
基于深度相机与激光雷达数据融合SLAM方法研究*
2023-12-13 11:26:06吴耀威吴自然赵宇博缪宏圣
机电工程技术 2023年11期
吴耀威,吴自然,2,赵宇博,缪宏圣
(1.温州大学电气与电子工程学院,浙江 温州 325035;2.温州大学乐清工业研究院,浙江 温州 325035)
0 引言
目前的同步定位和地图构建(SLAM)方案大致分为使用激光雷达传感器的激光SLAM 与使用视觉传感器的视觉SLAM。激光SLAM 与视觉SLAM 经过了近30年的研究,目前已经有成熟并且可以落地的方案出现。其中基于激光雷达的SLAM 方案有GMapping[1]、Cartographer[2]、Hector[3]等。基于相机的SLAM 方案有基于单目相机的ORB-SLAM 系列[4-6]、使用深度相机的RGB-D SLAM[7]。虽然上述方案基本解决了SLAM 问题,但使用单一传感器的SLAM 方案仍然存在着许多不足。如使用单目相机的SLAM 方案,通过提取关键帧图像上的特征点[8]来估计机器人的位姿增量,然而单目相机所构建的关键帧图像质量严重依赖环境中的光照条件。通常在强光或者黑暗的条件下由于RGB 图像缺乏环境中的纹理信息,将导致SLAM 系统无法提取图像中的特征点来构建特征地图,因此基于单目的SLAM 在室外强光或者黑夜环境中极易失效;使用深度相机的RGB-D SLAM,利用RGB-D 相机的成像特点,通过深度图获得每一帧图像中的像素深度,弥补了单目SLAM 需要消耗大量计算性能用于估计像素深度的缺点,但是RGB-D 相机往往精度与量程有限,因此只能用于室内建图。相较于受环境限制的视觉SLAM,激光SLAM 方案的应用场景要更加广泛,因此被常用于移动机器人的建图与导航任务[9]。虽然激光雷达具有精度高、抗干扰能力强等特点,但是仍有其局限性。例如二维激光雷达只能扫描单一平面上的2D信息,无法检测到扫描平面之外的障碍物,使用多线激光雷达[10]或者添加多组处在不同平面的二维激光雷达[11]可以解决上述问题,但是这样的方案造价高昂无法普及。由于使用单一传感器的SLAM 技术存在上述缺点,目前研究者开始探索融合激光雷达与深度相机等多传感器信息融合的SLAM方案。Ali Yeon[12]分析了融合深度相机与2D激光雷达信息的可行性,但是并未进行实验验证。Federico Nardi[13]提出了一种利用深度图模拟2D 激光雷达的方法,利用深度相机发布的深度图像提取出伪激光雷达数据,进而用于构建占用栅格地图,但是所提出的方法精度与效率较低。陈鹏[14]提出了一种利用贝叶斯估计理论融合视觉局部地图与激光局部地图得到全局地图的方案。钟敏[15]利用深度相机进行运动估计矫正激光SLAM 过程中的位姿累积误差,郑丽丽[16]通过扩展卡尔曼滤波框架融合IMU、轮式里程计与视觉里程计,从而提高机器人位姿估计精度,并没有考虑地图构建任务。
针对上述问题本文提出了一种深度相机与激光雷达在数据层面上的融合方法,融合后的传感器数据使用GMapping算法进行建图,最后利用Gazebo仿真软件搭建移动机器人仿真环境,验证本文所提出的传感器融合方法的可行性。
1 传感器模型
本文提出的传感器数据融合方法依赖于单线激光雷达与深度相机这两种传感器,单线激光雷达作为移动机器人环境感知的核心功能传感器,具有测距精准、感知范围广、抗干扰、运行稳定可靠等特点,在传感器融合过程中主要用于环境中的平面障碍物信息测量。深度相机是一种能够获取场景中物体与摄像头之间物理距离的相机,主流的深度相机通常由多种镜头、光学传感器组成,通常使用深度相机获取三维空间中的障碍物信息。本文主要研究的侧重点在于融合两种传感器的数据。
2 传感器数据融合
2.1 传感器数据融合框架
传统的SLAM 研究通常集中在单一传感器上,然而不管是基于视觉传感器的SLAM 还是基于激光雷达的SLAM 都无法准确的描述出复杂的环境,因而需要用到传感器融合技术,使用多个传感器能够提供丰富的环境信息,减少测量误差,提高移动机器人的运行鲁棒性。本文使用深度相机与单线激光雷达传感器,通过数据融合的形式实现传感器之间的优势互补。下面将从传感器外参联合标定、深度相机点云处理、传感器数据融合3个方面进行研究,图1所示为传感器数据融合总体框图。

图1 传感器数据融合总体框图
2.2 传感器外参标定
移动机器人搭载多种传感器,不同传感器通常位于移动机器人载体的不同位置,因此传感器之间是存在外参变换的。然而传感器融合技术需要将不同传感器之间的数据转换到同一坐标系下进行处理。为了求出传感器之间的外参矩阵,需要进行传感器外参联合标定实验,该步骤是传感器融合技术的必要步骤。
本文需要融合深度相机与激光雷达的数据,采用文献[17]的方法进行深度相机与激光雷达的联合标定。图2所示为深度相机与激光雷达联合标定实验示意图,由图可知深度相机通过场景中的棋盘格标定内参,激光雷达对场景中的棋盘格进行测量形成线状特征,通过构建三维激光点与棋盘格三维坐标之间的约束关系,进而求解深度相机与激光雷达的外参。其中传感器外参求解的本质就是估计激光雷达坐标系与相机坐标系之间的坐标变换。
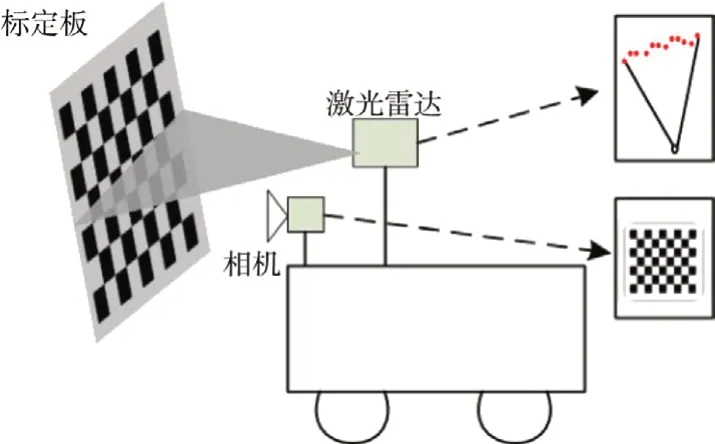
图2 联合标定实验示意图
为了描述外参标定的过程,引入如图3所示4个坐标系:激光雷达坐标系Ol-XlYlZl,基准坐标系Ow-XwYwZw,相机坐标系Oc-XcYcZc以及图像坐标系O-uv,其中基准坐标系为世界坐标系,为空间中的每一个点赋予坐标信息。激光雷达与相机坐标系为传感器中的每一个观测点赋予坐标信息。雷达外参的求解可以由式(1)实现。

图3 各坐标轴关系
同理对于相机坐标系与基准坐标系之间的外参标定,由式(2)描述:
根据针孔相机模型,如图4 所示。对于在相机坐标系下的三维空间点P,有齐次坐标P=[xc yc zc1]T,点P在成像平面上的坐标为P′=[u v1]T,点P与P’存在如下转换关系:

图4 针孔相机模型
式中:[xw yw zw]T为世界坐标系中的坐标;fx和fy分别为相机坐标为相机在x方向与y方向上的等效焦距;Cx和Cy分别为像素中心点在成像平面上坐标。
在联合标定过程中,激光雷达会在棋盘格标定板上生成扫描点,每一个扫描点都会在相机的图像空间中存在唯一的一个像素点与之对应。因此二维激光雷达与相机之间的外参标定问题即为激光雷达数据点与二维图像像素点之间的映射矩阵求解问题,联立式(1)、(2)、(3)可得外参标定问题方程组为:
式中:[xl yl1]T为激光雷达数据点的齐次坐标;[u v1]T为激光点对应的像素齐次坐标;Rt和tt分别为激光雷达坐标到相机坐标的旋转矩阵与平移向量。
2.3 深度相机点云预处理
根据第1 节描述的传感器模型,深度相机能够发布环境点云,但是发布的环境点云中包含大量的冗余点云。如图5 所示为深度相机发布的点云,由图可知,过高的墙体与地面点云不属于机器人建图时的障碍物信息,因此需要将这些点云进行剔除。本文采用VoxelGrid 体素化网格滤波器进行点云降采样,之后在使用随机抽样一致性算法RANSAC 提取地面点云并剔除,对于过高的墙体点云可以通过设置点云高度阈值进行剔除,具体步骤如下。
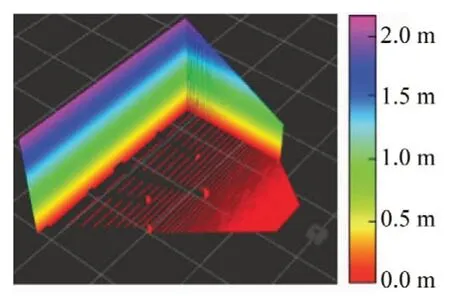
图5 深度相机发布的原始点云
(1)点云降采样处理:将深度相机发布的点云转换为能被PCL 库处理的点云格式,利用PCL 中的体素滤波器进行滤波处理,滤波后的点云如图6所示。通过与图5所示的原始点云进行对比可以看出,滤波后的点云数量明显减少,但是点云的形状特征并没有丢失。

图6 滤波后的点云
(2)去除过高点云:由于本文采用的机器人为地面移动机器人,因此过高的点云将不被视为障碍物。本文所用的机器人总高度为0.15 m,以0.30 m 为阈值,遍历所有点云的z轴数值,当点云的z轴数值小于0.30 时,即可保留该点云,图7所示为剔除过高点云之后的点云图。从图中可以看到使用该方法有效地去除了过高的点云,并且保留了地面上的障碍物点云。

图7 剔除过高点云
(3)去除地面点云:本文使用随机抽样一致性算法RANSAC去除地面点云,首先通过计算地面点云法向量,利用地面法向量计算地面拟合方程式如下:
通过RANSAC 算法随机选择数据点并计算该点所在平面方程π(A,B,C,D),计算点云数据中每一个点到该平面的距离,利用距离阈值dmax统计出该阈值内的点数Nin,重复上述过程,最终选择点数最多的平面方程,该平面方程所构成的点集为{P1,…,PN},利用该集合最小化距离函数式(6),求得最优地面拟合方程如下:
其中Dk表示集合{P1,…,PN}中的第k个点到地面平面的距离。满足最优地面拟合方程的点云即为地面点云,去除地面点云后的深度相机点云数据如图8所示。

图8 剔除过高点云与地面点云后
(4)点云转换伪激光雷达数据:去除地面与过高点云之后的数据仍然具有冗余的信息,本文采取点云投影的方法,将第三步所得点云转换为伪激光雷达数据,从而实现深度相机点云对激光雷达数据的模拟,转换原理如图9所示。
设障碍物点云为Mi(xi,yi,zi),地面投影点云为mi(θi,di),两者之间的转换关系由式(7)~(8)描述:
对于给定的深度相机,已知相机水平FOV 范围为(βmin,βmax),一帧激光束共有N个点,假设点mi(θi,di)为OC射线上距离光心O最近的点,则可以计算点mi(θi,di)在模拟激光数据中的索引值为:
重复上述步骤,即可得到模拟激光数据,如图10 所示为模拟激光数据。
2.4 传感器数据融合
本文采用点云融合的方式将深度相机模拟激光数据与激光雷达数据进行融合,先将激光雷达数据转换成点云格式,之后利用传感器外参矩阵将模拟激光点云通过坐标变换,转移到激光雷达坐标系下,最后在同一坐标系下将两种传感器点云进行融合,融合后的点云数据通过程序转换为激光雷达数据,为后文的SLAM 算法提供数据来源。图11所示为融合后的激光雷达数据,可以看出融合后的数据保留了深度相机点云的障碍物特征。

图11 融合后的激光雷达数据
3 GMapping算法研究
3.1 算法概述
GMapping 是一种基于Rao-Blackwellised 粒子滤波器(RBPF)的SLAM 算法,GMapping 在RBPF 的框架改进了提议分布,使用里程计与激光雷达数据作为提议分布。其次GMapping算法改进了重采样策略,使用自适应重采样来缓解粒子匮乏问题。因此本文第二章提出的传感器数据融合方法生成的激光扫描数据能够直接输入GMapping算法用于地图构建。
3.2 提议分布优化
传统RBPF框架中,通常使用移动机器人里程计数据作为控制量计算提议分布。此时粒子的权重由式(10)计算:
3.3 重采样策略
传统RBPF 滤波器中采用的重采样策略为:在重采样过程中使用权重大的粒子替代权重小的粒子,这种做法容易丢弃一些性质较好的低权重粒子,造成粒子匮乏使得最后的样本近似的分布与目标分布相差甚远。GMapping 采用自适应重采样的策略,该策略使用式(12)计算指标Neff,通过设定的阈值来判断是否需要进行重采样操作。
式(12)中分母的意义在于衡量粒子样本权值的差异,其核心思想:如果一组样本是对目标分布的良好采样,那么根据重要性权值的定义,各个样本的权重应当基本一致。所以权重的差异越大,意味着样本的分布与目标分布之间存在着较大的差异,需要进行重采样来修正。理论上样本的分布越靠近目标分布则各个粒子之间的权重应该越接近。
4 仿真实验验证和结果分析
4.1 仿真实验设计
为验证本文所提出的传感器数据融合方法的有效性与可行性,利用Gazebo仿真软件搭建3.5 m×3.5 m大小的实验环境,在实验环境中导入了2个边长为10 cm的正立方体,3 个边长7.5 cm 的正立方体,以及2 个边长为2.5 cm 的正立方体,仿真环境如图12(a)所示。实验环境中导入开源机器人模型turtlebot3 模拟真实移动机器人,turtlebot3 最高处为15 cm,其中激光雷达处在13 cm 处,深度相机处在11 cm 处。图13 所示为机器人仿真模型与障碍物对比。为了体现传感器数据融合对建图效果的影响,组别1仅使用激光雷达进行建图;组别2仅使用深度相机建图;组别3 使用深度相机与激光雷达数据融合进行建图。3 组实验皆为使用手动建图模式,其行驶路径节点顺序为1-2-3-4-1-5,并且在每个节点处移动机器人都顺时针旋转360°,目的是为了让传感器更好地感知周围的环境,行驶路径如图12(b)所示。

图12 仿真环境及行驶路径

图13 机器人仿真模型与障碍物对比
4.2 实验结果分析
实验按照所使用的传感器类型分为仅使用激光雷达、仅使用深度相机以及使用深度相机与激光雷达融合3 种方案,3种方案生成的传感器数据如图14所示。

图14 3种方案传感器数据
图14(a)所示为仅使用深度相机模拟激光雷达时发布的伪激光雷达扫描点,由图可知利用深度相机能够感知三维空间中的物体信息的特点,机器人感知到前方的5个障碍物,但是受限于相机视场角FOV 的限制,并不能得到360°方位的障碍物信息,因此仅使用深度相机模拟激光雷达数据是不完备的。图14(b)所示为仅使用激光雷达传感器时发布的激光扫描点,由图可知激光雷达很好地感知了周围墙体的信息,但是由于激光雷达扫描平面高于障碍物所在平面,因此仅使用激光雷达数据也是不完备的。如图14(c)所示为两种传感器融合后发布的激光扫描点数据,可以看出融合后的数据将深度相机与激光雷达的优点有效结合,因此本文提出的传感器融合策略是有效的。
通过将上述传感器数据输入GMapping算法分别构建地图,最终建图结果如图15所示。
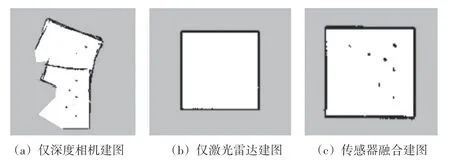
图15 建图结果对比
从仅使用深度相机建图结果图15(a)来看,仅使用深度相机构建的地图边缘轮廓粗糙,这是由于在深度相机点云模拟激光雷达扫描的时候传感器噪声带来的影响,虽然地图轮廓粗糙,但是使用深度相机仍然观测到了环境中的7 个障碍物。其次地图发生了较大的位移,这是由于深度相机的FOV过小,引起GMapping算法中扫描匹配模块失败,具体原因:当前时刻机器人通过转换深度相机点云至伪激光雷达数据,但是由于相机的FOV限制,该伪激光雷达数据过短,从而无法使用扫描匹配中的迭代最近点算法(ICP)估算出移动机器人此时的位姿增量,因为ICP 算法是通过迭代的方式求解最优位姿变换,所以采集到点越多意味着可迭代次数越多,求解出的位姿增量精度更高,同理数据越少ICP 效果越差。从图15(b)来看,由于单线激光雷达的扫描平面高于障碍物平面,因此在仅使用激光雷达建图时,地图中并没有构建出7个障碍物的位置。从图15(c)来看使用传感器融合的方法构建出的地图成功显示了7 个障碍物的位置,地图轮廓清晰但地图边缘略微有点加粗,这是由于两种传感器数据中的噪声所引起的。
为了定量分析本文所提出的方法,分别对上述3 种类别传感器进行多次建图实验,通过计算建图时间和障碍物检测率体现所提出方法的优点。
(1)建图时间。对3种类型的传感器分别进行5次实验,记录每次实验的建图耗时,通过观察实时建图结果,当机器人所构建的地图面积不再有明显增加时停止建图,通过计算每组实验平均用时衡量3种建图方法的效率。
实验结果如表1所示。由表中数据可知,3种建图实验平均用时如下:深度相机建图实验平均用时为40.31 s,激光雷达建图平均用时为16.91 s,传感器融合建图平均用时为30.72 s。3 种类别的使用中激光雷达建图用时最短,因为激光雷达返回的每一帧数据占用内存小,输入建图算法后处理过程快,所以得到最短的建图用时。使用深度相机建图,需要先将点云转换为激光雷达,这一过程需要将深度相机发布的大量点云数据进行提取并转换成对应格式,因此深度相机用时最长。使用传感器融合进行建图平均用时比深度相机建图平均用时减少31.22%,这是因为程序将深度相机发布的点云数据进行滤波和剪裁处理,使得融合时所用的数据量减小;又因为融合过程需要将点云格式进行转换,因此平均用时会比激光雷达建图增多44.95%。

表1 建图时间数据s
(2)障碍物检测率:本文使用障碍物检测率来衡量建图效果,统计由传感器构建的二维栅格地图中障碍物的总边长S1,真实环境中的障碍物总边长S2,通过式(13)计算障碍物检测率:
式(13)的原理简单表述:SLAM 构建的占用栅格地图都保存为.pgm 格式的灰度图,这种格式的图片每一个像素都保存为灰度值。已知所有的障碍物灰度值都是黑色也就是255,因此只要统计图像中所有黑色像素的个数,乘以每个像素的分辨率(算法规定的每一个像素栅格代表现实中多少米,本文使用的分辨率为0.05 m/栅格),即可得到障碍物总边长,再通过与真实环境中计算的总障碍物边长求比值,即可得到障碍物检测率。
每次实验的计算结果如表2 所示。由表2 数据可知,使用传感器数据融合方法得到最好的障碍物检测率为98.66%,比使用激光雷达的建图方法提高了13.24%,比使用深度相机建图方法提高了8.21%。
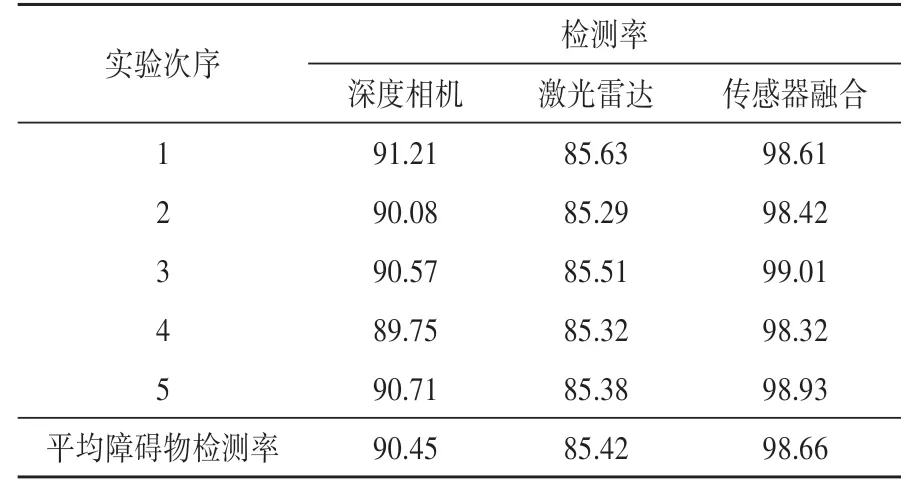
表2 障碍物检测率数据%
综上所述本文提出的传感器融合方法具有一定的可行性与有效性。
5 结束语
本文提出了一种多传感器数据融合的方法,该方法首先将深度相机点云数据进行滤波降采样处理,然后去除点云中的无关部分,再将深度相机点云转换成伪激光雷达数据,最后融合伪激光雷达与激光雷达数据,将融合后的激光雷达数据发布,利用GMapping算法构建二维占用栅格地图。通过实验对比分析建图效果,实验结果表明,本文所提出的传感器融合建图方法在建图时间上比使用深度相机平均建图用时减少31.22%。本文方法在障碍物检测率方面比激光雷达建图提高13.24%,比深度相机建图提高8.21%。但本文所提出的方法也存在不足,一是由于深度相机发布的点云数据在转换成伪激光雷达数据时计算量较大,影响融合程序性能。二是由于两种传感器的数据发布频率不同,导致建图时间增加。下一步的工作将会利用多线程方法改进融合程序,减少数据处理时间。
猜你喜欢
北京测绘(2022年5期)2022-11-22 06:57:43
北京航空航天大学学报(2022年6期)2022-07-02 01:59:12
汽车工程师(2021年12期)2022-01-17 02:29:56
汽车观察(2021年8期)2021-09-01 10:12:41
电子制作(2019年10期)2019-06-17 11:45:06
中国交通信息化(2019年1期)2019-03-26 06:43:46
成都信息工程大学学报(2018年4期)2019-01-23 06:57:18
电子制作(2018年16期)2018-09-26 03:27:00
制造技术与机床(2017年3期)2017-06-23 08:11:21
自动化学报(2017年4期)2017-06-15 20:28:55
