
基于近红外光谱技术的多酚类物质异常样本识别方法研究*
2024-01-13 08:09王桂瑶李少鹏郭建华宋纪真
南方农机 2024年2期
王桂瑶 ,李少鹏 ,詹 映 ,田 震 ,郭建华 ,宋纪真
(1.中国烟草总公司郑州烟草研究院,河南 郑州 450000;2.江苏中烟工业有限责任公司,江苏 南京 210000;3.上海创和亿电子科技发展有限公司,上海 200092)
0 引言
在近红外定量模型建立过程中一个重要环节就是异常样本剔除,这些异常样本值不仅会误导近红外变量的选择,而且会在建模过程中,给模型的参数选择带来误判,造成最后模型的稳定性降低、精度误差变大。在实际近红外模型构建过程中,有很多情况会引起近红外样本的异常,一种是测定的标准值误差较大,通过残差分析,可以很容易剔出来。另一种异常值,也可以叫做强影响点,其所对应的光谱没有代表性,偏离模型整体的平均光谱较大,建模过程中所表现出的残差值不大,可是杠杆值很大[1-9]。
引起样本异常的原因可以分为5 类。一类是基础数据产生的异常样本,即当基础数据操作失误,或者样本混淆的时候,化学值与样本所对应的近红外光谱不一致所产生的异常样本。一类是自身被检测物质引起的异常样本,批次、等级、部位、年份之间的差异导致建立的模型与将要检测的样本光谱有差异,这部分异常样本需要在模型维护的时候考虑[10-15]。一类是内外界环境造成的异常光谱样本,主要有近红外仪器背景变化产生的影响,或者扫到了非烟物质,或是检测环境的变化,如样本的温度、湿度。一类是工艺参数的改变引起的异常光谱样本,近红外光谱受外界环境影响比较大,如改变某些工艺参数,导致近红外仪器检测条件发生变化,比如真空回潮等参数会改变烟叶物质中所含有的水分,这个时候外界的湿度因素就会发生变化,产生异常光谱。一类是仪器自身的不稳定引起的异常样本,如仪器的硬件粗糙所引起的问题,近红外仪器老化以及更换近红外仪器零部件带来的光谱差异性等[16-20]。这些不同原因造成的异常点,如果建模时不进行剔除,不仅模型检测的数据精度不高,结果不可靠,而且需要频繁地对模型进行维护,造成人力、物力、财力的损失。
1 材料与方法
1.1 实验材料
采用不同产地、等级的初烤烟叶样品167 个,所有样品在60 ℃的电热烘箱中烘干30 min,经过粉碎后过60目筛子。
主要设备:Antaris Ⅱ型实验室近红外光谱仪(美国赛默飞世尔科技);FED240 电热烘箱(德国Binder);旋转式烟叶粉碎机。
1.2 测定方法
1.2.1 光谱测定
实验室光谱采集采用Antaris Ⅱ型实验室近红外光谱仪(美国赛默飞世尔科技),以仪器内部空气为背景,测量范围3 799 cm-1~10 001 cm-1,采样点数为1 609点,每张光谱扫描次数为64次,分辨率为8 cm-1。
1.2.2化学值测定
所有的烟叶化学值测定都经过去梗、剪碎,在40℃下烘焙4 h,粉碎,过60 目筛,制备好的样品取10 g,将样品粉末混合均匀装入样品杯中,Antaris Ⅱ型实验室近红外光谱仪采用旋转的方式进行漫反射检测。样品测量过程中环境温湿度基本保持一致。
测定方法为液相色谱法,具体方法参照YC/T 202—2006《烟草及烟草制品 多酚类化合物 绿原酸、莨菪亭和芸香苷的测定》。
1.2.3 建立校正模型
用实验室近红外光谱仪采集所有样品的光谱,并进行编号标记,用液相色谱法测量对应样品化学值,将光谱与化学值按编号一一对应。将光谱进行预处理、波段选择、异常样本剔除后用偏最小二乘法(PLS)进行建模,根据建模的平均绝对误差、平均相对误差、相关系数(R)和均方差(RMSEC)四个指标来评价异常样本剔除的不同方法,确定最佳异常样本剔除方法。
2 结果与分析
2.1 PCA马氏距离法
马氏距离的计算公式如下:
其中,ɡi、ɡj分别为第i个和第j个样本的光谱行向量。P-1为类G协方差矩阵的逆矩阵,即:
样本ɡi与某一类G之间的马氏距离为:
其中,¯ɡ为G的平均光谱;GI为G均值中心化后的光谱阵。
在实际计算时,通常用PCA 的得分T代替光谱数据G,这时:
也可以写成:
其中,c为主因子数,t¯j为类G的第j个主成分得分的平均值;tij为样本ɡi的第j个主成分得分,λj为矩阵(GITGI)的第j个特征值。
计算异常光谱样本存在的阈值范围:
其中,ε为调整阈值范围的权重系数分别为AB的平均值和标准差。ABi- ̄AB值越小,则样本i与平均光谱在主成分空间中就越相似。当ABi˃ ̄AB+εσB时,认为样本i为异常光谱样本。因此,可以设置不同的权重系数ε来调节异常样本的阈值范围。运用马氏距离法剔除异常化学值样本,剔除样本10个,如图1所示。
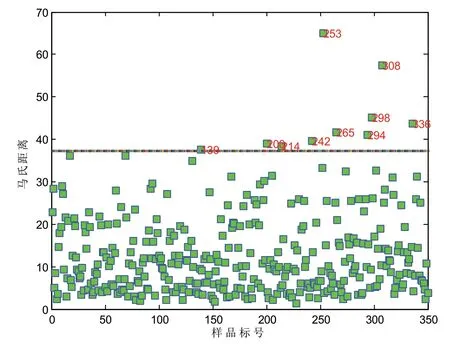
图1 马氏距离法剔除异常样本图
2.2 半数重采样法
基于对原始光谱的随机半数重采样统计出现奇异长度的样本。从原始光谱矩阵中随机选择部分(一般选择总样本数的一半)样本作为采样子集,计算每个采样子集矩阵的均值和方差,再根据均值和方差计算采样子集中每个样本的向量长度(向量长度计算公式与数据标准化公式相同)。对光谱数据进行多次随机采样,并记录每次采样后计算的向量长度。对样本的向量长度进行排序,距离最大的一定概率(如5%或10%)的样本得分为1,其余为0。最后对各样本的总得分进行统计,得分最高的部分样本就为奇异样本。采用半数重采样法剔除了18个异常样本,如图2所示。
图2 半数重采样法剔除异常样本图
2.3 蒙特卡洛偏最小二乘交叉检验法
基于蒙特卡洛交叉验证(MCCV)的一类奇异样本识别方法。利用MCCV 随机划分校正集与预测集,如果奇异样本在校正集中,整个模型的质量将受到影响;相反,如果奇异样本在预测集中,仅此样本的预测结果受到影响。尽管这种情况对预测结果都有影响,但效果明显不同。本文就利用奇异样本出现在校正集或预测集时模型预测误差的差异,通过MCCV及统计分析来进行奇异样本的识别。根据预测集中奇异样本的预测残差会明显大于正常样本的预测残差,提出了一种基于MCCV 的奇异样本识别方法。基于MCCV 的奇异样本识别方法充分利用统计学的性质,能够在一定程度上降低由掩蔽效应带来的风险,检出光谱阵和性质阵方向的奇异点,有望在奇异样本检测中得到更广泛的应用。
算法具体步骤:1)用PLS 确定最佳主成分数;2)用蒙特卡洛随机取样法取90%的样本作为校正集建立PLS 回归模型,剩余部分作预测集;3)循环1 000 次,得到各样本的一组预测残差;4)求各样本预测残差的均值与方差,并作图;5)若样本偏离主体,则从校正集中剔除。采用蒙特卡洛偏最小二乘交叉检验法剔除的18个异常样本,如图3所示。

图3 蒙特卡洛偏最小二乘交叉检验法剔除异常样本图
2.4 采用不同异常样本剔除方法建立PLS模型对比
表1 是采用不同异常样本剔除方法剔除异常样本,建立PLS 模型得到的验证集验证结果。从表中可以得出:采用蒙特卡洛偏最小二乘交叉检验法剔除异常样本建立的PLS模型预测性和稳定性最好。

表1 不同异常样本剔除方法剔除异常样本后所建模型结果对比表
3 结论
在建立多酚类物质咖啡奎尼酸定量模型前,应首先剔除异常样本,这些异常样本可能含有光谱异常值、异常化学组分或者浓度较为极端,与其他样本存在显著差异。如果这些异常值参与建模,必然会降低近红外光谱检测分析结果的准确性和可靠性,因此需要将这些异常样本进行剔除。采用蒙特卡洛偏最小二乘交叉检验法剔除异常样本较其他方法效果更佳。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
北京航空航天大学学报(2020年10期)2020-11-14
小哥白尼(趣味科学)(2020年6期)2020-05-22
自动化学报(2019年6期)2019-07-23
临床医药文献杂志(电子版)(2017年11期)2017-05-17
统计与决策(2017年2期)2017-03-20
通信电源技术(2016年1期)2016-04-16
深圳职业技术学院学报(2015年5期)2015-11-30
河南科技(2015年8期)2015-03-11
湖南师范大学自然科学学报(2013年5期)2013-03-11
