
学科专业文献数据分析处理系统功能架构设计与实现
2024-01-05 12:05:50杜文龙
电子设计工程 2024年1期
杜文龙,柴 源,李 慧
(西安航空学院图书馆,陕西 西安 710077)
数字经济是一种新兴的经济社会发展模式[1],数字和数据的价值在数字经济中进一步凸显[2]。随着大数据的指数级增长,在海量数据中提取出特定价值的“目标数据”难度增大[3]。如何挖掘、分析海量数据背后的隐性知识成为科学研究者关注的问题[4]。为了解决以上问题,帮助科学研究者挖掘海量数据背后的关联关系并以图谱的形式展现[5],设计了可揭示海量数据之间隐性知识关联的分析处理系统功能框架,针对数据分析处理过程设计出PM 模型,通过样本数据对系统功能框架和PM 模型进行双重验证。
1 数据分析处理系统功能框架
学科专业文献数据分析处理系统的功能架构由数据输入层(IN)、数据分析层(AN)和结果输出层(OU)三部分组成,如图1 所示。最底层为数据输入层,是整体架构的基础层,设计目标为对海量科学文献的结构化或非结构化数据进行清洗、格式转换和加工处理;中间层为数据分析层,是关联数据输入层和结果输出层的衔接层,设计目标为根据数据分析需求、数据分析目标和结果期望值对海量数据进行多维度关联分析;最顶层为结果输出层,为整体架构的数据分析结果展示层,设计目标为根据动态数据分析需求对图形成像进行主动干预并进行结果输出。

图1 学科专业文献数据分析处理系统功能架构
1.1 数据输入层(IN)
数据输入层定义了两种数据类型的技术参数。一种为结构化数据,即经过高度整合、组织的格式规范的数据,多以词频矩阵、图形数据等形式存储于关系数据库中,用户可使用SQL 等结构化查询语言查询和调取。另一种为非结构化数据,即除了结构化数据之外的数据的统称,非结构化数据是未经过预处理、未经过组织、字段不固定的数据类型,非结构化数据种类丰富,数据量巨大且增长飞速,如通过图书馆监控系统、环境感应系统、智慧门禁感应系统等智能化工具收集到的图书馆运行状态数据、环境监测数据和读者画像数据等非结构化数据。从数据内容、数据格式和数据语种三方面对非结构化数据进行了详细定义和描述,其中,数据内容方面包含论文数据、专利数据、科技报告以及自定义数据;描述了Excel、Txt、Access 三种数据格式;对数据的语种进行区分。
1.2 数据分析层(AN)
数据分析层描述科研关系、关系聚类和维度统计三类技术参数。科研关系参数定义数据揭示的学科发展演进、核心作者、核心机构、关键词和主题词之间的共引关系、关联关系和耦合关系等科研关系。关系聚类参数定义时间节点、作者节点、机构节点、学科节点、技术类别节点和主题词节点的聚类算法、中心度区间、最小距离算法、词语突变算法、相似度算法和聚类算法等反映节点之间关联强弱程度的技术特征。维度统计参数定义一维、二维、三维三个维度计算和分析时间、作者、机构、国家、省份、学科、技术类别、关键词和主题词等节点的技术特征。一维统计指通过一个维度描述数据特征,如反映某个作者发表的学术文献数量增长情况,形成反映数量变化的线状的数据结构。二维统计指通过二个维度描述数据特征,如通过X轴代表作者发文的年份指标,Y轴代表作者发文数量、被引用数量等指标,形成反映作者逐年发文情况的科研平面图。三维统计指通过三个维度描述数据特征,如形成的主题词密度立体网络图,便于科研用户从三维空间考究某领域的主题词引用关系,根据主题词节点路径算法、共引算法、中心性算法和密度函数计算出该领域的研究热点。
1.3 结果输出层(OU)
结果输出层定义和描述数据分析结果的输出界面参数控制、输出结果类型、输出结果形式、输出数据格式和可视化图谱显示等输出变量技术参数。结果输出层包含图形控制和数据输出两种技术参数。图形控制包括学科专业文献数据节点的控制和学科专业文献数据分析结果输出图形类型的控制。文献数据节点的控制包括节点位置、节点颜色、节点大小、节点中心性、节点路径计算、节点关联性、节点共引曲线等技术参数。学科专业文献数据分析结果输出图形类型控制包括主题聚类热力图、主题关联雷达图、科研机构关联网络图谱和主题演化路径等技术参数。分析数据输出模块包括分析结果输出报表类型的控制和分析结果输出链接接口的控制。分析结果输出报表类型的控制包括Excel、Word、PPT 等报表类型技术参数,分析结果输出链接接口控制包括Pajek、UciNet 和VosViewer 等技术参数。
2 主题词处理相关算法及数据分析过程模型构建
2.1 主题词处理相关算法
2.1.1 抽取算法PC-value
该文采用PC-value 算法以实现对样本海量文献数据中主题词的抽取、出现频次的揭示的技术目标[6]。首先根据样本海量文献数据的语义特征、字段描述构建文本特征提取特征词列表。用M表示预处理语料库,用a表示候选主题词,|a|指a的绝对长度,f(a)为a在语料库M中出现的频次,g(a)是包含a候选主题词的对应文档在语料库中出现的频次。用b表示提取的候选项,b包含a,f(b)是语料库中b的总频次。所有包含a的通过集合Ta描述,|Ta|指的是集合的出现频次。如式(1)所示:
2.1.2 主题词平面像素点密度算法Density
通过Density 算法计算从样本数据集合中抽取的主题词之间的位置关系和密度强度,进而根据密度值进行色彩渲染,确定主题词的坐标和每个主题词像素点的色彩参数,最终在客户终端呈现主题热力图[7]。具体算法过程为:
假设:n个主题词的坐标分别为(xi,yi),i=1,…,n,主题词之间的二维欧式距离平均值为Distance,每个主题词的数量为Numer,i=1,…,n,像素点Point的坐标(x,y),f(Numer)为主题词数量的标准化值;α、β为非负数,其取值不同,主题图效果不同,具体公式见式(2):
2.1.3 主题词强弱关联算法
通过主题词强弱关联算法可以揭示样本数据集合中主题词之间隐性关联程度,涉及最小支持度(Minimum-Support)和最小置信度(Minimum-Confidence)两个父参数,可进一步细化为两个子参数[8]:①发现频繁项目集;②生成关联规则。关联规则数据库标记为D,D={t1,t2,…,tk,…,tn},tk={i1,i2,…,im,…,ip},tk(k=1,2,…,n)称为事务(transactions),im(m=1,2,…,p)称为项目(item)。设I={i1,i2,…,im}为数据库D中全体项目组成的集合,I的任何子集称为D中的项目集(itemset),如|X|=k,则称集合X为k项目集(k-Itemset)。
定义1(支持度)设I1⊆I,项目集I1在数据集D上的支持度为包含I1的事务在D中所占的百分比,即:
定义2(频繁项目集)对于项目集I和事务数据库D,T中所有满足最小支持度的项目集,称为频繁项目集。在集合中抽取的所有不被其他元素包含的频繁项目集称为最大频繁项目集(MFI)或最大项目集(MLI)。
定义3(置信度)一个定义在I和D上的如I1⇒I2的关联规则通过满足一定的可信度、信任度或者置信度来给出。规则的置信度指包含I1和I2的事务数和包含I1的事务数之比,即:
2.2 数据分析处理过程模型构建
基于抽取算法PC-value、平面像素点密度算法Density 和强弱关联算法,该文构建了学科专业数据分析处理过程模型,如图2 所示,并对过程模型进行语义化描述。分析处理过程模型构建步骤如下:选择并获取数据集来源并对样本原始数据集进行数据清洗;对数据集相同字段(共同“域”)进行数据抓取、自然语言技术处理、时间切片、词规范化、模糊匹配和坐标定位等技术实现操作[9]。通过术语突变揭示研究前沿[10];通过主题聚类标识知识体系[11];通过主题演化模型揭示知识体系的演化路径视图[12]。
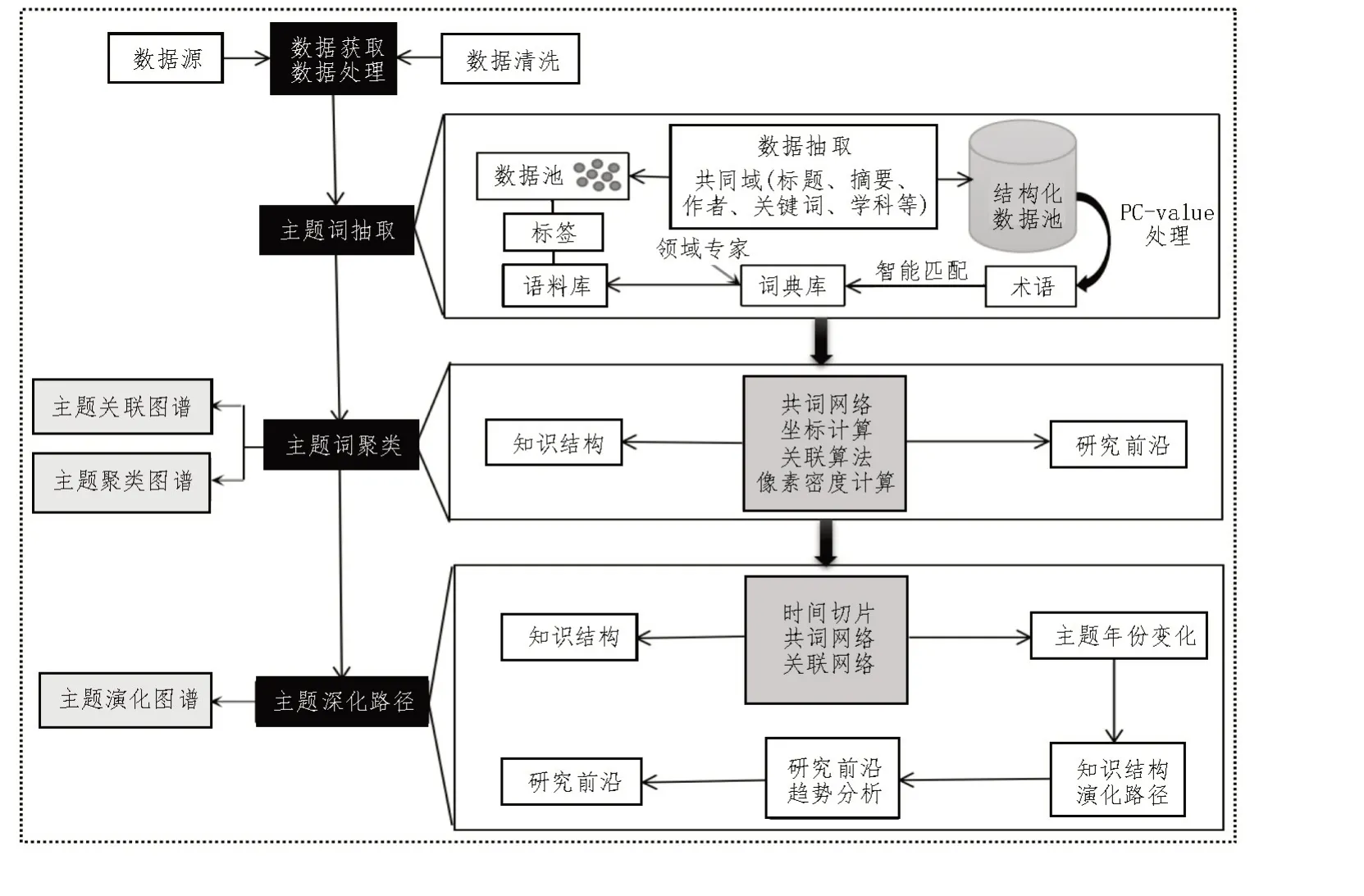
图2 数据分析处理过程模型(PM)
3 测试与分析
为了对设计的学科专业文献数据分析处理系统的功能框架和数据分析处理过程模型进行测试,选取来源于“web of science”平台的主题为“New energy materials”的2 632 条题录信息(含引文数据)为样本数据,以主题聚类、主题关联、科研机构关联和主题演化四个维度对系统功能架构和PM 模型进行测试和验证。
3.1 测试过程
3.1.1 主题聚类测试
通过抽取算法PC-value 并计算数据集中的候选主题词,按照出现频次确定最终的目标主题词。通过Density 算法确定目标主题词之间的逻辑关系、空间布局和坐标关系。根据主题词区域的密度值进行色彩渲染,主题词之间的空间分布位置越接近,表明它们之间的研究契合度越高,因此可形成样本数据的主题聚类热力图[13],如图3 所示。

图3 样本数据主题聚类热力图
通过综合分析得知:该知识领域可划分为三个聚类。第一个聚类(Group1)主要研究新能源材料的类型和分布,为最为核心的研究领域;第二个聚类(Group2)主要研究新能源材料所涉及到的技术、方法及理论,为比较重要的研究领域;第三个聚类(Group3)主要研究新能源材料的合成处理过程、转移传递过程及行业应用,为该领域新兴的研究分支。
3.1.2 主题关联雷达测试
根据主题词强弱关联算法计算并绘制样本数据的主题关联雷达图[14],雷达图中包含关联综合值(ASS 值)和中心度(C 值)两个技术参数,如图4 所示。雷达图中由里及外呈网状辐射结构,主题词在视图中越接近于辐射外沿,表示与其他主题词的关联趋势越显著,对应的ASS 值和C 值越高,反之亦然。依据ASS 值不低于0.6,C 值不低于0.75 的原则,计算并输出样本数据中的八个核心主题词。如表1所示。这些核心主题词构成该领域的研究“山峰”区域,此外进一步扩展语义分析得知,新能源材料领域的研究涉及化学、物理、材料、机械、电子等多领域,呈现多学科交叉融合研究的态势。
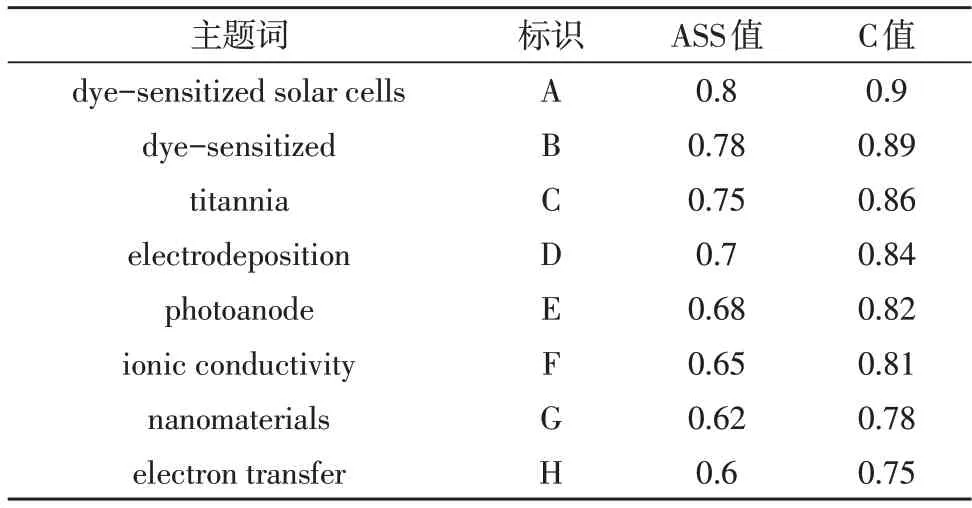
表1 样本数据核心主题词

图4 样本数据主题关联雷达图
3.1.3 科研机构关联测试
运用关联算法、坐标算法计算样本数据机构节点之间的合作关系,形成机构节点关联视图[15],如图5 所示,节点代表科研机构,节点的大小与机构发文量、被引频次呈正相关。节点之间的连线标识共引关系,共引程度通过连线的粗细体现[16]。共引关系网络可体现样本数据科研机构之间的合作关系,有助于发现高影响力的研究机构集群。通过综合分析结合图5 得知,样本数据形成三个研究子网络,分别为以中国科学院为核心的合作子网络(标识为A),A 网络中大连理工大学和瑞士联邦理工学院同核心节点存在显著的合作关系;以瑞士洛桑理工学院为核心的合作子网络(标识为B),B 网络中新加坡国立大学和伦敦大学帝国理工学院同核心节点存在显著的合作关系;以台湾大学为核心的合作子网络(标识为C),C 网络中英国提赛德大学和新加坡南洋理工大学同核心节点存在显著的合作关系。

图5 科研机构关联网络图谱
3.1.4 主题演化测试
对样本数据的主题词进行时间切片,形成样本数据主题演化路径折线图,如图6 所示。对样本数据主题演化路径进行分析有助于明晰研究前沿,进行趋势分析。经过分析得知,新能源材料领域经历了三个发展阶段:第一个发展阶段[2008-2013]重点研究储存和转换风能、水能、电能、太阳能等清洁能源的相对应新型材料;第二个发展阶段[2014-2018]重点研究LIB 锂离子电池、Ni/MH 电池等绿色二次储电电池,研究硅多晶材料、纳米电池材料等新型储存太阳能电池材料和技术;第三个发展阶段[2019-2022]重点研究二代纳米材料、石墨烯、半导体、光伏材料、光敏材料、高分子材料、超导材料和核材料等新型能源和材料。

图6 主题演化路径折线图
3.2 测试分析总结
通过选取海量样本数据并从主题聚类、主题关联、科研机构关联和主题演化路径四个维度对该文设计的系统功能架构和PM 模型进行测试。
按照设计的系统功能架构:在数据输入层(IN)对样本数据进行结构化控制、数据内容清洗、数据格式转换等数据预处理操作,该测试中将样本数据转换为“TXT”格式,挖掘“全字段”著录数据和引文数据并进行清洗操作,得到规范化的待处理数据,在数据分析层(AN)对样本数据进行不同维度、不同类型的数据耦合关联处理,该测试中主题聚类采用三维分析、主题关联采用二维分析、科研机构关联采用三维分析、主题演化采用一维分析,采用关系聚类相关算法揭示样本数据的科研关系。在结果输出层(OU)控制样本数据的图形类型和数据输出技术参数,该测试中控制节点的中心度值和属性参数,确保输出分辨率高、识别度高和可用性强的图形结果。系统整体功能架构合理,内部数据处理、数据分析逻辑关系和层级关系清晰,支持多种维度、多种算法对海量数据进行深度分析和关联揭示,并具有良好的结果控制和结果输出效果。
依据数据分析处理过程模型(PM):运用PCvalue 算法对数据集中的主题词进行抽取和共现计算,提取的主题词均有语义特征和显著性。运用Density 算法计算和定位主题词的空间位置和颜色渲染值,运用关联算法计算主题词之间关联关系,进而进行主题聚类分析。运用时间切片方法挖掘样本主题数据的知识结构演化路径,进而揭示研究前沿特征。通过测试得知:设计的PM 模型具有良好的数据适用性,主题聚类效果良好,密度算法能够计算出热力值层级明显的主题聚类热力图,关联算法能够计算出主题关联趋势明显并体现主题词的ASS 值、C 值的雷达图。科研机构关联网络图谱聚类效果良好,节点之间的引用链条清晰,形成不同研究分支的科研机构聚类子网络。时间切片方法实施效果良好,能够清晰地挖掘、揭示样本主题的演化规律和演化路径,形成的演化路径折线图较好地反应样本数据主题领域的不同发展阶段及研究侧重点。
4 结束语
经过选取样本数据并从多种维度对该文设计的系统功能架构和PM 模型进行测试得知:系统功能架构合理,数据处理逻辑关系清晰,结果控制和输出效果良好。PM 模型在主题挖掘、数据聚类、关联揭示和路径揭示等数据分析处理中具有良好的适用性和实施效果,数据关联关系链条清晰,形成显著的主题聚类效果,高效地揭示知识主题的研究路径。系统功能框架和PM 模型测试结果均达到预期效果。该文设计的学科专业文献数据分析处理系统功能架构和PM 模型可运用于图书情报学科、信息学科和计算机等学科的海量文献数据的分析与处理,通过系统的大数据计算与深度可视化分析有助于科研人员揭示和挖掘所属学科专业或主题领域的研究分支、研究现状、科研关系、研究脉络和演化路径,亦可准确判断科研竞争力并寻找潜在的合作科研机构。
猜你喜欢
当代陕西(2019年15期)2019-09-02 01:52:00
学苑创造·A版(2018年11期)2018-02-01 06:29:20
电子测试(2017年15期)2017-12-18 07:19:27
读者(2017年5期)2017-02-15 18:04:18
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
西北工业大学学报(2015年1期)2015-02-22 00:29:19
西北工业大学学报(2015年1期)2015-02-22 00:29:19
沈阳医学院学报(2014年4期)2014-12-27 13:44:34
疑难病杂志(2014年12期)2014-04-16 05:19:35
