
无人机辅助物联网中基于Safe Actor-Critic的信息年龄最小化研究
2024-02-02 14:54:26魏宪鹏张志才
测试技术学报 2024年1期
魏宪鹏,付 芳,张志才
(山西大学 物理电子工程学院,山西 太原 030006)
0 引言
由于无人机的灵活性、机动性和低成本,其在物联网(Internet of Things,IoT)网络中实时应用发挥着关键作用,如智能交通[1]、灾难救援[2]、野火预防[3]等。在这些应用程序中,要求将IoT设备生成的实时数据尽可能新鲜地传递给接收器。例如,智能交通中复杂的数据和过时数据可能会导致错误的操作,甚至造成灾难性的后果[4]。因此,保证接受数据的及时性对无人机辅助物联网网络至关重要。信息年龄(Age of Information,AoI)是一种有效的性能指标,其定义为自生成接收器的最新更新以来经过的时间量[5],其中最新收到的数据包的年龄值较小,因此,可以通过最小化AoI来保证接收数据的时效性。
基于深度强化学习(Deep Reinforcement Learning,DRL)的无人机轨迹设计被认为是处理无人机路径规划问题的有效方法[6-9],其中无人机被视为“智能体”,通过与环境直接交互获得最优轨迹。例如,Fu F 等[8]提出了一种基于好奇心驱动的DQN 路径规划方法;Wang L 等[9]提出了一种基于深度确定性策略梯度算法的无人机路径设计方法,以降低分布式边缘计算系统中用户的能量开销。然而,这些优化问题大都受短期限制条件约束。众所周知,无人机的飞行能量预算对无人机的路径规划有很大影响,然而,他们忽略了飞行的能耗成本。考虑到无人机承载能量的局限性,Hu X等[10]提出了一种最小化无人机能耗的无人机轨迹规划方案;Liao Y 等[11]提出了一种多目标优化方案,以最小化AoI 和无人机的能耗成本;Sun M 等[12]通过优化无人机的飞行路径和频谱分配,在AoI 和飞行能量成本之间找到平衡。上述工作可以有效降低能耗,但不能保证无人机累积飞行能耗不超过总能耗预算。此外,在这些方案中,无人机的可用能量通常没有得到充分利用,难以获得最优的无人机路径规划方案,从而导致高AoI。因此,如何充分利用无人机的能量做出更合理的决策是一个值得研究的问题。
本文研究无人机的路径规划和用户关联问题,以在满足长期飞行能量约束的同时最小化AoI加权和。
1 系统模型与假设
1.1 系统模型
无人机辅助物联网场景如图1 所示。IoT 设备随机部署在室外区域,在该区域中,无人机从起点到目的地巡航,旨在收集IoT 设备的状态信息尽可能新鲜。本文考虑的模型中,无人机在采集IoT 设备信息时会处于悬停状态,因此不会产生多普勒频移现象[13]。令K={1,2,…,K}表示所有物联网设备的集合,设备k的位置由qk=(xk,yk,0),∀k∈K表示。UAV 的巡航时间分为T个时隙,每个时隙的长度为τs。假设UAV 在固定的高度H上运动,相应地,设q[t]=(x[t],y[t],H),∀t∈T表示UAV 在第t个时隙的位置,q[0]=(xori,yori,H)表示UAV 的初始位置,q[T]=(xdest,ydest,H)表示UAV的目的地。
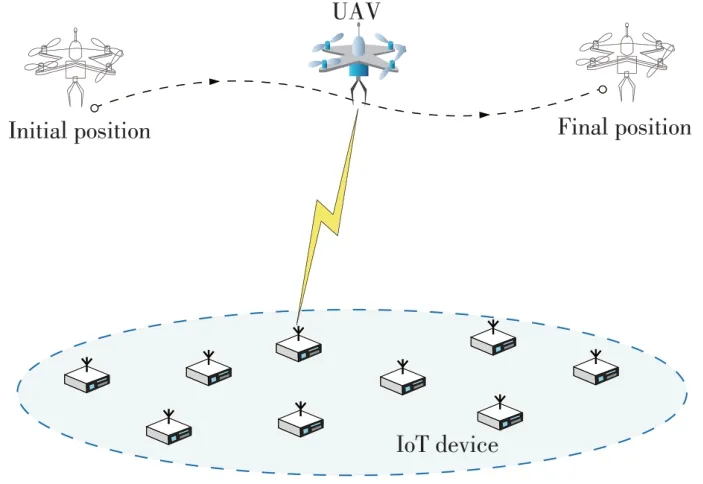
图1 系统场景Fig.1 System scenario
1.2 飞行能量消耗模型
无人机的能源推进成本通过式(2)计算
式中:P0为悬停状态恒功率;P1为诱导功率;Utip为叶片的叶尖速度;v0为悬停状态的转子平均诱导速度;z0和ρ分别为机身阻力比和空气密度;μ和ξ分别为转子坚固度和转子盘面积。为了UAV 保留足够的能量以执行其他功能,UAV 的机动性必须满足以下能量约束
式中:Efly[T]为整个巡航期间累计推进能耗;Emax为UAV最大允许推进能耗[14]。
1.3 无线传输与AoI模型
令Gk2U表示从装置k到位置为q[t]的UAV 的平均信道增益,其在LoS 和非LoS(NLoS)链路[15]下求平均,计算公式为
式中:fc为载波频率;ρ为光速;Λ为选择概率;dk2U(q[t])为从设备k到UAV的距离
设备k与UAV之间可实现的数据速率
式中:PA[t]为k2U的发射功率;σ2为设备k处的高斯白噪声功率。
1.4 问题建模
通过联合优化UAV 的轨迹q[t]以及调度策略z[t]=在满足能量约束的前提下,使整个飞行周期内的长期AoI加权和最小。问题表述为
式中:ωk为在式(6)中的权重,表示设备信息的相对重要性。UAV 的初始和最终位置在式(7)中给出。式(8)为无人机的速度约束,其中Vmax为UAV 的最大速度。式(9)和式(10)保证UAV在每个时间段内最多调度一个IoT 设备。式(11)表示Efly[T]整个巡航期间的累计推进能量消耗不能大于Emax。接下来,我们将式(6)建模为一个CMDP,然后采用一种新的DRL 算法,即Safe-Actor-Critic[16]来解决此CMDP问题。
2 约束性马尔可夫决策过程
本节将上述优化问题(6)建模为CMDP。将CMDP一个元组表示为每个元素具体描述如下:
S=S′∪Sdest为环境状态特征空间,其中S′为瞬态空间,Sdest为最终状态空间。S′包括3个部分:无人机在t时隙的坐标q[t]=(x[t],y[t],H);物联网设备的位置qk=(xk,yk,0);物联网设备的AoI值∀k∈K,t∈T。Sdest最终状态空间为q[T]=(xdest,ydest,H)。
A为动作空间,包括无人机的速度vt和方向,以及无人机的调度策略z[t]。
P为状态转移概率函数。无人机的坐标根据p[t]=vt*τ+p[t-1]进行转移,vt≤Vmax,vt为无人机在t时刻的飞行速度。
s0∈S为初始状态,其中包括q[0]=(x0,y0,H)及∀k∈K。
r为奖励函数,定义为
式中:Ω为一个正常数,用于将无人机诱导到最终位置[17-18]。
c为立即约束代价,定义为c(s,a)=Pfly[t]τ,c0为约束代价上限,根据式(11)有c0=Emax。
式中:T*为从起始状态s0到目的地首次成功的时间。安全约束为
解决CMDP 问题的方法是找到最优策略π*,使长期收益最大化,且满足安全约束。CMDP 的优化问题被公式化为
如何将长期约束Cπ(s0)转化为可行的单步策略集是求解CMDP的关键。
3 Safe Actor-Critic
3.1 安全策略集
本节利用Lyapunov函数理论来构建安全策略集。首先,假设可以获得式(15)的可行策略,用πb(·|s)∈Π 表示。给定初始状态s0和约束阈值c0,Lyapunov函数定义集为
式中:Bπb,c[ℓ](s)为贝尔曼函数计算,即
对于∀ℓ(s)∈Γπb(s0,c0),Lyapunov 函数诱导的安全策略集为
式中:ℓ(s0)≤c0,∀π(·|s)∈Fℓ(s)为式(15)的可行性策略。从式(17)中可以看出,较大的ℓ 意味着可以获得较大的Fℓ(s),因此,下面的关键工作是构造一个合适的Lyapunov函数ℓ。
根据文献[16]中的引理1,关于π*的长期约束Cπ*(s)可以转化为πb诱导的Lyapunov函数,写为
式中:Δ(st)为每一步中可用的附加约束成本,用于扩展可行的操作空间并改进策略。然而,在没有π*的先验知识的情况下构建Δ(st)是具有挑战性的。为了降低计算复杂度[19],Δ(st)近似为
式中:c0-Cπb(s0)为从s0到最终状态可用的总辅助约束成本;Ε[T*|s0,πb]为UAV 从开始位置到目的地的预期首次成功时间。通过这种方式,可以在规划轨迹的同时充分利用UAV 的推进能量预算。根据式(18)可以得到ℓΔ(s) 是可以由计 算,其 中QℓΔ(s,a)=QC(s,a) +Δ(s)QT(s,a) 为ℓΔ的状态-动作值,QC(s,a)为约束值,QT(s,a)为从s到最终状态的残差步长,Δ(s)QT(s,a)表示约束成本的其余部分。为保证策略π(a|s)安全,必须满足[π(a|s)-πb(a|s)]TQℓΔ(a|s)≤Δ(s),这意味着由π(a|s) 引起的额外成本[π(a|s)-πb(a|s)]TQℓΔ(a|s)不能超过Δ(s)。然后,由ℓΔ(s)诱导的安全策略集(17)可以写为
3.2 critic部分
以下采用actor-critic 框架来解决问题(15)。在critic 部分,使用DNN 分别评估Q(s,a),QC(s,a)和QT(s,a)。
在每步中,新生成的数据被保存在经验池中,即D←(s,a,r,c,s′)∪D,通过从经验池中随机采样一批样本(s,a,r,c,s′)来训练DNN,并通过式(21)更新参数
同样QC(s,a)和QT(s,a)也分别通过DNN 近似器Q(s,a;ϑC)和Q(s,a;ϑT)进行评估。参数ϑC和ϑT通过以下方式更新
3.3 actor部分
基于上节获得的QC(s,a)和QT(s,a)以及在式(20)中构建的安全策略集,可以计算出式(15)的最优行动概率为
3.4 Safe Actor-Critic算法
Safe Actor-Critic算法的框架如图2 所示。

图2 Safe Actor-Critic框架Fig.2 The framework of Safe Actor-Critic
算法收敛性可以在文献[16]中找到。该算法包括了三部分:actor 部分,critic 部分以及经验池,其学习率αc,t和αa,t满足
4 仿真结果与讨论
模拟基于Python的模拟器上实现,其中环境的参数设置如下:在600 m×600 m的面积上随即部署K个物联网设备,无人机在该区域上空巡航,接收设备产生的数据,其悬停高度固定为H=100 m。传输速率的参数设置为fc=5.9 GHz,B=1 MHz[20],pk2U=0.1 W(∀k∈K)[20],σ2=-110 dBm,信道参数的值为δ=9.61,β=0.16,ηLoS=1 dB,ηNLoS=20 dB[15]。无人机的能源推进成本参数设置为:P0=3.4 W,P1=118 W,Utip=60 m/s,Vmax=30 m/s,v0=5.4 m/s,ρ=1.225 km/m2,μ=0.03,z0=0.3,ξ=0.28 m2[21]。
图3 为所提算法不同Actor 学习率之间的收敛性能,其满足等式(26)且通过反复试验来设置。在这一部分中,Critic 的学习率被设定为αc,t=5×10-4。算法总共运行500 回合,每个回合中包括100步。
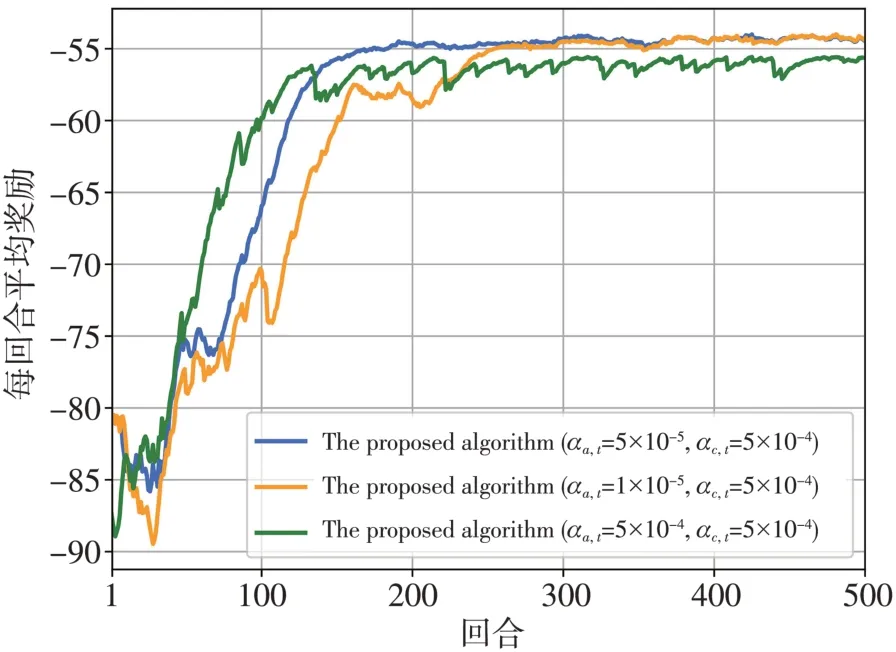
图3 不同Actor学习率奖励表现Fig.3 The reward performance comparison with different actor’s learning rates
由图3 可知,当学习率为αa,t=5×10-4,曲线大约150 回合处达到收敛,这是因为学习率过高,总会导致高方差和低奖励。然而,当学习率下降为αa,t=1×10-5时,学习速率变慢。相比αa,t=1×10-5和αa,t=5×10-4,学习率为αa,t=5×10-5是最佳的学习率,该学习率在平均收益和方差方面具有良好的性能。
图4 为不同Critic学习率之间的收敛性能,这里Actor的学习率被固定为αa,t=5×10-5。同样发现算法的收敛性能对学习率非常敏感,学习率为αc,t=5×10-3导致显著方差,而αc,t=3×10-4导致较长的学习时间,Critic 的最佳学习率为αc,t=5×10-4。因此,在下面的部分中,αa,t和αc,t分别被设为αa,t=5×10-5和αc,t=5×10-4。
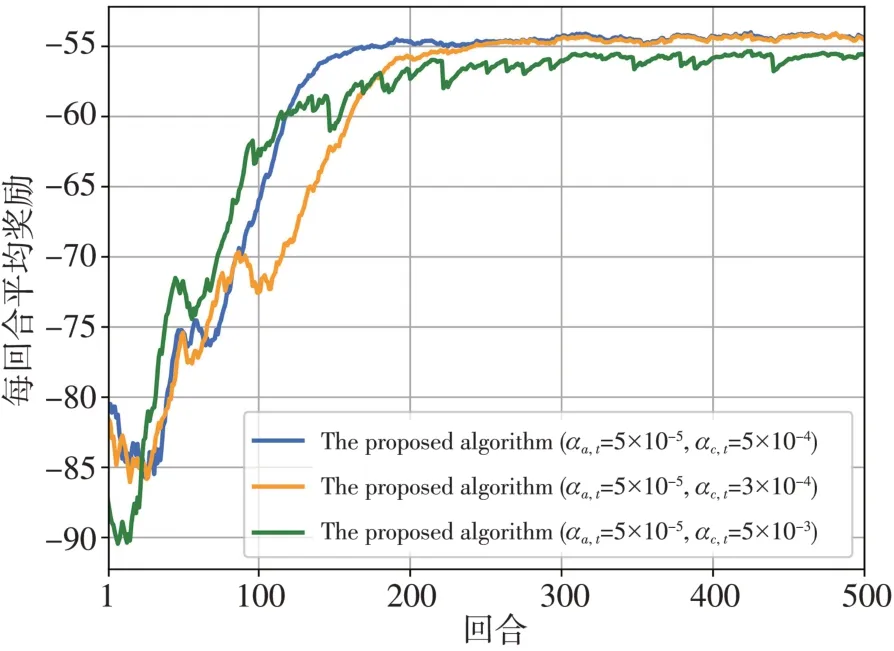
图4 不同Critic学习率奖励表现Fig.4 The reward performance comparison with different critic’s learning rates
为了显示所提出的基于Safe Actor-Critic(SAC)算法的高效率,还模拟了基于Safe DQN的算法(SDA)[7]和基于拉格朗日Actor-Critic 的算法(LAC)[21]。图5 为无人机在不同的总能量预算下每次SAC、SDA 和LAC 的累积推进能量消耗。从图5 可以看出,当Emax=1.1×104J 时,SAC的总推进能量成本在收敛后小于1.1×104J,SDA 的能耗成本同样小于1.1×104J。当Emax=2.6×104J 时,SAC 的能耗约2.5×104J。这是因为SAC 基于能量预算Emax为无人机构建了一个安全策略集,因此,总推进能量成本不会超过预算Emax。当Emax=1.1×104J 时,LAC 的能量消耗约为1.5×104J。这是因为LAC 的策略不可能受到长期能源约束的严重限制,即UAV 的每回合的总推进能量成本可能超过总能量预算。
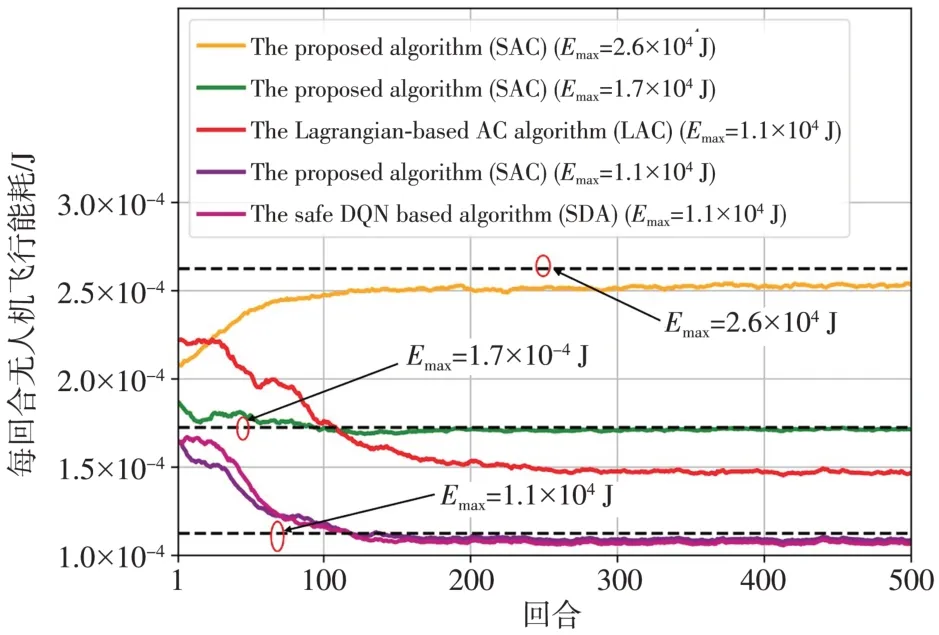
图5 不同总能量预算下无人机飞行的累积推进能耗Fig.5 The UAV’s cumulative propulsion energy consumption per episode with different total energy budgets
图6 为每回合SAC、LAC 和SDA 在不同总能量预算下的奖励表现。
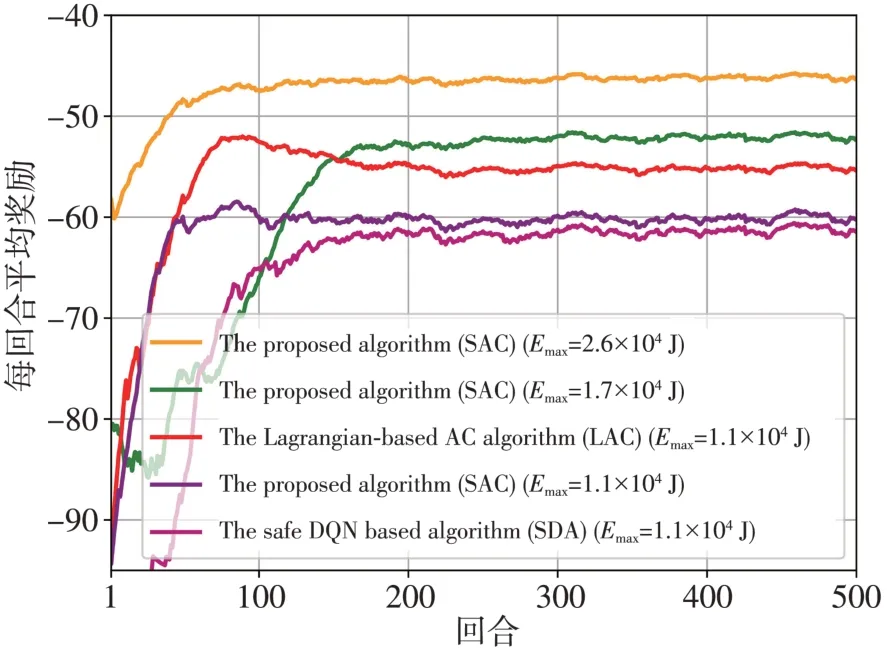
图6 不同能量预算下每回合奖励表现Fig.6 The reward performance per episode with different total energy budgets
从图6 中可以看到,当Emax从1.1×104J 增加到Emax=2.6×104J 时,SAC 的奖励明显增加,这是因为Emax越大,则无人机的可行动空间越大,获得最优策略的机会越多[22],获得的奖励也越高。当Emax=1.1×104J 时,LAC 的奖励比SAC 高,这是因为LAC 的策略并不严重受限于图5 所示的能量预算。尽管在图5 中,SDA 同样受到能量约束,但是从图6 中可以看出当Emax=1.1×104J时,SDA 的奖励低于SAC,因此,根据图5 和图6 可知,与SDA 和LAC 相比,提出的SAC 可严格满足推进能量消耗预算要求,并且收敛性能最佳。
图7 所示为每个回合中不同的总能量预算下不同物联网设备数目的AoI值,可见随着物联网设备数目的增加,AoI加权和显著增加。这是因为无人机在每个时隙最多连接一台设备,部署的设备越多,平均每台设备享受的服务越少,AoI之和也随之增加。此外,当能量预算增加时,固定数量物联网设备的AoI会减少,这是因为有了更多的推进能量预算,无人机可以进行更灵活的轨迹规划,以接收更高AoI值的设备。

图7 不同IoT个数的AoI加权和Fig.7 The weighted sum AoI of different devices
图8 显示了每一阶段的平均加权和AoI 与UAV飞行高度的关系,可见当无人机的高度增加时,AoI 值增加。由于物联网设备到无人机的信道增益主要取决于两者之间的距离,因此在带宽和发射功率一定的情况下,飞行高度越高,信道条件越弱,传输速率越低。
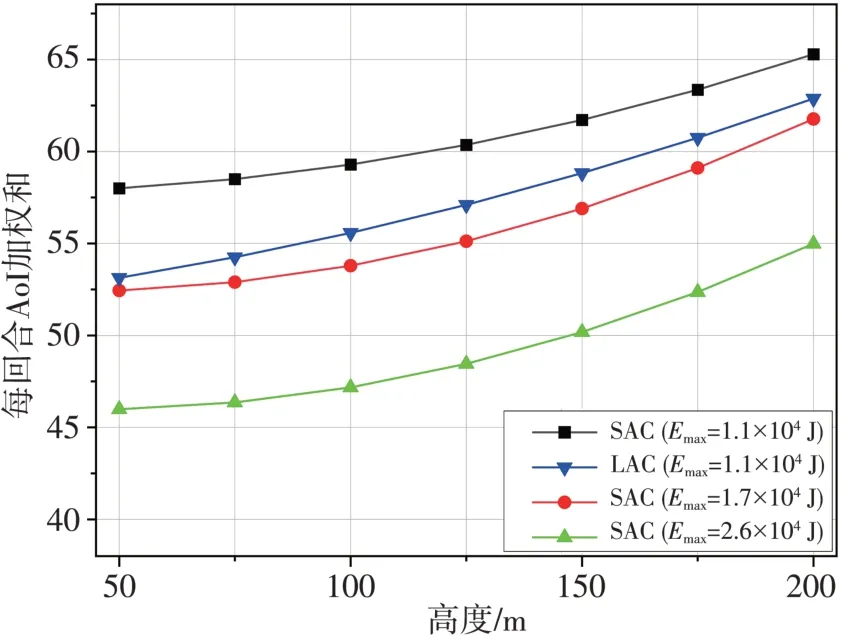
图8 不同高度下的建立表现Fig.8 The reward performance versus height
5 结论和展望
本研究的贡献总结如下:
1)联合优化无人机的轨迹和物联网设备调度策略以最小化网络的加权和AoI,其中无人机累积飞行能量成本受能量预算限制。
2)由于优化目标受一组短期约束和长期能量约束的限制,该问题被建模为约束马尔可夫决策过程(CMDP)。
3)采用Safe Actor-Critic 来求解该CMDP,为保证策略安全,利用Lyapunov函数构建安全策略集,并基于此策略集训练策略网络。
在未来的工作中,我们将利用多智能体DRL方法讨论多无人机场景下的AoI最小化问题。
猜你喜欢
机械工业标准化与质量(2023年6期)2023-09-26 06:43:28
昆钢科技(2022年2期)2022-07-08 06:36:14
当代水产(2021年10期)2022-01-12 06:20:28
加油站服务指南(2021年4期)2021-07-21 02:29:22
建材发展导向(2021年23期)2021-03-08 01:05:38
湖北农机化(2020年4期)2020-07-24 09:07:36
数学年刊A辑(中文版)(2020年1期)2020-05-19 00:30:30
华人时刊(2018年15期)2018-11-10 03:25:26
网络空间安全(2017年10期)2017-12-21 21:19:09
人生十六七(2015年6期)2015-02-28 13:08:38
