
基于二阶段对比学习的中文自动文本摘要方法研究
2024-01-01 00:00:00杨子健郭卫斌
华东理工大学学报(自然科学版) 2024年4期
关键词:指标





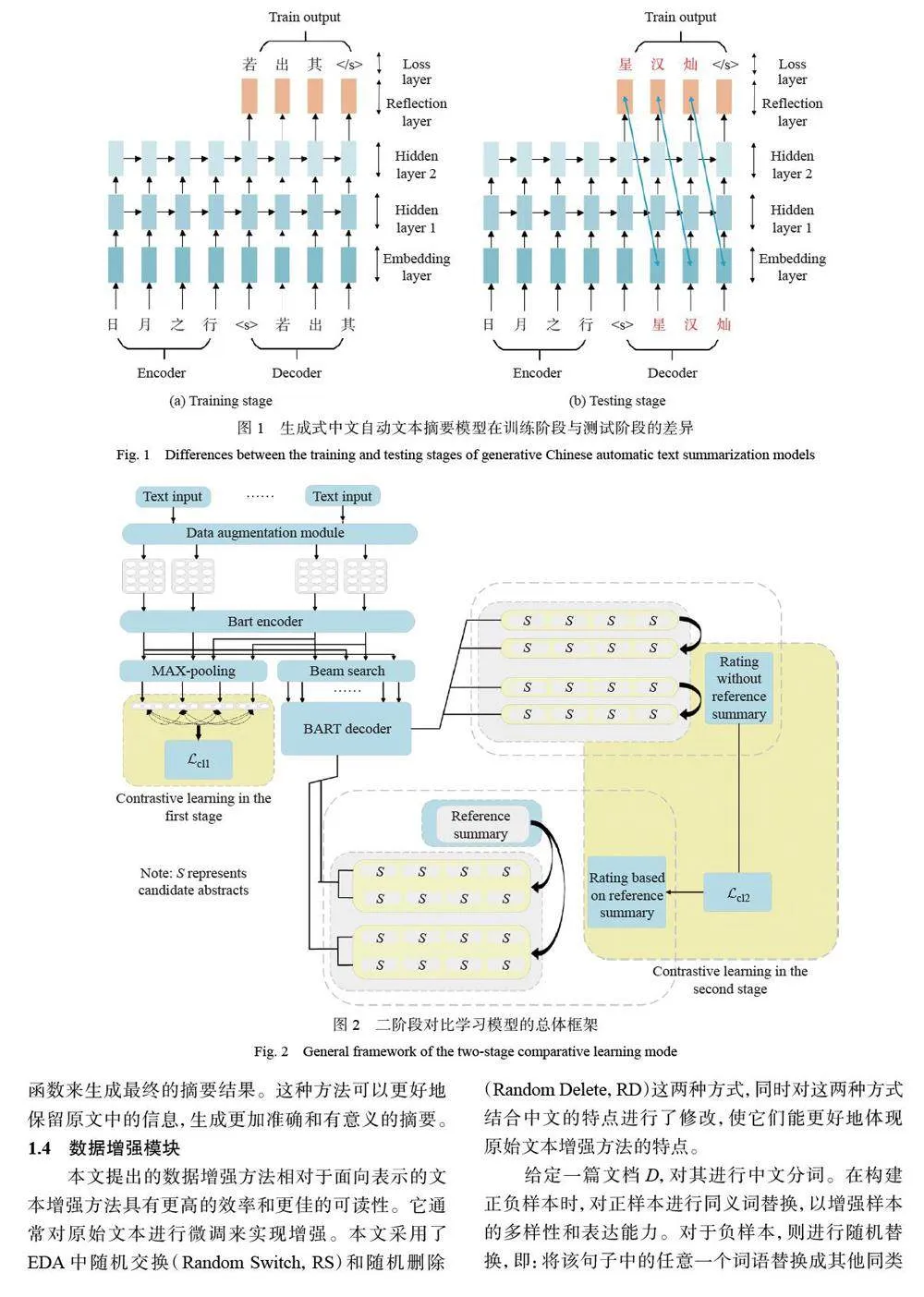

摘要:在中文自动文本摘要中,暴露偏差是一个常见的现象。由于中文文本自动摘要在序列到序列模型训练时解码器每一个词输入都来自真实样本,但是在测试时当前输入用的却是上一个词的输出,导致预测词在训练和测试时是从不同的分布中推断出来的,而这种不一致将导致训练模型和测试模型直接的差异。本文提出了一个两阶段对比学习框架以实现面向中文文本的生成式摘要训练,同时从摘要模型的训练以及摘要评价的建模进行对比学习。在大规模中文短文本摘要数据集(LCSTS)以及自然语言处理与中文计算会议的文本数据集(NLPCC)上的实验结果表明,相比于基线模型,本文方法可以获得更高的面向召回率的摘要评价方法(ROUGE)指标,并能更好地解决暴露偏差问题。
关键词:中文自动文本摘要;对比学习;暴露偏差;预处理模型;ROUGE 指标
中图分类号:TP391 文献标志码:A
中文文本摘要是将一个较长的中文文本压缩成较短的文本,并保留了文本的主要内容。这个过程通常由自动化程序完成,其目的是为了帮助人们快速理解和浏览大量的中文文本。中文文本摘要主要有两种类型:抽取式摘要和生成式摘要。Erkan 等[1] 提出了一种基于图论的抽取式摘要方法LexRank,该方法通过计算句子之间的相似度构建一个句子图,并利用PageRank 算法对句子进行排序。抽取式摘要的主要问题是受限于原始文本、信息丢失、可读性差等。生成式摘要则使用自然语言处理技术从原始文本中提取信息,然后基于这些信息生成全新的摘要。Nallapati 等[2] 提出了一种使用基于循环神经网络(RNN)的序列到序列(Sequence-to-Sequence)模型获得生成式摘要的方法。TextRank算法则构建标题和每个子句的特征向量,并计算子句特征向量间的相似性,最后结合子句位置、子句与标题的相似度等调整子句相似度矩阵,迭代计算直至收敛,进而选取得分最高的子句作为最终摘要[3]。
近年来,以Transformer 模型[4] 为代表的预处理模型在自然语言处理领域受到了广泛关注。Dodge 等[5]研究了预训练语言模型在微调阶段的3 个关键因素:权重初始化、数据顺序和早期停止。具有预训练的编解码器模型如BART( Bidirectional and Auto-Regressive Transformers)[6]、Pegasus[7] 等,在中文自动文本摘要任务中获得了较好的性能,这些模型的架构通常采用Transformers 模型。尽管生成式摘要在语言流畅性方面显示出很好的潜力,但其在训练序列到序列模型时面临着广泛的认知挑战[8]。
对比学习(Contrastive Learning,CL)通过添加额外的优化目标,降低那些束搜索出来的非目标序列。该方法的核心思想是通过构造具有代表性的负样本,并降低其在训练过程中的出现概率,以缓解暴露偏差并提高文本生成的性能。Liu 等[9]提出了一种新的对比学习框架,用于在有限的平行数据下训练文本摘要模型。Xu 等[10] 提出了一个用于抽取式文本摘要的对比学习框架从而提高了文本摘要的质量和一致性。Cao 等[11] 提出了一种新的对比学习方法,用于改进抽象式文本摘要;该方法利用对比学习的能力来学习更好的句子表示,从而提高了摘要的流畅性和准确性。上述研究成果在文本摘要领域的应用主要集中在2 个方面:一是摘要模型的训练,二是摘要评价的建模。
猜你喜欢
数学物理学报(2022年5期)2022-10-09 08:57:50
宁夏医学杂志(2020年4期)2020-03-01 13:16:20
宁夏医学杂志(2020年3期)2020-02-27 14:17:11
计算机应用(2018年12期)2019-01-08 01:55:48
商周刊(2018年26期)2018-12-29 12:56:00
西部广播电视(2015年5期)2016-01-16 03:45:07
集美大学学报(自然科学版)(2015年1期)2015-02-28 01:13:33
机电信息(2015年27期)2015-02-27 15:57:12
中国工程科学(2015年7期)2015-02-27 10:51:19
江苏年鉴(2014年0期)2014-03-11 17:10:15
