
Review of Recent Trends in the Hybridisation of Preprocessing-Based and Parameter Optimisation-Based Hybrid Models to Forecast Univariate Streamflow
2024-02-19 12:00BaydaaAbdulKareemSalahZubaidiNadhirAlAnsariandYousifRaadMuhsen
Baydaa Abdul Kareem,Salah L.Zubaidi,Nadhir Al-Ansariand Yousif Raad Muhsen
1Department of Civil Engineering,University of Maysan,Maysan,57000,Iraq
2Department of Civil Engineering,Wasit University,Wasit,52001,Iraq
3College of Engineering,University of Warith Al-Anbiyaa,Karbala,56001,Iraq
4Department of Civil Environmental and Natural Resources Engineering,Lulea University of Technology,Lulea,971 87,Sweden
5Department of Computer Science,Faculty of Computer Science and Information Technology,Universiti Putra Malaysia,Serdang,43400,Malaysia
ABSTRACT
Forecasting river flow is crucial for optimal planning,management,and sustainability using freshwater resources.Many machine learning (ML) approaches have been enhanced to improve streamflow prediction.Hybrid techniques have been viewed as a viable method for enhancing the accuracy of univariate streamflow estimation when compared to standalone approaches.Current researchers have also emphasised using hybrid models to improve forecast accuracy.Accordingly,this paper conducts an updated literature review of applications of hybrid models in estimating streamflow over the last five years,summarising data preprocessing,univariate machine learning modelling strategy,advantages and disadvantages of standalone ML techniques,hybrid models,and performance metrics.This study focuses on two types of hybrid models:parameter optimisation-based hybrid models(OBH)and hybridisation of parameter optimisation-based and preprocessing-based hybrid models(HOPH).Overall,this research supports the idea that meta-heuristic approaches precisely improve ML techniques.It’s also one of the first efforts to comprehensively examine the efficiency of various meta-heuristic approaches(classified into four primary classes)hybridised with ML techniques.This study revealed that previous research applied swarm,evolutionary,physics,and hybrid metaheuristics with 77%,61%,12%,and 12%,respectively.Finally,there is still room for improving OBH and HOPH models by examining different data pre-processing techniques and metaheuristic algorithms.
KEYWORDS
Univariate streamflow;machine learning;hybrid model;data pre-processing;performance metrics
1 Introduction
Water scarcity,high requests for electricity consumption,irrigation requirements,industrial and residential uses are the primary issues compelling academics to precisely estimate streamflow for the effective use of freshwater resources [1,2].Moreover,streamflow estimation is essential for flood forecasting and warning,environmental flow analysis,food risk management,hydropower generation,irrigation systems,and water quality management[3–5].In the past,multiple regression and autoregressive moving average methods were utilized as conventional models for streamflow forecasting.However,these models rely on static data and work well only when the data has linear distribution and is regularly distributed [6–8].In contrast,streamflow time series data usually has nonlinear and unstable characteristics.Thus,based on linear distribution,these approaches are then unsuitable for capturing the features of hydrological time series[9–13].Alternatively,machine learning(ML)approaches are highly helpful in modelling natural systems since they do not require equations and assumptions depending on physical procedures,which are frequently needed in other models.These strategies have also resulted in effective outcomes and frequently outperformed conventional approaches[14–16].As a toolbox,high-level programming languages,including Python,NeuroSolutions,MATLAB,etc.,are successful and effective[17].Hence,various techniques have been evolved to improve streamflow forecast:support vector regression(SVR)[18,19],adaptive neuro-fuzzy inference systems (ANFIS) [20,21],random forest (RF) [22],and artificial neural networks (ANN) [9,14,23–27].However,ML models fall short of capturing hydrological processes,particularly in records with frequent high and variable streamflow.In addition,these models encounter issues through the training procedure,including over-fitting or trapping in search of global optimums[28,29].Therefore,several nature-inspired and evolutionary algorithms locating the global optimum have been combined with ML techniques to overcome these limitations[30].
The hybrid techniques combine various models for supporting (manipulating the data) and optimising the primary method[31].Some research has shown that combined approaches are superior to single techniques in terms of streamflow estimation,such as Kilinc et al.[32],Tikhamarine et al.[33],Shyama et al.[34],Zaini et al.[35],Adnan et al.[36],and Tikhamarine et al.[37].Hybrid prediction models have been recently prioritised over standalone approaches in hydrology issues.Fig.1 shows the percentage number of research on combined methods performed to simulate univariate streamflow over the last five years(from 2018 to 2022).
Multiple combined techniques have been advanced and effectively used to enhance the precision of univariate streamflow prediction.According to Hajirahimi et al.[38],combined approaches are classified into several types.However,this study focuses only on two groups:
1) The parameter optimisation-based hybrid models(OBH):The rationale behind OBH models is to make use of optimisation methods[29,39]and integrate the models with nature-inspired algorithms to estimate the optimum hyperparameters of ML methods such as Kilinc et al.[32],Adnan et al.[40],and Kilinc et al.[41].
2) Hybridisation of parameter optimisation-based and preprocessing-based hybrid models(HOPH): It is developed by combining the metaheuristic algorithms with the preprocessingbased hybrid models(PBH)models to seek appropriate parameters[38].This hybrid method has been successfully studied for hydrological research such as Tikhamarine et al.[37] and Zakhrouf et al.[42].
The reason behind studying these hybrid models in detail is because they enhanced predictive performance and are better than standalone methods,as demonstrated in Table 4 through the comparison between the column,which contains all models (Models Used),and the column (Best Model).It can notice that the combined technique superior to the single methods.
The univariate prediction technique is a data-driven modelling strategy that uses the same time series data as input,such as streamflow time series data [43].Consequently,when only streamflow data are available,the forecasting model will rely on the best streamflow lag data scenario [44].A univariate approach is especially prevalent in watersheds with limited data.The univariate time series forecasting approach is more flexible and applicable than traditional hydrological modelling in basin-scale hydrological forecasting,which typically requires large amounts of data,especially for river basins with low availability [43].Therefore,univariate data-driven prediction has become more prevalent recently in hydrological predicting,as shown by Pham et al.[45],Marques et al.[46],Kabbilawsh et al.[47],Danandeh et al.[48],Hu et al.[49]and Sammen et al.[50].
Different metaheuristic optimisation methods could solve various issues for diverse application fields.The significant benefits of optimisation approaches are their capability to choose the optimum values for system hyperparameters across a wide range of operating situations[51,52].Ahmed et al.[28]classified the metaheuristic into the evolutionary group,swarm group,physics group,and hybrid group.The studies that used this method,such as Jiang et al.[53],Feng et al.[54],Adnan et al.[36],Ren et al.[55],Fatemeh et al.[56] and Zhao et al.[57].In addition,data preprocessing techniques have a significant potential benefit for enhancing the effectiveness of prediction models[58].It can be categorised into three steps,which are,firstly,data normalisation.Secondly,data cleansing has received more importance recently.Multiple signal pre-treatment methods have been used for cleanning and/or locate the stochastic,seasonal,and trend signals of streamflow time series,including wavelet transform(WT)[8,59–61]and singular spectrum analysis(SSA)[62–67].Finally,selecting the best model input,such as mutual information(MI)[53,68–72].
In addition,many other review articles have introduced the uses of machine learning to predict streamflow[43,73–76],whose keywords and essential features are summarised in Table 1.
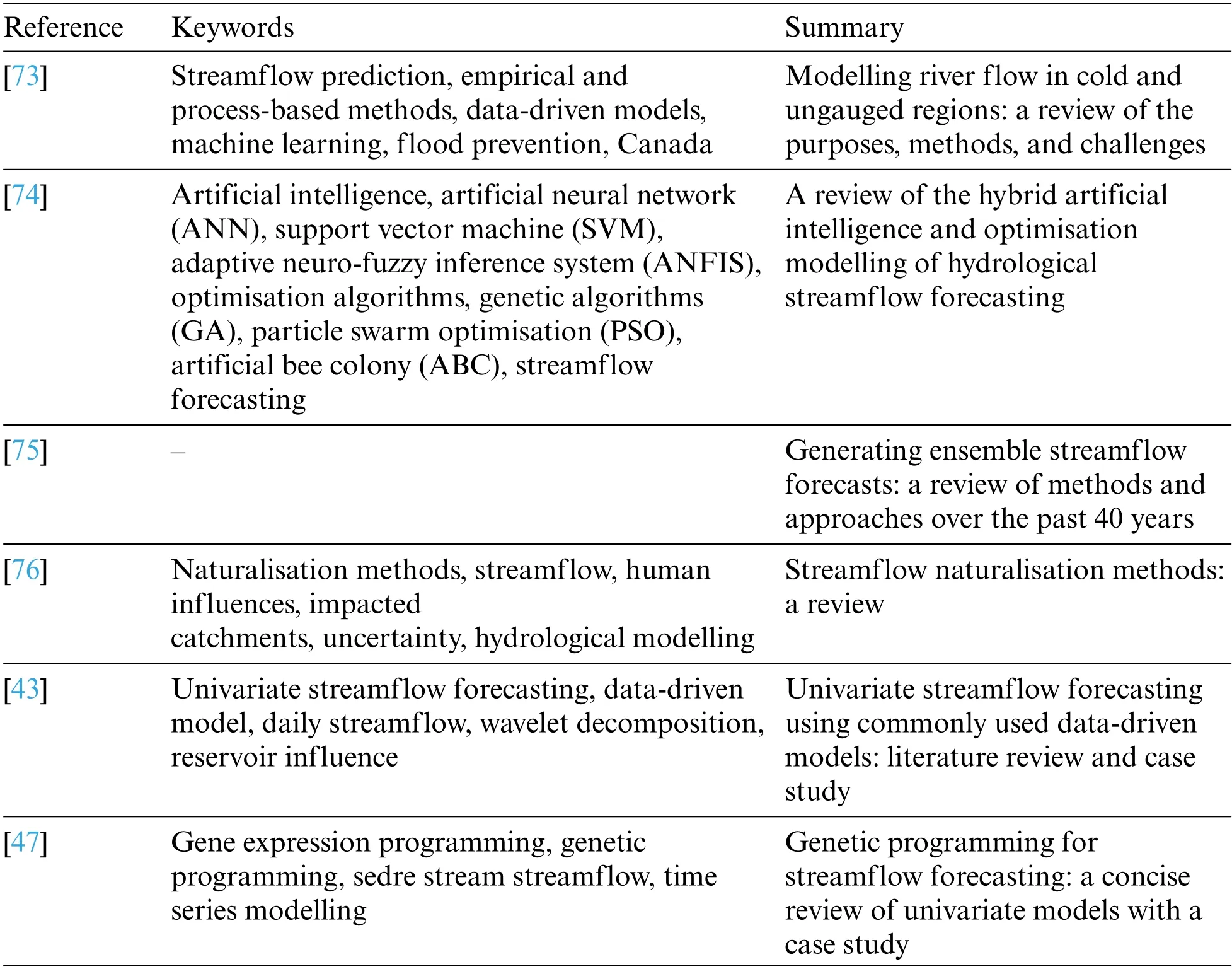
Table 1 : Summary of related review articles
Literature on streamflow estimation can be seen from numerous angles.Ibrahim et al.[74]analysed papers on hybrid artificial intelligence(AI)and optimisation of flow prediction.This review focused on ANN,the support vector machine (SVM),SVR,ANFIS,and AI techniques optimised using genetic algorithm(GA),particle swarm optimisation(PSO),and artificial bee colony(ABC).The study suggested that ML models can be used for advanced methodologies and future hybrid models.Troin et al.[75] investigated methods and strategies for forecasting streamflow for forty years and stated that ANN is the most well-known method for predicting streamflow.Furthermore,combined forecast techniques are a well-established field of research that covers a wide variety of practical applications.
Many studies on the development application of naturalisation procedures and the primary obstacles associated with the methods have been examined and evaluated.Naturalisation procedures are used when natural flows cannot be measured directly and must instead be calculated.Terrier et al.[76]provided literature with an overview of streamflow naturalisation approaches.The study revealed that the creation of hybrid approaches resulted from difficulty estimating the natural flow without human intervention and accumulating a long enough series to calculate robust hydrological indicators.Belvederesi et al.[73] focused on streamflow forecasting in cold and ungauged areas in previous studies.They showed the importance of developing hybrid models in such watersheds to aid flood prediction and warning and resource management challenges.
Zhenghao et al.[43]categorised the publications on data-driven models for univariate streamflow predictions: traditional and AI-based techniques.Traditional data-driven methods can be simply applied,such as auto-regressive integrated moving averages (ARIMA),multiple linear regressive(MLR),and auto-regressive moving averages with the exogenous term(ARMAX).The most widely employed AI-based data-driven techniques are SVM,ANN,ANFIS,genetic programming(GP),and least squares support vector machine(LSSVM).Finally,hybrid models incorporate both a data-driven technique and a data preprocessing method.The PSO,and GA,are widely used to determine ML hyperparameters,and wavelet decomposition(WD)is widely used as a data preprocessing approach.Additionally,researchers prefer hybrid models that integrate preprocessing techniques with novel datadriven techniques for streamflow predicting.
All the above reviewers in their studies considering the climate changes with streamflow,except Zhenghao et al.[43],discussed the univariate streamflow using data-driven models until 2018.One limitation of zhang’s study was that it did not consider the three preprocessing steps.
To this end,in all the above review papers,there is rarely a focus on univariate streamflow prediction.
In this context,the contributions made in this work could be introduced in detail below:
1-Collect previous studies and present them in coherent groups to shed light on the hybrid methods currently employed in univariate streamflow forecasting.Particularly meta-heuristic algorithms that incorporate machine learning.2-Explain and show the outcomes of using various algorithms in prior studies,highlighting the most common and successful varieties,and providing some recommendations for future investigations.3-Focus on how these algorithms help improve the reliability of predictions.4-Identify potential research pathways to help academics by illuminating the available options and gaps in this field.
The current research is up to date and explores using OBH and HOPH for univariate streamflow anticipating only ML models.Fig.2 presents all ML models and metaheuristic algorithms according to the finding of the summarised papers published from 2018 to 2022 that are considered in the present study.Thus,this study concentrated on combined ML approaches and their classification capability,including approaches for data pre-processing.Additionally,Fig.3 displays the general framework of streamflow prediction in this research.
2 Machine Learning(ML)
ML models have been utilised over decades and have gained considerable attention recently.This is because it can manage large volumes of data and permit nonlinear structures by applying complex mathematical processes [77].Typically,these algorithms can be classified into two groups:unsupervised and supervised training.In order to generate new data with the benefit of prior knowledge,supervised learning uses labelled training data[78].Various machine learning algorithms have been developed for predicting issues,such as ANNs [79–84],ANFIS [85–89],SVR [90–93],knearest neighbour(k-NN)[94–98],and multi-layer perceptron(MLP)[56,99–102].The pros and cons of the most prevalent ML approaches are briefed in Table 2.
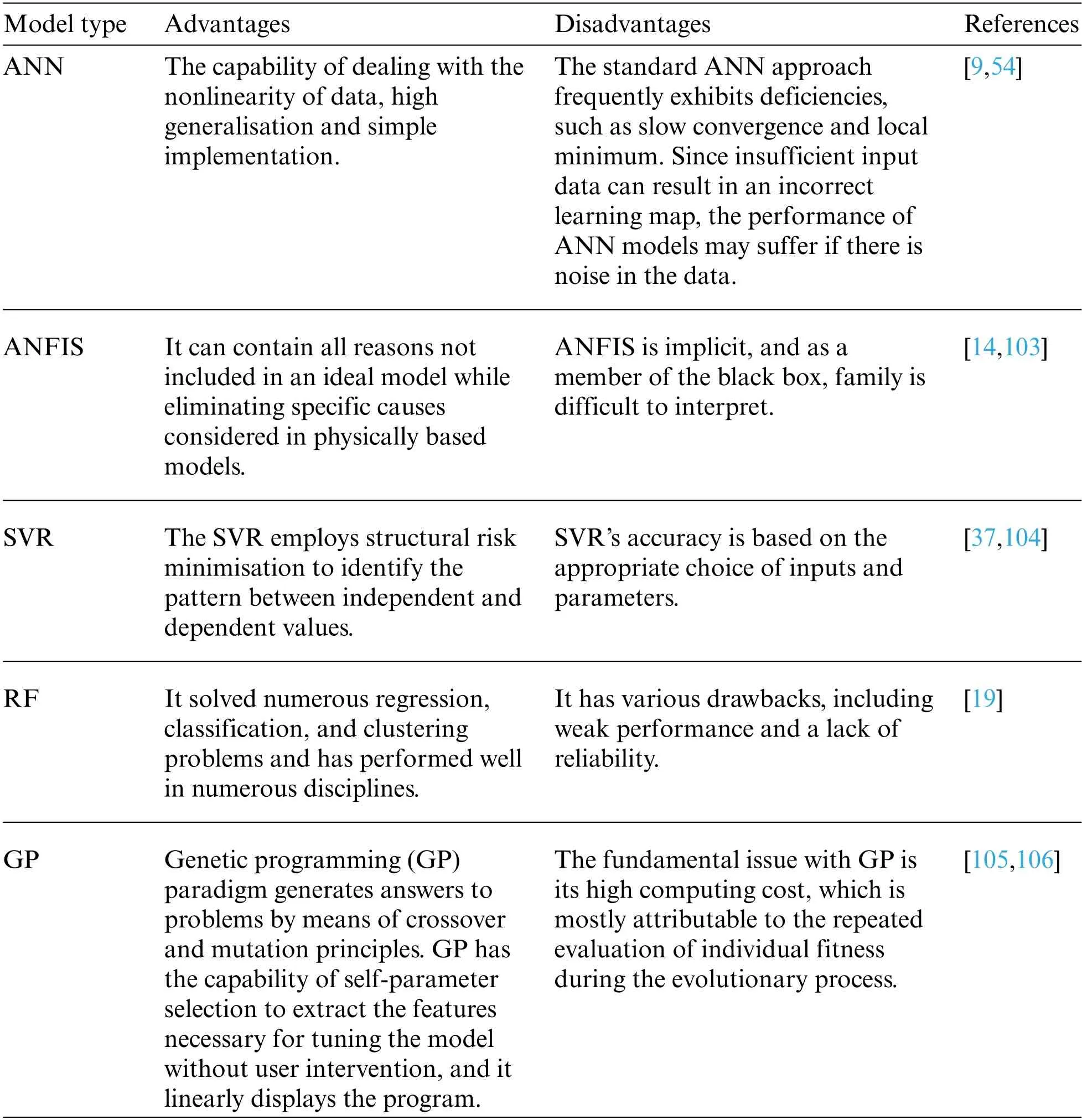
Table 2 : Pros and cons of the most prevalent ML techniques
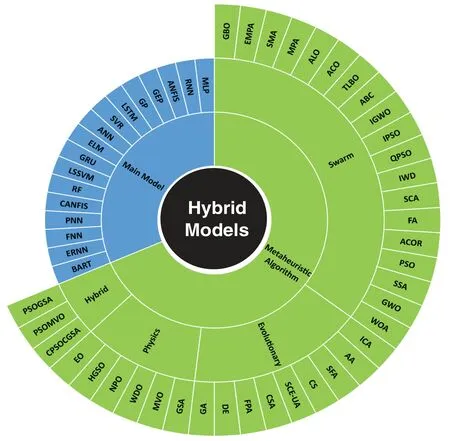
Figure 2 :All models and metaheuristics discussed in this paper are based on studies over the last five years

Figure 3 :The framework of streamflow simulation
3 Data Pre-Processing Methods
It plays a critical role in estimating variables by endorsing high precision and minimal processing costs throughout the training stage,where noisy and undependable data may badly influence the training stage and lead to a flawed model [77].These techniques are also fundamental to the data mining procedure by endorsing high precision and minimal processing costs throughout the training stage[107].Additionally,these techniques are essential for ensuring that all independent factors receive equal consideration throughout the training stage and for accelerating the procedure [108].Data preprocessing techniques have been used effectively in a variety of fields of research,e.g.,forecasting irrigation water [109],monthly rainfall [65],and drought prediction [110].The preprocessing data method comprises three steps: normalisation,cleaning,and selecting the optimal predictors,as indicated in Zubaidi et al.[111].
3.1 Normalisation
The goal of data normalisation is to provide each ANN model with input data that is normally or nearly normally distributed and has the same range of values[112].As a result,the convergence of the weights and biases will be more stable,and the outliers’impact will be reduced[58,113].
3.2 Cleaning
The step of cleaning data seeks to identify outliers and noise[114].Then,treat the outliers if found and remove noise from normalised time series to mitigate the scale of error and enhance the regression value[115].Outliers and noise negatively influence data analysis and the models’performance,so it is essential to determine and treat or remove undesirable values from the data[116].
3.3 Choosing the Best Predictors
Selecting the optimum predictors is one of the key processes in data preprocessing and evolving a viable prediction model[117].When applying the univariate strategy,various techniques,such as the mutual information method[16,118,119],are employed to choose the optimal antecedent lags scenario[39].According to the current research,only 42% of the academics made use of data normalisation,19% employed data cleaning,and 45% used best model input choice techniques.Table 3 summarises data preprocessing based on earlier research evaluated in this study.

Table 3 : Summary of data preprocessing steps
4 State of Art of Hybrid Models
This section will discuss the papers that the combined technique incorporates a couple or more methods:one works as the main technique and the rest as a pre-or post-processing technique.Recently,coupled techniques have been proposed to build flexible and effective techniques and increase the precision of single algorithms’forecasts[77].This study focuses on two types of combined methods:parameter optimisation-based hybrid models (OBH) and model hybridisation based on parameter optimisation and preprocessing (HOPH) [38].Fig.4 shows the best hybrid for OBH and HOPH models,and Table 4 demonstrates various research that applied hybrid models to forecast univariate streamflow over the period that this study focused on.The number of research reviewed in this paper is 31 research including six studies of the OBH model and 25 studies of HOPH model.The next sections review the summary of all research that were collected,contains models,time scale,location,best model,and performance metrics.

Table 4 : Summary of application of different types of hybrid models in streamflow

Figure 4 :Classification of the hybrid models utilised for streamflow forecasting
4.1 The Parameter Optimisation Based Hybrid Models(OBH)
The key idea behind these methods is to characterise the learning process and locate ML model hyperparameters through the use of optimisation methods[38].According to the nature-based method,a metaheuristic optimisation algorithm can be developed to address hydrological issues.Bio-inspired optimisation algorithms have proven useful in streamflow investigations for parameter estimation [135].Moreover,various forms of metaheuristic algorithms are employed for this issue.The metaheuristic algorithms imitate mathematical procedures via imitating natural processes,such as animal behaviour,physical annealing,and biological evolution[39].
The firefly algorithm (FFA),genetic algorithm (GA),grey wolf optimisation (GWO),particle swarm optimisation (PSO),and differential evolution (DE) are all hybrids of ANFIS and natureinspired optimisation algorithms that are used for streamflow simulation across three prediction perspectives:the short-term(daily time scale),the intermediate-term(weekly to monthly scale),and the long-term(annually).From June 2005 to December 2016 in the southwest of Iran,fifteen various input-output vectors were utilised for training the hybrid streamflow forecasting model.The results showed that on all time scales,the hybrid algorithms proposed exceeded the traditional ANFIS models.Values of R2,RMSE,NSE,and RAE were improved by 12%,10%,18.5%,and 14.3% for the shortterm,15%,13%,20%,and 21.1% for the medium-term,and 10.3%,7.5%,10.5%,and 14% for the longterm,respectively[30].The ideal models were ANFIS_GWO1,ANFIS_GWO7,and ANFIS_GWO11.
Additionally,Kilinc et al.[32] combined a long_short_term memory (LSTM) with GA for streamflow forecasting.The GA-LSTM approach was implemented using daily streamflow data of the Beyderesi_Kılayak station (Sep 2000–Jun 2019) and of Yazıköy station (Dec 2000–Jun 2018) in the Euphrates River,Turkey.The findings demonstrated that the suggested GA-LSTM reduced the prediction error more effectively than the benchmark models(i.e.,LSTM and Linear Regression)with MAE=0.2865 m3/s,RMSE=0.7795 m3/s,MAPE=5.2819,SD=0.0973,and R2=0.9689.
Moreover,compared the M5 Regression Tree(M5RT)models to 2 hybrid approaches,ANN GA and ANFIS GA,for forecasting streamflow in four distinct time-lag input combinations.For this research,we utilised monthly streamflow data from the 2 Rivers in Pakistan.When comparing the ANFIS GA and ANN GA to the M5RT models,it was discovered that the hybrid models performed better in terms of prediction.The results demonstrated that the ANN-GA model with three historical streamflow and periodicity input outperformed the ANFIS_GA model in Kunhar River (RMSE:31.16 m3/s,MAE:18.67 m3/s,and R2:0.891).
Also,a hybridisation of a gated recurrent unit (GRU) with a grey wolf algorithm (GWO) was used for estimating the streamflow of Üçtepe and Tuzla stations in Turkey from 2000 to 2009.The comparative model and linear regression were used to compare the hybrid model’s precision.Based on their findings,the GWO-GRU combined technique was superior to the standard methods in all statistical parameters except standard deviation (SD) at the Üctepe station and the entire Tuzla station.At Üçtepe,the flow measurement station(FMS),RMSE and MAE of the single GRU method were 124.57,184.06 m3/s,respectively,whereas that of the hybrid model were 82.93 and 85.93 m3/s,respectively,resulting in improvements of around 34% in RMSE and 53% in MAE.In addition,the Tuzla station’s GWO-GRU and linear regression R2values were 0.9827 and 0.9558,respectively.It also supported the potential of the hybrid GWO-GRU model for forecasting issues[41].
Samui et al.[130]employed three metaheuristic algorithms to enhance the ANN model to predict the daily streamflow of the Euphrates River relying on several historical data.The metaheuristic algorithms are ABC,TLBO,ACO,ALO,and ICA.Data were collected in a 2102-gauge station in Turkey from 1981 to 2010.The outcomes display that the ANN_ALO technique remained superior considering the performance criteria such as R2=0.962,NSE=0.962,RMSE=0.061 m3/s,MAE=0.029 m3/s,and MARE=0.003.
Nguyen et al.[132]used the genetic algorithm(GA)to determine the bayesian additive regression tree(BART)model’s variables in the most efficient manner possible.As a result,a novel hybrid GABART model was suggested for estimating hourly streamflow in the Jungrang urban basin,which is located on the Han River in South Korea with data(2003–2020).The GA-BART approach produced better results compared to the MLR and GA-SVR models.In comparison to models using different input predictors,the statistical results showed that the hybrid GA-BART model performed better than the other models for the hourly streamflow estimate with an RMSE=25.12 m3/s,MAE=8.00 m3/s,NSE=0.96,CC=0.98,and MAPE=9.0%.
4.2 Hybridisation of Parameter Optimisation-Based and Pre Processing-Based Hybrid Models(HOPH)
By combining optimisation methods with pre-processing-based hybrid (PBH) models,HOPH models can determine the best settings for their pre-processing stage or assess the correct weights to use when adding up the results of its decompositional elements’predictions[38].
Tikhamarine et al.[37] analysed the model of SVR using four algorithms (i.e.,grey_wolf optimiser(GWO),shuffled_complex_evolution_algorithm(SCE_UA),Multi_verse optimiser(MVO),and PSO).The aforementioned approach was then used to develop hybrid models that combine wavelet transform with SVR in order to make predictions about the monthly streamflows at the Ain Bedra and Fermatou stations in Algeria between 1970 and 1995.Finally,both the basic and hybrid models were compared.In comparison to other hybrid models,the created hybrid (GWO_WSVR)presented somewhat higher NSE(95.72%)and coefficient of determination(0.9786)and lower RMSE(0.6433 m3/s)and MAE(0.3047 m3/s)values.
Zhao et al.[61] also used the ICEEWT-IGWO-GRU model to estimate monthly streamflow prediction from 1956 to 2016 for the Shangjingyou station and from 1958 to 2016 for the Fenhe reservoir station in Taiyuan.They revealed that ICEEWT_IGWO_GRU was advanced to the single GRU model,so the values of MAE and RMSE were reduced by 50% and 52% for the two stations.
When it comes to daily streamflow forecasting,Niu et al.[123]developed a hybrid model based on variational mode decomposition(VMD),extreme learning machine(ELM),and sine cosine algorithm(SCA).For this reason,we decided to breakdown the original streamflow series using the VMD method of data processing.This analysis makes use of daily streamflow measurements taken at Danjiangkou Reservoir on the Han River in China between 1 January 2005 and 31 December 2019.The outcomes showed that compared with the control models,such as ANN,SVM,and ARMA,the hybrid method gave rise to high accuracy in predicting streamflow.The GVMD-ELM technique had the best performance(RMSE=50.48% m3/s,MAPE=63.06 m3/s,CE=12.75 and R=0.986).
Zakhrouf et al.[42] have established the discrete wavelet transform-based feed-forward neural networks(WFFNNs-GA)model for the multi-day-ahead streamflow prediction using three different evolutionary techniques(i.e.,MIMO,MIMO,and MIMO).In this analysis,we utilised data collected over a period of 14 years along the Chellif River in Algeria.Five statistical indices(root-mean-squared error,signal-to-noise ratio,correlation coefficient,nash-Sutcliffe efficiency,and peak flow criterion)were used to evaluate the suggested models.Outcomes demonstrated that the WFFNNs-GA model based on the MISMO evolutionary approach provided the best accuracy(i.e.,RMSE(m3/s)=1.550,SNR=0.066,CC=0.998,NSE(%)=99.565,and PFC=0.081).Results further supported the claim that hybrid models based on comparable evolutionary methodologies estimate results more accurately than solo models.
Moreover,Zakhrouf et al.[129]used a hybrid approach,combining wavelet(W)with data-driven models(ANN,ANFIS,and GA)to predict daily river flow in Northern Algeria.They analysed data from 12 years.Comparisons were also made between the WANN-GA and WANFIS-GA models and their individual counterparts,including ANN and ANFIS.Coefficients of determination(R2)achieved by using the WANFIS-GA and WANN-GA models were 87.2% and 78.9%,respectively,whereas those obtained using the individual models(i.e.,ANFIS and ANN)were 56% and 57%,respectively.For the peak values during the testing period (RMSE=12.1545 m3/s,MARE=106.785%,R=0.934,R2=0.872,and EC (%)=87.32),the WANFIS-GA model provided an excellent match for the observed data.
Furthermore,the MLP is integrated with three physics-inspired algorithms (i.e.,equilibrium optimisation (EO-MLP),nuclear reaction optimisation (NRO-MLP),and henry gas solubility optimisation (HGSO-MLP)) to forecast the monthly streamflow.Ahmed et al.[28] compared these hybrid models with two_neural network standalone models MLP and Recurrent Neural Network(RNN) and nine metaheuristic algorithms: evolutionary-inspired (genetic_algorithm (GA-MLP),differential evolution (DE_MLP),and flower pollination algorithm (FPA-MLP),swarm-inspired(particle swarm optimisation (PSO-MLP)),whale optimisation algorithm (WOA_MLP),grey wolf optimisation (GWO-MLP) and sparrow search algorithm (SSA-MLP),and two physics-inspired algorithms ((wind-driven optimisation (WDO-MLP) and multi-verse optimisation (MVO_MLP)).The case study was the Nile River,with 130 years of monthly natural streamflow between 1887 and 2000.Their findings indicated that physics-inspired models were more reliable in capturing the streamflow patterns.The NRO had the best accuracy with the lowest RMSE of 2.35,MAE of 1.356,MAPE of 16.747,the highest WI of 0.957,and R of 0.924.The study also concluded that enhancing the NRO algorithm with MLP may result in a reliable method for monthly streamflow predictions.
Azad et al.[120]also trained the ANFIS by GA,the ant colony optimisation for the continuous domain (ACOR),and PSO to predict river flow 1,3,5,and 7 days ahead.The data was collected from five stations,the upstream stations,including Eskandare(U1)and Ghaleh-Shahrukh(U2),and the downstream ones,including Saad-Tanzimi (D1),Pole-Zamankkhan (D2),and Cham-Aseeman(D3)in Iran for three years.Results demonstrated the PSO enhanced performance of ANFIS so that averages of R2,RMSE (m3/s),MARE,and NSE were developed up to 0.91%,0.30%,43.8%,and 0.13%,respectively.
Moreover,a gene expression program (GEP) was added to the (GA) to create a unique hybrid model for forecasting streamflow in an intermittent stream one month ahead of time.Results from the GEP-GA were compared to those from the classic GP,the GEP,multiple linear regression,and the GEP-linear regression models.They used a monthly streamflow data set for the region of northwest Iran from 1978 to 2008 for their study.As shown by the results,the GEP-GA performed better than all of the reference models(RMSE=249.6,NSE=0.523)[121].
Three machine-learning approaches were employed to predict monthly streamflow in Egypt from 1871 to 2000.These methods were SVM,multilayer perceptron neural network(MLPNN),and ANN.The above methods were hybridised with the GWO algorithm.Auto-regression (AR) was used for comparative analysis purposes.So,single models,such as SVM,MLPNN,and ANN,performed less well than combined ones.Among all the combined techniques,the SVR-GWO technique was the best in terms of estimating streamflow,based on statistical criteria (i.e.,RMSE=2.0570 m3/s,MAE=1.2005 m3/s,R=0.9363,NSE=0.8728,and WI=0.9671)[33].
An ELM was also combined with GA,the PSO algorithm,and upgraded particle swarm optimisation (IPSO) to raise the accuracy of monthly streamflow predictions using one delay time.The models were trained with data from the Chaohe River,in China,from January 1956 to December 2010.This research demonstrated that the developed procedure(ELM-IPSO)had a greater prediction accuracy when compared to AR,ANN,ELM-GA,and ELM-PSO approaches.The ELM-IPSO also had the lowest MAE,RMSE,and RE values throughout the training and prediction stages and the highest NSE and R values,indicating that ELM-IPSO is a practical approach for predicting monthly streamflow with MAE=1.16 m3/s,RMSE=1.46 m3/s,RE=-11.04%,NSE=0.78,and R=0.89[53].
Feng et al.[54]used the ANN model with five meta-heuristic algorithms,namely the cooperation search algorithm (CSA),PSO,DE,gravitational search algorithm (GSA),and quantum-behaved particle swarm optimisation(QPSO)to predict the monthly flow.The study was done in the Yangtze River,China; the flow data of three Gorge stations lasted from 1890 to 2019,while the data of the Gaochang station lasted from 1940 to 2019.They modelled the ANN using 12 input scenarios(M1 to M12).The experimental results indicated that the hybrid method ANN-CSA consistently outperformed the control models and produced superior predicting outcomes during the training and testing stages in various scenarios; the evaluation result was (RMSE=3653.3034 m3/s,MAPE=18.5002,R=0.9198,and CE=0.8457).
In another study,the ANFIS was combined with the particle swarm optimisation(ANFIS_PSO),genetic algorithm (ANFIS_GA),and differential evolution algorithm (ANFIS-DE) to predict monthly streamflow.The data was collected from one station(ID 3527410)in Malaysia from 2000 to 2014.The results suggested that integrating long antecedent data increases forecasting accuracy,as the model can capture seasonal patterns and the current trend in time series.The model with five input variables (t _1,t _2,t_3,t_6,t_12) was superior to the best,with a 68% improvement in prediction accuracy over the model with a single input variable(t_1).The results revealed that the PSO improved the capability of the ANFIS model (RMSE=7.96; MAE=2.34; R2=0.998 and WI=0.994)more than GA and DE in forecasting streamflow.Comparing evolutionary optimisation methods revealed that PSO is superior to GA and DE for optimising ANFIS functions.The precision of the ANFIS-PSO technique was somewhat greater than that of the ANFI-SGA and ANFIS-DE techniques(24% and 20%,respectively),and it was 25% more accurate than the non-hybrid ANFIS model.Therefore,the ANFIS-PSO model could accurately predict highly stochastic stream flow in a tropical setting[122].
A hybridisation of ANN and SVR with GA and (SVR,RF) was done using the grid search algorithm to simulate river flow from Jan 1991–Nov 2010.The historical data under 5 input scenarios were created(1stModel,2ndModel,...,5thModel)to predict streamflow in the Tigris River in Iraq.The results indicated that the SVR-GA model was the most accurate at predicting monthly river flow(i.e.,ME=-14.73,RMSE=100.78 m3/s,MAE=81.585 m3/s,MPE=-214.02,MAPE=670.30,and R2=0.96).Consequently,it was applicable to improve the flow of river forecasting capability by utilising the suggested hybrid model[19].
The multilayer perceptron (MLP) was hybridised with multiple metaheuristic algorithms: sunflower optimisation(SFA),the genetic algorithm(GA),and particle swarm optimisation(PSO)predict six lags of daily streamflow in two stations,Jam Seyed Omar(JSO)and Muda Di Jeniang(MDJ)in Malaysia.The MLP-SFA was compared to the conventional MLP and two other hybrid MLP models(MLP-PSO,MLP-GA).The assessment yielded the following outcomes:at the MDJ station(PBIAS=0.18,MAE=0.29 m3/s,NSE=0.93,RMSE=0.45 m3/s,d=0.95),and at the JSO station(PBIAS=0.16,MAE=0.27 m3/s,NSE=0.93,RMSE=0.37 m3/s,d=0.94).Compared to previous models,the MLP-SFA might reduce RMSE by 12%~21% at the JSO station and 8%~24% at the MDJ station.The results demonstrated that using MLP with optimisation methods led to the enhancement of the accuracy of the standalone MLP model[50].
Meshram et al.[126]suggested a novel hybrid technique(FNN-PSOGSA)for simulating monthly streamflow.The data was collected from Garber station of the Turkey River in Iowa from 1990 to 2016.This study utilised the PSOGSA for the perfect preparation of the FNN model.The model with two input variables(Qt-1,Qt-2)was superior.They were comparing revealed that FNN-PSOGSA is superior to the standard FNN and FNN_PSO models with RMSE=24.42 m3/s and MAE=16.47 m3/s,and the maximum rate of NSE=0.652,WI=0.864.The findings also show that the FNN-PSOGSA model is a workable strategy for estimating streamflow and increasing forecasting accuracy.
Abdul Kareem et al.[131]developed three combined models to forecast univariate streamflow of the Tigris River in Maysan Province,Iraq,over 11 years.The procedure comprises data preprocessing and an ANN method combined with CPSOCGSA,MPA,and SMA algorithms.The outcomes reveal that the ANN-CPSOCGSA algorithm offers the better solution based on multiple statistical tests,such as R2=0.91,RMSE=1.07 m3/s,MAE=1.07 m3/s,and MARE=1.01.
Zhao et al.[57]used monthly streamflow data collected at the Shangjingyou and Fenhe reservoir sites between the years 1956 and 2016.Comparisons are made between the LSSVM and ELM models and the monthly and sequential IGWO-GRU.The results showed that the hybrid IGWO-GRU method outperformed the other models in estimating monthly streamflow.The IGWO-GRU model reduced the MAPE values by an average of 55.8% compared with the ELM model.Likewise,it yielded a qr value of 97.22% in the Fenhe reservoir station and 86.11% in the Shangjingyou station;this falls under the “very good” and “good” grade categories,respectively.The monthly IGWO-GRU technique was determined to be a more accurate estimating tool,with an average qualification rate of 91.66 percent at two stations(RMSE=19.615 m3/s,NSE=0.675,R=0.896,MAPE=0.060,and qr=97.22%),(RMSE=147.666 m3/s,NSE=0.922,R=0.971,MAPE=0.049,and qr=86.11%)was the evaluation result for Shangjingyou and Fenhe reservoir stations,respectively.
Pham et al.[45] assessed a new procedure,which coupled the multi-layer perceptron neural network(MLP-NN)with the IWD algorithm to predict monthly streamflow.Nong Son and Thanh My Stations at the Vu Gia Thu Bon River basin were used to collecting historical river streamflow data(1978–2016).The MLP-IWD model was evaluated by four different scenarios for the model input–output architecture.Additionally,the classical MLP-NN model was compared with a proposed hybrid model.The MLP-IWD model offered the best performance(with R2=0.80,RMSE=73.70 m3/s,RE=195.08,NSE=0.70 and MAE=55.01 m3/s)for Thanh My station and(with R2=0.83,RMSE=173.65 m3/s,RE=47.75,NSE=0.784 and MAE=123.20 m3/s)for Nong Son station.
Tripura et al.[124]examined the applicability and ability of a hybrid coactive neuro-fuzzy inference system(CANFIS),with a genetic algorithm(CANFIS-GA)and a firefly algorithm(CANFISFA),in simulating hourly streamflow.The data were obtained from a Barak River system in Assam,India,from 2000 to 2005.Furthermore,the hybrid models were compared to traditional CANFIS,ANN,and probabilistic neural networks (PNN).The outcomes expression that the suggested CANFIS-FA model outperformed the conventional CANFIS,CANFIS-GA,ANN,and PNN estimates(MAPE=0.06%,the coefficient of correlation r=0.99965,and RMSE=3.92 m3/s).
Kilinc[125]created and implemented an innovative hybrid model using LSTM coupled with the PSO.The proposed hybrid model was compared with statistical methods,including linear regression and the autoregressive integrated moving average(ARIMA).This study employed daily streamflow data from three stations,including Karasu (2010–2019),Demirköprü (2010–2019) and Samanda˘g(2009–2018),located along the Orontes River basin,Turkey.The hybrid PSO-LSTM strategy gave more promising accuracy results and produced greater performance than the benchmark and linear regression techniques while simulating daily streamflow.For example,the results of the Samanda˘g station values exhibited the highest R2(0.9749) RMSE (1.2557 m3/s),MAE (0.1025 m3/s),MAPE(10.2574)and lowest standard deviation(-0.1541).
Mohammadi et al.[127]employed three hybrid techniques include,MLP_PSO,MLP_PSOMVO,and MLP-BL,to predict the daily streamflow.Statistical criteria were used to evaluate the aboveboosted methods against MLP and BL.Four hydrometric stations are utilised,two in Canada(Brantford and Galt) on the Grand River and two in the United States (Macon and Elkton,on the Ocmulgee and Umpqua rivers,respectively)to measure daily streamflows from 1998 to 2018.Results reveal that the boosted approaches,especially the boosted MLP-BL,are superior to the baseline models in terms of their ability to accurately estimate daily streamflows.It yields,for example,R2=0.994,MAE=3.53 m3/s,and RMSE=6.426 m3/s for Brantford station in the testing stage.
Zakhrouf et al.[128] integrated three deep learning techniques (i.e.,ERNN,LSTM,and GRU)and one machine learning method(i.e.,FFNN)by combining each model with the PSO algorithm to simulate the daily streamflow data in Sidi Aich and Ponteba Defluent stations,Algeria over six years.The results of the testing stage indicate that the GRUII two-stage combined technique delivers the best results compared with the rest of the models.It offers NSE=0.7337,SNR=0.5159,and RMSE=35.241 m3/s for Sidi Aich station and NSE=0.8703,SNR=0.3600,and RMSE=11.074 m3/s for Ponteba Defluent station.
Adnan et al.[5] established and applied an innovative hybrid model utilising two optimisation methods:the PSO and GWO,coupled with the ELM.The data used are monthly streamflow from 1980 to 2011 on the Mangla catchment in the north of Pakistan.In addition,the proposed hybrid model was contrasted with four models,including the standalone ELM,a hybrid of ELM-PSO,ELM-GWO,and binary hybrid ELM-PSOGSA (a hybrid of PSO with gravitational search algorithm) methods.According to the evaluation results,the developed coupled model ELM-PSOGWO outperformed the standalone ELM,hybrid ELM-PSO,ELM-GWO,and binary hybrid PSOGSA methods,with the lowest RMSE=55.14 m3/s,MAE=46.59 m3/s,and both a high R2and NSE of 0.925,0.919 in the test phase respectively.Furthermore,the outcomes reveal the potential of the ELM-PSOGWO model to be recommended for monthly streamflow prediction.
Ikram et al.[133] assessed a new procedure,which joined the ANN with the extended marine predators’algorithm (EMPA) (i.e.,ANN-EMPA) to predict monthly streamflow.The Upper Indus Basin(UIB)of northern Pakistan was used to collect river streamflow data(1974–2008).Additionally,the new method ANN-EMPA was compared with the hybrids ANN-MPA,ANN-GWO,ANN-GA,and ANN-PSO methods.The ANN-EMPA model offered the best performance with the lowest RMSE=131.80 m3/s,MAE=84.44 m3/s,and the highest NSE=0.9532.Additionally,the ANNEMPA enhanced the RMSE,MAE,and Nash–Sutcliffe efficiency of ANN-PSO by 4.8%,4.1%,and 0.5%,ANN-GA by 6.2%,5.6% and 0.6%,ANNGWO by 3.7%,4.4% and 0.5%,and ANN-MPA by 3.2%,7.5% and 0.3%,respectively.
Adnan et al.[134]used the gradient-based optimisation(GBO)algorithm to develop the ANFIS model for estimating monthly streamflow.The models were built using antecedent streamflow data collected from 1974 to 2009 and were based on two significant sub-basins of the Upper Indus Basin(UIB),namely the Astore and Gilgit basins in northern Pakistan.The accuracy of ANFIS-GBO was evaluated in comparison to ANFIS,ANFIS-GWO,ANFIS-PSO,ANFIS-ACO,ANFIS-GA,and ANFIS-DE.The GBO successfully improved the estimated precision of the ANFIS model by optimising its parameters.The outcomes indicated that the ANFIS-GBO model improved the forecast precision of other hybrid models with root mean square error (RMSE)=28%–29.5%,normalised RMSE=28%–26.9%,mean absolute error=28.7%–40.4%,determination coefficient=11.2%–20.1%,and Nash Sutcliffe Efficiency=10.4%–20.9%,respectively.The results of the Astore Station values in the test period were R2(0.853),RMSE (53.97 m3/s),MAE (33.69 m3/s),and NSE (0.843).Likewise,Gilgit Station yielded in the test period R2(0.923),RMSE(93.5 m3/s),MAE(48.63 m3/s),and NSE(0.915).
5 Analysing Scientific Maps
A continual stream of both applied and theoretical material makes keeping up with it difficult.Several authors have suggested using the R-tool and the VOS viewer to organise and show the results of the published studies in a transparent manner[136].The bibliometrics technique is distinguished by its high reliability and transparency in interpreting research results.Furthermore,these instruments are simple to utilise and are commonly accessible because they have been established and shared by the crowd.The bibliometric method was utilised in this study,as will be demonstrated below.
5.1 Country Scientific Production
It displays the total number of articles published by the country,researchers,and institution.Fig.5 depicts a graphic map of univariate streamflow data prediction using OBH and HOPH models.It has five colours.Maximum scientific output is represented by the deepest blue,while the lightest blue shows the minimum output.Gray indicates no significant scientific contribution.The highest levels of scientific output are found in Turkey,China,Algeria,Iran,and Malaysia,all of which can help advance the scientific understanding of researchers and policymakers.
5.2 Words Cloud
This word cloud investigates the most often occurring and significant words in the prior investigations.Fig.6 provides the most important concepts from the study literature in an effort to provide a summary and reorganise the data.Word sizes range from tiny to enormous.A higher frequency of occurrence was found for larger words.Thinner words are those that appear less frequently in the literature.Essential aspects of the current corpus of knowledge include river flow,hybrid model,particle swarm,swarm optimisation,and genetic algorithm.The results of the existing research suggest that optimisation algorithms are crucial factors to think about when trying to enhance ML approaches in univariate streamflow prediction models.
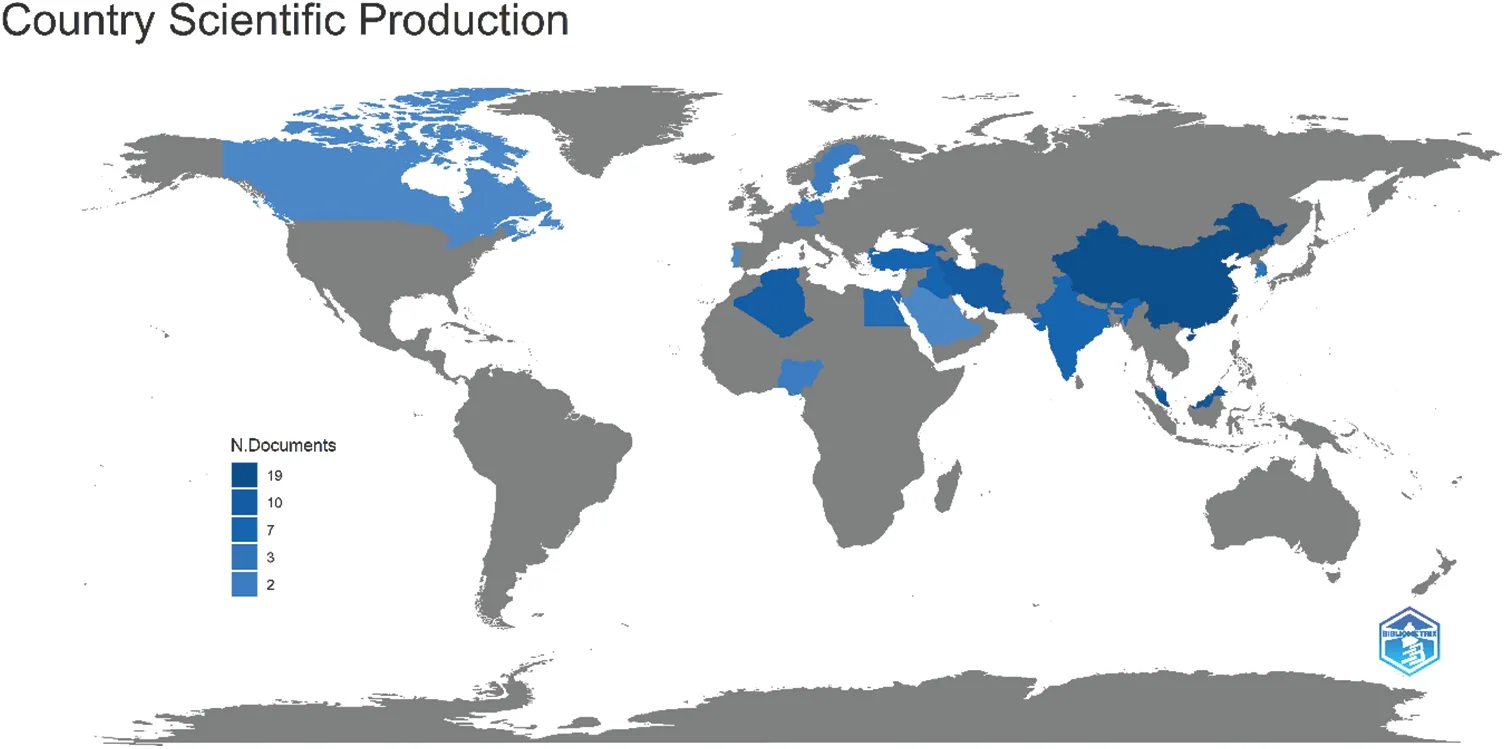
Figure 5 :The country’s scientific production map of studies on OBH and HOPH models were utilised to forecast univariate streamflow during the last five years

Figure 6 :A provides essential concepts from the academic literature
5.3 Co-Occurrence Networks
It is constructed utilising the current literature’s most frequently occurring phrases.Researchers,academics,and practitioners in a given subject may find the network structure revealed by cooccurrence analysis to be particularly useful,as it can help us understand the theoretical underpinnings of that field.Fig.7 shows the co-occurrence networks of several frequently used phrases.When it comes to previous literature,the greatest knots signify recurring topics.Optimisation techniques are among the most commonly utilised words by earlier researchers in the univariate streamflow forecast models since they may help researchers employ data networks in their attempts to reorganise the existing information and conclusions.
Figure 7 :A co-occurrence network structure
5.4 Three-Field Plot
There are potentially useful connections between journals,universities,and countries.We suggest a new three-field structure in Fig.8 that shows the relationships among the most important journals on the left,affiliations in the middle,and countries on the right.For this topic,we observed that most publications were written by writers from Malaysia,Iran,and China and published in environmental research and water resources management.The most common academic affiliations in this field are with the University of Duy Tan,the University of Malaya,and the Ilia State University.In general,Fig.8 provides a positive image for new authors to depend on.

Figure 8 :Three-field plot
5.5 Co-Occurrence Networks Authors
It is vital to identify the authors who have had the most impact on the field,which gives an impression to new researchers and provides them with consultants in their work.Similarly,gaining knowledge of author collaboration patterns in the literature might provide light on where the discipline is headed.The most influential writers in the field are summarised in Fig.9.The two most influential writers are Yaseen and Wang.
Figure 9 :A co-occurrence network authors
5.6 Journal Index Distribution
Additionally,the 31 papers that used OBH and HOPH models in the field of univariate streamflow and considered in this study are distributed over seven publishers,such as Science Direct,Springer,MDPI,IEEE,Taylor&Francis,and Hindawi,are given in the pie chart shown in Fig.10.

Figure 10 :Journal index distribution
6 Performance Metrics
The prediction precision is determined by comparing the measured and estimated flows.Different performance evaluations are used to assess the model’s predictive capabilities.An individual assessment may not be sufficient to determine the model(s)’efficacy and dependability [124,137].Additionally,the criteria employed to evaluate the accuracy of the predicting technique are crucial because they influence the selection of the optimal strategy or scenario[78,138].Also,graphical plots,such as a Taylor diagram[139],Violin diagrams[1],and scatter plots[140,141],were used to assess the predicting efficiency of the suggested methodologies.According to the finding of the current study,77% of the researchers made use of scatter plots,9% used the Violin diagrams,and 32% employed a Taylor diagram (see Fig.8).The following are the most commonly used criteria based on earlier research that are divided into three main categories:
6.1 Absolute Errors
6.1.1RootMeanSquareError(RMSE)
RMSE is the average squared deviation between the estimated and measured outputs.It is utilised for assessing the nonlinear error; this is an excellent measure of forecast accuracy [78,138].The Equation for determining RMSE is exposed in Eq.(1):
where Yiis:the forecast value,Xiis the actual value,:mean of the actual value,:the mean of the predicted value,N:the total number,i:counter.
6.1.2MeanAbsoluteError(MAE)
MAE estimates the mean of error magnitudes without regard to their direction.In other words,this is the mean absolute deviation between the predicted and actual values[142].
6.1.3MeanAbsolutePercentageError(MAPE)
MAPE is an objective statistic utilised to assess relative error by comparing predicted and observed data.MAPE is frequently insensitive to large magnitudes but sensitive to smaller magnitudes[54,143].
6.2 Relative Errors
6.2.1RelativeError(RE)
It represents the percentage error values between actual and anticipated values[144].
6.2.2MeanAbsoluteRelativeError(MARE)
This measure represents the average absolute error compared to the observed record.It is also known as the relative mean error[145,146].
6.3 Dimensionless Errors
6.3.1DeterminationCoefficient(R2)
The R2indicates the degree of correlation between the expected and measured values.The R2values range from 0 to 1: 1 means the whole relationship between the data set and the line drawn across data,and 0 indicates that there is no meaningful relationship between the type of data and the line drawn through them[39,120].
6.3.2Nash-Sutcliffe-Efficiency(NSE)
NSE was evolved by Nash et al.[147]in 1970.It measures the fit of hydrological models;When NSE equals 1,the model perfectly matches the measured data; NSE=0,model forecasts are as accurate as the mean of the empirical data[148].
6.3.3ScatterIndex(SI)
The SI is a dimensionless measure of a model’s relative accuracy.The model’s accuracy is considered poor if SI ≥30%,acceptable if 20%<SI<30%,good if 10%<SI<20%,and excellent if SI<10%[149,150].
Fig.11 shows the details of the prediction evaluation metrics and the papers’number utilising them.
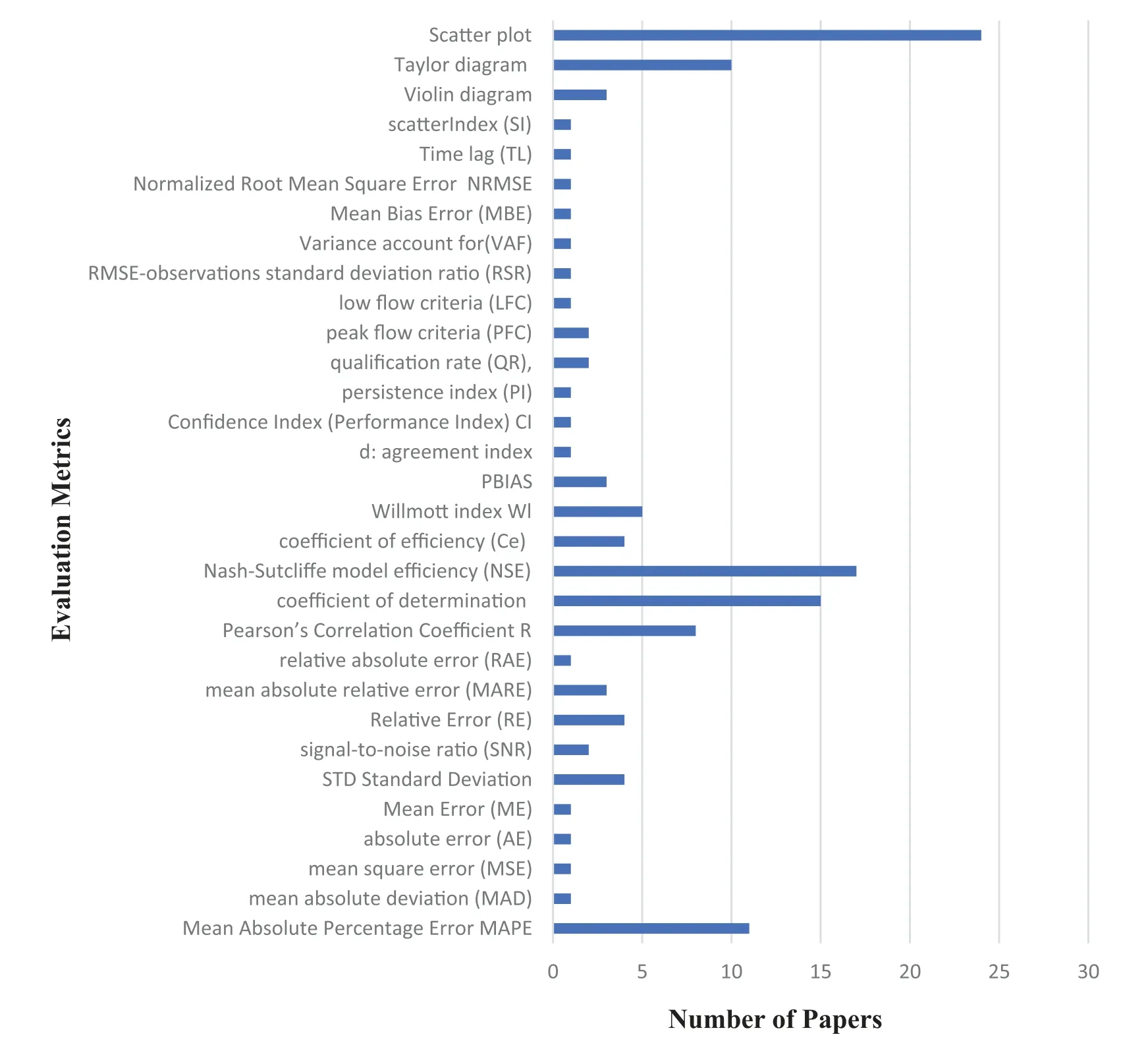
Figure 11 :Prediction evaluation metrics vs.number of papers
7 Future Research Directions
Ahmed et al.[28]advised that the proposed models could be evaluated using data from various research regions with varying climatic circumstances.Also,potential avenues for enhancing the performance of the suggested methods might be achieved by hybridising or evolving new variations of NRO before combining it with MLP.Additionally,Azad et al.[120]recommended(I)examining the performance of other acceptable evolutionary algorithms (EA) approaches and comparing them to the methods described in this study(ANFIS-GA,ANFIS-PSO,AFIS-ACOR).(II)using the offered methods of research (ANFIS-GA,ANFIS-PSO,ANFIS-ACOR) to anticipate other hydrological phenomena,(III) comparing the performance of the planned combined approach (ANFIS-PSO) to other well-known methods,such as ANNs,SVR,and GEP.Danandeh et al.[121]also applied GEPGA and GEP-LR for monthly streamflow forecasting.The recommendation was that future research might benefit from both preprocessing and post-processing methods to enhance the precision of GEP projections.
Tikhamarine et al.[33]proposed that the enhanced revised algorithm of GWO can be implemented in future research to advance the hyper-parameters optimisation and prevent local optima trapping.In addition,it is necessary to enhance the searching algorithm for the GWO to produce a rapid convergence method.Also,various advanced meta-heuristic techniques should be examined to enhance streamflow prediction.Tao et al.[19] suggested employing the mutual information (MI)statistical approach as a preliminary step in creating forecasting models to extract highly correlated data.Tikhamarine et al.[37]proposed using various meta-heuristic techniques,such as the slap swarm algorithm and grasshopper optimisation methods.
Additionally,based on an analysis of previous research,hybrid models could be enhanced in the following ways:
1.Applying the three data preprocessing stages significantly impacts the performance and precision of a model’s target.Therefore,it is suggested that more significant effort should be spent using data pre-treatment methods,such as singular spectrum analysis (SSA) and empirical mode decomposition(EMD),for denoising data.Additionally,establishing the ideal predictor combination scenario.Hence,it prefers expanding the use of the mutual information method better than the try-and-error method.
2.The use of combined ML techniques and metaheuristic algorithms for univariate streamflow forecasts has risen significantly recently.However,there is still an area for streamflow prediction improvement.
3.Recently,hybrid metaheuristic algorithms,such as CPSOCGSA (i.e.,combined swarm and physics kinds),have been confirmed effective.It would be useful to extend the current findings by examining different combinations of metaheuristic algorithms types.
4.There is still room for improving OBH and HOPH models by examining different data preprocessing techniques and metaheuristic algorithms.
8 Limitations
There are a couple of limitations to this research.Firstly,some studies may have been missed because they did not utilise the identified search terms in their title or abstract; however,the study covered previous studies very well.The second aspect is that the field is expanding so quickly that a timely survey is complex.The last limitation means that a snapshot of search activity in this active research direction does not reflect the fact that the algorithms are used but rather reflects the response to our research question,which is the aim of this research.
9 Conclusions
This study has reviewed the previous studies on typically used univariate approaches regarding prediction performance and accuracy.Since machine learning models are currently receiving more attention for streamflow prediction due to their simplicity and lower data needs compared to general hydrological techniques.This paper reviewed the recent univariate streamflow forecasting works for the last five years.
A variety of factors influence the effectiveness and accuracy of the prediction technique.Therefore,approaches were selected and compared based on data preprocessing,a univariate data-driven modelling strategy,a suitable timescale,and metaheuristic algorithms integrated into the model.Recent studies have demonstrated that different traditional ML techniques no longer produce the best accurate results.The features and limitations of ML techniques have several disadvantages,including a slow convergence rate and difficulty readily sliding into local minima.Hybrid models can address the limitations problems,involving a couple or more processes;the first works as the main method and the rest as pre-or post-processing.A combination of ML techniques and meta-heuristic optimisation techniques has been made.Consequently,hybrid models represent the most effective instruments for enhancing the precision of streamflow forecasts,such as a comprehensive hybrid approach that integrates preprocessing techniques and metaheuristic algorithms such as(OBH and HOPH).
This paper has concluded that the researchers employed swarm,evolutionary,physics,and hybrid algorithms in their articles with 77%,61%,12% and 12%,respectively.Also,the best model was 58% for the swarm,followed by 26% for evolutionary,10% for hybrid,3% for physics,and 3% for other models.
In general,this research supports the idea that meta-heuristic approaches precisely improve ML techniques.It is also one of the first efforts to comprehensively examine the efficiency of various metaheuristic approaches(classified into four primary classes)hybridised with ML techniques.There are a number of ways in which these results advance our knowledge of HOPH and OBH techniques.As there is still potential for improvement in HOPH and OBH techniques for univariate streamflow forecast techniques,it would be beneficial for academics to conduct further research into the role of metaheuristic approaches and data pre-processing techniques.Lastly,the availability of reliable univariate streamflow data drove a balance between water demand and supply that achieves sustainability.Moreover,Decision-makers should take into account the results of this study to have a scientific view of the current and expected research directions.
Acknowledgement:This paper’s logical organisation and content quality have been enhanced,so the authors thank anonymous reviewers and journal editors for assistance.
Funding Statement:The authors received no specific funding for this study.
Author Contributions:The authors confirm contribution to the paper as follows:study conception and design:B.A.K.,S.L.Z.;data collection:B.A.K.,S.L.Z.,N.A.-A.;analysis and interpretation of results:B.A.K.,S.L.Z.,N.A.-A.,Y.R.M.;draft manuscript preparation:B.A.K.,S.L.Z.,N.A.-A.All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials:Not applicable.
Conflicts of Interest:The authors declare that they have no conflicts of interest to report regarding the present study.
 Computer Modeling In Engineering&Sciences2024年1期
Computer Modeling In Engineering&Sciences2024年1期
- Computer Modeling In Engineering&Sciences的其它文章
- Blockchain-Enabled Cybersecurity Provision for Scalable Heterogeneous Network:A Comprehensive Survey
- Comprehensive Survey of the Landscape of Digital Twin Technologies and Their Diverse Applications
- Combining Deep Learning with Knowledge Graph for Design Knowledge Acquisition in Conceptual Product Design
- Meter-Scale Thin-Walled Structure with Lattice Infill for Fuel Tank Supporting Component of Satellite:Multiscale Design and Experimental Verification
- A Calculation Method of Double Strength Reduction for Layered Slope Based on the Reduction of Water Content Intensity
- An Interpolation Method for Karhunen–Loève Expansion of Random Field Discretization