料之一,咖啡的感官质量检测也尤为重要,目前对咖啡的质量、风味预测以及咖啡豆成熟度等方面的研究越来越成熟。Ramos 等[57]设计了一种用于无损的查找咖啡枝叶中可收获和不可收获的咖啡豆果实的多视图立体视觉(MVS)模型,MVS 使机器人能够计数水果并估计它们的成熟度。Araújo 等[58]开发了一个检测系统来检测豆类的质量和类型,随后作者采用了K-平均算法和KNN 将豆类分为三类:咖啡豆、黑白豆和黑豆,分类准确率为99.88%。咖啡的风味是影响咖啡销量的重要一环,目前已经有研究将深度学习方法应用于咖啡的风味预测中。Chang等[59]用近红外光谱提取咖啡的特征,然后作为数据输入到机器学习与深度学习模型进行学习。作者使用了4 种不同核函数的集成支持向量机、2种不同杂质指数的集成随机森林模型和一维ResNe101 模型,最后对7 种主要的咖啡风味预测结果中,采用集成支持向量机和一维ResNe101 模型的准确率相似,都为78%左右,而ResNe101 模型的召回率更高,达到了70.65%。因为对于水果的质量检测来说,召回率是一个更为重要的指标,因此认为ResNe101 模型拥有更高的识别精度。
2.3.2 动物产品质量检测 肉蛋类以及水产品是人类重要的蛋白质来源,近几年,机器视觉、机器学习以及光谱传感技术已经广泛的应用于肉产品领域的快速无损质量检测技术。畜肉产品的检测主要集中在检测肉类的颜色、质地以及破碎程度,尤其对于海产品来说,深度学习技术的应用,提供了一种检验水产品新鲜度的新方法,这不仅免除了大量的人工操作而且出现错误的概率也更小。Huang 等[60]使用计算机视觉系统与近红外光谱相结合的方法,捕获鱼类的图像得到有关鱼类感官和结构变化的信息。作者采用了主成分分析法来提取数据中最关键的特征,并建立了反向传播人工神经网络来预测鱼类的新鲜度。Poonnoy 等[61]首次将相对内部距离(RID)值与人工神经网络相结合,并以此为依据对煮虾的形状进行分类。4 种形状包括“规则”、“无尾”、“单尾”以及“破碎体”,通过分割虾图像并在分割轮廓上绘制相关线来计算RID 值。最后该模型的总体预测准确率为99.80%。然而目前关于机器学习技术应用在动物产品新鲜度的检验上,并没有准确的检验指标,相关的动物检测指标仍需进一步的研究报道。
对于有壳的蛋类食物,成像系统往往无法采集蛋内的 信息,Syahrir 等[62]首次将Nakano 等[63]开发的无损检测血斑褐壳鸡蛋系统与别的方法相结合,使用图像处理来检测鸡蛋内部的血液斑点。Nasiri 等[64]在Syahrir 等[62]开发的图像系统的基础上进行进一步改进,使用了深度卷积神经网络来对未清洗的鸡蛋进行分类。使用VGG16 架构修改全局平均池化层、密集层、批量归一化层和丢弃层,CNN 模型采用了分层结构,能够自动提取特征,无需去除背景便可实现分类任务,对于鸡蛋使用透光法对鸡蛋进行图像采集,用于对检测模型的训练以及测试。最后该模型对于3 种鸡蛋(即完整、带血和破损)的准确度、精密度、敏感度和特异度分别达到了96.55%,95.59%,94.92%,97.39%。
许多用来分析的模型成功应用在质量检测中,表明深度学习方法在未来食品行业中具有重大的应用前景。目前的问题是如何将这些先进的图像处理技术引入食品领域,如营养成分分析、缺陷检测以及食物不同成分的分割等,食物的多样性与复杂性为这些技术的应用提供了高难度。
2.4 机器学习在食品产业链上的应用
食品的产业链是一个复杂的系统,包括从种植者和养殖者到生产者到销售商再到消费者的全过程,这个过程也称作“从农田到餐桌”,这个过程中的每一步都与消费者的利益紧密相关。然而来自食品供应链的信息往往是不可靠的,这导致政府很难获得食品的准确信息来对食品进行监管,因此将智能学习应用于食品产业链上,有助于信息透明化以及帮助政府检验食品的信息。
在食品产业链中,假冒伪劣产品严重危害着消费者的健康,单独靠人工去检测假冒食品不仅费时费力而且容易出现误差,有研究已经将机器学习方法与机器视觉系统相结合,通过对比食品上的包装细节与文字等信息可以很好的解决人工检测的缺陷。例如Mezgec 等[65]提出了一种结合了深度学习、营养相容性和自然语言处理的用于识别假冒食品的模型。模型首先将捕获的食物图像匹配识别图片中的每个食物项目,然后将它们的食物细节与食物项目进行比较,同时考虑它们的名称。最终这种模型的准确率为92.18%。
质量和消费者接受度也是食品行业最重要的问题,为了确保食品的质量、安全和卫生,必须建立标准操作规范和质量控制系统,并在生产过程中和整个食品供应链中予以遵守。食品工业发展前期,保持食品的质量往往需要大量的人力对食品进行检测,这样不仅耗时耗力还有可能带来偏差。随着技术的进步,机器视觉系统、机器学习等方法在食品上的应用,改变了食品行业现有的状况。TOMRA 是一家提供基于机器学习的智能设备公司,该公司开发了一种机器视觉技术与传感器相结合的产品,现已应用到食品制造商的生产流水线中。这些基于传感器的机器视觉系统可用于食品的分拣、分级、去皮和包装,如图10 所示[66]。此外,在食品的加工程度上也有越来越多的研究者关注,食品的加工程度很大因素上影响着消费者的健康。长期使用过度加工的食品对消费者的身体伤害巨大。Menichetti 等[67]开发了一种机器学习算法来预测食品的加工程度,作者设计了Food-Pro(一种食品分类器),该模型可以提供准确的食品加工程度,捕捉食品的化学物理变化及其对健康的影响。最后作者研究发现对超加工食品的长期摄入会导致代谢综合征等风险,食用一些加工程度较为轻微的食品来代替超加工食品,可以显著降低超加工食品对健康的影响。基于目前的研究进展,并没有研究按照食品的加工程度对食品进行分类,关于食品的加工程度仍然很难鉴定,因此在未来的研究上,可能还会更多的涉及食品加工程度的鉴定以及食品分类。
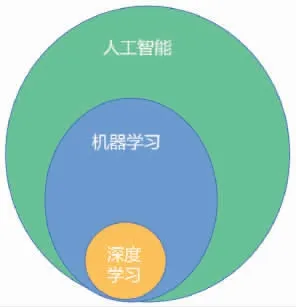
图1 人工智能、机器学习、深度学习之间的关系Fig.1 The relationship between artificial intelligence,machine learning,and deep learning
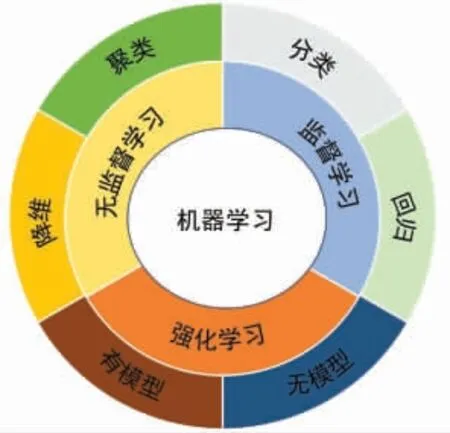
图2 机器学习的分类Fig.2 Classification of Machine Learning

图3 决策树模型示例Fig.3 An example of decision tree
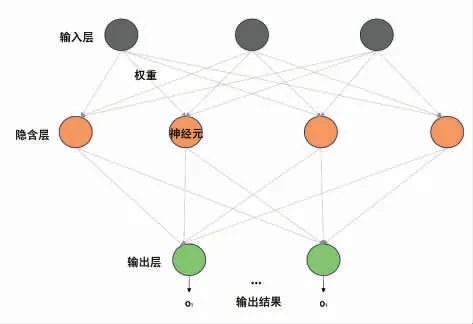
图4 一种典型的人工神经网络模型Fig.4 A typical model of artificial neural network

图5 一种反向传播网络模型Fig.5 An example structure of BP network
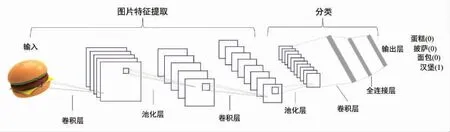
图6 一种典型的卷积神经网络模型Fig.6 A typical model of convolutional neural network
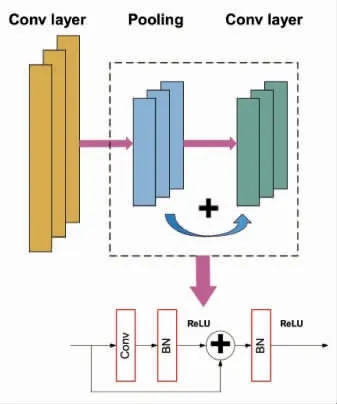
图7 一种典型的递归神经网络模型[24]Fig.7 A typical model of recurrent neural network[24]
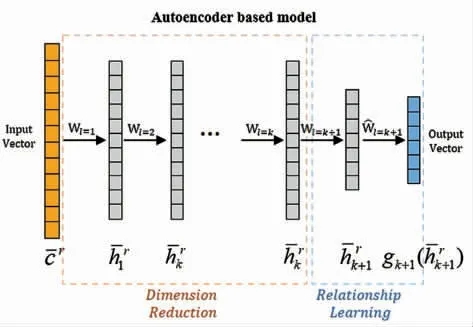
图8 基于自动编码器模型的框架[25]Fig.8 Framework of the proposed autoencoder based model[25]

图9 IVLFood-WS 工作示意图[42]Fig.9 Schematic representation of the IVLFood-WS work[42]
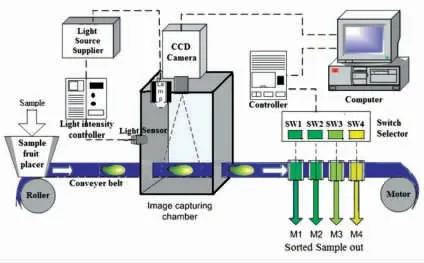
图10 一种基于自动机器视觉的芒果分类机模型[66]Fig.10 An automated machine-vision based mango sorter model[66]
3 结论
将机器学习技术引入食品工业中,不仅有助于提高所加工产品的安全与质量,保持了生产效率的同时确保了食品系统的一致性。深度学习是机器学习的一个子集,与各种神经网络模型和基于机器学习的方法相比,深度学习在食品加工领域诸如图像识别、食品分级、质量检测等方面都表现出了比机器学习更加优秀的性能,可以被证实成为一种有效的建模策略。深度学习的学习效率非常可观,可能是未来食品加工领域的一个重点探索目标。然而影响深度学习在食品领域应用的一些问题仍旧突出,如食品的多样性以及复杂性给模型进行特征提取带来了困难;这种模型对于小规模的数据会出现输出结果较差的偏差,因此模型需要大量且准确的数据样本进行学习训练,而获得一个准确且可靠的样本十分困难,研究者不停的对数据集进行补充与矫正;模型的高成本也制约着人工智能在食品加工领域的大规模应用;对于一些APP 的开发,制约因素则是需要移动设备具有足够的储存空间,现如今的大部分程序都是通过云端计算,这样会导致消耗的时间较长而且结果会发生一定的偏差。未来的研究方向可能集中于研究一些更复杂的神经网络应用于食品领域,并且搜集大量且准确的数据来丰富食品数据库。
猜你喜欢
环球时报(2022-07-13)2022-07-13 17:18:39
环球时报(2022-03-14)2022-03-14 18:19:44
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年19期)2019-11-23 08:42:00
电子制作(2019年11期)2019-07-04 00:34:38
电影(2018年8期)2018-09-21 08:00:06
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
小猕猴智力画刊(2015年4期)2015-04-28 23:55:53
