
基于EMD与Attention-LSTM的铁路货运站短期装车量预测研究
2023-12-26 06:30:32汪岗马亮陈奕霖
铁道货运 2023年12期
汪岗,马亮,陈奕霖
(1. 国能包神铁路集团有限责任公司 调度指挥中心, 内蒙古 包头 014000;2. 西南交通大学 信息科学与技术学院, 四川 成都 611756;3. 中国铁道科学研究院集团有限公司 国家铁路智能运输系统工程技术研究中心, 北京 100081;4. 西南交通大学 四川省列车运行控制技术工程研究中心,四川 成都 611756)
0 引言
近年来,随着我国产业结构调整,各种运输方式之间竞争加剧。为防止客户流失、均衡铁路运力配置和实现运输效益最大化,铁路运输企业需要具备较强的精准掌握货运需求和动态部署货运资源的能力。铁路货运站装车量预测研究对货运调度人员提前准确掌握未来货运需求、实现空车提前部署、减少空车无效走行和提高货运效率起到关键作用。
目前关于铁路货运站装车量预测的研究较少,但国内外学者对铁路货运量预测做了大量研究工作,传统的预测方法有灰色模型预测法[1-2]和回归预测法[3],这些方法适合长期的货运需求量预测,在以往稳定、线性变化的货运量需求预测中具有较高的精度。但对于具有随机性、不稳定性和非线性特征的历史数据,这些方法往往表现不佳。针对这一问题,机器学习、深度学习和组合模型等预测法被应用到铁路货运量预测研究中。例如,梁宁等[4]引入灰色关联分析计算货运量影响因素权重,将其作为输入变量构建多项式核函数与径向基核函数线性组合的SVM-mixed预测模型,提高了预测精度;陈鹏芳等[5]采用PCA和WOA算法对LSSVM进行参数优化,提高了模型的准确性和稳定性;考虑到深度学习模型的非线性学习能力和数据拟合能力,程肇兰等[6]选用LSTM网络对广州铁路(集团)公司2010—2017年的货运量数据进行预测,并与ARIMA模型和BP神经网络进行对比,结果表明LSTM模型更佳;欧雅琴等[7]采用蜻蜓算法对LSTM参数进行优化,提升了模型预测性能;郭洪鹏等[8]将Bi-LSTM网络用于铁路货运量预测,验证了该模型在某铁路企业月度和日货运量预测的准确度;徐玉萍等[9]将乘积集结模型与引入注意力机制的LSTM模型进行组合,验证了组合模型用于铁路货运量的预测性能优于单一模型。
这些研究对铁路货运站装车量预测做出了积极探索,但大多以全路或铁路局集团公司管辖范围内的铁路货运量为研究对象,并且以年为时间粒度进行预测,所得结果不适合作为铁路日常工作计划编制的依据,而货运站短期装车量的预测结果更有助于日常工作计划编制与货运组织调整。余姣姣[10]首次以货运站装车量为研究对象,但由于相空间重构参数选择的差异导致SVM模型的不稳定,使得该模型对不同货运站装车量预测的性能不同。张志文等[11]利用结合注意力机制的LSTM模型对国家能源投资集团有限责任公司某一区域内货运站日装车量趋势展开研究,但尚未验证该方法对具体某一货运站的预测性能。
考虑到货运站短期装车量的波动性和随机性,研究将模态分解引入短期装车量预测中,提出EMDAttention-LSTM组合模型。该方法将原本随机、波动性强的短期装车量数据分解成有限个固有模态和趋势分量,分解后的分量序列特征各异,再利用引入注意力机制的LSTM网络对各分量分别进行预测,最后叠加各分量预测结果,完成短期装车量预测工作。结果表明EMD-Attention-LSTM组合模型相较于其他方法具备更高的预测准确度。
1 铁路货运站短期装车量预测组合模型构建
1.1 铁路货运站短期装车量预测定义
货运站装车量预测主要目的是为编制和调整货运日计划提供依据,约定短期装车量预测时间粒度为1 d。预测模型表示为
式中:L为历史数据的时间窗口长度,历史天数;P为预测步长,未来天数;t=(L,L+1,…,N)为可选择的历史数据时刻值,N为历史数据的长度;xt-L+1:t=(xt-L+1,xt-L+1,…,xt-1,xt)表示预测模型输入长度为某货运站L天的历史装车量时间序列,等于历史每天装车量形成的序列;表示某货运站未来P天的装车量预测结果,等于未来每天预测装车量形成的序列;f为通过映射关系建立铁路货运站短期装车量预测模型,实现基于某货运站历史装车量时间序列,对未来装车量序列的预测工作。
1.2 经验模态分解理论
EMD[12]是一种高效的信号分解方法,该方法不依赖任何基函数,具有良好的自适应性,非常适合处理非线性和非平稳的数据。EMD基于数据局部特征时间尺度,从原信号中提取固有模态函数(IMF),其结果是将信号中不同尺度的波动和趋势分解开来,产生一系列具有不同尺度特征的数据序列,每一个序列代表一个固有模态函数,这使得每一个IMF代表了原信号中所包含的尺度波动成分,而剩余项代表原信号的趋势或均值。EMD算法与小波算法相比,可以更准确地反映原始数据的内部特征,有更强的局部表现能力,因而在处理非线性、非平稳数据时,EMD方法更为有效[13]。设装车量时间序列为x(t),其EMD分解步骤如下。
(1)确定x(t)的所有极大值和极小值点。
(2)通过3次样条插值连接极大值点构成上包络线eup(t),连接极小值点构成下包络线elow(t)。
(3)根据上、下包络线,计算x(t)的局部均值m1(t),将x(t)与m1(t)相减得到中间序列h1(t)。
(4)以h1(t)代替原始序列x(t),重复步骤(1)—(3),直到h1(t)=x(t)-m1(t)满足IMF条件,记c1(t)=h1(t),则c1(t)为装车量序列的第1个IMF分量,它包含原始序列中最短的周期分量。
(5)从原始信号中分离出IMF分量c1(t),得到剩余项r1(t)。
(6)将剩余项r1(t)作为新的原始数据,重复步骤(1)—(5),直到rN(t)小于设定值或者rN(t)变成单调函数,停止迭代,得到其余IMF分量和1个余量,如下所示。
至此,装车量序列x(t)就被分解为rN(t),每个IMF分量都反映了原序列在不同时间尺度下的内在模态特征。
1.3 长短期记忆网络
LSTM是循环神经网络(RNN)的变体,解决了RNN存在的长期信息保存和短期输入缺失的问题。LSTM引入门控机制来控制单元内容,LSTM单元结构如图1所示。

图1 LSTM单元结构Fig.1 Structure of LSTM unit
其中,Ct和Ht分别表示模型t时刻下的记忆状态和隐层状态,Xt和Yt为模型的输入和输出,σ为sigmoid激活函数。LSTM单元内部的计算过程如下。首先,将当前时间步的输入Xt和前一个时间步的隐状态Ht-1送入3个具有sigmoid函数和1个具有tanh函数的全连接层分别得到遗忘门Ft、输入门It、输出门Ot和候选记忆元的值。其次,通过遗忘门Ft和输入门It分别控制保留过去记忆元Ct-1的内容和选用候选记忆元的新数据得到当前时刻的记忆元Ct,最后将Ct送入具有tanh激活函数的全连接层,确保其值在(-1,1)内,再与输出门Ot按元素相乘得到新产生的隐状态Ht。其计算公式如下。
式中:Wxi,Wxf,Wxo和Wxc为每一层连接到输入向量Xt的权重矩阵;Whi,Whf,Who和Whc为每一层连接到前一隐状态Ht-1的权重矩阵;bi,bf,bo和bc为偏置参数。
1.4 注意力机制
注意力机制最早由Bahdanau等人在机器翻译模型中提出[14],注意力机制从人类视觉神经系统得到启发,即人类观察到的所有事物并非同等重要,大脑通过将注意力引向人类更感兴趣的一小部分信息,使得人类能更有效地分配资源。在深度学习模型中,注意力机制通过注意力评分函数f计算查询q和键k的注意力权重α,旨在利用注意力权重α实现对值v的选择倾向,通用的注意力机制计算过程如下。
(1)计算某一查询q对数据库中第i个键ki的注意力权重α(q,ki),通过softmax函数将其值限制在(0,1)内。
(2)将注意力权重α(q,ki)与键ki对应的值vi进行加权求和,得到注意力向量,m为数据库中键值对k-v的个数。
1.5 装车量预测组合模型EMD-Attention-LSTM
EMD-Attention-LSTM预测模型首先对历史货运站日装车量数据进行清洗,整理得到重点货运站历史装车量的时间序列数据。由于直接对全部历史数据进行分解会导致信息泄露的问题,因此将历史数据划分为训练集、验证集和测试集,采用EMD算法分别进行分解。随后将分解结果输入到Attention-LSTM模型进行训练,得到各分量预测模型并输出测试集预测结果,最后进行对比验证,EMD-Attention-LSTM组合模型预测流程如图2所示。
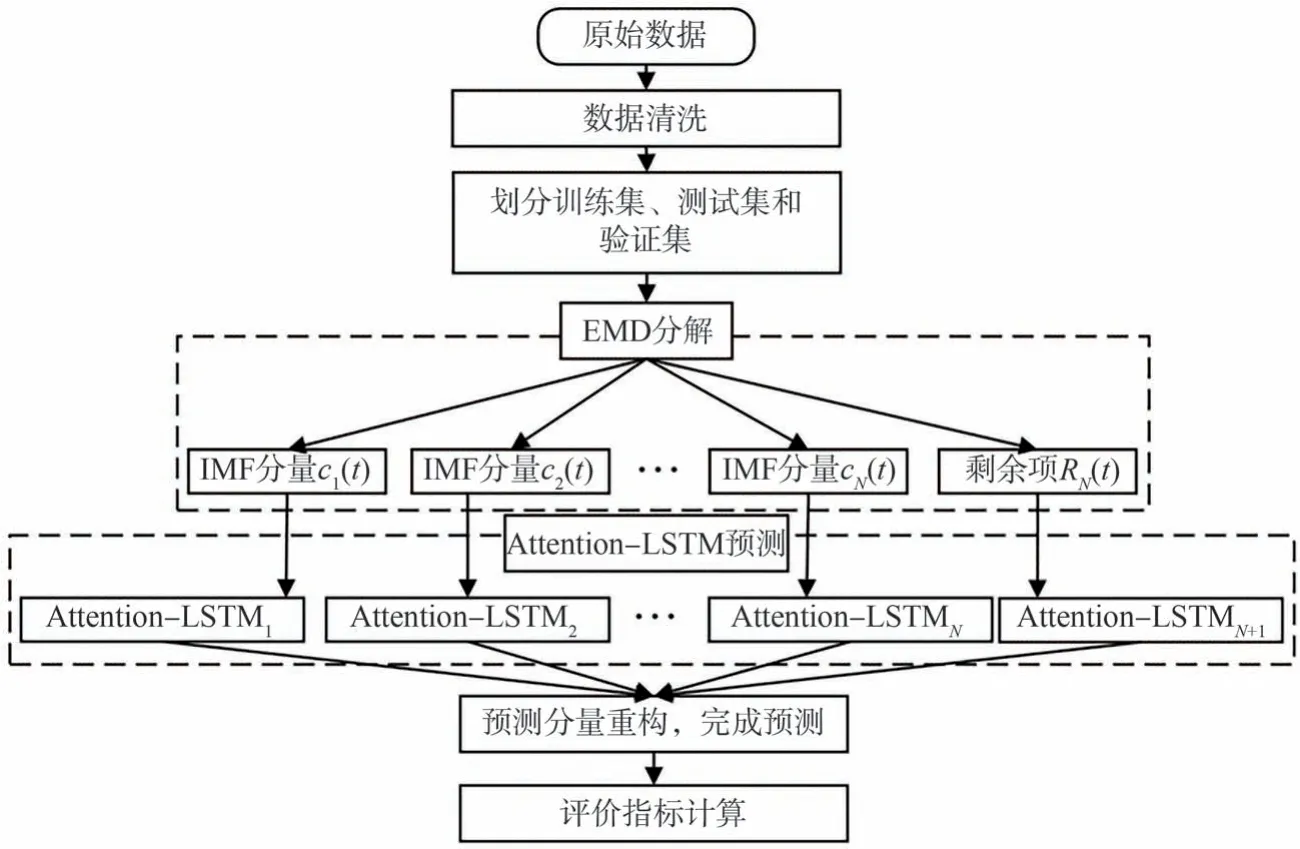
图2 EMD-Attention-LSTM组合模型预测流程Fig.2 Prediction process of EMD-Attention-LSTM
具体步骤如下。
(1)数据处理。收集历史货运站装车量数据,采用均值插值法对缺失数据进行处理,并将历史装车量数据按照6∶2∶2划分为训练集、验证集、测试集。
(2)经验模态分解。采用EMD算法将历史装车量数据分解为N个固有模态分量{c1(t),c2(t),…,cN(t)}和1个剩余项分量rN(t),为减少各分量尺度差异对预测结果的影响,采用min-max归一法对各分量进行归一化处理,将数值缩放在(0,1)之间,计算公式如下。
式中:x*为归一化后的数据;x为输入数据;xmin和xmax为数据中的最小值和最大值。
(3)Attention-LSTM模型预测。建立基于注意力机制的LSTM模型,注意力评分函数设为f(q,ki)=qki,以点积操作实现高效率的注意力机制。将EMD预测分量输入到Attention-LSTM模型,首先通过全连接层将时序输入信息映射为高维特征,再利用两层LSTM网络提取时序数据的有效信息,最后将各分量预测结果相加,重构为最终模型预测结果。Attention-LSTM网络流程图如图3所示。

图3 Attention-LSTM网络流程图Fig.3 Flow of Attention-LSTM network
(4)评价模型预测结果。通过预测值和实际值的误差度量模型精度,选用对称平均绝对百分比误差(SMAPE)、平均绝对百分比误差(MAE)和均方根误差(RMSE)作为评价函数,评价函数值越小表示预测值更贴近实际值,计算公式如下。
式中:n代表待预测装车量天数;和yi为预测第i天装车量的预测值和实际值。
2 实例验证
2.1 实验数据
采用某铁路运输企业3个重点货运站从2021年1月1日至2022年6月30日546 d的历史装车数据进行实验分析与评估,其中A,B站主要运输煤炭等大宗货物,C站主要运输非煤产品和集装箱的零散白货。煤炭等大宗货物均为整列运输,非煤产品和集装箱的零散白货主要以摘挂列车的方式运输,故采用列数表示A,B站装车量,以车辆数表示C站装车量。A,B和C货运站日装车量走势图如图4所示。

图4 A,B和C货运站日装车量走势图Fig.4 Trend of daily loading quantities of freight stations A, B, and C
可以看出A,B和C站日装车量序列在短期内存在波动,在长期内趋于平稳,C站的波动频率和幅度比A,B站更剧烈。采用PyEMD库中的EMD函数将原始数据的波动性和趋势性数据进行分离,EMD算法分解结果如图5所示。

图5 EMD算法分解结果Fig.5 Decomposition results of EMD algorithm
2.2 模型超参数设置
在深度学习时间序列预测任务中,历史数据长度一般为预测步长的3~7倍[15],考虑A站装车量预测,选择输入序列长度L=15 d和预测序列长度P=3 d的数据集,构建货运站装车量预测模型,并基于Python 3.7实现了ARIMA,Attention-LSTM,LSTM和SVM的对比模型。其中,深度学习方法使用了torch-1.13.0-cu117框架实现,而SVM模型则采用sklearn框架进行编写,ARIMA模型使用了statsmodels库实现。通过网格搜索法确定各个模型的最优超参数,A站对比模型的超参数设置如表1所示。

表1 A站对比模型的超参数设置Tab.1 Hyperparameter setting of comparison models at station A
2.3 实验结果与评价分析
为了比较EMD-Attention-LSTM装车量预测模型与其他经典模型在铁路货运站装车量预测性能上的差异,基于之前的参数设置,在同一数据集上对所有模型进行了反复实验。最终得到了A站装车量预测结果的趋势图,A站EMD-Attention-LSTM模型与对比模型预测趋势图如图6所示。
计算得到EMD-Attention-LSTM与对比模型在A站装车量数据上的评价结果如表2所示。

表2 EMD-Attention-LSTM与对比模型在A站装车量数据上的评价结果Tab.2 Evaluation results of EMD-Attention-LSTM and comparison model on the loading quantities of station A
从表2中对比分析得到:EMD-Attention-LSTM模型在SMAPE指标上较ARIMA模型低近3.4%,较LSTM模型低近2.7%;相比于传统方法,EMDAttention-LSTM模型在MAE和RMSE指标上也显著降低;基于深度学习的LSTM与Attention-LSTM模型在SMAPE指标上分别比机器学习模型SVM降低了0.4%和1.8%;而基于统计的时间序列预测模型ARIMA与传统的机器学习模型SVM的预测性能则相差不大;此外,Attention-LSTM模型在3个指标上表现出优于经典模型LSTM的预测性能,但加入EMD分解后的Attention-LSTM模型表现更为优异。
为探究EMD-Attention-LSTM模型的通用性,对同样主要运输煤炭等大宗货物的B站和主要运输零散白货的C站的日装车量进行预测,B货运站装车量预测结果如表3所示,C货运站装车量预测结果如表4所示。该模型在B站同样表现出最优预测性能,当预测步长分别为P=3 d和P=7 d时,EMD-Attention-LSTM预测模型的SMAPE指标比最优的对比模型Attention-LSTM下降了6.7%和3.4%,MAE与RMSE同样优于其他对比模型。在C站该模型比对比模型预测效果要优,但SMAPE指标仅为38.4%。

表3 B货运站装车量预测结果Table 3 Prediction results of loading quantities of freight station B

表4 C货运站装车量预测结果Table 4 Prediction results of loading quantities of freight station C
方差可以衡量时间序列的波动性,自相关系数则可以反映时间序列的趋势性和随机性,计算A,B和C货运站历史装车量时间序列的方差和一阶自相关系数如表5所示。

表5 A,B和C货运站历史装车量时间序列的方差和一阶自相关系数Table 5 Variance and first-order autocorrelation coefficients of loading quantities at freight stations A, B, and C
可以发现预测模型对自相关性较强、方差较小的A,B站预测效果较好,对自相关性较弱、方差大的C货运站预测性能较差。
3 结束语
在分析铁路货运站历史日装车量趋势与特点的基础上,基于EMD时间序列分解算法和Attention-LSTM神经网络构建了铁路货运站短期装车量预测组合模型EMD-Attention-LSTM,并将其应用于某铁路运输企业重点货运站的日装车量预测中。通过与其他主流机器学习和深度学习模型进行对比分析,结果表明EMD-Attention-LSTM模型具有更佳的预测性能。鉴于短期装车量数据存在波动大、随机性强等特点,EMD-Attention-LSTM模型的预测能力不稳定,如B货运站和C货运站未来3 d的装车量预测结果,其SMAPE值分别达到13.8%和38.4%。在后续研究中,将进一步提升模型的泛化能力以满足更多实际预测需求。
猜你喜欢
物流技术(2022年9期)2022-10-28 07:46:20
基层中医药(2021年12期)2021-06-05 06:56:26
装备制造技术(2020年9期)2021-01-26 00:15:28
智族GQ(2019年9期)2019-10-28 08:16:21
企业科技与发展(2019年11期)2019-06-30 02:30:51
新能源汽车报(2019年13期)2019-06-11 11:01:41
英美文学研究论丛(2018年1期)2018-08-16 03:00:06
纺织科学研究(2017年6期)2017-07-03 12:14:15
现代工业经济和信息化(2016年3期)2016-05-17 05:35:08
长江大学学报(自科版)(2014年4期)2014-03-20 13:20:36
