
基于YOLO-v7的无人机航拍图像小目标检测改进算法
2024-02-21 06:00:38郝紫霄
软件导刊 2024年1期
郝紫霄,王 琦
(江苏科技大学 计算机学院,江苏 镇江 212003)
0 引言
目标检测作为图像处理与计算机视觉领域的关键问题,备受重视。随着无人机、卫星遥感、航空航天等技术的发展,航拍图像目标检测已成为研究热点。无人机航拍图像是航拍图像的重要分支,是以无人机作为图像传感器的空中搭载平台所拍摄的图像。无人机具有操控简单、飞行灵活、成本低等优点。目前,无人机航拍图像目标检测已广泛应用于城市规划、交通监测、生态保护、军事安防等领域,且适用场景不断拓展[1]。然而,航拍图像区别于普通图像,具有背景信息复杂、目标尺度小、目标具有显著的方向性且分布稀疏不均等特点[2],这使得航拍图像的目标检测,尤其是小目标检测充满挑战。
为应对现有算法在无人机航拍图像小目标检测任务中存在的误检率与漏检率高、精度较低等问题,本文提出一种基于YOLO-v7 的无人机航拍图像小目标检测改进算法FCL-YOLO-v7。在此基础上,本文作出如下贡献:①将原始的3 个比例检测层扩充为4 个比例检测层,增加小目标检测层;②用FReLU 激活函数代替YOLO-v7 网络中Conv 模块与RepConv 模块中的SiLU 激活函数;③在YOLO-v7 的骨干网络(backbone)中添加CBAM 注意力机制模块;④通过从公开数据集中获取图片与自主采集图片,构建针对小目标的无人机航拍图像数据集。本文通过对比实验与消融实验验证了改进算法在无人机航拍图像小目标检测任务中的优越性。
1 相关研究
传统算法在无人机航拍图像目标检测领域取得了良好效果。韩露[3]基于SIFT 算法与霍夫变换,提出了针对无人机航拍图像中十字路口目标的检测方法。Xu 等[4]利用HOG 特征与SVM 分类器,并结合Viola-Jones 检测器,实现了低空无人机图像中的车辆目标检测。然而,传统算法不适应数据量庞大的无人机航拍数据集,且无法达到精准实时的检测效果。
基于深度学习的目标检测已成为主流,主要可以分类为一阶段的目标检测算法和二阶段的目标检测算法。二阶段目标检测算法基于区域建议,先生成一系列样本候选框,然后通过卷积神经网络进行样本分类,常用算法有Fast RCNN[5]、Faster RCNN[6]等。王立春等[7]利用Faster RCNN 算法,并结合连通区域颜色面积特征,提高了无人机图像中公路标线目标检测准确率。二阶段算法虽然精度高,但实时性较差。一阶段目标检测算法又被称为基于回归的目标检测算法,直接回归物体的类别概率和位置坐标,可以更好地兼顾精度与速度,代表算法有SSD(Single Shot Multi-Box Detector)[8]、YOLO(You Only Look Once)[9]系列等。Li 等[10]利用迁移学习原理,设计了一种多块SSD算法,提高了铁路监测场景下无人机航拍图像小目标检测精度。Zhang 等[11]提出一种改进的YOLO-v3 模型,使其具有更深的特征提取网络和更多的不同尺度的检测层,并通过实验验证了其鲁棒性与准确性。Sun 等[12]提出了一种改进的YOLO-v5 算法,添加了上采样应对高采样和大感受野的问题,同时采用特征融合方法应对浅层特征语义信息不足的问题,并用Mobilenet-V2 轻量网络提升检测速度。
2 相关算法与技术
2.1 YOLO-v7原理与结构
2022年提出的YOLO-v7[13]算法,其作为YOLO 系列的新秀,相比之前的YOLO 算法在精度与速度等方面都有所提升,在Microsoft COCO 数据集上的验证精度比YOLO-v5s算法高6.4 个百分点,每秒处理的图像帧数目多39 帧。在先前版本算法基础上,YOLO-v7 作出的改进主要有:①设计了几种可训练的bag-of-freebies 免费包方法,包括重参数化、引导头(lead head)、辅助头(auxiliary head),使得实时目标检测可以在不增加推理成本的前提下,大幅度提高检测精度;②在PlainNet 和ResNet 中设计了有计划的重参数化卷积结构,解决了重参数化的模块如何取代原始模块的问题,以及使用计算和优化方法生成可靠的软便签(Soft Label)并设计合理分配机制,解决了动态标签分配策略如何处理不同输出层的分配问题;③提出了“extend 扩展”方法与“复合缩放”方法,在实时目标检测任务中能够更充分地利用参数与计算资源。YOLO-v7 相比现有的实时目标检测器,参数量减少约40%,计算量减少约50%,推理速度与检测精度也得到提升;④YOLO-v7 对YOLO 的架构进行了革新,以YOLO-v4、Scaled YOLO v4[14]等为基础,构建了基于ELAN 计算块的E-ELAN(Extended Efficient Layer Aggregation Network)网络架构,在不破坏原有梯度路径的条件下,提高了网络学习能力。ELAN 结构如图1所示。

Fig.1 ELAN structure diagram图1 ELAN结构示意图
YOLO-v7 的head 网络中的ELAN 模块与backbone 网络中的ELAN 模块(见图2)略有不同,进行concat 操作的数量由4个变为6个,示意图如图2所示。
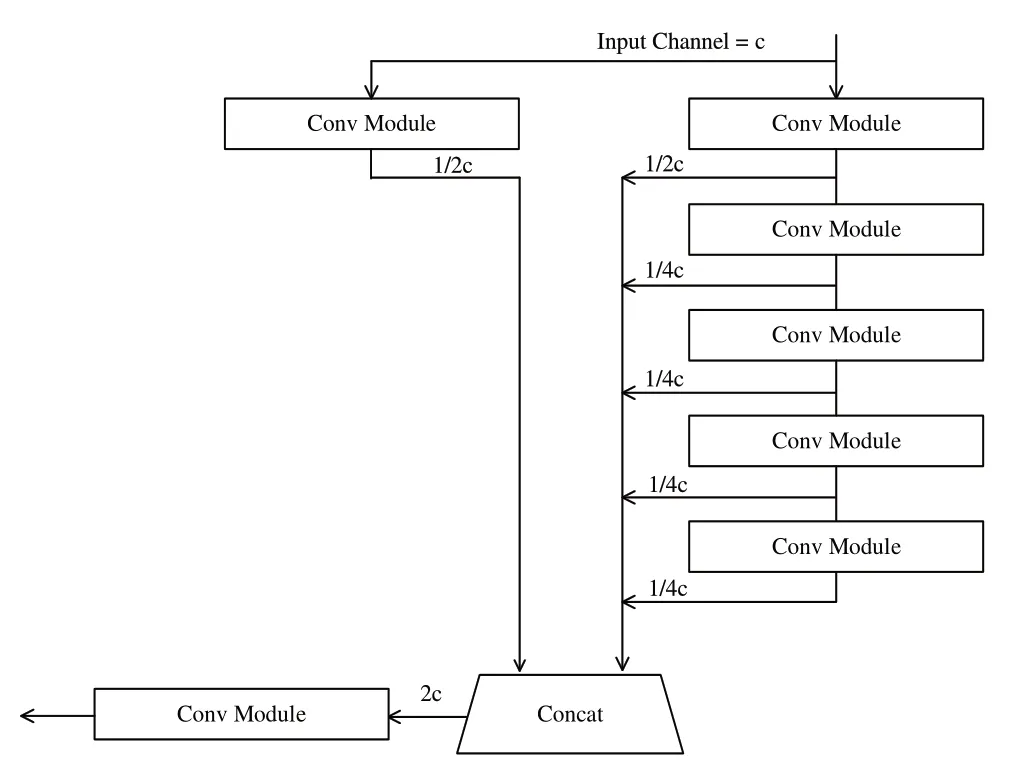
Fig.2 Head-ELAN diagram图2 Head-ELAN示意图
通过上述改进,YOLO-v7 的速度足以支持其在边缘设备上做推理运算。YOLO-v7在保持相对精度(56.8%)下的绝对的速度优势(30FPS)使得它在无人机集群飞行、无人机自主避障、无人机辅助降落等应用场景中拥有可预见的广阔前景。
2.2 FReLU激活函数
YOLO-v7 网络中的Conv 模块中包括卷积操作、批归一化操作(Batch Normalization)、激活函数操作。在原始YOLO-v7 算法中使用的是SiLU(Sigmoid Weighted Liner Unit)激活函数[15],公式如式(1)所示。
SiLU 函数的简单性及其与ReLU 函数的相似性使其可以有效替换ReLU 激活函数。而2020 年提出的FReLU(Funnel Activation)[16]激活函数在图像分类、对象检测、语义分割任务上的表现都优于ReLU、SiLU 等激活函数,克服了激活函数的空间不敏感对视觉任务的阻碍。作为专门为视觉任务设计的激活函数,FReLU 使用简单的二维条件代替激活函数中人工设计的条件,二维空间条件可以实现像素级的建模能力,用规则卷积捕捉复杂的视觉布局。FReLU 的公式如式(2)、式(3)所示。
其中,T(xc,i,j)代表定义的漏斗式条件;代表第c通道上,以2D 位置(i,j)为中心的窗口代表此窗口在同一通道中的共享参数。FReLU 以微不足道的计算开销与空间条件开销为代价,在一定程度上提升了目标检测,特别是小目标检测的精度。
2.3 CBAM注意力机制
即添即用的注意力机制模块可以让目标检测网络自适应地关注到值得注意的区域与特征,而不是不加区分地关注所有区域与特征。注意力机制可分为通道注意力机制、空间注意力机制、结合通道与空间的注意力机制。卷积注意力机制模块(Convolutional Block Attention Module,CBAM)[17]是通道注意力机制与空间注意力机制结合的典型实现,可以关注每个通道的比重与每个像素点的比重。CBAM 的示意图如图3所示。

Fig.3 CBAM diagram图3 CBAM示意图
图3 中通道注意力机制模块的公式如式(4)、式(5)、式(6)所示。
其中,uc是第c个通道大小为(H,W)的特征图;zcm是全局最大池化处理后的结果;zca是全局平均池化操作后的结果;Fmlp是共享全连接层处理;将两个处理结果相加再取Simoid函数值,得到权重Mc,最后,将权重与输入特征层相乘。
图3中空间注意力机制模块的公式如式(7)所示。
其中,Ms(F)是对特征图F处理得到的权重值;AP是平均池化操作;MP是最大池化操作;Conv表示对堆叠结果进行卷积操作;σ是Simoid函数操作。
CBAM 可以提高目标检测网络性能,节省参数与计算力,但在实际使用时要根据自身数据与网络特点综合决定插入与否以及具体插入位置,否则会得不偿失。
3 改进的YOLO-v7算法
3.1 FCL-YOLO-v7
随着无人机飞行高度的变化,目标的成像尺寸也会随之变化,因此目标检测模型要适应多种尺度。为使网络尽可能多地获取小目标的特征信息,从而提升小目标的检测效率,本文对YOLO-v7 的网络结构进行了改进。YOLOv7 中,backbone 网络对输入图像的宽高进行压缩,同时扩张通道数;经backbone 对特征点进行连续下采样后,会产生具有高语义内容的特征层,然后加强特征提取网络会重新进行上采样,使得特征层的尺度重新变大,利用大尺度的特征去检测小目标。原始YOLO-v7 算法的加强特征提取网络会进行两次上采样,而FCL-YOLO-v7 添加了第3次上采样,继续处理特征图,并将第3 次上采样之后的特征图与骨干网络中经过Stem 模块、第一个Conv-ELAN 模块后生成的特征层进行拼接操作,实现特征融合,从而生成宽高为160 的第4 个输出检测层。此外,由于上采样次数增加为3,下采样的次数也改为3 次,反映到网络结构上的变化为:加强特征提取网络中添加了一组“下采样模块-ElAN 模块”。因此,相比原始YOLO-v7 生成的3 个检测层,改进算法中对应尺度的检测层中由加强特征提取网络生成的部分在进行RepConv 操作前多进行了一组上采样与一组下采样操作,检测层包含的小目标信息量得到提升。经过改进,YOLO-v7 的特征金字塔结构得到了拓展[18],在一定程度上解决了浅层特征语义信息不足的问题;改进算法还考虑到新增的上采样结果可能会对小目标特征不明确,因此将之前下采样中生成的特征层与上采样中尺度相同的特征图进行堆叠,不仅尽可能多地保留了小目标信息,而且有利于充分利用深层特征与浅层特征,有利于融合纹理特征与语义特征。
为改进小尺度目标检测效果,FCL-YOLO-v7 对锚框(Anchor)进行了调整。锚框机制的原理是遍历输入图像上所有可能存在目标的像素框,然后选出实际存在目标的像素框,并对像素框的尺寸与位置进行调整从而完成目标检测任务。在实际任务中,锚框设置为多种不同尺度,以使网络检测范围尽可能多地覆盖面积与区域,同时方便后续锚框调整到与真实框基本接近。锚框机制的引入不仅可以降低模型训练复杂度、提高运行速度,还能有效预测不同宽高比的物体。锚框是检测的起点,需要将设计好的锚框分配给不同尺度的物体,然而物体的尺度是连续的,锚框的尺度是离散的,如果没有设计好锚框尺寸,容易造成小目标漏检。在原始YOLO-v7 算法中,Anchor 参数为[12,16,19,36,40,28];[36,75,76,55,72,146];[142,110,192,243,459,401],每一组Anchor 参数代表在不同的特征图上的锚框,一般在含有更多小目标信息的大的特征图上去检测小目标。改进后的网络Anchor 参数为[12,16,30,15,15,30];[56,20,28,43,93,30];[46,95,167,48,110,155];[383,136,286,354,609,255],解决了之前的3组锚框配置无法满足4个检测层的问题。
激活函数作为非线性因素,具有去线性化,即克服线性模型局限性的作用。因此,目标检测模型中激活函数的选择对其性能的影响不容忽视。在YOLO-v7 网络中,Conv 模块是其结构的关键组成部分。Conv 模块中封装了3 个功能,分别是卷积、批归一化、激活函数。改进算法将原网络中的Conv 模块包含的激活函数由SiLU 替换为FRe-LU,原网络中RepConv 模块包含的激活函数也使用FReLU函数替换SiLU 函数。YOLO-v7 中的RepConv 借鉴了RepVGG[19]的架构,延续了其推理速度快、记忆效率高的性能,而RepVGG 的提出是为了解决ResNet 等复杂多分支设计的模块难以实现且特质化困难的问题。
YOLO-v7 网络中的backbone 部分首先是Stem 结构,它由堆叠的3 层Conv 模块构成。第1 个Conv 模块的卷积核设置1,步长设置为1;第2 个的卷积核设置为3,步长为2;第3 个的卷积核设置为3,步长为1,以实现宽高分别减半、通道数变为64 的效果(针对三通道彩色图片的处理效果)。改进算法将YOLO-v7 的Stem 结构的第一个Conv 模块替换为CBAM 注意力机制模块。CBAM 是一种轻量型的通道—空间注意力机制,适合无人机的实时目标检测任务。
经过上述改进,FCL-YOLO-v7 算法的网络结构如图4所示。
3.2 PCUS-DataSets
无人机航拍图像小微目标数据集较缺乏,因此本文构建自定义数据集进行后续实验。自定义数据集PCUS-DataSets 的图片由公开数据集DTB70[20]、Visdrone[21]、Det-Fly[22]、NPS-Drones 以及自采集数据集中的相关图片所构成,其中,自采集图像由大疆Mavic Air 2 无人机通过实际飞行进行采集,分辨率为8 000×6 000。PCUS-DataSets 的图片总量为718 张,随机划分为训练集图片588 张,验证集图片65 张,测试集图片65 张。为定量定性地测试本文算法针对无人机航拍图像中小目标的检测性能,PCUS-Data-Sets 中的目标尺度均微小,在整张图片中的像素数占比可低至1/50 000。数据集还包含大量稠密分布、遮挡分布、边角分布、前景与背景难以区分等检测较为困难的小目标,分别如图5(a)(b)(c)(d)所示(彩图扫OSID 码可见,下同)。

Fig.5 Diagram of some targets图5 部分目标示意图
PCUS-DataSets 中的目标被标记为Pedestrian、Cyclist、UAV、Sheep 4 类:Pedestrian 类标记行人目标,共1 122 个;Cyclist 类标记骑行者目标,标记框覆盖骑行者及其代步非机动车机身,共616 个;UAV 标记同伴无人机目标,使算法的应用场景从单个无人机飞行扩展为无人机集群飞行,共325 个;Sheep 标记羊目标,共583 个。PCUS-DataSets 的拍摄场景多样,包含公园、商业街区、广场、公路、校园、水库、草地、天空、海滨等,且涵盖各时间维度。
4 实验与分析
实验条件为:本文实验是在Windows10 操作系统下进行;使用单块GPU,型号为NVIDIA GeForce RTX 3060 Laptop GPU;处理器为AMD Ryzen 75800H;训练时采用带预热的余弦退火算法;网络输入尺寸为640×640;实验数据集为自主构建的PCUS-DataSets 数据集。实验参数设置如表1所示。
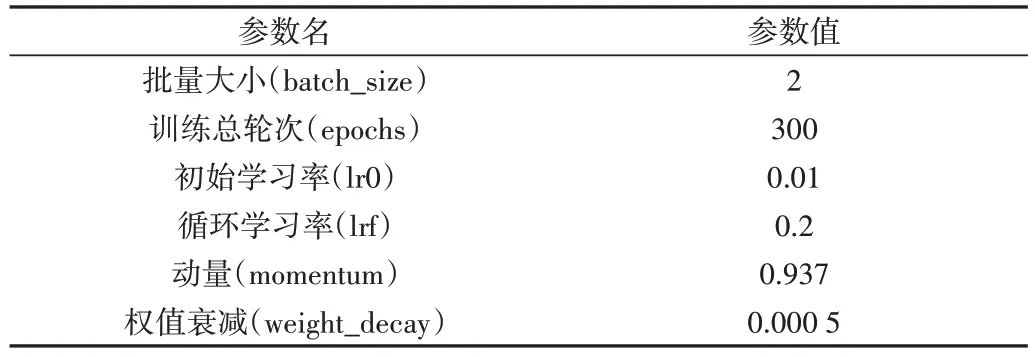
Table 1 Partial experimental parameters表1 部分实验参数
为评价改进算法性能,引入指标:精确率(Precision)、召回率(Recall)、测试所用非极大值抑制时间(NMS_time),公式如式(8)、式(9)所示。
其中,TP代表将正类预测为正类数,FP代表将负类预测为正类数,FN代表将负类预测为正类数。
本文以计算量,即模型运算次数衡量模型时间复杂度;以访存量,即模型参数数量衡量模型空间复杂度。输入图像尺度为640×640 时,FCL-YOLO-v7 模型计算量为121.2 GFLOPS,参数量为35.58M。
4.1 对比实验及结果分析
为检测本文改进算法的效果,将其与同类算法进行对比实验,结果如表2 所示。本文涉及的对比实验中,网络的深度(depth_multiple)均设置为1.0,宽度(width_multiple)均设置为1.0。

Table 2 Comparison of detection results of different algorithms表2 不同算法检测结果比较
由表2 可知,FCL-YOLO-v7 算法在精确率上比YOLO-v3 高7.3 个百分点,比YOLO-v5 高6.5 个百分点,比原始YOLO-v7 算法高6.7 个百分点;在召回率上比YOLO-v3高1.9 个百分点,比YOLO-v5 高3.3 个百分点,比原始YOLO-v7 算法高0.2 个百分点。经过改进,算法性能得到提升,与无人机航拍图像小目标检测任务的适配性得到提高。
为直观展示本文算法改进效果,图6(a)(b)分别为用YOLO-v7、FCL-YOLO-v7 在PCUS-DataSets 数据集上训练得到的权重检测无人机图像目标所得到的效果图。

Fig.6 Experimental processed image图6 实验处理图像
YOLO-v7 算法处理的图6(a)中出现了将斑马线误检为Cyclist 目标、将汽车轮胎误检为Pedestrian 目标的情况,正确目标的置信度较低,如右下角Cyclist 目标的置信度为0.78。而FCL-YOLO-v7 算法处理的图6(b)中则没有误检,且右下角Cyclist 目标的置信度为0.94。由此可见,改进算法能有效解决小目标检测难题。
4.2 消融实验及结果分析
为了进一步验证本文提出的各项改进对算法性能的影响,本文进行了消融实验。消融实验设置如表3 所示,对每个实验进行编号,表格中的“加号”表示“进行此项改进”,实验结果如表4 所示。实验1-4 在训练时应用了迁移学习原理,均使用了YOLO-v7 在Microsoft COCO 数据集上的预训练权重[23],利用预训练权重,可以使模型从较高的起点开始训练,从而以较短的耗时得到更精确的模型。Microsoft COCO 数据集由123 287 张图片构成,包含80 个目标类,且含有海量的小目标,因此预训练权重的使用可以解决无人机航拍图像样本较少的问题。

Table 3 Ablation experiment design表3 消融实验设置
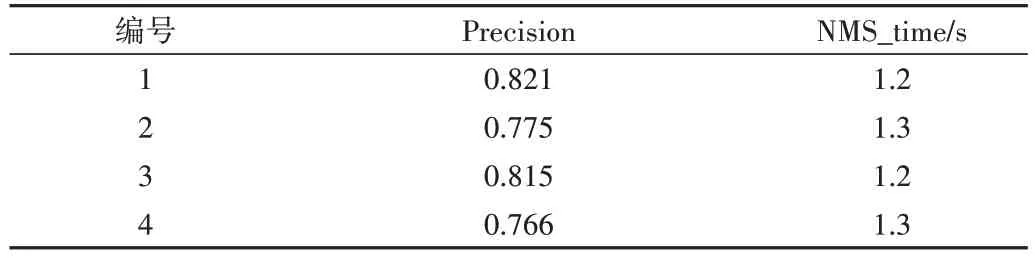
Table 4 Results of ablation experiment表4 消融实验结果
消融实验证明本文提出的改进方法确实在不影响用时的条件下有效地提高了算法精度,且改进算法中的各项改进均产生了积极影响。
5 结语
本文提出一种基于YOLO-v7 的无人机航拍小目标检测改进算法FCL-YOLO-v7,增加了小目标检测层并改进锚框数量与尺度设置,添加CBAM 注意力机制,使用FRe-LU 作为激活函数。在自主构建的无人机航拍图像小目标数据集PCUS-DataSets 上进行对比实验及消融实验,结果证明本文改进算法的性能优于YOLO-v3、YOLO-v5、原始YOLO-v7 算法,精确率较YOLO-v7 提升6.7%。但本文算法也存在不足,如改进方法会提高网络复杂度,增加参数量。下一步工作可改进如下:在保证高检测精度的前提下,将模型轻量化,降低模型参数量与网络复杂度;改进正负样本划分与采样策略,以实现召回率的有效提升;在不同自然环境状况下,继续进行无人机实飞作业,扩充数据集。
猜你喜欢
新世纪智能(数学备考)(2021年9期)2021-11-24 01:14:34
中学生数理化·中考版(2021年3期)2021-07-22 07:41:30
中外文摘(2021年10期)2021-05-31 12:10:40
新世纪智能(数学备考)(2020年9期)2021-01-04 00:25:12
中学生数理化(高中版.高考数学)(2020年9期)2020-10-28 08:43:52
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
当代陕西(2019年10期)2019-06-03 10:12:04
小学生优秀作文(低年级)(2018年6期)2018-05-19 01:54:27
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
作文通讯·高中版(2017年6期)2017-07-10 03:21:34
