
基于改进YOLOv5s-pose的多人人体姿态估计
2024-01-29 00:31:13蒋锦华庄丽萍陈锦姚洪泽蔡志明
软件工程 2024年1期
蒋锦华 庄丽萍 陈锦 姚洪泽 蔡志明


关键词:多人人体姿态检测;YOLOv5s;雙向特征金字塔网络;检测精度
0 引言(Introduction)
深度学习技术在图像分割、目标检测等方向取得的一系列突破,促进了多人人体姿态目标检测算法的进步。
目前,基于深度学习的多人人体姿态检测方法分为双阶段目标检测算法和单阶段检测算法,其中针对双阶段目标检测,如PAPANDREOU 等[1]在第一阶段采用FasterR-CNN 检测人体;在第二阶段采用ResNet预测每个关键点的热力图和偏移量,通过融合得到关键点的精确位置。CAO等[2]建立了一个OpenPose检测器,加快了人体关键点的检测速度。CHENG等[3]提出一种尺度感知的高分辨率网络(HigherHRNet),通过生成高分辨率热图来更精确地定位人体关键点。在单阶段检测算法中,NIE等[4]首次提出了单阶段的多人姿态估计网络,可以直接预测每个人的位置和关键点。MCNALLY等[5]提出一个密集基于锚的单阶段检测框架,同时检测关键点对象和姿态对象,能够更加快速地得出检测结果。
单阶段检测与双阶段检测相比,检测速度更快,但准确率相对较低。本研究在单阶段检测的基础上,进一步提高人体姿态的检测准确率。在单阶段检测算法中YOLO 系列的YOLOv5s网络具有计算高效、实时性强等特点,更适合在实际场景中检测多人人体姿态。因此,本文选择YOLOv5s网络作为基准模型。
1 YOLOv5s目标检测模型(YOLOv5s object detectionmodel)
1.1 YOLOv5s网络结构
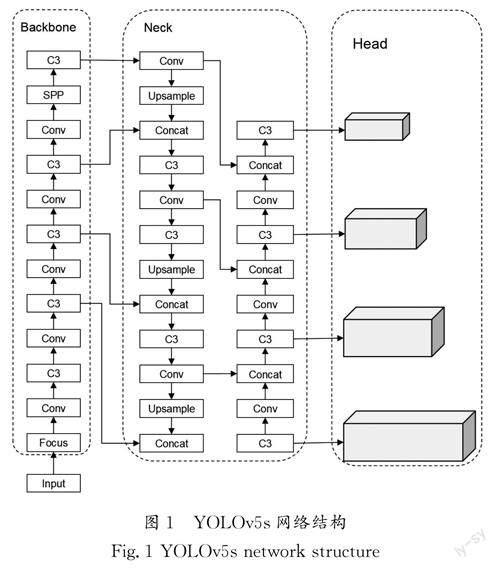
YOLOv5s的结构由四个部分组成:输入端、Backbone(骨干网络)、Neck(特征金字塔)和Head(目标检测)。输入端调节输入图片的尺寸大小,Backbone部分进行特征提取,Neck部分通过将特征与位置信息融合使模型获得更丰富的特征信息,Head部分进行最终的预测输出。
Backbone部分使用Darknet53作为特征提取网络,主要由Focus网络和CSPNet结构组成。Focus结构对特征图进行切片操作,使特征图的长和宽都缩小了1/2,减少了算法的计算量,加快了计算速度[6]。CSPNet结构用于提取输入图像特征信息,将梯度变化完全集成到特征图中,在减少模型参数量的同时,兼顾了推理速度和准确率,能够更好地解决其他大型卷积神经网络中的梯度信息冗余问题[7]。
Neck部分使用特征金字塔+路径聚合(FPN+PAN)结合的PANet结构,特征金字塔的结构为自上而下,该结构使顶层特征图享受来自底层的特征信息,从而提升对较大目标的检测效果[8]。
Head的主体是4个Detect检测器,基于网格的锚框在不同尺度的特征图,检测器分别用来检测大、中、小目标。YOLOv5s网络结构如图1所示。
1.2 人体关键点检测过程
检测基于YOLOv5s目标检测框架进行多人人体姿态估计,该模型能够在一次前向传递中联合检测多个人体边界框及其相应的2D姿态。对于输入的图像,将一个人的所有关键点与它对应的目标框联系起来,存储其整个2D姿态和边界框。使用CSP-darknet53作为主干网络,对人体关键点进行特征提取,生成不同尺度的特征图。使用PANet融合主干网络输出的不同尺度特征,生成四个不同尺度的检测头。每个检测头分别用于预测框和关键点。
2 改进后的结构与分析(Improved structure andanalysis)
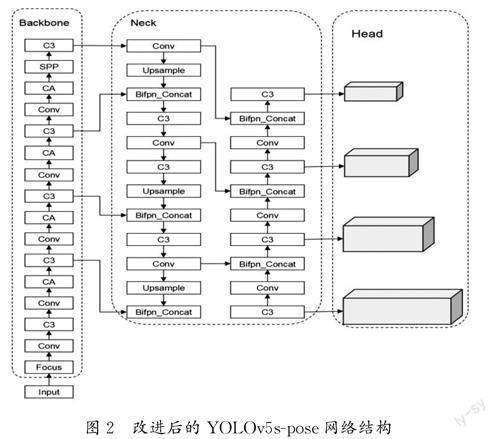
为了提高YOLOv5s在多人人体姿态中的检测精度,本研究对模型做出以下改进:(1)对主干网络进行改进,在主干网络卷积层后的每一层中都加入CA注意力模块,再输出给C3模块,通过将位置坐标信息嵌入信道注意力中,使移动网络能够大范围关注检测目标,同时避免产生大量的计算,提高了对人体目标的定位精度,使其能够抑制其他无用特征,进而更多地关注人体关键点这一特征信息。(2)对Neck部分进行改进,在Neck部分的特征连接层模块中加入一个可学习的权重参数,形成一种简单且高效的加权双向特征金字塔网络(BiFPN),将YOLOv5s原始的Concat替换成新构建的Bifpn_Concat,提升网络对不同尺度目标的特征融合能力。改进后的YOLOv5spose网络结构如图2所示。
2.1 加入CANet模块
由于待检测数据集为多人人体目标,存在人体目标被遮挡、实际场景中大小不一且分布疏密不均等问题,为了进一步增强网络对待检测目标的特征提取能力且不影响检测的实时性,又引入了一种更加高效且轻量级的注意力模块,称之为“坐标注意力机制”,即CANet[9]。
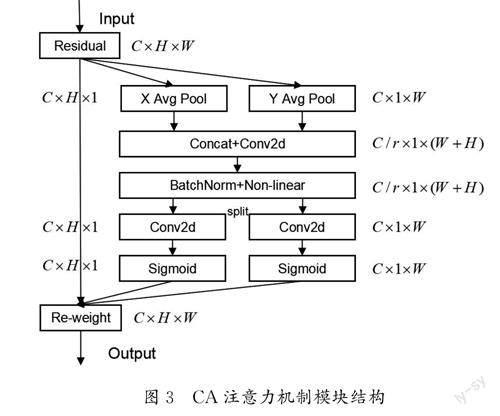
CANet是对输入特征图进行水平方向和垂直方向上的平均池化,其本质是空间注意力,在通道注意力当中嵌入位置信息后,赋予空间中不同位置处不同的权重系数。从空间上来看,类似于从两个方向对网络进行建模,对不同的特征进行一个融合再提取的过程。CA的整体结构如图3所示。
由图3可知,将输入特征图分别按X 轴和Y 轴方向进行池化,对每个通道进行编码,产生C×H ×1和C×1×W 形状的特征图。将所提取到的特征图按空间维度进行拼接,再通过卷积和Sigmoid激活函数得到坐标注意力。通过这种方式所产生的一对感知特征图可以使CA注意力能够在一个通道内捕获长距离的依赖关系,并且有助于保留精确的位置信息,使网络能够更加准确地定位对象。
2.2BiFPN———加权双向特征金字塔多尺度特征融合
BiFPN是在PANet的基础上改进而来的。双向特征金字塔结构(BiFPN)运用双向融合思想,重新构造了自顶向下和自底向上的路线,对不同尺度的特征信息进行融合,通过上采样和下采样统一特征分辨率尺度,并且在同一尺度的特征图之间建立双向连接,在一定程度上解决了特征信息遗失的问题[10]。
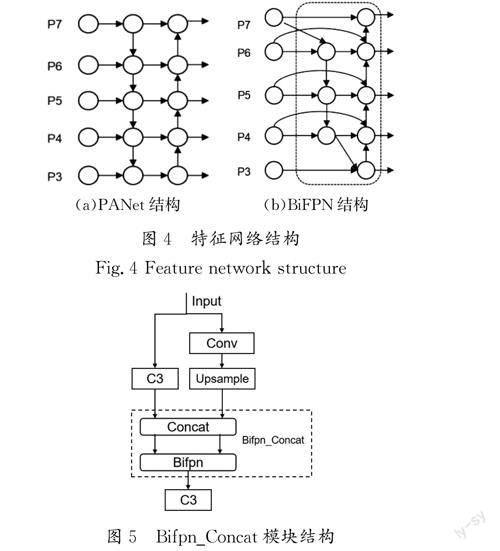
原始的YOLOv5s网络中,PANet作为YOLOv5s的特征融合网络,其结构如图4(a)所示,虽然可以实现浅层信息的传递和高层特征图强语义信息的融合,但是浅层和高层两部分融合采用的相加运算并没有相关的权重设计,而且只有一边输入没有特征融合的节点,冗余节点对特征融合的作用甚微,增加了额外的参数和计算量。基于以上问题,本文基于BiFPN结构修改YOLOv5s网络的Neck部分,将Neck部分中PANet的节点连接方式做出部分改变,减少了对网络特征融合贡献度较小的不必要连接,增加了输入节点和输出节点处于同一层时二者的连接,BiFPN 结构节点连接方式如图4(b)所示。在YOLOv5s网络的特征融合部分中,将负责特征信息融合的张量拼接操作结合加权双向特征金子塔(BiFPN),结合后的张量拼接操作记作Bifpn_Concat,其结构如图5所示。
BiFPN使用加权特征融合的方式为每个特征添加一个额外的权重。使网络可以不断调整权重,确定每个输入特征对输出特征的重要性;快速归一方法如公式(1)所示,用来约束每个权重的大小,使权重大小保持在0~1,提高模型在GPU上的運算速度。
3 实验结果与分析(Experimental results andanalysis)
3.1 实验环境与数据集
训练使用AutoDL云端服务器,在云端服务器上的实验环境配置如下:操作系统为Ubuntu 18.04、PyTorch 1.9.0框架、CUDA11.1、Python3.8,使用RTX3090显卡一块,batch-size设置为64,epoch 为300。训练和测试时将数据集中的图像尺寸固定为640×640,学习率为0.01。
本次训练的数据集为公共数据集MS COCO2017,MSCOCO关键点检测数据集是目前主流的二维人体姿态估计数据集之一,它包含20万张以上的图像和25万个带有关键点注释的人体实例,每个实例最多包含17个人体关键点,并对这些关键点进行了标注。在Train2017(约57 000张图像,包含150 000个人体实例)数据集上进行网络模型的训练,在Val2017数据集上进行网络模型的验证和测试。
3.2 评价指标
对于COCO数据集,采用官方指定关节点相似度OKS(Object Keypoint Similarity)为模型性能评价的度量方法。OKS 定义了不同人体关键点之间的相似性,值为0~1,越接近1,说明预测得到的人体关节点与数据集标注的真实值越相似,预测效果越好,OKS 的公式如下:
其中:i 表示关节点的类型,di 表示检测出来的关键点与其相应的标签值之间的欧氏距离,s 表示目标比例,vi 表示真实值的可见性标志,δ 函数表示当关键点被标注时才纳入计算,ki表示控制衰减的每个关键点的常数。
本文选用AP、AP75、APM、APL、AR 为评价指标,AP 为OKS=0.50,0.55,…,0.95时,每种检测类型的准确率,用于预测关键点的平均精度值。AP75 为在OKS=0.75时关键点的准确率。APM 为中等目标检测的AP 值,APL 为大目标检测的AP 值,AR 表示OKS=0.50,0.55,…,0.95这10个阈值上的平均查全率。准确率P、查全率R 的具体计算如公式(3)和公式(4)所示。平均精度值AP 的计算如公式(5)所示:
其中:TP 为正样本被正确识别为正样本的数量,FP 为负样本被错误识别为正样本的数量,FN 为正样本被错误识别为负样本的数量,N 为目标的类别数。AP 的意义是P-R 曲线所包围的面积。
3.3 结果与分析
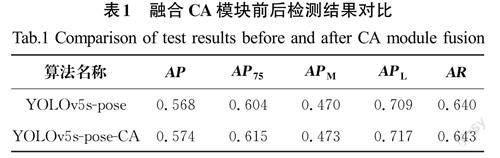
本实验比较了原始的YOLOv5s 网络和改进后的YOLOv5s-CA在人体姿态检测中的各项精度指标,融合CA模块前后检测结果对比见表1。从表1中可以看出,在多人人体姿态检测中,改进后的YOLOv5s-CA 算法相比于原始的YOLOv5s网络,AP 指标提升了0.6%,AP75 指标提升了1.1%,中等人体目标的准确率APM 提升了0.3%,大目标的准确率提升了0.8%。由此说明:在YOLOv5s的主干特征提取网络中加入CA坐标注意力机制模块能提升人体姿态关键点的检测精度。
在上述改进的基础上,本研究引入双向特征金字塔网络(BiFPN),进一步改进YOLOv5s网络的颈部(Neck)结构,将改进后的检测效果与原始的YOLOv5s进行对比,结果如表2所示。从表2中的数据可以发现,平均精度AP 提升了0.5%,AP75 指标提升了1.5%,中等人体目标的准确率APM 提升了0.8%;在改进CA注意力机制的基础上,AP75 指标的检测精度又提升了0.4%。实验证明,在YOLOv5s的网络模型中融入BiFPN模块以改进原来的PANet,可以进一步提升人体目标和人体关键点的检测精度。
图6与图7分别为YOLOv5s-pose算法改进前和改进后的检测效果对照,对比图6(a)与图7(a)的检测效果可以看出,改进后的算法应用于多人人体姿态关键点检测,检测结果更准确。如图6(a)所示,原始的YOLOv5s-pose网络存在关键点对应人体姿态错乱现象,如图7(a)所示,改进后的YOLOv5spose网络在关键点及对应人体姿态目标上的检测精度有所提升。从图6(b)中的检测效果可以看出,当人体目标被遮挡,只有部分人体部位显示时,改进前的YOLOv5s-pose网络存在人体目标漏检的情况,对于小目标人体,关键点及人体姿态检测精度较低,检测效果较差。对比图6(b)与图7(b)的检测效果可以看出,改进后的YOLOv5s-pose网络能够较好地检测出被遮挡部分的人体目标及其对应的人体姿态。此外,对于检测小目标的人体姿态,改进后的网络的检测效果更佳。
4 结论(Conclusion)
本文提出了一种基于YOLOv5s网络改进的多人人体姿态检测算法,为了提升模型在COCO人体姿态数据集中的检测精度,对模型进行了改进。首先在主干网络中通过融入CA坐标注意力机制模块提升主干网络部分对人体关键点的特征提取能力,其次基于BiFPN结构在Neck部分对原始网络进行优化改进,增强了不同目标尺度的融合度,进一步提升了模型对多人人体姿态目标的检测能力。实验结果表明,本文提出的方法在人体姿态COCO数据集中的检测能力更强,在面对部分人体被遮挡时,算法的鲁棒性更好,检测精度更高。
