
基于多源数据聚合的神经网络侧信道攻击
2024-01-12 06:54张润莲潘兆轩李金林武小年韦永壮
计算机研究与发展 2024年1期
张润莲 潘兆轩 李金林 武小年 韦永壮
(密码学与信息安全重点实验室(桂林电子科技大学) 广西桂林 541004)
(zhangrl@guet.edu.cn)
侧信道攻击通过对密码算法在设备实际运行过程中泄露的物理信息(如时间信息、能量信息、电磁信息)进行采集和分析,从而恢复密钥信息[1]. 侧信道攻击实用性强且破坏性大,严重威胁着密码设备的安全,是近年来密码分析的一个研究热点. 随着密码设备功能的完善以及新防护手段的应用,传统侧信道攻击的效率和成功率越来越低. 为提高侧信道攻击的效率和成功率,深度学习被引入侧信道攻击.
深度学习具有学习能力强、覆盖范围广、适应性好等优点. 基于密码设备运行过程中采集的数据,深度学习可以在一定程度上学习和提取密码算法在设备中进行数据加密时的特征信息,实现对密码算法的密钥恢复[2-4]. 2016 年,Maghrebi 等人[5]将深度学习用于AES(advanced encryption standard)算法在无掩码和有掩码情况下的攻击,证明基于深度学习的侧信道攻击具有更好的攻击效果. 2017 年,Cagli 等人[6]基于卷积神经网络实现在不需要对能量迹对齐和精确特征点提取的情况下的攻击. 2020 年,Benadjila 等人[7]提出基于ASCAD 数据集的最优神经网络模型,并通过实验证明神经网络模型的攻击效果优于被优化的模板攻击;Wang 等人[8]提出基于联邦学习的侧信道攻击,使用9 个同型号的不同设备采集数据进行联合训练,并成功完成攻击;Perin 等人[9]分析了基于深度学习的侧信道分析模型的泛化能力并以集成技术增强模型的攻击能力. 2021 年,Won 等人[10]提出将1 维数据的原始能量迹的测量值转化为具有数据位置信息的2 维数据,改进了基于深度学习的侧信道分析;Zaid 等人[11]则为了减少深度学习衡量指标与侧信道评估指标的差异,提出一种排名损失函数并论证了成功攻击所需的能量迹上界.
基于深度学习的侧信道分析,目前普遍的方法是针对采集的能量迹,基于每个密钥字节对应的泄露数据建模,再恢复该密钥字节. 例如,针对AES-128 算法,基于深度学习的侧信道分析将128 b 密钥以每组8 b 划分为16 个密钥字节,为了恢复16 个正确密钥需要分别对每个密钥字节建模再进行恢复[12].深度学习高度依赖数据,数据量越大,其学习效果越好. 因此,为提高攻击的准确率,上述方式需要采集大量数据且单独训练16 个模型,效率较低. 而对侧信道攻击来说,数据采集由于外部因素的限制,攻击者可能无法采集到足够的数据,而数据不足会严重影响神经网络的训练效果. 如何在数据采集要求无法被满足的情况下,提高深度学习侧信道攻击的效率和准确率,成为开展深度学习侧信道攻击的关键. 针对该问题,数据增强技术被使用. 2020 年,王恺等人[12]通过对原始功耗曲线增加抖动和高斯噪声实现数据增强,并将增强后的数据用于残差网络训练实现密钥恢复;同年,Wang 等人[13]将条件生成对抗网络(conditional generative adversarial network,CGAN)用于侧信道领域,通过条件生成对抗网络生成新的数据集进行训练数据集的扩充,从而提高能量迹不足情况下的攻击效率. 2021 年,Luo 等人[14]和Karim 等人[15]运用Mixup技术[16]生成能量迹,增加模型攻击效果.然而,数据增强方法需要先训练网络生成所需能量迹,增加了侧信道攻击中数据训练的复杂性.
针对上述问题,提出一种基于多源数据聚合的神经网络侧信道攻击方法,以AES-128 算法为攻击对象,先基于16 个密钥字节的泄露数据训练16 个模型,并分别实现对相应16 个密钥字节的恢复;进一步以每个模型分别恢复其他的密钥字节,了解每个模型在特征学习过程中的泛化效果;针对每个模型对所有密钥字节的攻击效果打分并排序,筛选出对所有密钥字节攻击效果好的模型所对应的泄露数据,构建和训练一个基于多密钥字节泄露数据的多源数据聚合模型,再恢复所有的密钥字节. 实验结果表明,该方法在较少能量迹情况下不需要数据增强处理也能够提高侧信道攻击的准确率,降低了模型训练的开销,减少了成功恢复密钥所需要的能量迹数量.
1 MLP 神经网络简介
多层感知器(multi-layer perceptron, MLP)是一种由多个感知器单元组成的神经网络,包括输入层、输出层和1 个或多个隐藏层,每一层包含1 个或多个感知器单元,每一层的所有感知器与下一层的所有感知器进行全连接,MLP 的结构如图1 所示.

Fig.1 The structure of MLP图1 MLP 结构
MLP 网络模型的核心思想是通过前向传播得到误差,再把误差通过反向传播实现权重的修正,最终得到最优模型. 在反向传播过程中通常使用随机梯度下降法对权重值进行修正,梯度下降法的原理是计算损失函数关于所有内部变量的梯度,并进行反向传播.
2 多源数据聚合模型
目前采用神经网络针对AES 算法的侧信道分析,主要利用采集的能量迹分别为每一个密钥字节在第1 轮S 盒处的泄露点进行建模,再恢复该密钥字节,如对AES-128 算法需要建立和训练16 个模型. 这种方法需要采集大量的数据进行训练,能量迹采集和训练开销大、效率低;若采集的能量迹不足,会导致模型的准确率低. 针对上述问题,提出基于多源数据聚合的模型构建方法,针对AES-128 算法筛选出对各个密钥字节攻击效果较好的数据集建立多源数据聚合模型,再进行密钥恢复.
2.1 基于单密钥字节的泄露数据集建模
在AES-128 算法加密过程中,16 个密钥字节加密明文的操作是一个时序操作,所有的泄露都在采集的一条能量迹中. 在整个时序中,由于每个密钥字节在加密不同明文时所泄露的能量信息具有相同特征,因此在采用深度学习方法进行侧信道分析时,通常是对单个密钥字节的泄露数据建模,在攻击阶段根据训练结果恢复出对应字节的密钥.
在传统侧信道攻击中,通常使用能量消耗模型模拟真实情况下泄露的能量消耗. 能量消耗模型有不同的精度级别,一般而言,精度越高的模型攻击效果越好,但所需要的资源也越多. 汉明重量模型是攻击者刻画总线与寄存器能量消耗常用的能量消耗模型,它的基本原理是假设能量消耗与寄存器中存储数据比特1 的数目成正比. 而密码设备S 盒置换的非线性操作在寄存器中引发的能量变化较为突出,因此主要针对S 盒的输出通过能量消耗模型寻找相关特征.
能量迹的特征依赖于密钥与明文,理论上针对单密钥字节所建立的模型并以其恢复对应密钥字节的效果是最佳的. 模型的建立需要先对采用的数据集进行数据处理,即完成数据标签. 数据的标签实际上是将每条能量迹的特征通过能量消耗模型重新刻画,即将每条能量迹的分类类别由明文和密钥转化为标签值函数计算后的标签值. 假设一条能量迹中某S 盒泄露点x的明文数据为p,该单密钥字节为k,假设采用汉明重量函数HW( )计算,则标签值z计算方法为
对于其他能量迹,同样在该泄露位置x计算对应的标签值z,完成对所有能量迹在泄露点x的标签. 采用同样的方法,继续针对所有能量迹的其他泄露点完成数据标签. 以所有能量迹在某个泄露点标签后的数据,训练建立一个单密钥字节模型,并以该模型恢复该泄露点对应的密钥字节.
AES-128 算法中,使用了16 个S 盒,但这16 个S盒的真值表是相同的. 这使得基于这16 个S 盒进行运算后的数据间可能存在一定的关联性,即所采集的能量迹不同泄露点的数据可能会表现出相似的特征. 对能量迹的标签计算,也会将这些相似特征表现出来,即在对这些能量迹进行标签时,通过标签值函数f(p,k)标签,不同泄露点的标签结果也可能会被归于同一类. 基于这种特征,以某个泄露点训练的模型,若能够有效恢复出其他泄露点对应的密钥字节,则可以有效降低能量迹采集和模型训练的开销.
为评估以某个泄露点训练的模型恢复其他泄露点对应密钥字节,针对AES-128 算法,先采集算法运行时的能量迹,再将其划分为16 个密钥字节的泄露数据集,进行数据标签处理,以这16 个密钥字节的数据集分别训练出16 个模型. 进一步地,利用这16个模型,先分别恢复该泄露数据集对应的密钥字节,再分别去恢复其他密钥字节.
采用Benadjila 等人[7]于2020 年对ASCAD 数据集提出的MLP-best 模型建立MLP 神经网络模型,MLP 模型一共有6 层,第1 层为输入层,其是大小为96 的1 维向量,输入层神经元数对应单个密钥字节在S 盒操作处的96 个能量采样点数据. 中间4 层为隐藏层,每层隐藏层都有200 个神经元;为了在快速收敛的同时避免梯度消失并提高网络的精度,激活函数采用RELU 函数. 最后一层是输出层,其大小与实验选择的能量消耗模型有关. ASCAD 公开数据集只提供第3 个S 盒处的泄露数据,本文方法需分析AES 算法的16 个S 盒的所有泄露数据,在此选用提供了全部字节泄露的DPAContest_V4 数据集. MLPbest 在ASCAD 数据集上有局部最优效果,但并不适用于采用RSM(rotating S-box masking)掩码方案[17]的DPAContest_V4 数据集[18]. 针对DPAContest_V4 数据集,构造新的标签值函数计算标签值:
将标签值f′(p,k)作为不同明文对应能量迹的标签值时,根据AES 的S 盒输入异或输出共163 种异或结果,因此输出层设置为163 个神经元,对应163种不同标签值的分类结果. 为提高分类的准确率,输出层的激活函数选择适用于多分类场景下的Softmax 函数,以将输出映射为各个类别的分类概率.
基于上述建立的模型,利用AES-128 算法16 个密钥字节的标签好的数据集训练出16 个模型,分别命名为Mi(i=1,2,…,16). 为区分不同密钥字节的标签数据集,以Sj(j=1,2,…,16)表示依据S 盒操作顺序并完成标签的数据集. DPAContest_V4 数据集中每个数据集Sj分别有10 000 条能量迹,从中随机抽取8 000条作为训练集训练神经网络模型Mi,剩下的2 000 条作为测试集用以恢复对应密钥字节. 为保证效果一致,在每个模型训练过程中统一设置相关参数:训练的epoch=300,batchsize=100,学习率设为0.000 01,优化器使用RMSprop,使用交叉熵损失函数.
基于上述建立的16 个模型,利用相应的测试集数据分别去恢复16 个密钥字节,各个模型恢复对应密钥字节所用的最少能量迹数如表1 所示.
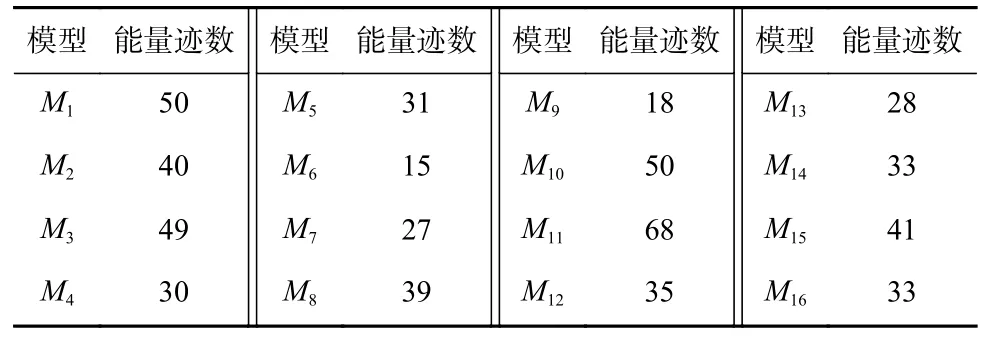
Table 1 Minimum Number of Traces for Sixteen Models Recovering the Corresponding Key Byte表1 16 个模型恢复对应密钥字节的最少能量迹数
进一步地,为评估以某个泄露点训练的模型是否能够恢复其他泄露点对应密钥字节,基于同样的实验环境,利用这16 个模型中的每一个模型,分别以每个密钥字节对应的测试集数据去恢复相应的密钥字节,各模型完成对各密钥字节恢复的最少能量迹数如表2 所示.
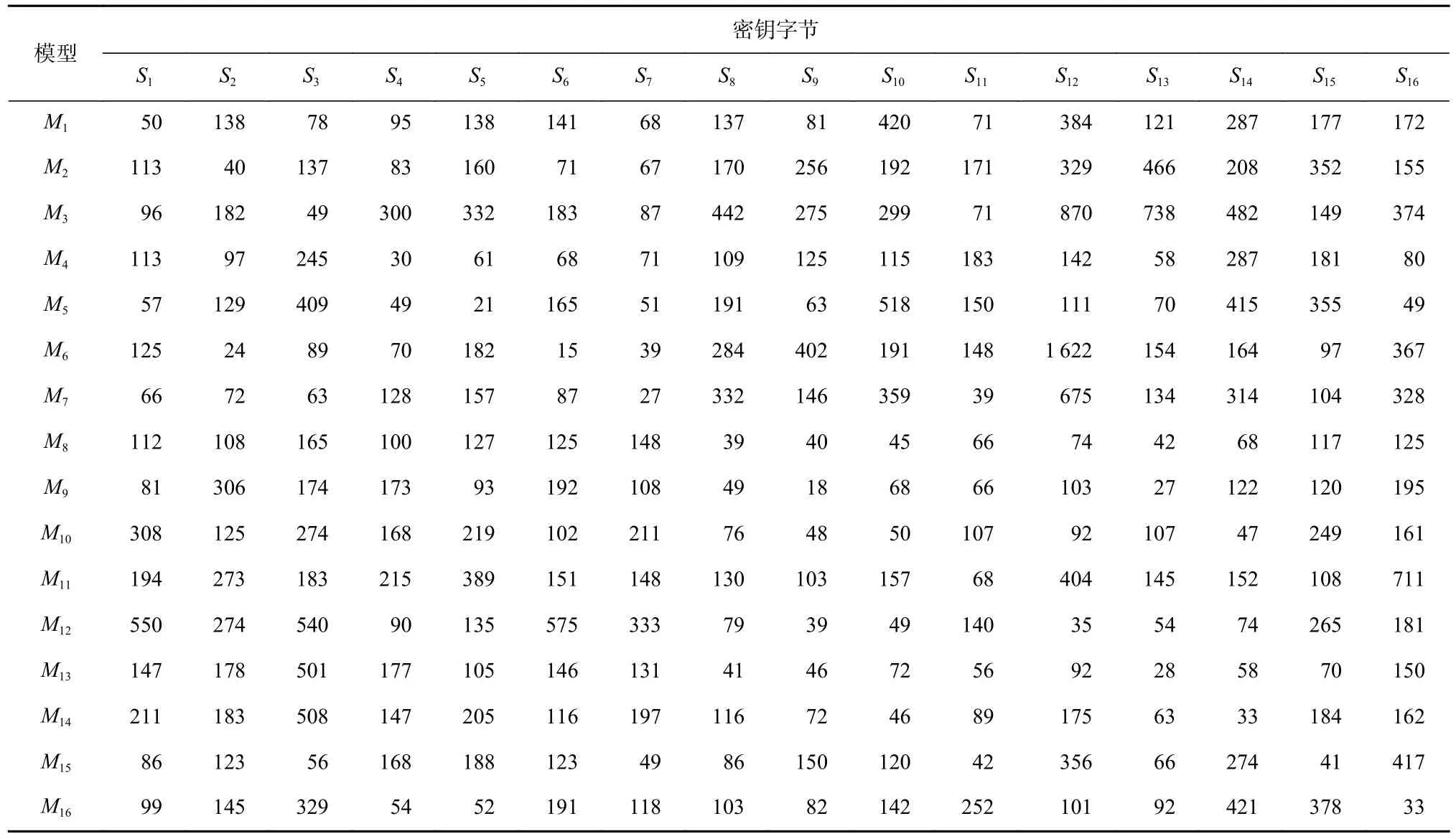
Table 2 Number of Traces for Sixteen Models Recovering Sixteen Key Bytes表2 16 个模型恢复16 个密钥字节的能量迹数
表2 中,每一行的数值表示第i个模型Mi恢复不同密钥字节的最少能量迹数. 从表2 中可以看出,以某个泄露点对应的密钥字节数据建立的模型,在恢复该泄露点对应的密钥字节时,除M10外都具有最佳效果;而以某个模型去恢复其他密钥字节时,也都可以恢复,只是需要使用更多的能量迹数量.
2.2 数据筛选与多源数据聚合模型构建
表2 结果表明,基于神经网络进行单密钥字节模型训练时,由于AES 算法中S 盒特性,密钥泄露数据集之间存在可能相似的特征,每个模型可以一定程度上学习到其他密钥字节的泛化特征,能够恢复出其他泄露点对应的密钥字节. 在因运行环境等原因无法大量采集能量迹的情况下,为减少数据采集和模型训练,基于密钥字节泄露数据集之间可能相似的特征,可以选用部分密钥字节的泄露数据集训练一个多源数据聚合模型去恢复所有密钥字节.
为保证训练的聚合模型具有更好的泛化效果,需要筛选出对其他所有密钥字节的攻击效果总体上最好的数据集进行训练. 具体地,设计一种打分机制进行评估. 先基于不同泄露数据集构建的16 个模型中的每个模型对所有密钥字节的攻击结果,根据每个模型恢复各个密钥字节的能量迹数量进行升序排序并进行打分,排序靠前的模型得分高,排序靠后的被认为对恢复密钥的作用较小,得分降低甚至忽略不计. 以Cx(Mi,Sj)表示模型Mi在密钥字节Sj上排序位置为x时的得分,打分方法为
根据Cx(Mi,Sj)计算出各个模型Mi在密钥字节Sj上的得分. 基于该方法,计算每个模型Mi在所有16 个密钥字节上的得分并求总分,以CT(Mi)表示模型Mi的总得分,则
根据表2 中不同单密钥字节模型对各个密钥字节恢复所需要的能量迹数,采用式(4)分别计算每个模型在恢复所有密钥字节时的得分情况如表3 所示.
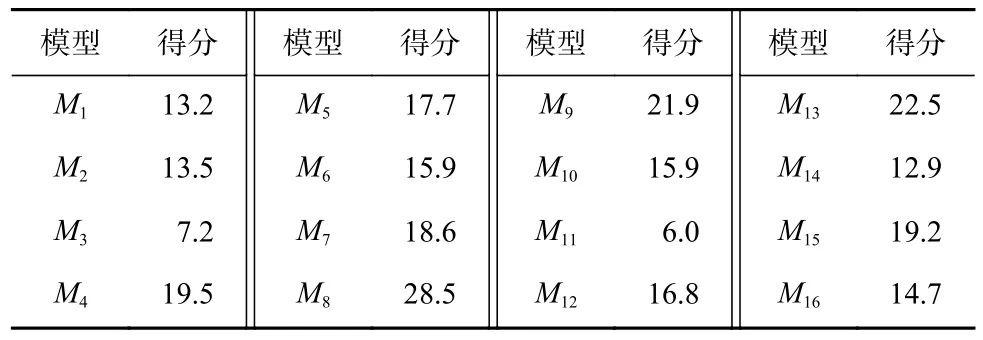
Table 3 Scores of Each Model表3 各个模型的得分
根据表3 中各个模型的得分进行升序排序,结果如表4 所示.

Table 4 Ranking of Each Model According to Scores表4 由得分得到的各个模型的排序
为构建一个具有较好泛化效果的聚合模型,选取排序靠前的几个模型分别对应的密钥字节泄露数据集进行聚合,训练出一个多源数据聚合模型,再以聚合模型进行密钥恢复.
在多源数据聚合模型训练中,仍然采用Benadjila等人[7]提出的MLP-best 模型建立MLP 神经网络模型,聚合模型的层数、激活函数和参数均与2.1 节中基于单密钥字节构建模型相同.
3 实验结果与分析
采用Python 语言,基于Keras 深度学习开源库(keras 2.2.4)和TensorFlow 后端(Tensorflow 1.12.0)在硬件配置为Intel(R)CoreTMi5-6300HQ CPU@2.30 GHz、内存8 GB 和 NVIDIA GeForce GTX 960 M 显卡的计算机上实现MLP 神经网络模型,基于DPAContest_V4数据集构建并训练16 个单密钥字节模型和多源数据聚合模型,并进行密钥恢复测试. 针对多源数据聚合模型,完成了其进行密钥恢复的能量迹数量及与其他模型的对比测试.
3.1 不同多源数据聚合模型的攻击效果测试
根据表4 中单密钥字节模型对不同密钥字节恢复的打分排名结果,按照排名情况选取各个模型对应的密钥字节数据进行聚合,训练多源数据聚合模型,再进行密钥恢复. 为更好地评估不同密钥字节数据集聚合的泛化攻击效果,根据表4 的排名情况分别以得分排名前6,8,10,12,14,16 的模型对应的密钥字节数据集进行多源数据聚合,建立和训练聚合模型Mix_6,Mix_8,Mix_10,Mix_12,Mix_14,Mix_16,对不同密钥字节数据进行恢复,并与各个单密钥字节模型Mi恢复相应密钥字节数据的结果进行对比,各自所需要的能量迹数如图2 所示.
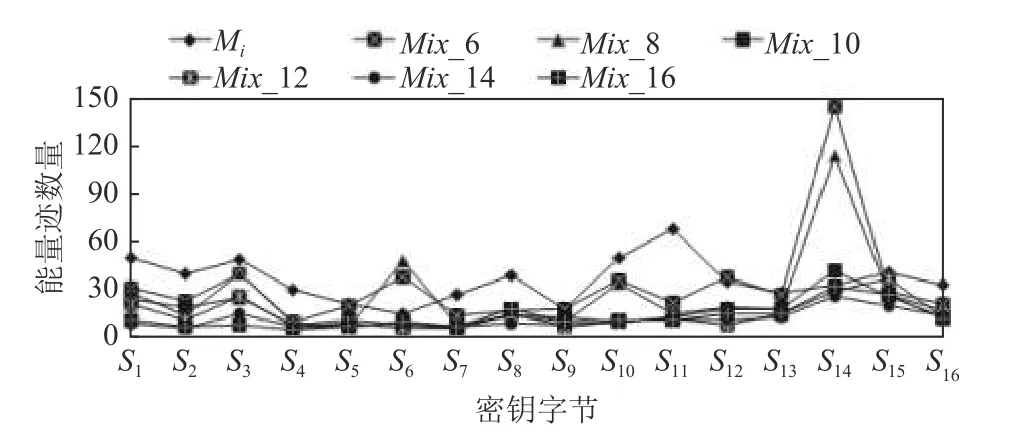
Fig.2 Number of traces for each key byte recovered by different models图2 不同模型恢复各密钥字节的能量迹数
图2 结果表明,多源数据聚合模型都能够以所聚合的部分密钥字节泄露数据集训练模型并有效恢复出所有密钥字节,包括那些没有参与聚合训练的密钥字节;同时,多源数据聚合模型较单密钥字节模型的攻击效果更好,其恢复各密钥字节所需要的能量迹数量更少. 从对每一个密钥字节数据的攻击结果看,随着聚合的数据集增加,聚合模型的攻击效果提升,恢复该密钥字节所需的能量迹数量减少,这表明聚合模型可以在更多的数据集中更好地学习到泛化特征.在聚合模型进行特征学习过程中,当聚合的数据集较少时,噪声容易干扰学习结果,攻击效果并没有显著提升;随着聚合数据集的增加,噪声干扰降低,在聚合6 个数据集进行训练后,对整体子密钥的恢复效果基本趋于稳定并优于单密钥字节模型的攻击结果.
多源数据聚合模型基于深度学习的强大学习能力,能够基于部分采集的能量迹数据有效恢复算法整体密钥,这在数据采集不便的情况下也能够实现高效的攻击;由于不需要训练多个模型也使得模型训练和分析测试工作有效减少.
3.2 公用数据集对比实验与分析
现有针对密码算法的基于深度学习的侧信道分析方法,更多的仍然是针对密码算法不同的密钥字节分别建模和分析. 针对AES-256 算法,文献[13]基于卷积神经网络 (convolutional neural network,CNN)和DPAV4 数据集,以第1 轮掩码S 盒输出值的最低有效位作为训练标签,针对其选择的某个密钥字节对应的泄露数据集分别建模和训练测试,使用1 000条能量迹作为训练集,2000 条作为验证集,2000 条作为测试集,完成对该密钥字节的恢复,其恢复该密钥字节所需要的能量迹为550 条.
采用多源数据聚合模型方法,按表4 分别取前8,10 个数据集聚合训练模型Mix_8,Mix_10,与文献[13]在同样数据集大小条件下进行模型训练并对前16 个密钥字节进行恢复;同时,根据算法原始的密钥字节顺序选取前8,10 个密钥字节的泄露数据集,采用本文的多源数据聚合思想以同样数据集大小聚合训练模型MO_8,MO_10 并恢复前16 个密钥字节,与在同样数据集大小情况下采用单密钥字节泄露数据训练模型Mi的密钥恢复结果对比,各自所需能量迹数如表5 所示.

Table 5 Recovery Results of Six Models for 16 Key Bytes表5 6 个模型对16 个密钥字节的恢复结果
文献[13]通过已知的掩码计算掩码S 盒的输出,将其转换为一个不受保护的实现,本实验中采用式(2)的标签方案并未对掩码进行额外操作,因此在只有1 000 条训练数据下训练的单密钥字节模型效果不太理想,但在2 000 条能量迹内也能恢复正确密钥.
表5 结果也显示多源数据聚合模型恢复密钥字节的效果都优于文献[13],所需能量迹数量更少;随着聚合数据集的增加,聚合模型对密钥字节的恢复效果更好,所需要的能量迹数减少. 模型Mix_8,Mix_10 的攻击效果分别优于模型MO_8,MO_10,这表明基于打分排名后筛选的多源数据聚合模型具有更好的泛化特征学习能力,其攻击效果要优于不做数据筛选的多源数据聚合模型,恢复密钥字节所需使用的能量迹数更少.
文献[9]基于MLP 网络和DPAV4 数据集,进行50 次随机超参数搜索训练得到50 个MLP 网络并使用引导聚集(bootstrap aggregating)算法进行集成,针对第1 个密钥字节的数据进行训练与恢复,以第1 轮掩码S 盒输出值的汉明重量作为训练标签,34 000 条能量迹作为训练集,1 000 条作为验证集,1 000 条作为测试集进行实验. 采用同样的数据集规模,基于多源数据聚合模型方法,按表4 分别取前8,10,12 个数据集聚合训练模型Mix_8,Mix_10,Mix_12 进行密钥恢复;同时,根据算法原始的密钥字节顺序选取前8,10,12 个密钥字节的泄露数据集,采用本文的多源数据聚合方法以同样数据集大小聚合训练模型MO_8,MO_10,MO_12 并恢复密钥,各自所需能量迹数如表6所示.
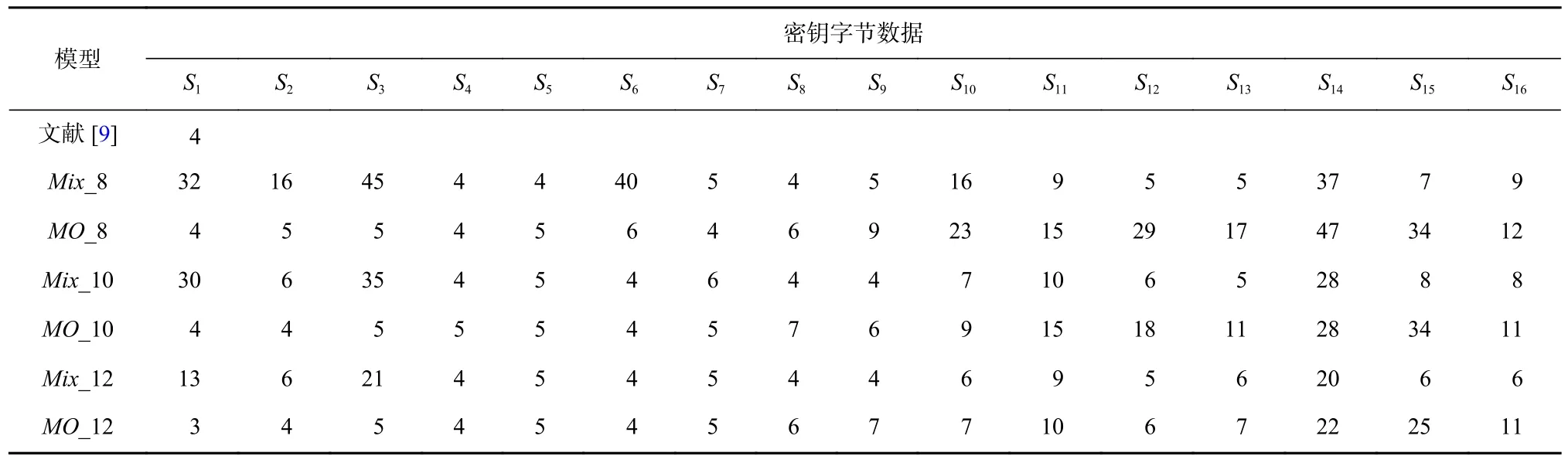
Table 6 Recovery Results of Seven Models for 16 Key Bytes表6 7 个模型对16 个密钥字节的恢复结果
表6 结果显示,相较于文献[9]中的结果,采用聚合模型进行攻击,各个模型中参与了训练的密钥字节的恢复所需要的能量迹在4 条左右,未参与训练的密钥字节的恢复需要更多的能量迹数;但采用聚合模型仅需要训练1 个模型,开销小、时间短,且在聚合12 个密钥字节的泄露数据集后,对未参与训练的密钥字节恢复密钥的能量迹数量都有效减少,而文献[9]需要训练50 个不同的模型才完成对第1个密钥字节的攻击,要完成对16 个密钥字节的攻击,其模型训练的开销极大、时间过长.
相比于表5 中的结果,表6 结果也显示聚合模型中相应密钥恢复所需要的能量迹数量进一步减少.这表明随着数据规模的增加,神经网络可以充分地学习到训练数据的特征,聚合模型的攻击成功率更高;其次,采用基于打分排名后筛选的数据聚合模型具有更好的泛化特征学习能力,其总体攻击效果仍然优于不做数据筛选的聚合模型;同时,随着参与训练的数据量增加,泄露数据参与了训练的密钥字节更容易被恢复,因其特征能够被更好地提取出来.
3.3 实测数据集对比实验与分析
使用MathMagic 侧信道分析仪,搭载目标芯片STC89C52 单片机,实现无防护的AES-128 算法,模拟数据采集困难、所采集的能量迹少的情景,共采集3 500 条能量迹,以其中3 000 条能量迹作为训练集,剩下500 条能量迹作为测试集. 实验中先通过相关性分析确定密钥字节在能量迹中的泄露位置,采用式(1)进行计算,由于汉明重量模型对应9 种类别,因此在保持MLP 模型结构参数与2.1 节模型参数其余部分不变的基础上,将输出层节点数设置为9. 对每个密钥字节独立建模并攻击,各单密钥字节模型记为Mi. 采用多源数据聚合模型方法,按表4 选取前8,10 个泄露数据集聚合训练模型Mix_8,Mix_10,同时按密码算法原始密钥字节顺序选取前8,10 个数据集聚合训练模型MO_8,MO_10,并分别恢复各密钥字节,各个模型完成密钥恢复所需的能量迹数对比结果如表7 所示.

Table 7 Recovery Results of Five Models for 16 Key Bytes表7 5 个模型对16 个密钥字节的恢复结果
表7 结果表明,由于训练数据的不足,采用单密钥字节建模并进行密钥恢复时,仅恢复出其中的3个字节,其他模型因不能学习到足够的特征,无法恢复密钥;采用多源数据聚合模型方法都有效完成了密钥恢复,优于单密钥字节模型攻击结果. 在Mix_8,Mix_10 中,恢复前3 个密钥字节的能量迹数较MO_8,MO_10 所需的能量迹数稍多,主要原因在于这些密钥字节泄露数据在Mix_8,Mix_10 中未参与训练,而在MO_8,MO_10 中参与了训练,在训练数据不足的情况下未参与训练的密钥字节特征学习效果相对减弱. 但总体上,与采用公用数据集训练模型一样,采用实测数据集训练模型时,基于打分排名后筛选的多源数据聚合模型仍然具有更好的泛化特征学习能力,其攻击效果优于不做数据筛选的多源数据聚合模型,恢复密钥字节所需使用的能量迹数更少. 此外,相对于加掩防护的公用数据集实验,实测实验针对的是未加掩码防护的AES-128 算法,因此更容易完成攻击,恢复密钥所需的能量迹数大大减少.
3.4 针对Present 算法的聚合模型实验与分析
为评估本文方法的通用性,将聚合模型应用于Present 算法,验证数据聚合模型的分析效果. Present算法是一个4 b 的S 盒且SPN 结构的轻量级密码算法. 使用osrtoolkit 功耗采集平台,搭载目标芯片ATMEGA2560,实现无防护的Present 算法,采集3 500条能量迹,以其中3 000 条能量迹作为训练集,500 条能量迹作为测试集. 实验中先通过相关性分析确定密钥半字节在能量迹中的泄露位置,以真实密钥作为身份标签,训练的epoch=300,batchsize=100,学习率设为0.000 01,优化器使用RMSprop,使用交叉熵损失函数,将输出层节点数设置为16. 对16 个密钥半字节分别独立建模并攻击,各密钥半字节模型记为Mi.利用这16 个模型中的每一个模型,分别以每个密钥半字节对应的测试集数据去恢复所有的密钥半字节,各模型完成对各密钥半字节恢复的最少能量迹数如表8 所示.

Table 8 Number of Traces for Sixteen Models Recovering Sixteen Key Nibbles for Present Algorithms表8 针对Present 算法16 个模型恢复16 个密钥字节的能量迹数
根据式(4),基于表8 的结果计算每个模型在恢复所有密钥半字节时的得分,结果如表9 所示.采用多源数据聚合模型方法,对表9 以得分高低排序后选取前8,10,12,16 个泄露数据集聚合训练模型Mix_8,Mix_10,Mix_12,Mix_16,分别恢复各密钥半字节,所需的能量迹数与单密钥半字节建模恢复的结果对比情况如表10 所示.

Table 9 Scores of Sixteen Models表9 16 个模型的得分

Table 10 Recovery Results of Different Models for Each Key Nibble表10 不同模型对各密钥半字节的恢复结果
表10 结果表明,在聚合模型中,由于密钥半字节S5和S9对应模型得分较低,相应数据集未能在Mix_8,Mix_10 中参与训练,无法被恢复. 但在Mix_12模型中,S5对应的数据集尽管没有参与训练,但由于有更多数据集参与训练,相应特征被学习,也能够被有效恢复. 而基于所有数据集的聚合模型,能够以更少的能量迹数量恢复所有密钥半字节. 从所有聚合模型恢复的结果看,若数据集参与了聚合模型训练,其恢复相应密钥半字节所需要的能量迹数量均少于单密钥半字节模型的结果;在单密钥半字节模型中无法恢复的其他密钥半字节,在聚合模型中除1 或2个密钥半字节外,其他的都能够有效恢复,这表明多源数据聚合模型具有更好的泛化特征学习能力,相对于单密钥半字节模型,有效提升了其恢复密钥的能力. 针对不同算法的攻击结果,表明了本文提出的多源数据聚合模型在攻击时具有较好的通用性.
4 结束语
为降低在实际应用中基于深度学习进行侧信道攻击所需要的数据采集和模型训练开销,提出一种基于多源数据聚合的神经网络侧信道攻击方法. 该方法针对AES-128 算法,通过评估单密钥字节模型的泛化效果,筛选出对各密钥字节恢复效果最好的部分密钥字节泄露数据集,构建多源数据聚合模型,再进行密钥恢复. 实验测试结果表明,多源数据聚合模型具有良好的泛化效果,有效提高了密钥恢复的准确率和效率,降低了恢复密钥所需的能量迹数量,可在能量迹采集困难、能量迹较少的情况下依然具有较好的攻击效果. 在今后工作中,将考虑结合数据增强技术,进一步提升在能量迹不足情况下的密钥恢复效果. 与此同时,也将研究针对深度学习侧信道攻击的防御措施,提高密码算法应用的安全性. 深度学习侧信道攻击主要针对S 盒部件的泄露数据开展攻击. 因此,为有效预防深度学习侧信道攻击,一方面是在密码部件设计中,考虑S 盒抗侧信道攻击的能力,并研究密码算法结构整体的安全性;另一方面是研究针对侧信道攻击的掩码防护技术,消除密码算法功耗泄露与中间值之间的可预测关系,达到防护的目的.
作者贡献声明:张润莲设计研究方案,撰写初稿;潘兆轩参与方案讨论、实验研究及结果分析;李金林采集数据,参与实验研究及结果分析;武小年参与设计研究方案及论文修改;韦永壮参与论文修改.
猜你喜欢
纺织科学研究(2023年9期)2023-10-23
销售与市场(营销版)(2021年10期)2021-11-21
北京电子科技学院学报(2020年2期)2020-11-20
销售与市场(营销版)(2019年6期)2019-06-21
信息安全研究(2018年1期)2018-02-07
网络安全技术与应用(2017年9期)2017-09-20
电信科学(2017年6期)2017-07-01
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27
华东理工大学学报(自然科学版)(2015年4期)2015-12-01
电子设计工程(2015年8期)2015-02-27
