
低温热年代学数据库建设现状与前景展望
2024-01-20 09:16戴梦瑶李安波刘品钦戴紧根张会平刘少峰
地震地质 2023年6期
戴梦瑶 王 平 李安波 丁 璐 刘品钦 戴紧根 张会平 刘少峰
1)南京师范大学,地理科学学院,南京 210023 2)江苏省地理信息资源开发与利用协同创新中心,南京 210023 3)中国地质大学(北京),地球科学与资源学院,北京 100083 4)中国地质大学(北京),地质过程与矿产资源国家重点实验室,北京 100083 5)中国地震局地质研究所,地震动力学国家重点实验室,北京 100029
0 引言
低温热年代学利用矿物中放射性元素的衰变或裂变产物标定岩石的冷却年龄,特别适合限定年轻地质体的构造活动时间(陈文寄等,1999)。由于其可对中、上地壳近地表矿物岩石温度随时间的演变过程提供较好约束,可用于计算山体的剥蚀或隆升速率,并反演隆升-埋藏的热历史,是开展造山带和盆地构造地貌演化、河流下切历史等新构造和地表侵蚀过程研究的重要手段(丁汝鑫等,2007; 王修喜,2017; 李广伟,2021)。低温热年代学技术依据放射性元素238U、232Th 通过α衰变最终形成Pb同位素的衰变过程。该过程会在矿物内部产生损伤并留下径迹,即裂变径迹,同时释放出α粒子,即4He核(周祖翼,2014; 田朋飞等,2020)。因此,选择U、Th含量较高的矿物(如磷灰石、锆石等)进行裂变径迹的统计或(U-Th)/He方法的测试,是获取低温热年代学数据的主要途径。
近年来,随着低温热年代学测试技术的普及,数据量不断增加,催生了很多基于大数据的构造地貌演化研究,在国际上产生了一系列有影响力的创新成果。Herman等(2013)通过搜集超过500篇文献中的约18000个低温热年代学数据,建立了全球造山带的数据集,从中发现晚新生代剥蚀加剧,认为全球气候变冷是晚新生代造山带剥蚀加剧的重要原因。而Schildgen等(2018)则认为晚新生代的剥蚀加剧不具普遍性,且其成因在不同地区也存在差异,气候和构造都可能是剥蚀加剧的成因。近期,Jepson等(2021)对青藏高原及周边区域的2511个低温热年代学数据进行了分析,通过对比气候指标和模拟结果,认为气候仍然是控制晚新生代青藏高原剥蚀的关键因素。除此以外,在大尺度板块构造和古地理恢复工作中,热年代学数据也成为恢复古地貌的有效途径。例如,Poblete等(2021)基于低温热年代学数据集,对新生代(距今60Ma)以来的古地貌进行了重建,填补了古地理重建过程中古地貌信息的空白。
当前的低温热年代学数据量已经非常可观,但大都分散于不同来源的文献中,格式、内容均不统一,数据质量参差不齐,在一定程度上限制了大数据的创新研究。因此,建立统一、完善的低温热年代学数据库势在必行。美国等发达国家的地质年代学数据库建设起步较早。例如,美国在20世纪70年代最早建立了NGDB地质年代数据库(Zartmanetal.,1995),并随后建设了Geochron数据库(Walker,2016)。加拿大的DataView数据库(Eglington,2004; 李秋立等,2020)、新西兰的Petlab数据库(Strongetal.,2016)等也都包含了低温热年代学数据。中国地质年代学研究虽然起步较晚,但近年来的数据增量很大,对数据库的需求亦与日俱增。中国地质科学院最早对全国的同位素年代学数据进行了汇编,采用Microsoft Access 97数据库软件与ESRI ArcInfo地理信息系统建立了中国首个同位素地质年代学数据库,并包含了裂变径迹热年代学数据(蔡俊军等,2002)。在之后的研究中,中国也建立了多个地区或专题的年代学数据库(方先君等,2018; Heetal.,2018)。最近,中国科学院地质与地球物理研究所开发了地质年代学数据共享平台(1)http:∥onelab.ac.cn/。(OneLab),将实验仪器与数据管理、科研数据管理与开发、科研数据出版与共享融为一体,旨在推动数据和仪器的开放共享。
现有地质年代学数据库的设计思路往往适合绝对年龄数据,但是低温热年代学有别于常规的地质年代学方法,其年代值只记录冷却时间,更具有地质意义的冷却历史则来自基于高程剖面、径迹长度等信息的数值模拟(周祖翼,2014)和(U-Th)/He体系的扩散动力学模型。另外,实验技术的革新也对热年代学数据库的建设提出了新的要求。以裂变径迹数据为例,传统的“在线”统计方法只产生3个方面的数据,即样品元数据、单颗粒的年代数据、单颗粒的径迹长度数据,且数据量较小(KB—MB级)。新的统计技术可先在线采集动态图像,然后在任何一台计算机上进行“离线”统计,数据量提升了数千倍。例如,FastTracks系统(Gleadowetal.,2019)中每个样品会产生10~20GB的数据量。如何更好地保存和利用这些数据,也是数据库建设中面对的主要问题。近期,澳大利亚的地球科学组织AuScope Geochemistry Network(AGN)发布了新的AusGeochem数据库(Booneetal.,2022),其中包含了由墨尔本大学设计的新一代低温热年代学数据库。美国也在EarthCube计划的支持下针对热年代学数据开发了新一代Sparrow数据库应用,代表了实验室与数据库融合的最新趋势。本文系统综述了当前国内外代表性的低温热年代学数据库的建设现状,着重对比了传统数据库与新一代数据库的差异,并对下一步数据库的建设进行了展望,以此为新构造和地貌演化的大数据研究提供基础保障。
1 传统地质年代学(热年代学)数据库现状
在过去的几十年里,基于公开发表的数据,不同的国家或组织都相继建立了包含低温热年代学数据的地质年代学数据库,除了上述提及的NGDB数据库、Geochron数据库、DataView数据库、Petlab数据库外,还有加拿大的Geochronology Knowledgebase数据库(Villeneuveetal.,2005)和哥伦比亚的地质年代学数据库(Rodriguez-Corchoetal.,2021)等。另外,也有些以数据集的形式分散在学者的文章中,或由公司收集并提供有偿数据咨询服务(Markwick,2019)。下文就以几个常见的公开数据库为例,介绍其在低温热年代学方面的数据组织形式、模型特点和应用现状。
1.1 美国国家地质年代数据库NGDB
美国国家地质年代数据库NGDB(2)https:∥apps.usgs.gov/geochron_database_explorer/。(National Geochronological Data Base)于1974年由美国地质调查局建立,是最早的放射性同位素年代学数据库(Zartmanetal.,1995),主要存储美国地质年代学数据,其中包含1397条热年代学数据。NGDB以Location(地理位置)作为主表,使用RecNo(样品标识符)作为主键,与从表采用“一对多”对应关系构成关系型数据库(图1)。数据入库采用手工方式,在入库前需要进行字段格式统一和地理位置校正。数据库包含了样品的地理位置、岩石描述、分析数据、年龄和参考文献(Sloanetal.,2003)。自2003年以来,NGDB数据和字段的更新都处于停滞状态,直到2019年6月由Peter Schweitzer负责再次启动数据库更新计划(李秋立等,2020)。新数据库平台已于2023年重新上线,定位为地质年代学和热年代学数据库,其中热年代学数据量增加到1764条数据,但基本来自美国。数据采用几何框选和关键字2种检索方式,检索结果支持JSON、CSV和GeoJOSN格式的下载。
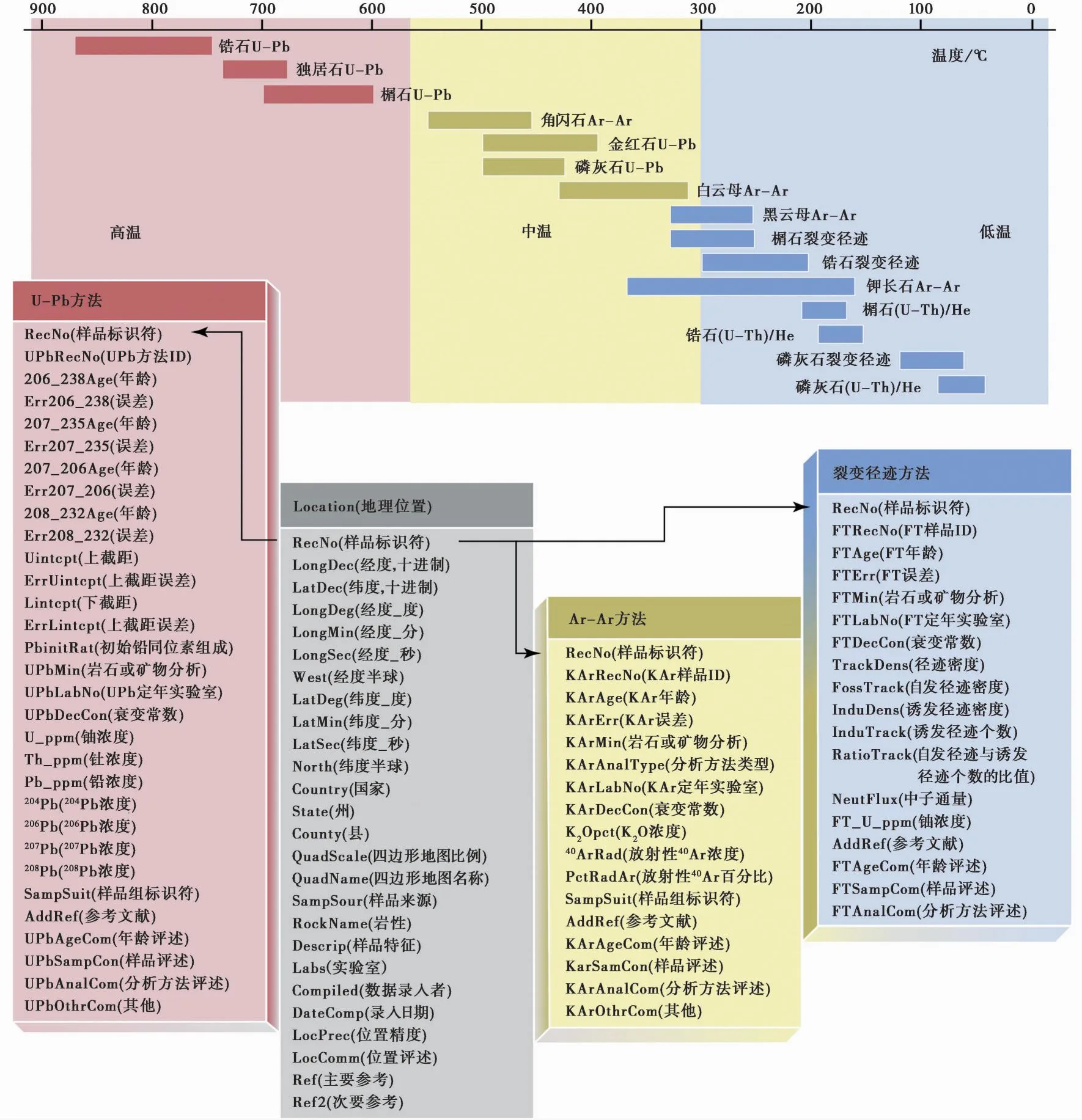
图1 地质年代学方法的温度范围及美国国家地质年代数据库(NGDB)针对不同方法设定的数据字段(改自Sloan et al.,2003)
1.2 Geochron地质年代学数据库
Geochron(3)http:∥www.geochron.org/。是美国2007年发布的地质年代学数据库,早期以U-Pb同位素地质年代数据为主,自2017年起增加了对低温热年代学数据的支持(McLean,2017)。目前,数据库维护由美国堪萨斯大学的Noah McLean团队负责。在数据录入方面,Geochron提供了完整的模板,由用户手工录入与样品相关的各种信息,如采样位置、岩性、实验室等,还包括单颗粒年龄、径迹长度等; 在数据查询方面,支持多要素条件联合查询和模糊查询,可选条件包括位置、年龄区间、岩性、实验室及IGSN样品编码等,同时也支持地图框选查询; 在数据导出方面,提供HTML、XLS和XML 3种文件格式的数据浏览和下载。虽然Geochron数据库设计得比较完善,但由于需要手工录入数据才能实现数据增长,其数据量很大程度上取决于数据拥有者的个人意愿,且没有得到实验室的广泛支持。因此,截至2021年,该数据库仅汇总了全球778个样品数据,其中包括438组(U-Th)/He数据、340组裂变径迹数据,该数据量可能还达不到全球已发表数据量的5%。此外,Geochron的低温年代学数据入库模板设计复杂,录入过程繁琐,降低了学者的录入意愿,且数据无法以结构化的二维表格形式展示,部分数据项缺失较为严重。
1.3 新西兰地质样品数据库Petlab
Petlab(4)https:∥pet.gns.cri.nz。是由新西兰的GNS Science(Geological and Nuclear Science)公司建设并维护的岩石、矿物和地质分析数据库,于2004年上线。其采用Oracle数据库软件的关系型架构,将面向用户的管理和授权行为、面向业务的数据操作规则和面向对象的实体属性关系都交由数据库中的业务逻辑层软件进行管理。对每个样品提供16个必填字段,包括样品编号、采样者、日期、地理坐标和岩石描述等基本信息,以及若干可选的描述性字段(如岩石学、矿物学描述等)。数据的收录包括2个渠道:对于GNS公司的自有数据,通常会在得到分析结果后的几周内录入; 对于来自学术期刊的公开发表数据(被称为legacy数据),则需要花费大量时间完成,更新的周期通常在一年以上。在数据查询方面,分为一般查询和结构化查询语言(SQL)高级查询。一般查询支持表单检索和采用Web地图空间检索2种形式; 使用SQL可构建更为复杂的查询条件。在数据导出方面,返回数据记录可以Excel或CSV格式下载,或以样本位置点的形式在专业GIS软件(如ArcGIS)或Google Earth中查看。Petlab维护和更新的活跃度较高,截至2021年,数据库共包含新西兰和南极地区的212139条数据,其中包括18条(U-Th)/He数据、1048条裂变径迹数据。然而,Petlab仅针对贡献数据的几个机构(如奥克兰大学等)开放,对于非合作机构的个人用户,注册审核及字段查询的权限管控则非常严格。
1.4 加拿大同位素地质年代学数据库DataView
DataView(5)http:∥thera2.usask.ca:8085/。是由加拿大萨斯喀彻温大学Bruce Eglington教授负责的国际地质年代学和同位素数据库。该数据库于2000年通过Paradox关系型数据库软件配置,以Windows桌面软件的形式发布(Eglington,2004),后于2007年转变为由开源关系数据库管理系统Firebird构建的网页数据库,目前仍在开发中(6)https:∥sil.usask.ca/databases.php。。DataView的查询功能设计得非常细致,可自定义查询的字段,进行精准定位,还可以自定义查询结果的展示字段,并提供EXCEL、CSV、HTML、PDF文件格式供用户下载。DataView在数据查询功能上定义了非常丰富的可选字段,方便用户在不熟悉字段格式的情况下进行模糊查询。此外,在录入数据时,数据库还提供了数据质量评价,并开发了多种绘图功能以便对查询结果进行直观的对比和分析。截至2020年12月,该数据库公开发布超过152000组数据,其中有255条(U-Th)/He数据、2248条裂变径迹数据。遗憾的是,相比其他的年代学数据,该数据库内的低温热年代学数据量非常有限,且缺乏实验室、岩性、分析方法等相关字段信息,更新也十分缓慢。
2 新一代低温热年代学数据库
2.1 澳大利亚AusGeochem数据库
AusGeochem(7)https:∥ausgeochem.auscope.org.au。是由澳大利亚国家合作研究基础设施战略(NCRIS)的AuScope项目资助的地球科学数据开放存储云平台,旨在完善年代学和同位素数据的存储,于2021年正式上线。AusGeochem的低温热年代学数据库由墨尔本大学热年代学实验室负责建设(Booneetal.,2021)。该实验室历史悠久,一直以来都是低温热年代学技术和方法的引领者,为Autoscan公司(全球最大的裂变径迹设备制造商)开发了裂变径迹分析软件,并将裂变径迹的操作流程标准化。实验室利用自身拥有的约2万件样品(Gleadowetal.,2009,2019),并对全澳洲的实验室数据进行了整合,采用PostgreSQL数据库软件、React组件库、Java Spring Boot框架构建了面向对象的低温热年代学数据库。
AusGeochem借助Filemaker Pro数据库建模软件将热年代学数据划分为样品信息、分析信息和数据模拟信息3个信息模块,以样品信息为核心,链接到特定的实验方法,在裂变径迹定年方法中充分考虑了单颗粒数据的展示(图2)。数据信息更加全面(包括单颗粒的裂变径迹、(U-Th)/He数据),每件样品都可以采用IGSN(International Geo Sample Number)进行注册,确保样品号的唯一性,并使用DataCite提供标准的引用方式(Lehnertetal.,2006)。

图2 墨尔本大学低温热年代学(裂变径迹)数据库模型
AusGeochem设计了完善的数据质量评估体系,不仅成立了专家咨询小组研讨、制定数据报道格式,还在数据的录入过程中容纳了错误报告。字段的类型和格式参考了IGSN样品元数据、Mindat数据库的岩性和矿物的分类方案等进行了标准化设计。在数据查询和使用方面,设计了全新的Web应用界面,除了具备常规数据库的增加、删除、修改、查询等功能,还增加了数据逻辑关系的快速构建,以及年龄计算、统计分析、数据可视化等功能。用户可对数据进行二次分析和处理,如生成直方图、年龄-高程图,也可结合不同数据类型进行综合分析和解释,例如在古地磁学数据框架下理解低温热年代学数据。AusGeochem与澳大利亚多家实验室开展合作,构建实验数据的安全保障,可为数据发布与传播设定密级,并在录入数据的同时提供权限选项。对于未发表的实验室数据可选择保密、与合作者有限共享或全部共享。
2.2 Sparrow数据库应用
Sparrow(8)https:∥sparrow-data.org/。是2022年在美国国家自然基金委员会EarthCube项目支持下开发的数据库应用,遵从FAIR(Findable,Accessible,Interoperable,Reusable)原则(Wilkinsonetal.,2016),致力于地球科学的数据管理、学科间的数据共享并发掘其中的未知规律。不同于上述的数据库,Sparrow并不是一个现成的“库”,而是面向实验室端和用户端建立的通用的模块化数据库应用。实验室端通过Sparrow将样品的地质背景和分析信息等原始数据标准化并归类,挖掘数据格式的规则以实现数据全自动入库,再传输到相应的数据库中。用户端利用Sparrow收集、解释数据,将数据应用或发表(图3)。Sparrow内嵌了开源的空间数据库PostgreSQL来存储并管理数据,采用TypeScript脚本语言和React框架构建Web用户界面。不仅部署了实验室管理员、访客等不同级别用户的访问、查询权限,还实现了通过API链接到第三方数据库(如Geochron)的功能。Sparrow提供了较完整的数据库实现工具,包括数据管理、分析、可视化各个层面的功能和框架,采用Docker进行安装配置,几乎支持所有操作系统。
Sparrow的核心模块包括数据导入、数据权限管理及年代学数据库相关的分析扩展。数据导入面向CSV和指定JOSN格式的元数据,在实际应用中会基于用户更改的数据规则和导入流程进行数据自动获取、清洗和错误捕获。在数据权限管理方面,综合考虑数据的时效性和层次性(如字段、文档等),保护数据提供方的优先使用权限,允许其对任一字段设置密级。此外,Sparrow兼容开源的专业软件,可实现更高级的查询、分析功能,如添加Mapbox样式用于样品分布的可视化、将数据导入到QGIS中进行空间分析操作及利用Python相关程序进行绘图等。
Sparrow真正打通了从实验室到数据库的中间环节,直接在数据入库和分析的过程中实施FAIR数据管理原则。不同的年代学实验室都可以通过Sparrow对数据进行标准化,将实验室数据映射到需要的数据报道格式,进而方便第三方数据库(如EarthCube)汇集来自不同实验室的数据。平台也内置了元数据管理工具,使实验室的标准化管理和实验室之间的数据共享更为便捷。目前,已经有十多所实验室参与到Sparrow的测试中,包括科罗拉多大学的(U-Th)/He 热年代学实验室和威斯康星大学麦迪逊分校的Ar-Ar实验室等。
3 数据库特征对比与存在的问题
3.1 传统数据库与新一代数据库的特征对比
传统低温热年代学数据库(如前文介绍的4个数据库)具有以下优点:1)数据来源于可靠性强的公开发表论文,侧重呈现以样品为单元的年龄信息; 2)根据样品与分析方法的一对多关系,将数据库的逻辑结构设计为“关系型”,并通过关系型数据库软件和结构化查询语言(SQL)集中管理和更新数据、设定用户权限和数据密级; 3)数据的录入和编辑采用已被广泛应用的Excel电子表格实现,能够自动与业务逻辑层连接,在数据库管理系统中下载、上传和编辑数据。此外,这些数据库都基于在线地图开发了地图查询功能,增强了可视化效果,提升了数据库的数据发现能力。
然而,传统数据库的缺点也非常明显。1)首先,也是最为突出的问题,即低温热年代学数据在传统的地质年代学数据库中往往只被作为一个子集,为了确保与其他年代学数据报道格式的统一,在数据录入、存储时不得不对字段进行取舍,放大了共性,但忽略了特性,特别是对于一些特有的数据类型(如单颗粒数据)而言,存在严重的缺失,以至于影响数据质量评估。2)其次,低温热年代学数据在传统地质年代学数据库中占比很低,整体数据量偏少,覆盖的区域非常有限,更新也十分缓慢。这与近年来低温热年代学数据的快速增长不匹配,也很难满足大地构造学、地貌学等领域对大数据分析的应用需求。3)此外,与高温同位素年代学体系相比,低温热年代学的优势在于可根据样品的单颗粒数据(如裂变径迹)反演样品的热历史,以揭示岩石的剥蚀冷却或构造抬升过程。但在传统数据库的设计思路上往往只存储年龄数据,并没有考虑低温热年代数据的解释或反演结果,需要专门的数据结构存储热历史数据。

表1 传统和新一代低温热年代学数据库的特性对比
3.2 新一代数据库建设面临的主要问题
然而,新一代低温热年代学数据库的建设尚处于初步探索阶段,如何保证数据的持续增长,仍然是摆在数据库建设者面前的难题。与实验室建立数据关联虽然能够在一定程度上推动数据的增长,但难以确保让全部或多数实验室接受统一的数据入库规则。ET_Redux(9)http:∥cirdles.org/projects/et_redux/。即为一个典型的例子,它是由美国EARTHTIME项目支持开发的开源的年代学数据处理软件,旨在为U-Pb年代学建立统一的年代数据处理规范、校正标准,以提高数据精度,并推动不同实验室之间实现便捷的数据共享(Bowringetal.,2011)。ET_Redux采用关联账号的形式与Geochron数据库进行互访,支持将实验室数据以标准的格式快速上传到数据库,现已为包括亚利桑那大学年代中心在内的十多个实验室提供了专门的数据接口。不尽人意的是,虽然已经推广了十多年,但真正能够通过ET_Redux汇总到Geochron数据库中的U-Pb年代学数据并不多,且实验室很可能根据自身的发展需求调整数据处理方法和工作目标,从而不能完全接受ET_Redux的运作方式。
其次,数据或样品的编号标准也是数据库建设面临的问题。虽然通过IGSN提供的注册服务能够获得样品的唯一编号,但这仅针对实验室所拥有的实体样品,而对于已经公开发表的大量低温热年代数据而言,几乎不可能让每件样品都拥有标准编号。此外,一些没有与IGSN建立合作关系的组织或机构短时间内也无法授权并获得IGSN的编号。因此,建立灵活的编号体系,对样品和数据建立可持续、可扩充的唯一标识,也是新一代数据库的重要任务。
第三,低温热年代学所具有的特殊数据结构特征,是新一代数据库设计者面临的一项挑战。现有的年代学数据库普遍采用关系型数据库逻辑结构(二维表),表与表之间可通过字段进行关联,这样做的好处是便于使用SQL查询,缺点是灵活性大大降低,数据录入必须符合字段规范,扩充性和兼容性较差。以裂变径迹为例,最新的实验室数据类型中除了文本、表格,还包含大量动态图片(Gleadowetal.,2019),数据量也较从前增加了上千倍,传统的数据结构根本无法完成此类数据的存储。在实验方法上,过去普遍采用白云母外探测器统计法(EDS)测量诱发径迹密度来计算238U 含量,最近则开始采用激光剥蚀等离子体质谱法(LA-ICP-MS)直接计算238U 含量,2种方法的数据报道格式差别较大,无法建成统一的入库表格(字段)。此外,(U-Th)/He方法普遍存在同一个样品单颗粒年龄分散的问题,因此需要探索更为灵活的入库方案。除原始数据以外,已经发表的裂变径迹文献中还包括大量热历史信息,它们是由作者解释或反演的结果,属于解释性数据,但对于恢复冷却历史或构造隆升却十分重要,如何将此类数据入库也是数据库设计时必须考虑的问题。
4 低温热年代学数据库建设展望
通过对比传统和新一代低温热年代学数据库的特征,并对现有数据库存在的问题进行分析,不难看出,建设完整、自主、灵活的新一代低温热年学数据库势在必行,其重要意义表现在3个方面:1)科研管理的需要。通过数据库集中管理已发表或即将发表的数据,可有效避免重复的科学研究,提高科研经费的使用效率。2)实验室分析的需要。通过实验室数据接口,可及时地发布数据,并方便不同实验室间的数据对比,规范数据表达。3)大数据创新研究的需要。通过汇集海量数据,探索发现未知的规律,揭示构造隆升、剥蚀等深时地质过程。为此,下文将针对现有数据库面临的问题,结合计算机技术等领域的最新进展,对低温热年代学数据库的建设提出展望。
4.1 可持续的数据增长
如前文所述,在低温热年代数据库的建设中,最关键的环节是如何实现数据快速、实时的增长。已有研究或应用表明,利用人工智能建立自动化入库机制,通过开放共享的文献获取途径快速更新数据及借助社交网络促进数据传播,都是促进数据快速增长的重要手段。
4.1.1 人工智能(AI)实现数据自动化入库
现有的数据库都采用人工录入的方式进行数据入库,有的是由数据作者本人录入和维护,有的数据库维护方配备专门的数据编辑团队,即使最新的AusGeochem数据库也不例外。最近,计算机科学家开始尝试利用人工智能(AI)技术从文献中自动提取信息,如自然语言处理或其他形式的机器学习算法。美国艾伦人工智能研究所(Allen Institute for Artificial Intelligence)于2015年推出了基于深度学习的Semantic Scholar学术搜索引擎,不再仅限于为用户提供普遍的关键字检索功能,而是在深度学习技术中内嵌信息筛选,对检索结果二次分析,突出有用信息。利用机器阅读技术从文本中挑选出最重要的关键词和短语,判断文章的主题,并从论文中提取图表,将其呈现在检索结果中,帮助用户快速理解文献内容,避免遗漏有用信息,同时也不会产生冗余。Semantic Scholar还为研究者提供应用程序接口(API)和开放研究的语料库(谢智敏等,2017)。
式中:Q为风机所需风量(m3/h);K为风管和除尘器的漏风系数,取 1.15;Q1为系统风量(m3/h).
在针对地学文献的具体研究中,美国威斯康星大学开发了基于人工智能的数据挖掘系统——GeoDeepDive,用于地学特定术语、主题或位置等相关文本信息的挖掘和解析。GeoDeepDive将海量文献存储于后端文献库中,即全集库(图4a)。用户可利用关键字从全集库中获取专题子集,然后在子集中分离出少量符合需求的测试数据集,接着将测试数据集与其余的子集进行匹配分析、完善匹配规则、找出结果,如此反复即可得到准确性较高的结果数据集(Marsiceketal.,2018)。近期,基于人工智能技术,上海交通大学也开发了在线的文献信息挖掘系统DeepShovel,用于支持深时数字地球(Deep-time Digital Earth,DDE)数据库的建设(Zhangetal.,2023)。DeepShovel以用户为中心,提供直观的界面协助用户进行文献管理、团队管理、信息挖掘和整理。为方便学科专家使用信息挖掘功能,DeepShovel自建了一个大型的PDF文献库进行解析和训练,挖掘出的数据被存储在后端数据库(图4b)。用户通过网页界面访问,可实现更为深入的信息挖掘,包括提取经过训练的含有关键语句、图、表、地图元素等信息。用户只需在界面上点击框选,系统就会反馈给后端,后端将实时处理结果传递到结果界面供用户核验,实现了交互式信息提取。
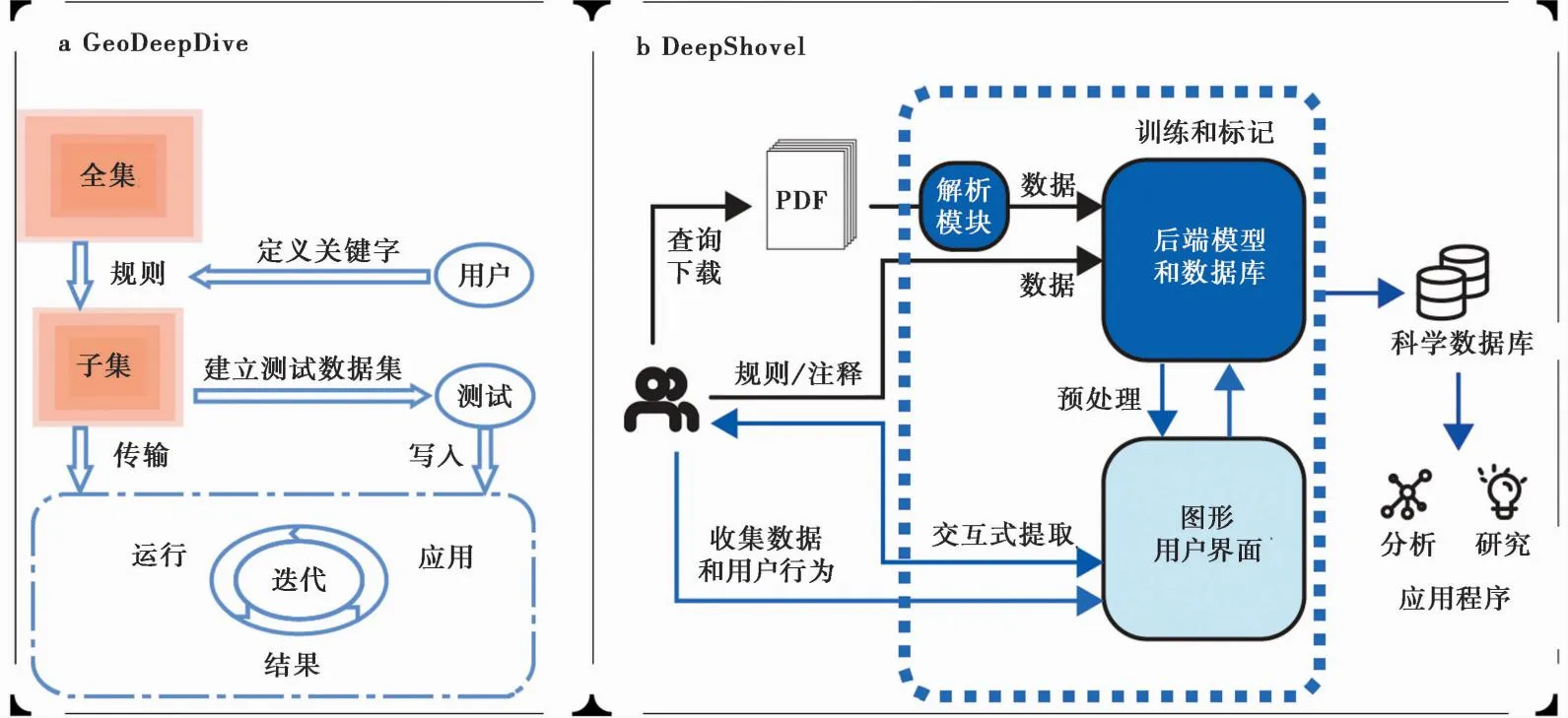
图4 GeoDeepDive(a)和DeepShovel(b)的工作流程示意图(据GeoDeepDive(10)http:∥eos.org/science-updates/a-new-tool-for-deep-down-data-mining/。和Zhang等(2023)修改)
4.1.2 开放共享的数据获取和更新模式
最近十余年,以预印本为代表的开放学术已逐渐成为一种新的数据传播形式。根据2002年布达佩斯会议提出的开放存取的行为定义和范围解释,在论文发表前首先公开预印本,可规避首发权争议,从而掌握科研交流的主动权(Christian,2008)。自1991年美国推出第1个预印本平台arXiv到2016年中国预印本服务器ChinaXiv启动,开放的预印本平台受到了越来越多学者的青睐,大量地球科学论文也选择在预印本平台首先发布。预印本大大缩短了从研究、实验到发表的周期,也便于数据库吸纳最新的研究数据,有望替代已发表的文献成为低温热年代学数据库重要的数据获取来源。
开放共享的学术生态也催生了开放共享的数据仓储平台,如Pangaea、Zenodo等。Pangaea(11)https:∥www.pangaea.de/。是开放存储的环境科学信息系统,数据来源于研究项目、机构和个人用户。如图5所示,Pangaea对上传的数据设定了比较严格的分析和检查流程,并对数据进行标准化,由数据审稿人作出审核、评价,最后对数据进行唯一编码(Diepenbroeketal.,2002)。开放的数据共享模式使得Pangaea拥有庞大的数据量和用户群,由此维持数据增长的良性循环。与Pangaea采用的模式不同,Zenodo(12)https:∥www.zenodo.org/。对数据的形式不设限制。Zenodo接受上传者授权的一切数据,将数据的质量交由上传者把控,且所有上传的数据都可以获得良好保护,因此近年来的数据增长非常快,是未来热年代学数据库重要的数据来源。

图5 Pangaea系统数据提取和入库工作流程
另外,在国际地质科学联盟(IUGS)的倡议下,中国科学家和13个国际组织、机构于2019年共同发起了深时数字地球(Deep-time Digital Earth,简称DDE)国际大科学计划,并在2022年正式上线了DDE一站式在线研究平台(13)https:∥deep-time.org/。。DDE联合了地质科学家、数据科学家和计算机科学家,提供了非常便捷的基于用户需求的数据提取和数据分析工具,极大地促进了数据的增长,同时为低温热年代学提供平台,以便进行数据的汇集和存放。
4.1.3 社交网络助力数据增长
20世纪以来,虚拟社交网络的流行改变了人们沟通和获取信息的方式,在带动学术交流和学术传播的同时,产生了专业的学术社交网络平台,如ResearchGate、Academia.edu等(Hailuetal.,2021)。学术社交网络具有一些共有的特点,包括用户的个人信息管理功能、用户间的学术跟踪和传播功能、学术影响的辅助衡量功能等(Noorden,2014),大大促进了学术交流和合作。例如,作为全球最大的学术社交网络平台之一,ResearchGate目前用户总量超过1000万,几乎遍布全球各个国家(Manca,2018; López-Hermosoetal.,2020)。由于平台打破了学术相关的等级制度,用户可自由联系同行、分享科研成果、了解研究动态并上传原始数据集。据不完全统计,通过ResearchGate分享的研究论文总计超过1亿篇(Jamali,2017)。由此可见,社交网络在协助低温热年代学数据增长方面拥有巨大潜力。
4.2 数据库的可扩展性
随着新的测试方法的不断涌现,传统的年代学数据库结构可能需要随时根据数据的类型做出调整。一些新的热年代学方法(如4He/3He技术)及实验方法(如裂变径迹的 LA-ICP-MS 定年方法、(U-Th)/He与U-Pb的双定年方法)的出现,将改变传统的数据结构,增加数据存储的复杂性。如何解决数据库的可扩展性,灵活应对不断变化的数据类型,也是新一代热年代学数据库面临的重要问题。
现有的年代学数据库大都采用关系型数据库,它是一种严格结构化的数据存储方式,其最典型的数据结构展现形式是二维表格,非常适用于逻辑性较强的地学数据(图6a)。如DateView数据库采用的Firebird、Petlab数据库采用的Oracle、NGDB数据库采用的Helix Express等,都是主流的关系型数据库软件。然而,在关系型数据库中,既定数据结构和字段的横向扩展困难,对非结构化的数据处理性能不尽如人意,因此难以适应那些采用新方法获得的新字段、新解释,以及非结构化的图片数据(Gleadowetal.,2019)。而非关系型数据库很好地填补了关系型数据库的不足。非关系型数据库并非为表,而是兼容结构化数据和非结构化数据存储需求的面向数据集的数据库(图6b)。在实际应用中可结合2种数据库的优势,实现对地学上基本信息和解释信息的全部收纳,达到New SQL(Pavloetal.,2016)的效果。
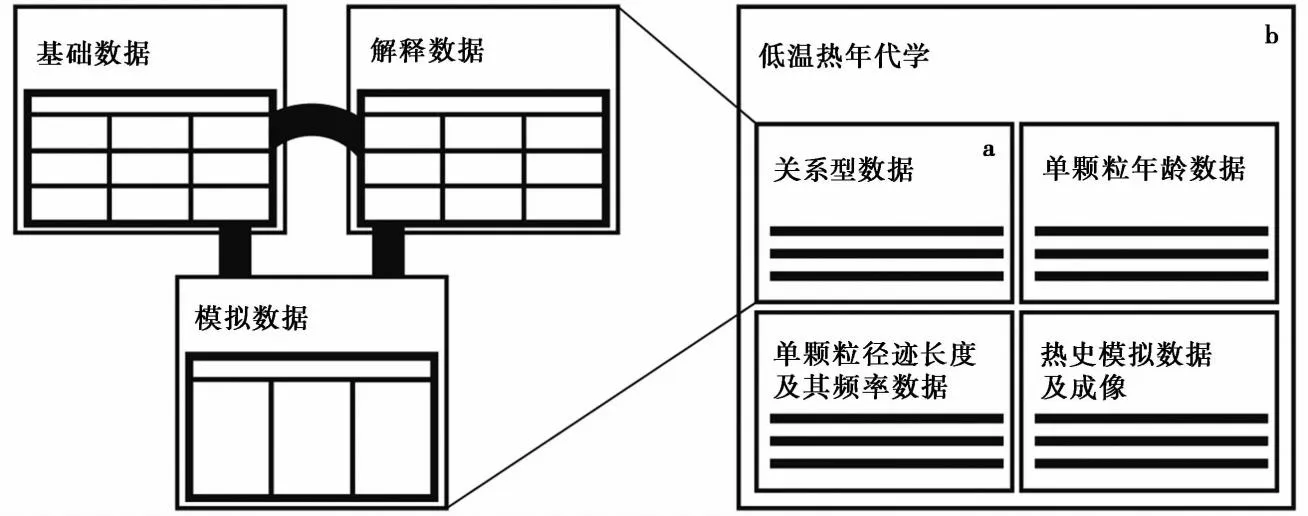
图6 关系型数据库(a)与非关系型数据库(b)的概念模型
此外,应用程序接口(API)的应用也可极大扩展和完善数据库的功能,它允许开发人员在不了解内部原理的情形下使用模块化的功能和操作,利于开发和维护,有效缩减开发成本(Zibranetal.,2011)。根据权威网站Programmableweb的统计显示,2010年数据库API的使用数量为2000,2022年已增加至超过24000个,其中数据统计分析、数据可视化API的应用非常广泛(Basole,2016)。在新型数据库中,AusGeochem、Sparrow等都提供了API接口,以便构建不同类型的数据分析和传播方式。
4.3 更为灵活的编号体系与更为全面的功能设计
为数据设置持久、唯一且通用的标识符是数据库设计的关键,这很大程度上决定了数据共享、链接和集成的能力(Klumpetal.,2017)。由于地质样品在实验、论文发表等过程中可能发生编号丢失或被重新命名,且部分样品的命名规则存在主观性,给样品元数据的跟踪、完善及学科间的互操作带来了很大困难。为了解决这一问题,IGSN(International Geo Sample Number)应运而生(Klumpetal.,2021)。IGSN为地质样品注册了唯一的编号,增强了数据系统之间的互操作性。然而,其对于未注册的样品或精细化程度更高的单颗粒数据的管理仍然力不从心。
AusGeochem与IGSN官方代理Lithodat合作,为平台提供了IGSN自动生成功能,这在一定程度上解决了未注册样品的编号问题,但单颗粒数据的管理仍然有待改善。Geochron数据库中记录了低温热年代学的单颗粒数据,其编码依赖于样品的原始命名。单颗粒数据随着数据可解释性的增加,其重要性越发明显。以裂变径迹为例,该方法测得的年龄与样品内各颗粒的径迹长度分布相关,且根据单颗粒的长度和年龄数据可以反演出该样品的热历史,目前已被大量应用于盆山演化、古地貌恢复。因此,单颗粒数据命名的规范化应当在原样品的基础上给出更灵活的考虑。
5 结论
当前,国内外低温热年代学数据库多以数据子集的形式附着存储在地质年代学数据库之中,其数据的表达、分析和解释受到了很大限制,亟需建设专门的低温热年代学数据库。通过对比分析不难发现,新一代低温热年学数据库需能够支持不同类型的数据来源、拥有更为灵活的数据存储模式,以及具备完善的数据分析和可视化功能。同时,作为应对低温热年代学数据爆发式增长的必要基础,如何保证数据库的持续增长、进一步提高数据库的可扩展性、建立灵活的数据编码体系,也是必须要解决的首要问题。在未来的低温热年代学建库工作中,需要融入开放学术的观念,借助先进的信息挖掘和传输技术,利用结构化与非结构化数据相结合的存储方式,以满足从实验室到科学家、再到数据用户的综合性需求。以此为理念,才能服务于新构造和地貌演化的研究需要,并有利于大数据的创新应用。
致谢本文成文过程中得到了李广伟老师的指导和帮助,在此表示衷心感谢!
猜你喜欢
真空与低温(2022年6期)2023-01-06
宁德师范学院学报(哲学社会科学版)(2022年1期)2022-07-11
南华大学学报(自然科学版)(2022年2期)2022-06-08
地质与资源(2021年1期)2021-05-22
现代塑料加工应用(2021年5期)2021-02-28
四川地质学报(2020年2期)2020-05-31
劳动保护(2018年8期)2018-09-12
东方考古(2018年0期)2018-08-28
云南地质(2015年3期)2015-12-08
发明与创新(2015年30期)2015-02-27
