
基于生态环境大数据与画像的污染源精准监管研究
2024-01-01 00:00:00尹民
环境科学与管理 2024年6期

关键词:污染源;企业画像;精准监管;数据挖掘
中图分类号:X171.1 文献标志码:A
前言
随着工业化和城市化的快速发展,环境污染源的精准监管成为环境治理的关键环节。不少学者探讨了企业污染的相关问题。如文献[1]韦啸等提出基于多通道分布式VOCs在线监测质谱系统精准识别企业污染源的方法,建立了一个多通道分布式质谱系统,通过该系统在企业内部和厂界设置多个在线监测点位,连续监测VOCs无组织排放污染源。运用PMF模型解析厂区环境大气VOCs的污染源因子,再结合CBPF方法识别各个污染源因子的地理位置信息。但是,该方法需要较高的初始投资用于购买和维护多通道监测设备,且数据分析过程较为复杂,需要专业的技术人员进行操作和维护。为解决深圳市生态环境局当前污染源监管“人少事多量大”的困难局面,避免污染源企业数据造假问题,提升污染源监管效率。提出一种基于大数据和画像的污染源精准监管方法。通过运用大数据和人工智能、机器学习、知识图谱等新技术构建污染源企业环保全景多维度画像体系,赋能污染源监管执法自动推荐、不同用户的个性化自动推荐、主动通过检索快速查找到所需的污染源数据,弥补监管漏洞。从而实现污染源精准化监管、科学化决策、精细化管理。
1研究方法和主要思路
1.1研究方法
通过深圳市生态环境局用户的实际调研,针对管理者、决策者和监管人员的访谈充分了解用户需求的基础上,开展“企业环保画像”场景实现污染源精准监管的应用研究。
1.2主要思路
如图1所示,污染源企业环保画像体系的构建,应以生态环境大数据平台整体框架为基础,汇聚污染源企业全域数据,通过建模形成企业环保行为特征标签体系,为执法应用、个性化推荐、智能检索等具像化应用场景提供技术支撑,最终实现“千企千面”智慧化运营和精准监管。同时,借助污染源企业环保画像建立以下四大“核心能力”。
(1)建立“动态采集+数据认证”的污染源数据收集网络体系。
(2)建立“污染源企业+大数据+人工智能+知识图谱”的能力核心。
(3)建立“执法应用+个性化推荐+智能检索”的数据应用场景模式。
(4)建立“数据库+专家经验智库”的污染源权威评估和决策方式。
2总体框架和技术方案
2.1总体框架
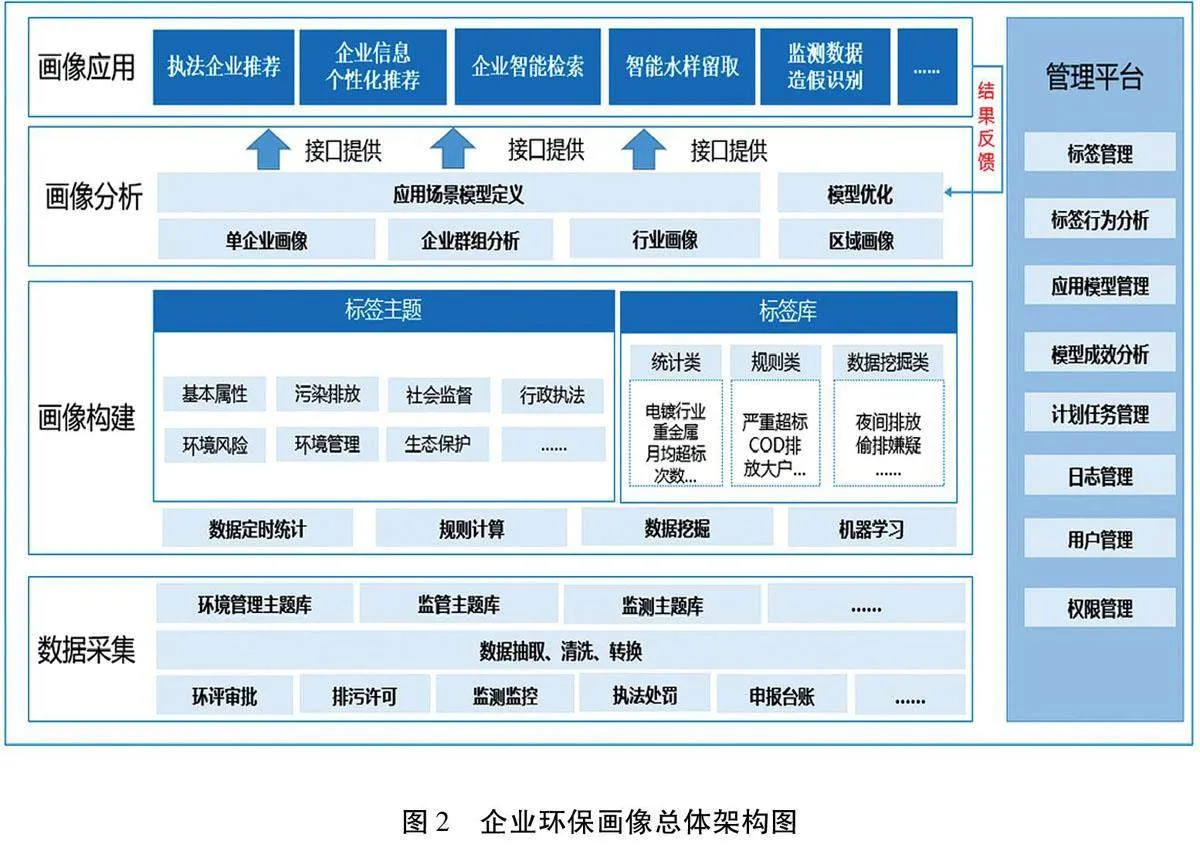
系统包括管理平台与画像构建及应用两个主要组成部分。
管理平台主要对标签进行管理,画像应用场景模型的构建,模型成效分析、标签行为分析、标签数据生产计划任务管理、系统用户权限、日志管理等基础功能。
画像构建及应用,主要包括从数据采集、画像构建、画像分析、画像可视化到应用场景模型、模型成效改进等几部分建设内容。(见图2)
2.2技术方案
实现基于生态环境大数据构建“企业环保画像”助力污染源精准监管,从数据准备、企业环境画像构建、企业环境画像可视化、企业环境画像应用等几个步骤进行实现。
2.2.1数据准备
2.2.1.1数据基础
构建企业环境行为画像,需要企业全生命周期高质量数据作为支撑。针对深圳市,现有监管污染源企业达九万余家,包括重点污染源企业、一般污染源企业和已核发排污许可证企业等,生态环境大数据中心已经汇聚了环评、许可证、执法、行政处罚、监测、申报等多元数据,所拥有数量已达120亿条,并且以每天5000万条的数据产生量在持续增加。
2.2.1.2数据融合
由于政府各个部门、企业、三方机构等的基础数据存在差异,需提取基本属性、污染排放、社会监督、行政执法等企业对环境产生影响的部分,基于这些数据,采用ETL技术进行数据抽取,清洗,创建企业环境行为画像构建需要的各类主题数据库。
2.2.2标签体系构建
2.2.2.1标签体系
数据准备好后,通过调研与海量历史数据分析结果,基于目的性、全面性、可获取性、可比性原则确定标签体系,包括基本属性、污染排放、社会监督、行政执法、环境风险、环境管理、生态保护等维度。其中,目的性原则即根据研究目的选取标签体系;全面性原则即选取的标签体系尽量涵盖企业各个方面;可获取性原则即可行性原则,确保选取的标签体系是容易获得并具有代表性的;可比性原则即确保所有标签的量纲统一,使标签之间具有可比性。
2.2.2.2标签数据开发
根据“数仓分层建模理论”建立以上述7个维度为主的三级模糊标签指标体系,通过将训练数据引入BERT(Bidirectional Encoder Representation from Transformers)即预训练语言表征模型,抽取不同维度的底层标签,并依据标签抽取的不同方法划分标签类型,包括:(1)统计类标签,根据企业多维度数据进行统计而来;(2)规则类标签,定义规则,设置定时任务,根据规则进行规则类标签的开发;(3)数据挖掘类标签,通过数据挖掘与机器学习方法进行标签的产生,一般通过监测数据为主,融合其他数据进行某种特定规律的发现、数据预测等。
2.2.2.3标签特征抽取
很多标签容易出现表达不明确的问题,为了使企业画像更为精确,需要对模糊标签进行特征提取。先利用BERT模型将模糊标签向量化,再通过特征融合方式,对多源标签进行向量拼接,并根据标签打分结果计算该权重,对其赋予权重后得到特征融合后的企业信息;再将该向量信息引入BiLSTM(双向长短期记忆网络,Bi-directional Long Short-Term Memory)网络捕捉双向语义依赖,得到更为准确的次级标签,并构建相应的标签库。例如,某化工企业被群众投诉夜间排放污染废水,投诉中包括企业具体违法行为、时间,将其向量化后乘以权重并与执法记录对应的执法时间及该企业处罚结果进行向量拼接,得到企业“偷排”这一次级标签,并计算此标签权重。
统计类标签主要是管理标签的启用/禁用状态;规则类标签可以修改标签的计算规则、启用/禁用状态等;数据挖掘类标签需要在标签管理中根据经验与应用进行人工确认与命名,例如:企业污染排放的规律、污染排放的周期性特征行为、排放数据造假行为等挖掘类标签。
2.2.3企业环境画像构建
利用数据挖掘、人工智能、机器学习等技术方法,分析企业环境行为特征,刻画企业动态标签,并根据建立的标签体系,构建企业环境画像。
根据各一级标签下二级标签的加权平均数,得到一级标签的权重配比,即企业整体画像中不同维度的贡献率,构建出整体企业画像。例:社会监督维度权重30%,即社会监督维度在企业整体画像的贡献率为30%,则整体企业画像中社会投诉生成的标签重要度为30%。同时也可以提取同一行业、同一区域等标签,根据含此类标签企业整体画像进一步构建行业企业画像或区域企业画像等。
2.2.4应用场景模型
结合用户实际的应用场景,通过标签的有机组合,形成各个应用场景模型,通过应用场景模型赋能相应的业务系统,使业务系统使用起来更智能化,同时通过业务系统使用的反馈数据,如执法系统推荐企业执法命中率等数据,进一步调优模型,使模型更精准。
3案例应用情况
深圳市生态环境局现有监管污染源企业达九万余家,包括重点污染源企业、一般污染源企业和已核发排污许可证企业等,其中需要重点监管的企业有一万多家,但是执法人员仅有400余人,基本上每个执法人员需要监管约200家企业,再加上现场执法耗时长,平均一天执法人员只能现场执法3~4家企业。通过给污染源企业进行特征标签,然后将标签中与违法情形挂钩的标签有机组合,形成执法推荐模型,可以有效地帮助监管执法人员在现场执法过程中命中违法企业,而非靠运气随机发现违法企业,大大提高了监管执法人员的工作效率,并有效地降低了企业违法的侥幸心理。另外,通过不断的现场执法实践,反馈推荐企业中违法企业的数量、基本信息等数据,可以帮助执法推荐模型进一步优化,提升未来命中违法企业的准确率。
4结束语
依托深圳大数据平台汇集的各类企业生产经营活动中产生的数据,利用规律计算、大数据挖掘算法、机器学习等方式,结合污染源监管业务场景等需求,构建完善、动态的标签体系形成企业画像,采集污染源企业环境行为特征体系,提取和识别污染源企业特征行为,帮助生态环境监管部门构建污染源企业环保标签体系,为业务系统赋能,使污染源监管更智能,更精准。企业画像应用场景丰富,改变了传统企业档案管理应用模式,发挥了大数据平台的价值,为生态环境监管部门减轻工作压力,针对污染源企业的监管效率也大大提升。在大数据相关技术高速发展的时代,作为污染源企业监管人员,应当积极转变思维模式与工作方式,借助科技的手段,精准有效的实现环保监管。
猜你喜欢
环境保护与循环经济(2021年7期)2021-11-02 08:10:50
大众投资指南(2021年35期)2021-02-16 01:06:26
环境影响评价(2020年2期)2020-12-02 01:23:24
环境保护与循环经济(2017年4期)2018-01-22 03:27:18
中国资源综合利用(2017年4期)2018-01-22 02:46:45
电力与能源(2017年6期)2017-05-14 06:19:37
中学生数理化·八年级物理人教版(2017年12期)2017-04-18 12:59:46
中国中医药信息杂志(2016年7期)2016-12-01 06:07:55
中国资源综合利用(2016年11期)2016-01-22 02:01:24
信息通信技术(2015年6期)2015-12-26 01:16:46
