
应用于扩容小样本量YOLO人脸数据集的imgaug图像增广方法
2024-01-15 05:44蔡艺军卓建明邹建航
厦门理工学院学报 2023年5期
尤 鑫,蔡艺军,林 云*,唐 凯,卓建明,邹建航
(1. 厦门理工学院光电与通信工程学院,福建 厦门 361024;2. 厦门唯识信息科技有限公司,福建 厦门 361024;3. 厦门蓝海环科仪器有限公司,福建 厦门 361024)
人脸识别能通过采集的单幅人脸图像或序列分析确定对象的身份信息和生物特征,它是一门基于概率论、优化技术、计算机视觉和深度学习的高度实用的分支学科[1]。随着目标检测和分类技术的不断发展,图像增强方法已经越来越广泛地应用到人脸识别上。近几年比较流行的算法可以分为两类:一类是基于图像区域划分的区域卷积神经网络(region-convolutional neural network,R-CNN)算法,它们首先通过选择性搜索来产生锚框标定区域,然后再做分类与回归,属于双阶段预测方法;另一类是单次预测算法,如单发多框检测器(single shot multiBox detector,SSD)、RetinaNet 都是直接使用一个卷积神经网络(convolutional neural networks,CNN)检验不同种类与方位的目标[2],二者的划分依据在于有无候选框的生成步骤。到目前为止,效果比较好的人脸识别算法基本上都是运用CNN 实现的。为了达到对二维输入的最佳处理结果,CNN被设计成深层前馈神经网络[3]。相比之下,基于YOLO 框架的图像检测技术识别更快,其主要原理是先把一整幅图像放置于实例中,然后预测框的边缘坐标及具体的类别概率,而当遇到光线遮挡等复杂多变的识别场景时,通过预先训练完成的YOLOv3和YOLOv5s网络模型来提取人脸特征,能够达到比传统CNN更好的人脸识别效果。
众所周知,许多深度学习的计算机视觉研究都需要大量的数据,因为大数据可以有效地防止过拟合。对此,文献[4]在几个公开的数据集上分别做镜像、对称变换,然后把生成的样本和原始数据融合起来以扩充训练容量,其错误识别率有所下降;文献[5]将随机噪声添加到训练样本中来增广训练数据;文献[6]基于3D人脸模型和单幅图片产生不同的神态,以及戴眼镜的人脸图像,对有限的训练样本进行扩充来增广数据。2019 年,Shorten 等[7]给出了更全面的数据增广,根据复杂度将常用的增广技术划分为基本图像处理和基于深度学习两种。虽然深度模型的过拟合问题得到了解决,但这些检测算法使用的人脸图像,普遍还是在亮度分布均匀、对象姿态单一、无特殊表情,以及规定图像分辨率的条件下采集的,所以识别系统才可以达到较高的识别精度。而实际场景中经常存在各种干扰且无约束因素,导致原始图像的摄影环境不受控,识别效果无疑会受到影响。除了上述问题外,所制作的训练数据集还会由于某类样本图像较少导致模型欠缺相应的先验知识,降低平均检测精度。因此,本文在训练过程中对图片采取像素级变换等数据增广操作,通过扩充测试集里部分类别缺乏的相关样本来提升总体的识别准确率。同时,为尽量还原真实情景,利用imgaug 库生成不同的增广图像,以调整图像亮度,丰富样本,增强YOLO系列网络模型的泛化能力。
1 数据增广方案
1.1 在线增广
YOLOv5的python训练文件自带了数据增广的选项,可以在原有的数据集上进行相关的增广操作。除此之外,Mosaic数据增广作为YOLOv5最大的创新点则是拼接随机缩放或者裁剪后的任意4张图片。
Cutmix增广方式、随机裁剪与填充类似,它可以看作是Cutout,仅裁剪图片不改变标签的局部融合思想和Mixup,混合标签的结合,该区域的一部分被剪切,但未填充 0 像素。即通过权重参数λ随机让2张图像Ii、Ij,以及它们的语义标签xi、xj执行加权的求和运算,产生另一张图像与标签[8],计算公式为
相反,Cutmix 随机填充训练集中其他标签像素值也有明显的优点,比如不包括信息的像素将不在训练的时候显示,因此效率也就得到了提升。向修剪区域添加其他样本的信息,提高了模型的目标位置,满足了模型从局部视图识别目标的要求,且Cutmix 处理的图像更符合人的视觉感受,模型分类的效果也得到了优化,而且训练和推理的复杂度并没有改变[9]。
以上的增广技术常常是嵌入通用文件夹底层代码的数据加载器内部,因此在训练每张图片的过程中都会做数据增广的操作。一般情况下,YOLOv5官方训练代码的数据增广方法是利用数据集进行反复多次的训练。由于每次数据增广都是随机的,因此与原先训练的数据集又有所区别,这样就相当于增加了数据集的样本数量,即在线增广,在线增广的效果示例如图1所示。本文的在线增广就是一边训练一边进行数据增广,本地保存的数据集文件不会发生改变。

图1 在线增广示例Fig.1 Online augmentation example
1.2 本地增广imgaug库
非在线数据增广就是对数据集进行增广并保存在本地,形成一个新的数据集,利用这个新数据集进行训练的同时,本地保存的数据也发生了改变。
imgaug是最实用的python图像增强库之一,常常被推荐用于深度学习领域内的分类问题,还有检测任务等多种要求的数据增强应用程序之中[10]。假设在基于深度学习应对实际的机器视觉工程项目的情景下,很多像人脸遮挡这样的问题是无法避免的。而各种现实环境又导致所制作的数据无法真实还原,所以数据增广操作非常有必要[11]。imgaug 库其实就是在人脸图像训练集中以提高特征识别的精度为前提,实现多尺度的图像变换等增广手段。该方法解决了数据样本不足时训练的网络模型泛化能力不足的问题,例如,通过仿射方法的rotate 参数让图像旋转-90°~90°区间范围内的随机角度。需要注意的是,当运用imgaug 自带的图像增广功能时,应该先传参生成某类含有增广数据的实例后,再通过它进行图像处理。其他的增广方法有水平翻转(Fliplr)、垂直翻转(Flipud)、取图片像素值的相反数(Invert)、从每个图像(Crop)裁剪0%~20%来产生增广图像,而且Crop 函数剪切图片后,默认会保持输入图像的尺寸不变,非原图区域用黑色填充。更改图像大小可以修改为Crop(…,keep_size=False)的形式;实现裁剪并设置填充模式为“边缘”,形如CropAndPad(percent= (-0.2,0.2),pad_mode="edge")能够达到先删除图像任意20%的区域,然后在边界填充图形到原先大小的目标,还有更改并调整空间饱和度(AddToHueAndSaturation)等。原始训练样本和不同增广方法生成的图像见图2。

图2 原始训练样本及相应的增广图像Fig.2 Original training samples and corresponding augmented images
除此之外,为适应不断变化的外部条件,往往需要同时使用多种图像增广技术搭配实际的深度学习模型来进行训练。在此情形下,可以使用imgaug 中符合keras 和Pytorch 框架中的Sequential 方法,将不同的增广器组合到一个管道中,然后将它们全部应用到单个增广调用中,以实现多种增广技术拼接在一起的功能,详细调用形式为iaa.Sequential([ … ])。假如要使用每项增广方法并随机排序,将random_order 设置成True 即可。SomeOf 子项增广器和生成增广序列的Sequential 方法同样可以组合使用多图像增广方法,但只能选用不超过子项中所用增广方法总数的其中几种。
处理边界框最常见的方法是计算交并比(intersection over union,IoU),相交处区域可以使用imgaug 提供的BoundingBox.intersection(other_bounding_box)方法进行估算,然后返回另一个边框。如果遇到需要把一个图像的边界框映射到其他图像的情况时,可以通过调用BoundingBox. project(from_shape,to_shape)和BoundingBoxesImage. on(new_image)。如果必须补偿填充,应使用Boundingbox. shift([top]、[right]、[bottom]、[left])或相同的BoundingBoxesImage 方法,同时更新.shape属性对应填充后生成的图像。
2 网络模型结构和数据集
2.1 网络模型
相较于早期版本的YOLO 算法,2018年改进之后的YOLOv3训练出了更加庞杂的网络模型。但其推理速度更快,识别更为准确,并且当以COCO数据集进行测试时,各类别平均检测精度的均值能达到57.9%[12]。对比不同网络模型结构的mAP 值(表1)可以得出,与大多数的ResNet-101 系列网络相比,Darknet-53更精确。
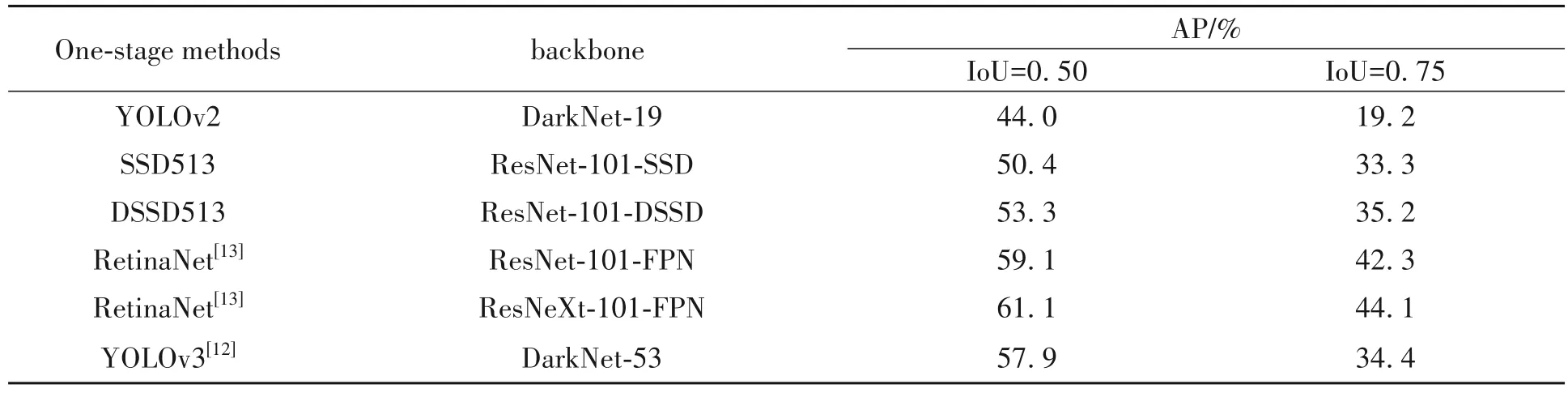
表1 不同网络模型结构的mAP值对比表Table 1 mAP values for network model structures compared
YOLOv3 在IoU=0.50 的情况下具有不错的识别结果,但随着交并比的增大,性能出现显著下滑,说明YOLOv3 在检测框回归的准确性问题上还有进一步提高的空间,其主干网络结构如图3所示。
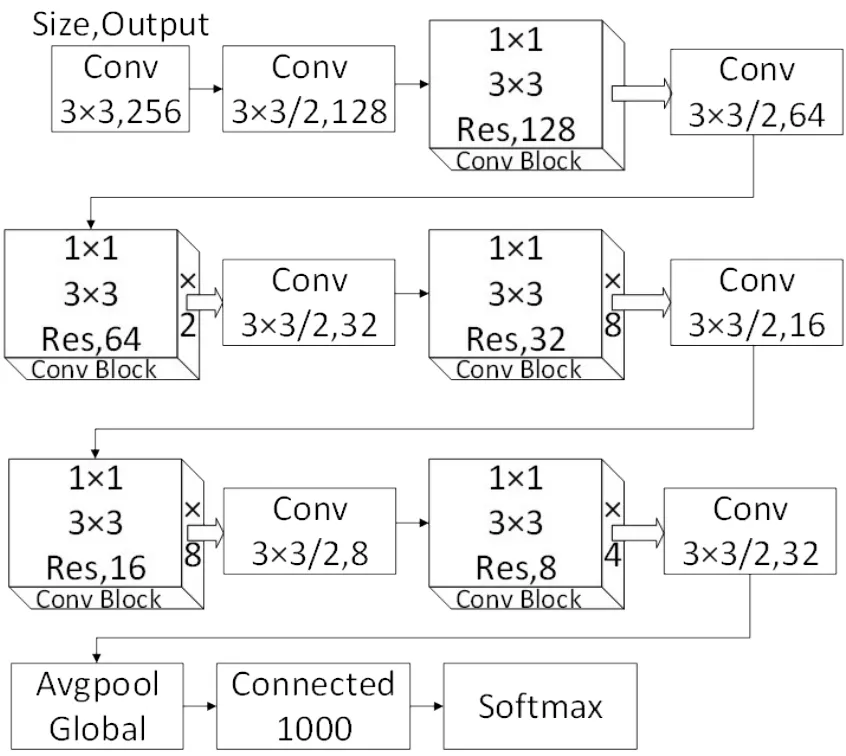
图3 DarkNet-53架构Fig.3 Architecture of DarkNet-53
YOLOv3 训练图像样本通常需要调用特定的程序算出锚框的初始坐标,而YOLOv5 对此做了改进,把这个过程写进了主函数代码里,并在每个单独的训练epoch 中自动计算出不同数据集所属最佳锚框的值[14]。
2.2 数据集的训练和预测
本文的原始数据是从互联网爬取的面部图片,利用fer2013 表情数据集和YALE 人脸数据库训练得到的模型进行预测,筛选出符合不同表情、不同角度与光照条件即正确率较高的部分图像制作成训练集。数据包含了18 类国内外知名人士共350 张图像,而验证集源自CelebA 分类完成后对应训练集所选人士的180张图像。图4为原始数据的部分图像。

图4 训练数据集部分图像Fig.4 Some images of the training dataset
只有训练数据集的图像丰富多样,才能保证识别或认证更有实际意义。为了有更大的几率使样本包含真实情形中的图片,并在测试集内扩充容量不足的那些类别,因此,选择节1.2中的imgaug本地增广方式所生成的旋转和裁剪图像、镜像和色彩反相图像、删除并填充和饱和度转换图像扩展源数据集,以研究图像增广方式在训练过程中对模型识别准确率的提升性能。增广后的数据容量由原来的350 张面部图片扩大了5 倍,然后将图像按9∶1 的比例分成了训练集和验证集[15]。图像增广的流程图如图5所示。
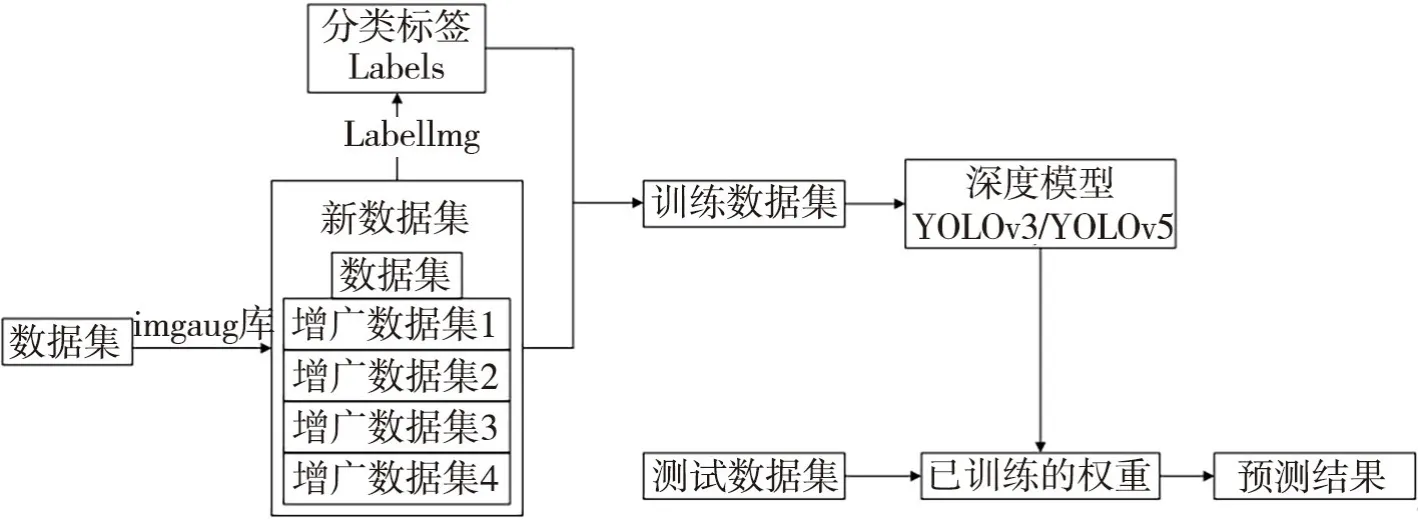
图5 图像增广流程图Fig.5 Flowchart of image augmentation
3 实验结果与分析
在之前提出的增广理论的基础上,为检验其实现预期的效果,首先通过已预训练的YOLOv3网络模型对人脸特征进行提取,测试时再根据标签的置信度分析具体所属类别,以达到识别人脸身份的目标。分别选取不同结构的特征提取主干网络,在训练过程中随机地对样本图片进行数据增广处理,总共训练了100轮epoch后再开始预测。
3.1 实验环境
实验部署于Xshell 终端模拟器,由Pycharm 专业版通过添加远程SSH 解释器环境运行,操作系统为ubuntu18.04;极链AI云平台提供算力供网络训练使用。
3.2 实验设计
验证阶段分别设计了多组对照实验,采用的网络模型是YOLOv3和YOLOv5s,然后在不同增广技术处理下的小样本数据集中对它们开始训练。实验组的设置分为两类:一类是边训练边随机生成增广图像,另一类是不使用图像增广。为了防止其他因素对测试效果产生影响,除了设置不同的增广方法和网络模型之外[16],具体参数也都大部分保持一致,如训练集所采用的训练batchsize 都是8,训练epoch数都是100轮次。
3.3 不同增广方式对识别精度的提升效果
在YOLOv3 的Pytorch 版本中,本文利用imgaug 图像增广库的Invert 和Fliplr 方式将源数据增广成新的数据集。在IoU=0.5 的情形下,图像增广前后模型的预测准确性与效果见图6。由图6 可见,利用imgaug数据增广库可以明显提高YOLOv3检测人脸的准确性。
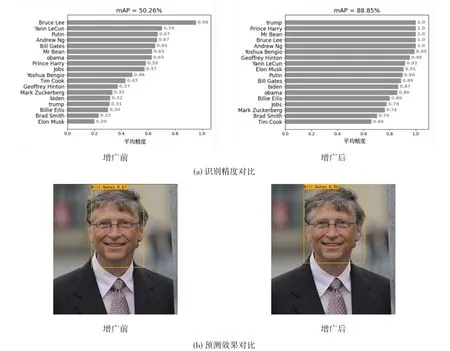
图6 基于YOLOv3的增广效果对比实验结果Fig.6 Experimental results of augmentation effect based on YOLOv3 conpared
在YOLOv5的网络框架下,源数据也通过imgaug库组合使用几种图像增广方法将数据集的样本容量扩充了5倍。图7给出了模型在增广前后测试集上 IoU=0.5和IoU=0.5~0.95的准确率及预测效果。
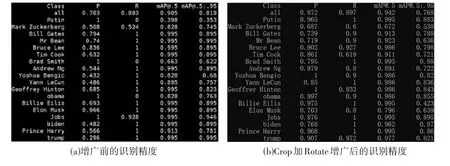
图7 基于YOLOv5的增广效果对比实验结果Fig.7 Experimental results of augmentation effect based on YOLOv5 compared
由实验组的4 幅图可知,在imgaug 数据增广库的作用下,CropAndPad 组合AddToHueAnd Saturation 技术在性能改进方面比其他增广技术更显著。但因为局部裁剪导致人脸部分有所损失,Crop加Rotate这种组合增广方法可能识别不出人脸身份,因此性能并不理想。
3.4 结果分析
不同增广方式下,YOLO 系列网络平均精度的实验结果如表2 所示。由表2 可见,根据图像增广方案的不同,YOLO 系列网络的预测精度都有不同程度的提高。由于训练时的在线随机增广处理并不能有效增强网络模型的泛化能力,因此,组合使用imgaug 库的多种本地增广方式,可以在不过多增加计算复杂度的基础上较好地优化识别准确率。

表2 不同增广方式下YOLO网络平均精度Table 2 Average Precision of YOLO network under different augmentation methods
4 结论
本文针对小样本数据集神经网络模型可能出现训练不足的问题,通过imgaug 图像增广库来增加样本容量,使所训练的网络模型的泛化能力得以提高,由增广的对照实验结果可见,效果比较理想。其中,对于很深的YOLOv3主干特征提取网络,其平均检测精度提高了38%左右;对于多种结构复杂的YOLOv5网络模型,其效果也很明显。可见,imgaug库普遍适用于小规模数据样本训练过程中的神经网络。另外,与其他增广方式相比,采用CropAndPad 和AddToHueAndSaturation 的组合增广方式,能表现出更好的效果,提升了约0.5%。
猜你喜欢
黑龙江大学自然科学学报(2022年4期)2022-11-17
少儿美术·书法版(2021年9期)2021-10-20
中学生数理化·高一版(2021年2期)2021-03-19
作文小学中年级(2020年6期)2020-07-24
动漫星空(2018年9期)2018-10-26
知识经济·中国直销(2018年8期)2018-08-23
数学学习与研究(2017年3期)2017-03-09
中国老区建设(2016年1期)2016-02-28
发明与创新(2015年33期)2015-02-27
奇闻怪事(2014年5期)2014-05-13
