
基于随机森林和多直方图修改的可逆信息隐藏
2024-01-05 02:01李丹阳李青岩
集美大学学报(自然科学版) 2023年5期
李丹阳,李 琳,李青岩
(1.集美大学理学院,福建 厦门 361021;2.集美大学计算机工程学院,福建 厦门 361021)
0 引言
随着互联网的蓬勃发展,数字图像信息安全问题受到了广泛关注。数字图像信息安全技术的研究主要包括两方面:图像加密和图像信息隐藏[1]。通常,信息隐藏技术会导致图像的永久性失真。为了解决这个问题,可逆信息隐藏(reversible data hiding,RDH)技术被提出,并引起了许多学者的注意。可逆信息隐藏技术可以从载密的图像中准确无误地提取嵌入的信息并恢复载体图像。它在军事、医疗、法律服务等内容敏感领域有着重要的应用需求[2]。
现有RDH技术大致可分为三类,分别基于无损压缩(lossless compression,LC)[3]、差分扩展(difference expance,DE)[4-5]和直方图移位(histogram shifting,HS)[6-8]。无损压缩方法对载体图像进行压缩获得空间以嵌入信息,但这种方法只能提供有限的嵌入容量。DE扩展技术在像素对上执行,通过扩展其差分将1 bit信息嵌入到每个选定的像素对中。与基于无损压缩的RDH相比,Tian[4]的基于差分扩展的方法可以提供更高的嵌入容量和峰值信噪比。随后,Thodi等[5]提出预测误差扩展方法(prediction error expansion,PEE),用预测误差代替差分扩展中的差值,PEE可以更加充分地利用图像的空间冗余。Ni等[6]提出直方图移位的方案,先生成直方图,然后通过修改直方图嵌入秘密信息,但是该方法的嵌入容量受生成直方图的峰值位的像素数影响。后来,研究者们将HS与PEE结合,构造了许多改进的方法。但是基于单直方图的方法,仅仅是收集图像的每个像素的预测误差,并未充分考虑到图像局部纹理的变化。于是,2015年Li等[9]提出基于多直方图修改的可逆信息隐藏技术(multiple histogram modification,MHM),根据每个像素的上下文计算其复杂度,并将具有给定复杂度的像素收集在一起来生成预测误差直方图(prediction error histogram,PEH),通过设置复杂度阈值,生成直方图序列,然后采用暴力搜索的方法在每个生成的直方图中选择两个扩展位(嵌入点)实现数据嵌入。MHM比其他基于单个PEH的方法具有更好的性能,特别是在低有效载荷方面。基于多直方图的可逆信息隐藏,关键是将具有相似上下文特征的像素聚集到相同的直方图中。Wang等[10]提出一种新的多直方图可逆信息隐藏方案,它通过设计一系列特征,使用模糊C-均值聚类,从而构造多直方图。文献[11]在文献[10]的基础上优化聚类的特征,使用K-Means聚类构造多直方图。尽管他们的方法与文献[9]相比,性能有所提升,但是为了保证可逆性,这些方法都采用两阶段嵌入的技术,只有与目标像素不同层的像素被用来设计特征,因此忽略了目标像素与其同层像素之间的相关关系。随机森林[12]是一种通过集成学习的思想构造多棵独立决策树的算法,其输出的结果由随机森林中每棵决策树输出结果投票而定。由于随机森林是用一种随机方式建立的,可以降低模型过拟合的风险。为了充分利用目标像素与其周围像素之间的相关性,本文提出一种基于随机森林的多直方图构建方法。
1 本文提出的算法
本文提出的基于随机森林的多直方图生成方法主要分为两个步骤:聚类和训练随机森林。随机森林分类器通常需要大量的数据进行训练,和文献[13]一样,本研究以Kodak图像集的24张图像作为训练数据。首先,设计能代表目标像素上下文像素分布的聚类特征,使用K-Means聚类算法标记具有相似上下文的像素;然后,从图像数据集中提取大量的上下文信息,即目标像素周围的像素特征,作为随机森林的输入,以聚类得到的结果标签作为随机森林的目标输出;最后,调整随机森林的相关参数,训练得到最优的随机森林模型。
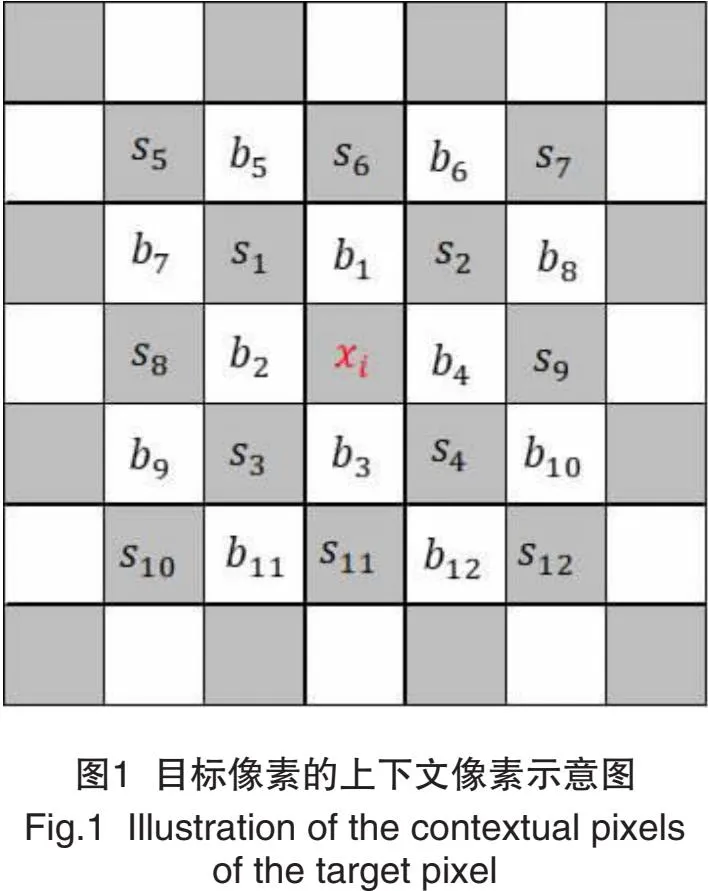
1.1 聚类特征的设计
基于预测误差扩展和直方图移位的可逆信息隐藏,直方图越清晰,其性能越好。因此,MHM方法中多直方图生成的关键点是使生成的每个直方图尽可能地清晰,也就是说,具有相似上下文的像素应该尽可能聚在同一类。目标像素所在块的局部特征设计得越精确,聚类结果也会越精确。在Wang等[10]的方法中,虽然设计了10个特征用于聚类,但是为了保证可逆性,这10个特征的计算只涉及到与目标像素不同层的像素,有一些与目标像素邻近但属于同层的像素值并未考虑到(如图1白色集合中的像素)。因而本研究认为这些特征不能完全反映每个区块的局部特征。由于本文所提出的方法的可逆性由随机森林的输入特征保证,因此设计的聚类特征可以充分利用目标像素周围的像素,包括同层的邻近像素。
在本文中,设计了4个与每个块的纹理复杂度密切相关的新特征,即:1)以目标像素xi为中心的3 px×3 px像素块的方差fi,1;2)以目标像素xi为中心的5 px×5 px像素块的熵fi,2;3)以目标像素xi为中心的5 px×5 px像素块的复杂度,即像素块中水平和垂直相邻像素的绝对差值之和fi,3;4)局部均值fi,4。这4个特征充分利用目标像素周围的像素,提高了聚类性能。
本算法用方差来衡量像素块中像素值的波动情况。方差越大,说明像素块中的像素值波动越大,像素块中像素值分布越复杂。方差计算公式为:
(1)
(2)
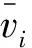
信息熵是用来衡量不确定性的指标,情况越混乱,信息熵也就越大,反之越小。在这里可以理解为,熵越大,像素块像素值分布的越混乱,图像越复杂;反之,熵越小,像素块像素值分布越集中,图像越平滑。熵计算公式为:
(3)
其中:count(bk/sk)代表像素值bk/sk在以目标像素xi为中心的5 px×5 px像素块中出现的次数。
复杂度计算公式为:
fi,3=w3(|s5-b7|+|b7-s8|+|s8-b9|+|b9-s10|+|b5-s1|+|b2-s3|+|s3-b11|+|s6-b1|+|b1-x|+|x-b3|+|b3-s11|+|b6-s2|+|s2-b4|+|b4-s4|+|s4-b12|+|s7-b8|+|b8-s9|+|s9-b10|+|b10-s12|+|s5-b5|+|b5-s6|+|s6-b6|+|b6-s7|+|b7-s1|+|s1-b1|+|b1-s2|+|s2-b8|++|s8-b2|+|b2-x|+|x-b4|+|b4-s9|+|b9-s3|+|s3-b3|)+|b3-s4|+|s4-b10|+|s10-b11|+|b11-s11|+|s11-b12|+|b12-s12|。
(4)
局部均值计算公式为:
(5)
式(1)~(5)中:w1、w2、w3、w4、w5为权重值,权重值初始值都为1,随后根据多次实验的结果进行调整,以得到更好的聚类结果;聚类的类别数参考了文献[13],设置为18。
1.2 基于随机森林的分类模型
随机森林模型训练速度快,且模型简单易于理解,综合考虑拟合能力和训练难度,本文选择用随机森林模型构建多直方图。随机森林的构造包含6个步骤:
1)从原始训练集中随机有放回地选择k条数据;
2)从原始的K维特征中,随机选取m个特征做节点分裂属性;
3)训练决策树;
4)重复1)~3)步构造n个决策树;
5)集成上述步骤生成的n个决策树,构建随机森林;
6)以n个决策树预测结果的众数作为随机森林的最终输出结果。
在本算法中,以Kodak24图像集的24张图像为训练数据,以由目标像素x上下文像素组成的向量B=(b1,b2,…,b12)(见图1)作为输入特征,以聚类得到的类别标签为输出目标,构建随机森林分类模型。随机森林的输入特征均为与目标像素不同层的像素,因此在嵌入信息前后,对于同一个目标像素随机森林可以得到相同的预测类别,使可逆性得以保证。
2 嵌入和提取过程
2.1 辅助信息
在可逆信息隐藏中,为了确保接收方可以无损提取信息和恢复图像,需要收集一部分辅助信息,作为有效负载的一部分嵌入到载体图像中。本方法中需要使用的辅助信息包括:
1)压缩后的位置图。在本方法中,由于每个像素值最多加或减1个单位,为了避免像素值超过[0,255]的范围,发生上溢或者下溢,像素值为255的将更改为254,像素值为0的将更改为1。位置图用来记录这些像素的位置,更改的像素在位置图中标记为1,而其他像素标记为0,然后使用算术编码方法对位置图进行压缩。
2)位置图的长度(log2N,bit,N为目标图像像素数目的一半)。
3)最优嵌入点bn,1≤n≤M(4M,bit,M为生成直方图的个数,M=18)。
4)随机森林分类得到的标签与按照熵排序之后的标签对应关系(5M,bit)。
5)嵌入结束的位置Nend(log2N,bit)。
2.2 嵌入过程
本文采取基于菱形预测的双层嵌入技术,在嵌入信息时,首先要把图像像素划分为两层:空白层和阴影层,如图1所示。第一层首先嵌入一半有效载荷,剩下的一半嵌入第二层。由于第二层的嵌入过程与第一层相似,因此本研究仅以第一层为例,阐述具体的嵌入过程(见图2)。为了保证可逆,要保留前后两行前后两列的像素,用于嵌入辅助信息。
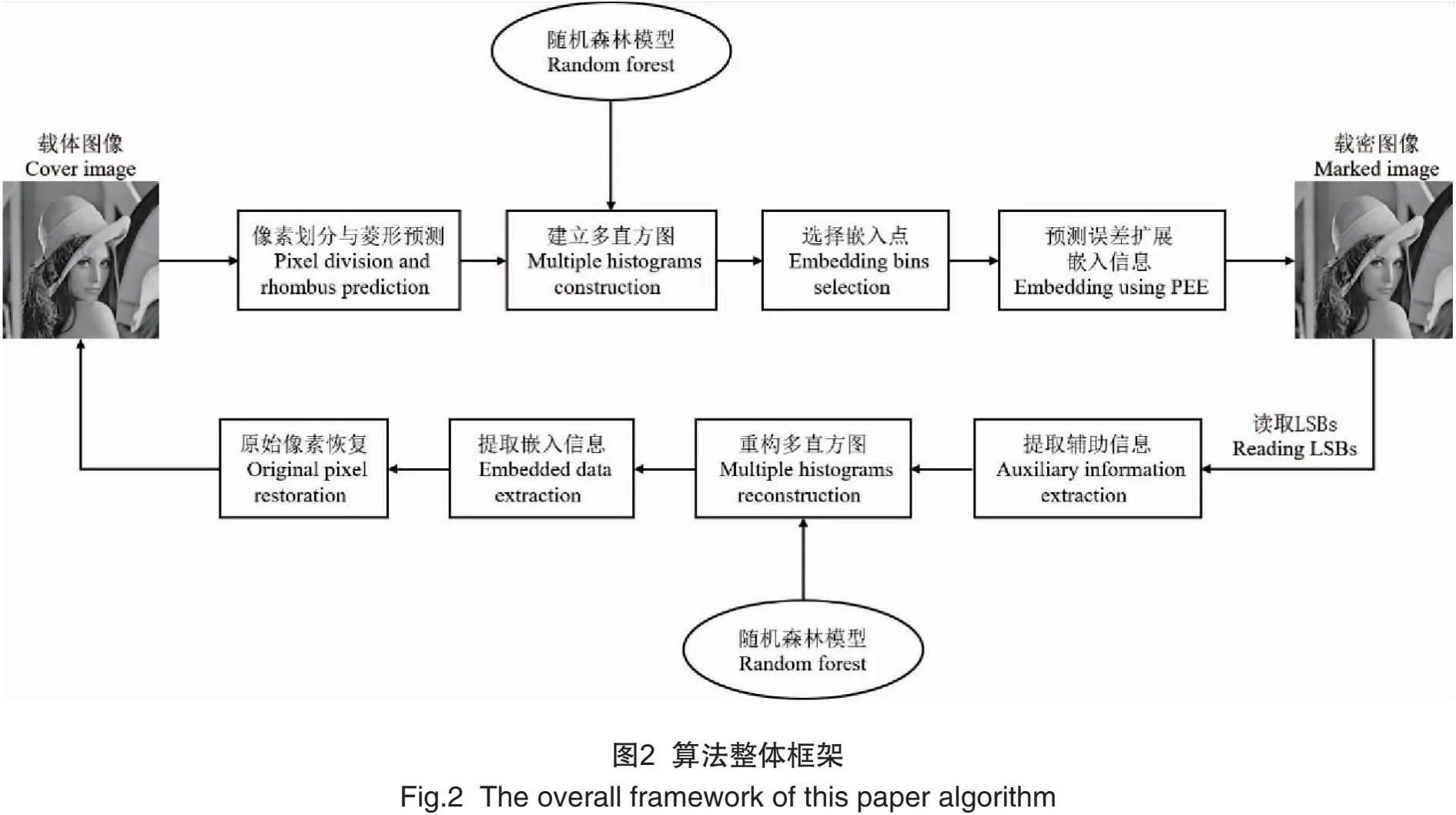
1)菱形预测
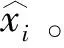
2)根据随机森林分类模型构建M个子直方图
根据1.2设计的随机森林模型,提取随机森林需要的12个上下文像素作为输入特征,将所有预测误差分为M类,每个类将生成一个直方图。生成M个直方图之后,计算每个直方图的熵,按照熵从低到高的顺序重新对直方图进行排序,决定嵌入信息的先后顺序。
3)选择M对嵌入点
为了满足率失真模型,即在嵌入容量满足给定的有效载荷情况下,使嵌入失真与嵌入容量的比率最小。使用文献[13]中选择扩展嵌入点的方法,为每一个直方图确定一对嵌入点,用(ak,bk)表示。
4)嵌入信息——基于直方图平移
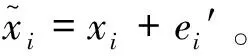
5)获得载密图像
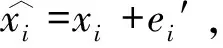
2.3 提取过程
为了保证可逆,信息的提取过程要与信息的嵌入过程相反,需要先提取第二层的嵌入信息,再提取第一层的。因为提取的步骤相似,本文仅以第二层的数据提取过程为例,展开详细介绍。
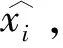
与嵌入信息时相同,提取随机森林需要的12个上下文像素,利用随机森林模型将所有预测误差分为M类,每个类生成一个直方图。
根据辅助信息获取直方图的嵌入顺序和每个直方图的嵌入点,提取嵌入的信息。以像素xi′的提取过程为例,假设xi′属于直方图hz,对应的嵌入点为(az,bz),预测误差为ei′,可以根据式(6)~(8)提取嵌入的秘密信息并恢复原始像素。
(6)
(7)
(8)
3 实验结果与分析
本文的随机森林模型通过scikit-learn机器学习框架用Python3.8构建,RDH过程在Matlab R2018a上完成。随机森林模型的构建需要一定的数据支持,即使图像像素不同,上下文分布特征也会具有很高的相似性,因此以Kodak24图像集的24张图像为训练数据,构建随机森林模型。为了评估所提出方案的性能,自USC-SIPI图像数据库中选择4张具有不同纹理特征的512 px×512 px像素大小的灰度图像,即Lena、Baboon、Boat、Elaine。
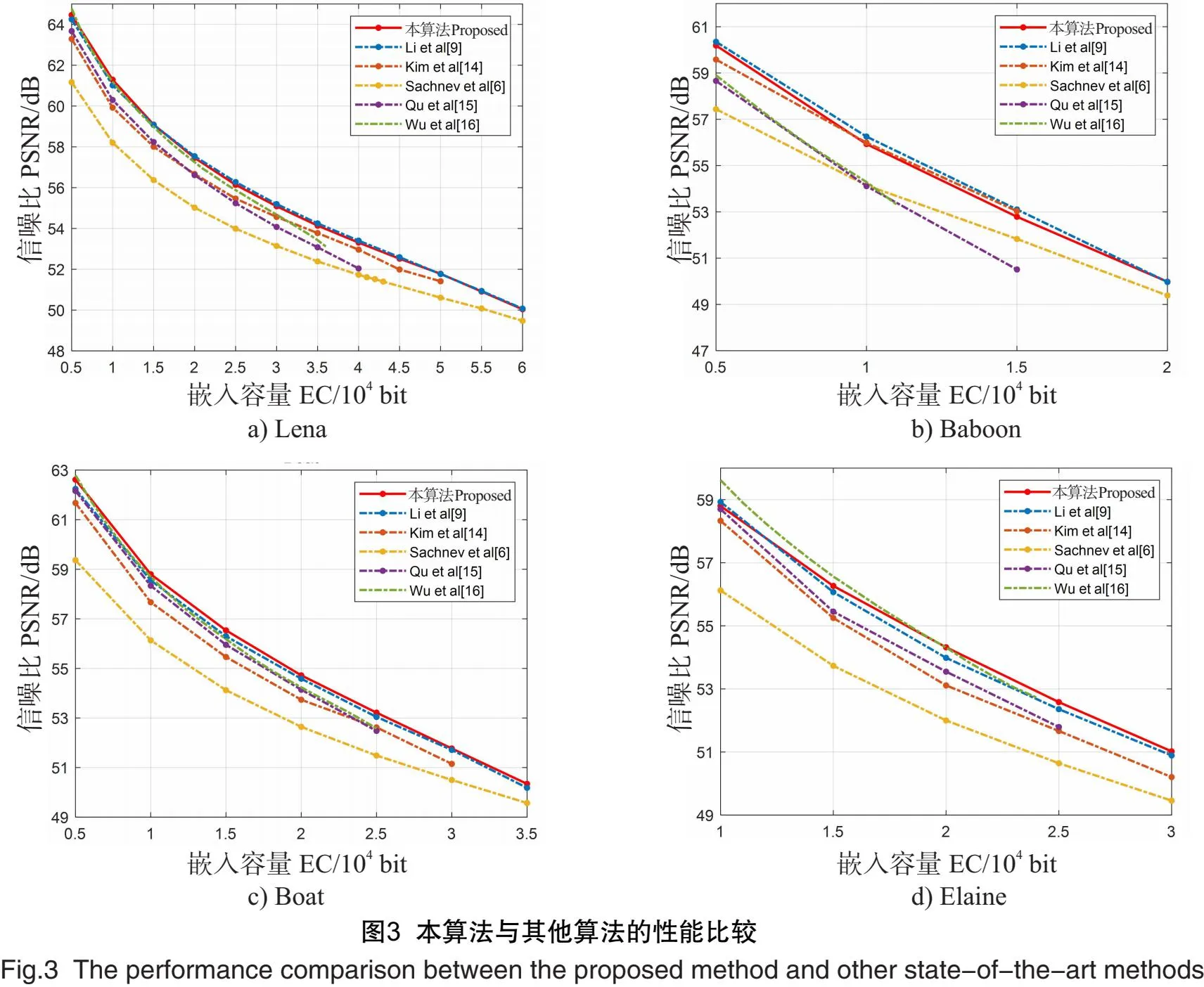
为了说明所提出方案的优越性,将本方案与Li等的传统多直方图方法[9]、Kim等的基于倾斜直方图的方法[14]、Sachnev等基于菱形预测的方法[6]、Qu等基于像素值排序的方法[15]、Wu等基于改进像素值排序的方法[16]等5种不同的先进方案进行了率失真性能对比实验。图3是几种不同方法不同嵌入容量(embedding capacity,EC)的峰值信噪比(peak signal noise ratio,PSNR)曲线。PSNR是常用的可逆信息隐藏方案评价指标,PSNR的值越高,说明载密图像和原始载体图像越相似,所对应的方法性能就越好。
从图3可以看出,本文提出的方法在大部分情况下都优于4个文献[6,14-16]的方法,原因在于这4种方法都是基于单一直方图进行信息嵌入,直方图被固定地修改,在建立直方图时并未考虑到图像像素分布的差异。对于图像Elaine,在低嵌入容量时,文献[16]的PSNR值虽然高于本文的方法,但是从图3中可以看出,文献[16]的最大嵌入容量较小,在实际应用过程中可能不能满足嵌入容量要求。在大多数情况下,本文提出的方法优于Li等提出的传统多直方图方法[9]。文献[9]未考虑图像内容的差异,而是根据目标像素的局部像素分布复杂程度平均划分像素,从而生成多直方图。本文提出的随机森林智能分类器可以通过学习先验知识,根据图像内容自适应地构建多直方图,因此取得了更好的性能。以Lena图为例,当嵌入容量为10 000 bit时,本方案的峰值信噪比比Li等[9]的方案提高了约0.27 dB,比其余4个方案也都更好。
4 结论
本文采用更能代表局部像素分布情况的特征,利用聚类算法标记目标像素,训练随机森林分类模型用于构建多直方图。与传统的基于多直方图的可逆信息隐藏方案相比,本方法结合K-Means聚类和随机森林机器学习算法,生成了更清晰的直方图,从而实现高效的可逆信息隐藏。未来,将进一步研究如何设计更好的聚类特征以及训练更高效的分类模型。
猜你喜欢
艺术家(2023年8期)2023-11-02
湘潭大学自然科学学报(2022年2期)2022-07-28
小哥白尼(军事科学)(2022年2期)2022-05-25
红领巾·萌芽(2019年8期)2019-08-27
摄影之友(影像视觉)(2018年12期)2019-01-28
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
潍坊学院学报(2016年6期)2016-04-18
CHIP新电脑(2016年3期)2016-03-10
计算机工程(2015年8期)2015-07-03
