
基于改进YOLOX算法的给水管道内缺陷智能识别与定位
2024-01-15 00:44苏常旺胡少伟张海丰潘福渠单常喜
测绘通报 2023年12期
苏常旺,胡少伟,张海丰,潘福渠,单常喜
(1. 重庆大学土木工程学院,重庆 400045; 2. 郑州大学水利与土木工程学院,河南 郑州 450001;3. 山东龙泉管道工程股份有限公司,江苏 常州 277599; 4. 山东东信塑胶科技有限公司,山东 聊城 252000)
给水地下管道作为城市基础设施建设的重要内容之一,其安全运行直接影响着百姓民生。然而,近年来,给水管道因为自然灾害或人为因素导致的如漏损、堵塞乃至地面塌陷等各类事故层出不穷,后续需要大量管道修复或替换工作,造成国家严重经济损失,同时还存在潜在的环境影响[1]。因此,对给水管道进行实时高效的内部病害检测是十分必要的。
针对给排水管道内检测技术,国内外采用较多也最先进的是CCTV技术,即内窥式管道机器人检测技术[2]。在此基础上,国内对传统的管道机器人进行了不断的更新改造工作,研发了更多适用于有水环境下的新型管道机器人。然而,不论是传统的CCTV技术,还是各类新型管道机器人,通常均采用人工对管道内部图像进行判读的方式,费时费力,且容易产生主观误判。基于此,国内外学者针对给排水管道内缺陷对自动化检测展开了深入研究,且主要集中于排水管道,对于给水管道缺陷识别研究很少。早期一般采用图像用技分割及特征提取处理技术[3],如今,随着计算机视觉领域的快速发展,其中最火热的卷积神经网络(CNN)[4]成为学者进行管道缺陷智能分类的常用技术。而对于管道内缺陷检测定位,通常采用R-CNN或Fast R-CNN等技术[5-8]。但这些算法虽然识别精度较高,但操作复杂,识别速度不够快[9],难以满足实时检测的需求。因此,本文基于新型管道机器人在给水管道工程中的检测视频,采用识别速度更快、精度较高的YOLOX[10]算法模型展开研究,提出一种更加高效精准的分类与定位方法,为给水管道内部缺陷识别定位提供技术支撑。
1 YOLOX算法简介及其改进
1.1 目标检测算法发展及YOLOX算法简介
在计算机视觉领域,早期的研究通常集中在图像分类上,卷积神经网络(CNN)就是其中的佼佼者。自2012年,图像目标检测成为学者们的研究重点[11],如图1所示。而YOLO算法[12]作为用于目标检测的神经网络算法之一,其特点在于处理速度快。以前的方法,如R-CNN及其变种,属于Two-Stage类算法,即需要分步完成图像识别与定位,虽然精度很高但必须设计多个神经网络来执行任务,通常运行缓慢,也很难优化,因为每个单独的组件都必须单独训练。而YOLO算法只需要设计一个神经网络,训练简单。

图1 目标检测算法发展历程
YOLOX算法作为YOLO算法的新变种,其摆脱了先验框约束(即anchor free,传统YOLO算法会采用K-means聚类等方法确定几种固定尺寸的先验框,利用这些先验框作预测,其缺点在于泛化能力差,计算量较大);同时创新性地以解耦预测头(decoupled head)代替传统的预测头(coupled head),其原因在于目标检测时往往会包含分类(classification)与回归(regression)两类损失(loss)的计算,两者如果放在一起进行运算,可能会产生冲突从而影响预测精度,因此在YOLOX中又将两者分开,解耦头示意如图2所示。YOLOX主体网络结构可分为4个部分:①输入端;②网络骨架(Backbone),此部分与传统的YOLOV3[13]算法结构基本相同;③颈端(Neck)部分,主要用于图像特征融合,采用FPN[14](特征金字塔)策略,形成3种不同尺寸的特征图像,其目的在于可同时满足预测大中小目标的要求;④预测端(Prediction),主要包含解耦头结构及最后的预测部分。基于管道缺陷识别建立的YOLOX主体结构如图3所示。
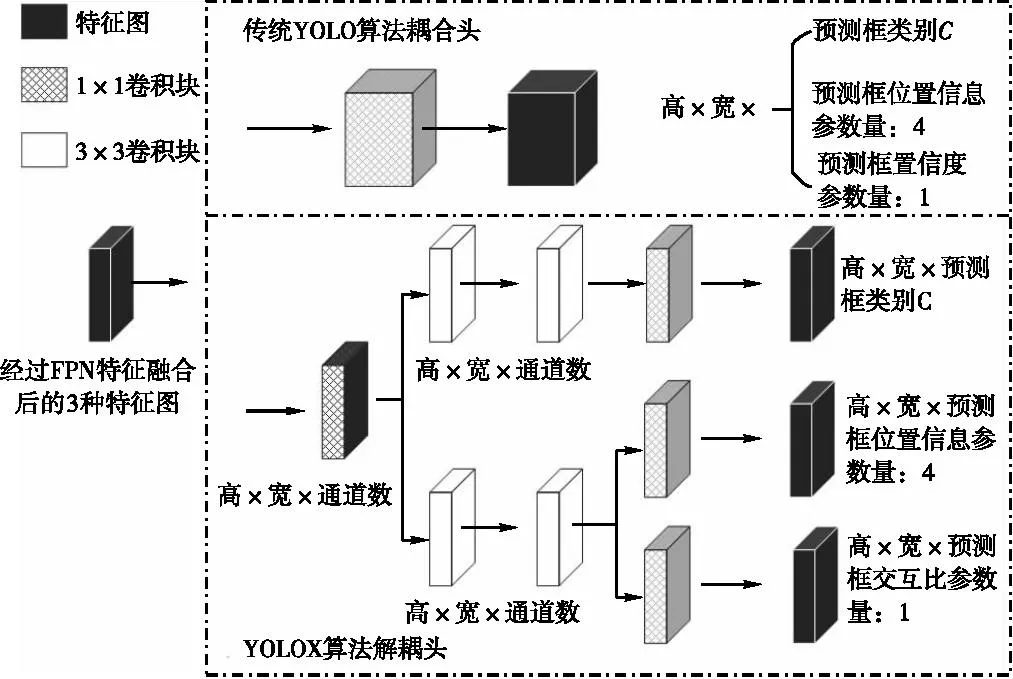
图2 YOLOX解耦头
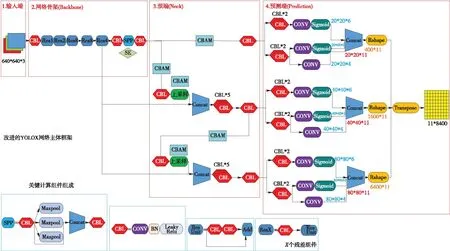
图3 基于增加注意力机制的管道缺陷识别的YOLOX网络框架
1.2 基于增加注意力机制后的改进YOLOX算法
1.2.1 注意力机制的基本原理
注意力机制[15](attention mechanism)源自自然语言处理(NLP)中的Transformer模型。其原理类似于人类眼睛关注事物的机理,当人们集中注意力时,往往可以抓住事物整体中最重要的部分。延伸至深度学习领域,可以理解为一种通过扫描全局、调整关键参数,获取重点领域信息的方法。通过引入注意力机制,可有效解决深度学习模型因参数量过多、信息量大而无法重点关注模型训练关键点的问题。随着研究的深入,其应用已不仅仅局限于NLP领域,在其他深度学习领域也开始逐渐得到应用,并取得了不错的效果。注意力函数的基本计算公式具体如下
(1)

1.2.2 在YOLOX算法中引入注意力机制
注意力机制为一个即插即用的网络模块,理论上可以放在网络结构的任意部分,本文为了避免改变网络主干部分(Backbone)而导致结果变化过大的问题,选择提高特征加强提取部分的效率,因而考虑在颈端(Neck)部分加入通道混合注意力机制(CABM),即在上下采样操作环节加入该网络模块,具体网络结构如图3所示。
2 YOLOX算法简介及其改进
2.1 平台搭建与数据集构建
本文采用的深度学习框架为Pytorch 1.8.0,CPU为AMD R7 4800 h,GPU配置为NVIDIA GeForce GTX 3060,数据集源自适用于水下环境的管道机器人采集的实际工程视频,对视频中的图像进行抽帧,提取图像并利用几何变换、颜色变换、Mosaic、Mixup技术扩增使数据集数量达到7940张。其中,Mosaic增强技术原理在于选取4张图片进行随机裁剪与拼接,从而获得一张新的图像;而Mixup增强技术原理是将两种不同类图像进行混合杂糅所形成的一张整体图像。两种技术的展示效果如图4所示。

图4 两种数据增强技术在本数据集中的应用
根据工程专家鉴定情况,将缺陷划分为6类:泄漏点、泥沙堆积、石块堆积、气囊、其他杂物、正常管道,如图5所示。训练集、验证集与测试集比例均为8∶1∶1,具体数据集划分见表1。为了进一步提高训练质量,本文还采用了迁移学习策略,即利用类似数据集对网络结构进行预训练后再用新的数据集进行正式训练。

表1 数据集划分

图5 管道缺陷样本展示
2.2 模型训练与预测
在完成平台搭建、整理并得到给水管道内缺陷数据集,以及完成预训练工作后,正式开始模型训练,训练次数根据计算平台实际情况确定为300次,共包含15 000次迭代。模型具体训练流程如下:
(1)输入端输入标注好的训练集,经过骨架层,对图像进行一系列卷积、归一化、激活、合并(concat)操作,得到不同大小尺寸的图像。
(2)选取3种尺寸的图像(分别为80×80、40×40、20×20),进入颈端,主要对3种图片进行特征融合,采取策略为FPN(特征金字塔),主要包括卷积、归一化、激活、合并、上采样、下采样操作,从而进一步得到用于3种满足大、中、小目标检测的特征图像。
(3)对3种特征图像利用解耦头进行解耦,以便于进行分类与回归的损失(loss)函数计算。其中,YOLOX模型的损失函数主要由3部分组成,公式为
(2)
式中,Lcls为分类损失;Lreg为定位损失;Lobj为置信度损失;λ为定位损失的平衡系数,默认设置为5.0;Npos为被分为正样的锚点数。
对于Lcls和Lobj,采用的都是二值交叉熵损失函数(BCELoss),具体计算公式为
(x,y)=L={l1,l2,…,lN}·
(3)
ln=-wn[yn·logxn+(1-yn)·log(1-xn)]
(4)
式中,ln为预测该样本第n个类别的损失;wn为该样本对应第n个类别的权重参数;yn为对应第n个真实类别的值,一般为0或1;xn为对应第n个类别的预测值。
对于Lreg采用的是IoULoss,即预测框与真实框的重合面积与总和面积的比值,公式为
(5)
式中,A为预测框的面积;B为真实框的面积。在完成损失训练后,得到最小损失下的网络权重,将初始权重修改为最小损失下的权重,即可进行预测。
3 预测结果与对比分析
完成训练后,对训练结果进行处理并展开预测。在整个训练过程中,损失函数随训练次数增加而稳定下降。当验证损失值不再下降时,即可判断为收敛,其训练与验证损失值分别由最开始的9.13、7.71最终下降到2.67、2.83,具体如图6所示。
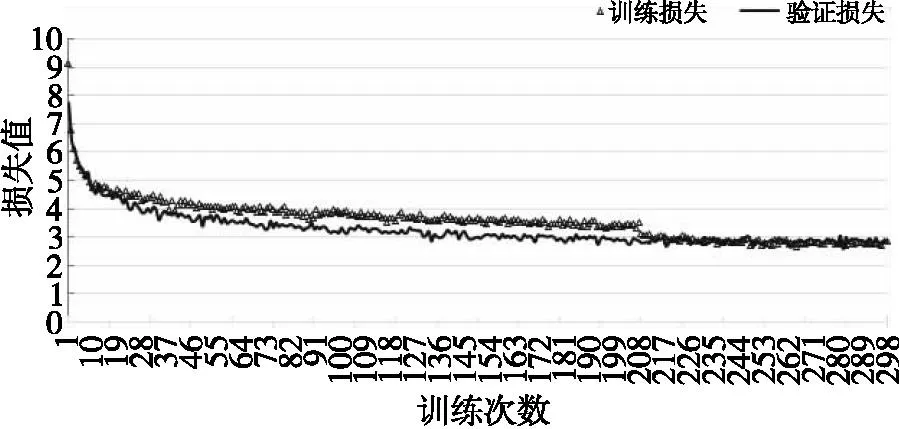
图6 训练及验证损失下降
部分测试集预测结果如图7所示,图片中标注部分主要由缺陷类别和预测置信度组成。结果表明,该模型预测整体效果良好,整体平均识别精度为94%,其中,预测准确度最高的为石块堆积缺陷,达到了98%,最低的泄漏点缺陷预测准确度也达到了89%,具体如图8所示。产生精度差异的原因主要由两部分组成: ①石块堆积缺陷图像整体更加清晰,噪点少; ②石块堆积图像数据集数量更多,对于模型训练而言,往往数据集越多,训练后达到的效果也越好。

图7 数据集预测结果效果

图8 管道内缺陷预测精度矩阵
为进一步验证改进的YOLOX算法的优越性,将此数据集分别利用传统卷积神经网络(Fast R-CNN)算法及YOLOv3算法进行训练预测并作对比,其对比评价指标主要包括平均精度(AP)与识别速度。其中,AP为召回率与准确率曲线所包含的下方面积,而均值平均精度(mAP)为所有类别的AP和除以类别数C,具体见表2。可知, YOLOX无论是mAP还是平均识别速度均超过YOLOV3,而Fast R-CNN虽然mAP略高于YOLOX模型,但平均识别速度远不如YOLOX,因此,综合来看,YOLOX在3种算法识别模型中表现最好。
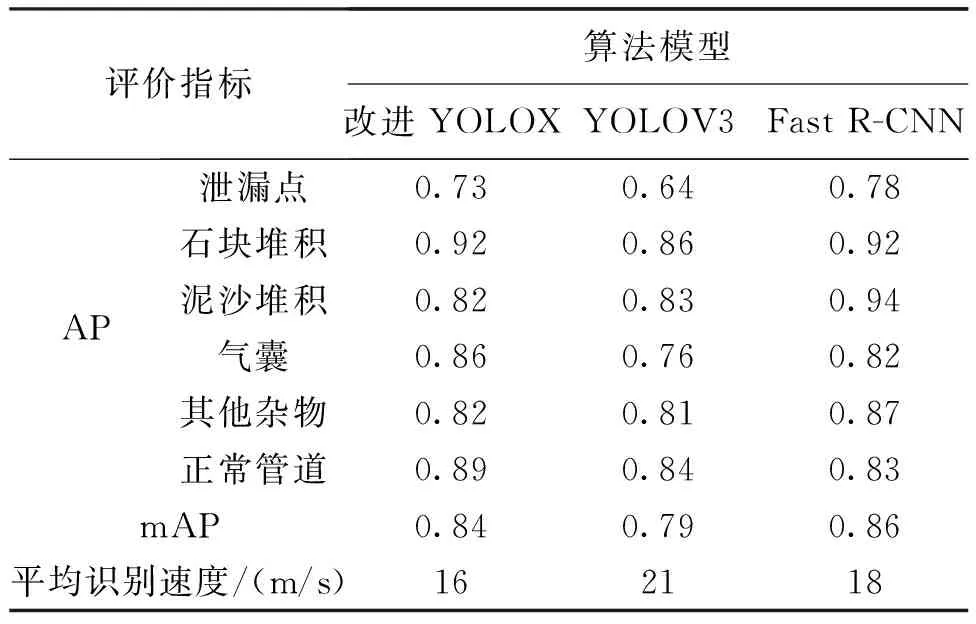
表2 3种算法模型的mAP值与识别速度对比
4 结 语
本文基于实际工程中的给水管道内检测视频,通过增加注意力机制,建立了基于改进YOLOX算法的给水管道内缺陷智能识别与定位模型,达到快速识别定位管道缺陷的效果。结果表明,改进YOLOX算法模型相较于传统的目标检测模型,具有较高的精度和更快的识别速度,其mAP达到了0.84,平均识别速度相较于前代YOLOv3模型及Fast R-CNN模型分别提升了31%和138%,综合性能超过了其他两种对比的目标检测模型。同时,该算法模型适用于视频实时检测,可以进一步应用到实际工程中,从而达到替代人工检测,高效、精确地识别定位管道内缺陷的目的。
尽管如此,本文建立的算法模型还有进一步发展空间: ①数据集的质量与数量有待提升,以进一步提升模型的训练效果和泛化能力; ②进一步优化相关训练参数,如学习率、权重值等,以提高训练效率。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
数学小灵通·3-4年级(2021年5期)2021-07-16
建筑与预算(2020年4期)2020-06-05
今日农业(2019年15期)2019-01-03
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
中国塑料(2016年8期)2016-06-27
现代工业经济和信息化(2016年1期)2016-05-17
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
