
症状动态网络的分析方法介绍及R软件实现
2024-01-12 05:58余骏雯胡天天杨中方何加敏金依霖朱政
护士进修杂志 2023年24期
余骏雯 胡天天 杨中方 何加敏 金依霖 朱政,2,3
(1.复旦大学护理学院,上海 200032;2.上海市循证护理中心,上海 200032;3.纽约大学护理学院, 纽约 10010)
根据症状的数据类型,症状网络可以分为3种类型:基于横断面症状数据的同期网络、基于单个个体症状数据的时态/个体化网络和基于重复测量的群体面板症状数据的动态网络。其中,同期网络主要关注在同一时间点上不同症状之间的关联性。这种网络类型有助于帮助我们理解症状之间的共现模式,例如,抑郁症和焦虑症常常在同一患者中同时存在[1-2]。然而,同期网络无法捕捉症状之间的时间序列关系,即它无法显示一个症状是如何随着时间的推移影响另一个症状的[3]。相比之下,动态网络结合了同期网络和时态/个体化网络的优点,它基于重复测量的群体面板症状数据,可以捕捉到症状之间的时间序列关系,同时也可以反映出症状在群体中的共现模式。动态网络的主要优势在于它可以更全面地理解症状的动态演变过程和症状之间的复杂交互关系。然而,动态网络的建立和分析需要复杂的统计方法,这可能是其在实际应用中的一个主要挑战。本文将从症状动态网络的定义、常用网络特异性指标以及R软件的实现等方面进行介绍,旨在为推广和规范症状动态网络的相关研究提供借鉴和指导。
1 症状动态网络的基本概念
1.1动态网络的定义 动态网络是一种基于重复测量的群体面板症状数据构建的网络,这种网络可以在多个时间点对同一群体的症状进行测量[4]。动态网络不仅反映了群体症状各类指标随时间变化的情况,还能揭示症状之间的时间序列关系,以及症状在群体中的共现模式。动态网络的主要目标是理解各种症状随时间变化如何相互影响,以及这些症状如何共同影响其他症状的发展和演变。因此动态网络是基于面板数据所形成的是有向网络,见图1。
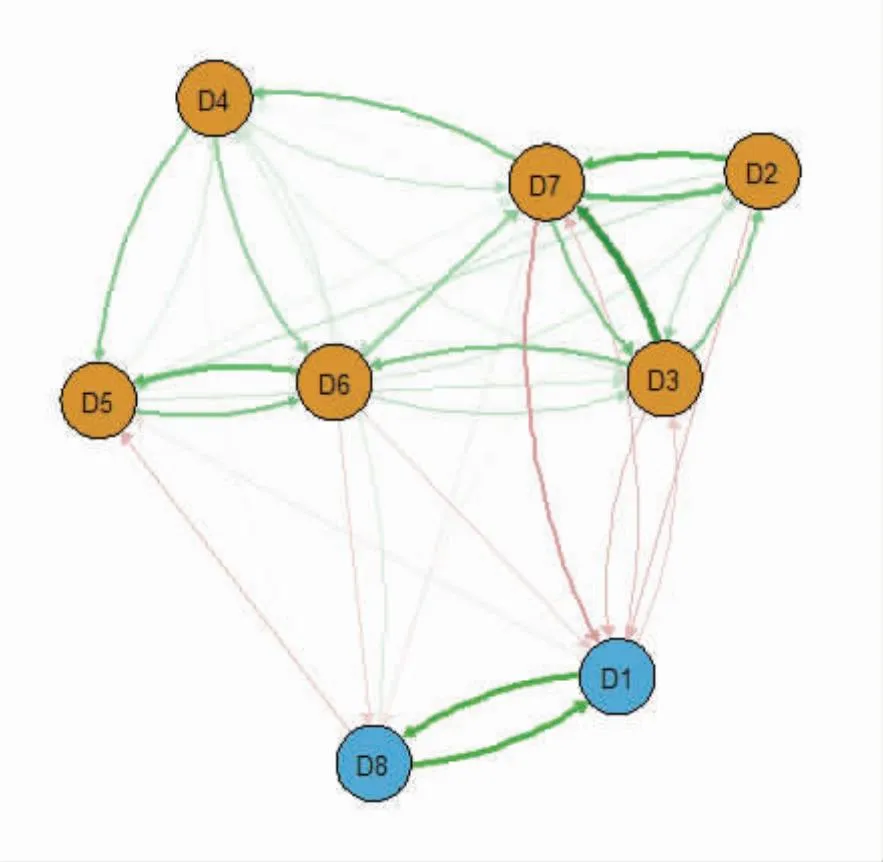
图1 症状动态网络的示意图
既往研究基于症状动态网络来剖析症状的发生机制。例如Van等[5]在比较处于精神病早期不同临床阶段的个体之间的跨诊断症状网络研究中,构建了基于10个关于抑郁、焦虑、精神病、非特异性和脆弱性领域的症状的时变向量自回归的症状动态状网络。结果发现随着临床阶段的增加,症状网络的密度会增加,且精神病相关症状会在网络中占据更核心的位置。研究结果强调了评估症状网络的重要性。再如Zhu等[6]探索中国中老年人群中抑郁症状的纵向关系的研究使用了来自中国健康和退休纵向研究的3波数据(2013年、2015年和2018年),构建了基于时变向量自回归模型的动态网络来识别十种抑郁症状之间随时间动态变化的相互关联。研究结果发现“感到恐惧”是具有最强预测性的因子。
1.2动态网络的分析方法 分析动态网络的方法主要包括网络结果分析法、交叉滞后网络分析法和时变向量自回归分析法,这3种方法的应用场景各异。见表1。

表1 常用症状网络分析方法
这些方法的选择应根据研究的目标和可用的数据来决定。总的来说,无论是那种方法,动态网络模型都需要大量的数据,并且对数据的质量和完整性有较高的要求。
1.3动态网络中常用的网络特异性指标 动态网络的特异性指标与其他症状网络类似,也可以分为节点指标、网络指标、网络拟合指标和差异性检验指标4类。但由于动态网络生成的是有向网络,存在自变量与因变量的方向性,因此,在部分指标存在“出”和“入”的区分。动态网络中常用的特异性指标的类型,见表2。

表2 动态网络中常用的网络特异性指标类型
2 动态网络分析内容和R软件的实现
动态网络根据研究目的和数据结构可以采用不同的分析方法。例如,动态网络可以采用交叉滞后网络模型或时变向量自回归模型进行分析[7]。本文将重点介绍动态网络中的交叉滞后网络分析,并介绍如何使用R软件进行实现。
2.1数据准备和清理 症状网络分析的数据准备和清理需要注意以下几点。(1)数据收集: 首先,需要收集关于症状的数据。这可能包括从患者那里获取的自我报告数据,或者从医疗记录中提取的数据。数据应该包括症状的类型、严重程度,以及症状在不同时间点的变化。(2)数据清理:删除或修正错误的数据,处理缺失值,以及检查数据的一致性。例如,如果一个患者在某一时间点报告了一个症状,但在下一个时间点没有报告这个症状,那么需要增补数据或删除数据。网络分析不允许缺失值存在。(3)数据转化和标准化:由于不同的症状可能有不同的度量标准,在进行网络分析之前,可能需要对数据进行标准化。(4)数据保存:将症状数据转化为构建症状网络所需的形式,可以提取需要的变量并保存为CSV格式。(5)设置症状发生率阈值:有些症状的发生率较低,导致网络分析时出现错误,建议剔除此类症状。

完成数据整理后,需要进行以下步骤:按照glmnet,qgraph和lavaan安装包,设置工作目录、读取数据,并导入命令包、标签化节点名称、剔除缺失值。glmnet是一个用于拟合广义线性模型的工具包,特别是用于处理具有大量预测变量的情况[8]。它使用了弹性网正则化,这是一种结合了L1和L2正则化的方法,可以有效地进行变量选择和复杂度调整。qgraph是一个R语言的命令包,主要用于构建同期症状网络图模型。该包的主要功能是利用图形和统计方法来可视化网络数据,以帮助研究者更好地理解网络结构和关系[9]。lavaan是一个用于结构方程模型的工具包。结构方程模型是一种复杂的统计模型,可以同时估计多个回归方程,并允许变量之间存在复杂的相互关系[10]。读取方式,见框1,扫二维码获取框1。
2.2运算交叉滞后面板模型 运算交叉滞后面板模型采用glmnet包进行Lasso回归,以构建1个矩阵,该矩阵表示数据集中各个变量之间的关系。以框1案例为例,首先,设定节点的数量为9,并创建1个9×9的零矩阵和一个长度为9的零向量。此后,开始一个循环,对每个变量进行Lasso回归,预测变量是数据集中的前9列,响应变量是第9列之后的列。在进行回归之前,所有的变量都被标准化。接着,提取出使交叉验证误差最小的lambda值,并使用这个lambda值计算Lasso回归的系数。最后,这些系数被存储在9×9的矩阵的相应列中。这个矩阵可以被用来理解数据集中变量之间的关系,或者用来构建1个网络模型。
2.3动态网络的可视化 动态网络的可视化主要分为包含和去除自回归模型2个部分。它使用了qgraph函数来创建网络图,见图2。
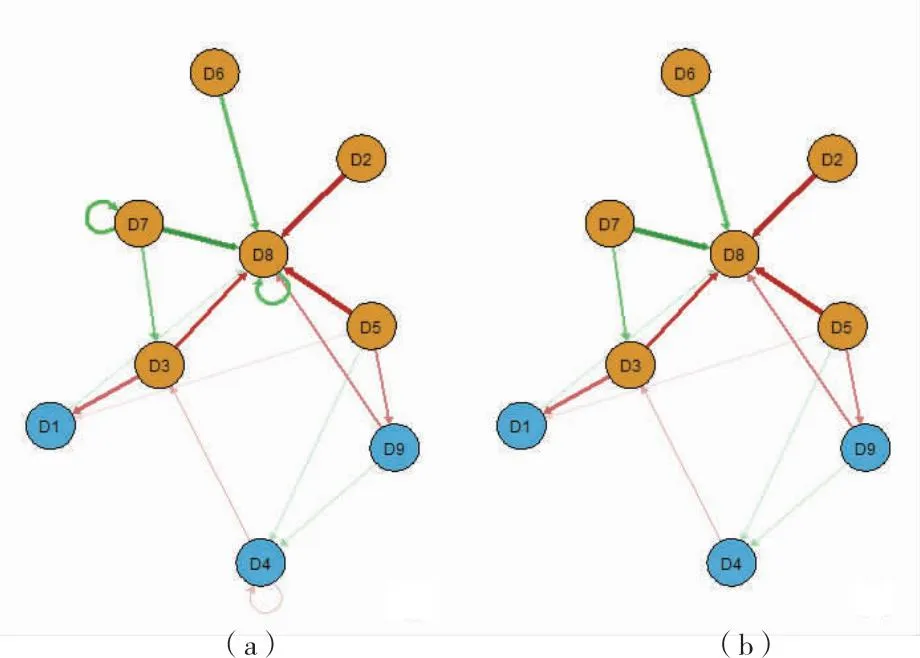
注:(a)自回归网络示意图 (b)去除自回归网络示意图图2 动态网络示意图
在包含自回归模型中,首先定义一个变量标签的向量,再创建一个JPEG文件来保存图像。接着,使用qgraph函数来创建一个网络图,其中adjMat是之前通过Lasso回归计算得到的系数矩阵,groups是一个向量,用于指定每个节点的组别,labels是节点的标签,colors用于定义节点的颜色。此后,创建一个新的图形区域,并添加一个图例来标识变量。最后,使用dev.off函数关闭图形设备,保存图像。
在去除自回归模型中,首先创建一个新的系数矩阵adj Mat 2,并将其对角线上的元素(即自回归的系数)设置为0,从而去除了自回归。接着,创建一个新的JPEG文件来保存图像,和上一部分的操作类似,使用qgraph函数来创建一个网络图,再添加一个图例,并使用dev.off函数关闭图形设备,保存图像。
这2部分代码的主要区别在于是否包含自回归。在包含自回归模型中,网络图中的每个节点都有一个指向自己的箭头,表示自回归的效应。而在去除自回归模型中,这些箭头被去除,只保留了节点之间的关系。通常会使用去除自回归的可视化结果,保留自回归会导致当自回归系数过大时,其他边缘系数可视化差异性减小。
2.4计算和可视化预测性 预测性是指一个变量能够预测其他变量的程度。在代码中主要要进行2个部分:计算预测性和可视化预测性结果。
2.4.1在计算预测性的部分 代码首先创建了3个空向量来存储预测性的结果。接着,开始一个循环,对每个变量进行处理。在每次循环中,首先读取因变量的标签和分组信息,再定义3种模型:包含变量自回归的模型、剔除变量自回归的模型和明确自变量分组的模型。此后,使用sem函数来拟合这3种模型,并计算模型的R2值,这个值被用来衡量模型的预测性。最后,将计算得到的R2方值存储在之前创建的空向量中。
2.4.2在可视化预测性 代码首先创建了一个JPEG文件来保存图像。之后,使用barplot函数来创建2个条形图,分别表示入可预测性(in-predictability)和出可预测性(out-predictability)。接着,创建1个新的图形区域,并添加1个图例来标识变量。最后,使用dev.off函数关闭图形设备,保存图像结果的部分,见图3。
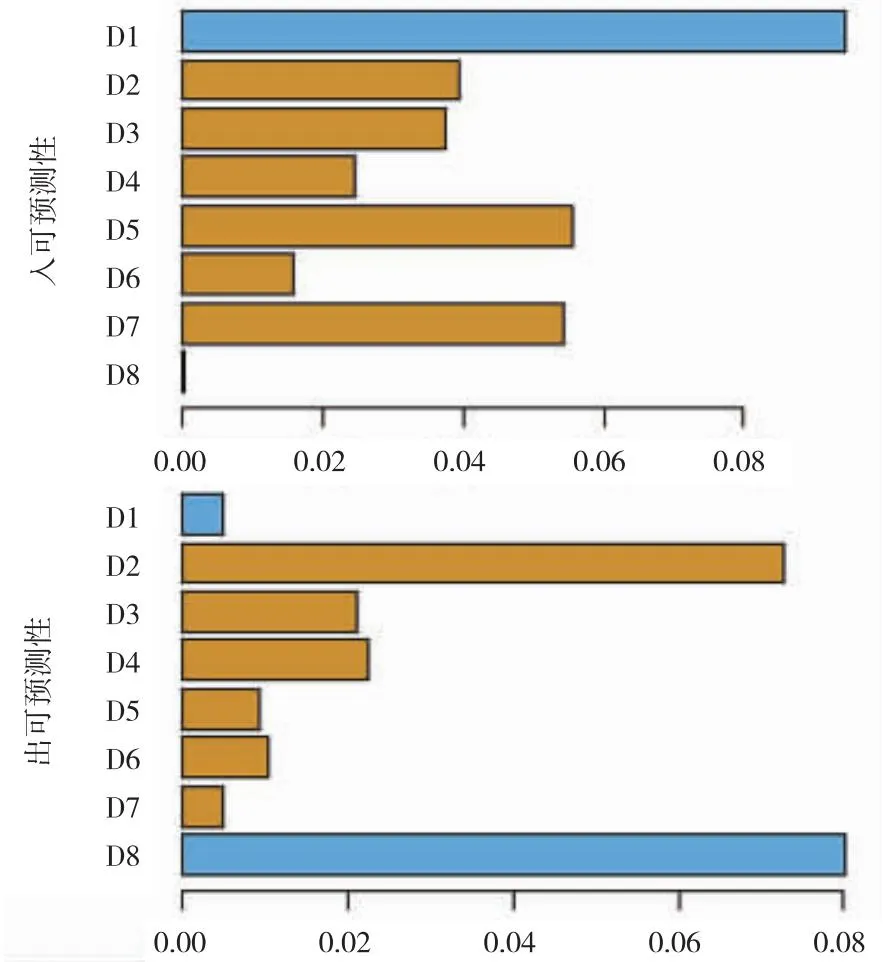
图3 预测性结果的示意图
这段代码的结果是1个包含2个条形图的图像,这2个图分别表示了每个变量的“入预测性”和“出预测性”。这2个指标可以帮助我们理解每个变量对其他变量的预测能力。
2.5中心化指标分析 在症状网络中,中心性指标是用来描述节点在网络中核心地位的重要指标,主要包括入强度中心性、出强度中心性、紧密中心性和中介中心性,见图4。这段R代码使用qgraph包的centrality和centralityPlot函数来计算和可视化网络中节点的中心性指标。centrality(g)函数和centralityPlot函数计算和可视化网络g中每个节点的入强度中心性、出强度中心性、紧密中心性和中介中心性,这些指标有助于理解网络中每个节点的重要性。
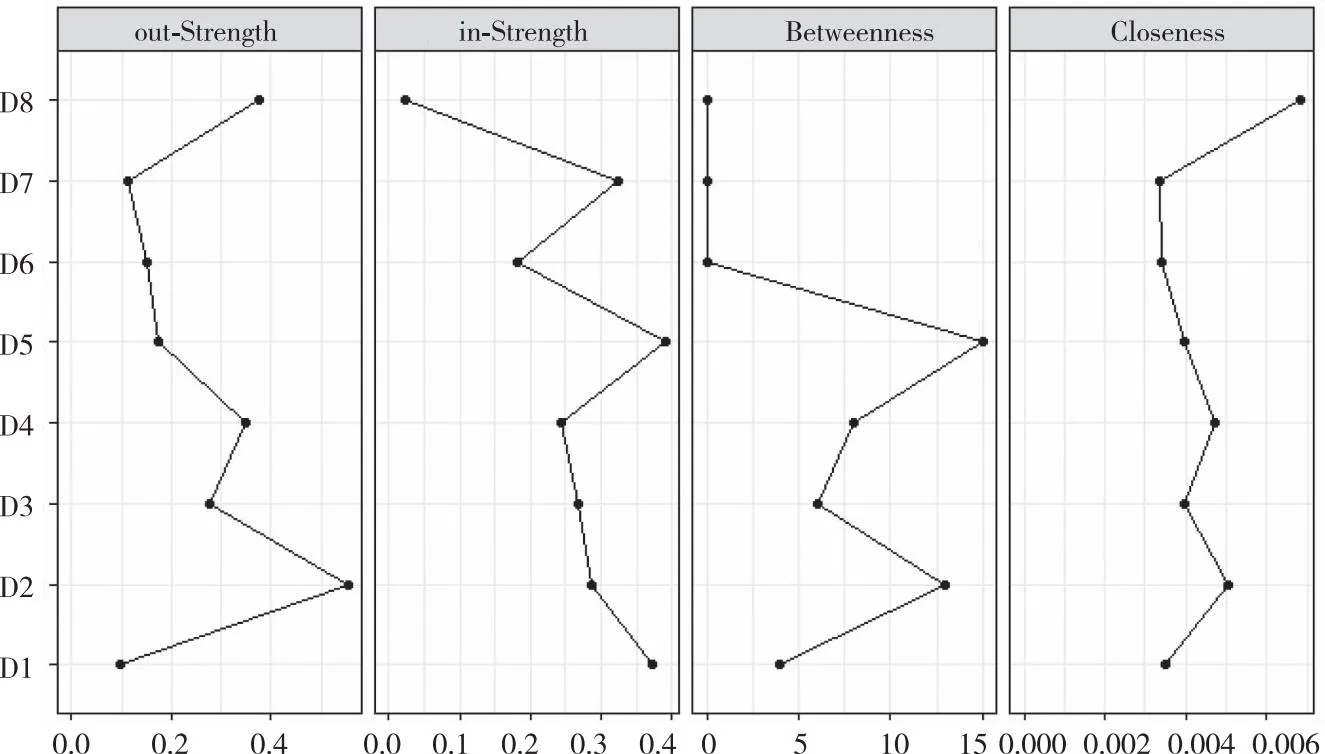
图4 中心化指标分析结果示例
3 讨论
3.1症状动态网络的模型选择 在症状动态网络的研究中,模型的选择主要取决于研究的目标和数据的特性,常用方法包括网络结果分析法、交叉滞后网络分析法和时变向量自回归分析法[11]。
3.1.1网络结果分析法 是动态网络模型中的一种特殊情况,该方法将预测变量(t1时刻)和结果变量(t2时刻)整合为1个网络。这种方法允许研究者在控制了t1时刻所有其他变量的关联后,检查预测变量和结果变量之间是否存在直接的预测关联。这种方法仅适用于只有在部分数据收集波次中才能获得重要结果变量的情况,其关键优点是它可以直接考虑到预测变量和结果变量之间的关系,而不需要对整个网络进行全局分析。
3.1.2交叉滞后网络分析法 可用于研究不同变量之间随时间而动态变化的关联,通过正则化回归来估计除自身外所有其他节点的滞后交叉关联,并考虑其自回归效应。这些滞后关联表示在调整了第一个波次所有其他变量后的有向效应。该方法的关键优点是它可以直接考虑到时间的影响,从而更准确地描述变量之间的动态关系。然而,其主要限制是它需要至少2个测量时间点的数据。
3.1.3时变向量自回归分析法 可以区分个体内和个体间效应,其在结构上类似于随机截距滞后面板模型,并且需要至少3个测量时间点的数据。每个变量通过自身和模型中其他所有变量的滞后交叉值来进行预测,从而得到自回归和时间滞后的估计。这种方法的一个关键优点是它可以同时考虑多个变量,并且可以直接考虑到个体内和个体间的差异。
在选择症状动态网络的分析方法时,需要综合考虑多种因素。(1)研究目标和数据特性是决定分析方法的关键。研究者需考虑研究的目标是探索变量之间的关系,还是预测未来的变化;数据是时间序列还是横截面数据,并兼顾数据量的大小以及数据的质量等。(2)需要考虑数据的时间序列特性,如季节性、趋势性等,以及变量的性质,如变量是否为连续性变量、二分类变量或等级变量等。此外,计算资源也是一个重要的考虑因素,一些复杂的方法可能需要大量的计算资源。(3)研究问题的复杂性也会影响分析方法的选择,对于涉及到多个交互效应或非线性关系的复杂研究问题,可能需要使用更复杂的模型。
3.2网络结果的异质性 动态网络在总人群中的结果可能存在异质性,异质性来源的识别需要研究者对该领域人群特征有较好的把握,识别异质性的来源和处理异质性是一个重要的挑战。以下是一些可以使用的策略:(1)分层分析,如果研究者对特定的人群特性(如年龄、性别、种族等)有先验的假设,可以进行分层分析,即分别在不同的人群中建立和分析网络模型。这可以帮助研究者理解不同人群中网络结构和参数的差异。如Zhu等[6]探索中国中老年人群中抑郁症状的纵向关系的研究中,对性别进行了亚组分析,结果发现男性与女性中老年人在抑郁症状的发生机制上存在较大的差异。(2)多群体比较,如果研究者对多个人群的网络结构或参数是否存在差异感兴趣,可以使用多群体比较的方法。这种方法可以测试网络的全局结构是否在不同的人群中保持一致,以及特定的网络参数是否在不同的人群中有显著的差异。(3)随机效应模型,如果人群间的异质性主要表现在网络参数而非网络的全局结构上,可以使用随机效应模型来建模这种异质性。该模型假设每个人群的网络参数都是从一个共同的总体分布中抽取的,因此可以用来估计总体分布的参数,并测试个体参数是否显著地偏离总体参数。(4)个体化网络模型,如果人群间的异质性非常大,以至于无法通过上述方法进行有效的建模,可以考虑使用个体化网络模型。
4 小结
在本文中,深入探讨了症状动态网络的核心理念,并详细介绍了如何使用R软件进行动态网络的分析和可视化。我们重点讨论了交叉滞后网络分析法,并解析了如何根据研究目标和数据特性选择合适的方法。症状动态网络分析的目的是帮助研究者更深入地理解症状的动态交互机制,从而为制定更精准的预防和治疗策略提供依据。我们希望本文能对初学者了解症状动态网络分析方法有所帮助,并为该领域的研究者提供一定的参考价值。
猜你喜欢
世界科学技术-中医药现代化(2022年3期)2022-08-22
建材发展导向(2022年4期)2022-03-16
云南化工(2021年8期)2021-12-21
海洋信息技术与应用(2020年1期)2020-06-11
传媒评论(2019年4期)2019-07-13
铁道通信信号(2018年3期)2018-04-19
中国科技信息(2016年10期)2016-09-03
新闻前哨(2015年2期)2015-03-11
长江师范学院学报(2015年6期)2015-02-27
外语教学理论与实践(2014年2期)2014-06-21
