
基于分层的体域网异常数据检测方法
2024-01-22 07:19:10廖栋森祝长鸿余琪琦任君玉黄福莹覃团发
计算机工程与设计 2024年1期
廖栋森,祝长鸿,余琪琦,任君玉,黄福莹,覃团发+
(1.广西大学 计算机与电子信息学院,广西 南宁 530004;2.广西大学 多媒体通信与网络技术重点实验室,广西 南宁 530004)
0 引 言
无线体域网[1](wireless body area networks,WBAN)是由人体携带的传感器节点、汇聚节点和远程服务器组成的网络。WBAN根据节点观测的异常数据获知人体健康状态的变化和节点的工作状态。现有的WBAN异常数据检测方法可分为两类:①基于数据统计特性的异常数据检测方法。这类方法根据距离和信息熵来检测异常数据。②基于机器学习的异常数据检测方法。这类方法使用已有的数据训练模型,将数据分类而得到异常数据。然而这两类检测方法对数据点逐一分类,得到的异常数据是非连续数据点的集合,忽视了人体健康状态发生变化时,异常数据应呈连续分布,检测的结果应按时间段分布,而这两类方法只反映了人体在离散时间点的状态,缺乏对人体健康状态发生变化时间段的准确定位。由此本文将异常数据分为偶然性的异常数据点和连续性的异常数据集两部分,并提出了基于Hampel滤波器和DBSCAN分层的异常数据检测方法。该方法首先根据Hampel滤波器检测并替换偶然性的异常数据点,保证数据的连续性;其次,基于滑动时间窗,将时间窗中的数据全部视为异常数据或正常数据;然后根据DBSCAN本质为划分高密度区域的特征,将DBSCAN对数据聚类的结果转换为每一个时间窗中数据能否聚类的问题;最后依据人体生理参数的相关性标注出异常数据集。
1 相关工作
基于数据统计特性的异常数据检测方法使用数据的中心趋势统计量、散布程度统计量和分布统计量检测异常数据。Chang等[2]提出了基于时间窗的滑动平均模型,在时间窗截取数据的基础上,使用滑动平均模型预测下一数据点是否为异常数据点,其模型简单并提供了较好的检测精度;在文献[3,4]中,研究者提出了基于马氏距离和信息熵的异常数据检测方法,这些方法通过计算数据点之间的马氏距离和信息熵作为判定异常数据点的依据,计算复杂度低,但需要访问所有待检测的数据,不满足WBAN的实时性要求。
在基于机器学习的异常数据检测方面,文献[5-8]提出了基于监督学习的异常数据检测方法,采用的监督学习方法有One-Class SVM(support vector machine)、k-NN(k-nearest neighbors)、贝叶斯网络等,这些方法根据已有数据建立模型,利用数据的内在特征训练模型,提高了异常数据检测的精度,但存在使用的数据需预标签,WBAN异常数据占比较小,模型训练困难,且每个人健康状态不同,训练的模型不能泛化,以及One-Class SVM时间复杂度高,K-NN检测精度不足,贝叶斯网络适应度低等问题。文献[9-12]提出了基于无监督学习的异常数据检测方法,采用的无监督学习方法有主成分分析法、k-means、高斯混合模型、多层次聚类等,这些方法根据人体处于正常状态时数据相对集中而异常数据较少的分布特征进行聚类或降维,无需对数据进行预标签,提高了算法的泛化能力,但存在需采集较长时间段的数据进行学习,限制了WBAN系统的实时性,以及主成分分析法效率不高,k-means和高斯混合模型需根据不同个体获取先验知识等问题。
2 系统模型
2.1 网络模型
WBAN网络模型如图1所示。被监护人员携带n个传感器节点 {p1,p2,…,pi,…,pn},pi表示其中第i个传感器节点。传感器节点由于携带的能量、计算能力受限,对采集的数据进行一定处理后,将其传输至汇聚节点,汇聚节点一般具有较高的运算和存储能力,可以承担复杂的计算任务,数据在汇聚节点处理后通过互联网传输至医院并备份于数据中心。
2.2 检测模型
图2为本文提出的异常数据检测模型。由于偶然性的异常数据点来源于环境噪声和偶然的软件或硬件错误等因素,连续性的异常数据集产生于人体健康状态的变化和连续的软件或硬件错误等因素,因此模型根据异常数据的来源分为两个部分。①模型先通过Hampel滤波器检测并替换偶然性的异常数据点,保证数据的连续性;②模型将异常数据集检测分解为基于DBSCAN的异常数据集检测和异常数据集验证。基于DBSCAN的异常数据集检测找出异常数据集所在的位置,在验证异常数据集的来源后,若数据集证实为人体健康状态发生了变化,则向有关人员发出警报。最后更新数据库和时间节点。
3 异常数据点检测
异常数据点由于破坏了数据的连续性,对提取数据的特征具有较大的影响。基于数据序列时间相关性的Hampel滤波器是中值滤波器的改进,能够有效地分辨并替换异常数据点。Hampel滤波器使用被检测数据点对应时间窗数据序列的中值和中值绝对偏移量(median absolute deviation,MAD)作为判断被检测数据点是否为异常数据点的依据。当时间窗口大小为g时,第i个数据点ri对应的时间窗序列表示为Ri={ri-g,…,ri-1,ri,ri+1,…,ri+g} 根据Ri可得中值和MAD的计算公式
Mi=median(Ri)
(1)
Swi=1.4826×median{|Ri-Mi|}
(2)
其中,Mi表示ri对应Ri的中值,Swi表示ri对应Ri的MAD,常量1.4826表示该偏移量在数据序列呈正态分布时等于标准偏移量。
Hampel滤波器根据ri、Mi和Swi三者之间的关系来判断ri是否为异常数据点,判决公式如下所示
|ri-Mi|≥k×Swi
(3)
其中,k为可变参量,如果式(3)成立则认为ri为异常点并将Mi替换ri,否则为正常点。
由于k和Swi决定了异常数据点的筛选,须根据人体特征选取。在文献[13]中详细讨论了k的选取,一般为2~5。对于Swi,由式(1)、式(2)可得,Hampel滤波器不能处理时间窗序列中含有连续w个数据点为相同数值时的情形。而人体处于稳定状态时,节点测量精度不足可能会产生上述错误,MAD近于0,k和Swi对异常数据点判决影响过小;同时,偶然丢失的数据须通过k和Swi恢复。因此,本文对Swi进行了如下改进
Swi=max(Swi,d)
(4)
其中,d是预定义大于0的常数,根据观测数据的方差选取,max表示取Swi和d的最大值。
由式(1)~式(4)可得,Hampel 滤波器依次处理传感器的观测数据,保证了数据的连续性,时间窗包含了数据点前后各g个数据点,具有一定的滞后性,可根据任务的实时性要求选取g的大小。Hampel滤波器的时间复杂度为O(n)。
4 异常数据集检测
本小节所使用的变量含义见表1。

表1 变量说明
4.1 问题描述
设单个传感器可观测m个生理参数,一次观测的时间点个数为t,则单个传感器采集的数据可用矩阵G表示
其中,Xi=(xi1,xi2,…,xim) 表示传感器节点在时间点i对m个生理参数的观测值集合,Si=(x1i,x2i,…,xti) 表示传感器节点对第i个生理参数在t个时间点的观测值集合。异常数据集检测的结果为准确地标识出异常数据集开始和结束时间点,可表示为 [t1,t2]=f(S1,S2,…,St)。 其中 [t1,t2] 表示异常数据集开始和结束的时间点,f(S1,S2,…,St) 表示对矩阵G进行的某种变换。
4.2 DBSCAN算法
DBSCAN算法根据数据之间的密度连通性发现簇和噪声点,包含Eps(指定数据集G中任一点的周围半径)和minPts(在指定的Eps下数据点成为核对象至少包含的对象个数)两个参数,根据以上参数可有如下定义。
定义1 邻域:任意数据点p在G中的邻域NbEps(P) 可通过如下定义获得NEps={p|dist(p,q)≤Eps,q∈G}, 其中dist(p,q) 表示p和q之间的距离。
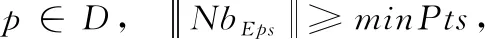
定义3 直接密度可达:若p,q∈G,NEps(q)≥minPts,p∈NEps(q), 则对象q从对象p直接密度。
定义4 密度可达:若D={d1,d2,…,dn},d1=q,dn=p, 任意di,di+1,NEps(di)≥minPts,di+1∈NEps(q), 则p和q密度可达,其中D为一串相邻对象直接密度可达的序列。
定义5 密度相连:若G中存在一个对象O,使得对象p和q都从O密度可达,则称对象p和q密度相连。
4.3 基于滑动时间窗的DBSCAN改进
DBSCAN算法无需预标记数据,可实现任意形状和大小的集群,能够检测出噪声。DBSCAN聚类的结果是非连续数据点的集合,而人体生理参数在一段时间内具有连续性,前一时刻的生理状态影响着后一时刻,数据点之间的相关性决定了异常数据呈连续分布,因此直接使用DBSCAN检测异常数据不能准确标识出异常数据集的起始和结束位置,且Eps和minPts是具有全局作用的参数,决定了DBSCAN的聚类结果的好坏,这限制了DBSCAN对于不同异常数据的适应能力。因此,本文从Eps和minPts的定义出发,设置滑动时间窗,某一时间窗内的数据被认为全部是异常数据或正常数据,这样将整个数据集聚类的结果变换为每一个时间窗中的数据能否聚为一个类的问题。图3表示滑动时间窗,时间窗的宽度是可调的参数,当传感器节点采集的数据充满第一个时间窗时,即可对时间窗中的数据进行分析。
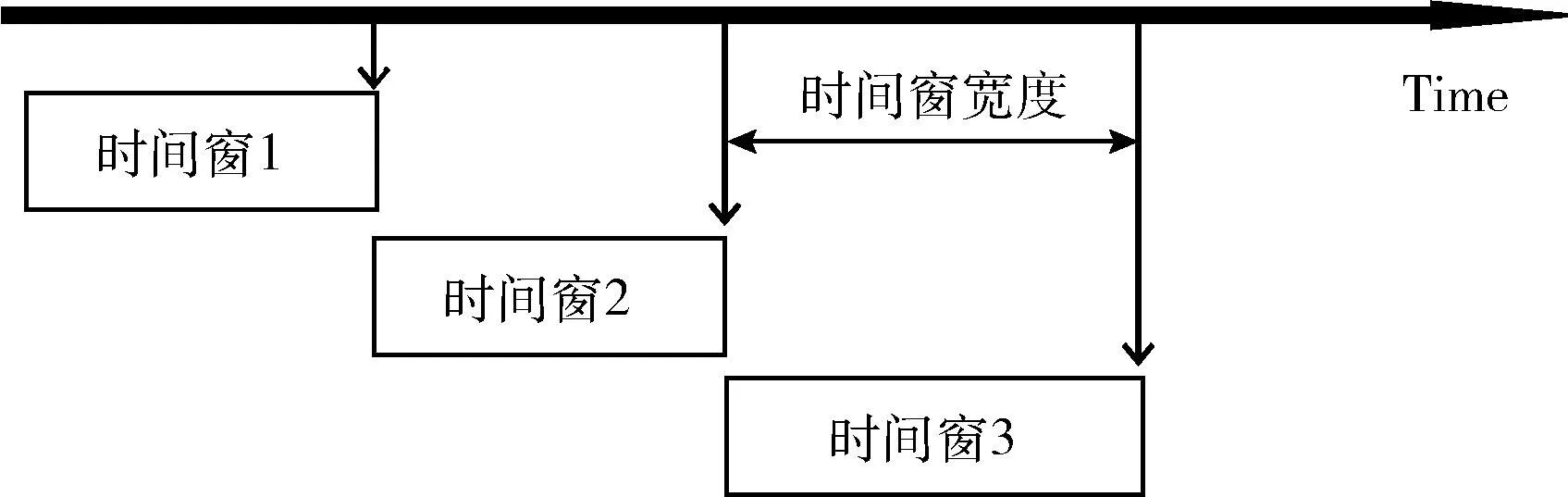
图3 滑动时间窗
Eps和minPts的选取:时间窗中的数据一旦采集完毕,数据点之间的距离不再变化。因此,对于任意数据点,若minPts为1,Eps为数据点的最近邻距离,则该数据点为核心点。单独一个数据点的最近邻距离不具有代表性,本文将每一个数据点的最近邻距离相加后平均得平均最近邻距离,平均最近邻距离作为Eps的候选值。同理,当minPts为k时,Eps为数据点与第k个最近邻数据点之间的距离,将每一个数据点的第k个最近邻数据点之间的距离平均得第k个Eps的候选值。设时间窗宽度为n,则Eps存在n个候选值,由此可得Eps候选值的计算步骤为:
步骤1 计算时间窗数据的距离分布矩阵Dn×n={Dist(i,j)|1≤i≤n,1≤j≤n}, 其中n为时间窗包含的数据点个数,Dist(i,j) 为第i个数据点到第j个数据点之间的距离。
步骤2 对距离分布矩阵进行升序排序,第一列为数据点到自身距离为0,第k列表示所有数据点与其对应第k个最近邻数据点之间的距离。
步骤3 对每一列求平均,将其作为Eps的候选值。
在得出Eps候选值的过程中,假设minPts为固定数值,这样的限制不能代表数据自身的特征。minPts是在指定的Eps下数据点成为核对象至少包含的对象个数,应由Eps的候选值确定minPts的个数。因此,对于每一个Eps候选值,依次求出所有数据点的邻域对象数量,所有数据点邻域对象的期望值作为minPts的候选值。计算方法为
(5)
其中,Qi表示第i个数据点的邻域数据点个数。这样每一个minPts对应于一个Eps,但minPts和Eps对于聚类算法是二维随机变量,因此,本文将minPts和Eps合为一个变量,其公式如下所示
Density=minPts/Eps2
(6)
其中,Density表示以Eps为半径的圆内存在minPts个数据点。Eps和Density一一对应,故Density有n个候选值。由于Eps第一个候选值为数据点到自身的距离0,Density从第二个值开始计算。
Density候选值趋势分析:平均最近邻距离表示数据的紧密程度,Eps候选值不断增大表示数据的紧密程度不断减小,因此Density呈不断减小的趋势。本文将时间窗中的数据全部认定为异常数据或正常数据。若为正常数据,则时间窗内的数据被视为一个类,不同数据点之间的相关性可用平均最近邻距离衡量,因此平均最近邻距离对应的Density应远大于其它Eps候选值对应的Density,同时随着Eps的不断增加,时间窗中数据点的个数是不变的,Density逐渐趋于水平。若为异常数据,数据点之间的紧密程度小,平均最近邻距离和其它Eps候选值对应的Density不具有显著差别。
根据Density的变化趋势,本文提出以下准则作为判断时间窗中的数据是否正常数据的标准。
准则1:平均最近邻距离对应的Density应远大于其它Eps候选值对应的Density即Density(2)>k×Density(3), 其中k>10。
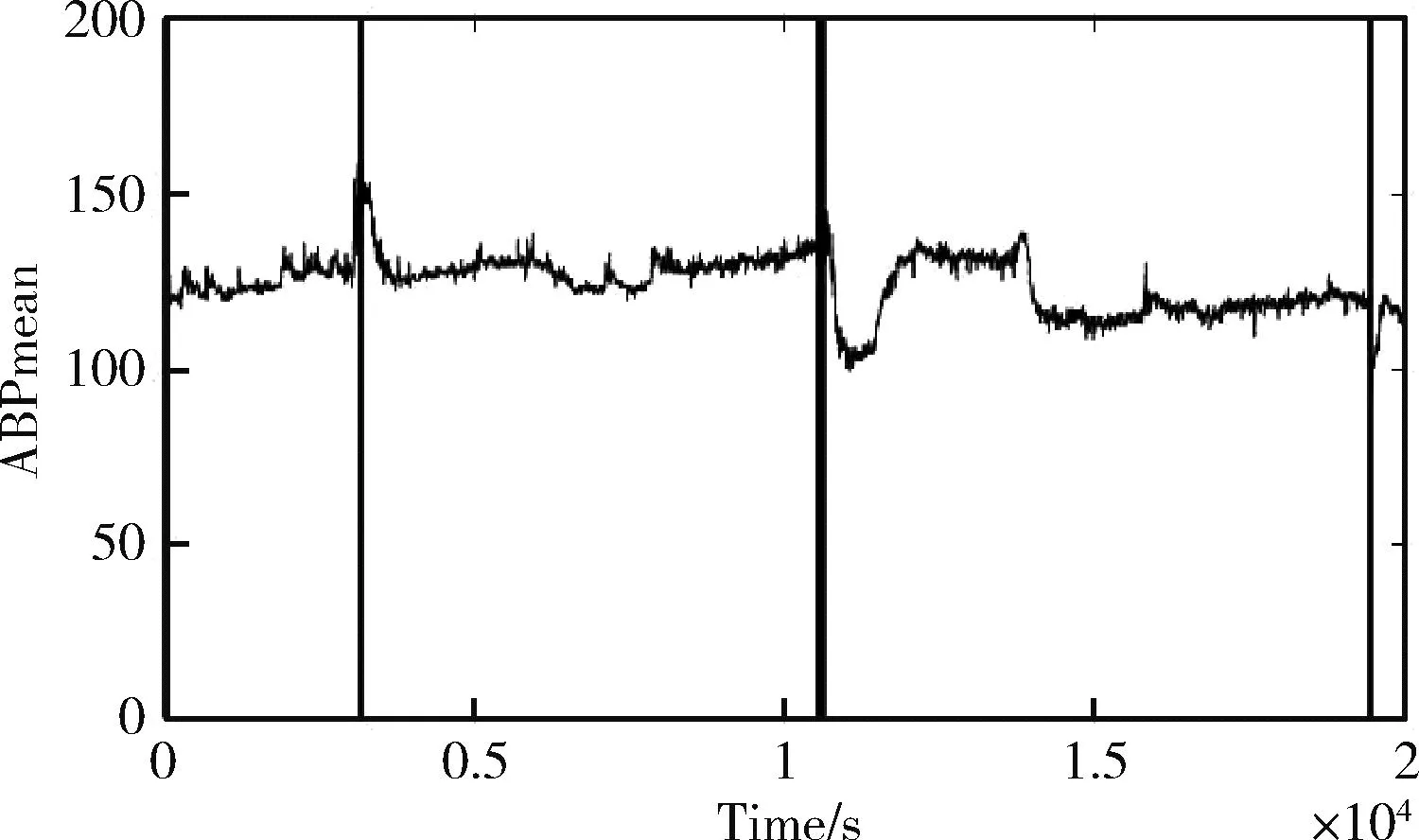
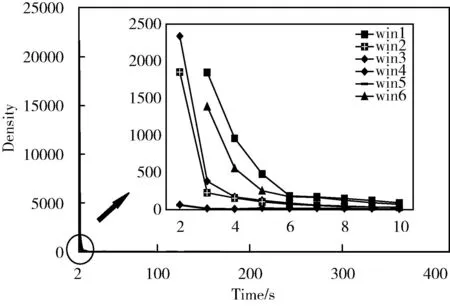
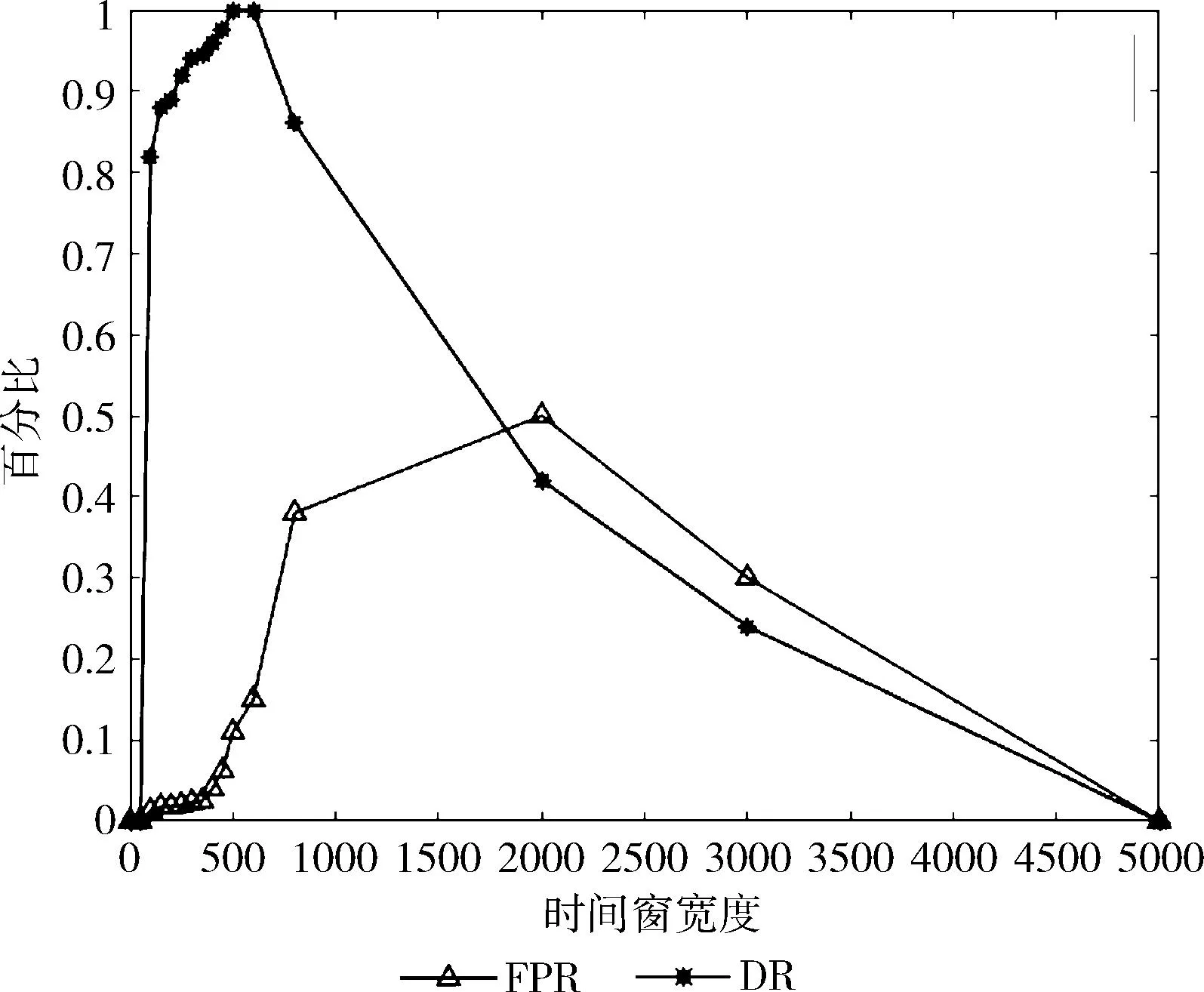
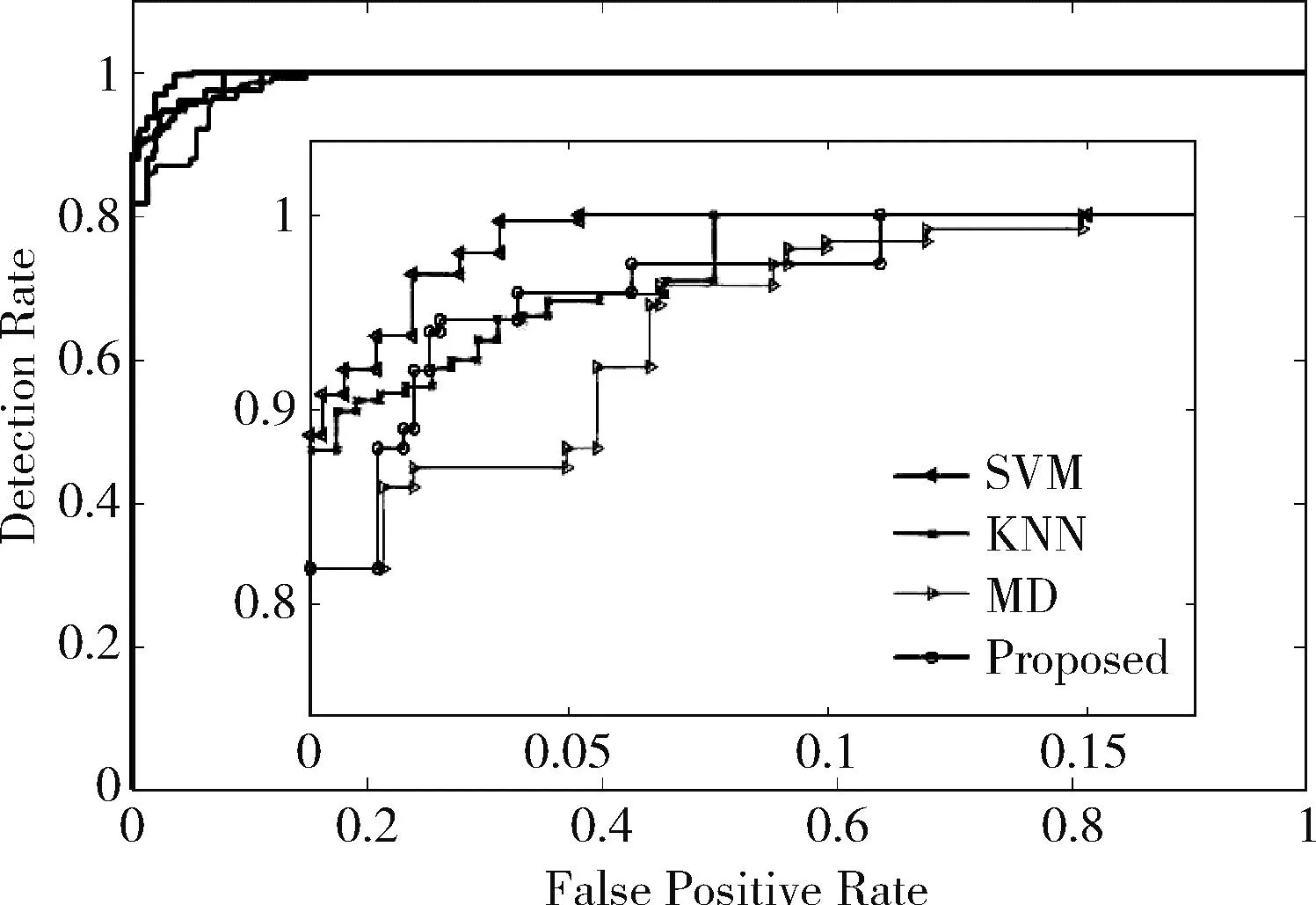
准则2:Density应在起始处快速下降,并随着数据点的增长趋于水平,即Density(i)-Density(i-1) 不断减小并趋近于0,其中0 这样通过划分时间窗的方式将DBSCAN直接聚类的结果转换为Density趋势的变化,由此判断时间窗中的数据是否为异常数据。 WBAN通常有多个功能不同的传感器节点对人体健康状态进行监护,人体作为一个有机的系统,各种生理参数之间具有强相关性。本文使用协方差系数来描述不同生理参数之间的相关性。生理参数X和Y之间的协方差系数可表示为 (7) 由于人体生理参数具有波动性,协方差系数应在一定的范围内波动,本文采用3σ原则对其判定,其中σ表示协方差系数的标准差。如果某一节点测量的人体生理参数和其它节点测量的生理参数的协方差系数和人体处于正常健康状态测得的协方差系数不超过3σ,则认为异常数据来源于人体健康状态。由于涉及到多个节点,单独一个节点不能承担验证分析,需将多个节点的数据传输至汇聚节点处。异常数据集检测已明确标出了异常数据集所在的时间窗,其它时间窗中的数据对于异常数据集没有提供有效信息,可直接忽略。因此,只需将异常数据集所在时间窗的数据传输至汇聚节点。 异常数据集检测方法流程为: 步骤1 初始化时间窗的大小n。 步骤2 当时间窗中数据点个数达到n时,根据时间窗中的数据点得距离分布矩阵Dn×n。 步骤3 计算Eps和minPts的候选值。 步骤4 由式(6)得Density向量。 步骤5 根据准则1和准则2判断时间窗中的数据是否为异常数据集。 步骤6 若时间窗中的数据为异常数据,将异常数据传输至汇聚节点,汇聚节点根据式(7)计算不同生理参数之间的协方差系数。 步骤7 比较人体健康状态下的协方差系数和计算得到的协方差系数,验证异常数据集后标注出异常数据集所在的时间窗,并发出警报。 数据集G中数据点个数为n,时间窗宽度为w,则存在n/w个时间窗,异常数据集检测方法在每个时间窗运行的时间复杂度为O(w2), 则总体时间复杂度为O(nw)。 每次算法只需存储w个数据点,其空间复杂度为O(w)。 为保证实验结果的有效性和真实性,本次仿真实验使用的医疗数据来源于Physionet[14]的数据库MIMIC(multiparameter intelligent monitoring in intensive care)中编号为221患者的生理数据,其包括以下生理参数、心跳频率(heart rate,HR)、呼吸频率(respiration,RESP)、血氧饱和度(SpO2)、平均动脉血压(mean arterial blood pressure,ABPmean)。图4表示患者生理参数在0到20 000个时间点的变化图。 图4 人体生理参数 图5为ABPmean异常数据点检测的结果。其中时间窗w取值为50,k为3,d在Hampel滤波器中作用为抑制常数错误,在本次实验中选取为4。图中竖线标出的点为Hampel滤波器检测出的异常数据点,主要为常数错误的数据点和相对于周围数据具有显著变化的点。 图5 ABPmean异常数据点 在不失一般性的条件下,本文选取ABPmean和HR作为同一个节点观测的人体生理参数。由于时间窗的大小对实验结果有着显著影响,本文在4.3节进行了详细分析。图6为不同时间窗密度曲线图,时间窗宽度为400,其中“win”表示时间窗,图中圈出的位置为Density曲线横坐标2到10的放大图,其中win1和win6的横坐标为2的数据超过了圆圈范围,进行了截取,由图可知Density趋势符合上文的分析。通过准则1和准则2可知,第五和第六个时间窗是异常数据集所在的时间窗。图7为异常数据集标注图,通过对20 000个数据进行时间窗划分并判定每一个时间窗数据是否为连续的异常数据集得到的结果,图中每两个竖线之间的时间窗中的数据为异常数据集,和文献[14]相比,标准的异常数据集具有一致性,较好地反映了异常数据集所在的位置。 图6 不同时间窗密度曲线 图7 异常数据集标注 本文使用检测精度DR(detection rate)和虚警率FPR(false positive rate)来量化所提方法的有效性,并用受试者工作特征曲线(receiver operating characteristic curver,ROC)表示FPR和DR之间的关系[15]。下述定义中正常数据表示人体处于健康状态时的观测数据,异常数据表示受到环境噪声影响或人体健康状态发生变化时的观测数据。检测率DR可通过如下公式表示 (8) 其中,FD表示检测的异常数据点个数,TN表示总体异常数据点个数。与之相应的,虚警率可通过如下公式表示 (9) 其中,FP表示正常数据点被检测为异常数据点的个数,TF表示正常数据点的个数。 图8为时间窗的大小对DR和FPR的影响。当时间窗较小时,由于人体生理参数具有连续性,无法区分一个时间窗内的数据是否为异常数据,由于异常数据占比较小,本文将每一个时间窗中的数据均视为正常数据,得到DR=0,FPR=0;当时间窗宽度增至一个时间窗宽度内的数据能够表示人体处于异常状态时,即某些时间窗内的数据不能够聚类时,异常数据检测算法工作于正常区间的起始点,得到DR=81.82%,FPR =0;在时间窗宽度增加至最长异常数据集时间长度时,一部分正常数据被视为异常数据,另一部分在时间窗长度较小时检测为异常数据集的数据被视为正常数据,FPR和DR呈非线性上升直至DR=100%,FPR=11%,异常数据检测算法工作于正常区间的截止点;当时间窗增大到最长异常数据集被视为正常数据时,DR=0,FPR=0,此时本方法失去实际应用价值。 图8 FPR和DR随时间窗宽度变化 本文在文献[14]基础上将所提出的方法和基于SVM、KNN、MD的异常数据检测方法进行对比,如图9和表2所示。图9为不同检测方法的ROC图,表2为不同检测方法的对比图。由9图可知,基于SVM的检测方法有效性最好,当DR=100%时,FPR=5.2%,但由表2可知其空间和时间复杂度达到了O(n2)和O(n3),在对比的方法中计算复杂度最高,因此不适用节点资源有限的WBAN;基于KNN、MD方法和本文提出的方法在DR=100%时,FPR分别为6.8%、15%、11%。因此,本文提出的方法相比于基于MD的方法具有更好的检测精度,但差于KNN,主要因为本文提出的方法为达到100%检测精度,选用的时间窗过大。但由图8和图9可知,当时间窗处于正常工作区间时,本文提出的方法的ROC曲线在KNN之上,因此在检测精度和虚警率上优于KNN,同时由表2可知,基于KNN和MD的方法和本文提出的方法的时间复杂度分别为O(n*k)、O(n)、O(wn), 其中k为特征维度,w为时间窗宽度,因此这3种方法在时间复杂度上不具有明显差距,在空间复杂度上分别为O(n*k),O(n2),O(w), 因此本文提出的方法空间复杂度为常数,显著优于其它方法,且基于SVM、KNN和MD的检测方法均需在传感器获取所有数据后再检测异常数据,因此不满足WBAN的实时性要求。而本文提出的方法只需存储时间窗内的数据,可根据任务的实时性调整时间窗的大小,当时间窗内的数据为异常数据集时,只需将时间窗内的数据传输至汇聚节点,有效地降低了传感器节点由于频繁通信产生的能量损耗。因此,本文提出的方法与基于SVM、KNN和MD的方法相比更适合用于传感器侧检测异常数据。 表2 不同检测方法复杂度对比 图9 不同检测方法ROC 本文提出了一种分层的异常数据检测方法。Hampel滤波器检测异常数据点,在此基础上异常数据集检测方法通过划分时间窗的方式将聚类的结果转换为每一个时间窗中的数据能否聚类的问题,并与其它方法相比,本文的方法考虑了人体健康状态发生变化时异常数据具有连续性的特征,空间复杂度更小,在检测出异常数据集后,只需将异常数据集所在时间窗的数据传输至汇聚节点,降低了节点的能量损耗。但所提出的方法固定了时间窗的宽度,降低了系统性能。因此,设计可变的时间窗,提高异常数据集的标注准确性是下一步改进方向。4.4 异常数据集验证
4.5 异常数据集检测算法描述
5 实验仿真分析
5.1 数据集来源

5.2 异常数据检测方法仿真

5.3 异常数据检测方法法性能评估

6 结束语
猜你喜欢
计算技术与自动化(2024年3期)2024-10-10 00:00:00
电子制作(2019年11期)2019-07-04 00:34:38
中国惯性技术学报(2019年6期)2019-03-04 09:50:10
小学生导刊(2018年34期)2018-12-18 01:53:14
电子制作(2018年16期)2018-09-26 03:26:50
中央民族大学学报(自然科学版)(2017年2期)2017-06-11 07:14:54
山东青年(2016年3期)2016-02-28 14:25:55
火控雷达技术(2016年3期)2016-02-06 02:30:28
火控雷达技术(2016年2期)2016-02-06 02:29:00
浙江理工大学学报(自然科学版)(2015年10期)2015-03-01 02:54:43
