
基于半监督学习的新能源运行错误数据辨识系统
2024-01-05 12:05:44许力方
电子设计工程 2024年1期
许力方,杨 正,姚 阳
(国网冀北综合能源服务有限公司,北京 100142)
半监督学习算法将监督学习与无监督学习思想融合在一起,在应用过程中,大量使用标记数据与未标记数据来完成系统主机所分配的模式识别工作。与其他类型的识别算法相比,半监督学习算法依据假设模型判断数据信息参量所处的传输等级,一般来说,传输速度越快的数据信息,其自身所具备的传输等级也就越高,在半监督学习算法的作用下,系统主机在识别该数据时所消耗的时间也就越长[1-2]。当信息与信息之间的关联程度较小时,半监督学习算法对于信息参量的定义标准也就相对较为宽泛,同一识别原则的信息参量都可以被存储在同一个数据集合之中。
新能源具有资源丰富、碳元素含量低、分布广泛等多项应用优势[3]。随着新能源资源使用量的增大,其在运行过程中可能会出现大量的错误数据,这些错误数据与常规信息参量混合在一起,会造成系统主机辨识能力的不断下降,并最终导致数据信息错误分拣行为的出现。改进式k-prototypes聚类型系统虽然能够对常规信息与新能源运行错误数据进行分类存储,但由于处理器元件的执行运转行为相对受限,故而在精准检测运行错误数据参量方面的处理能力相对有限[4]。为解决上述问题,以半监督学习算法为基础,设计一种新型的新能源运行错误数据辨识系统。
1 系统硬件设计
1.1 PT-LAB处理平台
PT-LAB 处理平台结构如图1 所示,其是一种嵌入式硬件应用结构,在新能源运行错误数据辨识系统中,负责对待识别信息参量进行聚合处理[5]。由于相邻端口节点之间的连接方式并不唯一,所以PTLAB 处理平台也具有极强的运行灵活性。

图1 PT-LAB处理平台结构
在PT-LAB 处理平台中,目标机与I/O 接口作为一个结构模块,负责分析数据传输行为,并可以从已存储数据文件中提取待处理信息参量[6];数据分辨结构、新能源运行机制、聚合节点作为另一个结构模块,负责分析新能源运行错误指令的传输情况,并可以根据系统主机的应用能力更改待处理新能源运行错误数据的实时存储位置。
1.2 数据分辨模块
数据分辨模块可以在半监督学习算法的支持下,借助传输信道组织,提取PT-LAB 处理平台内部已存储的新能源运行错误数据参量,并可以将未完全消耗的信息文本反馈至下级运行指令分析模块之中[7-8]。在实际应用过程中,数据分辨模块的搭建必须完善如下几个结构单元之间的实时连接关系。
1)ExcuteUpdate 设备:负责对新能源运行错误数据进行入库处理,借助聚合节点与PT-LAB 处理平台建立连接关系,可以在调度待处理信息参量的同时,提升系统主机对于新能源运行错误数据的辨别能力;
2)search 设备:负责更新待检测的新能源运行错误数据参量,在PT-LAB 处理平台的作用下,该设备结构可以更改数据信息文本的传输形式;
3)setCell 设备:负责连接ExcuteUpdate 设备与search 设备,可以在调取PT-LAB 处理平台中已存储新能源运行错误数据信息参量的同时,扩充与系统数据库主机匹配的信息承载能力。
1.3 运行指令分析模块
运行指令分析模块由bak 设备阶层、核心应用阶层、数据库应用阶层三部分共同组成。其中,bak分析设备负责对新能源运行错误数据进行分流处理,并可以按照分析指令的形式,将完成初步甄别的信息参量反馈至核心应用阶层之中[9-10]。核心应用阶层可以在分辨运行指令文件的同时,将新能源运行错误数据分成多种存储类型,并通过正向反馈的方式,将已接收执行指令反馈给下级应用主机。运行指令分析模块的结构如图2 所示。

图2 运行指令分析模块的结构
数据库应用阶层存在于运行指令分析模块最下端,以数据库主机作为核心应用结构,可以完整存储上级bak 设备与核心应用设备输出的新能源运行错误数据。
2 系统软件设计
在各级硬件执行结构的支持下,按照半监督支持向量求解、UCI 学习参数计算、数据库E-R 图建立执行流程,实现系统的软件执行环境搭建。两相结合,完成基于半监督学习的新能源运行错误数据辨识系统设计。
2.1 半监督支持向量求解
对于新能源运行错误数据辨识系统而言,半监督支持向量的应用目的在于建立低维输入数据与高维输出数据之间的非线性映射关系,由于系统主机的执行能力必须保持绝对稳定的存在状态,所以在提取半监督支持向量时,要求低维数据与高维数据之间的映射关系也必须保持稳定[11-12]。设i表示一个随机选取的新能源运行错误数据参量,e表示信息规划系数的最小取值结果,ui表示基于参量i的数据信息监督特征,χ表示信息参量监督系数,R表示半监督学习行为指令的惯常赋值。联立上述物理量,可将新能源运行错误数据的半监督执行指令运行表达式定义为:
新能源运行错误数据辨识系统的半监督支持向量定义表达式为:
随着系统主机内新能源运行错误数据累积量的增大,半监督支持向量的赋值结果也会不断增大。
2.2 UCI学习参数计算
UCI 学习参数决定了系统主机对于新能源运行错误数据的辨识与处理能力,在已知半监督支持向量取值结果的情况下,UCI 学习参数的计算数值越大,系统主机对于新能源运行错误数据的辨识与处理能力也就越强[13]。由于新能源运行错误数据传输行为具有明显的可变性,所以在搭建辨识系统应用环境时,要求UCI 学习参数必须反映出待处理信息参量的实时排列与分布状态[14]。设s1、s2表示两个随机选取的新能源运行错误数据辨识参量,且s1≠s2恒成立,β表示半监督学习行为的表现系数,a表示数据信息参量的拆分系数。联立上述物理量,可将UCI 学习参数求解式定义为:
式中,ϕ表示新能源运行错误数据在辨识系统主机中的学习特征值。在求解UCI 学习参数表达式时,要求系数β、系数a的取值必须同时大于自然数“1”。
2.3 数据库E-R图建立
在辨识系统中,数据库主机负责存储新能源运行错误数据,并可以根据提取规则的不同,建立与已存储信息参量相关的文件执行指令[15-16]。E-R 图(如图3 所示)决定了数据库主机的运行能力,在半监督学习算法的作用下,新能源运行错误数据所属位置必须得到清晰标注,系统主机才有可能具备准确辨识数据信息参量的能力[17-18]。若将半监督支持向量、UCI 学习参数看作已知条件,则可认为待存储的新能源运行错误数据总量越大,数据库主机所具备的信息转存能力也就越强。

图3 数据库E-R图
至此,完成系统软、硬件执行环境的搭建,在半监督学习算法原则的支持下,实现新能源运行错误数据辨识系统的顺利应用。
3 实例分析
按照图4 所示流程对新能源运行错误数据进行分流处理;然后,分别应用实验组(基于半监督学习的新能源运行错误数据辨识系统)、对照组(改进式k-prototypes 聚类型系统)应用系统对所选实验主机进行控制;最后,对比实验组、对照组实验变量的数值变化情况。
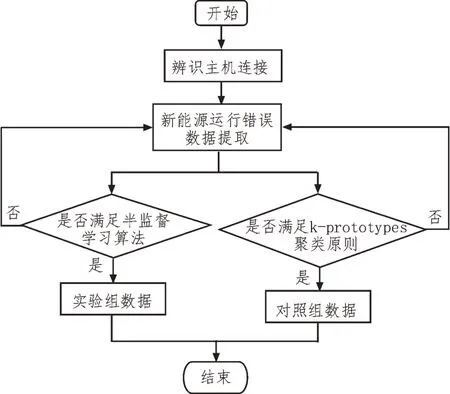
图4 实验数据处理流程
系统主机对于待传输新能源运行错误数据的提取准确度μ可表示为:
其中,μ1表示主动分辨系数,μ2表示被动分辨系数。
图5、图6 反映了实验组、对照组μ1与μ2系数的具体数值变化情况。

图5 主动分辨系数μ1

图6 被动分辨系数μ2
分析图5 可知,在整个实验过程中,实验组主动分辨系数的均值水平高于对照组。
分析图6 可知,实验组、对照组被动分辨系数均呈现出来回波动的数值变化状态,但明显实验组系数的均值水平更高。
联合图5、图6 对准确度指标μ进行计算,实验详情如表1 所示。

表1 准确度指标μ
分析表1 可知,当实验时间等于35 min 时,实验组准确度指标的最大值为91.5%;当实验时间等于15 min 时,对照组准确度指标的最大值为71.2%,与实验组最大值相比,下降了20.3%。
综上可知,在半监督学习算法的作用下,系统主机对于新能源运行错误数据的提取准确度最大值超过了90.0%,在解决数据信息错误分拣问题方面具有较强的实用性价值。
4 结束语
该文依照半监督学习算法,规范PT-LAB 处理平台、数据分辨模块与运行指令分析模块之间的实时连接关系,又联合半监督支持向量与UCI 学习参数,完善数据库E-R 图的表现形式,优化设计了新能源运行错误数据辨识系统。在实用性方面,设计系统主机对于待传输新能源运行错误数据的提取准确度均值接近90%,能够较好避免数据信息错误分拣行为的出现。
猜你喜欢
科普童话·神秘大侦探(2023年1期)2023-05-30 12:48:10
测控技术(2018年5期)2018-12-09 09:04:26
电子测试(2018年18期)2018-11-14 02:30:34
瞭望东方周刊(2016年40期)2016-11-02 18:30:31
物理实验(2015年9期)2015-02-28 17:36:51
风能(2015年4期)2015-02-27 10:14:36
风能(2015年4期)2015-02-27 10:14:34
数学年刊A辑(中文版)(2014年4期)2014-10-30 01:50:32
声学技术(2014年2期)2014-06-21 06:59:14
机电信息(2014年27期)2014-02-27 15:53:56
