
基于CNN-BiLSTM-CRF 的企业舆情监控模型构建
2023-12-18 18:13:49张欣艺郑军红何利力
计算机时代 2023年11期
张欣艺 郑军红 何利力


关键词:企业舆情監控;CNN;BiLSTM;舆论观点抽取;K-means
中图分类号:TP391.1 文献标识码:A 文章编号:1006-8228(2023)11-136-05
0 引言
在当今的信息化背景下,网络上的大量网络舆情信息得到有效保存。互联网营销平台也被许多企业选择作为开展营销活动的重要根据地,汇聚了大量用户数据、营销活动数据。这些数据对于企业的经营和管理具有极高的参考价值,但如何合理利用这些数据来进行决策指导,是企业面临的重要问题。
近年,基于深度学习的情感分析方法在各个领域内都有所应用。吴贵珍等[1]提出一种将CNN 与双层双向门控循环单元(BIGRU)相结合的方法,改善了CNN只能提取文本局部信息和RNN 容易陷入梯度爆炸的问题。但存在时间效率不高以及随着数据规模增长,训练时间也会显著变长的问题。赵星宇等[2]提出一种融合双向LSTM 和CNN 的混合情感分析模型,改善了现有文本情感分析方法实时性不强、难以应用到大规模文本等问题。曾莉等[3]提出一种融合主题模型和情感分析的LDA-Attention-BiLSTM 模型,对舆情中的热点话题和情感时序变化有更好的反映。但该模型在方便计算的同时丢失了很多信息。杨秀璋等[4]提出一种改进LDA-CNN-BiLSTM 模型,在社交媒体情感分析忽略情感特征的长距离语义关系,无法精确捕获带有情感色彩的特征词,过度依赖人工标注等问题上做出了改善。
企业在舆情监控时需要更多地考虑到评价的主体,并聚焦于互联网营销平台和网络舆情平台中多数人关注的事件,不同的企业所关注的内容会不同。因此,目前的舆情监控模型不完全适用于各个企业。我们可以将以上的问题转换为对特征向量分配权重的问题。目前,许多研究人员针对这个问题做出了不同的改进。赵蕊洁等[5] 提出一种基于Attention-BiLSTM-CRF 的医药实体识别模型,提高了医药实体识别的效果,但应用范围较为单一。佘恒健等[6]采用BiLSTM-CRF 方法,对标注的政务公文进行了中文实体识别实验,更加准确有效地识别政务公文中的实体。陈伟等[7]提出了一种多头自注意力机制与条件随机场(CRF)结合的实体抽取模型,改善了传统命名识别容易受上下文相对距离的影响、实体整体识别效果差的问题。
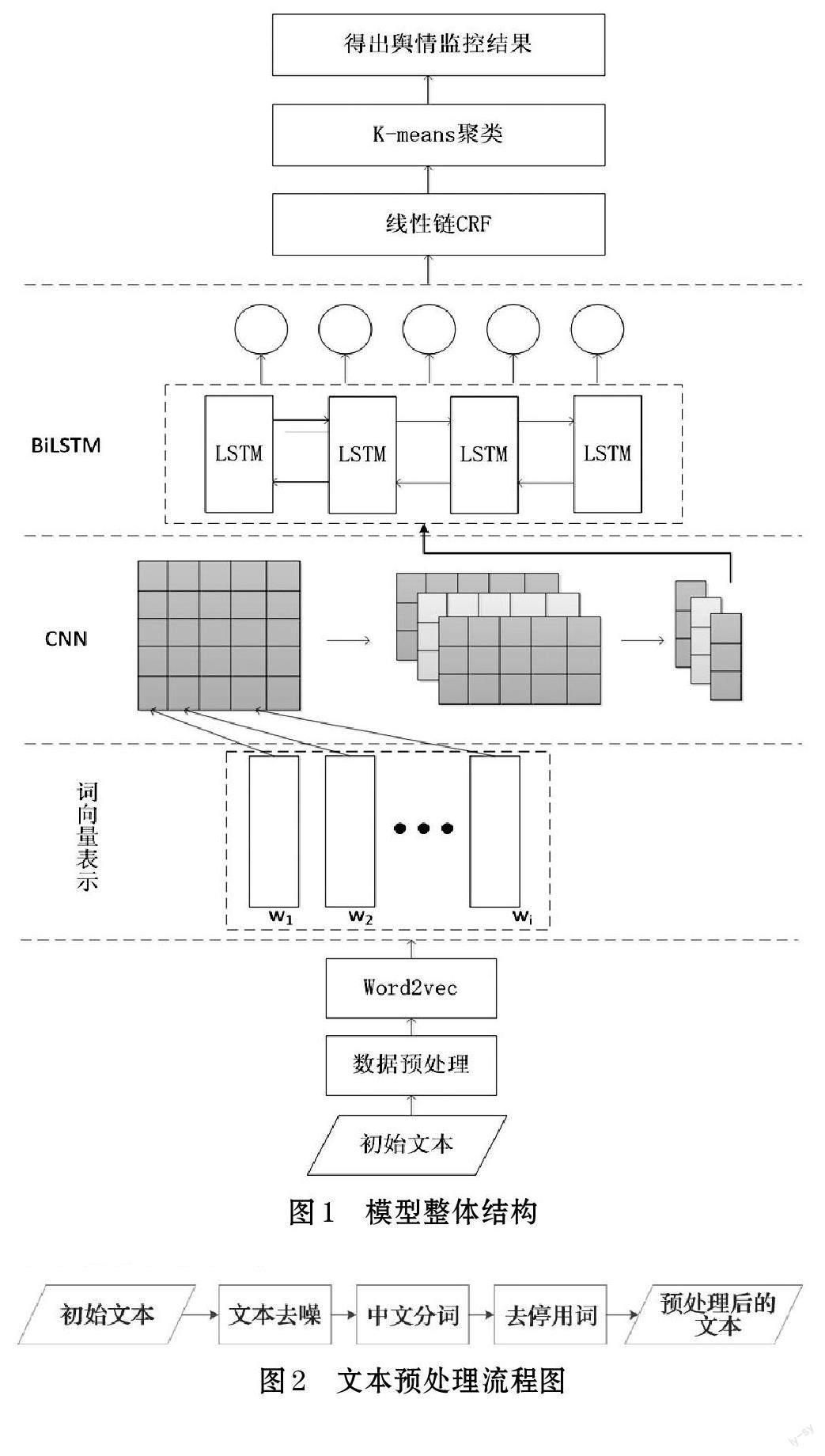
综上所述,增加条件随机场(Conditional RandomField,CRF)[8]能在以上模型中起到很好的效果。但是针对企业舆情监控仍存在以下问题:①单一的神经网络模型无法充分提取情感特征,卷积网络只能提取局部特征,而具有序列特性的神经网络(如LSTM,GRU等)只能提取整个序列特征,其时间效率低下。②虽然网络舆情监测一直是比较热门的研究方向之一,但目前的舆情监控模型与企业的需求契合度较低。因此本文从情感分析的角度,运用深度学习理论,提出了一种基于CNN-BiLSTM-CRF 的企业舆情监控模型。首先将社交平台评论信息和互联网营销平台留言信息进行预处理,然后使用Word2vec 技术获取文本的词向量表示。将其输出作为CNN 卷积神经网络的输入,再将经过处理的数据输入到BiLSTM 网络层,加入条件随机场模型对标签序列进行优化,最后,基于K-means 进行观点聚类,得到企业网络舆论焦点,从而进行企业舆情监控。本文的主要贡献如下:①提出一种结合CNN-BiLSTM 和条件随机场、K-means 聚类的模型,实验结果表明,该模型在各个指标上均得到提升,说明了模型的有效性。②根据企业舆情监控特点,结合社交平台和互联网营销平台信息,建立了面向企业的舆情监控模型。
1 模型构建
本模型首先将社交平台评论信息和互联网营销平台留言信息作为初始文本进行预处理,并将预处理完的短文本数据导入Word2vec[9]获取文本的词向量表示,将其输出作为CNN 卷积神经网络的输入,通过CNN 的卷积层和池化层的构建,用来提取特征,再将经过处理的数据输入到BiLSTM 网络层,加入条件随机场模型对标签序列进行优化,最后,基于K-means进行观点聚类,得到企业网络舆论焦点,从而进行企业舆情监控。模型整体结构如图1 所示。
1.1 数据预处理
首先,我们需要对收集到的数据进行处理,转化为机器可以接受的输入。本模型文本预处理的具体步骤如图2 所示。
本模型主要采用JieBa 分词库进行分词,使用Word2vec 技术向量化实验数据。由于数据量较大,本模型选用word2vec 的Skip-gram 模型进行词向量训练,以分词处理后的文本序列(w1,w1,…,wn)转换为低纬稠密的词向量序列作为CNN 神经网络的输入。Skip-gram 模型结构图如图3 所示。
2.4 对照基准模型
本次实验选取CNN、CRF、LSTM-CRF、BiLSTMCRF和BiGRU-CRF 模型来与本文模型做对比实验。
⑴ CNN:经典深度学习模型,很早被应用于命名实体识别,提取句子级别的特征。
⑵ CRF:将命名实体识别问题转化为序列标注问题,可以考虑到复杂的特征。
⑶ LSTM-CRF:将LSTM 和CRF 结合在一起,可以捕捉到输入的过去特征和句子级的标签信息。
⑷ BiLSTM-CRF:与LSTM-CRF 类似,将LSTM换为BiLSTM,是序列标注问题的经典模型。使用Word2vec完成词向量训练,并将其输出值导入BiLSTM来获取文本特征、得到各标签取值的概率,通过CRF约束标签间的顺序关系。
⑸ BiGRU-CRF:BiGRU 网络是由RNN 发展而来,它在处理序列数据的任务中被广泛使用,结合CRF优化目标函数。
2.5 实验结果与分析
本次实验选取CNN、CRF、LSTM-CRF、BiLSTMCRF和BiGRU-CRF 模型来与本文提出的模型做对比实验,实验结果如表3 所示。本文提出的模型最后结果精确率达到88.26%,召回率为87.60%,F1 值为87.93%,相较于其他模型结构,各个指标都有所提升。
3 结束语
通过对网络社交平台舆情信息和企业互联网营销平台相关信息的处理分析,可以实现对企业的舆情监控,并指导企业决策。在当前的互联网+环境下,这对企业来说是必不可少的,基于此,本文提出了一种基于CNN-BiLSTM-CRF 的企业舆情监控模型。通过在真实数据集上进行对比实验,本文模型在精确率、召回率、F1 值指标上均优于其他基准模型,验证了本文提出模型的有效性。接下来,将基于目前的研究成果,面向企业网络舆情监控,结合企业舆情焦点中的感情极性进行研究。
