
基于RI-YOLO的学生行为检测算法
2024-02-15 00:00:00牛泽刚赵玉兰
无线互联科技 2024年24期
关键词:目标检测




摘要: 针对学生行为检测算法准确率不高、易出现漏检误检问题,文章提出了一种改进的RI-YOLO学生行为检测算法。该算法通过引入感受野注意力卷积(Receptive-Field Attention Convolution, RFAConv)对C3模块进行优化,提出新型的RFAC3模块,可以更精确地捕捉细微的局部特征,提升网络特征提取能力。此外,采用基于辅助边框的交并比(Intersection over Union,IoU)损失函数Inner-IoU替代传统损失函数,加速模型的收敛速度。在学生课堂行为数据集SCB-Dataset3上验证表明,RI-YOLO平均精度mAP50较YOLOv5提升了1.5%,mAP50:95提升了1.2%,与其他主流检测模型对比,展示出了优异检测效果。
关键词:目标检测;学生行为;RFAC3;辅助边框;平均精度
中图分类号:TP391.4" 文献标志码:A
0 引言
近年来,随着大数据、深度学习等技术的快速发展,人工智能技术在多个领域取得了突破性进展,尤其是教育领域,人工智能技术得到了广泛应用[1]。通过利用基于深度学习的目标检测技术对学生在课堂上的行为进行检测,可以获取学生课堂状态和学习表现的信息,进而为教育者提供有价值的数据支持,帮助他们更好地调整教学策略,从而提升教学效率和课堂管理效果。对于学生而言,了解每个学生的具体行为模式有助于提供个性化的学习支持,确保每个学生都能获得适合自己的教学方案。总的来说,利用目标检测技术对学生课堂行为进行检测,将有助于智慧课堂的建设,对于教师教学和学生个性化学习都有积极影响。
对于学生行为检测,国内外许多学者已经做出了大量研究。刘新运等[2]设计多尺寸输出神经网络并使用聚类方法生成预选框,采用两段式训练策略对学生课堂行为进行了有效检测。贺子琴等[3]基于YOLOv5(You Only Look Once version 5)设计了基于学生课堂行为分析系统,利用自训练的权重模型对图像分类识别,实现了学生课堂行为的智能检测。夏道勋等[4]通过引入全局视觉显著性机制和基于二值范数化梯度(Binarized Normed Gradients,BING)特征,采用Faster-RCNN(Faster Region-based Convolutional Neural Network)模型和时空网络算法实现了对多种典型学生课堂行为进行检测和识别。曾钰琦等[5]创建了一个学生课堂行为数据集,提出了一种基于改进 YOLOv8的学生课堂行为检测算法,进一步通过实验证明了改进方法的有效性。
然而,现有目标检测算法在复杂背景下密集的学生检测中准确率较低,容易出现漏检和误检。学生目标密集、学生姿态多样、检测背景复杂等问题都对学生行为检测的准确度带来了影响。为了解决上述问题,本研究提出了一种改进的RI-YOLO检测算法,以提高对课堂学生行为的检测精度,有效减少误检和漏检。
1 原理与方法
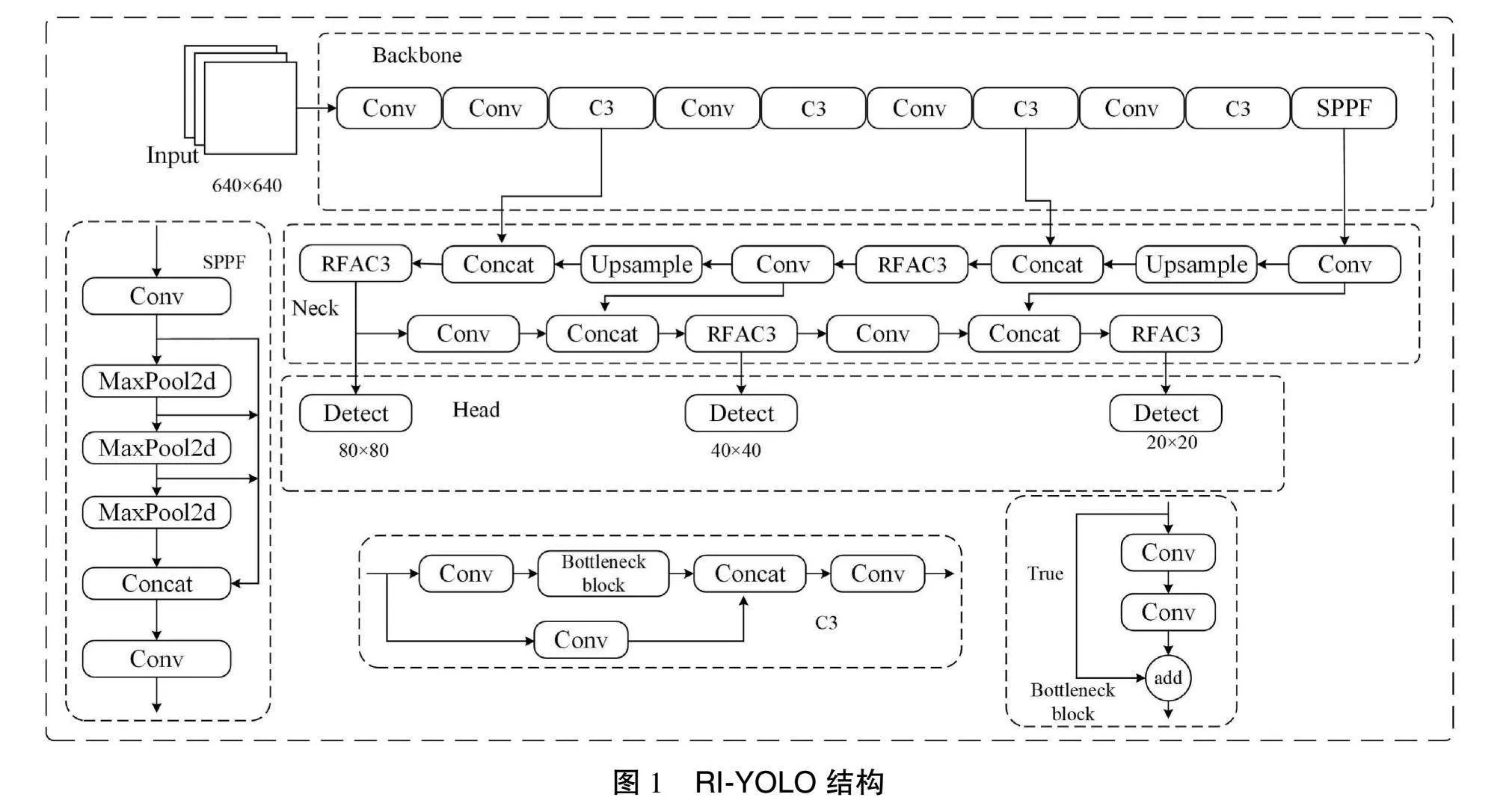
1.1 RI-YOLO网络结构
YOLOv5是一种单阶段目标检测算法,它汲取了许多优秀网络结构的优点,确保高检测精度的同时还能维持较高的检测速度,能够实现实时检测目标[6]。YOLOv5根据不同的网络深度分为s、m、l和x 4种,考虑到参数量和检测精度上的平衡,本文选择在YOLOv5s基础上进行研究。
原始 YOLOv5s算法在对学生检测中有精度不高、易发生漏检或误检等问题。针对这些问题,本研究在YOLOv5s基础上进行了改进,在特征融合阶段,利用感受野注意力卷积[7]结合C3(CSP Bottleneck with 3 Convolutions)模块生成全新的RFAC3模块,网络能更有效地理解和处理图像中的局部区域,从而提高特征提取的精确性,得到更全面的特征信息。其次采用Inner-IoU辅助边界框损失,使用不同尺寸的辅助边框,进一步加快收敛过程,改善目标的检测效果。通过上述改进,RI-YOLO相比于原始YOLOv5s网络的整体检测效果得到大幅提升。RI-YOLO结构如图 1所示。
1.2 融合感受野注意力的RFAC3
在原始的YOLOv5特征融合网络中,C3模块对有遮挡情况的目标检测效果较差,因此本研究引入感受野注意力卷积改进原有C3模块,提出全新的RFAC3模块,提高网络性能,感受野注意力卷积的结构如图 2 所示。
相较于传统卷积,RFAConv使用了交互感受野特征信息的方法,网络能更有效地理解和处理图像不同区域的信息,从而提升网络在复杂场景下的表现。在传统的卷积神经网络中,卷积核在处理不同区域的图像时共享同样的参数,这可能限制了模型对于复杂模式的学习能力,而RFAConv通过引入感受野注意力机制,动态地为不同的感受野分配不同的卷积核参数,从而更好地捕捉不同区域的信息特征,解决了卷积核参数共享导致的局限性。利用RFAConv得到改进后的RFAC3,不仅解决了卷积核参数共享的问题,还充分考虑了感受野中每个特征在全局中的重要性,使改进后的网络在识别和定位目标时更加精准[7]。
1.3 基于辅助边框的IoU损失
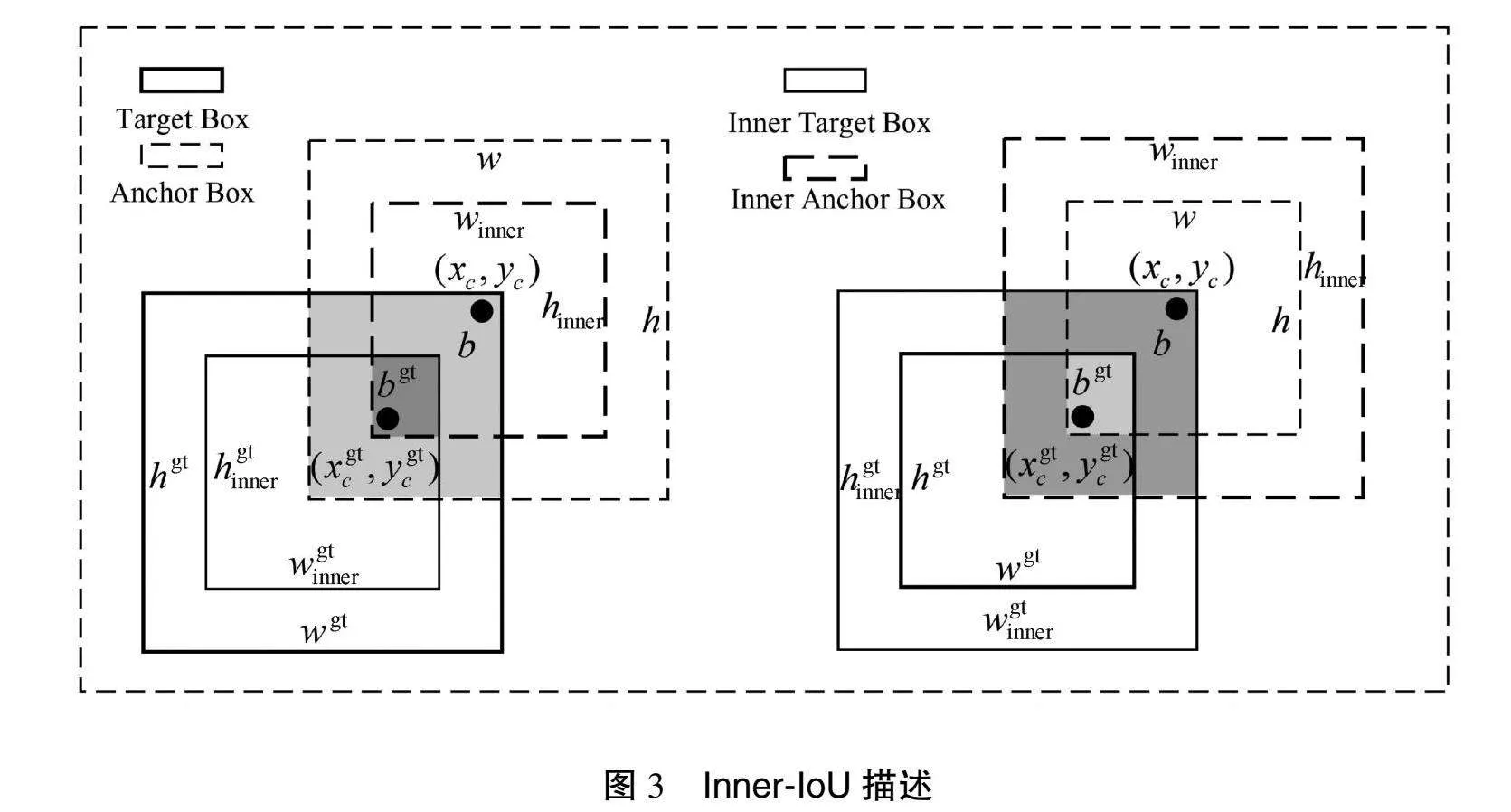
现有的基于IoU的边框回归方法通常通过引入新的损失项来加速收敛,但忽略了IoU损失本身的局限性。为此,本研究引入了辅助边框损失函数Inner-IoU Loss[8],利用辅助边框来计算IoU损失,针对不同的回归样本使用不同尺度的辅助边界框,从而有效加速边界框回归过程。Inner-IoU描述如图3所示。
如图3所示,Inner-IoU定义如下:
blgt=xcgt-wgt×ratio2,brgt=xcgt-wgt×ratio2(1)
btgt=ycgt-hgt×ratio2,bbgt=ycgt-hgt×ratio2(2)
br=xc-w×ratio2,bl=xc-w×ratio2(3)
bt=yc-h×ratio2,bb=yc-h×ratio2(4)
inter=(min(brgt,br)-max(blgt,bl)×(min(bbgt,bb)-max(btgt,bt))(5)
union=(wgthgt)×(ratio)2+(wh)×(ratio)2-inter(6)
IoUinner=interunion(7)
其中,bgt和b分别为真实框和预测框;xgtc和ygtc为真实框的中心坐标点;xc和yc为预测框的中心坐标点;bgtt、bgtr、bgtt和bgtb分别为真实框的左、右、上、下边界;bl、br、bt和bb分别为预测框的左、右、上、下边界;w、h、wgt、hgt分别为预测框和真实框的宽和高;inter为预测框与真实框的重叠区域;union为两者的总覆盖区域。
Inner-IoU应用至现有基于IoU的边框回归损失函数中,则Linner-CIoU被定义为:
Linner-IoU=1-IoUinner(8)
Linner-CIoU=LCIoU+IoU-IoUinner(9)
相比于其他损失函数,Inner-IoU Loss更加关注边界框的核心部分,能够对重叠区域提供更精确的评估。当尺度因子ratio小于1时,辅助边框小于实际边框,此时回归范围小于标准IoU损失,但由于梯度较大,可以加速高IoU损失情况下的收敛。相反,当ratio大于1时,辅助边框的尺度较大,扩展了回归范围,有助于低IoU情况下的回归优化。
2 实验结果与分析
2.1 数据集与评价指标
实验采用的数据集为Yang等[9]制作的学生课堂行为(Student Classroom Behavior Datasets, SCB-Dataset)数据集。该数据集从不同角度(包括正面、侧面和背面)收集了真实的学生课堂行为图像。其中,SCB-Dataset3数据集包含5686张图像和45578个标签,涵盖了6种学生行为:举手、阅读、写作、使用电话、低头以及俯身在桌上,这些行为数据涵盖了从幼儿园到大学的学生群体。SCB-Dataset3数据集相比于前2个版本(SCB-Dataset1和SCB-Dataset2),在学生行为种类和场景丰富性上有显著提升。
本研究采用的评价指标有准确率(Precision, P)、召回率(Recall, R)、平均准确率均值(Mean Average Precision, mAP)。P 表示精度,衡量预测为正样本的准确性;R 表示召回率,衡量识别出的正样本比例;mAP 代表所有类别的平均精度。
2.2 消融实验分析
为更好地评估改进结构对模型整体性能的贡献,本研究进行了消融实验,实验结果如表1所示。从改进点的消融实验可以看出,编号2的实验中采用了RFAC3模块,与原始YOLOv5(编号1)相比,加入RFAC3后的网络模型mAP@0.5提升了0.9%,这表明RFAC3模块的引入增强了网络对复杂背景特征信息的提取能力,使得模型在处理图像时更加高效。编号3表示将 CIoU损失函数替换为 Inner-IoU,其引入尺度因子 ratio 控制辅助边界框的尺寸,加速模型的收敛速度,mAP 相较原模型提高了 0.7%。编号4为改进后的RI-YOLO模型,通过结合2个模块的共同作用,相较于原始YOLOv5s平均精度mAP50提升了1.5%,mAP50:95提升了1.2%。
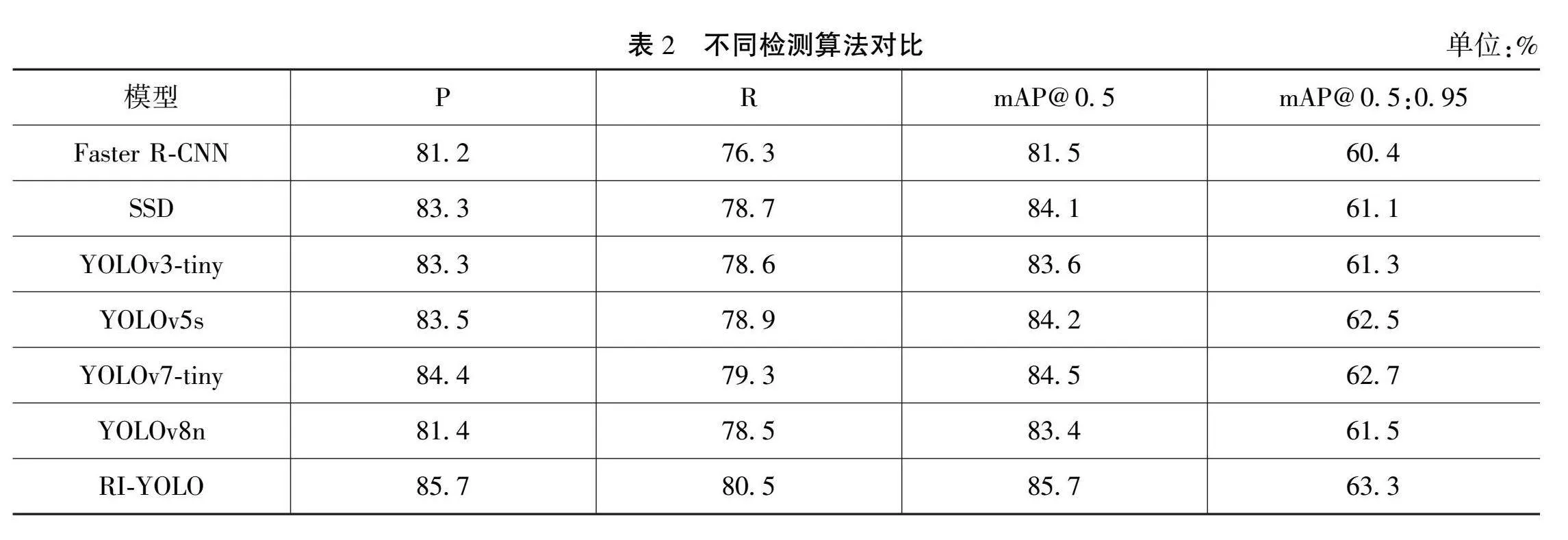
2.3 不同模型对比试验
为了进一步证明 RI-YOLO 在学生行为检测中的优势,本研究在SCB-Dataset3数据集上与现有综合性能较高的目标检测模型进行了对比实验,包括 Faster R-CNN、SSD、YOLOv3-tiny、YOLOv5s、YOLOv7-tiny和 YOLOv8n检测算法,实验结果如表2 所示。通过表2中数据可以看出,RI-YOLO与几种主流模型对比,平均精度mAP50分别提升了3.2%、1.6%、2.1%、1.5%、1.2%、2.3%,进一步验证了RI-YOLO模型在学生行为检测问题上的优越性和可行性。
RI-YOLO 在 SCB-Dataset3 数据集上的检测效果如图 4所示。由图4可以看出,本研究中学生场景非常丰富,涵盖了从小学到中学的各类课堂场景,人员密度很大,传统YOLOv5s 容易出现误检或漏检问题,而通过RI-YOLO则增强了对学生行为的检测能力。
3 结语
针对现有目标检测算法在对学生行为检测中准确率不高、易出现漏检误检等问题,本研究提出了一种基于YOLOv5s的改进RI-YOLO学生行为检测算法。首先,结合感受野注意力卷积RFAConv与C3模块,提出了全新的RFAC3模块,使网络能够更加有效地理解和处理图像中的局部区域。然后利用Inner-IoU 的辅助边框计算IoU损失,对于不同的回归样本使用不同尺度的辅助边界框来计算损失,有效加速了边界框回归过程。通过在SCB-Datase3数据集上进行试验,RI-YOLO平均精度 mAP50值达到 85.7%,达到预期要求,有效缓解了传统检测算法对目标密集、姿态多样、遮挡率较高的学生行为检测效果较差的难题,证明了改进方法的有效性。
参考文献
[1]陶施帆.人工智能技术在计算机网络教育中的应用探讨[J].通讯世界,2024(9):55-57.
[2]刘新运,叶时平,张登辉.改进的多目标回归学生课堂行为检测方法[J].计算机工程与设计,2020(9):2684-2689.
[3]贺子琴,黄文辉,肖嘉彦,等.基于YOLOv5的学生课堂行为分析系统设计[J].电脑知识与技术,2023(26):19-22.
[4]夏道勋,田星瑜,唐胜男.基于视觉注意力的学生课堂行为分析[J].贵州师范大学学报(自然科学版),2021(4):83-89.
[5]曾钰琦,刘博,钟柏昌,等.智慧教育下基于改进YOLOv8的学生课堂行为检测算法[J].计算机工程,2024(9):344-355.
[6]井方科,任红格,李松.基于多尺度特征融合的小目标交通标志检测[J].激光与光电子学进展,2024(12):372-380.
[7]ZHANG X, LIU C, YANG D, et al. RFAConv: innovating spatital attention and standard convolutional operation [EB/OL]. (2023-04-03) [2024-10-02]. http://arxiv.org/abs/2304.03198.
[8]ZHANG H, XU C, ZHANG S J. Inner-IoU: more effective intersection over union loss with auxiliary bounding box [EB/OL]. (2023-11-14) [2024-10-02]. http://arxiv.org/abs/2311.02877.
[9]YANG F, WANG T. SCB-Dataset3: a benchmark for detecting student classroom behavior [EB/OL]. (2023-08-04) [2024-10-03]. http://arxiv.org/abs/2310.02522.
(编辑 王永超编辑)
Student behavior detection algorithm based on RI-YOLO
NIU" Zegang1, ZHAO" Yulan1,2*
(1.Jilin Institute of Chemical Technology, Jilin 132022, China; 2.Jilin Agricultural Science and
Technology University, Jilin 132101, China)
Abstract:" To address the issues of low accuracy in student behavior detection algorithms, which often lead to missed detections and 1 positives, the article proposes an improved student behavior detection algorithm based on YOLOv5s called RI-YOLO. The algorithm optimizes the C3 module by introducing Receptive-Field Attention Convolution (RFAConv), proposing a new RFAC3 module that can more accurately capture subtle local features, thereby enhancing the network’s feature extraction capabilities. Additionally, it adopts an Inner-IoU loss function based on auxiliary bounding boxes to replace traditional loss functions, accelerating the convergence speed of the model. Testing on the student classroom behavior dataset SCB-Dataset3 shows that RI-YOLO improves mean average precision (mAP50) by 1.5% compared to YOLOv5, and mAP50:95 by 1.2%, demonstrating superior detection performance when compared with other mainstream detection models.
Key words: object detection; student behavior; RFAC3; auxiliary bounding box; mean average precision
猜你喜欢
科技创新与应用(2016年36期)2017-02-21 18:48:01
软件(2016年4期)2017-01-20 09:38:03
科教导刊·电子版(2016年28期)2017-01-10 22:25:23
科学与财富(2016年28期)2016-10-14 23:45:18
无线互联科技(2016年7期)2016-05-30 13:57:06
电脑知识与技术(2016年5期)2016-04-14 13:48:16
科技视界(2016年4期)2016-02-22 13:09:19
哈尔滨理工大学学报(2015年5期)2016-01-19 18:06:12
湖南大学学报·自然科学版(2015年10期)2015-11-30 18:52:07
现代电子技术(2015年20期)2015-10-26 22:48:16
