
城市固体废物焚烧过程炉温的鲁棒加权异构特征集成预测模型
2024-02-03 10:41郭京承严爱军
自动化学报 2024年1期
郭京承 严爱军,3 汤 健
焚烧可以实现城市固体废物(Municipal solid waste,MSW)的减量化、无害化和资源化,是MSW处理的主要方式之一[1-2].在MSW 焚烧过程中,炉温是评估焚烧过程运行合格与否的关键指标之一.为了保证焚烧过程中二噁英气体被完全分解,炉温需要持续控制在850 ℃以上[3].然而,在焚烧炉内的高温环境下,炉内热电偶存在易损坏和精度低等问题,并且由于焚烧过程具有滞后性,操作人员难以及时判断炉温变化情况.因此,构建炉温预测模型,对指导与优化MSW 焚烧过程稳定运行,具有现实意义.
目前,炉温预测模型主要包括机理模型和数据驱动模型两类.机理模型是根据焚烧过程中固、气相反应的物理化学变化以及能量、动量守恒等先验知识,确定炉排速度、一次和二次风机风量等操作变量与炉温的映射关系[4-5].虽然这类模型在可靠性和解释性方面具有优势,但焚烧过程机理的复杂性和MSW 热值的不确定性导致机理模型的预测精度无法保证.而以人工神经网络为代表的数据驱动模型,无需获取焚烧过程中的复杂机理和先验知识,通过运行数据,学习输入变量与炉温之间的映射关系[6-7].这类模型的训练算法普遍采用误差反向传播算法,存在收敛速度慢和容易陷入局部最优等问题.随机学习技术通过随机分配隐含层输入权重和偏置,将神经网络模型训练问题转化为求解线性优化问题[8],可以实现神经网络的快速训练.Wang 等[9]引入一种依赖于数据的监督机制,递增式地快速构建神经网络模型,从而获得了具有万能逼近性质的随机配置网络(Stochastic configuration network,SCN)模型.该模型在参数建模领域的成功应用,为构建焚烧过程炉温预测模型提供了技术支持[10-12].然而,焚烧过程数据存在异常值和特征变量维度高的现象,使得SCN 模型的准确性和泛化能力仍有待提升.
在提升SCN 模型对异常值的鲁棒性方面,文献[13]将核密度估计方法与M估计相结合,并采用加权最小二乘法计算模型输出权重,提升了SCN模型对异常值的鲁棒性.文献[14]使用最大相关熵准则度量训练样本的惩罚权重,在提升SCN 模型鲁棒性方面,有不错的效果.此外,工业过程的复杂性和不确定性导致单一分布难以恰当描述样本中异常值的分布情况,文献[15]和文献[16]分别采用将高斯分布与若干个拉普拉斯分布的混合分布以及混合t分布,作为训练样本的异常值分布,均在不同程度上缓解了异常值对建模性能的影响.但随着特征变量维度的增加,单个SCN 模型的泛化能力难以保证.
在具有高维特征变量情况下,虽然特征选择与特征提取技术通过选择部分重要特征或提取高维数据中的主成分来构建数据驱动模型[17-18],但可能损失高维特征数据中蕴含的部分信息,从而影响模型准确性.文献[19]提出一种异构特征神经网络集成的框架,该框架以SCN 为基模型,并通过负相关学习(Negative correlation learning,NCL)策略[20],实现了基模型之间的同步训练,在高维特征数据建模方面,具有不错的应用前景.但该方法未考虑各组异构特征对输出变量的重要性以及异常值对模型准确性的影响.
基于上述分析,本文综合考虑MSW 焚烧过程数据中同时存在异常值和高维特征变量两种情况,提出一种用于构建MSW 焚烧过程炉温预测模型的鲁棒加权异构特征集成建模方法.本文主要贡献如下: 1)综合焚烧过程运行机理以及焚烧炉排构造,将高维特征变量划分为异构特征集合,应用后续集成建模;2)在异构特征集成框架的基础上,采用互信息和皮尔逊相关系数(后续简称“相关系数”),确定每组异构特征对输出变量的贡献度,从而明确每个基模型的重要性;3)采用文献[16]的鲁棒SCN构建基模型,并综合各个基模型的训练过程确定样本惩罚权重;4)设计一种鲁棒加权NCL 策略,实现基模型之间的鲁棒同步训练.采用焚烧过程的炉温历史数据,验证了本文方法的有效性和优越性.
1 MSW 焚烧过程
MSW 焚烧过程的工艺流程如图1 所示.MSW焚烧过程由固体废物储运系统、固体废物焚烧系统、余热锅炉系统、蒸汽发电系统和烟气处理系统5 个系统组成,各系统的具体功能如下:
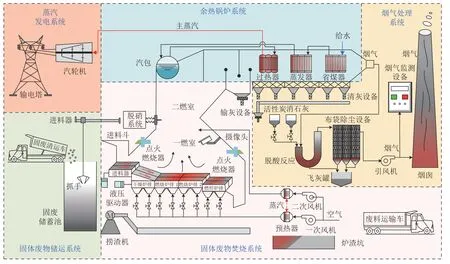
图1 MSW 焚烧过程工艺流程图Fig.1 MSW incineration process flow chart
1)固体废物储运系统.生活中产生的MSW 由固体废物清运车送至固体废物储蓄池内.MSW 具有高水分、低热值的特点,需要在储蓄池内静置3~10 天,以完成MSW 的脱水、发酵环节,并由抓手送至焚烧炉的进料器,进行焚烧.
2)固体废物焚烧系统.预处理后的MSW 由进料器送入干燥炉排.在一次风对流换热以及炉内高温辐射的作用下,完成MSW 的水分干燥过程;干燥后的MSW 经过2 段燃烧炉排,在高温作用下,析出挥发分,并与一次风中的氧气在一燃室燃烧,未充分燃烧的挥发分气体在二次风的作用下,进一步燃烧;MSW 中的固定碳在燃烬段炉排燃烧.
3)余热锅炉系统和蒸汽发电系统.由MSW 焚烧产生的高温气体在烟气通道内,依次通过过热器、蒸发器和省煤器,实现烟气余热回收,回收的热量将冷却水转化为主蒸汽,用于汽轮机发电,从而实现焚烧过程的资源化.
4)烟气处理系统.焚烧过程产生的烟气将分别通过脱酸反应、布袋除尘设备实现烟气处理,并在引风机的作用下,由烟囱排出.
在焚烧工艺流程中,炉温通常指一燃室烟气的平均温度,是衡量焚烧过程运行是否正常的关键指标之一.目前,现场采用热电偶实时测量炉温的变化情况.然而,在炉内高温环境下,热电偶存在精度低和易损坏等问题.并且,炉温变化具有滞后性,即调整过程变量后,炉内的热电偶难以及时反映炉温的变化情况.基于上述炉温的特点可知,构建炉温预测模型,对保证焚烧过程安全稳定运行,具有现实意义.
从构建炉温预测模型的角度看,影响炉温的机理反应主要包括水分干燥、挥发分析出、挥发分燃烧等多阶段的物理化学变化[21].这导致构建炉温预测模型涉及的特征变量数量众多,变量明细如表A1所示.采用特征选择或特征提取方法可以降低预测模型的输入变量维度,提升模型的泛化能力,但降低特征维度会损失过程数据中蕴含的部分信息.另外,焚烧过程数据中包含的异常值会导致炉温预测的准确性降低.因此,本文的研究重点是在焚烧过程数据具有高维特征变量和异常值的情况下,提升炉温预测模型的准确性和泛化能力.
2 鲁棒加权异构特征集成建模方法
针对焚烧过程数据同时存在异常值和高维特征变量的特点,提出一种鲁棒加权异构特征集成建模方法,着重提升MSW 焚烧过程炉温预测模型的准确性和泛化能力.下面分别介绍该方法的建模策略和实现过程.
2.1 建模策略
鲁棒加权异构特征集成建模方法的建模策略如图2 所示.首先,依据焚烧过程机理和炉排结构,将MSW 焚烧过程炉温的高维特征变量训练集划分为异构特征集合,并以互信息和相关系数综合评估每组异构特征对炉温的贡献度;其次,采用文献[16]的鲁棒SCN 建模方法,构建每组异构特征对应的基模型,并综合所有基模型的训练情况,确定训练样本的惩罚权重;最后,根据训练样本的惩罚权重和每组异构特征的贡献度,设计一种鲁棒加权NCL策略,实现基模型间的同步训练,从而获得最终的炉温预测模型.
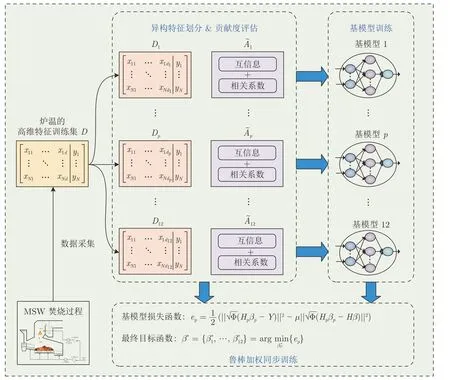
图2 建模策略图Fig.2 Diagram of the modeling strategy
图2 中,D表示炉温的高维特征训练集,d表示输入变量维度,N表示训练样本数量;Dp表示第p组异构特征对应的训练子集,dp表示第p组异构特征的维度,p=1,2,···,12,所有训练集的输出变量保持一致;表示第p组异构特征对炉温的贡献度,由输入变量和输出变量的互信息和相关系数综合确定;ep表示第p个基模型的损失函数,Φ 是训练样本的惩罚权重,Hp和βp分别表示第p个基模型的隐含层输出矩阵和输出权重矩阵,H和β分别由所有基模型隐含层输出矩阵和输出权重矩阵组成;µ为NCL 惩罚因子,Y为相应的输出矩阵.
2.2 实现过程
基于上述建模策略,本节分别介绍异构特征划分与贡献度评估、基模型训练和鲁棒加权同步训练的实现过程,并在最后给出算法伪代码.
2.2.1 异构特征划分与贡献度评估
从焚烧过程运行机理看,炉温受水分干燥、挥发分析出、挥发分燃烧等阶段影响[21-22].另外,从炉排上方热电偶分布情况看,炉排上方安装了12 组K 型铠装热电偶,分布情况如图3 所示.综合考虑各阶段的运行机理和炉排上方热电偶分布,将表A1中的特征变量划分为12 组异构特征,每组异构特征包括当前段的炉排速度、一次风量、炉排出口温度、一次风温度、一次风机压力、二次风量和当前炉温7 个变量.此时,异构特征对应的训练集记为Dp={Xp,Y},其中p=1,2,···,12,Xp为第p个训练集的输入矩阵.
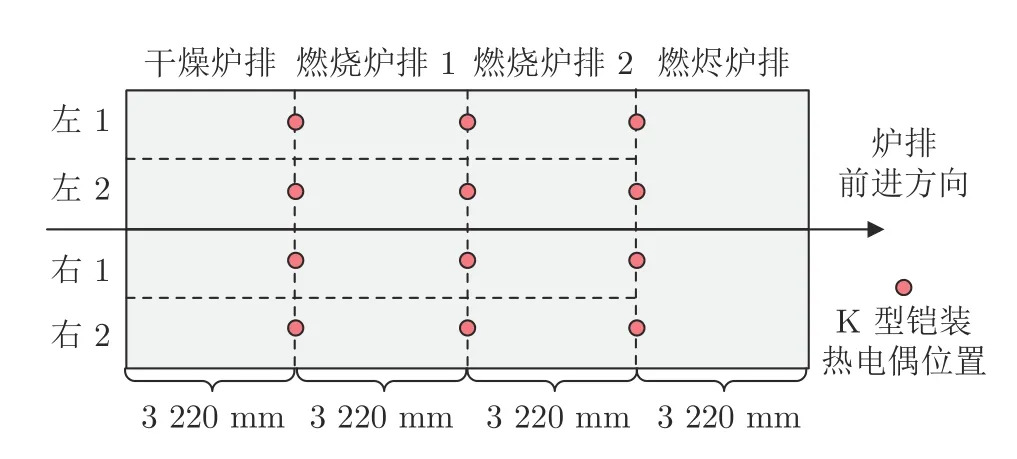
图3 炉排上方热电偶分布情况Fig.3 The distribution diagram of thermocouple on the grate
首先,对第p个训练集Dp,分别计算每个输入变量与炉温的互信息和相关系数:
式中,x i∈R1×N表示第i个输入变量,Y∈R1×N表示输出矩阵即炉温;p x(x) 和p y(y) 分别表示x和y的边缘概率分布;p(x,y) 表示x和y的联合概率分布;i=1,2,···,dp,dp为第p组异构特征的特征数量,p=1,2,···,12;Cov(xi,Y) 表示xi与Y之间的协方差;Var(xi) 和 Var(Y) 分别表示xi与Y之间的方差.然后,采用互信息和相关系数的乘积作为每个特征变量与输出变量相关性的评估指标,并以所有变量与炉温相关性的平均值表示第p组异构特征的贡献度:
式中,ai表示第i个特征变量与炉温的相关性;Ap表示第p组异构特征的贡献度,故Ap越大,表示该异构特征对炉温影响越大.
最后,对每组异构特征的贡献度进行归一化处理:
2.2.2 基模型训练
焚烧过程数据中的异常值会降低基模型准确性,因此,本节采用基于混合t分布的鲁棒SCN[16],实现基模型的训练过程.该方法实现步骤如下:
步骤1.初始化基模型的最大隐含层神经元数量、最大随机配置次数和混合t分布的位置参数、尺度参数和自由度;
步骤2.采用SC-III 算法,确定基模型的网络结构和连接权重;
步骤3.计算基模型输出权重在给定训练集下的期望值;
步骤4.使步骤3 中的期望值最大化,从而确定模型输出权重和混合t分布的位置参数、尺度参数和自由度;
步骤5.判断算法是否收敛? 若达到收敛条件,基模型训练结束;否则,返回步骤3.
因此,训练完成的基模型Mp可以表示为:
来该院治疗的糖尿病患者90例,其中男65例,年龄 32~75 岁,平均(40±10.3)岁,女 25 例,年龄 44~67岁,平均((50±9.7岁)根据随机分组的原则,分为对照组和观察组各45例,其中对照组男30例,年龄32~70岁,平均(47.6±2.3)岁,女 15 例,年龄 45~65 岁,平均(47.6±2.3)岁,观察组其中男 38 例,年龄 35~75 岁,平均(40+7.5)岁,女 10 例,年龄 45~67 岁,平均(48.5±2.4)岁。对两组患者分别采取常规尿液检查和生化检验的诊断方式。
式中,Hp和βp分别表示第p个基模型的隐含层输出矩阵和输出权重矩阵;φ(·) 是Sigmoid 激活函数;Lp表示第p个基模型的隐含层神经元数量,p=1,2,···,12.为了后续表述简洁,令H=[H1,···,H12]表示由所有基模型隐含层输出和贡献度乘积构成的矩阵;β=[β1,···,β12] 表示所有基模型输出权重构成的矩阵.在上述训练过程中,每个基模型均可获得一组训练样本的惩罚权重矩阵,综合考虑所有基模型的训练结果,将所有惩罚权重矩阵的均值作为最终训练集的惩罚权重,记为 Φ.此时,基模型训练过程结束.
注1.本节采用基于混合t分布的鲁棒SCN[16]构建基模型,其优势在于混合t分布具有重尾特性,且通过调整自由度可以使其概率密度曲线适应不同类型的异常值分布,故该方法构建的基模型对训练数据中的异常值具有较强的鲁棒性.此外,在基模型训练过程中,可以获得训练样本的惩罚权重,这为后续鲁棒加权同步训练奠定了基础.
2.2.3 鲁棒加权同步训练
NCL 策略是实现神经网络集成模型同步训练的重要方法,该方法通过在神经网络集成的损失函数中,引入基模型间的相关惩罚项,实现基模型输出之间的负相关,从而降低基模型输出之间的协方差[20].文献[19]和文献[23]均采用了NCL 策略,实现了随机学习模型间的同步训练,从而提升了神经网络集成模型的准确性.然而,在MSW 焚烧过程中,由于运行数据中存在服从未知分布的异常值,导致NCL 策略的鲁棒性难以保证.因此,本节设计一种鲁棒加权NCL 策略,来实现基模型之间的鲁棒同步训练.
在每个基模型的代价函数中引入训练样本的惩罚权重矩阵 Φ,则第p个基模型的训练代价函数为:
此时,鲁棒异构特征集成模型的目标函数可以表示为:
式中,β*表示同步训练后集成模型的隐含层输出权重矩阵.
式中,N表示训练样本数量,Lp表示第p个基模型的隐含层神经元数量.
对于p=1,2,···,12,采用线性矩阵运算形式,可将式(9)表示为:
式中,H定义如下:
根据式(10),可得基模型隐含层输出权重的解析解:
此时,MSW 焚烧过程炉温的鲁棒异构特征集成模型构建完毕.基于上述分析,鲁棒异构特征集成算法伪代码见算法1.
算法1.鲁棒加权异构特征集成算法
输入.训练子集D={D1,···,D12}.
输出.鲁棒加权异构特征集成模型.
1)初始化.鲁棒SCN 的超参数、基模型的最大隐含层神经元数量Lmax、NCL 的惩罚因子µ;
2) for {p ←1 to 12};
3)用式(1)和式(2)计算每组异构特征与炉温的互信息和相关系数;
5)依据文献[16]的鲁棒SCN,构建基模型Mp;
6) end;
7)用式(11)计算H;
8)用式(12)更新集成模型输出权重;
9)返回鲁棒加权异构特征集成模型.
注2.本文提出的鲁棒加权异构特征集成建模方法以异构特征集成框架为基础,采用基于混合t分布的鲁棒SCN 构建基模型,保证了基模型对训练数据的鲁棒性.通过设计鲁棒加权NCL 策略,实现了基模型的同步训练,并依据每组异构特征的贡献度,将各个基模型输出的加权平均值作为集成模型的最终输出.该方法对训练数据中的异常值具有较强的鲁棒性,并且通过将表A1 中的高维特征变量划分为 12 组异构特征,降低了基模型的复杂程度,从而保证了炉温预测模型的泛化能力.
3 实验测试
本节采用MSW 焚烧过程的历史数据,验证鲁棒加权异构特征集成建模方法的有效性,并将结果与其他典型集成建模方法进行比较.
3.1 数据准备
本文采用的实验数据为2020 年10 月北京某焚烧发电厂的历史运行数据,其中样本采样间隔为5 min 且所有数据经过归一化处理.训练集样本数量为700,测试集样本数量为200,验证集样本数量为100,均由随机采样获得.输入特征变量维度为42,输出变量为10 min 后的炉温预测值,详细信息见表A1.在本文提出的鲁棒加权异构特征集成炉温预测模型中,依据第2.2.1 节内容,异构特征共划分为12 组,其中第1~4 组对应干燥段炉排,第5~8 组对应燃烧1 段炉排,第9~12 组对应燃烧2 段炉排.每组异构特征包含对应段的炉排速度、一次风量、炉排出口温度、一次风温度、一次风机压力、二次风量以及当前炉温.本文实验采用的性能评价指标为均方根误差(Root mean square error,RMSE)和平均绝对误差(Mean absolute error,MAE),计算公式如下:
式中,N表示样本数量,yi表示炉温的真值,是炉温的预测值.为了避免随机参数对实验结果的影响,所有实验结果均为50 次独立重复实验结果的均值和标准差.
为了突显模型对训练数据中异常值的鲁棒性,在训练样本中,分别随机选择0%、10%和20%比例的样本作为异常样本,并将这些样本的输出进行异常化处理,具体处理方式为:
式中,yi和y i,outlier分别表示炉温的真实值和处理后的异常值,rand(0,1)表示0 和1 之间的随机数,max(yi) 和 min(yi) 分别表示正常工况下炉温的最大值和最小值.为了使异常值分布更加不平衡,正偏差异常值(sign=1)和负偏差异常值(sign=-1)的比例设置为2:1.
3.2 性能测试
本节对基于鲁棒加权异构特征集成的炉温预测模型开展性能测试.为了后续表述简洁,将本文方法命名为Mt-RSCNE.由图4 的异构特征集合对炉温的互信息、相关系数和贡献度的对比可以看出,第1~4 组的贡献度较高,说明干燥段炉排对应的特征变量对炉温变化的影响较大.其原因在于MSW具有高水分、低热值的特点,随着焚烧过程运行,在水分干燥过程中吸收的热量差异较大.因此,结果与焚烧过程的运行机理存在一致性.
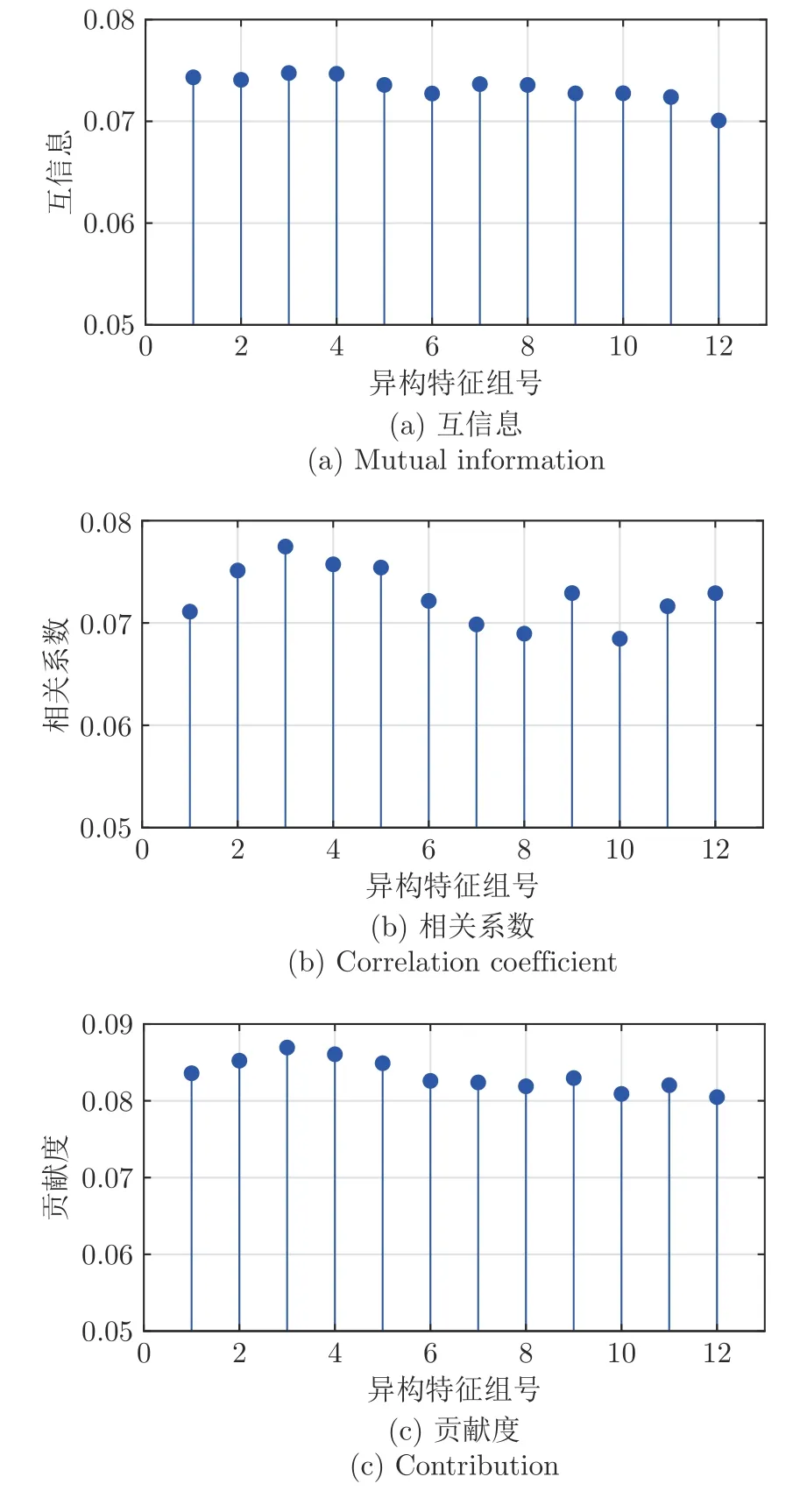
图4 每组异构特征集合对炉温的互信息、相关系数和贡献度对比Fig.4 Comparison of mutual information,correlation coefficient,and contribution of each heterogeneous feature set to furnace temperature
基模型隐含层神经元数量Lmax和NCL 惩罚因子µ是Mt-RSCNE 模型中的两个重要参数.为了验证模型对上述超参数的鲁棒性,图5 和图6 分别为Lmax和µ取不同数值时,模型测试误差的分布情况.其中,Lmax的取值为10~50,间隔数量为5;µ的取值为0.1~0.9,间隔数量为0.1.由图5可以看出,随着基模型隐含层神经元数量的增加,炉温预测模型50 次实验的测试误差均值变化较小,但测试误差的标准差变化较大,说明当Lmax较大时,炉温预测模型可能出现过拟合现象.因此,在后续实验中,基模型隐含层神经元数量设置为15.由图6 可以看出,µ的取值对炉温预测模型的测试性能有轻微影响,但影响并不显著,说明本文方法对参数µ具有较好的鲁棒性.
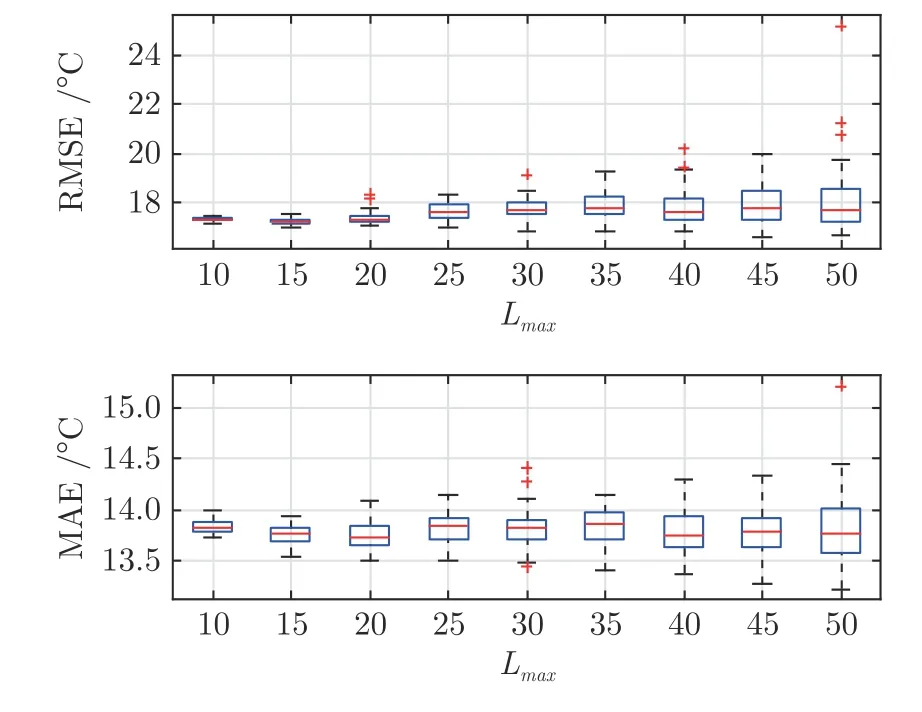
图5 Lmax 取值为10~50 时,炉温预测模型在验证集上的误差分布Fig.5 Error distribution of the furnace temperature prediction model on the verification set with Lmax from 10~50
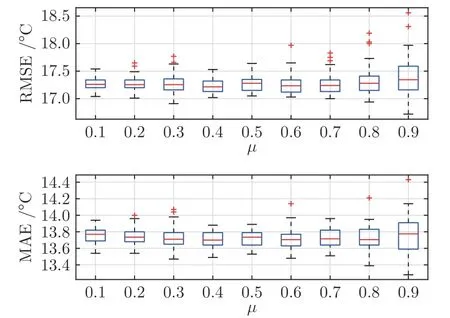
图6 µ 取值为0.1~0.9 时,炉温预测模型在验证集上的误差分布Fig.6 Error distribution of the furnace temperature prediction model on the verification set withµfrom 0.1~0.9
3.3 对比分析
为了验证本文提出的Mt-RSCNE 模型在准确性和泛化能力方面的优越性,本节将该方法与典型建模方法构建的炉温预测模型的预测结果进行对比分析.为表达简洁,使用如下缩写表示各建模方法:MoGL-SCNE 表示基于混合高斯分布和拉普拉斯分布的集成SCN 建模方法[15],SCNE 表示基于SCN的经典异构特征集成方法[19],DNNE 表示快速去相关神经网络集成方法[23],BESCN 表示基于Bootstrap 集成的SCN[24].
本文的Mt-RSCNE 方法的实验参数设置如下:基模型隐含层神经元数量为15,基模型最大配置次数为50,混合t分布的组分数量为3,权重分别为0.5、0.3 和0.2,位置参数均为0,尺度参数分别为0.12、0.11 和0.10,自由度均为4,NCL 惩罚因子µ为0.1.对比方法参数设置如下: 1) DNNE 方法.基模型数量为12,基模型隐含层神经元数量为15,随机权重选择范围为[-1,1].2) SCNE 方法.与本文方法一致.3) MoGL-SCNE 方法.基模型数量为12,基模型隐含层神经元数量为15,混合分布由高斯分布和两个拉普拉斯分布组成.其中高斯分布的权重为0.8,均值为0,方差为0.2,两个拉普拉斯分布权重均为0.1,尺度参数均为0.1.4) BESCN 方法.基模型数量为12,基模型隐含层神经元数量为15,误差分布和输出权重先验分布的方差分别为1和0.5.上述实验参数均采用验证集测试获得.
在训练数据输出中,分别引入0%、10%和20%比例的异常值时,上述5 种建模方法构建的炉温预测模型的RMSE 和MAE 分布如图7 所示.由图7可以看出,采用异构特征集成框架的炉温预测模型(Mt-RSCNE 和SCNE)的测试误差明显低于其他方法,这说明异构特征集成可以缓解高维特征变量对模型准确性和泛化能力的影响.当训练集引入10%和20%的异常值时,本文提出的Mt-RSCNE 的测试误差变化幅度较小,说明本文设计的鲁棒加权NCL策略可以提升炉温预测模型对异常数据的鲁棒性.表1 和表2 为上述对比结果的具体数值.

表1 在不同异常值比例下,各集成炉温预测模型的测试RMSE (均值 ± 标准差) (℃)Table 1 Test RMSE of each ensemble furnace temperature prediction model under different percentages of abnormal value (mean ± standard deviation) (℃)

表2 在不同异常值比例下,各集成炉温预测模型的测试MAE (均值 ± 标准差) (℃)Table 2 Test MAE of each ensemble furnace temperature prediction model under different percentages of abnormal value (mean ± standard deviation) (℃)
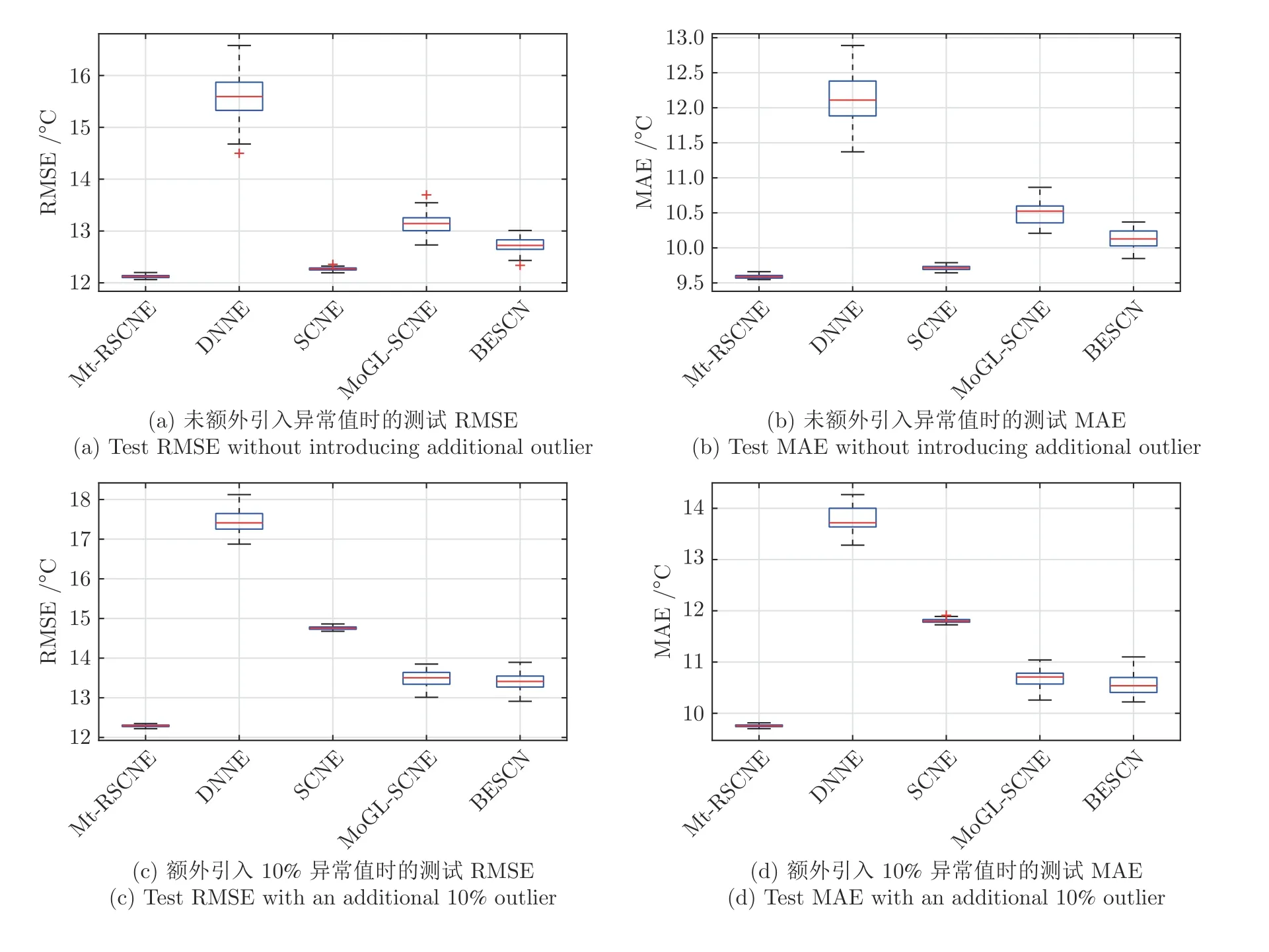
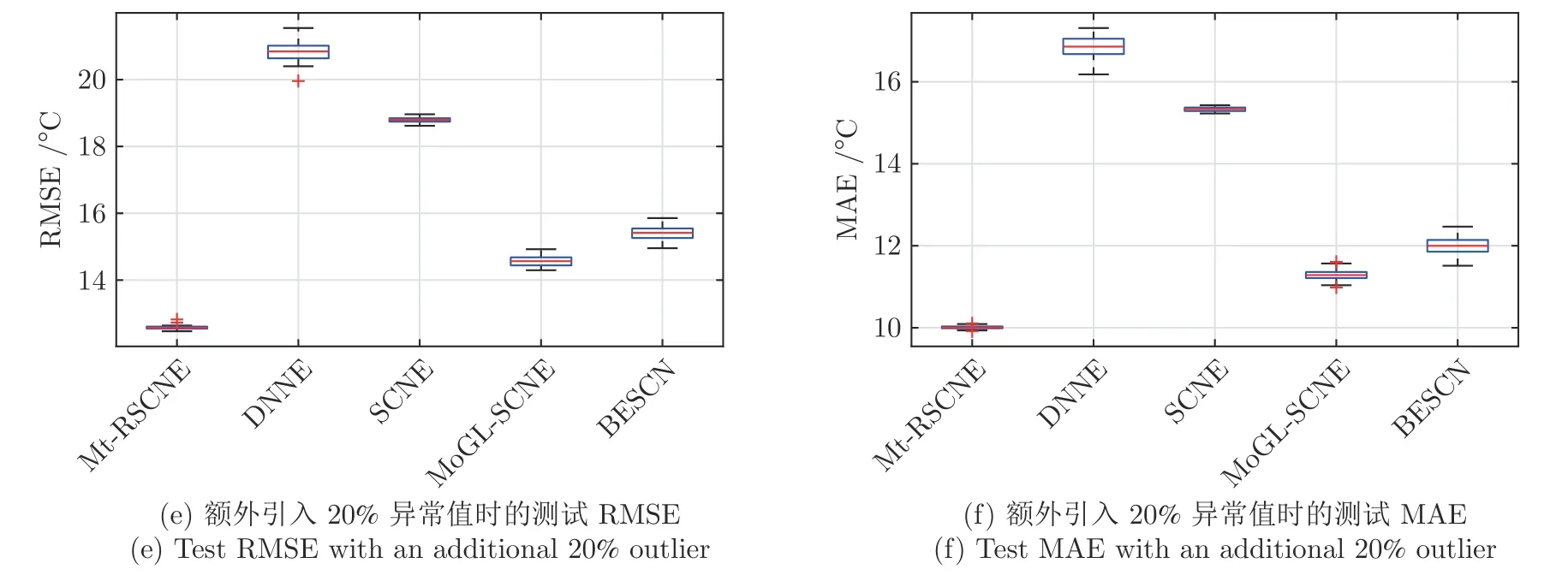
图7 在不同异常值比例下,各集成模型对炉温预测的性能对比Fig.7 Performance comparison of ensemble models for furnace temperature prediction under different percentages of abnormal value
为了更直观地表现本文Mt-RSCNE 方法对训练数据中异常值的鲁棒性,图8 绘制了上述5 种集成炉温预测模型在20%的异常值情况下的散点图.由图8 可以看出,Mt-RSCNE 方法对应点的位置更加靠近对角线,说明该方法得到炉温预测模型的结果更接近真实值.再次验证了本文方法在炉温预测准确性和泛化能力方面的优越性,同时也说明了本文方法在工业过程参数建模领域中,具有一定的应用价值.
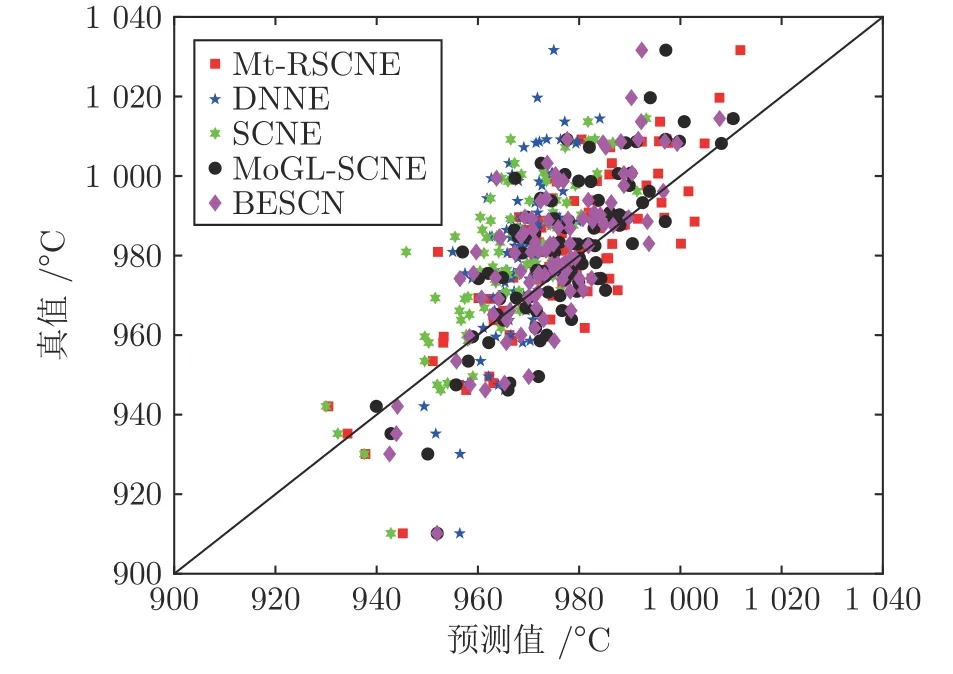
图8 在20%异常值情况下,各集成模型输出的散点图Fig.8 Scatter diagram of the output of each ensemble model under 20% abnormal value
4 结束语
为了提升MSW 焚烧过程炉温预测模型的准确性和泛化能力,本文提出一种鲁棒加权异构特征集成建模方法,并采用焚烧过程历史运行数据验证了该方法的有效性.本文的主要贡献如下:
1)针对焚烧过程数据具有高维特征变量的特点,依据MSW 焚烧过程的机理和炉排结构,将高维特征划分为异构特征集合,并采用互信息与相关系数,综合确定每组异构特征对炉温的贡献度;
2)针对焚烧过程数据具有异常值的特点,采用基于混合t分布的鲁棒SCN 构建基模型,并综合基模型的训练过程确定样本惩罚权重,从而保证了基模型对数据中异常值的鲁棒性;
3)设计一种鲁棒加权NCL 策略,实现了基模型之间的鲁棒同步训练,从而提升了炉温预测模型的准确性和泛化能力.
实验结果表明,与典型集成建模方法相比,本文构建的MSW 焚烧过程炉温预测模型在准确性和泛化能力方面具有优势,说明该方法在工业过程参数建模领域具有应用价值.值得注意的是,该方法的训练模式为离线批量训练,这导致模型的训练效率会随训练样本数量的增加而降低.因此,针对提升模型训练效率或模型在线自适应学习能力的研究,是未来研究的主要方向.
附录A

表A1 炉温预测模型过程变量明细Table A1 Process variable details of furnace temperature prediction model
猜你喜欢
小学教学研究(2022年5期)2022-04-28
自动化学报(2019年6期)2019-07-23
山东冶金(2019年2期)2019-05-11
材料与冶金学报(2019年1期)2019-03-08
中国铸造装备与技术(2017年6期)2018-01-22
电子制作(2017年13期)2017-12-15
自动化学报(2017年4期)2017-06-15
中国洗涤用品工业(2017年2期)2017-04-16
电信科学(2016年11期)2016-11-23
通信电源技术(2016年6期)2016-04-20
