
基于改进特征融合的口罩检测算法
2024-02-22 07:45武友新
计算机工程与设计 2024年2期
曹 琦,武友新
(南昌大学 数学与计算机学院,江西 南昌 330036)
0 引 言
为减少口罩佩戴人工检测造成的劳力成本,使用目标检测技术[1]可以自动高效识别监控区域中的口罩佩戴情况,YOLO(you only look once)[2,3]作为一阶段目标检测算法的主流框架,近两年在口罩检测任务中被广泛改进应用。文献[4]在SSD算法上引入注意力机制,改进损失函数,对图片中的口罩进行检测,平均精度达到了96.28%,但检测精度较原始算法提高不多,检测速度仅达29 FPS,较原算法略微下降,且不适合小型受限制的场所布置使用。文献[5] 对YOLO算法特征提取进行特征增强,精度达到90.1%,但模型未考虑不规范佩戴分类,且模型检测速度与大小仍有很大优化空间。文献[6]通过分析一阶段检测算法过程中卷积分类和回归框预测存在最优化不一致的问题,提出一种从特征对齐方向进行改进的新思路。针对当前口罩检测算法缺少对特征融合的改进,本文在多尺度特征上进行尺度特征对齐、选择和增强,通过解耦结构提高检测精度和速度。实验结果表明,改进特征融合算法在识别速度远高于实时标准的同时,可以保持较高的口罩规范佩戴识别精度,在人脸规范佩戴口罩检测任务下具有良好性能表现。
1 算 法
YOLOv3特征提取网络采用DarkNet,颈部网络采用特征金字塔网络(FPN)[7]进行深层向低层的单向特征融合,在检测通道采用全卷积神经网络对生成的锚框进行位置信息回归、类别概率预测。改进算法设计轻型特征提取网络DM-CSP提高模型检测速度,加入自设计多尺度注意力提高特征提取能力,对不同深度的提取网络输出的三层特征进行对齐、选择及增强后传入新型解耦头结构,算法结构如图1所示。
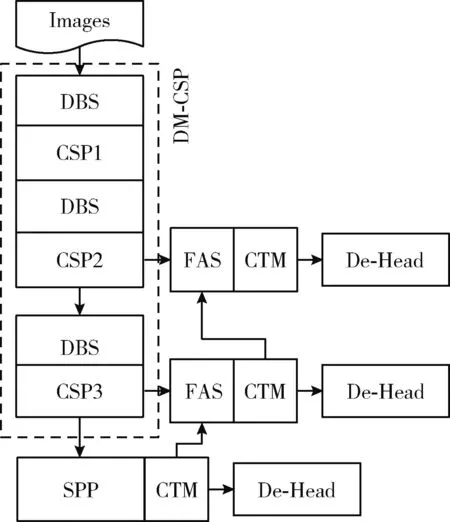
图1 改进算法网络结构
1.1 DM-CSP
考虑到本文检测任务类别只有3类,且检测图片中主体主要是人脸与口罩,要求模型稳定、快速收敛,而DarkNet网络参数较多、计算量较大,容易导致模型训练时间和推理时间增加,因此本文算法骨干网络选用YOLOv4中的CSPDarkNet为基础架构进行特征提取,有效地增强特征图谱的提取能力,大幅度减少模型的计算量。
本文算法骨干网络DM-CSP设计改进CSP结构作为提取网络的组成模块,网络由3个不同深度的映射结构(CSPNet)组成,其中Resunit采用了深度可分离卷积层(depthwise separable convolution,DSC)[8,9]组成,采用残差连接结构,CSPN由卷积层、多个ResUnit和多尺度注意力(multiscale coordinate attention,MCA)组成,残差端和融合输出端增加3×3的普通卷积,最后使用MCA加强提取位置和通道信息,可以在减少参数量同时增强特征提取能力。DM-CSP在进入每一个CSP结构前采用DSC中的深度卷积和点卷积来改变尺度大小与通道数,改进CSPNet结构如图2所示,其中CBS与DBS激活层均采用Silu函数,利于模型快速收敛。

图2 算法CSP结构
由于本文算法骨干网络DM-CSP采用了DSC替代普通卷积,在提高训练速度的同时,网络的精度会相对下降,因此增加MCA模块增强特征提取能力。当前大多数检测模型采用的注意力机制如SE注意力[10](squeeze-and-excitation module)都是仅融合不同卷积层的通道信息或者位置信息,而CA[11]注意力(coordinate attention)是一种新提出的空间注意力机制,它有效地在不同位置间进行通道融合。与一般注意力全局池化不同,CA在横宽方向和纵高位置上对不同通道进行池化、卷积和激活,有助于精确捕捉同纹理方向的语义信息,最后对两个方向的融合通道进行权重再分配,有助于提取网络对感兴趣检测信息如口罩、人脸进行筛选。
考虑到CA注意力在池化时将输入图片压缩会降低分辨率,导致一些特征细节丢失,在提取网络深度增加时,深层的小特征如口罩等的分辨率可能会被压缩到很小导致丢失语义信息,因此需要丰富模型的感受尺度信息,避免深层特征的小目标检测丢失。本文设计一种如图3所示的MCA网络,将CA注意力与空洞卷积构成的多尺度空间金字塔进行组合,利用空洞卷积改变输入空间信息,使模型充分利用多个尺度信息,减少注意力对关键信息的提取丢失,提高特征提取效率。其中普通卷积使用1×1的卷积核,空洞卷积使用3个因子分别为1、3、5的大小为3×3的卷积核,卷积通道数都取输入的1/4,各卷积输出经填充融合后作为CA注意力的输入。
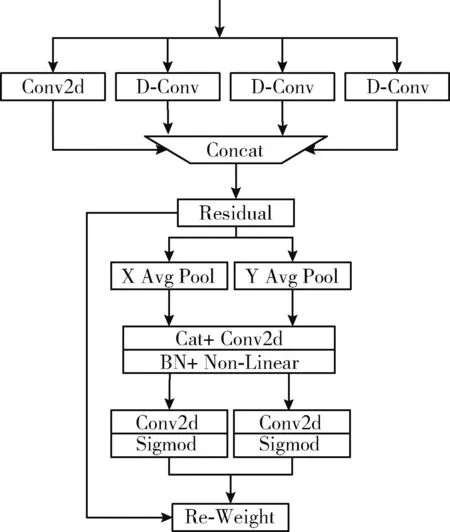
图3 MCA网络
1.2 特征对齐及选择
YOLO算法在提取特征后对3层不同大小的特征尺度进行融合,但传统FPN在上采样时首先将深层特征进行1×1卷积的降维操作,这会导致深层特征的语义信息丢失,上采样后特征容易出现特征区域与网格预测区域不对齐问题,随后直接与浅层通道进行融合会产生大量的噪声影响性能。特征对齐及选择模块(feature alignment and selection,FAS)取消上采样前对深层特征的降维卷积,首先通过自编码器AED[12]将深层特征f2在上采样后进行解码得到对齐特征f′2, 其中自编码器AED编码、解码器均由3层卷积层组成,大小分别为7×7、3×3、1×1;然后对融合特征进行特征筛选,选择模块S首先将融合特征沿宽、高方向进行平均池化,得到两组1×1×C大小的特征通道,随后依次经过1×1卷积层、Relu激活层、相加操作,生成通道数不变的一组向量,FAS选用这组权重向量作为选择因子,利用选择因子与融合特征进行点乘操作,得到新的具有空间特征的选择信息,再与经过3×3卷积的另一通道进行相加操作,最后通过1×1卷积进行通道降维,选择模块S在训练中通过不断优化选择因子对感兴趣的特征进行选择,从而增加对口罩、人脸的特征信息关注,筛选掉不重要通道进入检测通道,FAS网络结构如图4所示。
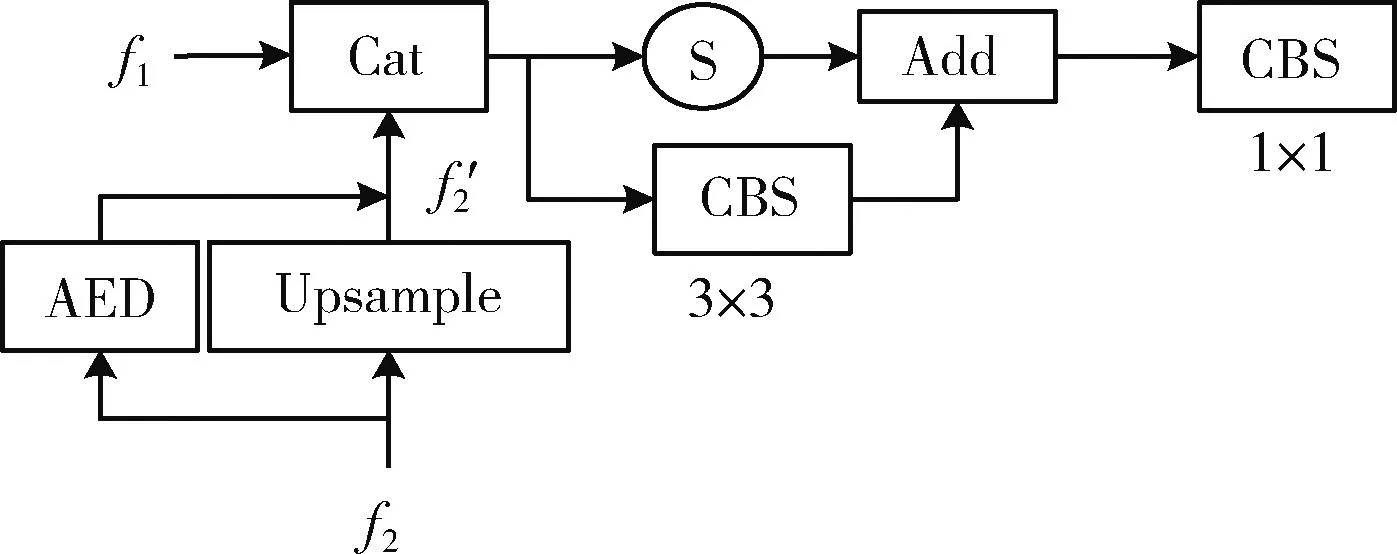
图4 FAS结构
1.3 特征增强
相较其它算法仅对图片口罩存在的是否进行检测,本文算法重视对图中口罩是否规范佩戴的检测,因此特征图中口罩和人脸的特征排列相对位置尤为重要,设计模块CTM来进行特征上下文信息增强。CTM结构如图5所示,共有三层通道操作:第一层设置空洞卷积扩大上下文尺度信息范围,在保留原始信息特征分布的同时提取小范围特征上下文信息,特征空洞因子设置为1,卷积大小为3×3;第二层将输入特征进行3×3的最大值池化,获取局部关键上下文信息,随后通过扩展操作利用1×1卷积增加通道数;第三层利用全局平均池化,可得到整张特征图谱的上下文信息分布情况,卷积操作与第二层相同;输入特征经过3层处理后融合,可使本层特征在进入检测通道前尽可能丰富上下文信息,通过上下文信息增强可以增加口罩与人脸特征的关联性,进一步提高口罩规范佩戴检测的置信度。
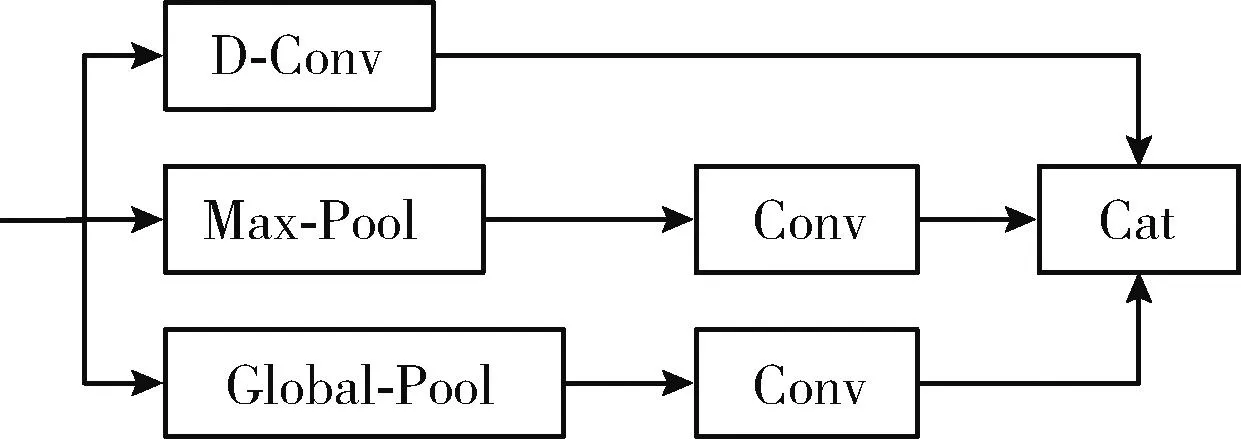
图5 CTM网络
1.4 通道解耦
YOLO系列轻量级算法通常会在原有算法基础上去掉最大的尺度,只保留两个下采样特征,用精度损失换来了速度快和设备性能要求低的优点。针对本数据集密集人群中人脸、口罩检测目标像素占比较小,双通道检测头可能会存在小目标漏检情况,因此本算法仍保留一层8倍下采样特征层,组成3层不同大小的特征尺度经过处理形成本算法的检测头部。
YOLO系列算法检测头均采用单通道同时处理对目标分类、位置回归的卷积预测,但部分网格对口罩及人脸的分类正确率与回归框预测正确率不匹配,因此采用解耦设计是对目标分类、位置回归分别进行卷积计算,有效避免分类与位置回归预测任务的冲突,从而提高了预测准确率。受文献[13]启发,本算法使用图6中的解耦结构,首先将3层特征分别经过1个1×1深度可分离卷积进行降维,随后分成两个平行分支,分支内都包括两个3×3大小的卷积核,一平行分支负责类别分类,另一分支负责置信度回归和预测框位置回归,消融实验验证此解耦设计有效改进了模型的检测速度和精度性能。

图6 Decouple head结构
2 实 验
2.1 数据集与实验环境
本文算法主要面向公共场所密集人群场景,算法所用数据集首先在遮挡人脸检测数据集MAFA[14]、开源数据集AIZOO上抽取部分图片,然后通过相机拍摄和网络采集扩充口罩图片,共计5000张图片。使用标注工具对每张图片中人脸口罩部分打上标签,保存为XML文件。数据集部分原始图片样本如图7所示。

图7 数据集图片样本
数据集图片类别分为正确佩戴(c-mask)、错误佩戴(i-mask)和未佩戴口罩(n-mask)这3类,实验中将佩戴口罩露出口、鼻或下巴视为错误佩戴口罩情形,数据集中样本目标分布情况见表1。
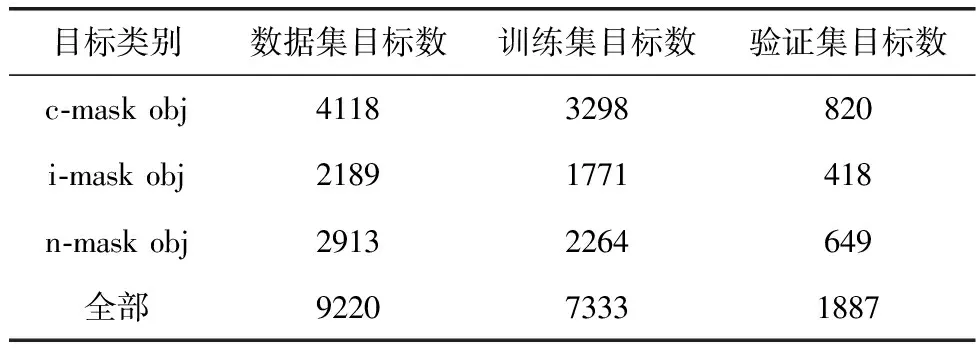
表1 数据集中样本分布情况
本文算法在Windows操作系统进行模型训练与测试,使用PyTorch 框架,CPU为AMD Ryzen 5 4600H,GPU为NVIDIA GeForce GTX 1660Ti(6 GB),软件环境为CUDA 10.2、CuDNN 7.6、Python 3.8。实验环境配置参数见表2。

表2 实验环境配置参数
2.2 评价指标
目标检测领域中一般使用准确率(A)、精确率(P)、召回率(R)、平均精确度(AP)和每秒帧率(FPS)等评价指标。本文重点使用AP50(交并比取0.5时的AP)和FPS作为算法评价指标。平均精确率均值(mAP)可通过计算各类的AP50平均值得到,各类AP计算公式如下

(1)
式中:r为数据集不同类别样本的召回率;P(r)为召回率为r时的精确率。
AP一般通过计算精度召回曲线(PR曲线)下面积得到,统计数据集中每张图片中这一类别的TP、FP、FN数目,从而得到该类别P和R指标。本文mAP通过计算正确佩戴口罩、未佩戴口罩、错误佩戴口罩3类AP50平均值得到,计算公式如下
(2)
算法主要针对提高模型检测mAP和FPS进行改进,其它评价指标如模型参数量、计算量(GFLOPs)、模型大小(Size)也可作为算法性能比较指标,其中FPS即模型推理速度也从一定方面代表了模型参数量和计算量的大小。
2.3 实验结果

表3 算法测试结果
改进算法实验结果对比YOLOv3,3类mAP提升2.5%,但不规范佩戴口罩类别mAP提升8.4%,一方面是因为YOLOv3算法检测COCO数据集含有80类别,因此在特定规范佩戴口罩检测任务上表现不佳,另一方面也印证了改进算法的特征对齐及增强设计的有效性。改进算法FPS较YOLOv3提升近5倍,由18 FPS提升至107 FPS,模型较YOLOv3计算量也降低了95%,模型大小仅为7.8 MB,实验测试结果部分样本如图8所示,图左侧改进算法正确佩戴口罩、未规范佩戴口罩、未佩戴口罩分别用对应检测框(c-mask、i-mask、n-mask)标出,与图8右侧原始YOLOv3算法测试结果对比可以看出,本文改进算法对3类口罩检测的置信度更高,对不规范佩戴口罩和不佩戴口罩检测的区分度更好。此外与其它轻量级算法YOLOv3-Tiny、YOLOv4-Tiny和YOLOX-Tiny相比,mAP分别提高了5.6%、4.8%和2.7%,FPS也相应提高了19%、13%和9%,计算量降低了63%、78%和28%,模型大小降低了77%、65%和80%。文献[5]中的改进YOLOv3算法只检测输入图片中口罩的存在,未对人脸规范佩戴进行检测,由于本文数据集来源与该算法相似,因此由算法测试结果对比,可以看出本文算法在精度和速度上都具有很大提升。实验结果表明,本文提出的公共场所密集人群场景下口罩规范佩戴检测算法相较于其它算法,对于错误佩戴类别检测精度更高,在场景复杂、设备算力、空间资源受限且实时性要求高的公共场所检测任务中,性能优于其它流行检测算法,更适用于公共场所口罩规范性佩戴检测任务。

图8 测试结果图片样本
2.4 消融实验
2.4.1 DM-CSP消融实验
首先将YOLOv3算法的特征提取模块DarkNet替换为改进算法中使用的普通卷积CSPNet结构,随后将网络中卷积改为深度可分离卷积,最后添加注意力MCA形成本文改进算法中使用的DM-CSP特征提取模块。对YOLOv3算法结构分别使用上述3种特征提取模块,在本实验数据集上使用416 px×416 px大小的图片进行训练并测试,进行对比实验,实验结果见表4。

表4 DM-CSP模块消融结果
2.4.2 特征融合实验
对特征融合模块进行消融实验分析,实验1使用DM-CSP特征提取模块替换原始YOLOv3算法使用的DarkNet,融合阶段仅将FPN上采样与融合操作替换为FAS模块完成;实验2使用DM-CSP替换DarkNet,然后在FPN输出端后增加特征增强模块CTM,对FPN融合到的特征进一步增强上下文信息;实验3将实验1、2进行整合,在实验1的基础上使用CTM模块;实验4在实验3的基础上采用通道解耦替换原始检测头通道,对CTM增强的特征分别进行位置回归和类别分类卷积运算,实验结果见表5。

表5 融合模块消融结果
表5可以看出,实验1结果中mAP在DM-CSP提取特征基础上增加了2.1%,验证了增加FAS机制能够缓解特征丢失及上采样融合造成的不对齐问题,改善了算法的特征筛选功能,验证了FAS设计的有效性,但FPS也减少了7,推测为深层通道在筛选模块前而不是上采样阶段进行降维操作,导致自编码器中的卷积操作增大了模型计算量,从而减缓推理速度;实验2结果中mAP在DM-CSP基础上增加了1.4%,验证了在特征融合阶段对上下文信息进行增强是很有必要的,这会大幅提高特征间的关联性,扩大了模型的感受信息,提高特征的一致性,结果中FPS略微下降,主要是因为此模块较多采用1×1的卷积操作,计算量增加不多;实验3结果印证了FAS模块和CTM模块可以有效地结合使用,表明经过特征对齐、筛选后特征更适合进行上下文信息的捕捉;实验4结果中验证了解耦设计较原始检测头的合并卷积结构能够提高准确率,并且加快模型推理速度,验证了检测头解耦设计对YOLO结构改善的有效性,最终改进算法在DM-CSP骨干网络上,结合FAS、CTM特征融合模块,采用解耦通道进行实验,提高了3.9%的检测精度,推理速度变为107 FPS。
2.4.3 注意力对比实验
为了验证注意力MCA的有效性,将MCA添加在多个主流通用模型的特征融合模块中,在本文使用的口罩数据集上进行训练、测试,随后将MCA替换为通用注意力SE、CA模块进行对比实验,对比结果见表6。YOLOv3由于骨干提取网络参数太多,因此可以看出在融合网络FPN添加各注意力模块精度提升效果不显著。对于YOLOv3-Tiny、YOLOv4-Tiny和YOLOX-Tiny算法,在融合网络PaNet和骨干提取网络之中添加各注意力模块,精度都取得了不错的提升效果,MCA对比其它注意力模块提升效果更好,分别取得了1.6%、1.2%、0.7的精度提升,验证了通过膨胀卷积加大输入感受野可以更好加强注意力效果。
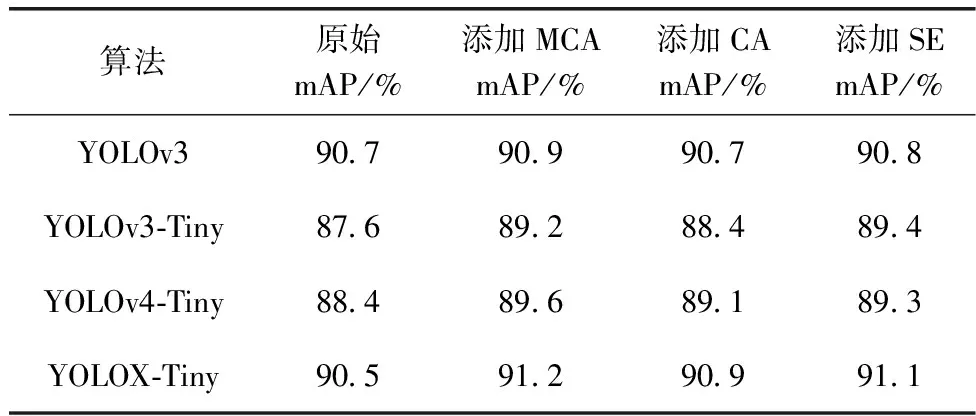
表6 添加注意力效果对比
2.4.4 公开数据集实验
将公开数据集PASCAL VOC2007和VOC2012合并进行训练,在VOC2007数据集进行测试,实验结果如图9所示。本文算法在VOC数据集中取得了AP50为75.4%的精度结果,相比YOLOv3和YOLOv4的轻量级算法,提升了4.2%和2.1%,充分验证了本文改进算法的通用性。
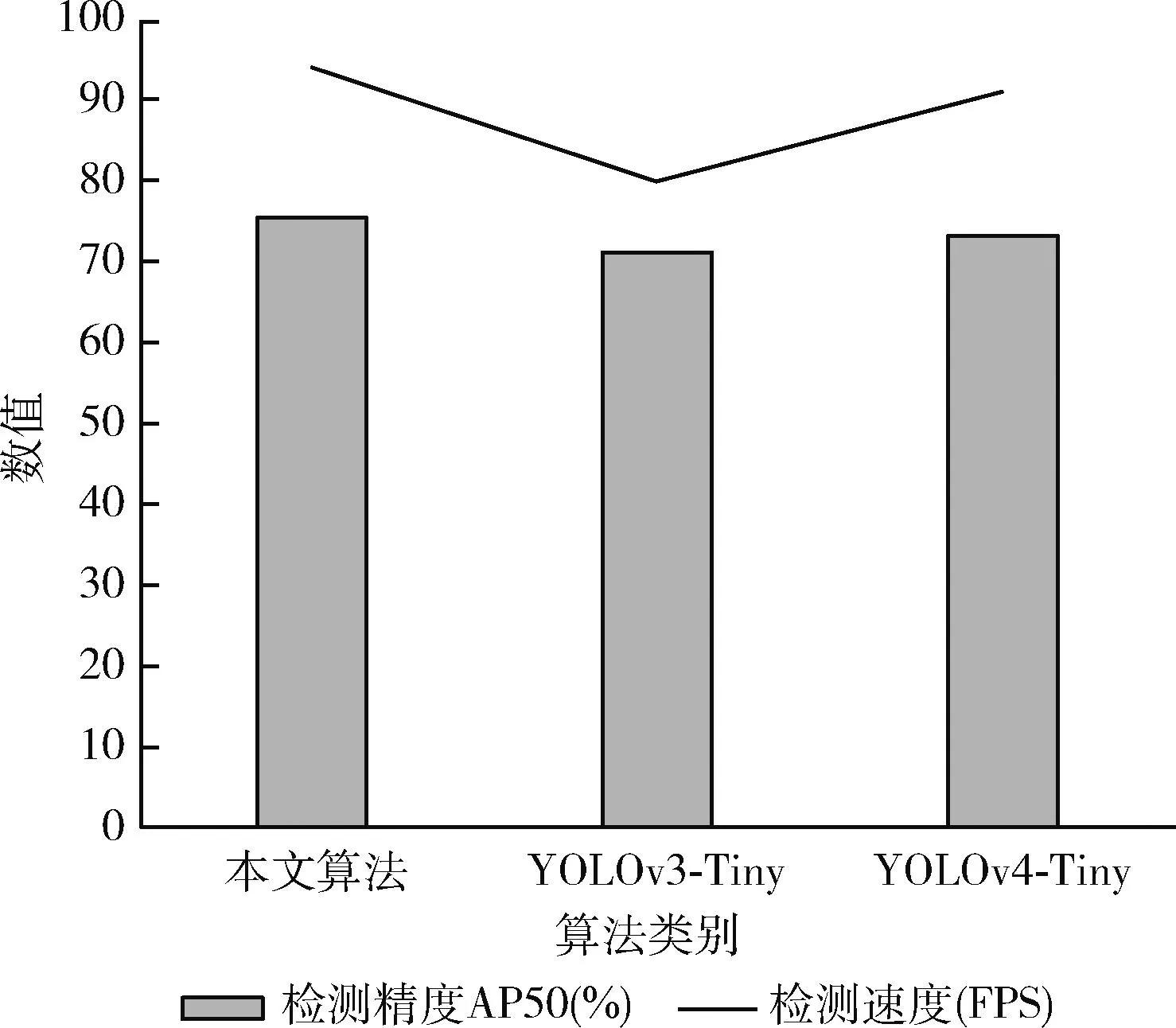
图9 VOC数据集测试结果
3 结束语
本文从改进特征融合角度出发,提出一种口罩规范佩戴检测的单阶段算法。对网络进行骨干提取轻量化时,扩大注意力感受野可以进一步提高性能。针对特征不对齐和上下文信息关联性低进行改进,是提升检测精度的一个可行方向。改进特征融合算法性能优于其它轻量级检测算法,利于口罩检测场景的部署和应用。针对FAS影响推理速度进行改进,是我们重点推进的后续工作,同时考虑到数据采集、标注繁琐,结合半监督学习进行数据增强也是我们推进的后续工作。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
意林(2020年9期)2020-06-01
海峡姐妹(2020年4期)2020-05-30
电子制作(2019年11期)2019-07-04
作文大王·笑话大王(2019年3期)2019-04-22
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
电视技术(2014年19期)2014-03-11
