
基于特征融合的多任务视频情感识别模型
2024-01-02 07:54:26张景浩谷晓燕
北京信息科技大学学报(自然科学版) 2023年6期
张景浩,谷晓燕
(北京信息科技大学 信息管理学院,北京 100192)
0 引言
近年来短视频数据呈爆炸式增长,传播方式也日趋便利。视频中包含文本、图像、音频三种模态的数据。研究其中包含的情感信息对于医疗健康、突发舆情、市场调研等领域的发展具有重要作用[1]。现有研究大多集中于对文本模态的情感分析,而视频中文本、图像、音频三种模态的数据可能含有不同的情感信息,如何捕获这些模态间的关联和互补信息对于视频多模态情感分析至关重要。
深度学习是目前多模态融合使用的主流方法。Bahdanau等[2]首次将全局注意力和局部注意力应用于自然语言处理中。Poria等[3]在模态的融合中使用了注意力机制,并设计了一种基于注意力的循环神经网络,该方法的缺点是较多地引入了其他模态的噪声。多头注意力机制是注意力机制模型的扩展,它可以在同一时间并行处理多个注意力模块以学习序列内部不同依赖关系。Xi等[4]提出了基于多头注意力机制的多模态情感分析模型,该模型首次运用多头注意力机制实现模态间的两两交互。宋云峰等[5]提出了基于注意力的多层次混合融合模型,使用多头注意力实现跨模态特征融合,利用自注意力机制提取任务贡献度高的模态信息。
多任务学习是一种通过同时训练多个任务并共享浅层参数来提高整体模型泛化能力的机器学习范式。深度学习模型通常都需要大量的训练样本以达到较高的分类精确度,但是收集大量的训练样本通常耗时耗力。在样本数量有限的情况下,多任务学习是学习多个相关联的任务很好的解决方法[6]。在多模态领域,常常使用多任务学习来提升任务的识别率。Yu等[7]通过增加单模态标签的识别任务来辅助多模态情感的识别;Latif等[8]将识别人物类别作为辅助任务来提升情感识别的表现。
本文提出了一种基于特征融合的多任务视频情感识别模型,该模型能有效提取视频中文本、音频、图像的特征,并将这些特征融合用于情感分类。在公开数据集CH-SIMS上的实验结果表明,相比于主流多模态情感分析模型,本文模型在分类准确率上有显著提高。
1 视频多模态特征提取
多模态数据特征提取的准确性直接影响模型情感识别的效果。为了有效地利用视频数据中含有的信息并提高模型在情感识别任务上的准确率,本文针对文本、图像和音频三种模态设计了不同的特征提取方法,根据提取的特征层次可以分为低阶特征、高阶特征。
1.1 文本特征提取
在文本处理领域,文本特征提取方法通常包括Word2Vec(word to vector)、BERT(bidirectional encoder representations from transformers)、GloVe(global vectors for word representation)。Word2Vec通过神经网络将词映射为向量,捕捉词与词之间的上下文关系,缺点在于它只依赖于局部上下文信息,忽略了词的全局统计信息。GloVe结合了词频统计和词嵌入技术,通过全局矩阵提取出能够反映词间关系的词向量,它虽然结合了全局统计信息,但在捕捉复杂语义关系上效果不佳。BERT利用双向 Transformer 架构,通过大规模预训练,生成能够理解上下文的深度语言表示。相比于 Word2Vec 和 GloVe,BERT 的优点在于采用双向上下文理解词义,能够更全面地捕捉文本含有的语义信息。本文选用中文BERT预训练模型作为词向量嵌入层,来提取低阶文本特征。每段文本序列经过BERT预训练模型得到的低阶文本特征如式(1)所示:
Xt=BERT(T)
(1)
式中:Xt为低阶文本特征;T为文本序列的输入字符。为了进一步提取Xt中的局部特征,将低阶特征Xt输入到卷积神经网络中,如式(2)所示:
(2)
(3)

图1 文本高阶特征提取Fig.1 Text high-order feature extraction
1.2 图像特征提取
在图像特征提取方面,CLIP(contrastive language-image pre-training)可以有效地捕捉到图像中的空间局部和全局特征。CLIP是一种多模态预训练模型,其使用Vision Transformer(ViT)[9]作为图片的编码器。这种基于Transformer架构的ViT模型在图像分类和识别方面表现出优越的性能。为了提取出图片中含有的情感信息,本文采用 CLIP预训练模型来提取图像的低阶特征。每段视频经过CLIP预训练模型得到的低阶图像特征XV,如式(4)所示:
XV=CLIP(P)
(4)
式中:XV为低阶图像特征;P为输入的视频片段。为了提取音频模态数据的局部特征,将低阶特征XV输入到卷积神经网络中,如式(5)所示:
(5)

(6)
式中LSTM表示长短期记忆网络。提取高阶图像特征的流程如图2所示。

图2 图像高阶特征提取Fig.2 Image high-order feature extraction
1.3 音频特征提取
Wav2Vec[10]是一种无监督训练大量语音数据的预训练模型,能将原始语音数据映射成含有语义表征的向量。Wav2Vec能有效降低噪声干扰,已在语音情感识别任务中展现出优秀的性能。本文使用Wav2Vec提取音频特征,每段音频信号经过Wav2Vec后得到的低阶音频特征,如式(7)所示:
XA=Wav2Vec(C)
(7)
式中:XA为低阶音频特征;C为输入的语音片段。卷积神经网络能对齐数据的序列维度并提取局部特征。为了进一步提取音频数据的特征,将低阶音频特征XA输入到卷积神经网络中,如式(8)所示:
(8)

(9)
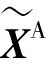
(10)
式中:BiLSTM代表双向长短期记忆网络。提取音频特征的流程如图3所示。

图3 音频高阶特征提取Fig.3 Audio high-order feature extraction
2 视频多模态情感识别模型设计
2.1 特征融合模块
如何有效地将三种单模态(文本、图像、音频)特征融合成最终的多模态表示一直是多模态情感分析中面临的主要挑战。多头注意力机制常用于特征融合,它能捕获模态间的相关性,实现模态间的动态交互。本文采用多头注意力来实现三模态的特征融合,具体过程如下:
首先得到经本文1.1~1.3节中单模态特征提取方法提取的高阶特征,如式(11)所示:
(11)
式中:L为序列长度;d为特征维度;i表示视频片段的索引;m∈{S,A,V},S表示文本模态,A表示音频模态,V表示图像模态。
注意力机制能够依据信息的权重度量不同信息特征的重要性,加强内部关键信息和内部相关性,弱化无用信息和对外部信息的依赖。注意力机制定义为
(12)
式中:R为输入的向量;dk为键向量K的维度;查询向量Q定义为
Q=RWq
(13)
式中:Wq为可学习的矩阵参数,Wq∈d×dq,dq为查询向量的维度。键向量K定义为
K=RWk
(14)
式中:Wk为可学习的矩阵参数,Wk∈d×dk,dk为Q和K的维度。值向量V定义为
V=RWv
(15)
式中:Wv为可学习的矩阵参数,Wv∈d×dv,dv为值向量的维度。为了进一步获得文本模态的关键信息,将文本模态高阶特征作为输入向量,通过自注意力模型式(12)~(15)得到过程如下:
(16)

(17)
(18)
模型中三模态的交互和融合是利用多头注意力机制实现的。多头注意力机制[11]是基于自注意力模块的扩展,它能提取更具表现力的序列表示,将突出关键信息的文本模态ZS作为多头注意力输入的键向量K和值向量V,将音频视频混合模态特征向量XAV作为多头注意力的查询向量Q,输入到多头注意力机制中,融合过程如图4中(b)多头注意力融合模块所示,得到最终的多模态表示Z:
Z=Multi(XAV,ZS,ZS)
(19)
式中:Multi表示多头注意力机制,定义为
Multi(Q,K,V)=concat(m1,m2,…,mi)W
(20)
式中:mi为第i个注意力头的输出,定义为
(21)
式中:i为注意力头的索引。
整个融合过程如图4所示。

图4 多模态注意力融合模块Fig.4 Multimodal attention fusion module
2.2 多任务情感分类与性别分类模块
将融合后的多模态表示Z输入到情感分类网络中获得最后的预测结果。为了进一步提高模型识别情感值的准确性,模型引入性别识别作为多任务学习的辅助任务,如图4中(c)多任务分类模块所示。Z被送入一个全连接神经网络构成的分类器。这个分类器预测情感分布的同时也预测性别分布。对于每个样本,模型的输出值有两个,第一个是预测的情感值,第二个是预测的性别值,通过计算预测情感值和真实情感值之间的误差、预测性别值和真实性别值之间的误差得到总的损失函数L:
L=αLe+(1-α)Lg
(22)
式中:Le表示情感预测的损失函数;Lg为性别预测的损失函数;α为超参数,用来调整不同任务的权重。在训练过程中,模型将根据损失函数的值在反向传播的过程中更新绝大部分隐藏层参数,只保留相应任务层的隐藏层参数独立。
3 实验与分析
3.1 实验数据
实验数据集选用中文多模态数据集CH-SIMS[7]。CH-SIMS共有2 281个视频片段,来自中文影视剧、综艺节目。每条数据都标记了情感倾向:消极、中性、积极。原始视频数据没有对男女性别进行标注,本文手工对男女性别进行标注,以便能在模型中进行多任务性别识别。CH-SIMS的数据统计信息如表1所示。

表1 数据集统计信息Table 1 Dataset statistical information
3.2 实验参数与评价指标
实验使用 TensorFlow开源框架,在NVIDIA RTX 3090 GPU上对网络进行训练。对于情感三分类(积极、中性、消极)问题使用准确率和F1值作为评价指标。具体实验参数如表2所示。
3.3 实验结果
为了评估本文模型的性能,选用以下6种较为先进的多模态情感分析模型进行对比。具体介绍如下:
1)EF-LSTM[12]:通过早期融合将不同模态特征拼接后输入到LSTM网络中得到分类结果。

表2 实验参数设置Table 2 Experimental parameter settings
2)LF-LSTM[12]:将不同模态特征输入LSTM网络后通过后期融合进行拼接得到分类结果。
3)TFN[13]:将不同模态特征进行外积运算进行多模态融合。
4)MULT[14]:使用Transformer 模型进行模态间的两两交互增强,从而进行跨模态融合。
5)EMHMT[15]:是一种结合多头注意力与多任务学习的跨模态视频情感分析模型。
6)MLMF[7]:把三个单模态的情感识别作为辅助任务进行多任务学习。
实验结果如表3所示。本文模型的准确率和 F1 值分别达到了68.71%和68.08%。与模型EF-LSTM、LF-LSTM相比,本文模型在融合方式上使用注意力机制突出了关键信息,并用合适的神经网络提取高阶模态特征用来融合分类,在准确率和F1值上分别提升了10%以上;相比于选取的最先进模型MLMF在准确率上提升了1.01百分点,验证了模型的有效性。

表3 不同模型实验结果对比
为了验证本文1.1、1.2和1.3节中提取高阶特征方法的有效性,分别设置多个对比实验,将本文1.1、1.2和1.3节模型中提取的高阶特征与其他模型提取的高阶特征在情感分类效果上作对比。文本模态高阶特征提取的对比实验结果如表4所示。其过程是将从预训练模型中得到的文本低阶特征向量输入到不同的神经网络模型中提取高阶特征并测试分类效果。对比模型具体介绍如下。
1) 全连接层:将式(1)中的低阶文本特征向量Xt输入到全连接层进行分类。
2)BiLSTM:将低阶文本特征向量输入到双向长短期记忆网络后用全连接层分类。
3)CNN:将低阶文本特征向量输入到卷积神经网络后用全连接层进行分类。
4)BiLSTM+Att:将低阶文本特征向量依次输入到双向长短期记忆网络和注意力机制后进行分类。
5)CNN+Att:将低阶文本特征向量依次输入到卷积神经网络和注意力机制后进行分类。

表4 文本模态高阶特征提取的对比实验结果Table 4 Comparative experimental results of high-order feature extraction in text modality %
从表4可以看到,用卷积神经网络和注意力机制提取的高阶文本特征在情感分类任务上的准确率和F1值分别达到66.03%、64.13%,证明本文1.1节中描述的文本单模态高阶特征提取网络能获得语义更丰富、特征更突出的高阶特征向量。
将从预训练模型中得到的低阶图像特征输入到不同的神经网络模型中提取高阶特征并测试分类效果,图像模态高阶特征向量提取的实验结果如表5所示。对比模型具体介绍如下:
1)全连接层:直接将式(4)中的低阶图像特征向量XV输入到全连接层进行分类。
2)CNN:将图像低阶特征向量输入到卷积神经网络后输入全连接层进行分类。
3)CNN+LSTM:将图像低阶特征向量依次输入到卷积神经网络和长短期记忆网络后进行分类。
4)CNN+LSTM+Att:将图像低阶特征向量依次输入到卷积神经网络和长短期记忆网络、注意力机制后进行分类。

表5 图像模态高阶特征提取的对比实验结果Table 5 Comparative experimental results of high-order feature extraction in image modality %
在图像单模态的对比实验中,加入了注意力机制之后分类效果相比于CNN+LSTM的准确率和F1值分别下降了3.21百分点和1.19百分点,这可能是由于过拟合造成的。因此在提取图像高阶特征向量时使用准确率最高的CNN+LSTM。
音频单模态低阶特征的实验结果如表6所示。其过程是将从预训练模型中得到的音频低阶特征向量输入到不同的神经网络模型中提取高阶特征并测试分类效果。对比模型具体介绍如下。
1)全连接层:直接将式(7)中的音频低阶特征向量XA输入到全连接层得到的分类结果。
2)BiLSTM:将音频低阶特征向量输入到双向长短期记忆网络后用全连接层进行分类。
3)CNN+BiLSTM:将音频低阶特征向量依次输入到卷积神经网络和双向长短期记忆网络后进行分类。
4)CNN+BiLSTM+Att:将音频低阶特征向量依次输入到卷积神经网络和双向长短期记忆网络、注意力机制最后进行分类。

表6 音频模态高阶特征提取的对比实验结果Table 6 Comparative experimental results of high-order feature extraction in audio modality %
从表6中可以看到,用卷积神经网络和双向LSTM网络与注意力机制的组合网络准确率和F1值分别达到了56.45%、50.33%,能获取分类效果更好的高阶音频特征向量。
3.4 消融实验
为了验证模型的有效性,共设计了6组消融实验。分别使用单模态特征或移除模型中单个模块进行对比,以此来验证本模型的有效性和各模块的重要程度。实验结果如表7所示,前3个消融实验直接使用单模态高阶特征进行情感分类。实验结果显示单文本模态在准确率上比另外两个模态(音频、图像)高,这是因为文本模态特征提取技术较为成熟,含有的有效信息也较多,而图像和音频模态的实验准确率则较低,说明该模态特征提取效率较低。用单模态性能最好的文本单模态特征识别的准确率和F1值低于三模态融合的准确率和F1值,这证明了文本、音频、图像的充分融合的必要性。移除了多任务学习模块,在情感分类任务上的准确率和F1值分别下降了0.47百分点、0.66百分点,这说明加入性别识别多任务学习能提升情感分类的效果。在移除了多头注意力模块后,本文模型其准确率和F1值分别下降了2.85百分点、2.43百分点,说明了本文的多头注意力融合模块能够利用不同模态的互补信息进行融合,提升了识别准确率。

表7 消融实验结果Table 7 Ablation experimental results %
4 结束语
本文提出了一种基于注意力融合与多任务学习的多模态情感分析模型。首先使用预训练模型BERT、Wav2Vec、CLIP得到文本、音频、图像的低阶特征表示;然后将低阶特征表示分别输入到神经网络中来提取模态的高阶特征表示;接着利用多头注意力融合模块实现三模态的交互融合;最后,结合多任务学习获得情感和性别的分类结果。在公开的中文多模态数据集CH-SIMS上的实验结果表明,情感分类的准确率得到有效提升。未来的研究目标是探索模态缺失条件下如何进行模态融合,进一步提高情感识别的准确率。
猜你喜欢
数学物理学报(2021年1期)2021-03-29 03:13:48
数学物理学报(2020年6期)2021-01-14 01:00:36
矿产勘查(2020年11期)2020-12-25 02:55:34
哈尔滨轴承(2020年1期)2020-11-03 09:16:02
数学物理学报(2019年3期)2019-07-23 01:15:30
家庭影院技术(2018年11期)2019-01-21 02:20:52
电子制作(2018年19期)2018-11-14 02:37:08
数学物理学报(2018年3期)2018-07-17 06:15:40
电子制作(2017年9期)2017-04-17 03:00:46
人间(2015年8期)2016-01-09 13:12:42
