
Machine Learning-Based Decision-Making Mechanism for Risk Assessment of Cardiovascular Disease
2024-02-19 12:02ChengWangHaoranZhuandCongjunRao
Cheng Wang,Haoran Zhuand Congjun Rao
1School of Mathematics and Statistics,Hubei University of Education,Wuhan,430205,China
2School of Science,Wuhan University of Technology,Wuhan,430070,China
ABSTRACT
Cardiovascular disease (CVD) has gradually become one of the main causes of harm to the life and health of residents.Exploring the influencing factors and risk assessment methods of CVD has become a general trend.In this paper,a machine learning-based decision-making mechanism for risk assessment of CVD is designed.In this mechanism,the logistics regression analysis method and factor analysis model are used to select age,obesity degree,blood pressure,blood fat,blood sugar,smoking status,drinking status,and exercise status as the main pathogenic factors of CVD,and an index system of risk assessment for CVD is established.Then,a two-stage model combining K-means cluster analysis and random forest (RF) is proposed to evaluate and predict the risk of CVD,and the predicted results are compared with the methods of Bayesian discrimination,K-means cluster analysis and RF.The results show that the prediction effect of the proposed two-stage model is better than that of the compared methods.Moreover,several suggestions for the government,the medical industry and the public are provided based on the research results.
KEYWORDS
CVD;influencing factors;risk assessment;machine learning;two-stage model
1 Introduction
With the development of the national economy and the improvement of people’s living standards,people’s diet and lifestyle have changed greatly,which also brings many health problems,including CVD [1].CVD is a kind of heart or blood vessel disease,also known as circulatory system disease,which is a series of diseases involving the circulatory system such as ischemic heart disease,endocarditis,cardiomyopathy,peripheral artery disease,and so on.CVD is seriously harmful to human health,with high prevalence,high disability rate and high mortality.It has been reported that CVD has become the first cause of death of human beings,with more than 15 million people dying from CVD every year in the world.The number of deaths from CVD will increase by about 6 million in the next 20 years[2,3].
In recent years,although some achievements have been made in the prevention and treatment of CVD,the mortality rate of CVD is still on the rise.Data shows that there are about 290 million people suffering from CVD,and more than 3 million people die from CVD every year in China[4,5].According to research analysis,there are more than 300 factors that may lead to CVD,where the more important factors include age,obesity,high blood pressure,high blood sugar,high blood fat,smoking,drinking,lack of physical exercise,and so on.In addition to the risk of death,the high incidence and mortality of CVD also bring great pressure to patients’individuals,families and society[6,7].
Based on the above background,it has become a general trend to explore the main influencing factors of CVD and the methods to evaluate disease risk.This paper collects risk assessment indicators and actual patient data of CVD,combines statistical models with machine learning methods to quantitatively analyze the main influencing factors of CVD,and establishes a risk assessment system to evaluate the disease risk of CVD.Based on the study results,this paper puts forward some suggestions to the government,the medical industry and the public,respectively,so as to arouse people’s attention to the prevention of CVD,and then take effective measures to jointly improve the prevention and control of CVD.
The contributions of this paper are as follows:
(1) This paper combines the methods of univariate variance analysis and logistics regression analysis to study whether each index has a significant impact on CVD.The obtained results are consistent,which makes the investigation conclusions more real and reliable.
(2) The factor analysis model is adopted to classify the main influencing factors of CVD,and the main influencing factors are divided into basic physical conditions,“three high” diseases and living habits,so as to establish a risk assessment system of CVD.
(3) A new two-stage model combining K-means cluster analysis with RF is proposed to evaluate and predict patients’CVD risk.The empirical analysis results show that the proposed method in this paper is better than that of Bayesian discrimination,traditional K-means cluster analysis and RF,which also provides a new method for risk assessment of CVD.
The rest of this paper is organized as follows.Section 2 provides the literature review.Section 3 identifies the main pathogenic factors of CVD by using the methods of logistics regression analysis and factor analysis,and then establishes a risk assessment system of CVD.In Section 4,a two-stage model based on K-means cluster analysis and RF is proposed to evaluate the risk of CVD,and then the proposed model is compared with Bayesian discriminant analysis,K-means cluster analysis and RF to test the reliability and rationality of the proposed two-stage model.Section 5 provides some suggestions for improving the current situation of prevention and control for CVD according to the results of empirical analysis.Section 6 concludes the paper.
2 Literature Review
In terms of the influencing factors for CVD,Steinberger et al.[8]collected the sample data set of seven cities in North Carolina from 1999 to 2001,fitted the three-stage Bayesian hierarchical model,and concluded that the higher the concentration of PM2.5,the greater the probability of residents suffering from CVD.Ferrandiz et al.[9] used the Spanish Rapid Inquiry System (RIF) to conduct more precise and systematic exposure measurement and disease data collection.Through correlation analysis,they found that magnesium in drinking water had a stronger protective effect on mortality of CVD than calcium.Through statistical analysis of big data,Kannel et al.[10]found that the relative risk of CVD was significantly increased with the increase of blood glucose and lipid concentrations.Rosenlund et al.[11]systematically analyzed the patient population of a hospital through case-control method,and concluded that gender,drinking habits,family genetic history,residential area,air quality and other 10 indicators were the most important influencing factors of CVD.Odden et al.[12]concluded that mental state,environmental factors and physical conditions are the most important risk factors for CVD by using the method of factor analysis.Hunt et al.[13]applied Cox proportional risk regression model to explore the relationship between body mass index(BMI)and the risk of CVD in a rural male population,and concluded that the incidence rate of CVD in the obese population was much higher than that in the normal population.
Similarly,Wu et al.[14]adopted one-way variance analysis and multi-factor logistics regression methods to discuss the current situation and influencing factors of CVD in the elderly population,and concluded that age,smoking history,drinking history and other 7 indicators are the important risk factors for CVD in the elderly.He et al.[15]investigated and analyzed the risk factors related to CVD among citizens in Bao’an District of Shenzhen City through Chi-square test,and established a risk assessment system of CVD.Hou [16] used descriptive statistical analysis,Fisher’s exact probability method and logistics regression analysis to study the status quo and the main risk factors of CVD among bank employees in Changchun City,and sorted the influence degree of each factor.He et al.[17]analyzed the influencing factors of CVD in elderly maintenance hemodialysis patients in a hospital in Chongqing through single-factor and multi-factor logistics regression combining with controlled experiments,and concluded that obesity and hypertension are the main causes of CVD.Jiang et al.[18]extracted 256 patients with diabetes and kidney disease from a hospital in Shanghai for difference analysis,and concluded that both diabetes and kidney disease would increase the probability of CVD.Wang et al.[19]analyzed the risk factors of atherosclerotic CVD in the elderly population by stepwise regression method,and the results showed that age,sleep quality,genetic history,obesity and other 9 indicators may lead to the occurrence of CVD.In recent years,population-based cohort studies that investigate epidemiological factors such as genetic,clinical,environmental,lifestyle,and socioeconomic have been conducted for risk factor identification of CVD[20].
In terms of risk assessment of CVD,many scholars have proposed some quantitative methods based on statistics and machine learning[6,21–23].For example,Kannel et al.[24]created the first risk assessment model of CVD based on Framingham Heart Study,and concluded that nine indicators such as hyperglycemia,hyperlipids and alcohol consumption are the important causes of CVD through case analysis.By collecting research data from 12 countries,European scholars created a risk assessment model for CVD applicable to the European population,which predicted the risk of CVD in the next 10 years through four indicators including gender,age,smoking and drinking[25].In 2008,the World Health Organization(WHO)published the risk prediction chart of CVD in the Prevention and Treatment of CVD,which introduced a new risk assessment model for countries around the world[26].The American Heart Association and the Society of Cardiovascular and Cerebrovascular Diseases put forward the summary cohort formula based on the large community cohort of multi-region and multi-ethnicity,including the indicators of age,gender and diastolic blood pressure,and achieved good prediction effect[27].In 2016,through the study of the latest large cohort data,Professor Gu and his team created the Prediction for ASCVD Risk in China(China-PAR)model to evaluate the 10-year and lifetime risk of CVD.The model takes into account important factors such as age,gender,smoking,alcohol consumption,and congenital genetic disease.It provides an effective tool for improving the protection and management of CVD[28].
In terms of machine learning methods,Polaka et al.[29] used decision tree and RF to classify CVD.Dimopoulos et al.[30]compared K Nearest Neighbors(KNN),decision tree and RF algorithm with traditional scoring models of CVD,and concluded that machine learning methods have better evaluation effect on CVD risk.Chen et al.[31]established a CVD prediction model based on eXtreme Gradient Boosting (XGBoost),and summarized the influence rule of each index according to the research conclusions.Zheng[32]modeled and predicted CVD risk and found that RF,decision tree and logistics regression all have good predictive value,where RF has the best predictive effect.Wang[33] conducted risk assessment on nearly 10 million patients with CVD based on RF and support vector machine,and achieved good evaluation results.Zhang et al.[34]proposed a prediction model of CVD based on feature selection and probabilistic neural network.Compared with other models,this model used fewer features to achieve better prediction results.Liu et al.[35]used the stacking method to combine classification models such as naive Bayes and logistic regression to predict CVD risk,greatly improving the prediction accuracy.Johri et al.[36] proposed a deep learning artificial intelligence framework for multiclass coronary artery disease prediction by using combination of conventional risk factors,carotid ultrasound,and intraplaque neovascularization.
Through the analysis of the above studies,it can be concluded that scholars have achieved a certain harvest in the fields of influencing factors analysis and risk assessment of CVD,but there are still some room for improvement.First of all,the risk assessment system of CVD established in the existing literature is not perfect,and the selected indicators are not systematic.Secondly,although the machine learning methods have been applied in risk prediction of CVD,the selected models and methods are relatively simple and lack of innovation.Therefore,this paper collects sample data through Kaggle website(https://www.kaggle.com/sulianova/cardiovascular-disease-dataset),explores the main influencing factors of CVD through variance analysis,logistics regression analysis and factor analysis,and establishes a risk assessment system of CVD.The effectiveness of machine learning methods in risk assessment of CVD is tested by Bayesian discrimination,and then a new two-stage model combining cluster analysis with RF is established for risk assessment of CVD.Finally,several suggestions are provided based on the research results in order to improve the prevention and control of CVD.
3 Design of Risk Assessment Index System for CVD
In this section,the selected indicators are introduced in detail,and the risk assessment system of CVD is initially established.Then,the selected data are preprocessed,and the single factor analysis of variance is used for preliminary selection of these indicators.
3.1 Preliminary Selection of Indicators for Risk Assessment of CVD
Based on some existing relative work [1–5,37–42],the risk assessment indicators of CVD are selected initially as follows:
(1) Age
The older you get,the more likely you are to develop CVD.Heart muscle cells increase in size with age.This can cause the heart chamber to dilate slightly and the left ventricle to become unfilled,which can lead to heart failure.In addition,with the passage of time,the aging heart and blood vessels will appear subcellular defects.Even if the body maintains a relatively healthy state,it is prone to a decline in cardiovascular function,leading to common problems such as diastolic insufficiency,which increases the risk of CVD[37].
(2) Gender
Relevant studies[3,5]have shown that physiological differences between the sexes may affect the incidence of CVD.The incidence of CVD in females is generally lower than that in males,because female hormones have protective effects on cardiovascular and cerebrovascular diseases.However,other data show that women have slightly lower rates of CVD before menopause,but no significant difference after menopause.
(3) Obesity degree
Obesity is harmful to health in many aspects,especially cardiovascular system damage is the most serious threat to life.For people with long-term obesity,the pressure on the heart is heavier,and the contraction needs excessive force,which leads to the damage of the intima of the blood vessels,the appearance of arteriosclerosis,and the formation of fatty cardiomyopathy.In addition,the massive accumulation of fat in the abdomen of obese people will also cause the disorder of lipid metabolism and glucose metabolism,aggravate oxidative stress and inflammatory response,and the lipotoxic factors in the body will promote the apoptosis of cardiomyocytes,leading to reduced cardiac function,and then lead to heart disease and abnormal heart rate[38].
(4) Blood pressure
High blood pressure is one of the most concerned health problems in this century,and it is also an important cause of CVD.Because of long-term elevated blood pressure,the burden of the heart will be aggravated by pumping enough blood volume,which is prone to myocardial hypertrophy and atrial enlargement,and can also damage vascular endothelial function,thus leading to coronary atherosclerosis and causing coronary heart disease.In addition,blood pressure disease will lead to peripheral vascular resistance,increase the elasticity and brittleness of arterial wall,and secondary increase of blood viscosity,thus increasing the probability of heart disease[39].
(5) Blood fat
Hyperlipidemia is easy to block blood vessels and stimulate blood vessels.Since the function of human myocardium is orderly,when hyperlipidemia occurs,it may lead to myocardial dysfunction,which may lead to hemorrhagic and apoplexy cerebral thrombosis,thus threatening the safety of patients.In addition,studies have also shown that hyperlipidemia may lead to atherosclerosis,vascular embolism and other diseases[40].
(6) Blood sugar
Excessive blood sugar may lead to vascular wall damage,affect blood flow,and increase blood viscosity.In addition,a study by a foreign collaborative group of emerging risk factors found that diabetes has an extremely serious impact on the risk of death from CVD,which can lead to about twice the probability of death from CVD[41].
(7) Smoking status
Smoking is the leading cause of human death worldwide,with data showing that CVD accounts for 40 per cent of all smoking-related deaths.As an important cause of CVD,smoking increases heart rate,reduces cardiac output and coronary blood flow,leads to short-and long-term increases in blood pressure,and significantly increases the risk of ischemic stroke,which in turn has a significant impact on cardiovascular function.
(8) Drinking status
Drinking alcohol will speed up the heartbeat and blood flow of the human body.Excessive alcohol consumption can cause reduced systolic function of the heart muscle,leading to high blood pressure,stroke and secondary heart disease.In addition,long-term alcohol consumption will affect the metabolism of sugars and fats in the body,resulting in elevated triglycerides,obesity and hypertriglyceridemia in patients,thus increasing the risk of CVD.Other studies have shown that there is a causal relationship between alcohol consumption and CVD risk,and the trend is basically linear[42].
(9) Exercise status
Regular physical exercise plays a certain role in preventing CVD.It can improve the function of the cardiovascular system,slow down the heart rate and enhance the contractility of the myocardium,thereby increasing the output of the heart pulse and improving the microcirculation.In addition,physical exercise can also promote the dilation of coronary arteries,increase the number of myocardial capillaries,and improve myocardial ischemia.
In summary,9 factors,i.e.,age,gender,obesity degree,blood pressure,blood fat,blood sugar,smoking status,drinking status and exercise status,are preliminarily selected as evaluation indicators for risk assessment of CVD in this paper.
3.2 Preprocessing for Index Values
3.2.1DataSourcesandStandardization
In this paper,the data are selected from Kaggle site survey report (https://www.kaggle.com/sulianova/cardiovascular-disease-dataset).After eliminating some abnormal data,we get 68241 valid samples from 70000 patients.According to the evaluation indicators obtained in Section 3.1,the original data of each index are standardized and listed as shown in Table 1.
The corresponding indicators of the 9 variables in Table 1 and their meanings are shown in Table 2.
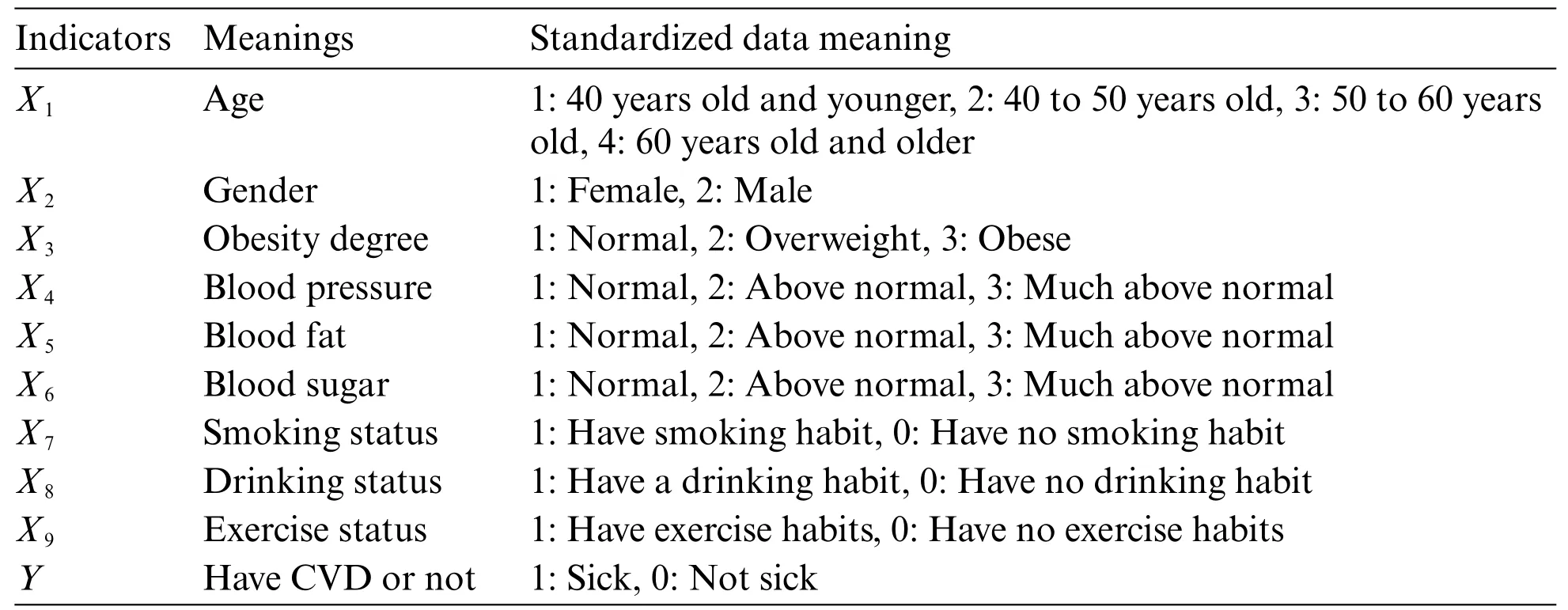
Table 2 : Evaluation indicators and their meanings
3.2.2PreliminaryScreeningofRiskAssessmentIndicatorsviaUnivariateAnalysisofVariance
In this section,the univariate analysis of variance[43–45]is used to analyze the independent test results of the 9 indicators,so as to test whether the indicators have a significant impact on CVD,and eliminate the indicators that have a small impact on CVD.SPSS software is used to conduct univariate analysis of variance on standardized data,and the results are shown in Table 3.

Table 3 : The results of univariate analysis of variance
From Table 3,thePvalue of the significance test of gender is greater than 0.05,which can be considered that gender has no significant effect on CVD.While thePvalue of the significance test of age,obesity degree,blood pressure,blood fat,blood sugar,smoking status,drinking status and exercise status are all less than 0.05,which means they all pass the significance test.Therefore,8 factors,i.e.,age,obesity degree,blood pressure,blood fat,blood sugar,smoking status,drinking status and exercise status are preliminarily determined as the influencing factors of CVD.
3.3 Identification of Main Pathogenic Factors Using Logistic Regression and Factor Analysis
Based on the 8 influencing factors of CVD and the standardized data obtained in Section 3.2,the method of logistics regression analysis is firstly used to further verify the results of univariate analysis of variance.Secondly,a factor analysis method is applied to classify the evaluation indicators obtained,so as to identify the main pathogenic factors of CVD and establish the final risk assessment index system of CVD.
3.3.1TestofInfluencingFactorsUsingLogisticsRegressionAnalysisModel
In order to further verify the reasonability of the influencing factors obtained from univariate analysis of variance,a logistics regression analysis model is established,and 8 indicators that have a significant impact are taken as independent variables for testing.Different from the traditional linear regression model,the dependent variables of logistics regression model are discrete,so the independent variable cannot be used directly for the regression of dependent variable,but can be used to regress the probability value of the dependent variable.
The value of the dependent variableyi(whether to suffer from CVD) in the logistics regression model is only 0 or 1.Pis set to represent the probability ofy=1(getting sick),andQis the probability ofy=0(not sick),which satisfiesQ=1-P.Theminfluencing factors of CVD are denoted as the vectorX=(x1,x2,...,xm)′,and the specific relationship betweenyandXis expressed by
By logit transformation for Eq.(1),the final logistics regression model can be expressed by
wherem=8,andβ0,β1,...,βmare the estimated parameters of the influencing factors of CVD.
The standardized data is substituted into the logistics regression analysis model(2).The software of SPSS is used to solve the model(2),and the results are shown in Table 4.

Table 4 : Results of logistics regression analysis
As can be seen from Table 4,the 8 indicators all have passed the significance test of logistics regression analysis model,indicating the reliability of the results obtained by univariate analysis of variance.Moreover,according to the results of regression coefficients,we can conclude that people with older age,obesity,hypertension,high blood fat,high blood sugar,smoking and drinking habits,and no exercise habits are more likely to suffer from CVD.
3.3.2IdentificationofMajorPathogenicFactorsofCVDUsingFactorAnalysisModel
In order to find out the root cause of CVD and formulate reasonable preventive measures,this paper establishes a factor analysis model[46–48].Based on the mutual relationship of the influencing factors of CVD,the influential factors with high correlation are grouped into one class to obtain a common factor,and finally achieve the effect of dimensionality reduction.According to the above basic ideas,the eight influencing factors are systematically classified through data preprocessing,Kaiser-Meyer-Olkin(KMO)test and Bartlett’s test of sphericity[49,50],factor extraction and factor rotation,and factor score calculation,so as to form an evaluation system of CVD.The steps of factor analysis model are given as follows:
Step 1:Data preprocessing
According to the results of logistics regression analysis,it can be concluded that the sample data corresponding to the exercise status factor in the data set is negatively correlated with the sample data corresponding to the CVD,while the sample data corresponding to the other factors is positively correlated with the sample data corresponding to the CVD.In order to facilitate the study of cardiovascular evaluation system,the data set corresponding to exercise status is taken as a negative sign,so that all factors have a positive effect on CVD risk.
Step 2:KMO test and Bartlett’s test of sphericity
In order to test whether there is correlation between various influencing factors,and further explain the feasibility of factor analysis,the KMO test and Bartlett’s test of sphericity are used on sample data.
The ideas and steps of KMO test[49]are as follows.KMO test statistic is used to compare simple correlation coefficient and partial correlation coefficient between variables.It is mainly used in factor analysis of multivariate statistics.The KMO statistic is between 0 and 1.When the sum of the squares of the simple correlation coefficients among all variables is much larger than the sum of the squares of the partial correlation coefficients,the closer the KMO value is to 1,which means that the correlation between variables is stronger,and the original variables are more suitable for factor analysis.When the sum of squares of the simple correlation coefficients among all variables is close to 0,the closer the KMO value is to 0,which means that the correlation between variables is weaker and the original variables are less suitable for factor analysis.
The ideas and steps of Bartlett’s test of sphericity [49,51] are as follows.Bartlett’s spherical test is a test method to test the degree of correlation between various variables,which is generally carried out before factor analysis to determine whether variables are suitable for factor analysis.Bartlett’s sphericity test is based on the correlation coefficient matrix of variables.Its correlation coefficient matrix of null hypothesis is an identity matrix,that is,all elements on the diagonal of the correlation coefficient matrix are 1 and all non-diagonal elements are zero.The statistics of Bartlett’s sphericity test are obtained from the determinant of the matrix of correlation coefficients.If the value is large,and its corresponding associated probability value is less than the significance level in the user’s mind,then the null hypothesis should be rejected and the correlation coefficient should be considered as an identity matrix.That is,there is correlation between the original variables,which is suitable for factor analysis.On the contrary,it is not suitable for factor analysis.
By implementing the KMO test and Bartlett’s test of sphericity,the test results are shown in Table 5.

Table 5 : Results of KMO test and Bartlett’s test of sphericity
It can be seen from Table 5 that thePvalue of the significance test is less than 0.05,so the null hypothesis is rejected,indicating that there is a correlation between different influencing factors of CVD,so the factor analysis can be conducted.
Step 3:Factor extraction
The 8 impact factors are recombined,the same type of impact factors is inductively combined,and finally several common factors with the greatest explanatory power are selected.The results are shown in Table 6.
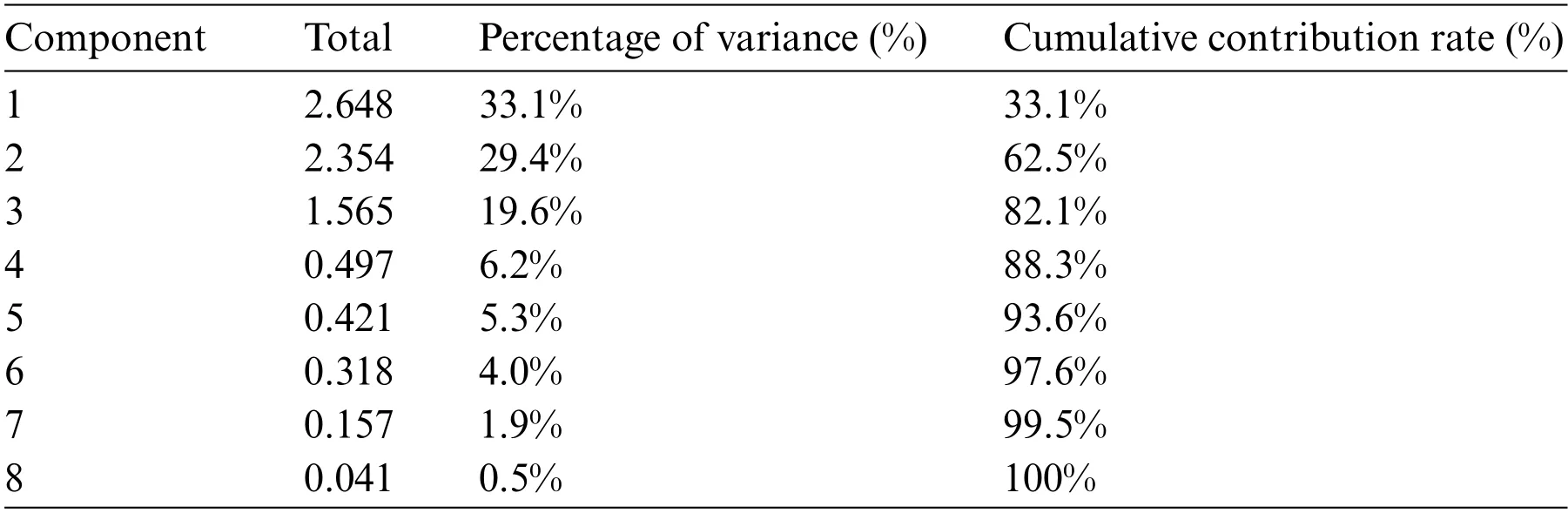
Table 6 : Feature extraction
From Table 6,the eigenvalue of the first three factors exceeds 1 and the cumulative contribution rate reaches 82.1%,indicating that these three common factors have been able to cover most of the information of the eight influencing factors of CVD.Therefore,the number of common factors selected by factor analysis in this paper is 3.
Step 4:Factor rotation
In order to make the results easier to understand,this paper uses the maximum variance method to rotate the load matrix and increase the difference between the loads of various factors,which makes the specific meaning of the load matrix clearer,so as to identify the main pathogenic factors of CVD.
SPSS software is used to calculate,and the final factor load matrix is shown in Table 7.

Table 7 : Factor load
As can be seen from Table 7,common factorF1has large loading values onX3(blood pressure),X4(blood fat)andX5(blood sugar),which can be regarded as “three high” disease factors.The loading values of common factorF2onX6(smoking status),X7(drinking status)andX8(exercise status)are large,which can be regarded as lifestyle factors.Common factorF3has large loading values onX1(age)andX2(obesity degree),which can be regarded as basic body condition factors.
Step 5:Calculate the factor score
The factor score is estimated by the regression method,and the proportion of variance contribution rate of each common factor in the total variance contribution rate of the three common factors is taken as the weight for weighted summary,i.e.,
Therefore,the comprehensive scores of 68241 patients in CVD risk are obtained,and the results are shown in Table 8 (SF1,SF2 and SF3 represent the scores of each sample on the three common factors,respectively).

Table 8 : The comprehensive score of each patient
From Table 8,the comprehensive score of the samples suffering from CVD is higher,while the comprehensive score of the samples without CVD is lower,indicating that the factor score is scientific to a certain extent.
Based on the above analysis,a risk assessment index system of CVD is established,as shown in Fig.1.
4 Risk Assessment of Two-Stage Model via K-Means Clustering and RF
Based on the standardized data and the final influencing factors of CVD obtained in Section 3,a two-stage model integrating K-means clustering analysis and RF is proposed to evaluate the risk of CVD,and the empirical analysis based on the sample data of 68241 patients in a Kaggle dataset is conducted.Moreover,the evaluation effect obtained by the two-stage model is compared with the traditional methods including Bayesian discrimination,K-means cluster analysis and RF,so as to verify the reliability of the two-stage model in improving the effect of risk assessment of CVD,and the feasibility of machine learning method in risk assessment of CVD.
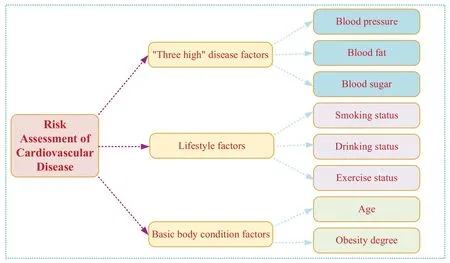
Figure 1 :Risk assessment index system of CVD
4.1 K-Means Cluster Analysis
To evaluate the CVD of each patient,68241 patients could be classified according to the relevant data of each indicator through K-means cluster analysis[52–54].The main idea is to selectKpatients in the data set as the initial center of each class according to certain strategies,and then divide the remaining patients into the class closest to theKpatients,so as to complete a division.However,theKclasses formed are not necessarily the best division,so it is necessary to recalculate the central point of each new class,and then re-divide until the results of each division are consistent.The specific algorithm flow is as follows:
(1) AnyKpatients from thenpatients are selected as the initial clustering center.
(2) Calculate the distance between the remaining patients and theKpatients,and divide them into the closest category.
(3) The center of each class is recalculated to obtainKnew clustering centers.
(4) Cycle the above Steps(2)and(3)until the results of each partition no longer change.
The standard of stable location of clustering center is:make the error of clustering center change reach a certain threshold or reach a certain number of iterations,and the error sum of squares is:
wherecirepresents thei-th classification,i=1,2,...,k,andxijrepresents the indicator data of thej-th patient in thei-th classification.
4.2 Random Forest
In addition to K-means cluster analysis,the RF model can be used to evaluate the patients’CVD risk.This model obtainsnsample sets throughnrandom sampling of patient samples.For each sample set,the decision tree model can be trained independently.For the results ofndecision tree models,the method of simple majority voting is used to determine the final prediction results[55–57].It should be noted that thendecision tree models are independent of each other,but not completely independent.There can be intersection between training sets.
Decision tree is the basis of establishing the RF model,which is a top-down tree classification algorithm for patient sample data.It is composed of nodes and directed edges.Nodes are divided into root nodes,child nodes and leaf nodes.The root node represents the first traversed and most important influencing factors of CVD,each child node represents other influencing factors that may be traversed,and leaf node represents the category of patients eventually assigned.Starting from the top root node,all patients are gathered together.After the division of the root node,patients are assigned to different sub-nodes,and then further divided according to the influencing factors in the sub-nodes until all patients are respectively classified into a certain category(namely leaf node)[58,59].
In order to select appropriate influencing factors of CVD and construct decision tree,feature selection is needed.Its function is to select the factors that have a great influence on the decision tree algorithm from the 8 factors affecting CVD,so that the patient samples contained in the leaf nodes of the decision tree belong to the same category as far as possible,even if the nodes are of higher “purity”.
Gini coefficient is usually used in decision tree to measure node impurity,which reflects two patients randomly selected from the data set with different probabilities marked by their categories.The calculation formula is as follows:
wherecis the number of classes,tis the node position,p(i|t)is the frequency of the classidistribution,and the Gini coefficient value is in the range of[0,1].
The implementation process of RF mainly includes the following steps:
(1)csamples are randomly selected from the original 68241 patient samples as the training set,and the remaining samples as the test set.
(2) A new patient data set is obtained by randomly extractingmsamples from patient training setCthrough sampling with retractions.
(3) A certain number of influencing factors are randomly selected from the original eight influencing factors of CVD through sampling without retracting to form a new feature subspace on which a decision tree was established.
(4) Repeat Steps (1) and (2)ntimes to generatensample setsD1,D2,...,Dnandndecision tree modelsT1,T2,...,Tn.
(5) Thendecision trees are used to independently classify the test set of patient samples,and the final prediction results are determined based on the classification results combined with the majority voting mechanism[56].Among them,the classification prediction result of the sample test set can be expressed by Eq.(6):
wherehiis the basic classification model of a single classification tree,andYis the output variable,namely whether to suffer from CVD.
4.3 Two-Stage Model Integrating K-Means Clustering Analysis and Random Forest
It can be concluded from the above analysis that the risk of CVD can be evaluated by K-means cluster analysis or RF model.However,the K-means clustering analysis is an iterative method,only the local optimal solution can be obtained.In addition,due to the large number of influencing factors in this paper,the RF may reduce the prediction accuracy of the model due to improper feature selection.In order to improve the effect of risk assessment of CVD,a two-stage model that integrates K-means cluster analysis and RF is proposed in order to provide a new method for machine learning in risk assessment of CVD.The specific process is as follows:
(1) A K-means cluster analysis is performed on 68241 patients,and the samples are divided intoKcategories.
(2) Comparing factor scores,theMgroup with the highest score is classified as patients,while theMgroup with the lowest score is classified as non-patients.
(3) The remainingK-2Msample set is reorganized to obtain a new patient data set,and then the RF model is used for discrimination and classification.
(4) The final risk assessment results of CVD are obtained by combining the results of K-means clustering analysis and RF.
4.4 Empirical Analysis
4.4.1InitialClassificationBasedonK-MeansClusterAnalysis
Combining with 8 influencing factors,the samples are divided into 4 categories by K-means clustering analysis method.Through repeated iterations with SPSS software,the final 4 clustering centers are obtained,as shown in Table 9.
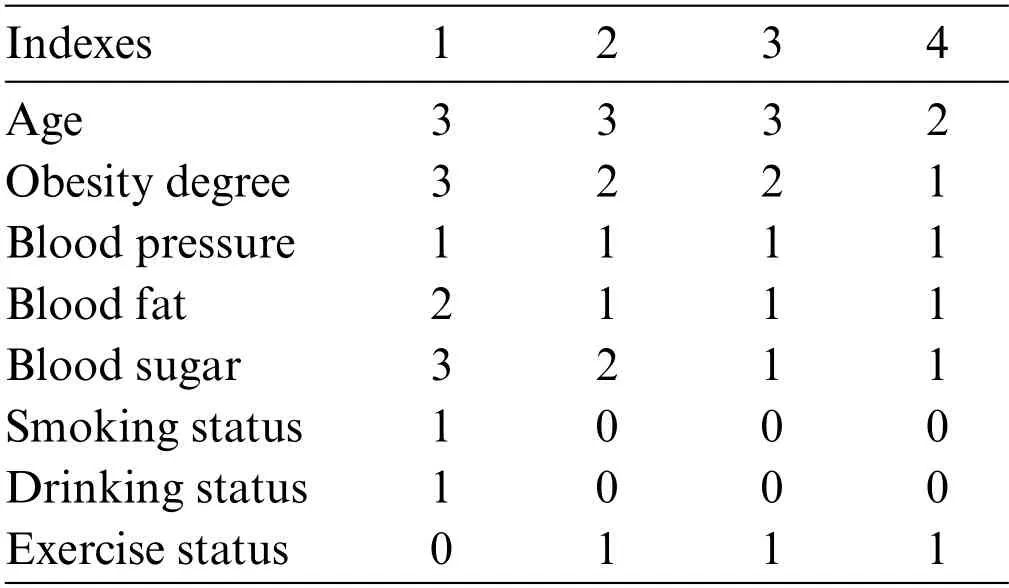
Table 9 : The clustering centers
After the initial cluster analysis,7682 patients are classified as class 1,26241 as class 2,8408 as class 3,and 25910 as class 4.Combined the clustering center with the factor scores obtained in Section 3,it can be seen that patients in the first category are generally older,seriously obese,have high blood sugar content,have smoking and drinking habits and lack of exercise,so patients in the first category are judged as patients with CVD.In addition,it can be found that the fourth type of patients are relatively young,normal physical indicators,no smoking and drinking habits,and often exercise,so the fourth type of patients are judged as non-CVD patients.Among them,the misjudgment matrix of the first and fourth samples is shown in Table 10.

Table 10 : False judgment matrix of cluster analysis
From Table 10,the initial prediction accuracy of K-means clustering is 75.5%.Moreover,it can be found that the CVD risk of patients in the second and third categories obtained by cluster analysis is roughly between the first and fourth categories,which is difficult to distinguish.To further evaluate the CVD risk of these two groups of patients,a total of 34649 patients from the two groups were combined into a new data set,and RF is used for re-prediction.
4.4.2ReclassificationBasedonRF
Step 1:Parameter determination
In order to avoid problems such as excessive error rate and poor model fitting,the two most important parametersmtryandntreeshould be determined before establishing the RF model.mtryis the number of characteristic variables of the decision tree,andntreeis the number of decision tree trees.By using R software,when the number of selected indicators(mtry)ranges from 3 to 8,the correctness rate of RF judgment results changes with the increase ofntree,as shown in Fig.2.

Figure 2 :Prediction accuracy with parameter change
According to the results shown in Fig.2,when the number of randomly selected indicators is 6 and the decision tree is 250(the maximum value is set),the average decision accuracy rate of the sample reaches the highest,which is 0.916.Thus,we choosemtry=6 andntry=250.
Step 2:Model implementation
Setmtry=6,ntry=250,integrate the remaining 34649 samples,divide them into test set and training set(sample numbers are 27719 and 6930,respectively)in a ratio of 8:2,and substitute them into RF for judgment.The predicted results are shown in Table 11.

Table 11 : Prediction accuracy by RF
After the prediction,the prediction results of 31073 patients are consistent with the actual situation,and the classification results are obtained by combining K-means clustering analysis.Among 68241 patients,57249 patients are correctly predicted,and the prediction accuracy of the two-stage model is 83.9%,achieving a good prediction effect.The effectiveness of machine learning method in risk assessment of CVD is further verified.
Step 3:Ranking the importance of indicators
In the stochastic forest model,IncNodePurityis an important reference index for ranking the importance of input variables,which can be used as a standard to measure the interpretation degree of characteristic variables to dependent variables.The greater the value,the greater the influence of input variables on the model.By using theRsoftware,the importance ranking of the 8 indicators is shown in Table 12.

Table 12 : Ranking the importance of indicators
From Table 12,theIncNodePurityvalues of blood pressure,blood fat,age and obesity degree are higher,indicating that these indicators are the most important factors affecting CVD.Among them,high blood pressure,high blood fat,old age,body fat population has a higher probability of CVD.Meanwhile,combined with the results of logistics regression analysis,it is found that the order of regression coefficients is basically consistent with the results of RF,which confirms the reliability of the results of logistics regression model.
4.5 Comparison of Models
In order to further verify the efficiency of the prediction results of the two-stage model combining K-means cluster analysis and RF,this paper compares the two-stage model with the methods of Bayesian discriminant analysis,K-means cluster analysis and RF.
4.5.1BayesianDiscriminantAnalysis
Bayes discriminant analysis[60]is a commonly used discriminant method,which considers prior probability and misjudgment loss,respectively,and takes the maximum probability of an individual belonging to a certain class(or the value of a certain class of discriminant function)or the minimum total average loss of misjudgment as the criterion.
LetG1,G2,...,Gkbekpopulations,and their prior probabilities beq1,q2,...,qk,respectively.The density function of each population is denoted asp1(x),p2(x),...,pk(x),respectively,xis a patient sample,and the posterior probability of the patient from thek-th population is:
Ifp(j/x)=thenxis judged as thej-th population.
In addition,the concept of minimum misjudgment loss can also be used as a discriminant function.The average loss ofxwrongly judged as thej-th population is defined as:
whereL(g/j) is the loss function,which represents the loss of misjudging patients from thej-th population to thegpopulation.Wheng=j,we haveL(g/j)=0.Wheng/=j,L(g/j)>0,and the discriminant criteria are established as follows:
WhenE(g/x)=xis judged as theg-th population.
The sample data sets corresponding to the 8 indicators are substituted into the software of SPSS for Bayesian discriminant analysis,and the classification function coefficients are obtained as shown in Table 13.
Combined with Table 13,two types of linear discriminant functions can be obtained:
Normal group:
Diseased group:
The patient sample data is substituted into the linear discriminant function for discrimination,and the discriminant results of 68241 patients are obtained,as shown in Table 14.

Table 14 : Bayesian discriminant results
After sorting out the discriminant data,the wrong judgment matrix can be obtained,as shown in Table 15.

Table 15 : The wrong judgment matrix
According to the misjudgment matrix in Table 15,among the actual 34457 patients with non-CVD,27330 are correctly identified and 7127 are wrongly identified as patients with CVD.While among the actual 33784 patients with CVD,21712 are correctly identified and 12072 are wrongly identified as patients with non-CVD.To sum up,the accuracy of Bayes discrimination is
The calculation results show that the prediction accuracy of Bayes discriminant method is 71.9%,which means the prediction effect is mediocre.
4.5.2ComparisonofExperimentResults
In this paper,accuracy(acc),precision(pre),recall(rec)andF1-scoreare adopted to evaluate the accuracy of model classification[56,61–63].The specific calculation formulas are as follows:
whereTP,TN,FPandFNrepresent the number of true patients,true non-patients,false patients and false non-patients,respectively.
The accuracy,precision,recall andF1-scoreof the two-stage model,Bayesian discriminant analysis,K-means clustering analysis and RF are calculated,respectively,and the results are shown in Table 16.
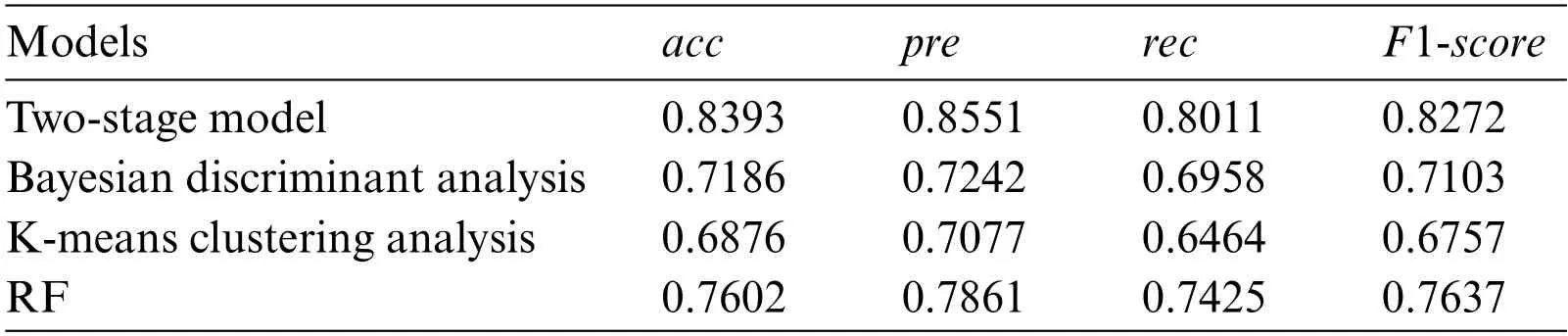
Table 16 : Comparison results of models
From Table 16,the accuracy rate,precision rate,recall rate andF1-scoreof the two-stage model are superior to Bayesian discriminant analysis,traditional K-means clustering analysis and RF model.Thus,the two-stage model combining K-means cluster analysis with RF can effectively improve the effect of predicting CVD risk,which also provides a new method for evaluating CVD risk.In addition,Bayesian discriminant analysis,K-means cluster analysis and RF model also achieve good prediction results,which fully demonstrates the scientific nature of machine learning methods in risk assessment of CVD.
4.6 Test and Improvement of Two-Stage Model
In Section 4.4,K=4 andM=1 are set,respectively,and the samples are divided into four categories by K-means clustering analysis method.The first category with the highest factor score is classified as CVD patients,and the first category with the lowest factor score is classified as non-CVD patients.The remaining two categories are further evaluated by RF model,which achieved good prediction effect.In order to further test the effectiveness of the two-stage model and explore a scheme to make the prediction results more accurate,different parameters are set forKandM.The results of the prediction accuracy changing with the parameters are shown in Table 17.
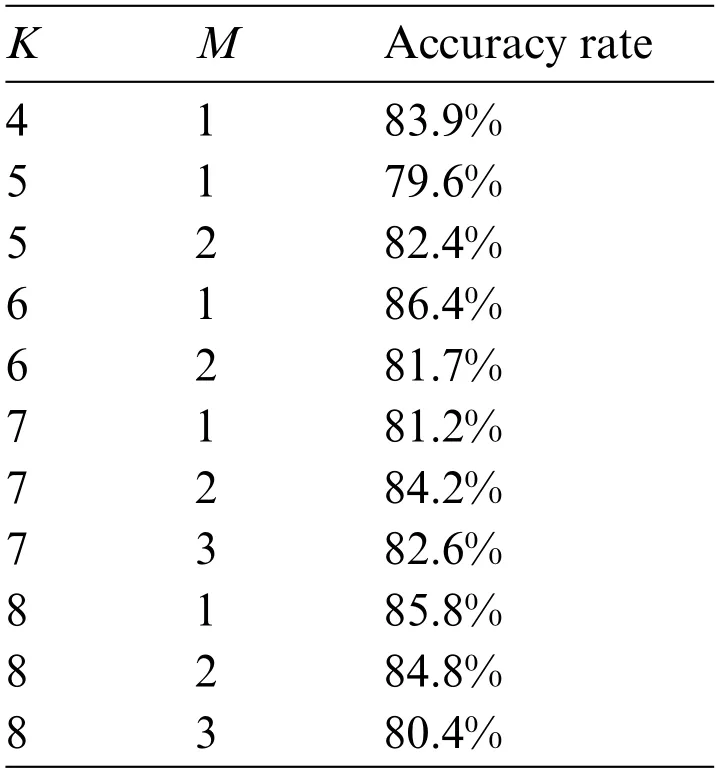
Table 17 : Variation of prediction accuracy with parameters in two-stage model
As can be seen from Table 17,whenK=6 andM=1,the prediction accuracy of the two-stage model reaches the highest 86.4%.Therefore,the operation of the two-stage model is modified as follows:First,the sample set is divided into 6 categories by K-means clustering analysis method,and the category 1 with the highest factor score is classified as patients with CVD,while the category 1 with the lowest factor score is classified as patients with non-CVD.Secondly,the remaining 4 types of samples are integrated and the RF model is used for re-prediction.
By using the softwares of SPSS and R,the prediction accuracy of single K-means clustering analysis and RF is 68.8% and 76.0%,respectively.Compared with the results in above Table 17,it is found that the prediction accuracy of two-stage model is better than that of single K-means clustering analysis,RF and Bayesian discrimination.
5 Result Analysis and Suggestions
In Sections 3 and 4,the main influencing factors and risk assessment of CVD are studied respectively.In terms of influencing factors of CVD,the univariate analysis of variance and logistics regression analysis are made firstly.The results show that the factors of age,obesity degree,blood pressure,blood fat,blood sugar,smoking status,drinking status and exercise status are the influencing factors of CVD,among which older age,obesity,hypertension,hyperlipidemia,high blood glucose,smoking and drinking habits,no exercise habits of people are more prone to CVD.Secondly,combined with the regression coefficient and RF results,it was concluded that the degree of influence on the risk of CVD from large to small is blood pressure,blood fat,age,obesity degree,blood sugar,exercise status,smoking status and drinking status.Finally,through the factor analysis model,age and obesity degree are classified as basic physical condition factors,blood pressure,blood sugar and blood fat as “three high” disease factors,smoking status,drinking status and exercise status as lifestyle factors,and the final risk assessment system of CVD is obtained.These conclusions on influencing factors of CVD we obtained by quantitative method is consistent with the cognition of the causative factors of CVD in our daily life.In terms of risk assessment for CVD,combined with 8 influencing factors obtained by Section 3,the risk of CVD of samples is evaluated and predicted by a new twostage model,and it is concluded that the proposed two-stage model achieved better prediction effect then that of Bayesian discrimination,K-means clustering analysis,and RF,which also provides a new method for risk assessment of CVD.
Based on the above research results,the countermeasures and suggestions on how to scientifically prevent CAD are put forward from the three levels of the government,the medical industry and the public.
(1) From the perspective of government
According to the study results in this paper,smoking,drinking and lack of physical exercise are the main causes of CVD.In view of the above results,the government needs to take targeted measures to reduce the impact of these factors on CVD.
First,make great efforts to popularize health education and improve the health quality of the whole people.It can be seen from the results of logistics regression analysis in Table 4 that the multiple factors such as physical conditions and living habits can lead to the occurrence of CVD.Therefore,the government needs to establish a sound health education system,carry out different forms of CVD publicity and education through media channels,vigorously popularize the harm and prevention knowledge of CVD,enhance the public’s awareness and understanding of CVD,and then prevent diseases by improving their lifestyle.
Second,improve the policy environment and people’s living habits.The results of logistics regression analysis in Table 4 show that smoking and drinking will cause the occurrence of CVD.Therefore,the government should introduce policies to strengthen the control of smoking in public places and increase the punishment for smoking in public places.At the same time,tax policies on tobacco and alcohol should be improved,prices of tobacco and alcohol should be appropriately raised,and harmful smoking and alcohol consumption should be reduced.
Third,build a healthy living environment and promote the development of national sports.As can be seen from Table 12,lack of physical exercise plays an important role in the causes of CVD.In order to promote the public to carry out sports,the government can build fitness trails,health theme parks and other sports facilities,use the existing resources to create a good environment for sports,so that more people have the opportunity to participate in sports,so as to better implement the policy of national sports.
Fourth,use science and technology to accelerate the integration of emerging medical and Internet achievements.According to the empirical analysis results in Section 4.4,the two-stage model based on machine learning proposed in this paper has good decision support for improving the evaluation effect of CVD.Therefore,it is necessary for the government to make full use of the current advanced science and technology,promote the deep integration of mobile Internet,cloud computing,big data and medical industry,and make full use of emerging technologies to prevent CVD.
(2) From the perspective of the medical industry
According to the results of this study,hypertension,hyperlipidemia,hyperglycemia,obesity and other problems will increase the probability of CVD in the public.Therefore,the medical industry should be targeted to these groups of key protection.
First,implement community-level prevention and control and intensify monitoring of high-risk groups.According to the empirical analysis results in Section 4.4,the machine learning algorithm is scientific in predicting the risk of CVD.Therefore,the medical industry should reach into urban communities and rural areas and set up pilot public health services.In addition,collect public health data,establish health records,predict high-risk groups prone to CVD based on risk factors that may cause CVD,conduct targeted health publicity and education for high-risk groups,provide specific guidance on preventive measures,and urge them to maintain reasonable living habits,so as to reduce the level of risk factors.To achieve the prevention of CVD.
Second,select professionals and set up prevention and control teams.According to the empirical analysis results in Section 4.4,the two-stage model proposed in this paper can effectively improve the prediction accuracy of CVD.Therefore,the medical industry can select outstanding personnel in the industry,set up a CVD prevention and control team,strengthen professional knowledge training and necessary practical training,and enhance their ability to predict the risk of CVD through the investigation and analysis of high-risk groups of CVD,so as to reserve talents for the prevention and control of CVD.
Third,expand consultation services and carry out personalized health intervention.As can be seen from Fig.1,living habits,“three high” diseases and basic physical conditions are the main pathogenic factors of CVD.Therefore,it is necessary for medical institutions to open counseling services for smoking cessation and alcohol abstinence to advocate the public to quit smoking and alcohol abstinence and maintain good living habits.Meanwhile,combined with the risk assessment method proposed in this paper,the risk assessment and intervention guidance can be gradually carried out for patients with high-risk groups such as obesity,hypertension,hyperglycemia and hyperlipidemia,and consultation services such as reasonable diet,fitness and disease prevention can be provided.
Fourth,deepen the care institutions and promote the integrated development of medical and nursing care.The results of logistics regression analysis in Table 4 show that the elderly is an important group of people suffering from CVD.Therefore,medical institutions need to actively cooperate with pension institutions to establish and improve telemedicine service stations for all the elderly.In addition,community-level medical institutions are encouraged to establish a relationship of assistance with the families of the elderly,and provide medical services such as regular physical check-ups,management of health records and popularizing methods for keeping fit,so as to provide regular medical assistance to the elderly.
(3) From the perspective of the public
The results in this paper showed that the risk factors of CVD mainly came from basic physical conditions,“three high” diseases and poor living habits.Therefore,the public should improve their living habits and pay attention to physical check-ups.
First,eat a reasonable diet to avoid obesity.The results of logistics regression analysis in Table 4 show that obesity is an important factor causing CVD.Therefore,the staple food of the general public should be cereals,and a certain number of fresh vegetables and fruits should be consumed every day.At the same time,the public should try to avoid or eat less fatty meat,animal oil and animal offal,eat more legumes and put an end to overeating.In addition,the public can drink a small amount of fresh milk every day,but try to avoid some milk products with high oil content.
Second,take care of health by having regular physical examination.Table 12 shows that hypertension,hyperlipidemia and hyperglycemia are the most important risk factors for CVD.Therefore,the general public,especially the elderly,need to go to the hospital for regular physical examination,especially to pay attention to the condition of blood pressure,blood fat and blood sugar.If a certain indicator is too high,the patients need to pay enough attention to it.It is best to have physical therapy under the guidance of a doctor to reduce the risk of developing CVD.
Third,give up smoking and drinking and keep healthy.As can be seen from Table 4,both smoking and drinking are likely to cause CVD.Therefore,it is necessary for the public to strengthen the study of medical and health,so as to increase the awareness of the harm of tobacco and alcohol to CVD,do not smoke,do not drink,so as to maintain good health.
Fourth,insist on exercise to enhance physical fitness.As can be seen from Table 4,moderate physical exercise can reduce the probability of CVD to some extent.Therefore,the public can use their spare time to go to parks,playgrounds,gyms and other places for physical exercise,which should ensure more than 30 min a day,but should not be too long.Through the accumulation of long-term exercise,you can improve your physical fitness,thereby improving immune function and significantly reducing the risk of CVD.
6 Conclusions
With the prevention and control of CVD as the research background,this paper firstly collected patient data through Kaggle platform,selected evaluation indicators of CVD on the basis of reading a large number of literatures,and initially established a risk assessment system of CVD.Then,the univariate analysis of variance and logistics regression analysis are used to test the impact of each indicator on CVD.Combined with the factor analysis model,the indicators that passed the significance test are classified to obtain the final risk assessment system of CVD.Secondly,a new two-stage model integrating K-means clustering analysis and RF is proposed to evaluate the risk of CVD,and the comparative analysis is made to verify the effectiveness and superiority of the proposed two-stage model.Finally,based on the results of empirical analysis,several suggestions are provided for the government,the medical industry and the public to jointly improve the prevention and control of CVD.
The work in this paper still has several limitations,for example,the final risk assessment system of CVD only includes basic physical conditions,“three high” diseases and living habits,while CVD may also be affected by other factors,such as environment.In addition,this paper evaluated and predicted the risk of CVD in samples through the two-stage model combining K-means clustering analysis and RF,but it only conducted the cases whenK=4,6,8,and lacked comprehensiveness in parameter selection.From these limitations,in order to make the risk assessment results of CVD more valuable,future work should make in the following aspects:(i)In the future investigation of influencing factors of CVD,a more complete evaluation system should be established and more comprehensive factors should be quantitatively analyzed.(ii)More parameters can be added to the parameters of the twostage model in future work,so as to find the combination methods with the best prediction effect.(iii) It is also our future research direction to propose some novel integrated models based on the combination of deep learning and statistical methods for CVD risk assessment.
Acknowledgement: The authors wish to express their appreciation to the reviewers for their helpful suggestions which greatly improved the presentation of this paper.
Funding Statement: This work is supported by the National Natural Science Foundation of China(Nos.72071150,71871174).
Author Contributions:The authors confirm contribution to the paper as follows:study conception and design:C.Wang,H.Zhu,and C.Rao;data collection:H.Zhu;analysis and interpretation of results:C.Wang and C.Rao;draft manuscript preparation:H.Zhu and C.Wang.All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The datasets generated and analyzed during the current study are available in the [Kaggle site survey report] repository,[https://www.kaggle.com/sulianova/cardiovascular-disease-dataset].
Conflicts of Interest:The authors declare that they have no conflicts of interest to report regarding the present study.
 Computer Modeling In Engineering&Sciences2024年1期
Computer Modeling In Engineering&Sciences2024年1期
- Computer Modeling In Engineering&Sciences的其它文章
- Review of Recent Trends in the Hybridisation of Preprocessing-Based and Parameter Optimisation-Based Hybrid Models to Forecast Univariate Streamflow
- Blockchain-Enabled Cybersecurity Provision for Scalable Heterogeneous Network:A Comprehensive Survey
- Comprehensive Survey of the Landscape of Digital Twin Technologies and Their Diverse Applications
- Combining Deep Learning with Knowledge Graph for Design Knowledge Acquisition in Conceptual Product Design
- Meter-Scale Thin-Walled Structure with Lattice Infill for Fuel Tank Supporting Component of Satellite:Multiscale Design and Experimental Verification
- A Calculation Method of Double Strength Reduction for Layered Slope Based on the Reduction of Water Content Intensity