
Extraction and analysis of risk factors from Chinese chemical accident reports
2023-12-12 00:03XiLuoXiayuanFengXuJiYaguDangLiZhouKexinBiYiyangDai
Xi Luo,Xiayuan Feng,Xu Ji,Yagu Dang,Li Zhou,Kexin Bi,Yiyang Dai
School of Chemical Engineering, Sichuan University, Chengdu 610065, China
Keywords:Chemical processes Chemical process safety Natural language process Knowledge graph Neural networks Algorithm
ABSTRACT Accidents in chemical production usually result in fatal injury,economic loss and negative social impact.Chemical accident reports which record past accident information,contain a large amount of expert knowledge.However,manually finding out the key factors causing accidents needs reading and analyzing of numerous accident reports,which is time-consuming and labor intensive.Herein,in this paper,a semiautomatic method based on natural language process (NLP) technology is developed to construct a knowledge graph of chemical accidents.Firstly,we build a named entity recognition (NER) model using SoftLexicon (simplify the usage of lexicon)+BERT-Transformer-CRF (conditional random field) to automatically extract the accident information and risk factors.The risk factors leading to accident in chemical accident reports are divided into five categories: human,machine,material,management,and environment.Through analysis of the extraction results of different chemical industries and different accident types,corresponding accident prevention suggestions are given.Secondly,based on the definition of classes and hierarchies of information in chemical accident reports,the seven-step method developed at Stanford University is used to construct the ontology-based chemical accident knowledge description model.Finally,the ontology knowledge description model is imported into the graph database Neo4j,and the knowledge graph is constructed to realize the structured storage of chemical accident knowledge.In the case of information extraction from 290 Chinese chemical accident reports,SoftLexicon+BERT-Transformer-CRF shows the best extraction performance among nine experimental models.Demonstrating that the method developed in the current work can be a promising tool in obtaining the factors causing accidents,which contributes to intelligent accident analysis and auxiliary accident prevention.
1.Introduction
In order to ensure chemical safety,a great number of current research is devoted to the use of digital data,such as physical signals,for pattern recognition or fault diagnosis.Mirzaeiet al.[1]examined the fault diagnosis performance and classification mechanism of basic LSTMs and GRUs,providing comparative information for appropriate fault diagnosis models in chemical processes.Aiming at the high-dimensional nonlinear problem of chemical process data,Songet al.[2]proposed a chemical process fault diagnosis method based on multi-scale convolutional neural network(MsCNN) combined with matrix diagram.Wuet al.[3] proposed a fault diagnosis method based on the DCNN model for chemical process fault diagnosis,and the average fault diagnosis rate reached 88.2%.Ming and Zhao [4] proposed a fault antibody feature selection optimization (FAFSO) algorithm based on genetic algorithm to optimize the fault antibody features and the antibody libraries’ thresholds simultaneously.Gaoet al.[5] proposed a way to exploit the prior knowledge existing in refineries,and developed a decision-making system to guide the scheduling process.Tianet al.[6] used principal component analysis (PCA) weights and Johnson transformation to optimize the alarm threshold in the chemical processes.Liet al.[7] established a classification visualization method based on kernel principal component analysis(KPCA) and self-organizing map (SOM),in order to better monitor the process status and observe the performance trend of the process.Penget al.[8] developed an improved artificial bee colony(IABC) algorithm for steelmaking-refining-continuous casting(SCC) scheduling.Wanget al.[9] proposed a comprehensive pH value prediction model for bauxite froth flotation considering the effect of ore composition on pH value.Aiming at the twodimensional (2D) characteristics and the unknown optimal trajectory problem of the batch processes,Jiaet al.[10]proposed an integrated model predictive control-iterative learning control (MPCILC) for batch processing.Ge and Tan [11] proposed an adaptive rationalized Haar function approximation method to obtain the optimal injection strategy for alkali-surfactant-polymer (ASP)flooding.
However,digital data is only one manifestation of an unsafe state.The digital data can’t directly provide detailed accident information,nor can it directly explain the cause of the accident.Compared with numerical data,there is a large amount of text information in the chemical safety domain,such as chemical accident reports that recorded past accident information,which contain a large amount of accident information,accident risk factors,and expert knowledge.Therefore,there is increasingly more demand to mine useful information from these text data.
The current progress of text mining models benefit from the development of natural language process (NLP) technology,but most text mining models fous on the fields of law[12],biomedical[13],construction[14],and transportation[15].Chalkidiset al.[12]proposed a systematic investigation of the available strategies when applying BERT [16] in legal domain and achieved state-ofart results in three end-tasks.Leeet al.[13] investigated how recently introduced pre-trained language model BERT can be adapted for biomedical corpora and propose BioBERT(bidirectional encoder representations from transformers for biomedical text mining),which significantly outperformed them on the following three representative biomedical text mining tasks: biomedical named entity recognition,biomedical relation extraction and biomedical question answering.Xuet al.[14]proposed a text mining framework for safety risk factor extraction in construction accident reports based on domain lexicon,including domain-specific wordlist,synonyms wordlist,and stop word list.Antoineet al.[17] built a natural language processing system to extract precursors and results from unstructured injury reports,enabling automated content analysis for construction safety.Fenget al.[18]proposed an approach using BERT-BiLSTM (bi-directional long short-term memory)-Attention to learn the classification of consequence severity levels in high-quality HAZOP analysis reports.Liuet al.[19] identified the causal relationships and contributing factors of pipeline accidents by employing natural language processing and text mining techniques.Among them,K-means clustering and co-occurrence networks are used to infer potential causality of events.Zhanget al.[20] applied text mining and natural language processing [NLP] techniques to analyze construction accident reports.Specifically,a grammatical rule-based approach is employed to extract common objects that cause accidents.Fanget al.[21] developed an improved deep learning-based method to automatically classify near-miss information contained in security reports using a bidirectional transformer [22] for language understanding(BERT).Singleet al.[23]used natural language processing and ontology-based method to extract information from a chemical accident database.The results show that the ontology is useful for discovering causal accident relationships due to the semantically described context of accident information.
NLP tasks are numerous and complex,among which named entity recognition(NER)is a task used to identify meaningful entities in text.For example,in chemical industry,NER technology can identify entities such as equipment and risk factors.At present,NER has become a research hotspot in the medical field [13] and the field of railway [15] accident reports,but the application of NER technology in the chemical safety field is rarely heard.In the field of biomedicine,biomedical named entity (BioNE) identification is one of the key and fundamental tasks in biomedical text mining.Songet al.[24] comprehensively summarized deep learning-based BioNER (BioNE recognition) methods and datasets for training and testing.Liet al.[25] explored a two-phase approach to identify biomedical entities using CRFs [26],in which the recognition task was divided into two subtasks: named entity detection (NED) and named entity classification (NEC).Luoet al.[27] proposed an attention-based bidirectional long short-term memory with a conditional random field layer (Att-BiLSTM-CRF),for document-level chemical NER.In the field of railways,Huaet al.[15] proposed a method based on multi-channel convolutional neural network (M-CNN) and conditional random fields(CRF) model to extract cause and result events in Chinese railway accident reports.In the field of construction,Fenget al.[28] used a small samples training framework for deep Learning-based automatic information extraction and analyzed construction accident news reports.Based on deep learning,Wanget al.[29] proposed a framework to automatically extract and classify contributing factors from confined space accident reports using BERT-BiLSTM-CRF and CNN models.In the chemical field,Maoet al.[30] applied the BERT-CRF model to identify different entities in the HAZOP analysis report.
The technical route of named entity recognition has been continuously developing over time,from the early dictionary and rulebased methods,to the traditional machine learning methods,to the current deep learning-based methods.Among them,BiLSTMCRF [31] is currently the most mainstream model among the NER methods based on deep learning.Chinese NER problem depends largely on the effect of word segmentation,which is not the same as English NER.To solve this problem,a lattice model of LSTM for Chinese NER is proposed.Lattice-LSTM[32]improves the performance of Chinese NER using word lexicons,but its complex model architecture limits its application in industrial fields.Then,Maet al.[33]proposed the SoftLexicon method to integrate word dictionaries into character representations easily and efficiently.
Chemical accident reports are important text in the field of chemical safety.Through the analysis of previous chemical accident reports,we can have a deep understanding of various risk factors that lead to accidents (hereinafter referred to as effective information) to further assist accident prevention.
But up to now,a great number of accident reports have often been manually read by chemical safety experts to extract effective information,which is time-consuming and labor-intensive.Therefore,finding a method that can automatically extract effective information from chemical accident reports and store them in a structured manner is of great significance to the prevention of chemical safety accidents.
In the current work,based on natural language processing technology,a semi-automatic method is explored to construct a knowledge graph of chemical accidents to understand the characteristics of chemical accidents and assist in the prevention of chemical accidents.An NER model is established using SoftLexicon+BERT-Trans former-CRF to automatically extract effective information in chemical accident reports.Through the summary and analysis of the extracted information,preventive measures for different types of chemical plants and different types of accidents are proposed.Then an ontology-based chemical accident knowledge description model is built using the seven-step method.Finally,the ontology knowledge description model is imported into the graph database Neo4j to build a knowledge graph and realize the structured storage of chemical accident knowledge.
In this paper,Section 2 introduces the construction of the model and key technologies.On Section 3,the proposed method is applied to case study on chemical accident reports.On Section 4,the results of the case are analyzed,preventive measures for different types of chemical plants and different types of accidents are proposed,and more applications of chemical accident knowledge graph are described.In the end,the conclusions and future works are presented.
2.Approach
The structure of the semi-automatic method to construct a knowledge graph of chemical accidents is shown in Fig.1.Through the first three parts of the method,namely data acquisition,data labeling,and information extraction model construction,accident information and risk factors in chemical accident reports are extractedviathe SoftLexicon+BERT-Transformer-CRF model.The fourth part is to establish an ontology-based chemical accident knowledge description model,and finally import it into the graph database to establish a chemical accident knowledge graph.
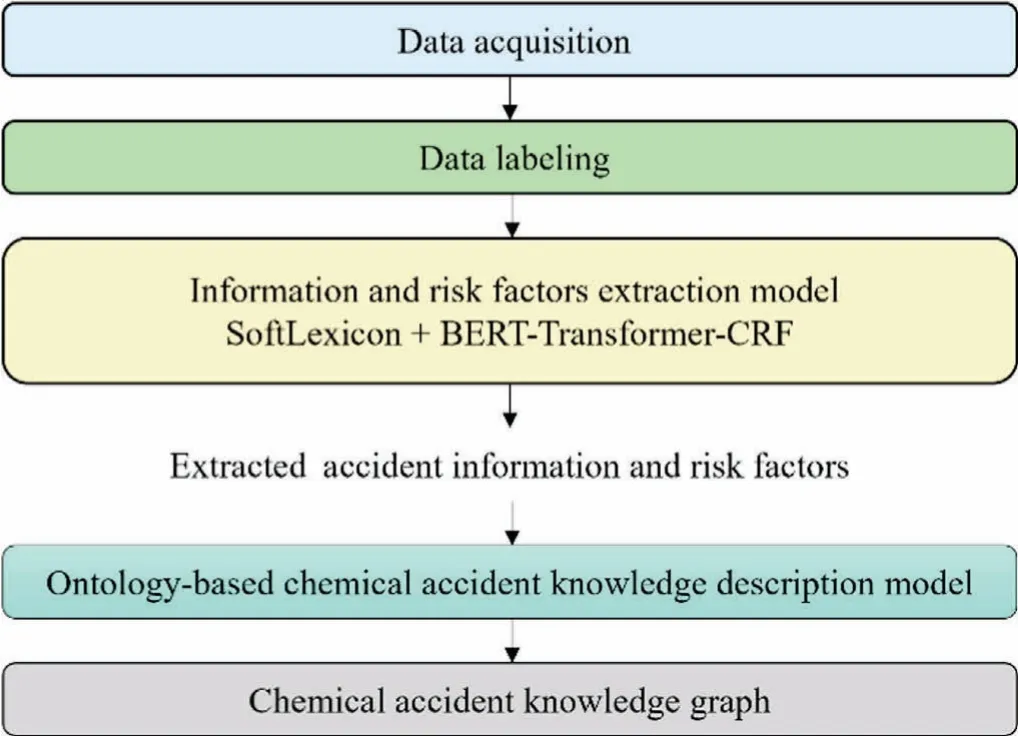
Fig.1.The structure of the proposed method.
2.1.Data acquisition
290 Chinese chemical accident reports are screened out from the official website of the Ministry of Emergency Management and Baidu Library.
2.2.Data labeling
The accident report texts are manually labeled with BMEO labels,and the valid information in it is divided into two categories: accident information and risk factors that cause the accident.The accident information includes the time,location,equipment,and factory status of the accident.Risk factors include personnel,machinery and equipment,materials,management,and the environment factors,as shown in Table 1.Taking the event time entity as an example,B represents the first word of the entity,E represents the last word of the entity,and M represents the middle word of the entity,shown in Table 2.All labels are shown in Table 3.
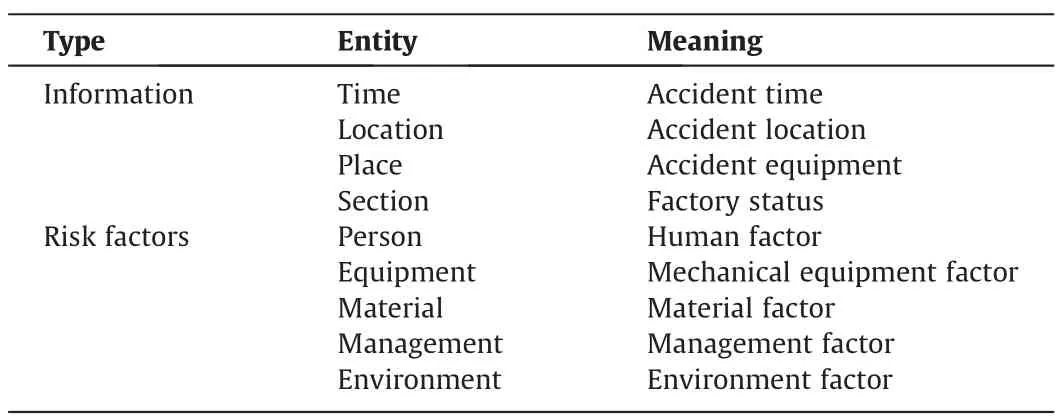
Table 1 Tagging entities
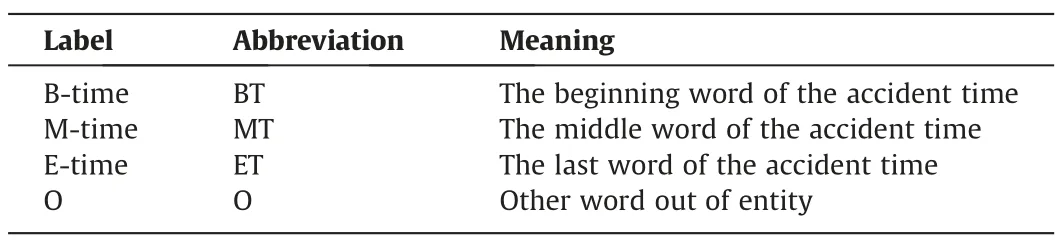
Table 2 Labels

Table 3 Labels &abbreviation
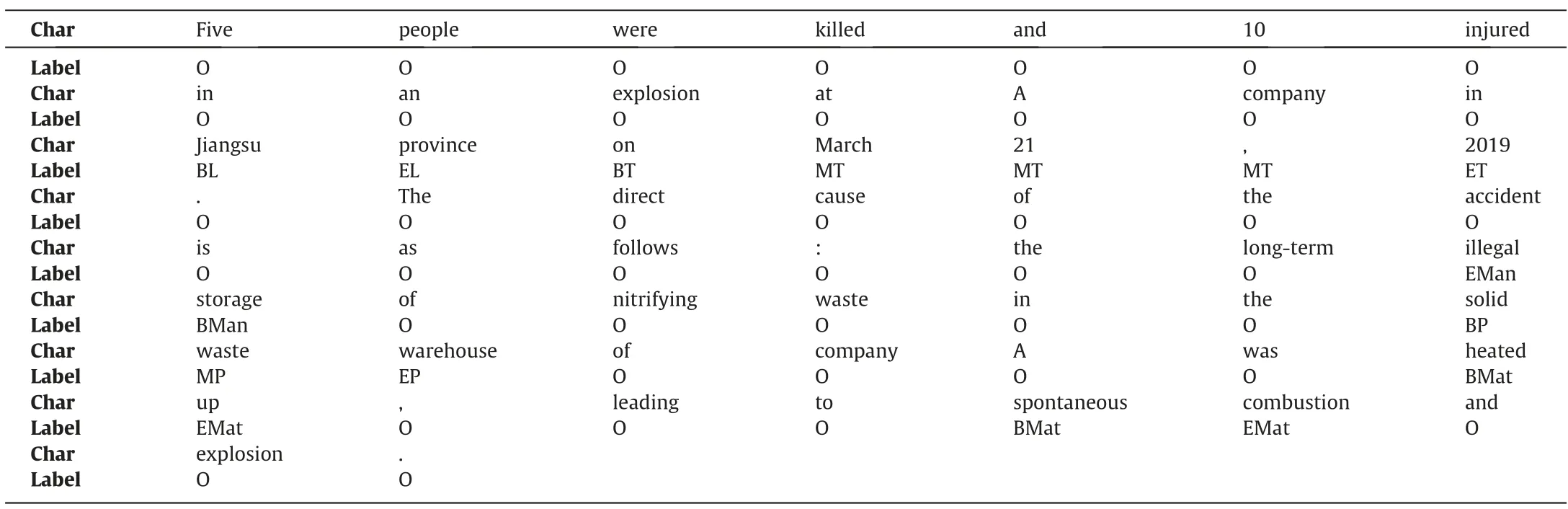
Table 4 Example of statement tag (example 1)
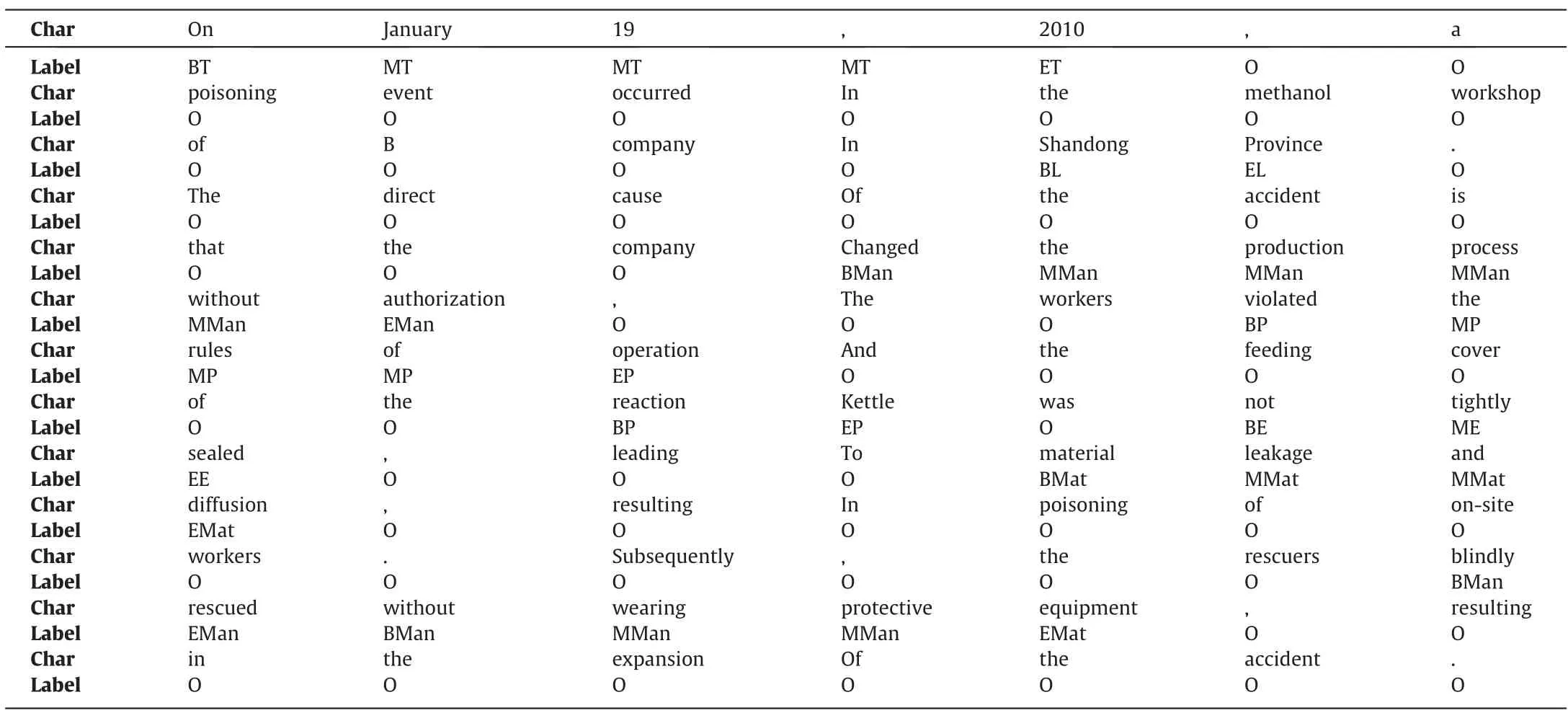
Table 5 Example of statement tag (example 2)
2.3.Information and risk factors extraction model
The widely used deep neural network models is employed in our study.The structure of information and risk factors extraction model in this article is shown in Fig.2.
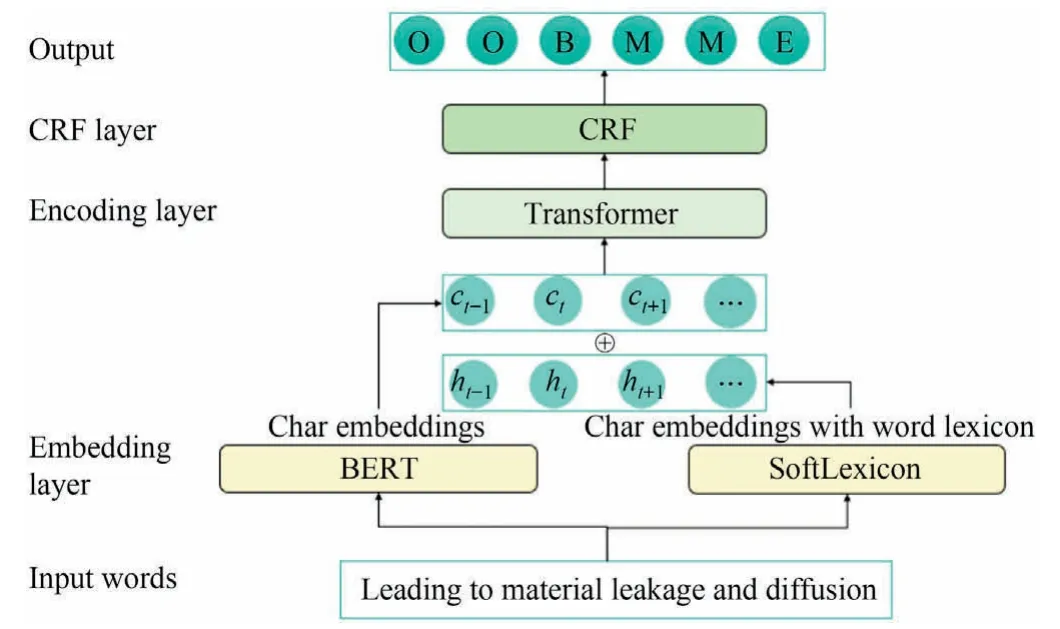
Fig.2.Structure of information and risk factors extraction model.
Firstly,the labeled chemical accident reports are input into the embedding layer.As shown in Fig.2,the input word sequence is‘leading to material leakage and diffusion’.In the embedding layer,each character of the sequences is converted into a vector by BERT and SoftLexicon,wherectrepresents character embeddings obtained by BERT,andhtrepresents character embeddings obtained through SoftLexicon that synthesizes the lexicon information.BERT,which stands for bidirectional encoder representation from transformers,is a pre-trained bidirectional language representation model.It encodes contexts bidirectionally,requires minimal architectural changes for most NLP tasks and generates deep bidirectional language representations by the new masked language model (MLM).The pre-trained wwm-BERT [34] released by Harbin Institute of Technology is used as the character embedding model,and we further pre-trained wwm-BERT on the chemical accident reports to obtain the embedding vector that has learned the characteristics of the chemical corpus.SoftLexicon integrates lexicon information.In order to retain word segmentation information,each character matched to all possible words is classified into four word sets:‘‘BMES”,representing that this character in matched word is the first word,the middle word,the ending word,and a single word.Then each word set is condensed into a vector of fixed dimensions.Finally,the embedding of the four sets is combined into a fixed dimension feature and added to each character representation.More details about BERT and SoftLexicon can be found in Refs.[16]and[33].Then complete embedding vector is obtained by concatenating character representations output by BERT and SoftLexicon.
Secondly,the obtained embedding vectors are fed into the encoding layer,where transformer is used to model the dependencies between characters.
The final layer is the label inference layer,where CRF is used to infer the label of each character in the sequence.The output corresponds to the defined accident information and risk factor labels.Words classified as {BT,MT,ET,BL,ML,EL,BP,MP,EP,BS,MS,ES} and {BPe,MPe,EPe,BE,ME,EE,BMat,MMat,EMat,BMan,MMan,EMan,BEn,MEn,EEn} represent accident information,and risk factors,respectively.As shown in Fig.2,the words ‘leading’ and ‘to’ are both classified as ‘O’,which stands for other word out of entity;word‘material’is classified as‘BM’,which stands for‘B-material’,the beginning word of the material risk factor,abbreviated as ‘B’ in Fig.2.Similarly,words ‘leakage’ and ‘and’ are both classified as ‘MM’,which stands for ‘M-material’,the middle word of the material risk factor,abbreviated as‘M’in Fig.2;word‘diffusion’ is classified as ‘EM’,which stands for ‘E-material’,the last word of the material risk factor,abbreviated as ‘E’ in Fig.2.Then,combining the words classified as ‘BM’,‘MM’,‘EM’ forms a complete material risk factor ‘material leakage and diffusion’.Therefore,by classifying each word in the text according to the above principles,extracting accident information and risk factors from chemical accident reports can be realized.
All the above steps for model training and evaluating are accomplished by a series of programs written in Python language and executed on Linux platforms.An open-source deep-learning framework Pytorch is used to implement the neural network,and the procedure is accelerated on two GTX-1080Ti GPUs.
2.4.Ontology-based knowledge description model
Ontology is a tool for integrating and modeling knowledge,and a conceptual model that describes terms and their relationships.There are five elements in the composition of the ontology:classes,relations,functions,axioms and instances.There are a variety of ontology construction methods,and several well-known methods include the seven-step method,the methodology method,the IDEF-5 method,the TOVE method,and the skeletal methodology.The seven-step method developed at Stanford University is used in this study to construct the chemical accident ontology,which is widely used in the construction of domain ontology.The seven steps are:
(1) Determine the professional field and scope of the ontology;
(2) Examine the possibility of reusing existing ontology;
(3) List important terms in the ontology;
(4) Define classes and class hierarchies;
(5) Define the properties of the class;
(6) Define constraints on attributes;
(7) Create instances.
In the current study,the seven-step method was modified and used to design the chemical accident ontology model.
First of all,determine the professional field and category of ontology.The ontology knowledge model constructed in this study is oriented to the chemical accident field,and is used to define and store the professional terms and common concepts in chemical accident reports to assist in the investigation of artificial chemical accidents.
What needs to be done next is to list the important terms in the ontology,define the classes,class hierarchies,and the properties of the class.Based on the division of entity categories in the chemical accident reports in Section 2.2,the chemical accident knowledge ontology structure is obtained,as shown in Fig.3.First define the two major classes of accident information and risk factors.Then,under the accident information class,subclasses time,location,place,and section are defined,and under the category of risk factors,subclasses person,machine,material,management,and environment are defined.The object property of the major class and the subclass under the major class is‘subclass_of’,and the object property between the subclasses is‘disjoint_with’.Taking‘section’as an example,the object property between‘section’and‘accident information’ is ‘subclass_of’,and the object property between ‘section’and ‘location’,‘time’,‘place’ is ‘disjoint_with’.
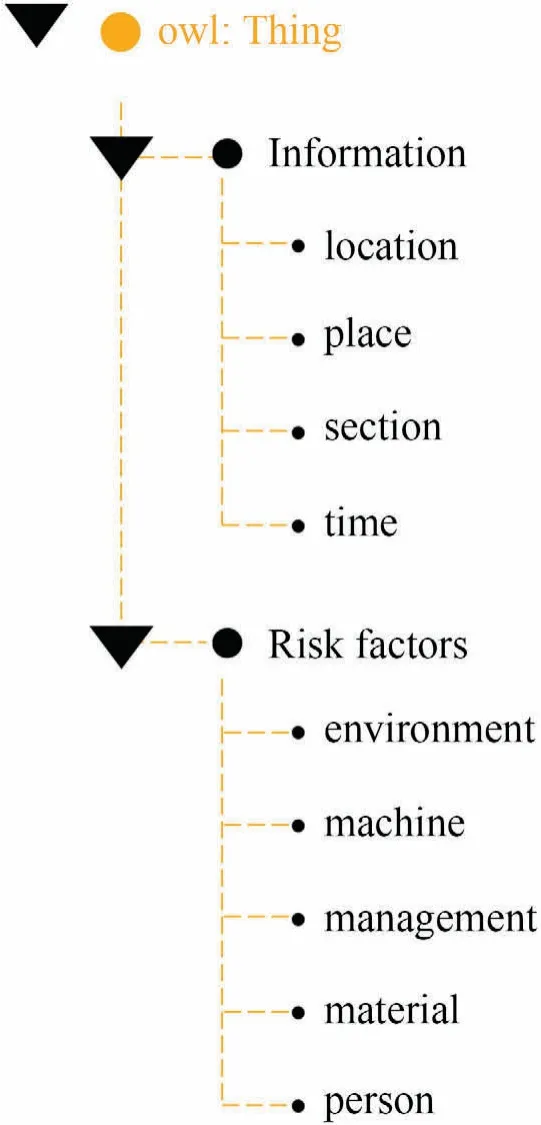
Fig.3.Class hierarchies of the ontology-based knowledge description model.
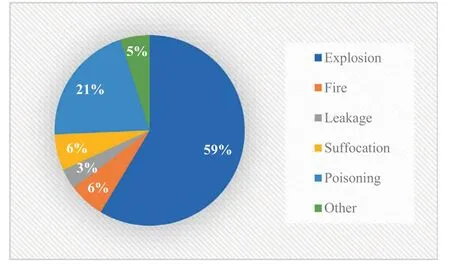
Fig.5.Proportion of accident types in chemical accident reports.
Finally,instantiation is the last step in the ontology construction process.Since it does not affect the structure of the ontology knowledge model,instances can be directly imported into the corresponding class.
As he stood on the gallows40 he said: Every one doomed41 to death has the right to speak once before he dies; and I too have that privilege? Yes, said the King, it shall be granted to you
Protégé is an ontology editing and knowledge acquisition software developed by the Bioinformatics Research Center of Stanford University School of Medicine based on the Java language.In Protégé,users can build an ontology-based model by defining class and the relationship between class,defining attributes,and filling instance into the class according to the knowledge structure of the specific application field.
2.5.Knowledge graph
Knowledge graph is a structured semantic knowledge base for describing concepts and their relationships in the physical world in symbolic form.Knowledge graphs can integrate unstructured chemical accident reports,clearly show the characteristics and even correlations of accidents,and store them structured in a high-performance,lightweight graph database.Based on this,the chemical accident profile and accident distribution can be displayed.
The basic unit of knowledge graph is the‘entity-relation-entity’triplet.Entities are connected to each other through relationships to form a networked knowledge structure.Based on the classes,subclasses,hierarchical relationships of classes,and instances in the ontology knowledge model,the ‘entity-relation-entity’ triplet can be formed to construct the knowledge graph.Since knowledge graph data contains entities,attributes,relationships,etc.,common relational databases cannot reflect these characteristics of data well,so knowledge graph data is generally stored using Graph Databases.Neo4j is the most common graph database among them,which is a high-performance NOSQL graph database that stores structured data on the network rather than in tables.In neo4j,the graph contains two basic data types:nodes and relationships.Nodes and relationships contain key/value properties.Nodes are connected by the relationships to form a relational network structure.
3.Case Study
In this section,the proposed method is applied to extract accident information and risk factors leading to accidents from chemical accident reports.Then an ontology-based chemical accident knowledge description model is established,and finally those data was imported into the graph database to establish a chemical accident knowledge graph.
3.1.Data sets
There are 290 Chinese chemical accident reports selected from the official website of the Ministry of Emergency Management of China and Baidu Library.Accident reports can be divided into seven types: chemical fertilizer industry,fine chemical industry,coal chemical industry,petrochemical industry,inorganic chemical industry,organic chemical industry and other industries.In addition,accident reports can be divided into six types:explosion,fire,leakage,suffocation,poisoning and other accidents.The distribution of accident reports data is shown in Figs.4 and 5.
Based on those reports,it is found that the fine chemical industry accounts for the highest proportion of accidents,reaching 30%,while explosions and poisoning account for the first(59%)and second (21%) accident types,respectively.
3.2.Data labeling
The collected 290 accident reports are manually annotated,and 2 of the annotated reports are shown in Tables 4 and 5 as examples.70% of the text is used as the training set,20% as the test set,and 10% as the validation set.
Statistics of the number of entities in the training set are made based on the definition of entities in Table 1 in Section 2.2,as shown in Table 6.The specific statistical method is,taking time entity as an example,to count the occurrences of the label ‘BT’,and the result is regarded as the statistical quantity of the time entity.
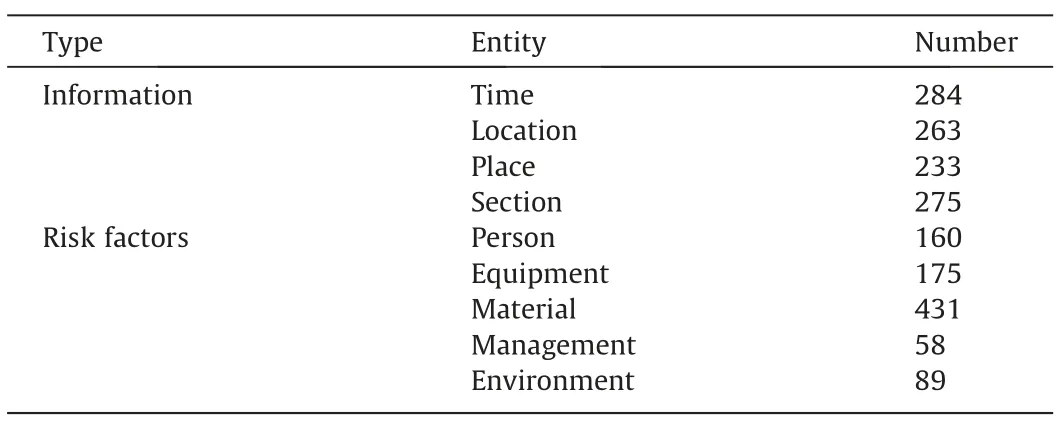
Table 6 Number of entities in the training set
3.3.Competitiveness of the information and risk factors extraction model
First,the marked nine types of entities are all directly used in the experiment,and the results are shown in Table 7.To demonstrate the rationality and reliability of the proposed method,two classic sequence models in NER are used for comparison: Bidirectional long-short term memory network (BiLSTM) [28],and the convolutional neural network (CNN) [15].We also compared the performance of each model with and without BERT or SoftLexicon method.The results are evaluated by F1 score of comprehensive accuracy and recall rate,as shown in Table 7.In natural language processing tasks,when there is no extreme data,the F1 score is generally used to evaluate the results.Since entities are bounded,in the process of named entity recognition,it is necessary to predict the entity category and the boundary range.Only when these two parts are successfully matched can the prediction be correct,otherwise the prediction is wrong.
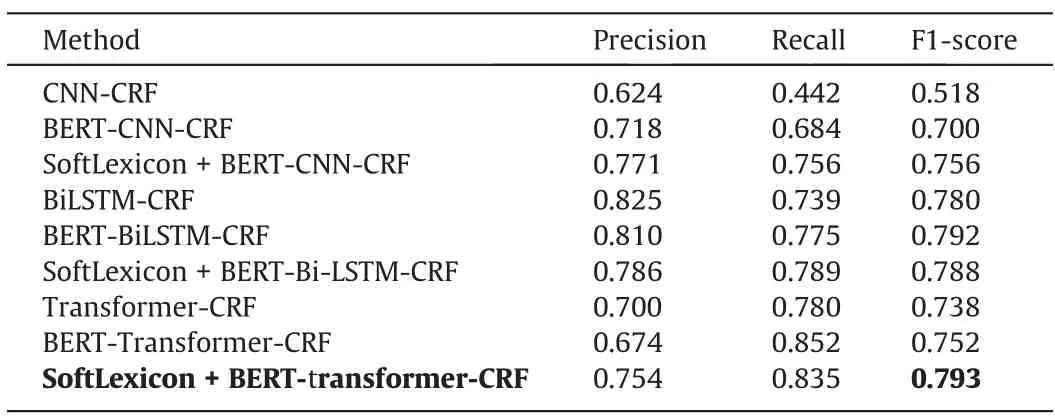
Table 7 Full label experiment result

Table 8 Corpora partitioning methods

Table 9 Result of accident information &risk factor partition experiment
As shown in Tables 7 and 9,the proposed method achieves the best results no matter if the data is partitioned or not.When the annotated corpus is divided according to accident information and risk factors,the best extraction results are achieved by SoftLexicon+BERT-Transformer-CRF and SoftLexicon+BERT-BiLS TM-CRF,with an average F1 score of 0.806.So considering the results of full label experiment and accident information&risk factor partition experiment,SoftLexicon+BERT-Transformer-CRF model is used to extract risk factors and accident information in the accident report.Then the trained model is used to extract risk factors and accident information separately in 87 chemical accident reports (test set &valid set).Then the results extracted by the model are analyzed,and the analysis content is shown in the next section.
3.4.Ontology-based chemical accident knowledge description model
The information and risk factors in the chemical accident reports have been identifiedviathe model.Next,with the help of ontology method,through the definition of class,attribute and instance of the extracted knowledge,the ontology-based chemical accident knowledge description model is constructed by using the ontology development software Protégé.Fig.6 shows part of the obtained model.Two main classes of ‘accident information’ and‘risk factors’ are defined according to entity categories.The ‘accident information’class includes subclasses of time,location,place,and section,and the ‘risk factors’ class includes subclasses of person,equipment,material,management,and environment.There are corresponding instances under each subclass.For example,the ‘machine’ subclass contains instances of machine risk factors such as water leakage and overpressure.
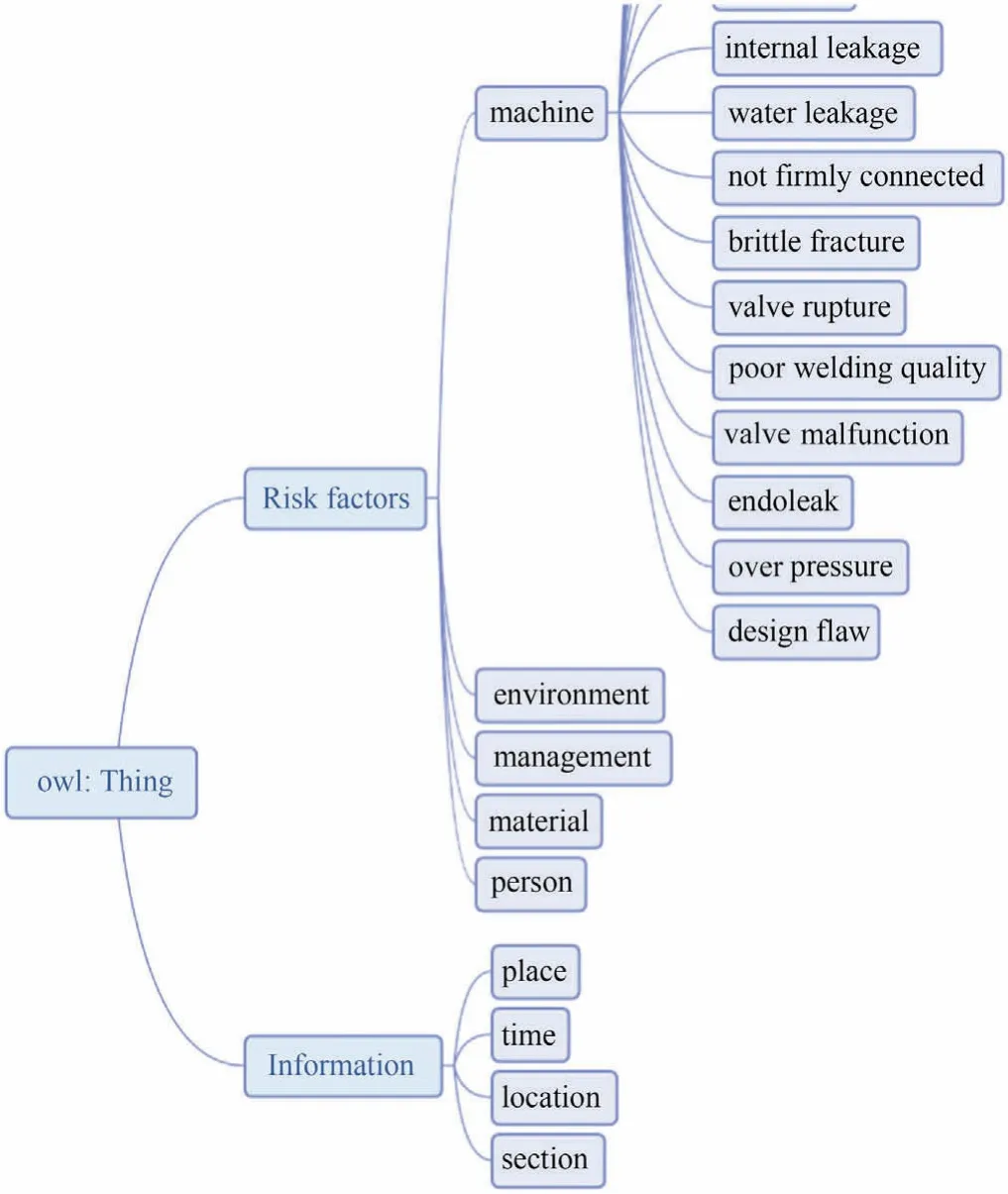
Fig.6.Ontology-based chemical accident knowledge description model.
3.5.Chemical accident knowledge graph
Finally,the ontology-based chemical accident knowledge description model needs to be imported into the graph database neo4j,which enables structured storage and visualization of the obtained chemical accident knowledge.
In the neo4j command line,cypher statements are used to load the ontology-based chemical accident knowledge description model and build a chemical accident knowledge graph,as shown in Fig.7.The constructed chemical accident knowledge graph can display accident portraits and accident distribution,from which we can comprehensively understand the accident overview and the factors that lead to the accident.
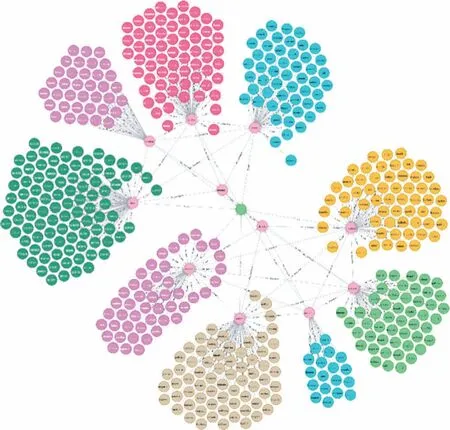
Fig.7.Chemical accident knowledge graph.
Each node in the graph represents an entity,including a class,subclass and instance,and the specific name of the entity is displayed on the node.The line between the nodes in the graph indicates that there is a relationship between the nodes,and the specific relationship type is marked on the line.The whole graph is derived from the green node in the center,which is the ‘thing’ontology in the ontology model.The ‘thing’ ontology derives two major classes of accident information and risk factors,and the connection between the ‘thing’ ontology and the two major classes is marked with‘type’.The two major classes are connected to several subclasses.The line between the major class and the subclass ismarked with ‘subclass_of’,and the line between the subclasses is marked with ‘disjoint_with’.The subclass is also connected to many instances,and the line between the instance and the subclass is marked with ‘type’.
4.Results and Discussion
In order to gain insight into the various risk factors leading to accidents,we perform a statistical analysis of the extraction results.We calculate the frequency of accident risk factors from different chemical industry type and different accident type,respectively.Then,the chemical accident prevention suggestions are given for different chemical industries and different accident types.
4.1.Accident information analysis based on different chemical industries
The accident information includes the accident time,location,equipment,and accident status.As shown in Fig.8,the frequency statistical results are composed of two parts.The heat chart in the middle is the frequency statistics of accident information for seven industries,while the bar chart on the right side is the frequency statistics for different accident time(month),location,accident equipment and accident status.
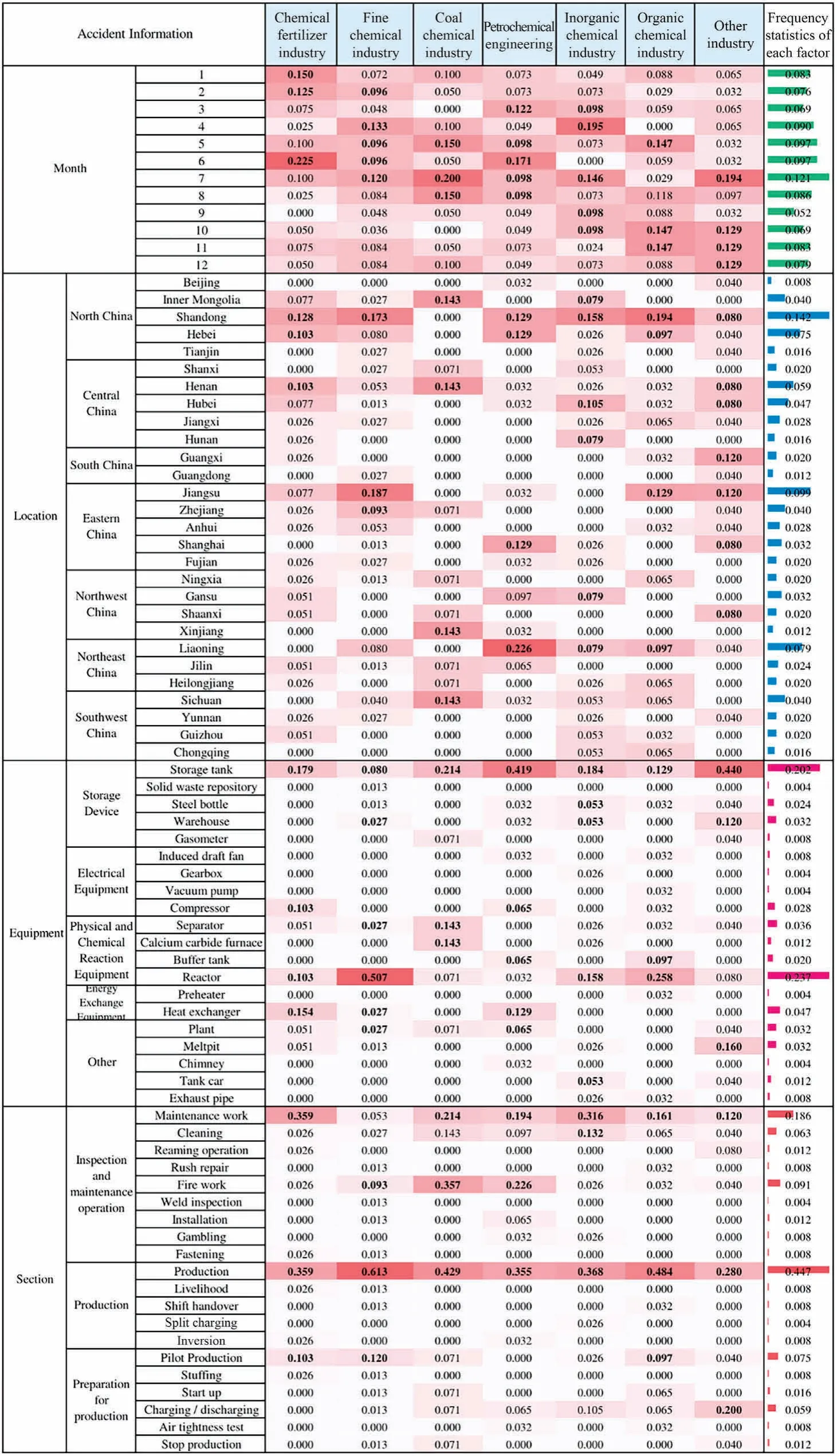
Fig.8.Frequency statistics of accident information based on different chemical industries.
As shown in Fig.8,from April to July is a period of high occurrence of chemical accidents.Furthermore,Shandong,Jiangsu and Liaoning are accident prone areas.In addition to normal production,chemical plants are also prone to safety accidents during inspection and maintenance,fire operation,cleaning operation and trial production.Specifically,for the accident equipment,the reactor of fine chemical industry and the storage tank of petrochemical industry are equipment with high accident incidence.Coal chemical industry and petrochemical industry are more likely to have accidents in the fire operation,while inorganic chemical industry is more likely to have accidents in the cleaning operation.
4.2.Risk factors analysis based on different chemical industries
The risk factors leading to accident are analyzed from the perspectives of personnel,equipment,materials,management and environment.As shown in Fig.9,the frequency statistical results are composed of two parts.The heat chart in the middle is the frequency statistics of risk factors on seven industries,while the bar chart on the right is the frequency statistics for different factors.The most frequent risk factors in the heat map are represented in deep red,while the least frequent risk factors are represented in white.For each chemical industry type,the five most frequent risk factors are represented in bold as shown below.
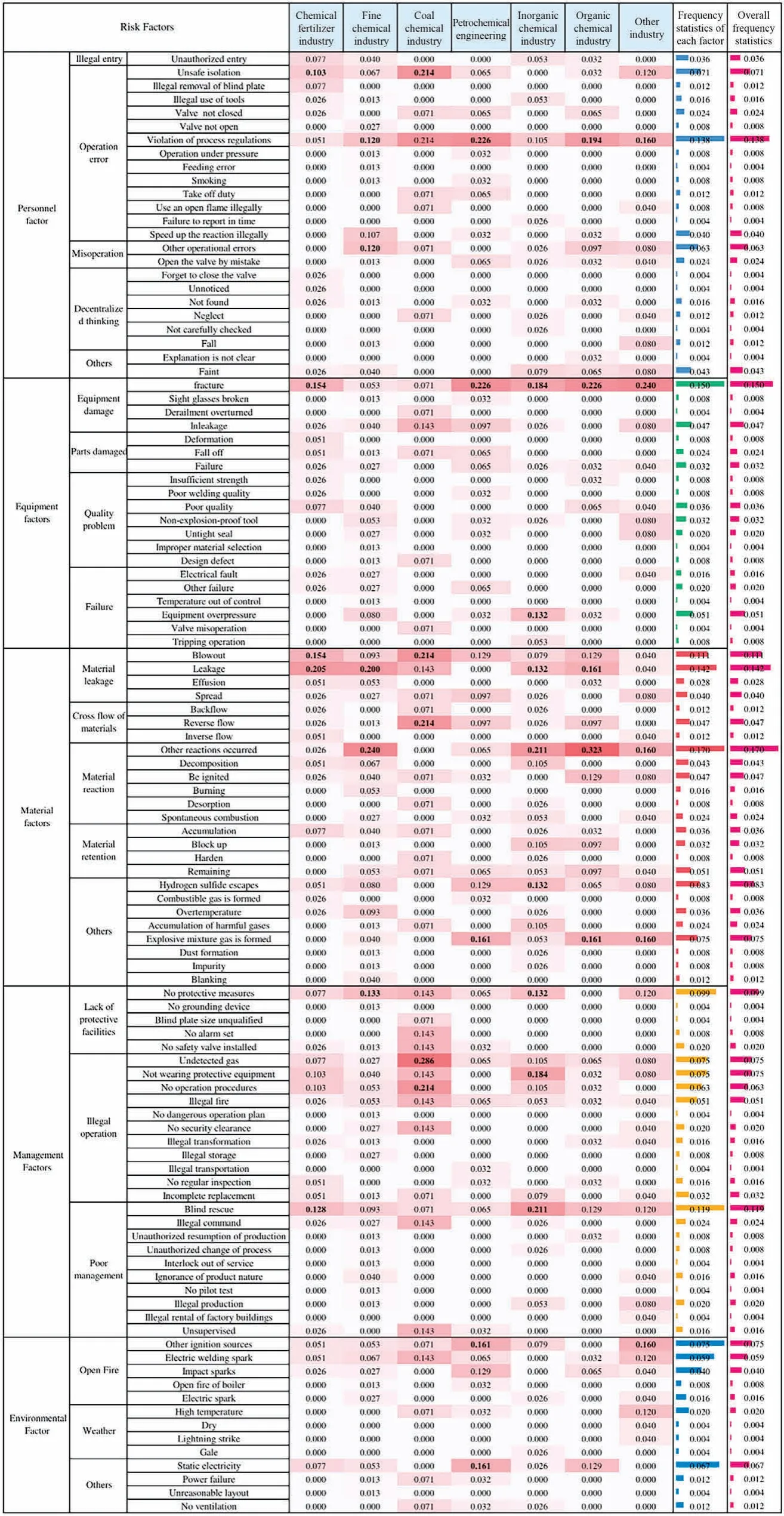
Fig.9.Frequency statistics of risk factors based on different chemical industries.
Personnel factors:Personnel factors include the risk factors caused by the improper behavior of personnel operating in chemical plants.According to the extraction results,personnel factors include illegal entry,operation error,and decentralize thinking.
Equipment factors:Equipment factors include the risk factors caused by malfunction or damage of equipment and its components,valves,etc.According to the extraction results,the equipment damage,parts damage,quality problems and other equipment failures are the representative equipment factors.
Material factors:Material factors include the risk factors caused by physical or chemical changes of the material itself.According to the extraction results,material factors are mainly divided into material leakage,cross flow,retention,and occurrence of other reactions.
Management factors:Management factors include the dangerous factors caused by the wrong command of chemical plant management,illegal production,and illegal maintenance.According to the extraction results,management factors are mainly divided into the lack of protective facilities,illegal operations,and inadequate management.
Environmental factors:Environmental factors include the risk factors caused by natural operating environment.According to the extraction results,environmental factors include open fire,weather,power failure,static electricity,unreasonable layout and so on.
Take coal chemical industry and petrochemical industry as examples.Coal chemical industry refers to the process of using coal as raw material to convert coal into gas,liquid,solid fuels,and other chemicals through chemical processing.For coal chemical industry,the five most frequent risk factors are no gas detected,no operation procedures,material blowout,reverse flow,and unsafe isolation.Therefore,it is an important prerequisite to ensure safe production to detect the gas composition and handle the operation procedures according to the provisions before the maintenance operation,while effectively isolating the working space.At the same time,it is also necessary to check and maintain the equipment regularly to avoid material ejection or reverse flow caused by equipment or equipment parts damage.
Petrochemical industry generally refers to the chemical industry that uses petroleum and natural gas as raw materials.For petrochemical industry,the four most frequent risk factors are: equipment damage,workers’ violation of process operation rules,formation of explosive gas mixture,and static electricity.Therefore,for petrochemical enterprises,it is necessary to check the safety status of equipment regularly,train the operators on process operation rules,make emergency preplan and preventive measures for the production environment that may form explosive gas mixture,and strengthen the management of static electricity and fire operation.
Take the overall bar chart of Fig.9 on the far right for example.It can be seen that,in all the five categories of risk factors,the five high-frequency factors that lead to accidents are: other reactions of materials(materials),equipment fracture(equipment),material leakage (materials),violation of process operation rules (personnel),and blind rescue (management).Therefore,chemical plants should be familiar with the physical and chemical properties of process materials,and have corresponding emergency plans for other reactions that may occur.At the same time,they also need to repair the equipment regularly to ensure the normal operation of the equipment,conduct regular process training for operators,formulate rescue plans for various accidents,and conduct regular security drills,to reduce the occurrence of accidents.
4.3.Accident information analysis based on different accident types
The composition of accident information is the same as that in Section 4.1.The structure of Fig.10 is the same as that in Fig.8,which consists of heat map and histogram.Both analyses are based on the same group of chemical accident reports,so the bar chart of Figs.8 and 10 are the same.Therefore,only heat map is discussed in this section.
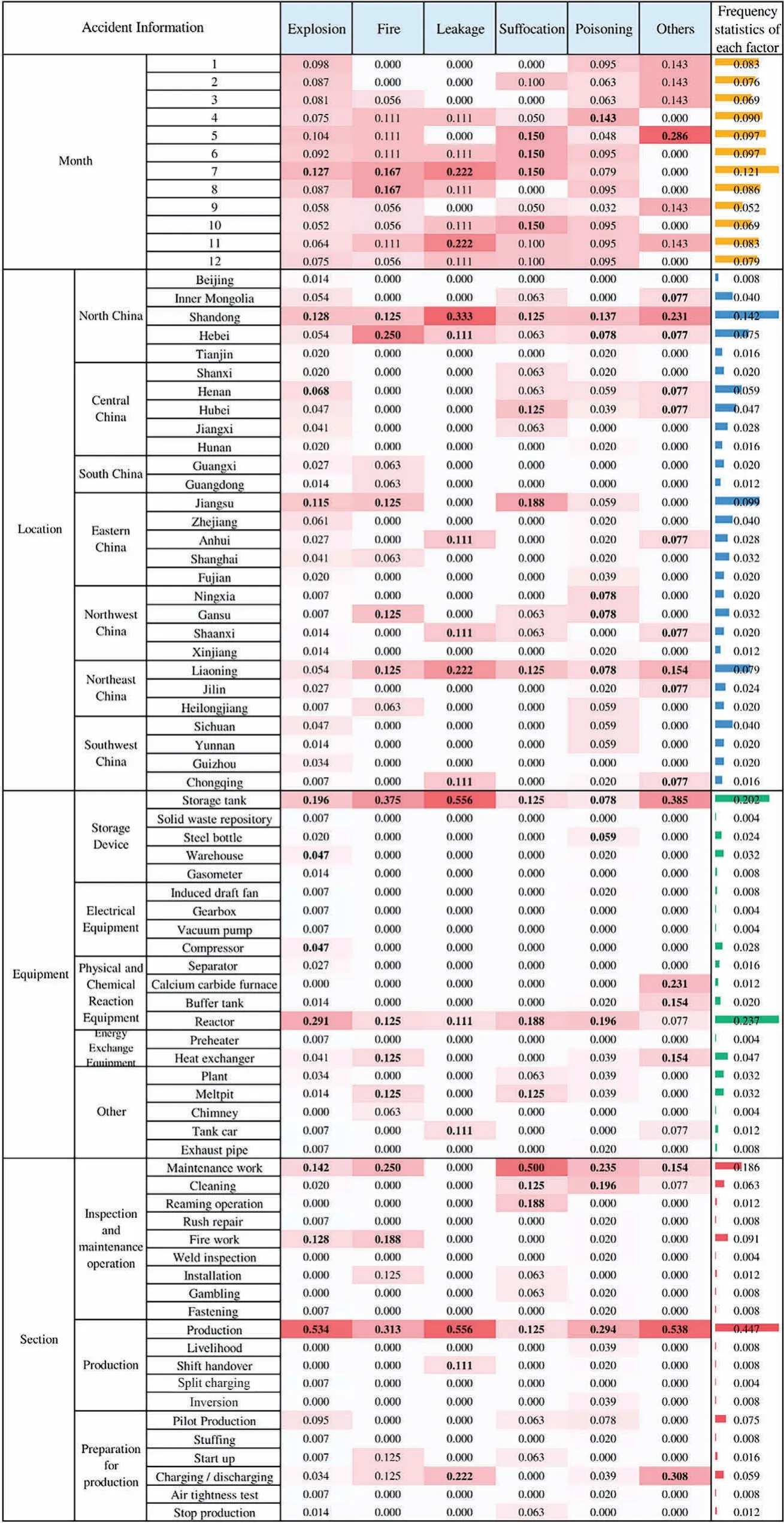
Fig.10.Frequency statistics of accident Information based on different accident types.
Take explosion,fire and poisoning accidents as examples.Most of the explosion accidents occurred from June to August in Shandong,Henan and Jiangsu.Most of the accident equipment are tanks and reactors.The factory status at the time of the accident is in production,maintenance,and hot work.Most of the fire accidents occurred from July to August in Hebei,Shandong and Jiangsu.Most of the accident equipment are in storage tanks,reactors,heat exchangers,pits and ditches.At the time of the accident,the factory status is most likely in production,maintenance,and hot work.For poisoning accidents,the most frequent period is April,and the most frequent places are Shandong,Ningxia,and Gansu.The accident equipment are mostly reactors,cylinders,and storage tanks.At the time of the accident,the factory is mostly in the process of maintenance,cleaning,and normal production.
4.4.Risk factors analysis based on different accident types
As shown in Fig.11,the most frequent risk factors in the heat map are represented in deep red,while the least frequent risk factors are represented in white.For each chemical industry type,the five most frequent risk factors are represented in bold,which have been introduced in Section 4.2.
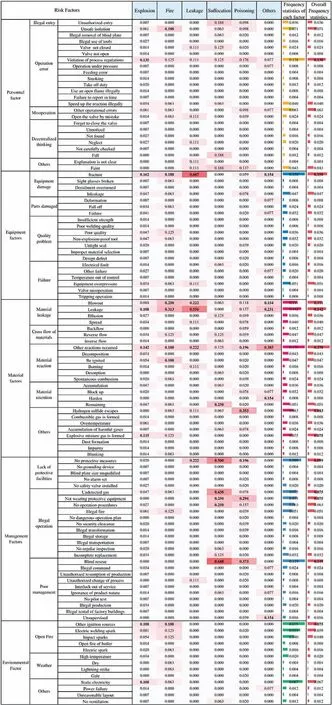
Fig.11.Frequency statistics of risk factors based on different accident types.
Take explosion and poisoning accidents as examples,for explosion accidents,the risk factors with high frequency are equipment fracture,other reactions of materials,violation of process operation regulations by operators,formation of explosive gas mixture,appearance of other ignition sources and static electricity.Therefore,chemical enterprises should carry out regular maintenance of equipment,regular training of process operation procedures for personnel,detection of gas concentration in the environment that may form explosive gas mixture,and strengthen the management of hot work and static electricity to prevent explosion accidents.For poisoning accidents,risk factors with high frequency are blind rescue,hydrogen sulfide gas escape,not wearing protective equipment,no protective facilities and other reactions of materials.Therefore,chemical enterprises need to make plans for the rescue process,monitor the surrounding gas composition of places that may produce hydrogen sulfide gas,equipping with protective facilities in advance,while wearing protective equipment when entering specific places.
4.5.More applications of chemical accident knowledge graph
In addition to the structured storage of accident data,the chemical accident knowledge graph can also be used for in-depth assistance for accident prevention and intelligent decision-making.
Based on the currently constructed chemical accident knowledge graph,an accident semantic search system can be established: users input the accident search conditions,and then the system automatically parses the semantics,queries the corresponding entities and relationships from the graph,and outputs accident information.In this way,historical cases can be easily and quickly consulted,which helps to draw lessons from experience and prevent accidents from happening again.
The chemical accident knowledge graph constructed so far already has ontology structure and entity elements,which lays a foundation for the subsequent analysis of the relationship between risk factors.In this study,the named entity recognition technology has been used to automatically extract the risk factor entities in the accident report,and relationship extraction technology can be used in follow-up work to automatically extract the relationship between the risk factors.By combining the extracted entities and relationships into triples,a more complete knowledge graph of chemical accidents can be constructed.Based on the improved knowledge graph of chemical accidents,it is possible to figure out how the various risk factors in the accident development process act successively and work together to finally lead to the accident.Further combined with knowledge reasoning,it can also be applied to the analysis and prediction of accident development paths,so that accident early warning can be carried out in time before a new accident occurs,and emergency decision-making can be provided to achieve accident prevention.
5.Conclusion and Future Works
This study introduces a semi-automatic method to construct a knowledge graph of chemical accidents with the NER model trained on chemical accident reports to extract general information and risk factors leading to the accident.In our information extraction model,for the embedding layer,the Chinese language model wwm-BERT and the SoftLexicon method are used to gain the character embedding,transformer is used as encoding layer and CRF is used as label inference layer.Compared with the other eight models,our model achieves the best results.Statistical analysis is carried out on the extraction results,and suggestions for chemical accident prevention are given for different chemical industries and accidents.The ontology-based chemical accident knowledge description model is further constructed and imported into graph database to construct the knowledge graph,which realizes the structured storage of chemical accident knowledge.
The results show that the proposed framework can automatically obtain accident risk factors from huge amount of unstructured chemical accident reports,and store them in a structured graph database,which is of great benefit to in-depth understanding of the characteristics of chemical accidents,assisting accident prevention,and maintaining chemical safety.In particular,the ontology-based chemical accident knowledge description model is equivalent to an encyclopedia in the field of chemical accidents,which brings the reusability,timeliness and extensibility of knowledge to a whole new level.The role of the ontology knowledge model is not only the ontology model itself,it is like a powerful domain knowledge database,which can serve many downstream applications.The knowledge graph constructed in this paper can not only be used to store structured accident data and build accident portraits,but also can be used for more in-depth accident intelligent analysis,accident prevention and accident intelligent decision-making,such as accident semantic search,accident correlation path analysis,accident early warningetc.,to further assist in the prevention of safety accidents.
In the future,work can be carried out to improve the information extraction accuracy of the current model.In addition,the relationships between accident risk factors will be extracted to improve the knowledge graph of chemical accidents.Work can also be done to further explore the methods of accident cause reasoning and accident development path analysis.
Data Availability
Data will be made available on request.
Declaration of Competing Interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Acknowledgements
The authors are grateful for the support of the National Key Research and Development Program of China (2021YFB4000505)and Sichuan Science and Technology Program (2021YFS0301).
 Chinese Journal of Chemical Engineering2023年9期
Chinese Journal of Chemical Engineering2023年9期
- Chinese Journal of Chemical Engineering的其它文章
- Anti-carbon deposition performance of twinned HZSM-5 encapsulated Ru in the toluene alkylation with methanol
- A highly efficient La-modified ZnAl-LDO catalyst and its performance in the synthesis of dimethyl carbonate from methyl carbamate and methanol
- Studies on polyoxymethylene dimethyl ethers production from dimethoxymethane and 1,3,5-trioxane over /ZrO2-TiO2
- Continuous,efficient and safe synthesis of 1-oxa-2-azaspiro[2.5]octane in a microreaction system
- Closed-loop scheduling optimization strategy based on particle swarm optimization with niche technology and soft sensor method of attributes-applied to gasoline blending process
- Loading CuO on the surface of MgO with low-coordination basic O2- sites for effective enhanced CO2 capture and photothermal synergistic catalytic reduction of CO2 to ethanol