
基于动态贝叶斯网络的输电走廊山火风险时空评估
2023-12-30 03:18刘晖向谆周恩泽周洋卓君黄宇向坤轩周游
南方电网技术 2023年11期
刘晖,向谆,周恩泽,周洋卓君,黄宇,向坤轩,周游
(1.长沙理工大学电气与信息工程学院智能电网运行与控制湖南省重点实验室,长沙 410114;2.广东电网有限责任公司电力科学研究院,广州 510080)
0 引言
近年来,随着“退耕还林”政策的实施,以及人民生产生活用火习俗和各种极端天气等因素影响,输电走廊附近易爆发大范围山火灾害,严重影响电网安全稳定运行[1-3]。山火分布规律研究表明,输电走廊山火具有时空分布不均衡特性[4-6]。在时间上呈现较强的季节和时节性特点,每年9 月至翌年4 月是相对高发期,并随着春节、清明等民俗节气因素而呈现逐日增长的爆发性趋势;在空间上具有明显地域性特征,靠近人类生活和交通运输区域的输电走廊区段通常发生山火的概率也会高于偏远地区。开展输电走廊山火时空分布研究,确定特定时段的山火高发生风险区域,有助于运维单位开展针对性的防山火工作,提升电网安全稳定运行性。
早期气象和林业部门根据天气因素和历史火灾数据建立森林火险气象指数,预测大范围区域火险等级[7-10],但是该类方法不适用于目标需求更加精细化的输电走廊山火预测。文献[11]在森林火险气象指数的基础上,引入了地表燃烧因子和历史火情因子,构建图模型评估输电线路山火风险等级。文献[12]综合考虑气象、卫星监测热点、工农业用火和隐患点要素,通过赋予不同的权重计算山火预警值实现输电走廊山火风险评估和预警。但是上述方法中的各要素权重由专家主观确定,受人为影响较大。为降低专家主观经验不足造成的山火风险误判,文献[13]结合电网历史监测数据,利用BP 神经网络评估输电线路山火风险。文献[14-15]选取人为、气象、地形和植被因子,构建Logistic 回归模型实现了输电走廊山火风险评估。文献[16-17]采用朴素贝叶斯网络进行山火风险评估,绘制了山火风险分布图。但是这些模型通常要求因子和要素之间相互独立,且所选变量为年平均值,未考虑气象等因子随时间和季节的动态变化对山火发生的影响。综上,目前输电线路山火风险评估和预测存在两方面问题,一是构建模型过程中变量对山火发生事件的影响差异主要以主观或客观权重来体现,没有考虑山火影响因子之间的相互耦合关系;二是模型变量通常选择的是当下时刻的值或者年平均分布情况,然而山火发生的概率除了和当下的气象条件有关以外,还和过去几天的气象和近期的人类活动变化有关,现有的因子变量无法体现山火发生的时空聚集性。
为此,本文提出了一种基于动态贝叶斯网络(dynamic Bayesian network,DBN)的山火风险时空分布评估方法。首先,综合选取和收集了人为、气象、植被和地理四大类共计17 个山火因子,利用随机森林算法筛选最优因子集。然后利用静态贝叶斯网络消除因子之间耦合关系的基础上,建立了动态贝叶斯网络模型,对比月时间尺度下静态贝叶斯网络和动态贝叶斯网络模型对山火风险评估的影响,探索引入过去的因素对于山火风险评估的影响,并研究不同时间尺度对的动态贝叶斯网络性能的影响。最后,利用最优山火评估模型绘制输电走廊山火风险分布图验证了模型的工程适用性。
1 输电走廊山火风险时空评估框架
为了更好地应对突发性的山火灾害,本文提出了一种输电走廊山火风险时空评估方法,主要分为数据收集与预处理、因子优选和山火风险分布评估3个部分,总体框架如图1所示。

图1 输电走廊山火风险时空评估框架Fig.1 Framework for assessing the spatial-temporal distribution of wildfire risk in transmission line corridors
1)数据收集与预处理。首先,从气象部门和电力部门收集得到气象、人为、植被和地理数据,采用箱线图检测数据集中的异常值并对空缺值进行填充,得到山火因子数据集。然后,为进行不同时间的山火风险评估,将历史火点按照一定的时间间隔进行划分,得到不同时间的火点分布。最后,将研究区域按照经纬度进行网格划分,其中火点所在网格作为火点样本点,其他网格则作为非火点样本点,获得不同空间上的火点分布。利用地理信息软件将山火特征数据提取至火点和非火点样本点,构成原始的山火样本数据集。
2)因子优选。原始的山火样本数据集因子众多,过多的冗余因子可能会带来不必要的噪声影响模型性能。因此采用随机森林算法进行因子优选,通过Bootstrap重抽样技术将数据集划分为训练数据集和袋外数据集,在训练集上同步训练决策树。然后逐一对因子施加扰动并计算袋外误差,得到各因子的重要度排序,得到最优因子集。
3)山火风险分布评估。将筛选得到的山火因子数据集离散化,作为动态贝叶斯网络模型的输入,采用极大似然估计法学习初始网络和转移网络的条件概率。然后以受试者工作特性曲线(receiver operating characteristic,ROC)和曲线下方面积(area under curve,AUC)作为评价指标,评估模型在测试集上的预测效果。
2 山火影响因子分析与因子优选
2.1 山火影响因子分析
可燃物、助燃物和着火源是火灾发生必备的三要素[18],其中可燃物和助燃物为自然因子,着火源包括人为火源和自然火源。早期的森林火灾预测预报研究[19]主要从自然因子出发,考虑气象和植被等因子,建立综合评价指标对大范围的森林区域进行笼统的火险等级预测,该方法准确性主要依赖于气象数据的精确度。而输电线路大多穿梭于人类活动较为频繁的山区和田地,线路周边居民生产生活以及祭祖用火频繁、且地形和植被等因子相互关联,山火爆发随机性强,仅考虑自然因子的林火预报难以实现对小范围输电线路山火的准确预测。2017年国家电网公司颁布《架空输电线路山火分布图绘制导则》[20],采用了历史火点密度表征人为火源分布情况,同时考虑植被燃烧危害等级评估输电线路山火风险。但该方法未考虑气象和地形等助燃物要素,难以保证评估时效性。因此在评估输电走廊山火时,应该从火灾三要素出发,综合考虑影响山火发生的气象、人为、植被和地形等因子。
由于山火灾害还具有一定的时间变化特性,上一时刻的气象信息和发生火灾情况会对当前时刻山火发生造成一定影响。因此,本文综合考虑气象、人为、植被和地形4 类因子,通过静态因子和动态因子相结合来刻画山火时间相关性。其中选取了历史火点密度、人口密度、GDP、线路到公路距离、线路到居民点距离、植被类型、NDVI、可燃物载量、土地利用类型、海拔、坡度和坡向12 个基本短时间内不随着时间变化的因子作为静态因子;并选择目标时段内的连续无雨日、平均温度、平均降水量、平均湿度和平均风速5 个随时间变化的动态因子来反映时间变化对山火发生风险影响。构建DBN 模型,通过证据推理计算山火发生的概率,评估山火风险。
2.2 基于随机森林的因子优选
通常为全面挖掘山火发生规律,在构建模型时倾向于采用较多的因子。而引入过多的因子会带来“维数灾”问题,导致模型复杂度增大,训练时间成本增加,甚至引入噪声降低模型精度;与此同时,随着变量的增加,贝叶斯网络的参数学习所需样本量也会急剧增加,给模型参数评估带来困难。为此,本文采用随机森林特征选择算法[21-22]从原始的高维山火数据集中筛选出最优因子集,提高模型的计算效率和拟合精度。
随机森林是一种以决策树为基学习器的集成监督学习模型。随机森林通过Bootstrap自助采样法和节点随机分裂技术建立决策树,以少数服从多数的投票方式集成决策树输出结果。通过计算每个因子在每棵树上的贡献程度,可以评估因子对山火发生事件的重要程度,对应的算法步骤如下。
步骤1:从原始样本集中随机有放回地抽取K个训练数据集{D1,D2,…,DK}和K个对应的袋外数据集{B1,B2,…,BK};
步骤2:设置k=1,在训练集Dk上建立决策树,使用决策树对Bk进行预测,统计袋外数据预测误差,记为;
步骤3:对Bk中的因子Xi,i=1,2,…,n施加扰动,统计袋外数据预测误差;
步骤4:对于k=2,3,…,K,重复步骤2、3;
步骤5:利用式(1)度量因子Xi的重要度;
3 基于动态贝叶斯网络的山火风险评估模型
3.1 贝叶斯网络和动态贝叶斯网络
贝叶斯网络(Bayesian network,BN)是一种用于概率推理的图形化数学模型,它利用有向无环图描述变量间的依赖关系,在给定观测样本数据或专家先验知识下,BN 能够利用贝叶斯概率理论对目标变量进行概率推理,在含有多变量的不确定性问题中得到广泛应用。DBN 在BN 的基础上引入了时序概念,通过刻画随机变量的时序转移和因果关系,对动态时变随机过程进行推理,在负荷预测、数据链路预测、海底管道失效预测[23-25]等动态推理预测领域具有成熟应用。
DBN 可被定义为(B1,B→),B1为初始时刻的BN,定义了变量之间的因果关系和概率分布,B→为转移网络,它将前后相邻的时间片的BN 联结起来,描述了2 个相邻时刻变量间的转移概率P(Xt|Xt-1),即:

图2 DBN网络拓扑Fig.2 Topology of DBN network
通常为简化动态模型推理的复杂度,假设DBN 满足一阶马尔科夫和转移概率不变两个前提假设[26]。其中一阶马尔科夫假设要求节点之间的有向边必须位于同一时间片或相邻时间片之间,不能跨越时间片,即因子变化只与上一个时间片的状态有关,与更早之前的时间片的状态无关;转移概率不变假设是指B→的转移概率P(Xt|Xt-1)不随时间变化。基于上述假设,可将DBN 拓展至第T个时间片,得到DBN 任一节点的联合概率,如式(3)所示。
3.2 基于DBN的山火风险评估
构建DBN 山火风险评估模型时,包含网络结构学习和参数学习两个步骤。网络结构学习指根据专家经验或者样本数据搜索初始网络结构B1,并对B1进行时间延拓得到DBN 结构,本文采用专家经验法,通过分析山火影响因子之间的因果关系获得合适的山火风险评估DBN 结构;然后基于时间序列样本训练得到DBN 各节点条件概率;最后通过DBN推理算法计算样本点的山火发生概率。
3.2.1 模型节点参数的计算
DBN 节点参数即为各节点的条件概率表(conditional probability table,CPT),反映了各影响因子之间的概率依赖关系。CPT 通常可由专家经验直接给出或者基于样本数据训练得到。由于山火灾害爆发随机性强,专家经验给定的参数难以适用于各因素相互耦合的山火预测。因此本文基于历史时间序列样本学习节点的CPT,充分挖掘节点之间的依赖关系。
在山火历史数据集观测完全的条件下,采用统计学中的极大似然法[27]估计网络节点的CPT。设样本集合为D={d1,d2,…,dm}建立对数似然函数为:
式中:m为样本数;n为时间片内节点数;T为时间片数。定义θi,j,k,t=,则式(4)可化为:
式中j、k为节点取值,本文中取离散值1、2、3、4。Ii,j,k,l,t为:
利用拉格朗日乘数法求取L的极大值,得到参数θi,j,k,t的估计值为:
3.2.2 山火发生概率推理
确定模型网络结构和参数后,通过DBN 推理对山火发生概率进行预测。DBN 推理方法可分为精确推理和近似推理2 种方法,本文采用精确推理中的直接计算推理算法[28],该方法无需进行复杂的图形变换,根据贝叶斯公式和条件独立性假设即可实现后验概率推理,推理计算效率较高。
对于T个时间片的网络,假定影响山火发生的人为、气象、植被和地理因子分别为变量R、Q、Z和D,山火为变量F,则在观测值{R1:T,Q1:T,Z1:T,D1:T,F1:T-1}下F在时间片T上的后验概率为:
由条件独立性假设,联合分布概率为:
结合式(8)—(9)可以实现第T个时间片山火发生概率预测。
3.3 模型评估指标
山火预测是一种二分类问题,因此采用混淆矩阵[29]来度量模型泛化性能,如表1 所示。真正类数(true positive,TP)记作NTP,表示实际有火网格样本中被正确预测为有火的数量;假负类数(false negative,FN)记作NFN,表示实际有火网格样本中被错误预测为无火的数量;假正类数(false positive,FP)记作NFP,表示实际无火网格样本中被错误预测为有火的数量;真负类数(true negative,TN)记作NTN,表示实际无火网格样本中被正确预测为无火的个数。

表1 混淆矩阵Tab.1 Definition of confusion matrix
NTP和NTN为模型预测正确的样本数,其占比越高,预测效果越好。为综合评估预测性能,引入准确率(accuracy)和召回率(recall),如式(10)-(11)所示:
式中:A为全体样本中被正确预测的比例;R为实际有火样本中被正确预测的比例,R越高意味着有火预测越准确。
采用ROC 曲线和AUC 值来衡量模型的分类性能[30]。ROC 曲线绘制方法为:将样本预测值降序排列,分别以每个样本的预测值作为分类阈值,将预测值大于或等于分类阈值的样本判断为正类,反之为负类;然后根据式(12)和式(13)计算真正类率(true positive rate,TPR)记作RTP和假正类率(false positive rate,FPR)记作RFP并分别以其为横坐标和纵坐标绘制曲线。ROC曲线越靠近图形左上方,表明模型分类效果越好。
AUC 值为ROC 曲线在区间[0,1]的面积,表示模型根据预测值将正样本排在负样本前面的概率,反映了模型对样本的排序分类能力。当AUC大于0.5 时,表示模型具备分类能力,AUC 大于0.8时,模型具有优良的分类性能。
4 算例分析
4.1 研究区域及数据预处理
本文选择华南地区广东省作为研究区域。2015—2020 年间广东省发生森林火灾3 584 起,空间分布如图3 所示。全省总面积17.97 万平方千米,地形以山地、丘陵为主。广东省大部分地区属亚热带季风气候,全年雨热同期,适宜植被生长。近年来森林覆盖不断扩张,已达58.7%。2021 年,广东常住人口总量达12 684 万人。密集的人口分布,适宜的气候条件和丰富的植被使其易受山火灾害侵袭。
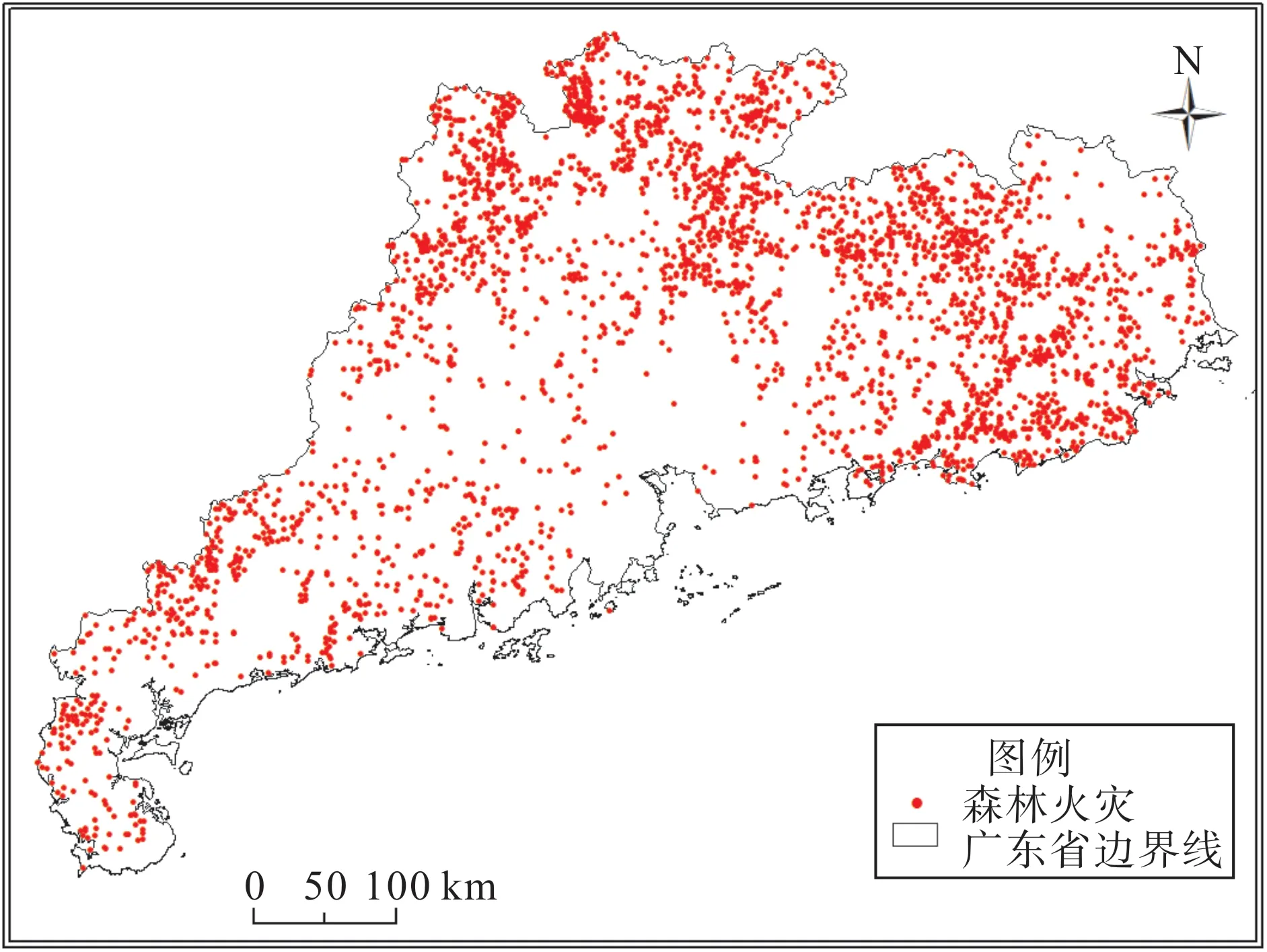
图3 2015—2020年广东省森林火灾空间分布Fig.3 Spatial distribution of wildfires in Guangdong Province,2015—2020
为建立研究区域山火预测模型,收集了广东省2010—2020年的历史火点数据,包括火灾发生时间和经纬度信息。由于超过90%的山火灾害由人为野外用火造成[31],因此将2010—2014 年的历史火点用于计算历史火点密度,综合反映研究区域人为用火分布状况。为全面考虑山火影响因素,从气象、人为、植被和地理4个方面收集了17个山火因子数据,如表2 所示。其中气象因子以及可燃物载量数据由国家卫星气象中心提供,人为、植被和地理因子数据从中国科学院资源环境科学与数据中心(https://www.resdc.cn/)下载得到,分辨率均为1 km×1 km。

表2 输电走廊山火因子Tab.2 Wildfire factors of transmission line corridors
根据山火灾害在时间上呈现月度分布不均衡这一特性,以月为时间单位构建山火样本集。首先将2015—2020年的火点以月为单位进行时间划分,生成逐月火点时间序列数据集。然后为实现网格化收集数据,利用地理信息软件将研究区域按照经纬度划分成0.05 °×0.05 °的网格,并按照目标时间间隔计算落在网格内的火点数,将火点数大于等于1 的网格作为有火网格,否则为无火网格。由于气象数据为广东省气象站点数据,本文采用克里金插值法成1 km×1 km 分辨率栅格数据。最后,逐一提取网格山火因子数据,生成时间序列的有火和无火网格样本集。
4.2 山火因子筛选
按照2.2 节所述方法对17 个山火因子进行筛选,得到各因子贡献度排序以及累计贡献度如图4所示。前9 个山火因子累计贡献度高达95.07%[32],后8 个因子贡献度小,可视为冗余因子,因此选取前9个因子作为模型输入数据。

图4 各因子贡献度及累计贡献度Fig.4 Various factors VIM and cumulative VIM
4.3 静态模型与动态模型对比
4.3.1 网络构建
在短期内,气象因子时序关联性强,随时间变化范围大,其在上一时刻和当前时刻的状态会持续对植被可燃性产生影响,具有时间累计效应。因此在模型中引入时间因素,将气象、植被等动态因子上下两个时刻的状态结合起来。DBN 模型一方面基于概率理论和图论耦合气象、人为、植被和地理等多种因子,另一方面利用有向边将动态变量在时间轴上进行连接,通过转移概率挖掘时序关联性,从而融入时间因素对山火发生概率进行推理。本文构建2时间片的DBN模型,基于各因子在上一时刻和当前时刻的状态对山火发生概率进行推理,以反映当前时刻山火发生的难易程度。
为探索引入时间因素对山火发生风险评估准确性的影响,构建静态BN 模型,与2 个相邻时间片的DBN 模型形成对比。首先以月为时间尺度,构建静态BN 网络结构,然后将BN 拓展至2时间片的DBN模型。
基于筛选得到的9 个山火因子构建静态BN。首先,对各因子进行皮尔逊相关性分析,绘制相关性热力图,如图5所示。

图5 山火影响因子的相关性热力图Fig.5 Wildfire factors correlation heat map
相关系数绝对值大于0.1 的两个因子之间存在一定的相关关系[33]。例如海拔与人口密度、温度和火点密度的相关系数分别为-0.24、-0.18 和0.33,这是因为海拔越高,相应的温度越低,因此人类通常生活在海拔较低的地区,人口密度越大,则由人类活动产生的历史火点密度越大,该地区越容易发生山火。利用有向箭头将这些因果关系进行连接,得到静态BN结构如图6所示。
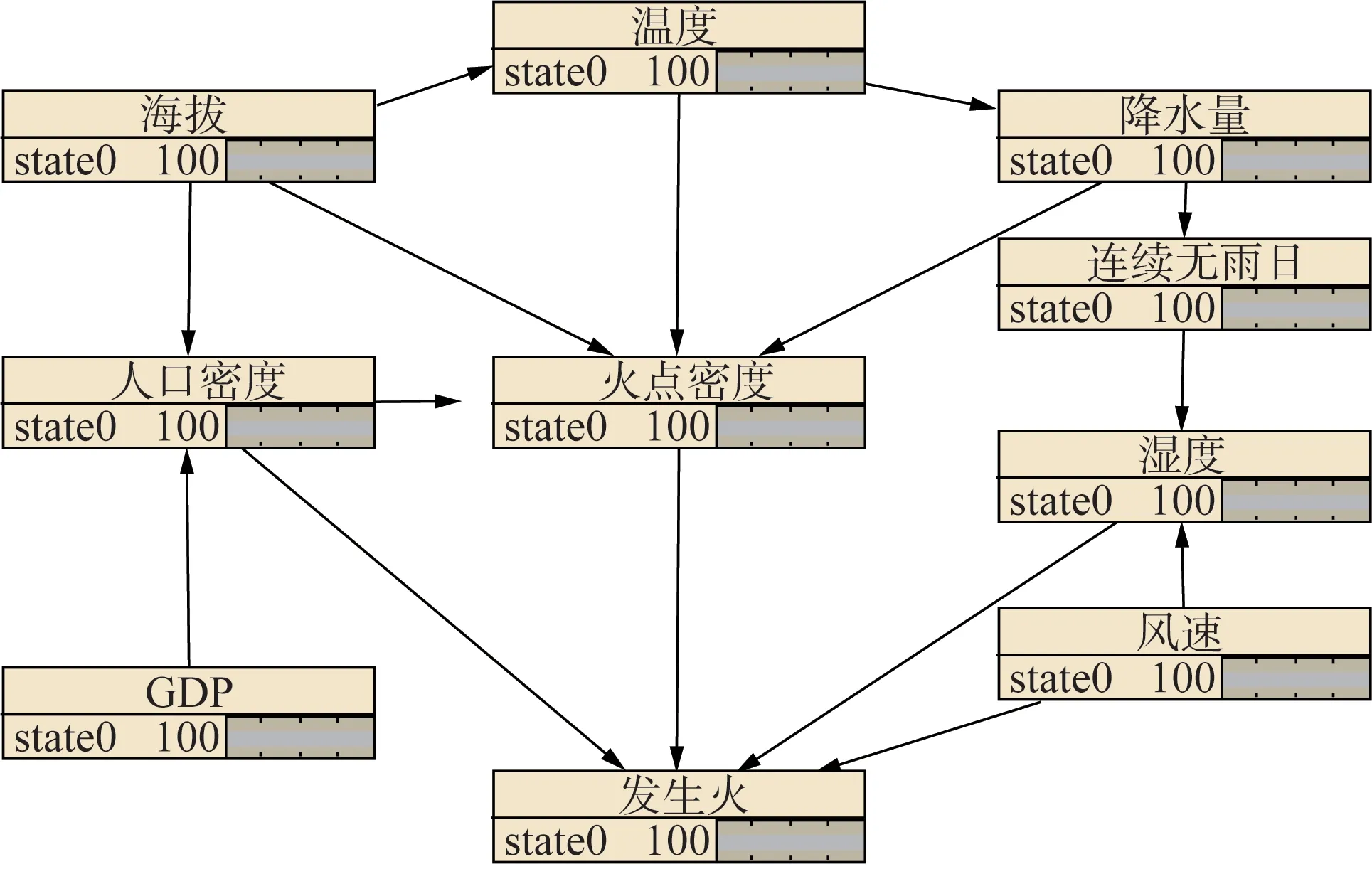
图6 输电走廊山火风险静态贝叶斯网络结构Fig.6 Static Bayesian network structure of transmission line corridor wildfire risk
对静态BN 在时间轴上进行延拓,生成含有2个时间片的DBN,如图7 所示。DBN 网络中温度、降水量、风速、湿度和连续无雨日为动态变量,因此利用有向边将其相邻时间片节点连接,以反映变量的时间变化,其余静态变量则无需在时间片间进行连接。
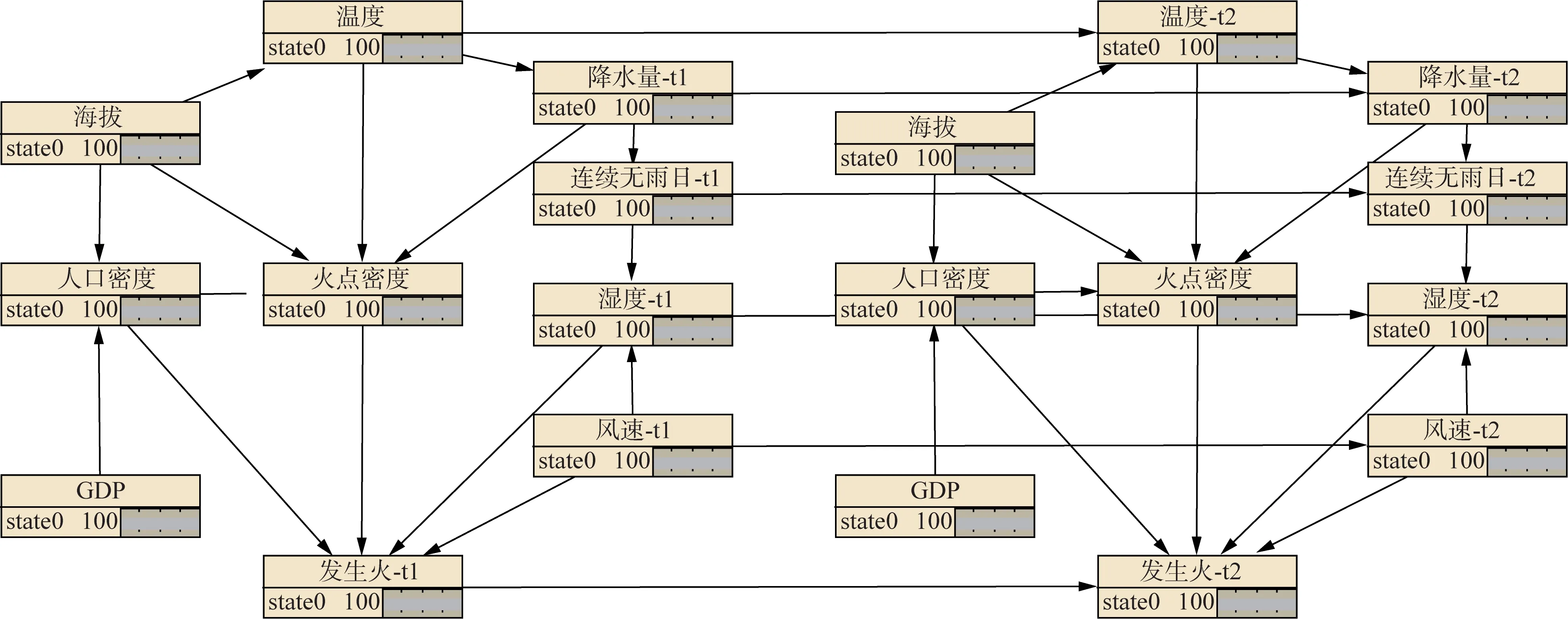
图7 输电走廊山火风险动态贝叶斯网络结构Fig.7 The dynamic Bayesian network structure of transmission line corridor wildfire risk
4.3.2 建模结果分析
由于DBN 处理离散化的数据效率更高,且模型结果更加稳定[34],因此对连续型数据离散化处理。为体现有火与无火网格样本分级离散化后的差异,逐一统计各因子的频数分布,根据数据分布差异性进行离散化处理,如表3所示。
为保障模型结果的稳定性和真实性,采用5 折交叉验证法分别对BN 和DBN 进行训练和测试,即通过分层采样的方式将数据集划分为5 个同等大小的互斥子集,每次以其中4 个子集作为训练集,余下的1 个子集作为测试集。利用极大似然估计法学习BN 和DBN 的节点参数,然后对测试集样本进行山火概率评估计算,将预测概率大于等于0.5 的样本判识为有火,而小于0.5 的样本判识为无火。将5 次测试集预测结果取平均值,使用ROC 曲线、AUC 值、预测准确率和召回率对两个模型进行评价对比,结果如表4和图8所示。

表4 模型评价指标对比Tab.4 Comparison of Model Evaluation Indexes

图8 DBN和BN模型的ROC曲线Fig.8 ROC curves of DBN and BN model
从表中可看出,DBN模型的准确率为78.47%,高于BN 的70.99%,说明DBN 对于样本集的拟合度更高。DBN 召回率为65.89%,优于BN 的49.18%,表明DBN 对于有火网格样本的预测更准确,能有效降低有火的误判或漏判。从图8 可见,DBN 的ROC 曲线处于BN 的左上方,其AUC 值更高,说明DBN具有更好的分类效果。
综上所述,在月时间尺度下,基于相邻2 月的样本构建的DBN 山火风险评估模型明显优于静态BN 模型,这意味着引入上一个阶段的因素后有助于贝叶斯网络进行山火风险评估,并降低对有火的误判或漏判率。
4.4 不同时间尺度下的山火预测模型对比分析
由4.3 节可知,动态贝叶斯模型山火风险评估效果优于静态模型。但是在月时间尺度下,DBN的准确率和召回率仅达78.47%和65.89%,并非足够理想。为此,本文进一步细化时间尺度,通过重新处理动态特征数据,研究DBN 在15 d、10 d、7 d、3 d 等不同时间尺度下的山火风险评估效果。
采用与月时间尺度相同的方法,建立不同时间尺度下的动态数据集,分别构建DBN,利用5 折交叉验证法进行训练和测试,结果如表5 和图9 所示。随着时间尺度的减小,模型准确率和召回率不断上升。其中3 d 模型结果最优,准确率达86.39%,召回率达80.33%。ROC 曲线随着时间减小逐渐靠近左上方,对应的AUC 值也逐渐增大,表明模型分类能力不断提升。

表5 不同时间尺度下DBN模型评价指标对比Tab.5 Comparison of evaluation indexes of DBN model under different time scales

图9 不同时间尺度下DBN模型ROC曲线Fig.9 ROC curves of DBN model under different time scales
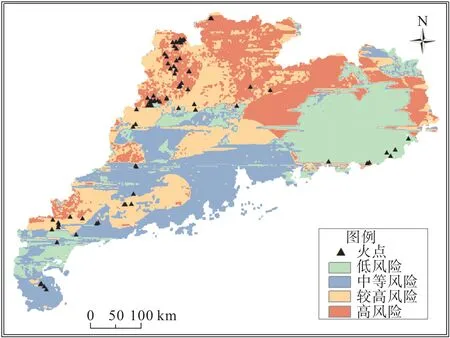
图10 2022年清明节期间广东省山火风险分布Fig.10 Distribution of wildire risk in Guangdong Province during Qingming Festival in 2022
上述结果表明,山火预测准确率随着时间尺度减小而提高,其原因主要为:根据山火因子重要度排序,气象因子为重要因子,一方面,随着时间尺度变小,温度、降水量等气象因子数据越来越精确,更加能够反映当时山火的发生容易程度;另一方面,DBN 将上下2 个时间片的动态因子联系起来,融入了时间信息,使得模型的拟合度不断提升,进而提高模型预测准确度。
4.5 模型工程化应用
为实现山火风险空间分布评估的工程化应用,收集了2022年广东省清明节期间(4月1日—4月6日)山火因子数据,采用训练好的3天DBN模型计算4月4日至4 月6 日山火发生概率。并分别以25%、50%、75%为间断点,将山火发生概率划分为低风险,中等风险,较高风险和高风险四级风险等级,利用地理信息软件将山火风险可视化,绘制成1 km×1 km分辨率的广东省山火风险分布图,如图11所示。
从分布图可以发现,广东省高风险区域主要集中在北部和东部地区,应当重点关注。根据当地电力公司提供的广东省2022 年4 月4 日至4 月6 日期间共计84 起输电走廊山火经纬度信息,提取火点位置对应的风险等级。经验证,其中68 个火点落在较高风险和高风险区域,预测准确率达80.95%,验证了分布图的合理性和适用性。
5 结论
本文考虑时间因素对山火发生的影响,提出了一种基于动态贝叶斯网络的输电走廊山火风险时空评估方法。
1)根据输电走廊山火月度分布不均衡特性,分别建立基于静态贝叶斯网络和动态贝叶斯网络的山火风险评估模型,发现引入上一个时间的因子的动态模型提高了评估准确性。
2)在月时间尺度基础上,研究了时间尺度对DBN 模型效果的影响,分别建立了15 d、10 d、7 d、3 d 动态贝叶斯网络山火风险评估模型。随着时间尺度变小,模型评估效果逐步提升,其中以3 d为时间尺度的DBN 模型测试集准确率达86.39%,召回率达80.33%,这是因为随时间细化,气象因子数据越来越精确,提高了模型预测准确性。
3)利用3 d 为时间尺度的DBN 模型评估了2022年清明节期间广东省山火风险分布,绘制了1 km×1 km 分辨率山火风险分布图,80.95%真实火点被预测成功,验证了本文所提方法的有效性。
猜你喜欢
力学学报(2021年10期)2021-12-02
能源工程(2021年1期)2021-04-13
红外技术(2021年1期)2021-01-29
苏州科技大学学报(自然科学版)(2020年1期)2020-04-13
家庭科学·新健康(2019年10期)2019-11-18
消防界(电子版)(2018年15期)2018-08-29
鹿鸣(2018年1期)2018-01-30
水利技术监督(2016年6期)2017-01-15
中国环境监察(2016年7期)2016-10-23
环球时报(2016-07-14)2016-07-14
