
利用集成OS-ELM的不平衡数据流分类与存储方法
2024-01-02 08:35汤程皓卢诚波
软件导刊 2023年12期
汤程皓,梅 颖,卢诚波
(1.浙江理工大学 计算机科学与技术学院,浙江 杭州 310018;2.丽水学院 数学与计算机学院,浙江 丽水 323000)
0 引言
在生产生活的许多领域,无时无刻都在产生具有实时、高速、海量等特点的数据流[1],例如传感器实时监测数据、网络流量监测、交通监控等。其中,类分布不平衡的情况经常出现,例如网络入侵检测、垃圾邮件检测。在网络空间中,少数入侵事件隐藏在正常访问请求中,具有高度隐蔽性[2],在大量正常邮件中也混杂着少量垃圾邮件。
数据流类分布不均衡通常是指在数据流中,少数类样本数量远小于多数类样本数量,多数类样本的分布在数据流中占有绝对的统治地位。目前,数据流分类算法一般针对类分布基本均衡的数据流所设计,如果在类不平衡数据流上使用,得到的决策边界会偏向于多数类,因此对少数类的分类准确率往往较差,存在非常严重的分类损失。在医疗诊断、信用卡欺诈交易监测等应用领域,正确识别少数类具有重要的现实意义。
然而,目前大多数针对不平衡数据流分类算法的研究都聚焦在提升分类性能[3-4],较少关注数据流中历史数据的存储及查询方法。为了更有效地利用有限的计算机性能资源,本文设计了一种基于集成欠采样与在线序列超限学习机(Ensemble Undersampling and OS-ELM,EU-OSELM)方法,在提升分类性能的同时,可减少对计算机内存的占用。
1 相关研究
目前,在提升不平衡数据流分类性能方面,在数据层面可使用预处理技术处理原始数据,利用重采样方法优化样本空间,降低数据分布的不平衡程度,减轻模型在训练中因偏态类分布对结果的干扰。重采样方法可分为过采样和欠采样[5-6]。Chawla 等[7]提出的SMOTE 方法是其中最具有代表性的一种方法,使用线性插值在两个少数类样本间添加人工合成的样本使类分布平衡,方法简单且鲁棒性强。在SMOTE 方法基础上,Han 等[8]提出Borderline-SMOTE 方法,仅对分布在分类边界的少数类样本进行过采样。樊东醒等[9]提出一种改进K 中心点算法的过采样方法,首先选择合适进行聚类采样的区域,然后在聚类基础上进行加权过采样。He 等[10]提出ADASYN 算法可自适应地确定过采样少数类时需要生成的样本数量,多数类在进行简单的欠采样时也可降低数据分布的不平衡程度,但由于潜在特征损失,无法充分利用多数类特征,可能会导致模型学习不充分,影响预测准确率。Hou 等[11]提出一种欠采样方法,在保留有效样本信息的同时删除噪声。Ng等[12]先对多数类样本进行聚类,然后选择最具标识性的样本计算敏感度,接下来选择所需样本。文献[11、12]的算法均针对性地进行欠采样,可使采样结果尽量保留样本的关键特征信息。于艳丽等[13]提出一种基于K-means 聚类的欠采样方法,根据多数类样本和簇心距离选择所需样本。
在算法层面,可改进、集成分类算法,使算法更符合在不平衡数据流上分类的要求,以提升分类精度。一般通过集成学习提升算法分类性能。Wang 等[14]结合过采样、欠采样和SMOTE 的重采样方法,提出适用于多分类情况下的SMOTEBagging 集成学习方法。TAO 等[15]提出一种基于自适应代价权重的支持向量机代价敏感集成算法。Chen等[16-18]提出REA、SERA 和MuSeRA 一系列针对不平衡数据流的学习算法。REA 利用KNN 算法从保存的少数类样本中选择一部分样本与当前数据块合并训练基分类器;SERA 利用少数类样本间的相似程度选择样本,以平衡训练数据集;MuSeRA 在SERA 基础上引入权重机制训练集成分类器。以上算法的共同特点均需保存全部历史数据中的少数类样本。
然而,以上类处理方法均存在共同缺陷,即不符合数据流单通道特征,正常情况下只有当数据第一次到达时才能对其进行处理。同时,REA、SERA 和MuSeRA 算法在训练过程中需不断保存历史少数类样本,随着数据不断到达,将耗尽内存空间[19],在某些需要低成本部署的应用场景下,该问题将尤为严重。
2 通用框架集成算法与OS-ELM
2.1 通用框架集成算法
算法由采样和集成(Sampling and Ensemble,SE)两部分组成[20]。数据以块形式到达,每接收到一个数据块S,将数据分成少数类集合P和多数类集合Q。然后,将少数类样本全部保存为一个数据集,随着数据块不断到达,可将少数类的集合表示成AP={P1,P2,...,Pm-1}。接下来,将最新到达的数据块Sm分成Pm、Qm,Pm加入到少数类集合中,集合更新为{P1,P2,...,Pm},集合中样本数为np,在多数类上进行随机欠采样得到Qm的一个子集O,使用分布率r、np控制采样,得到的多数类样本数量为nq=np/r。最后,获得用于训练基分类器的数据集{O,AP}。
根据设定基分类器的数量k、nq,在多数类Qm上进行k次随机不放回欠采样。因此,每个基分类器所用数据集中的多数类样本完全不相交。根据所生成的k个数据集,训练k个基分类器C1,C2,...,Ck,得到一个集成分类器。
2.2 OS-ELM
超限学习机(Extreme Learning Machine,ELM)[21]是一种基于单隐层前馈神经网络的学习算法,结合最小二乘法计算输出权重,随机设置输入权重和偏置,且后续无需迭代调整。ELM 能进一步被描述为一个线性参数模型,输出权重具有最小训练误差,相较于传统神经网络算法无需使用梯度下降法更新输入权重也能取得全局最优解,因此具备更高的训练效率与较好的泛化性能。
为解决ELM 无法适用于数据流分类的问题,Liang等[22]基于ELM 的在线学习算法提出在线序列超限学习机(Online Sequential Extreme Learning Machine,OS-ELM),无需保存历史数据,由初始化阶段和序列学习阶段组成。
2.2.1 初始化阶段
从到达的第k个数据块中选择样本x,设k=0,即最先到达的数据块。随机分配输入权重ai、偏置bi,给定激活函数G(x),计算初始输出权重β(0)。
式中:T0为初始阶段所选择样本对应的目标矩阵;H0为初始阶段隐层输出矩阵。
式中:n为样本数量;N为隐藏层节点;P0为:
2.2.2 序列学习阶段
在序列学习阶段,接收到第k+1 块数据,计算隐层输出矩阵Hk+1。然后在线更新输出权重β(k+1)、Pk+1。
式中:Tk+1为新到达样本的标签;Pk+1为:
式中:I为单位阵。
利用β可得预测的标签T。
由于Chen 等[16-20]的集成算法需全部保存处理数据流中少数类样本,随着数据不断到达,要为历史少数类样本数据开辟额外的内存空间,内存空间大小由数据量和数据维度两方面决定。因此,在实际训练过程中存在以下问题:①由于数据流具有高速、海量等特点,随着时间推移,所需空间大小可能很快就会抵达计算机内存上限;②在到达上限后是否丢弃历史数据或进行欠采样,之后如何弥补潜在的少数类特征的损失也是需要考虑的问题;③由于数据流具有实时性特点,对算法的实时处理和分析能力提出了一定要求,如果将历史数据存放在外部存储介质中,将增加额外的I/O 操作,因此也不适合使用数据库管理系统保存数据;④庞大的数据量也会增加模型训练时间,导致模型在新到达的数据上变得过时的问题。
3 EU-OS-ELM 算法的分类与存储
3.1 基本思想
本文集成欠采样和OS-ELM 算法,提出一种面向不平衡数据流的分类、存储与查询历史数据方法。EU-OSELM 算法利用ELM 网络中固定大小的外权矩阵来存储历史数据的特征信息。必要时,通过查询历史数据的特征信息代替对历史数据的查询。由于EU-OS-ELM 算法仅保存历史数据在特征空间的信息,因此可解决因不断保存历史数据而导致耗尽内存空间的问题。该算法使用集成方法来提升分类性能,在构建基分类器的训练样本时,使用不放回随机欠采样来进一步提升算法的鲁棒性,降低因特征损失导致欠拟合对模型的影响。
EU-OS-ELM 算法的目的是在提升不平衡数据流的分类准确率基础上,解决传统方法因保存历史数据而导致内存空间无限增长,占据大量存储空间的问题。算法流程如图1所示,历史少数类特征信息的存储方式如图2所示。

Fig.1 Algorithm flow图1 算法流程
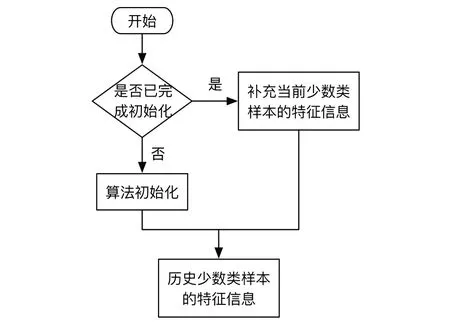
Fig.2 Storage of historical sample feature information图2 历史样本特征信息存储
3.2 算法描述
在初始化阶段,设隐藏层节点数为N,为每一个隐藏层节点随机分配输入权重ai、偏置bi,i=1,2,3,…,N。首先选取n0个少数类样本进行初始化,在第k个数据块上确定所需样本后,使用激活函数计算隐藏层输出矩阵,接下来根据式(1)、式(2)计算输出权重,此处中保存的信息为少数类样本的特征信息。
在集成在线学习阶段,使用后续到达的数据块中的少数类来更新输出权重矩阵及训练集成分类器。由于存在概念漂移现象,最近到达的数据块Sm一般代表数据流中数据的最新分布情况,在最近到达的数据块上训练分类器有利于减少期望误差。无论数据流发生何种形式概念漂移,在最近数据上更新模型总有利于后续预测结果[20]。在数据块Sk+1,Sk+2,…,Sm-1中,Sk+i为初始化完成之后到达的数据块,根据式(3)、式(4)保存并更新少数类F的特征信息,同时记录已经到达的少数类的总数nA。
在特征空间中,通过组合低层特征可形成更抽象的高层特征,本文通过固定大小的矩阵存储历史数据的特征信息,在接收到新的样本时通过式(3)、式(4)将当前少数类样本的特征信息补充到中,实现对少数类样本特征信息的存储。特征信息矩阵更新方式如下:
当需要历史数据时,查询该数据在特征空间中的信息以代替原始数据完成任务,即使用保存的输出权重矩阵,结合当前数据块来训练分类器。在最新数据块Sm上,将数据分为多数类Q、少数类F,引入不平衡率r=|F|/|Q|为数据块少数类样本数量与多数类样本数量的比率。
在多数类上进行不放回随机欠采样,得到多数类样本集合Oi,Oi集合样本数为nq=nA/r,可根据需要进行多次采样,将每次采样的结果和少数类F合并,得到一系列训练样本集合Train={{O0,F},{O1,F},…,{Od,F}}。将式(3)、式(4)改写为式(8)、式(9),查询并利用保存的历史少数类样本的特征信息训练基分类器。
式中:Hi为Traini的隐藏层输出矩阵;Ti为Traini的标签矩阵。
本文根据式(8)、式(9)结合历史数据特征信息训练得到一个基分类器βi,由此得到一个集成分类器E={β0,β1,…,βd}。首先在测试数据块Spre上根据激活函数得到Hpre,然后根据式(5)得到每一个基分类器的预测标签,最后根据各基分类的分类结果进行投票得到最终预测结果。
算法1:EU-OS-ELM 算法
3.3 内存空间分析
EU-OS-ELM 算法在集成在线学习阶段需占用额外内存空间,具体指为了保存历史少数类的特征信息所需空间。在数据块Si上,少数类样本的隐藏层输出矩阵H+i的维度为(n×N),n、N分别为样本数和隐藏层节点个数,Pi为一个维度为(N×N)的矩阵,Ti为样本的标签,维度为(n×t),t为样本长度。由此可知,保存少数类样本特征信息的β+为固定大小的N×t矩阵,一旦算法初始化后,β+所需要的内存空间就不会再发生任何改变。
EU-OS-ELM 算法在训练每个基分类器时,除了需要少数类样本外,还需当前数据块中的部分多数类样本。如果简单地对多数类样本进行欠采样会重复使用某一些样本,导致基分类器间相似度过高,从而降低集成分类器的泛化性能。因此,算法1 中的步骤7 对当前数据块中的多数类样本,使用了不放回随机欠采样方法,每一次采样得到的多数类样本没有重复项,能让大量不同的多数类样本参与学习,确保各基分类器训练样本的多样性,降低因欠采样导致特征损失对分类性能产生影响。此外,不放回随机欠采样使各基分类器间保持一定的差异性,既降低了算法方差,又提升了分类和泛化性能。
4 实验结果与分析
4.1 实验环境与评价指标
本文实验在macOS 12.2 系统、Core i5 处理器、16 GB 内存的机器上运行,算法实现编程语言为Python 3.7.7。在不平衡数据流问题中,使用总体正确率无法准确反映模型对少数类样本的分类性能,因此实验使用ROC 曲线、P-R 曲线、AUC 及G-mean 评价算法的性能。其中,ROC 为一个横轴为假正率(FPR),纵轴为真正率(TPR)的二维曲线图;AUC 为ROC 曲线下面积,是评价分类算法处理不平衡数据流问题的常用指标;P-R 曲线横轴为查全率(Recall),纵轴为查准率(Precision);G-mean 为多数类准确率与少数类准确率的综合指标。
不平衡率r的取值范围为[0.3,0.6],集成中基分类器个数设置为6,激活函数G(x)选择Sigmoid 函数。
4.2 数据集
本文选择8 个人工数据集和1 个真实数据集。其中,SEA、SIN 和STAGG 数据集考虑了带有不同类型概念漂移的情况;Spiral为一个螺旋数据集,包含4条螺旋臂,将其中一条螺旋臂的数据视为少数类,剩余数据为多数类;Covtype 来自UCI 的真实世界数据集,将其中数量最少的一个类视为少数类。具体数据如表1所示。
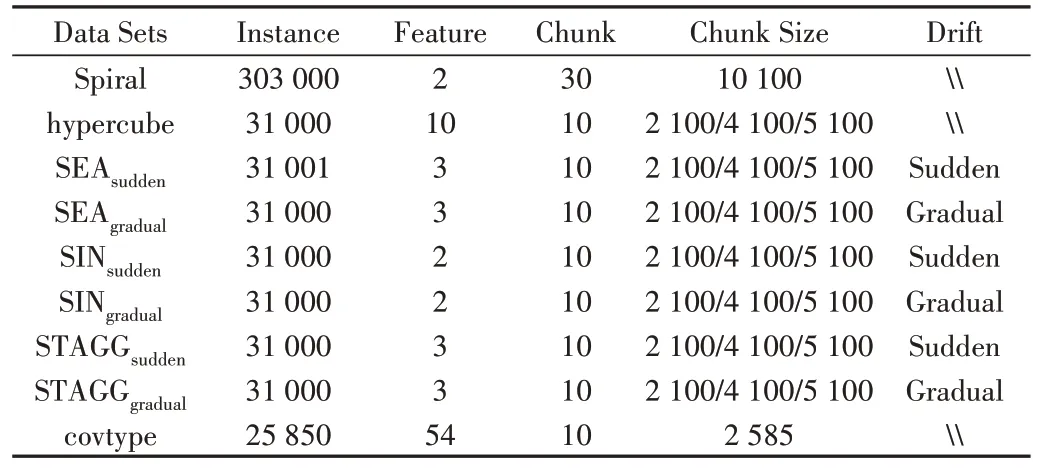
Table 1 Details of datasets表1 数据集细节
4.3 结果分析
将REA[16]、SERA[17]、MuSeRA[18]、SE[20]算法作为对照算法与EU-OS-ELM 算法从分类性能和历史少数类内存使用方面进行比较。集成算法SE 分别选择Decision Tree(DT)、Naive Bayes(NB)、Neural Network(NN)和LogisticRegression(LR)作为基分类器,在实验中分别标注为EDT、ENB、ENN、ELR。由表2 可知,EU-OS-ELM 算法在处理类不平衡数据流时能得到较为优异的分类性能。在hypercube、covtype 数据集上,EU-OS-ELM算法的AUC 达 到0.99;Naive Bayes(NB)作为基分类器的集成算法[20],在covtype 数据集之外的数据集上性能较差,原因是数据集的样本分布边界较为复杂,会影响先验概率与条件概率的计算。

Table 2 AUC and G-mean values of each algorithm in different data sets表2 各算法在不同数据集中的AUC和G-mean值
在处理类不平衡数据流时,对于少数类样本的存储问题,EU-OS-ELM 算法通过保存样本在特征空间的信息的方式,避免直接存储实际样本。由表2 与内存使用量的分析可知,EU-OS-ELM 算法在处理类不平衡数据流的整个过程中,仅需非常少的内存空间,即可达到甚至优于一些传统算法的分类精度。
图3、图4 为EU-OS-ELM 算法在Spiral 数据集上的ROC 曲线和P-R 曲线。由此可见,EU-OS-ELM 算法对应的P-R 曲线仅次于在通用框架集成算法SE 中选择决策树作为基分类器时的性能,ROC 曲线基本位于左上角,表2中相应的ROC 曲线下方面积AUC 值为0.912 3,可得出EU-OS-ELM 算法在该数据集的分类性能优秀。
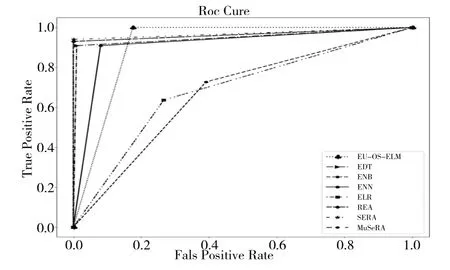
Fig.3 ROC curve on Spiral图3 Spiral上的ROC曲线

Fig.4 P-R curve on Spiral图4 Spiral上的P-R曲线
图5 展示了选择不同基分类器的集成算法SE、REA、SERA、MuSeRA,在不同数据集上与EU-OS-ELM 算法的额外内存使用比较情况。由于SE、REA、SERA、MuSeRA 算法需要保存每个数据块中原始的少数类样本来处理不平衡问题,所使用的内存空间数量为nA(Features+1),Features为样本特征数量。随着数据不断到达,保存历史少数类样本所需的额外空间不断增加,将很快消耗完计算机的内存空间。然而,EU-OS-ELM 算法由于使用固定大小的外权矩阵存储历史数据的特征信息,在整个学习过程中所使用的额外内存恒定为一个低值,所需内存空间数量为Nt,在不平衡数据流环境中nA≫N,与历史少数类样本的数量规模和维度无关。因此,EU-OS-ELM 算法在提升分类准确率的同时,所使用的内存最少,当数据量越多时,在内存方面的优势越明显。

Fig.5 Memory space for storing historical minority samples on each data set图5 各数据集上存储历史少数类样本的内存空间
EU-OS-ELM 用于保存特征信息的外权矩阵在算法开始阶段完成初始化,因此在图5 中的每一个子图的开始部分会出现EU-OS-ELM 算法所需的额外内存空间大于比较算法的情况,外权矩阵的内存使用量小于1 KB,并且在非常短的时间内就会被SE、REA、SERA、MuSeRA 算法所需的内存空间反超。因此,这一现象从处理不平衡数据流的整体过程而言对实验结论没有造成影响。
图5 中折线呈阶梯状分布的原因为:①只需要保存少数类样本,当数据到达后如果扫描到多数类样本则跳过;②Python 的内存分配机制所导致,当预留的动态内存空间消耗完后会向系统请求一个新的、更大的内存空间,然后将数据拷贝到新的空间中,并释放旧的内存空间,这一操作包含创建内存空间、移动数据和销毁原始内存空间3 个步骤,在实际应用中存在额外的时间、空间及操作系统开销,但EU-OS-ELM 算法在整个处理过程中只使用一个较小且恒定的内存空间,不存在额外开销。为了确保实验的客观性,实验中逐块处理数据流,在不同算法中保证生成的数据流中数据块的到达次序、同数据块中的少数类样本数量均一致,因此存储这些少数类样本所需的内存空间数量也一致,即不同传统算法在处理完同一数据块后,所需内存空间相同,解释了图5 传统算法在间隔一定数量样本后所需内存空间趋于一致的现象。
考虑到不同数据流样本分布情况,EU-OS-ELM 所需隐藏层节点数不同。在二分类问题中,输出权重β+的内存空间受隐藏层节点数的影响,如图6 所示。由此可见,随着隐藏层节点数N增加,输出权重矩阵β+所需要的内存空间基本上呈现一个线性增长趋势,完全处于可预估和控制的状态。
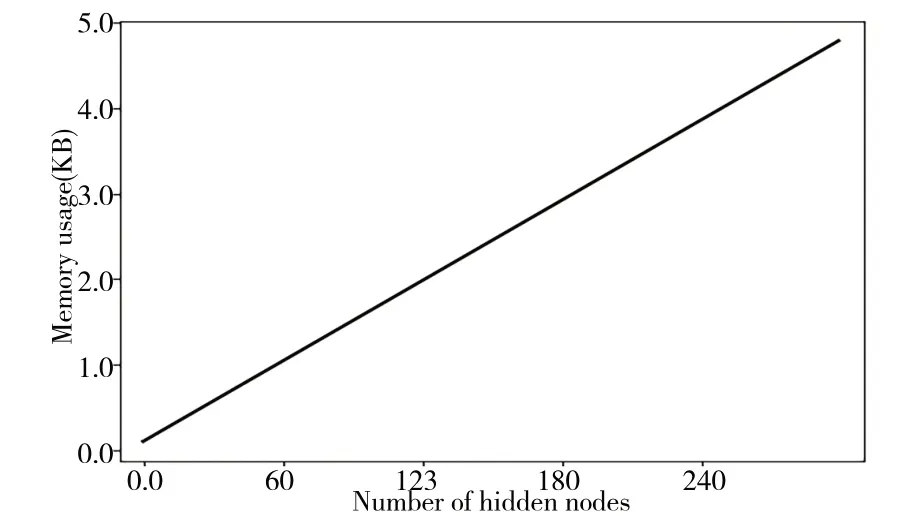
Fig.6 Memory space occupied by different hidden layer nodes图6 不同隐藏层节点数占用的内存空间
5 结语
本文基于OS-ELM 算法提出一种EU-OS-ELM 的不平衡数据流分类与存储方法。采用集成方式,在利用OSELM 训练基分类器时,使用不放回随机欠采样方法降低样本间的相关性,使训练得到的分类模型在对不平衡数据流进行分类时,具有更好的分类性能。
同时,为解决传统方法因不断保存历史少数类样本而导致的存储问题,本文利用一个固定大小的外权矩阵β+保存少数类样本特征信息,在需要使用历史数据的信息时,只需查询历史数据的特征信息,因此大幅度减少了内存空间的使用。此外,在实际应用中也可用相似的方法存储多数类样本的特征信息。
猜你喜欢
河北电力技术(2021年2期)2021-07-29
电子测试(2018年1期)2018-04-18
电脑与电信(2018年12期)2018-03-23
新课程·下旬(2016年12期)2017-06-07
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
西北工业大学学报(2015年3期)2015-12-14
中国卫生(2014年7期)2014-11-10
电测与仪表(2014年15期)2014-04-04
