
EfficientShip:A Hybrid Deep Learning Framework for Ship Detection in the River
2024-02-19 12:01HuafengChenJunxingXueHanyunWenYurongHuandYudongZhang
Huafeng Chen,Junxing Xue,Hanyun Wen,Yurong Hu and Yudong Zhang
1School of Computer Engineering,Jingchu University of Technology,Jingmen,448000,China
2School of Computer Science,Yangtze University,Jingzhou,434023,China
3School of Computing and Mathematic Sciences,University of Leicester,Leicester,LE1 7RH,UK
ABSTRACT
Optical image-based ship detection can ensure the safety of ships and promote the orderly management of ships in offshore waters.Current deep learning researches on optical image-based ship detection mainly focus on improving one-stage detectors for real-time ship detection but sacrifices the accuracy of detection.To solve this problem,we present a hybrid ship detection framework which is named EfficientShip in this paper.The core parts of the EfficientShip are DLA-backboned object location (DBOL) and CascadeRCNN-guided object classification (CROC).The DBOL is responsible for finding potential ship objects,and the CROC is used to categorize the potential ship objects.We also design a pixel-spatial-level data augmentation(PSDA)to reduce the risk of detection model overfitting.We compare the proposed EfficientShip with state-of-the-art(SOTA)literature on a ship detection dataset called Seaships.Experiments show our ship detection framework achieves a result of 99.63%(mAP)at 45 fps,which is much better than 8 SOTA approaches on detection accuracy and can also meet the requirements of real-time application scenarios.
KEYWORDS
Ship detection;deep learning;data augmentation;object location;object classification
1 Introduction
With the continuous advancement of technology and the rapid development of industrial production,international trade is gradually increasing.The market of the shipping industry is also flourishing.In order to ensure the safety of ships and promote the orderly management of ships,satellites(generate SAR images)are used to monitor ships at sea[1]and surveillance cameras(generate optical images)are adopted for tracking ships in offshore waters[2,3].At the technical level,with the maturity of artificial intelligence technology[4],computer-aided methods of ship classification,ship instance segmentation and ship detection from images are studied to reduce the burden on human monitors[5].We focus on ship detection based on optical images generated by surveillance cameras in this paper.
In recent years,deep learning-based ship detection has become a hot research area [6–8].Sea ship detection is one of the general object detections [9].Researches on deep learning based object detection can be roughly split into two classifications:One-stage detectors and two-stage detectors[10].One-stage detectors combine object location and classification in one deep learning framework,while two-stage detectors find object location in the first place and classify the potential objects secondly.Representative one-stage detection algorithms are RetinaNet[11],FCOS[12],CenterNet[13],ATSS[14],PAA [15],BorderDet [16],and YOLO series [17–21].Mainstream two-stage object detection approaches are R-CNN [22],SPPNet [23],Fast RCNN [24],Faster RCNN [25],FPN [26],Cascade RCNN[27],Grid RCNN[28],and CenterNet2[29].
Generally,the one-stage detector is considered to have a faster detection speed,while the two-stage detection algorithm has higher detection accuracy.While recent methods of ship detection[3,30–37]focus on improving one-stage detectors for real-time ship detection,they sacrifice the accuracy of detection.In this paper,we present a real-time two-stage ship detection algorithm,which improves detection accuracy while ensuring real-time performance.The algorithm includes two parts:the DLAbackboned object location(DBOL)and the CascadeRCNN-guided object classification(CROC).To further improve the accuracy of ship detection,we design a novel pixel-spatial-level data augmentation(PSDA) for increasing the number of samples at a high multiple and effectively.The PSDA,DBOL and CROC make up the proposed hybrid deep learning framework of EfficientShip.
The contributions of this study can be summarized as follows:
(1)The DBOL is presented for finding potential ship objects in real time.We integrate DLA[38],ResNet-50[39]and CenterNet[13]into DBOL for evaluating object likelihoods quickly and accurately.
(2) The CROC is put forward to real-time categorize the potential ship objects.We calculate the category scores of suspected objects based on conditional probability and extrapolate the final detection.
(3)The PSDA is proposed to reduce the risk of the model overfitting.We amplify the original data by 960 times based on pixel and spatial image augmentation.
(4)Our EfficientShip(includes PSDA,DBOL and CROC)gets the best performance compared with 8 existing SOTA methods:99.63%(accuracy)with 45 fps(speed).
2 Related Work
2.1 Ship Detection
Ship detection can be divided into SAR image-based[5,40]and optical image-based ship detection[2,3].Here we focus on reviewing optical image-based ship detection.Traditional optical image-based ship detection use hand-crafted features which sliding window to obtain the candidate area of the ship target based on the saliency map algorithm or the visual attention mechanism.The features of the candidate target are extracted for training to obtain the detection model[41,42].
Recently,deep learning-based ship detection has attracted researchers’attention.Shao et al.[3]introduced a CNN framework on the basis of saliency-aware for ship detection.Based on YOLOv2,the ship’s location and classification under a complex environment were inferred by CNN firstly and were refined through saliency detection.Sun et al.[32]presented an algorithm named NSD-SSD for realtime ship detection.They combined dilated convolution and multiscale feature to promote knockdown performance in detecting a small object of a ship.For getting the inferring score of every class and the variation of every prior bounding box,they also designed a batch of convolution filters at every trenchant feature layer.They finally reconstructed prior boxes with K-means clustering to advance visual accuracy and the ship-detecting efficiency.
Liu et al.[31] have designed an advanced CNN-enabled learning method for promoting ship detection under different weather conditions.On the basis of YOLOv3,they devised new scale of anchor boxes,localization probability of bounding boxes,soft non-maximum suppression,and medley loss function for advancing the CNN capacities of learning and expression.On the other hand,they introduced an agile DA tactics through produce synthetically-degraded pictures to enlarge the capacity and diversity of rudimentary ship detection dataset.Considering the influence of meteorological factors on ship detection accuracy,Nie et al.[30]synthesized foggy images and low visibility pictures via exploiting physical models separately.They trained YOLOv3 on the expanded dataset,including both composite and original ship pictures and illustrated that the trained model achieved excellent ship detection accuracy within a variety of weather conditions.For real-time ship detection,Li et al.[33]concentrated the network of YOLOv3 by training predetermined anchors based on the annotations of Seaship,instead max-pooling layer with convolution layer,expanding channels of prediction network to promote the detection ability of tiny object,and embedding CBAM attention module into the backbone network to facilitate the model focusing on the object.Liu et al.[43] proposed two new anchor-setting methods,the average method and the select-all method,for detecting ship targets on the basis of YOLOv3.Additionally,they adopt the feature fusion structure of cross PANet for combining the different anchor-setting methods.Chen et al.[35]introduced the AE-YOLOv3 for real-time endto-end ship identification.AE-YOLOv3 was merged in the feature attention module,embedded with the feature extraction network,and fused through multiscale feature enhancement model.
Liu et al.[34] presented a method of RDSC on the basis of YOLOv4 by reducing more than 40% weights compared to the original one.The improved lightweight algorithm achieved a tinier network volume and preferable real-time performance on ship detection.Zhang et al.[36]presented a lightweight CNN named Light-SDNet for detecting ships under various weather conditions.Based on YOLOv5,they modificated CA-Ghost,C3Ghost,and DWConv to decrease the model parameters size.They designed a hybrid training tactic by deriving jointly-degraded pictures to expand the number of the primitive dataset.Zhou et al.[37] improved YOLOv5 for ship target detection,and named it as YOLO-Ship,which adopted MixConv to update classical convolution operation and concordant attention framework.At decision stage,they employed Focal Loss and CIoU Loss for optimizing raw cost functions.
In order to reach the goal of real-time application while obtaining detection accuracy,most of the above algorithms choose a one-stage detection algorithm as the basis for improvement.Different from these methods,we present a real-time approach of two-stage detection as the main ship detection framework and verify its accuracy and real-time performance through experiments.
2.2 Data Augmentation(DA)
Image data collection and labeling are very labor-intensive.Due to funding constraints,ship detection datasets usually have only thousands of annotated images[2].But the deep learning model has many parameters and requires tens of thousands of data for training.While a deep convolutional neural network(CNN)learns a function that has a very high correlation with the small training data,it is poorly generalizable to testing set(overfitting).Data augmentation technology can simulate training image data through lighting variations,occlusion,scale and orientation variations,background clutter,object deformatio,etc.,so that the deep learning model is robust to these disturbances and reducing overfitting on testing data[44,45].
Image DA algorithms can be split into basic image manipulations and deep learning approaches[44].Basic image manipulations change original image pixels while the image label is conserved.Basic image manipulations include geometric transformations,color space transformations,kernel filters and random erasing.Image geometric transformations shift the geometry of image without altering its actual pixel values.Simple geometric transformations cover flipping,cropping,rotation and translation.Color space transformations will shift pixel values through an invariable number,separate RGB color channel or limit pixel values into a range.The methods of kernel filter sharpen or blur original images via sliding of filter matrix across training image.Inspired by CNN dropout regularization,random erasing does the operation of masking training image patch with the values 0,255,or random number.Taylor et al.proved the effectiveness of geometric and color space transformations[46],while Zhong et al.verified the performance of random erasing through experiments[47].Xu et al.presented a novel shadow enhancement named SBN-3D-SD for higher detection-tracking accuracy[48].
Deep learning-based augmentation adopts learning methods to produce synthetic examples for training data.It can be divided into adversarial training based DA,GAN-based DA,neural transfer based DA,and meta-learning-based DA [44].Adversarial training based DA generates adversarial samples and inserts them into the training set so that the inferential model can learn from the adversarial samples during training [49].Method of GAN is an unsupervised generative model that can generate synthetic data given a random noise vector.Adding the data generated by GAN-based DA into the training set can optimize deep learning model parameters[50].The idea of neural style transfer is to manipulate sequential features across a CNN so that the image pattern can be shifted into other styles while retaining its primitive substance.Meta-learning-based DA uses a pre-prepared neural network to learn DA parameters from medley images,Neural Style Transfer,and geometric transfigurations.The image generated by deep learning-based augmentation is abstract and cannot pinpoint target bounding boxes.So it is not suitable for ship detection.
3 Methodology
In this section,we describe the method of EfficientShip for ship detection.It includes proposed PSDA,DBOL and CROC(as shown in Fig.1).

Figure 1 : The architecture of the proposed EfficientShip.PSDA is used for expanding the amount of image sample; DBOL is responsible for detecting potential objects; CROC tries to identify the potential objects
3.1 Proposed PSDA
The ship detection dataset is small for the current study.Therefore,we present a method named PSDA to counteract the overfitting of the ship detection model.PSDA includes pixel level DA(PDA),spatial level DA(SDA),and their combination.PDA will change the content of the input image at the pixel level,and SDA is to perform geometric transformations on it.
Suppose the number of DA methods we used ismda,and a train imagextr(i) ∈Xtr,whereXtrindicates the train set.Each DA method will generatenda(as shown in Fig.2),for every image will producemda×ndanew images.At the pixel level,we will perform five subsequent DA methods for the training image setXtr.
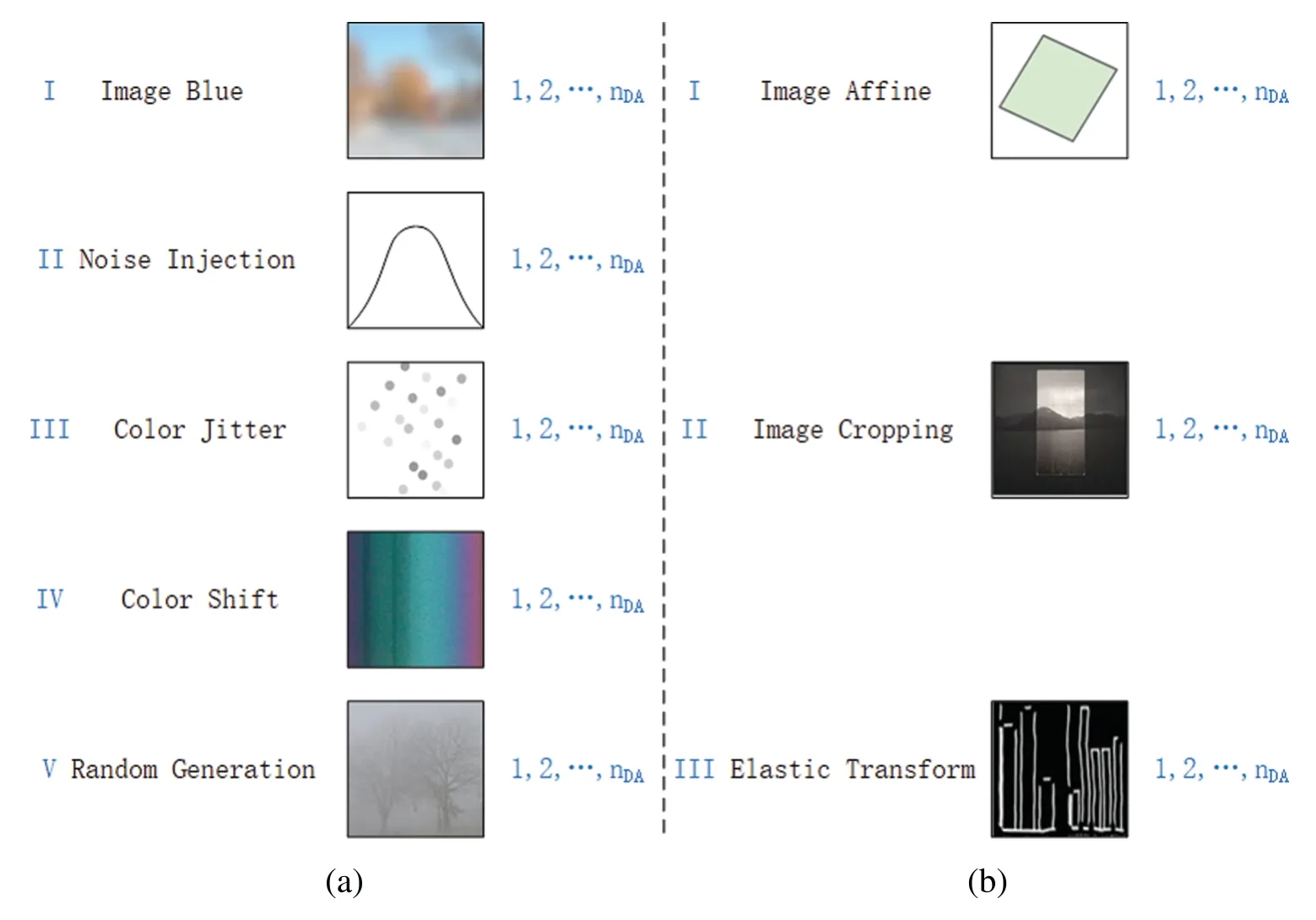
Figure 2 :Schematic of proposed PSDA.(a)PDA is used for expanding the amount of image sample at pixel level;(b)SDA is used for expanding the amount of image sample at spatial level
(I)Image Blur
Applying an image blur algorithm to a raw image can generatendaimages.
whereFIBmeans a certain image blur function[51].The functions include Gaussian blur,glass blur,median blur,motion blur,zoom blur,etc.
(II)Noise Injection
Newndaimages were generated by noise injection.
whereFNImeans a noise injection function [51].Noise injection algorithms include Gaussian noise,ISO noise,multiplicative noise,etc.
(III)Color Jitter
Color jitter generates a minor variations of color values in the training image.
whereFCJdenotes color jitter[51].Color jitter can be operated from three aspects:hfb-brightness,hfccontrast andhfs-saturation.
(IV)Color Shift
Color shift is color variation caused by different fade rates of dyes or imbalance of dyes within a picture patch.
whereFCSmeans color shift[51].Color shift can be operated from three channels:tfr-red,tfb-blue andtfg-green.
(V)Random Generation
Random generation method can generate new images by performing multiple operations on original image pixels,such as brightness,contrast,gamma correction,curve,fog,rain,shadow,snow,sun flare,etc.Each training image inXtris operatedndatimes through random generationgop.The variation range ofgopis[-az,+az]and complies with the distributionV.
whereMSRis the maximum operation range[52].Hence,we have
whereFRGmeans random generation[45].
At the spatial level,the image transformation will not change the original image content,but the object bounding box will be transformed along with the transformation.The main transformations are:
(I)Image Affine
Image affine is a common geometric transformation that preserves the collinearity between pixels.It includes translation,rotation,scaling,shear and their combination.
whereFIRmeans the image affine function,harepresents an operation of translation,rotation,scaling,or shear[45].
(II)Image Cropping
Image cropping can freely crop the input image to any size.
whereFICmeans the image cropping function[52].
(III)Elastic Transform
Elastic transformation alters the silhouette of the input picture upon the application of a force within its elastic limit.It is controlled by the parameters of the Gaussian filter and affine.
whereFETmeans the elastic transform function[45].
Algorithm 1 shows the pseudocode of PSDA on one training imagextr(i).

Algorithm 1:Pseudocode of PSDA on a training image Input:A raw training image xtr(i)Output:A new dataset Φ emanated with|Φ|=mda×nda 1: #PDA:2: Apply image blur for generating xtr_p1 3: Apply noise injection for generating xtr_p2 4: Apply color jitter for generating xtr_p3 5: Apply color shift for generating xtr_p4 6: Apply random generation for generating xtr_p5 7: #SDA:8: Apply image affine for generating xtr_s1 9: Apply image cropping for generating xtr_s2 10: Apply elastic transform for generating xtr_s3 11: Combine above outputs,|Φ|=xtr_p1 ∪xtr_p2 ∪xtr_p3 ∪xtr_p4 ∪xtr_p5 ∪xtr_s1 ∪xtr_s2 ∪xtr_s3
3.2 Proposed DLA-Backboned Object Location(DBOL)
The main task in the first step of two-stage object detection is to produce a number of patch bounding boxes with different proportions and sizes according to the characteristic features such as texture,color and other details of the image.Some of the patches represented by bounding boxes contain target,while others only involve background.
As Fig.1 illustrated,the first step of two-stage ship detection is to generate a set ofKship detections as bounding boxesb1,···,bK.We useP(Ok) to indicates the likelihood of the objectOkwith an unknown category.We can get
whereP(Ok)=0 shows the objectOkis the background whileP(Ok)=1 implies the thingsOkin bounding box is a target waiting to be classified[29].
The network architecture of the proposed DBOL is shown n Fig.3.We select compact DLA[38]as CNN backbone for inferringP(Ok) in the first stage of real-time object detection.The compact DLA runs on the basis of ResNet-50[39].The method of CenterNet[13]is used for finding objects as keypoints and regressing to bounding box parameters.The DLA-based feature pyramid generates feature maps from stride 8 to 128.A 4-level regression branch and classification branch are used for all feature pyramids to generate a detection heatmap and bounding box map.During the phase of training,annotations of the actual center are allocated to given feature pyramid levels based on the object scale.Locations are added into the 3 × 3 neighbor of the center,which will yield superior bounding box as positives.The distance between boundaries is used as the representation of the bounding box,and the gIoU cost is adopted for bounding box regression.
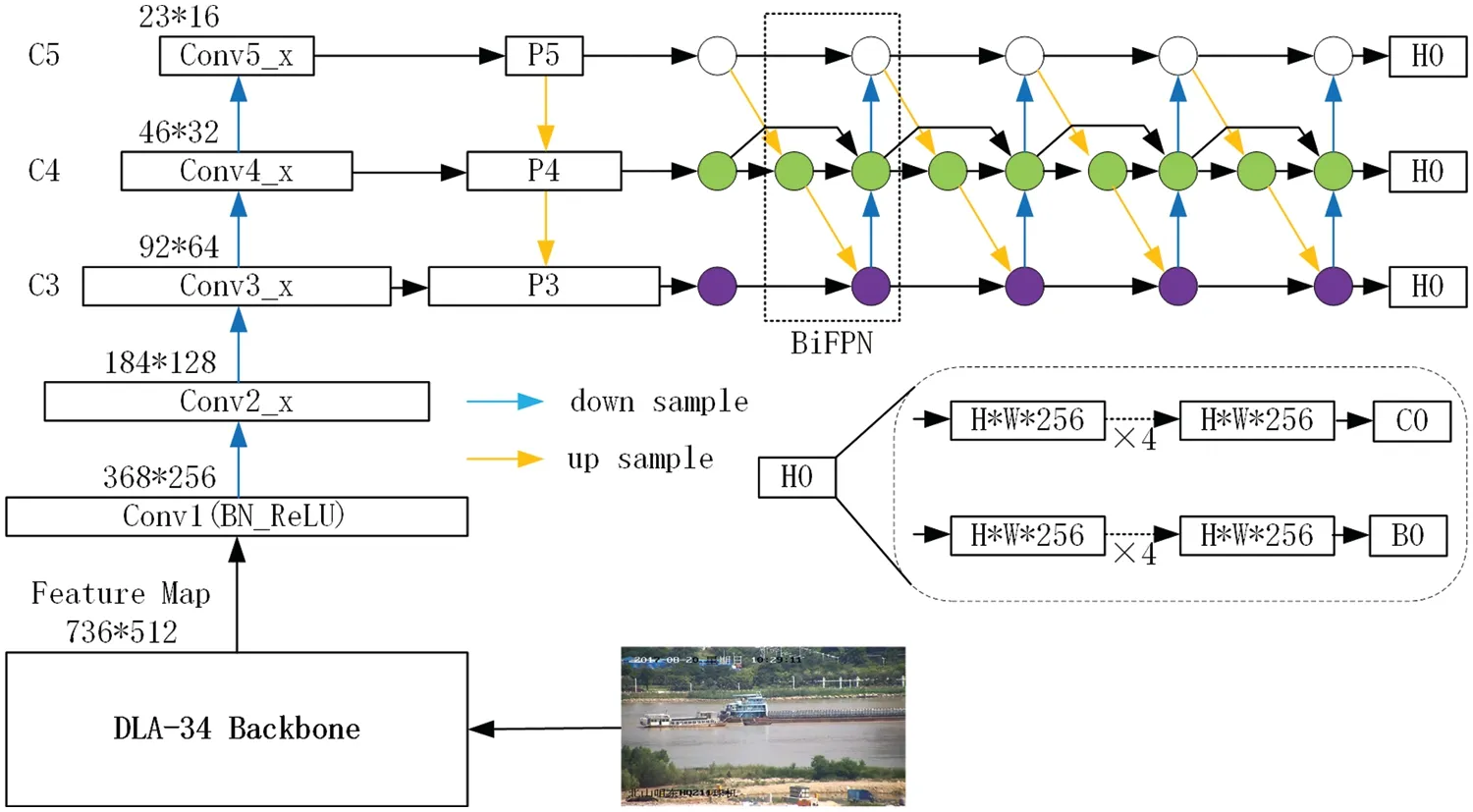
Figure 3 :The architecture of the proposed DBOL.“Conv*” is convolution operation,“C3,C4,C5” denote the feature maps of the backbone network,“P3,P4,P5” are the feature levels used for the final prediction,“H*” is network head,“B*” is bouding box of proposals,“C0” is object classification
3.3 Proposed CascadeRCNN-Guided Object Classification(CROC)
For every ship targetk,the class distribution isdk(c)=P(Ck=c)to classc∈C∪{background},whereCis a collection of all ship classes.AndP(Ck|Ok) designates the conditional categorical classification at the second detection stage.If the equationP(Ok)=0 holds,thenCk=background,which meansP(Ck=background|Ok=0)=1.
The conjoint category distribution of the ship detection is
whereoindicates an arbitrary object in the image[29].Maximum likelihood estimation is employed for training the detectors.For every labeled object,we maximize
to decrease to conjoint maximum likelihood objects of the two stages,respectively[29].The maximumlikelihood objective of the background class is
The architecture of the proposed CROC is shown in Fig.4.In this stage of detection,we select CascadeRCNN[27]for inferringP(Ck|Ok)on the basis ofP(Ok),which is deduced from the first stage.At each cascade staget,CascadeRCNN has a classifierhtoptimal for IoU threshold valueut(ut>ut-1).This is learned through reducing the cost
wherebt=ft-1(xt-1,bt-1),gis the ground truth object classification forxt,λ=1 is the trade-off coefficient,[·]is the indicator function,ytis the label ofxtunder givenut[27].

Figure 4 : The architecture of the proposed CROC.The Feature Map is generated from DLA-34 backbone network,“H*” is the network head,“B*” is the bouding box of proposals,“B0” is the bounding box of proposals produced in Fig.3
Algorithm 2 shows the pseudocode of the CROC training process.

Algorithm 2:Pseudocode of CROC training process Input:Training images Output:Trained CNN model 1: Maximize log P(Ck)(See Eq.(12))2: Factorize log P(background)(See Eq.(13))3: Reduce the cost L(xt,g)(See Eq.(14))
4 Experimental Result and Analysis
In this section,we evaluate the proposed EfficientShip on Seaships[2]dataset.The experiments use Pytorch(1.11.0)library which is installed in Ubuntu 20.04.The model parameters are trained on an NVIDIA GeForce RTX 3090 GPU with 24 GB RAM.And the CPU is Intel(R)Xeon(R)Platinum 8255C with 45 GB RAM.
4.1 Dataset and Evaluation Metrics
The dataset we selected in this paper is SeaShips [2].The dataset has 7000 images and includes six categories: bulk cargo carrier,container ship,fishing boat,general cargo ship,ore carrier,and passenger ship.Fig.5 shows the appearance of different ships in SeaShips.The resolution of images is 1920×1080.All pictures in the dataset are selected from 5400 real-world video segments generated by 156 monitoring cameras in the coastline surveillance system.It covers targets of different backgrounds,scales,hull parts,illumination,occlusions and viewpoints.We randomly divide the dataset into a training set and a test set with proportion of 9:1 for the experiments followed by[35].

Figure 5 :Illustration of different ship samples and their labels in the SeaShips dataset.(a)bulk cargo carrier;(b)container ship;(c)fishing boat;(d)general cargo ship;(e)ore carrier;(f)passenger ship
Experimental evaluation metrics include ship detection accuracy and runtime.The runtime is reported by fps,and the detection accuracy is evaluated by standard mAP which defined as
whereK=6 for all ship categories in SeaShips.
4.2 Parameter Setting
PSDA.For PDA,we select 33 augmentation methods(with 40 adjustable parameters)for every original training image.There are 15 parameter variations for each adjustable parameter setting shown in Table 1.For one raw image,600 new images can be augmented at this stage.Fig.6 displays the augmentation results of methods RandomFog and ColorJitter(in brightness).We choose 24 augmentation algorithms at the stage of SDA which generates 24*15=360 new images with spatial variation.The spatial parameter settings are listed in Table 2,and images generated by methods Affine(rotate) and Resize are illustrated in Fig.7.We construct a total of 960 new images for each original training image in SeaShips[2]through PSDA.

Table 1 : Pixel level DA parameter settings

Table 2 : Space level DA parameter settings
DBOL&CROC.The method of DLA[38]is selected as the backbone of the first ship detection stage.We extend DLA through a 4-layer BiFPN[53]with 160 feature channels.We reduce the output FPN levels to 3 levels with strides 8-32.The model parameters in the first stage are trained with a long schedule that repetitively fine-tunes.The amount of object proposals is reduced to 128 in the target-detecting stage.For the second stage,the detection part of CascadeRcNN[27]is adopted for recognizing the proposals.We raise the positive IoU threshold value from 0.6 to 0.8 for the method of CascadeRcNN to reimburse the IoU distribution variation.

Figure 6 :Illustration of pixel level DA.Upper:Augmentation with RandomFog;Under:Augmentation with ColorJitter(brightness)
4.3 Results and Analysis
(I)Ablation Study
We design the different experiments on the modules of the proposed framework to find their effectiveness.We first select the EfficientShip with non-DA as a baseline.Then we add pixel-level and spatial-level DA separately on the basis of the ship detection.Finally,we test the whole hybrid ship detection framework which includes three complete steps.Details of the experimental results are presented in Table 3.We can observe that the basic EfficientShip with non-DA yields the lowest mAP value of 98.85%,and the baseline plus SDA can get a 0.43% boost.The baseline plus PDA yields a 0.62% improvement which shows PDA is much better than SDA.The whole proposed EfficientShip achieves a detection accuracy of 99.63%.

Table 3 : Comparision of ship detection accuracy of different modules
Fig.8 shows the mAP comparison chart of different modules.It also indicates the changes in detection accuracy among various categories of the SeaShips dataset.Relatively,the bulk cargo carrier is the most recognizable object,while the passenger ship is the most difficult target to identify.After superimposing DA on the basis of two-stage detection,each category of detection accuracy is gradually approaching 100%.

Figure 7 :Illustration of space level DA.Upper:Augmentation with Affine(rotate);Under:Augmentation with PixelDropout
(II)Comparison to State-of-the-Art Approaches
We compare the proposed approach with 8 SOTA methods [2,3,31–35,43] from accuracy and efficiency of ship detection,as shown in Table 4.The data values of all SOTA algorithms are derived from their original papers.Although the algorithm speed is not comparable because of the difference in the platform on which the algorithm runs.However,it can be seen from Table 4 that the speeds of all methods meet the requirements of real-time application scenarios.Compared with the earliest sea ship detection algorithm[2],the accuracy of our method has improved detection accuracy by 16.63%.The accuracy of proposed algorithm is 99.63%,which has a 0.93% increase over the best SOTA-performing algorithm[35].
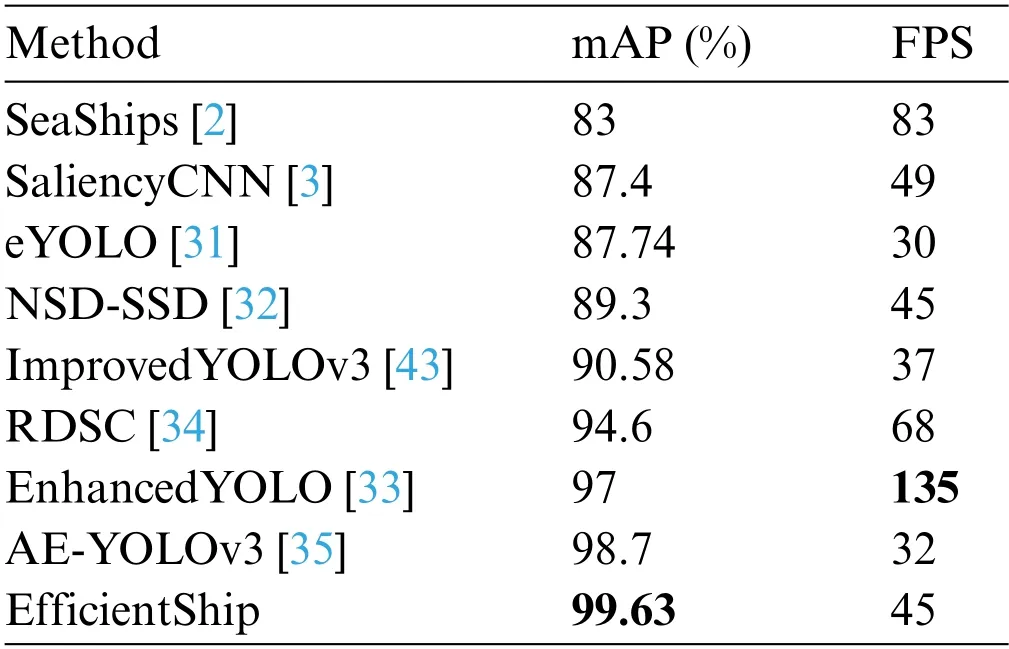
Table 4 : Comparison of EfficientShip with SOTA
5 Conclusions
Different from the traditional one-stage real-time ship detection methods,we fully utilized the latest real-time algorithms of object detection to construct a novel two-stage ship detection named EfficientShip.It includes DBOL,CROC,and PSDA.The DBOL is responsible for producing highquality bounding boxes of the potential ship,and the CROC undertakes object recognition.We train the two stages jointly to boost the log-likelihood of actual objects.We also designed the PSDA to make further efforts of promoting the accuracy of target detection.Experiments on the dataset SeaShips show that the proposed EfficientShip has the highest ship detection accuracy among SOTA methods on the premise of achieving real-time performance.In the future,we will further verify the proposed algorithm on some new larger datasets,such as LS-SSDD-v1.0 and Official-SSDD[54].
Acknowledgement: The authors wish to express their appreciation to the reviewers for their helpful suggestions which greatly improved the presentation of this paper.
Funding Statement: This work was supported by the Outstanding Youth Science and Technology Innovation Team Project of Colleges and Universities in Hubei Province (Grant No.T201923),Key Science and Technology Project of Jingmen(Grant Nos.2021ZDYF024,2022ZDYF019),LIAS Pioneering Partnerships Award,UK(Grant No.P202ED10),Data Science Enhancement Fund,UK(Grant No.P202RE237),and Cultivation Project of Jingchu University of Technology (Grant No.PY201904).
Author Contributions:The authors confirm contribution to the paper as follows:study conception and design:Huafeng Chen;data collection:Junxing Xue;analysis and interpretation of results:Huafeng Chen,Junxing Xue,Yudong Zhang; draft manuscript preparation: Huafeng Chen,Hanyun Wen,Yurong Hu,Yudong Zhang.All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data can be download from http://www.lmars.whu.edu.cn/prof_web/shaozhenfeng/datasets/SeaShips(7000).zip.
Conflicts of Interest:The authors declare that they have no conflicts of interest to report regarding the present study.
 Computer Modeling In Engineering&Sciences2024年1期
Computer Modeling In Engineering&Sciences2024年1期
- Computer Modeling In Engineering&Sciences的其它文章
- Review of Recent Trends in the Hybridisation of Preprocessing-Based and Parameter Optimisation-Based Hybrid Models to Forecast Univariate Streamflow
- Blockchain-Enabled Cybersecurity Provision for Scalable Heterogeneous Network:A Comprehensive Survey
- Comprehensive Survey of the Landscape of Digital Twin Technologies and Their Diverse Applications
- Combining Deep Learning with Knowledge Graph for Design Knowledge Acquisition in Conceptual Product Design
- Meter-Scale Thin-Walled Structure with Lattice Infill for Fuel Tank Supporting Component of Satellite:Multiscale Design and Experimental Verification
- A Calculation Method of Double Strength Reduction for Layered Slope Based on the Reduction of Water Content Intensity