
近底探测型仿生UUV 小目标物视觉识别检测系统
2024-01-13 12:17:30陈栢仲王崇磊郭春雨
水下无人系统学报 2023年6期
陈栢仲,王崇磊,郭春雨
(哈尔滨工程大学 青岛创新发展中心,山东 青岛,266000)
0 引言
仿生无人水下航行器(unmanned undersea vehicle,UUV)以鱼类的外形结构进行设计,模拟海洋鱼类的游动方式进行推进,具有高速、灵活且低噪等特点[1-2],能够快速适应复杂极端的水下环境并自主开展各项水下作业。当其搭载摄像头进行水下拍摄以及目标检测识别任务时,相较于传统的螺旋桨式推进UUV,具备如下优势: 1) 仿生UUV进行海洋生物样本检测工作时,其具备的仿生结构和仿生推进特性,使其运动规律与周围生物相同,能够完美地融入到海洋生物当中,在不惊扰周围鱼类的情况下,可有效动态跟踪拍摄鱼群等水下生物;2) 由于其仿生学结构推进特性,仿生UUV在灵活航行的同时产生噪声较低,有利于海岸巡逻等军事任务的顺利实施;3) 仿生UUV 具有较强的稳定性与抗干扰性,可有效减少传统螺旋桨推进过程中产生的过度抖动问题,使拍摄更加清晰。
近年来,随着深度学习的快速发展,众多学者也开展了大量基于神经网络训练的水下目标识别技术研究。贺帆等[3]利用YOLO 进行水下河蟹的目标识别检测。万鹏等[4]使用改进的ResNet50模型对淡水鱼种类进行识别。Pan 等[5]改进MResNet 对水下目标尤其是小目标物进行实时检测,提高了水下目标检测的精准度。Jeon 等[6]使用三维计算机辅助设计(computer aided design,CAD)模型制作数据集,进行基于深度学习的水下物体检测和姿态估计,并为水下环境中的深度学习模型提供了新的观点。
文中在上述研究的基础上提出一种近底探测型仿生UUV 水下目标识别方法。针对水下4 种小目标贝类贴底探测任务,对水下图像预处理与Resnet 图像分类检测算法展开深入研究,结合仿生UUV 自身运动控制规律,进行图像采集、预测分析、结果验证和对比分析,试验结果证明文中方法能够很好地完成近水底小目标物探测任务。
1 仿生UUV 水下视觉系统
1.1 水下成像与增稳系统
水下成像系统分为硬件装备和软件两部分,硬件部分主要用于水下图像采集与信号传输,常用采集设备包括水下电荷耦合器件(charge coupled device,CCD)摄像头、云台、辅助照明灯和计算机。计算机作为陆地上位机可以完成视觉图像建模、水下环境监测和信号传输反馈的工作,通常会配备总线路图像采集卡,用于水下摄像机图像采集和图像数据处理[7]。
软件部分用于进行图像处理,主要由2 部分组成: 1) 图像处理部分,该部分包括图像预处理、图像分割、关键帧提取以及图像增强,通过以上处理步骤形成初步的图像数据库以获取水下环境信息,是图像处理最为关键的一步,可为水下环境感知、目标检测识别以及目标物距离计算提供初步信息判断;2) 图像高级处理部分,该部分的主要手段为机器学习和深度学习,最为常见的处理方法为分类和识别,当输出变量为有限相互独立图像时为分类手段,输出变量标签数量多时为标注识别手段,通过上一步骤提供的原始数据集进行机器学习或深度学习训练得到新的模型,可以有效判断水下目标物。
UUV 在水下会受到水下湍流波动、波流耦合和机身抖动带来的影响,使其拍摄具有不稳定性,因此对采集系统的稳定性控制操作有很高要求。常见的视觉增稳方法包括硬件增稳和软件增稳2 大类。
硬件增稳方法是指根据UUV 的运动规律选择合适的拍摄硬件,以减少水下波动和机身振动带来的影响,其中最常见的方法就是搭建云台系统。Sagara 等[8]针对水下目标的测量追踪问题,设计了一种适用于双目视觉的4 自由度云台;江明明等[9]设计了一款水下增稳视觉采集装置,具有体积小、结构简单且安装方便等特性。针对仿生机器鱼的视觉抖动问题,不同于螺旋桨式UUV,其具有明显的周期性特征。为此,Yang[10]和Zhang[11]等先后提出了单自由度与2 自由度的云台伺服系统,用于减缓机器鱼的节律性运动所带来的视觉抖动问题。梅家宁[12]进行了基于视频帧频运动矢量的UUV 光视觉图像的稳像方法研究。
文中提出的方法针对特定的仿生UUV 进行了硬件与软件方面的优化。硬件方面固定摄像头在前端初始相位处,能够保证摄像头视频信息随UUV 周期性运动,减少横摇带来的抖动,软件方面以波动周期为参考条件合理选择关键帧。这种设计能够实现在实时近水底目标检测时减少视觉动态模糊并提高识别的准确率,为后续的运动决策提供准确度输入。
1.2 图像预处理
水下成像环境十分特殊,会使获取的图像存在对比度降低、图像失真且噪点多等问题,因此对水下光学图像进行图像预处理十分必要[13]。采用低通滤波技术能够有效消除水粒子散射,并通过基于互熵的模糊增强技术增强对比度。常见的滤波手段有高斯滤波、双边滤波、中值滤波和均值滤波等。
以高斯滤波为例,如图1 和图2 所示,其考虑了像素离滤波器中心距离的影响,以高斯滤波器中心位置为高斯分布均值,通过滤波器在整幅图像上滚动对图像像素值进行加权平均[14],可有效去除高斯噪声,高斯滤波的数学表达式为
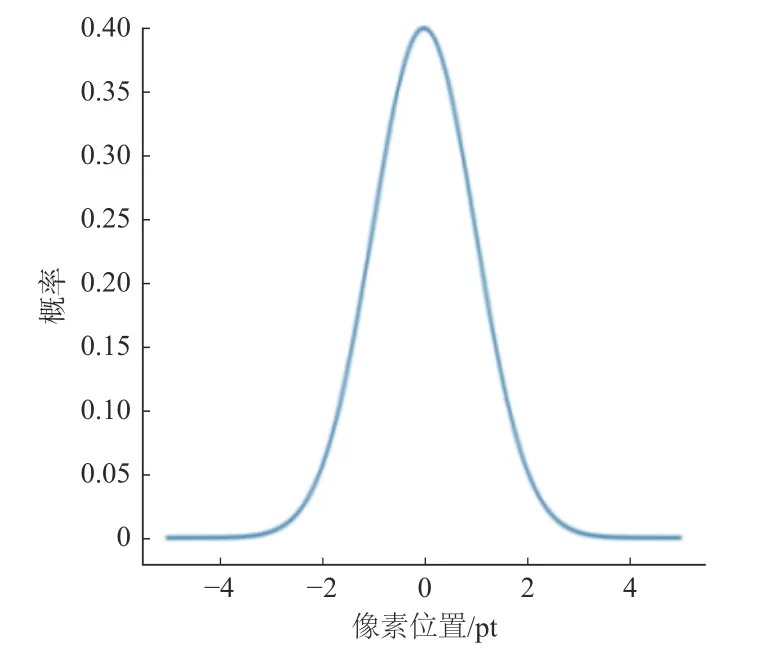
图1 一维高斯滤波模型Fig.1 One-dimensional Gaussian filter model
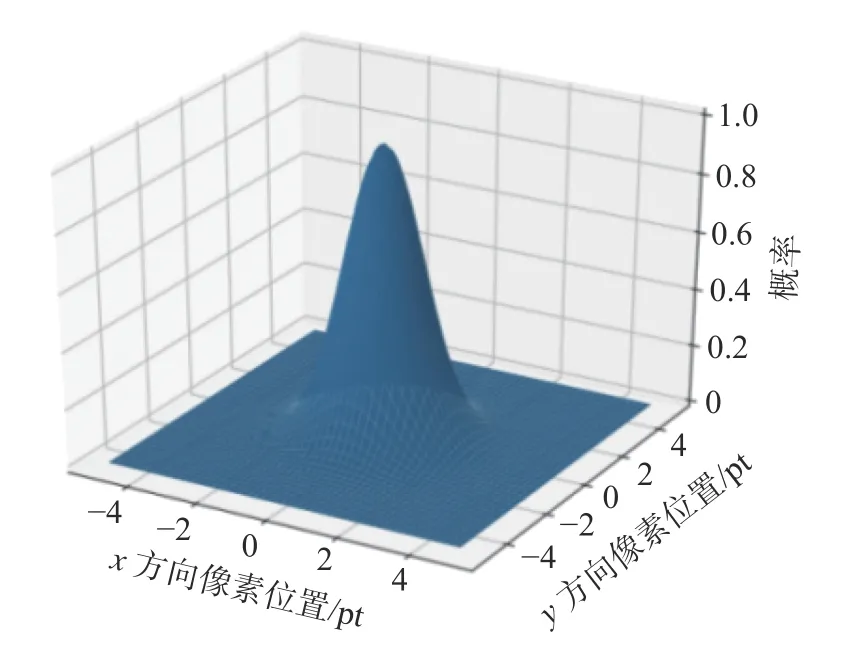
图2 二维高斯滤波模型Fig.2 Two-dimensional Gaussian filter model
式中:x2和y2分别为邻域内其他像素与邻域内中心像素的距离;σ代表的是标准差;G(x,y)为分布;I(x,y)为亮度。
滤波后的图像相较于原图像来说,虽然像素点被滤波器加权平均使图像变得模糊,但却能有效降低噪声因素对图像检测的干扰。
同时由于光照不均与光线衰减的问题,水下图像会出现图像亮度不均和灰度值跳跃等问题,常见的方法是灰度映射,其中Gamma 函数矫正被广泛使用,Gamma 矫正(幂律变换)是一种重要的非线性变换,调整后的像素值表达式为
式中:i为原始像素值;γ为控制对比度的参数。γ值越大,图像对比度越低;γ值越小,图像对比度越高。一般情况下,当γ>1 时,图像的高光部分被压缩而暗调部分被扩展;当γ<1 时,图像的高光部分被扩展,而暗调部分被压缩,从而达到亮度矫正的目的。
1.3 Canny 边缘检测
Canny 边缘检测是从不同视觉对象中提取有用结构信息,并极大程度减少数据处理量的技术,已广泛应用于各种计算机视觉系统。Canny 边缘检测的具体流程[15]如下:
1) 采用高斯滤波器进行高斯平滑处理,具体操作如1.2 节中所示;
2) 采用1 阶偏导的有限差分方法计算梯度的大小和方向等矢量;
3) 采用非极大值抑制梯度大小;
4) 利用双阈值的算法进行检测,同时采取边缘连接。
Canny 处理结果如图3 所示。

图3 Canny 处理结果Fig.3 Processing results of Canny
1.4 Resnet 分类神经网络
深度学习算法在图像识别分类等领域有着十分突出的优越性,但由于神经网络深度的不断增加,会出现梯度消失、退化等问题,导致模型难以训练,错误率增加。包含残差结构的网络模型能够在很大程度上避免出现此种问题[5],同时可以极大地加深网络,文中选择具有残差结构的ResNet34模型,如图4 所示。经过实验测试分析,该网络结构具有较强的训练效果,预测准确性也较高。
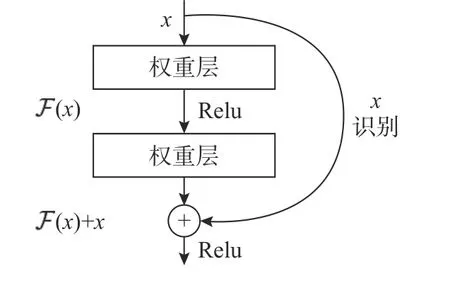
图4 ResNet 模型的残差块结构Fig.4 Residual block structure of ResNet model
2 方法研究
文中提出方法流程如图5 所示。首先由仿生UUV 进行水下实时拍摄,并根据其运动规律进行周期性关键帧提取;然后UUV 将信息传递给上位机端,上位机采用传统方法进行图像的预处理,使水下图像能够实时进行色彩增强与噪声去除,并传入优化后的Resnet 网络中进行目标分类预测;最后对纹理信息检测输出与目标分类结果进行对比分析。

图5 文中所提方法流程图Fig.5 Flow chart of the proposed method
2.1 关键帧提取模块设计
仿生UUV 在水下进行视频拍摄与数据收集的主要存储方式为上层人工智能(artificial intelligence,AI)控制板,存储空间有限。文中使用的摄像设备拍摄视频的大小为40 MB/min,过多的内存占用不但会影响仿生UUV 控制程序的运行速度,同时记录的水下信息也有限,因此进行关键帧提取保存设计十分必要。
仿生UUV 的波动鳍采用周期性波动泵喷耦合推进方式,相比于传统的螺旋桨推进方式减少了拍摄时抖动的问题,能够获取更加清晰的视频图像,但其波动与悬停过程中仍然会产生动态模糊图像,如图6 所示,因此文中提出的关键帧提取方法将建立在仿生波动推进UUV 的水动力学建模控制基础上。胸鳍波动建模中每个舵机单波形见图7。

图6 UUV 拍摄视频帧Fig.6 Video frames shot by UUV

图7 每个舵机的单波形图Fig.7 Primary wave motion of each steering engine
如图7 所示,由于摄像头的位置位于头部,因此将以最靠前的2 个舵机的运动周期规律限制关键帧提取,其中波形图初始位置为舵机平衡位置,提取模块以运动波峰、波谷和平衡位置为参照点,每2 s 提取1 次图像关键帧,并输出保存第10~14帧图像。
2.2 预处理模块设计
对采集的图像选取关键帧与关键区域,进行高斯滤波降噪和Gamma 亮度调整图像预处理。选取高斯滤波核大小为3×3,步长为1,见图8(a)~(c)。对处理后的图像进行图像分割与Canny 边缘检测实验,根据实际测试该水池环境下的Canny上下阈值分别为50 和150,通过初步判别可以获得较好的目标判断与纹理信息(见图8(d))。由于该仿生UUV 的摄像头置于上方,在水下拍摄时会导致图像的直观视图发生倾斜,为此通过调整拍摄距离,以展现更直观的视图,见图8(e)~(f)。

图8 水下图像预处理Fig.8 Underwater image preprocessing
其中经过矫正后的图片将被输入到Resnet 网络中,边缘检测结果将作为目标物细节判断结果输出,如图9 所示。

图9 浑浊水下图像边缘检测Fig.9 Image edge detection in turbid water
2.3 Resnet 网络优化设计
为对水下小目标物进行分类,对Resnet 网络进行了一系列的优化设计,优化方案和优势特点如下:
1) 将第1 层卷积由单层的7×7 卷积核改为双层3×3,以增加网络对小目标物细节点的分析与特征提取能力;
2) 下采样池化层改为卷积层,以便在一定程度上加快网络的训练速度;
3) 残差模块增加注意力机制,通过权重矩阵,从通道域的角度赋予图像不同位置以不同的权重,从而得到重要的特征信息;
4) 激活函数使用leakRelu,系数参数设置为0.2,使输入为负也能进行权重更新;
5) 残差块个数由[3,4,6,3]变为[2,2,4,3],防止网络训练产生欠拟合现象。
3 实验与数据准备
实验中,训练图像识别方法的核心步骤是采用更改过的ResNet 网络,选用Pytorch 框架进行网络搭建,网络环境为Windows10、cuda11.0、cudnn11.0、英伟达GEFORCE RTX 3050(GPU)、python3.8、VS2017、OpenCV4.1.0,摄像头搭载UUV 为仿生波动式推进水下航行器,摄像机和云台位于UUV 上部,如图10 所示。数据集拍摄位置为实验室3 m直径圆形水池,如图11 所示。

图10 仿生UUVFig.10 Bionic UUV

图11 3 m 直径圆形水池Fig.11 Circular pool with a diameter of 3 m
首先利用仿生UUV 在水池中收集了4 种相似贝类的数据集,包括白蛤蜊300 张、花蛤蜊300 张、扇贝300 张和蛏子300 张,模拟真实泥沙浑浊的水下环境(如图12 所示)。数据集按照训练集∶验证集=7∶3 的比例进行分类。

图12 水下贝类数据集Fig.12 Data set of underwater shellfish
4 实验结果分析
4.1 训练结果
对数据集进行了100 个迭代代数(epoch)的训练,学习率为0.000 1,批大小(batchsize)为16,训练的结果如图13 所示,训练的验证准确率最终趋近于1,且损失函数呈现不断下降的趋势,整体训练结果良好。

图13 训练的损失与验证准确率Fig.13 Training losses and validation accuracy
4.2 预测结果
使用UUV 水下再次拍摄获取未被处理过的图像,使用Resnet34、VGG、Alexnet、Googlenet 和Resnet50 进行训练,并使用相同的90 组验证数据集进行测试,部分预测结果如图14 所示。文中提出的方法最终平均准确率为89.6%,相比上述网络准确率分别增长了6.6%、6%、13.07%、17.2%和19.3%,具有最高的准确性与良好的鲁棒性,准确率对比如图15 所示。

图14 部分预测结果(单位: mm)Fig.14 Partial prediction results(Unit: mm)
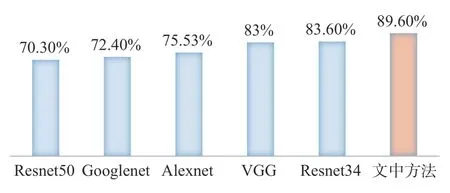
图15 准确率对比图Fig.15 Comparison of accuracy
5 结束语
文中提出一种近底探测型仿生UUV 小目标物视觉识别检测系统研究方法,通过结合UUV 自身运动特性对硬件和软件进行了设计。文中提出的关键帧采集与软件模型优化使实时目标检测结果达到89.6%,可为进一步的决策提供有效输入,对于未来进一步海底近距离小目标物探测提供了技术支持。近水底目标探测如图16~图17 所示。

图16 贴水底目标拍摄Fig.16 Shooting of target on the sea floor

图17 水下预伏拍摄Fig.17 Underwater preloading shooting
但同时仿生UUV 在水下探测的过程中也存在一些问题,例如由于摄像头云台安置在仿生UUV的头部,对于水下的部分区域会造成视觉盲区,会造成机体腹部以下区域图像信息丢失,针对上述问题仍需深入研究。
猜你喜欢
数学小灵通(1-2年级)(2024年4期)2024-05-14 09:30:52
小学生学习指导(低年级)(2019年6期)2019-07-22 03:33:10
大连理工大学学报(2017年4期)2017-08-07 07:03:20
重庆交通大学学报(自然科学版)(2016年1期)2016-05-25 00:37:00
西北工业大学学报(2015年3期)2015-12-14 13:08:46
空间控制技术与应用(2015年3期)2015-06-05 14:30:31
遥测遥控(2015年2期)2015-04-23 08:15:18
四川师范大学学报(自然科学版)(2015年2期)2015-02-28 14:07:36
文艺生活·中旬刊(2014年12期)2015-01-06 03:03:56
电子设计工程(2014年20期)2014-02-27 12:01:00
