
基于深度卷积网络和卷积去噪自编码器的水声信号识别方法
2023-12-13 11:43:46徐剑秋
网络安全与数据管理 2023年11期
曹 琳,彭 圆,牟 林,孙 悦,徐剑秋
(水下测控技术重点实验室,辽宁 大连 116013)
0 引言
如何在复杂的海洋环境下对水声信号进行识别是目前亟需解决的难题。传统的基于信号特征的水声目标信号识别方法,特征受时/频/空域变换算法的制约不可避免地丢失目标信息。深度学习方法能够自动地通过逐层训练学习到数据高级的特征表示,从而得到更丰富的特征信息。该方法集特征提取与分类于一体,完成从输入信号到输出分类的处理。随着深度学习在图像识别、语音识别等领域取得了巨大的成功,国内外学者陆续尝试将深度学习方法应用于水声信号识别中。一些学者将卷积神经网络对水声信号的时频谱特征进行学习和识别[1],有效降低了噪声的影响,分类精度可达98.57%,取得了很好的识别效果,李俊豪等学者根据水声信号的特点,从水声信号时频特征出发设计了深度卷积网络[2],有助于提取到具有一定物理意义的谱特征,识别率显著提高。但由于水声信号的获取难度大,导致水声数据样本是小样本,样本较少模型容易产生过拟合的现象。深度自编码网络可以对原始数据进行有效的降维,避免模型出现过拟合。陈越超等学者基于降噪自编码器对水声数据进行特征提取与识别[3],结果表明,对于不同类型目标与同一目标的不同状态,降噪自编码器都能提取可分性特征,识别率也高于其他对比方法。薛灵芝等学者对深度自编码网络进行了改进,在最后一层隐藏层的输入值中加入第一层的特征值,有效地避免了单一通道中由于连乘导致的梯度消失问题[4],结果表明,该算法能有效地对水声信号进行特征提取和分类,并具有良好的鲁棒性。但是自编码器一般基于全连接的方式构建网络模型,但是全连接网络的运算量较大,对实时性要求较高的应用来说有较大的局限性。
综上所述,本文综合利用卷积神经网络(CNN)和卷积去噪自编码器(CDAE)的优势,构建了适应水声信号的深度卷积网络和卷积去噪自编码器(CDAE-CNN),将水声信号的Lofar谱特征作为模型的输入,进行特征提取和分类,利用更少的参数学习更丰富的特征,实现对水声信号的分类。
1 深度神经网络
1.1 卷积神经网络
卷积神经网络(CNN)是被设计用来处理多维数组数据的神经网络[5],例如时间序列数据和图像数据。它在图像检测、语音识别等领域表现优异。卷积网络具有局部连接、权值共享、池化以及使用多个网络层的特点[5],可以识别数据中的局部模式,利用更少的参数获得更丰富的特征。一般卷积神经网络结构中的基本组件都是卷积层、池化层交替使用的,其后跟着全连接层,对于分类任务而言,需要经过Softmax操作后进行最终的分类输出。
卷积层是CNN的核心层,主要是通过卷积核提取输入数据的特征,它是在做卷积过程中的滤波算子。卷积核大小的设置决定了卷积网络提取样本特征的能力的强弱,将卷积核的高(h)和宽(w)设置成w>h的矩形能够提取图像中与频率相关的特征,相反,将卷积核的高和宽设置成w
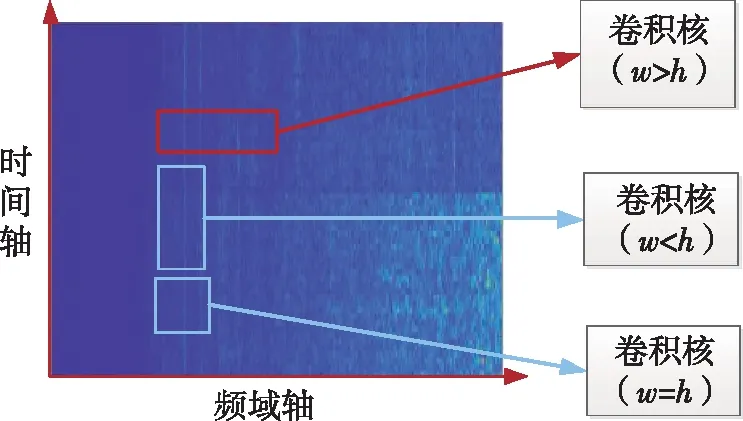
图1 卷积核尺寸
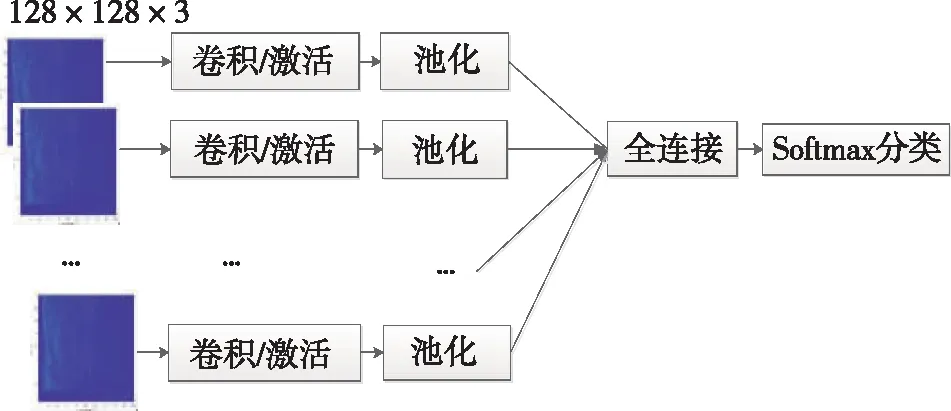
图2 卷积神经网络结构
1.2 卷积去噪自编码器
自编码器是一种经过无监督训练后能将输入复制到输出的神经网络[6]。该网络由两部分组成:编码器和解码器,编码器可以用h=f(x)表示,式中x为输入数据,f为编码函数,h为x的特征表达,解码器可以用解码函数r=g(h)表示,式中g为解码函数,r为输出数据,它们之间通过隐藏空间相连接。去噪自编码器是与自编码器具有相同的结构[3],只是在训练样本中向x中加入了噪声,得到估计值x′,训练时学习从含噪声的输入中去除噪声获得纯净的输入,这样就增强了模型对信号的特征提取能力。传统的自编码器最小化以下目标[6]:
L(x,g(f(x)))
(1)
其中L是一个损失函数,惩罚g(f(x))与x的差异。
而去噪自编码器最小化为[6]:
L(x,g(f(x′)))
(2)
其中x′是被某种噪声损坏的x的副本,图3是去噪自编码器的模型结构图。
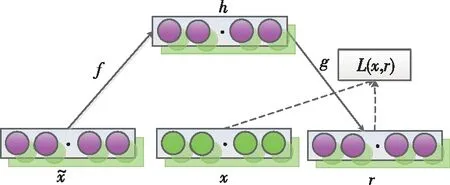
图3 去噪自编码器结构


图4 卷积去噪自编码器结构
2 模型结构介绍
本文结合CDAE和CNN特点设计适合水声Lofar谱的分类网络(如图5所示)。模型主要由三个网络组合而成,即网络1、网络2和网络3,网络1和网络2主要是CDAE网络结构。其中网络1中主要由卷积层、激活层和池化层交替4次组成编码器。第一个卷积层采用64个卷积核,第二个卷积层采用32个卷积核,第三个卷积层采用16个卷积核,第四个卷积层采用8个卷积核,每个卷积层的卷积核大小都设置成3×3,激活层采用ReLU函数来激活,它能更好地增加模型的非线性,并简化模型来学习水声信号中更复杂的关系。池化层采用最大池化来对特征进行降维,同时降低卷积层对特征位置的敏感性。128×128×3的水声Lofar谱图经过网络1的编码器后输出被压缩成16×16×8的特征,压缩后的特征虽然保留了水声信号中最重要的信息,但是大部分的细节信息都丢失了,这时需要解码器来获取更多水声信号的细节信息。网络2为模型结构种的解码器,主要由上采样层、卷积层和激活层交替3次组成,其中每个上采样层的窗口大小被设置成2×2。第一个卷积层采用8个卷积核,第二个卷积层采用16个卷积核,第三个卷积层采用3个卷积核,用于恢复水声Lofar谱图原RGB通道数,每个卷积核的大小都设置为3×3。在训练前,对水声Lofar谱数据集添加噪声系数为0.15的随机噪声,这样就能保证构建的CDAE提取出水声Lofar谱图的稳定特征。此外,为了适应水声信号自身的特点,本文将CNN的结构进行了改进,设计了网络3用于对水声Lofar谱图进行分类(如表1所示),该网络卷积层的卷积核设置成了w>h大小,提取水声Lofar谱图中稳定的特征信息。由于本文使用的数据集样本量较小,为了防止网络模型在训练过程中出现过拟合,本文在全连接层的后面加入了Dropout层,以简化网络模型的结构。

表1 网络3的CNN网络模型结构
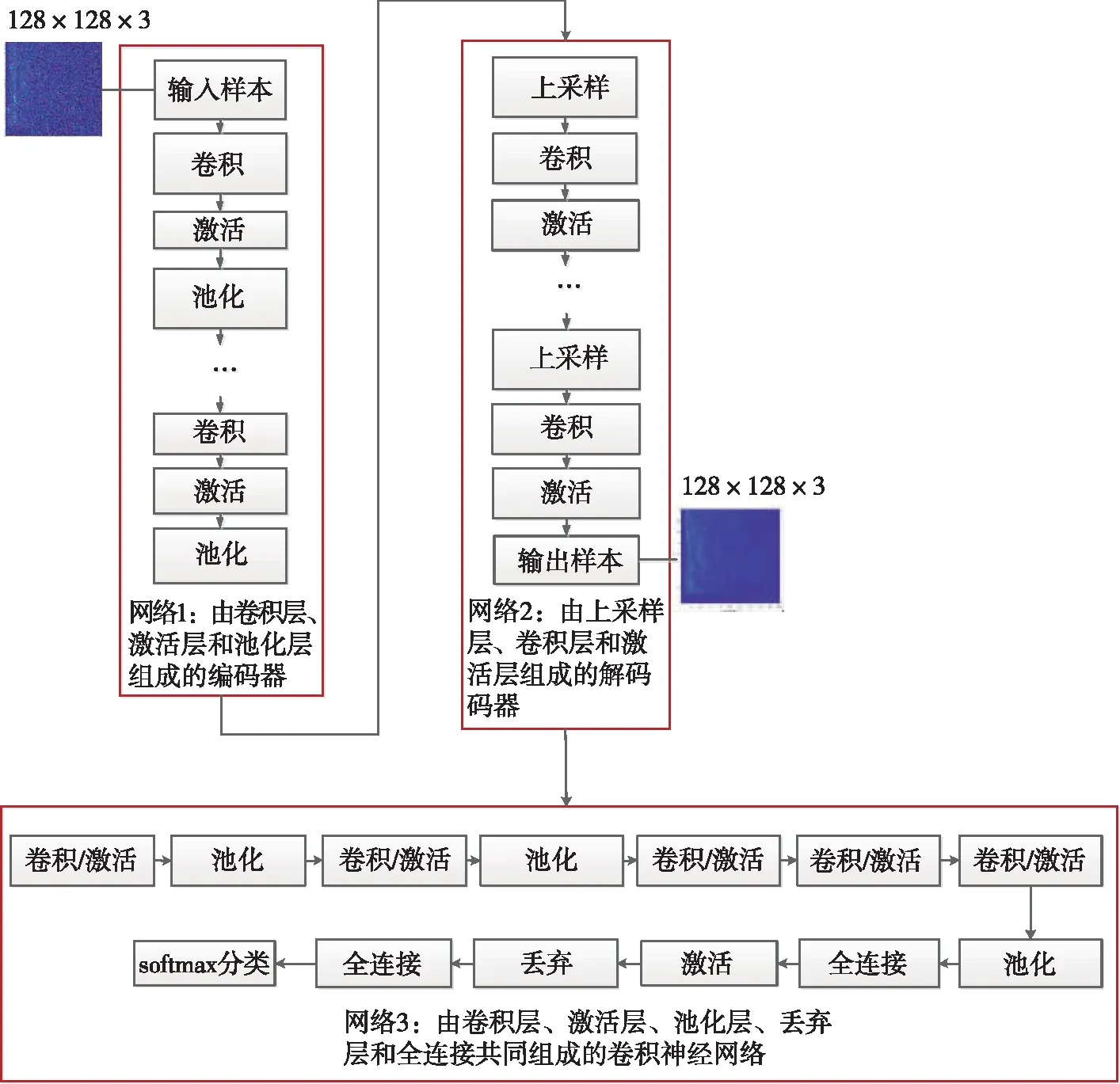
图5 CDAE-CNN网络模型结构图
3 模型实验与结果分析
3.1 数据集
本文使用实测的水声信号对方法的有效性进行验证,现有数据的种类为A、B两类目标,共713个样本,每个数据样本时长10 s。首先对水声原始音频信号进行FFT处理,得到Lofar谱数据集,将Lofar谱图像结构被统一调整成128×128×3。训练时将所有的数据随机划分为82%的训练集,为604个样本,18%的测试集,为109个样本,数据集情况如表2所示。
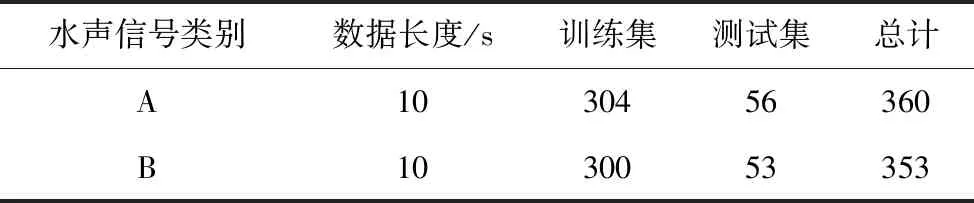
表2 水声信号数据集
3.2 模型训练结果分析
本文在TensorFlow框架下利用水声Lofar谱数据集对设计的CNN、CDAE-CNN网络模型进行训练,训练学习率设置为0.000 5,动量超参数设置为0.9,训练批次大小为16。
经过100次的迭代后,分别得到CNN网络模型和CDAE-CNN网络模型的训练损失率(如图6、图7所示),水声Lofar谱图的识别测试准确率如表3所示。
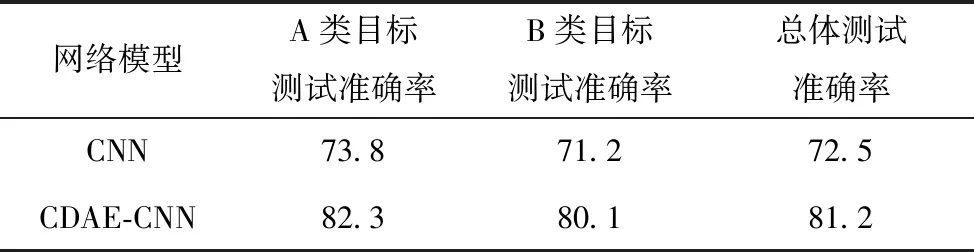
表3 不同方法的测试准确率对比 %

图6 CNN模型训练过程损失率曲线

图7 CDAE-CNN模型训练过程损失率曲线
从图6、图7的模型训练损失率曲线中可以看出,CDAE-CNN模型的拟合效果较好,另外,从表3中可以看出,与CNN方法进行对比,本文提出的CDAE-CNN模型的测试准确率更高。
4 结论
本文根据水声信号的特点,设计了卷积网络与卷积去噪自编码器的组合网络,通过卷积去噪自编码器对输入数据进行降维和特征提取,将卷积神经网络中卷积核的形状进行了改进,以适应水声信号Lofar谱中频率随时间稳定分布的特点,提取出用于识别的更稳定的特征。针对水声数据集样本量较小,模型容易出现过拟合的问题,在CNN全连接层的后面加入了Dropout层,试验结果表明,本文提出的模型的总体测试准确率为81.2%,性能高于CNN网络。
本文的不足之处在于所使用的数据类型单一,数据集样本量较少,下一步需继续扩充数据集,同时充分考虑海洋环境对数据集的影响,不断优化网络模型参数,提升模型的泛化性能。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年11期)2019-07-04 00:34:38
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
电子设计工程(2017年20期)2017-02-10 03:39:29
电子制作(2017年22期)2017-02-02 07:10:34
电子制作(2017年19期)2017-02-02 07:08:28
系统工程与电子技术(2016年7期)2016-08-21 13:59:18
电子器件(2015年5期)2015-12-29 08:42:24
声学技术(2014年1期)2014-06-21 06:56:22
