
乌兹别克语命名实体数据集构建研究
2023-12-06 04:01:18艾孜海尔江玉素甫姬东鸿艾孜尔古丽
中文信息学报 2023年9期
艾孜海尔江·玉素甫,姬东鸿,李 霏,滕 冲,艾孜尔古丽
(1. 武汉大学 国家网络安全学院 空天信息安全与可信计算教育部重点实验室,湖北 武汉430072;2. 新疆师范大学 计算机科学技术学院,新疆 乌鲁木齐 830054)
0 引言
命名实体识别(Named Entity Recognition,NER)是自然语言处理中的一项重要任务,其发展经历了从早期基于词典和规则的方法,到传统机器学习方法,再到目前采用基于深度学习的方法,如注意力机制、图神经网络等。尽管现在已经出现了许多命名实体识别方法,但由于命名实体本身的随意性、复杂性和多变性等特点,仍存在许多问题需要解决。其中,缺乏高质量数据集是当前实体命名识别技术发展的一个主要障碍。高质量标注的数据集对于模型的训练和评估具有至关重要的作用。目前,监督学习仍然是最有效的模型训练方法,从Word2Vec到BERT等基于深度学习的命名实体识别方法的性能提升,得益于大规模语料库的预训练模型的发展。然而,数据集的缺乏将直接导致模型的训练和部署效果受到限制。数据标注仍然是一项耗时昂贵的任务,特别是在某些特定领域,需要领域专家进行数据标注,这是一个巨大的挑战。因此,如何快速、准确、经济地构建高质量的数据集,是当前命名实体识别技术需要解决的一个重要问题。
本文构建了一个规模较大、标注质量较高的乌语命名实体数据集,数据集来源于新闻语料。文章详细介绍了数据集的准备、标注体系、构建方法及过程。本文采用了双向长短时记忆网络(Bi-directional Long Short-Term Memory,BiLSTM)-条件随机场(CRF)算法、迭代扩张卷积神经网络(Iterated Dilated Convolutional Neural Networks, IDCNN)-CRF算法和双向门控循环单元网络(Bidirectional Gating Recurrent Unit,BiGRU) -CRF算法对该数据集进行了实验评估和分析。该数据集可为后续相关研究提供数据基础和评测依据,为乌语命名实体识别领域的研究提供了有力的数据支撑和有效的评测基础。
1 相关工作
乌语自然语言处理在国内外都处于初始阶段。国外学者Baisa[1]等构建了包括乌语在内的六种语言的网络语料库。King[2]等在使用弱监督方法标记混合语言文档中单词的语言时构建文本语料库。Li[3]等构建了乌兹别克语-英语和土耳其语-英语语素对齐语料库。Tsai[4]等通过对维吾尔语和乌兹别克语进行跨语言迁移实体命名识别并获得60.4的F1值。Sharipov[5]等训练了基于 BERT 架构的预训练乌兹别克语语言模型。Salaev[6]等填补了乌兹别克语语义相似性和相关性数据集的空白。Matlatipov[7]等通过乌兹别克斯坦当地餐厅评论进行情绪分析,最终在性能最佳的模型中达到了91% 的准确率。Sharipov[8]等为乌兹别克语创建词法和句法标记语料库。
国内学者帕提古丽·艾合买提[9]等研究了基于信息处理的乌兹别克语语音变化现象自动还原技术。阿西穆·托合提[10]等人构建乌兹别克语-维吾尔语双语语料库。胡创业[11]等研究了基于翻译API的HSK汉-乌平行词库构建方法。吐拉克孜·吐尔逊[12]等研究了乌孜别克语动词的基本特征。艾孜海尔江[13]等研究了基于多策略的乌孜别克语名词词干识别。玉素甫·艾白都拉[14]等研究了面向自然语言处理的现代乌兹别克语名词词缀。吾买尔江·买买提明[15]等研究了乌兹别克语词干提取算法的比较。原伟[16]研究了基于情感词典和标注语料库的乌兹别克语短文本情感分析。这些研究对该领域的发展均做出了积极贡献,但目前尚没有学者开展专门针对乌语命名实体识别问题的研究。
相对而言,维吾尔语实体命名识别有着较多的成果。维吾尔语命名实体数据集构建,学者艾斯卡尔·肉孜[17]等根据维吾尔人名特点构建人名数据集。塔什甫拉提·尼扎木丁[18]等在人名、地名、机构名的一体化识别任务中所构建的数据集。阿迪来·艾合买提[19]等在对维吾尔语音乐实体识别研究的任务中,构建含有音乐实体的数据集。买买提阿依甫[20]等对天山网新闻数据进行人工标注词性和命名实体标记作为实验语料库。王路路[21]等在使用深度神经网络对维吾尔文命名实体识别研究的任务中,使用新疆多语种信息技术实验室标注的命名实体数据集。孔祥鹏[22]等使用迁移学习对维吾尔语命名实体识别中构建新闻语料标注数据集。
综上所述,乌语实体命名识别在国内外是一个未被开发的领域,而在机器学习方面研究命名实体识别需要依赖规范的数据资源。因此,建立符合规范的命名实体相关数据资源是十分关键的工作,是不可忽视的任务。针对上述问题,本文主要贡献为以下三点:
(1) 构建了一个包含25 966个标注实体的乌兹别克语新闻实体命名识别数据集。该数据集涵盖了三种类型的命名实体: 人名、地名和组织机构名,具有很高的质量和覆盖范围。
(2) 在该数据集上进行了实验和分析,使用了三种不同的深度学习模型: BiLSTM-CRF、BiGRU-CRF和IDCNN-CRF。实验结果表明,这些模型均可显著提高NER任务的准确性和F1值,其中BiGRU-CRF模型表现最好。
(3) 对模型的预测结果进行了可视化分析,并进一步分析了模型在不同类型的命名实体上的性能。
实验结果表明,模型能准确地识别大多数命名实体,并将它们正确分类为人名、地名或组织机构名。但仍然存在一些问题。其中之一是识别未登录词,即在训练数据中从未出现过的单词或词组,因为模型可能无法正确理解这些词的含义。此外,模型存在将组织机构名称错误地分类为地名的问题,这也是需要改进的问题。
2 数据集构建
2.1 数据收集
目前,尚未见关于乌语实体命名识别研究的公开数据集,因此,本文从https://dunyo.info/uz新闻媒体平台收集500篇新闻文章,并对这些文本进行了预处理。预处理包括去除HTML标签、分词、去除重复数据等。乌语是一种黏着语言,具有丰富的形态变化。单词可以通过添加前缀、后缀、中缀和变音来表示不同的语法和语义信息。因此,单词本身往往比较长,且可以有很多不同的变体。这使得对乌语的分词自然语言处理任务具有一定的挑战性。乌语因历史原因,存在西里尔文和拉丁文两种文字体系共用的情况。本文为了更好地处理乌语语料,对文本中西里尔文的书写统一转换成了拉丁文,由此得到两万条乌语拉丁文文本数据集。
2.2 标注流程、数据格式与标注规范
为了保证数据的质量和准确性,由一名语言学专家带领三名精通乌语的语言学专业硕士生担任标注员,三名学生先进行一轮试标注与讨论,在此基础上总结出具体的乌语实体命名数据的标注规范,然后依据标注规范由标注员独立进行标注。对于不一致性标注,由语言学专家进行统一仲裁。同时我们也进行了反复的自查和审核。
数据格式由于每一个实体类句子可能由两个或两个以上的词组成,因此在生成实验数据时,本文采用 BIO[23](Begin-in-Out)标记模式,通过对每个词进行标记,来确定该词是否为某一类实体的一部分。每类实体内部又分为开始位置(B-)、非开始位置(I-),非实体类词统一标记为 O。最终定义的完整的标记集 TagSet={O,B-PER,I-PER,B-LOC,I-LOC,B-ORG,I-ORG},共包含 7 种标签。这些标签用于确定每个词所属的实体类别,以便进行命名实体识别。定义的标注集如表1所示。
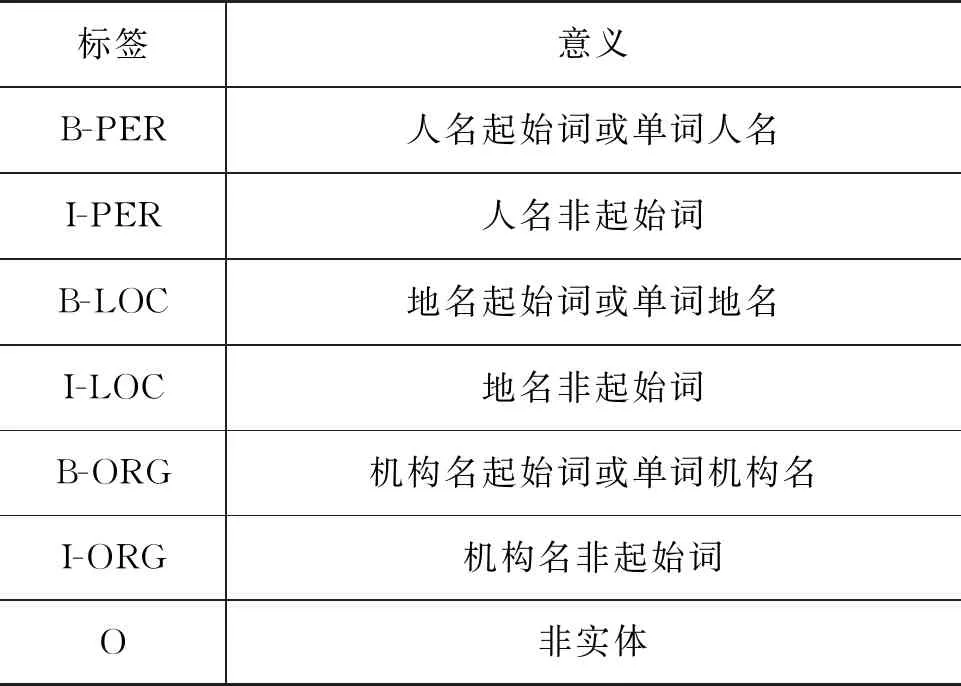
表1 乌语命名实体标注集
标注规范(1) 实体类型: 乌语实体类型在人工标注语料的过程当中,对所有语料本文使用人名、地名和机构名三类实体标记,不是命名实体的词语不需要标记。实体样例如表2所示。

表2 语料标记实例
(2) 标注单位: 参照其他实体命名识别数据集,以单条语句为单位进行标注。
2.3 标注结果
本文选取了500篇新闻文章,通过以上步骤,最终构建了一个包含两万条新闻文本、25 966个实体和274 730个词汇的乌兹别克语新闻实体命名识别数据集。其中,最长的句子由38个词组组成,新闻文本中包含的实体数量最多为7个词组,最少为1个词组。在数据集的构建过程中,我们对这些实体词的长度和词频分布进行了统计,并将统计结果详细呈现于图1中。在标注过程中,本文采用了统一的标注体系,保证了数据集的一致性和可比性。为了确保标注的一致性,本文从数据集中随机抽取了1 000条数据,并由三名标注员进行一致性实验,标注一致性达到了84.3%。
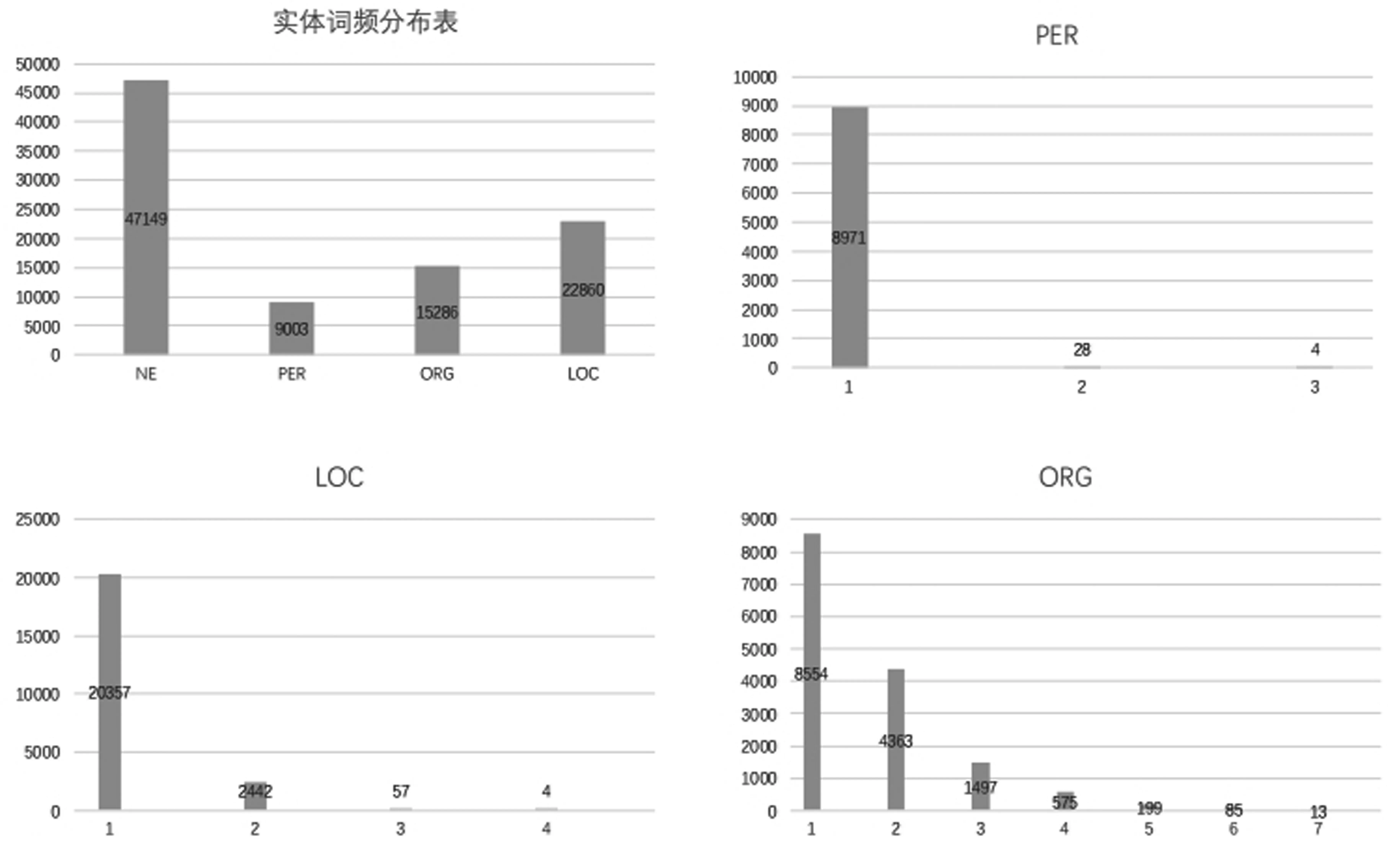
图1 实体词频统计及实体类型长度表
3 实验模型
乌语是多音节语言,与其他语言相比,乌语中的地名和机构名数量庞大,同时音译地名较多,这些名词的长度也没有限制。因此,在处理乌语句子时,将其分成短语或词组更为符合其语言形态特征。本文针对乌语的特性,选择了基于词组进行处理的词级模型。这种模型可以将句子分成不同的词组,每个词组表示一个完整的语言单位,包括名词、动词、形容词和副词等。同时,这种模型可以考虑乌语的黏着性和形态丰富性等特点,能够更好地处理复杂的语法和语义信息。例如,在识别机构名或地名时,考虑到这些名称常常由多个词组成,可以通过识别这些词组来提高准确率。因此,基于词组的词级模型在处理乌语这种黏着性强、形态丰富的语言方面具有一定的优势,特别是在处理地名、机构名等长词汇时更具有效性。
为了进一步探索和分析乌语实体命名识别在本文构建数据集上的表现,本文参考了维吾尔语实体命名识别研究[21]的方法,最终本文选择了三组具有代表性神经网络模型BiLSTM-CRF、BiGRU-CRF和IDCNN-CRF进行实验。
3.1 BiLSTM-CRF模型
BiLSTM-CRF[24]是一种序列标注模型,结合了双向长短时记忆网络(BiLSTM)和条件随机场(CRF)两种方法。BiLSTM用于从输入序列中提取特征并捕捉上下文信息;然后CRF用于对标签序列进行全局优化,以提高模型的准确性和鲁棒性。该模型的结构如图2所示。首先将文本序列输入到嵌入层中,每个单词通过嵌入层转换为固定维度的向量表示。接着,采用双向长短时记忆网络(BiLSTM)从输入序列中提取特征。BiLSTM由两个长短时记忆网络(Long Short Term Memory Network, LSTM)层组成,一个从左到右(Forward),一个从右到左(Backward),分别捕捉到输入序列的前向和后向信息。BiLSTM层输出的特征序列输入到条件随机场(CRF)中,对标签序列进行全局优化。 CRF层可以考虑上下文和相邻标签之间的关系,使得标签序列的预测更加准确和连贯。最终,将CRF层输出的标签序列作为模型的最终输出,即对输入序列中每个单词进行标注。
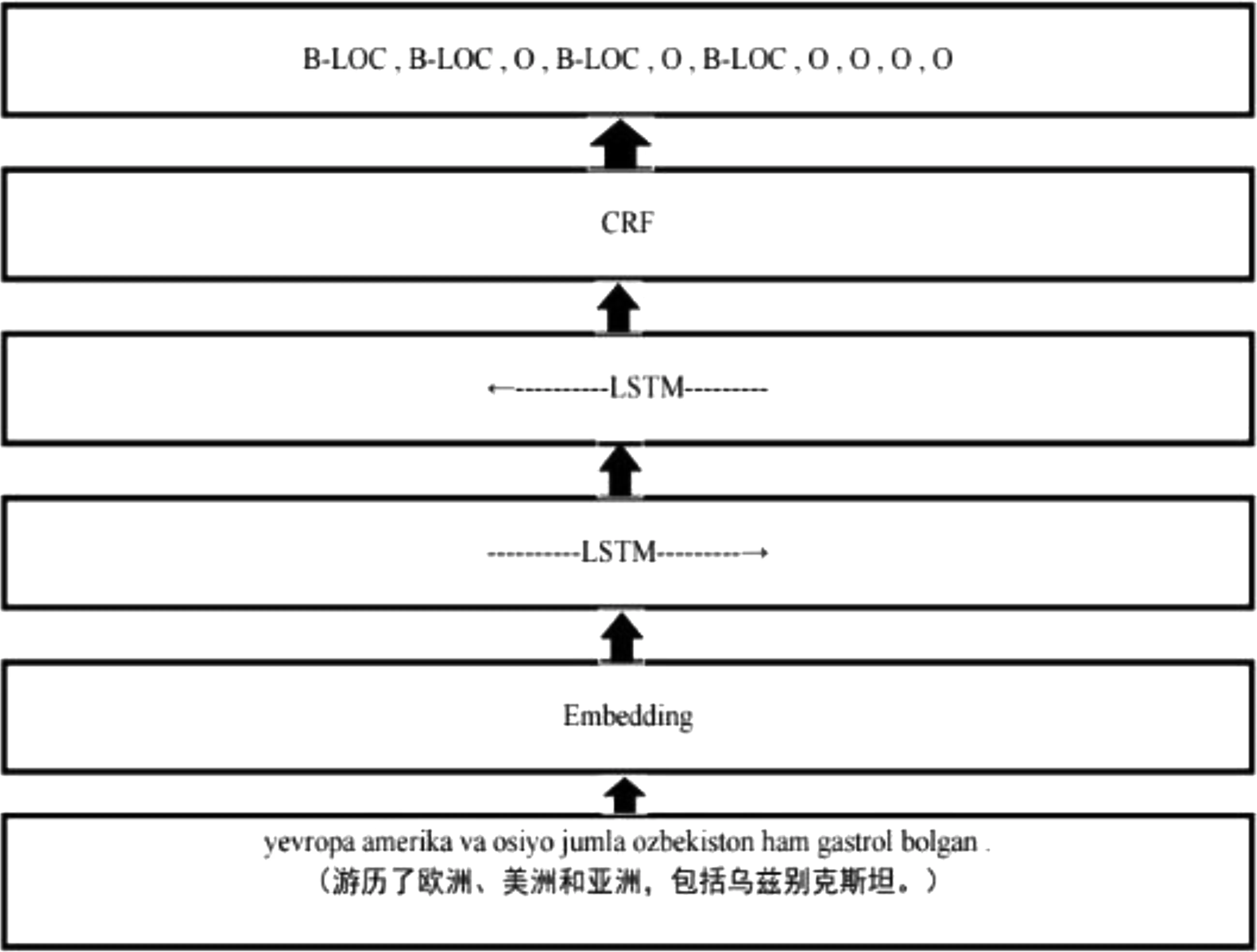
图2 BiLSTM-CRF模型图
3.2 BiGRU-CRF模型
BiGRU-CRF[25]是一种序列标注模型,结合了双向门控循环单元(BiGRU)和条件随机场(CRF)两种方法。 BiGRU用于从输入序列中提取特征并捕捉上下文信息,然后用CRF对标签序列进行全局优化,以提高模型的准确性和鲁棒性。 门循环单元(Gate Recurrent Unit, GRU)是LSTM的一种变体,其单元结构如图3所示。
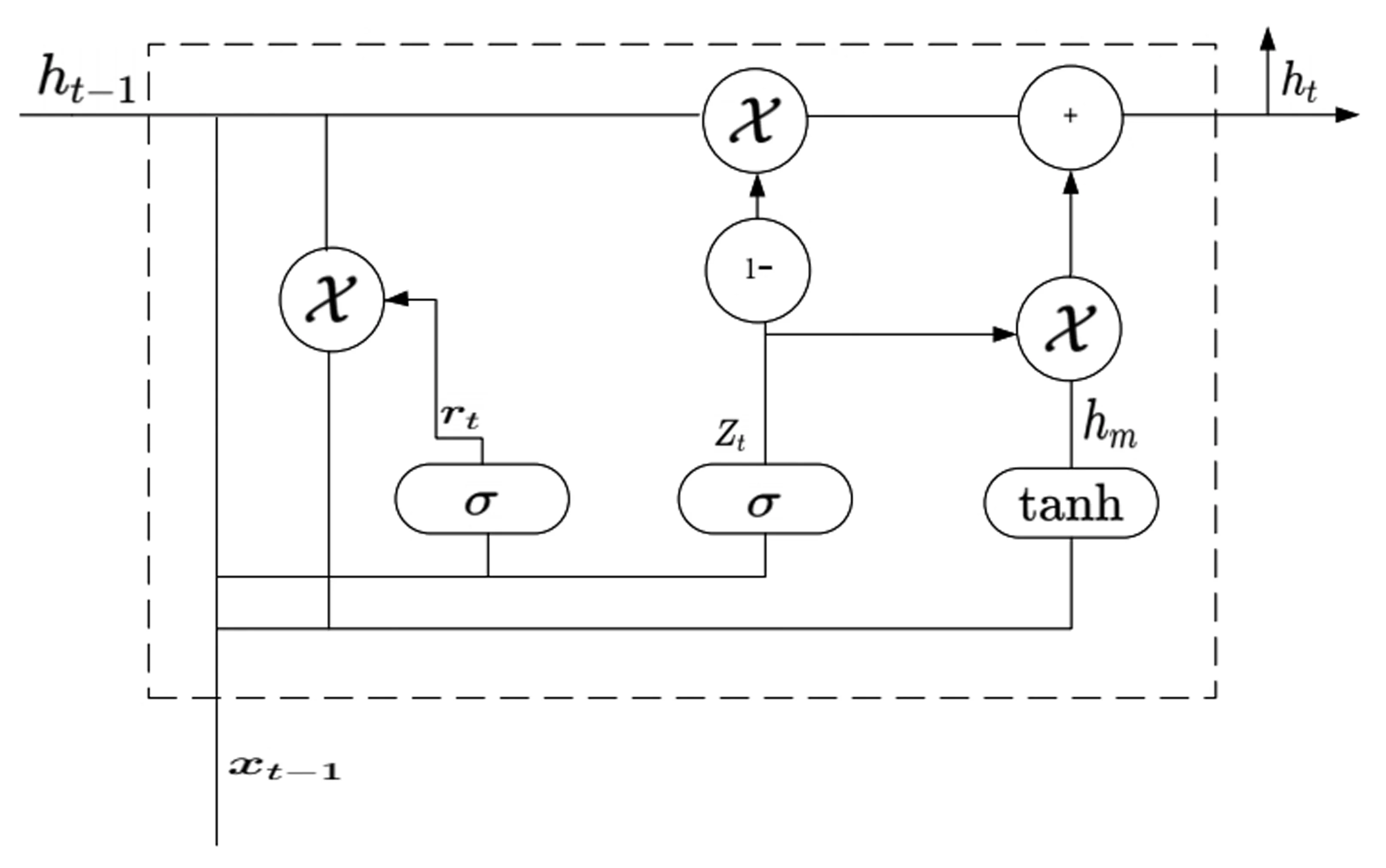
图3 GRU单元结构
与LSTM相比,GRU的结构更加简单,将遗忘门和输入门合成为一个单一的更新门,同时将细胞状态和隐藏状态结合起来。BiGRU是在GRU的基础上进行改进,通过双向传递联系上下文语义,提高了模型的特征提取能力和上下文建模能力。
BiGRU模型的结构如图4所示。首先将文本序列输入模型中,单词通过嵌入层转换为固定维度的向量表示。随后使用双向门控循环单元(BiGRU)从输入序列中提取特征。BiGRU由两个GRU层组成,一个从左到右(Forward),一个从右到左(Backward),分别捕捉输入序列的前向信息和后向信息。将BiGRU层输出的特征序列输入到条件随机场(CRF)中,对标签序列进行全局优化。CRF层可以考虑上下文和相邻标签之间的关系,使得标签序列的预测更加准确和连贯。最后将CRF层输出的标签序列作为模型的最终输出,即对输入序列中的单词进行标注。
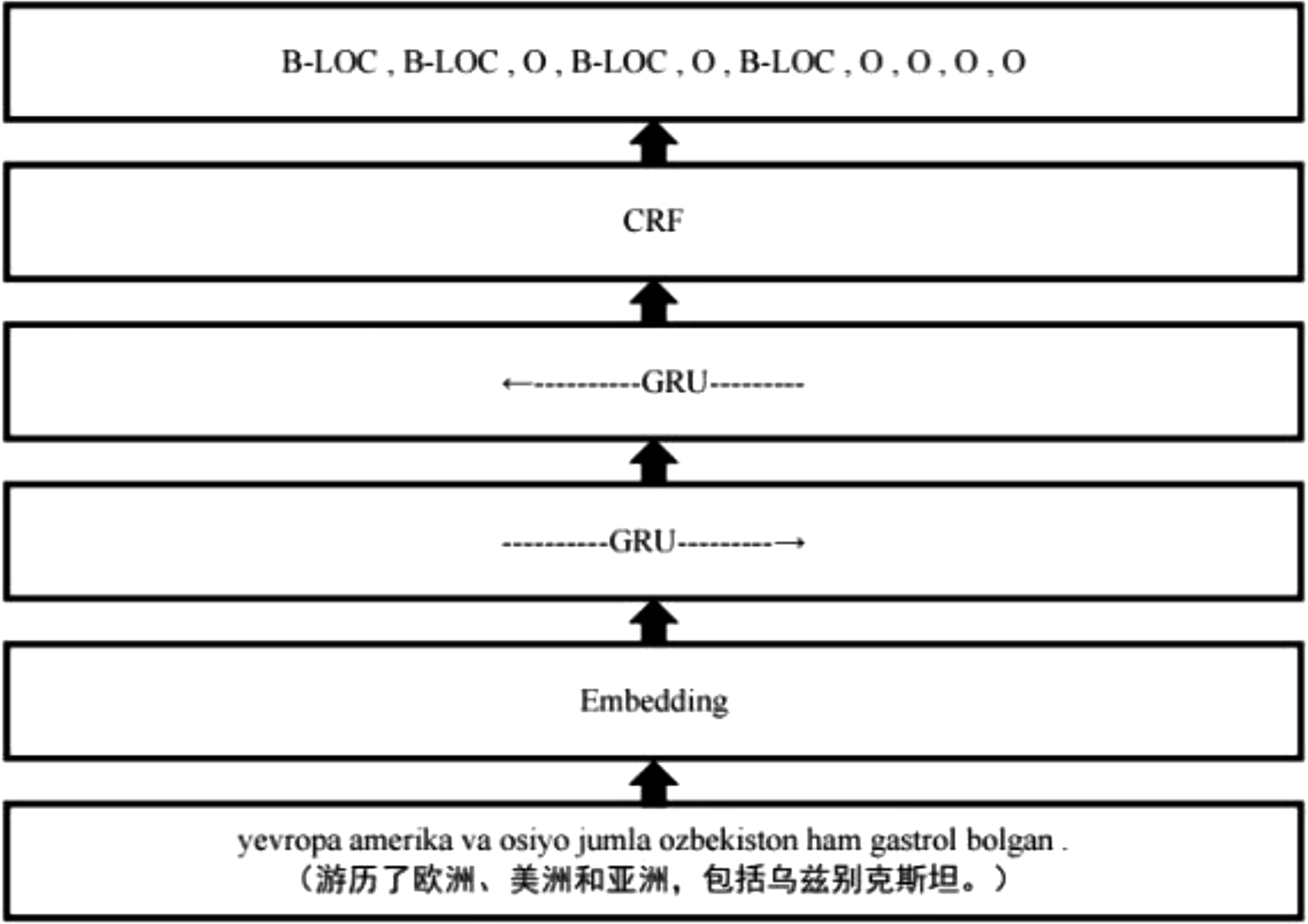
图4 BIGRU模型图
3.3 IDCNN-CRF模型
IDCNN-CRF[26]结合了迭代扩张卷积神经网络(IDCNN)和条件随机场(CRF)两种方法,其主要目的是在不增加模型参数和保持模型速度的前提下,增大模型的感受野。IDCNN用于从输入序列中提取特征,然后CRF对标签序列进行全局优化,以提高模型的准确性和鲁棒性。模型结构如图5所示,它先将文本序列输入模型中,每个单词通过嵌入层转换为固定维度的向量表示。使用卷积神经网络(CNN)变种IDCNN,从输入序列中提取特征。这些特征可以是局部的或全局的,可以捕捉到不同层次的信息,如词汇、句法、语义等。将特征序列输入到条件随机场(CRF)中,对标签序列进行全局优化。CRF层可以考虑上下文和相邻标签之间的关系,使得标签序列的预测更加准确和连贯。最终将CRF层输出的标签序列作为模型的最终输出,即对输入序列中的每个单词进行标注。

图5 IDCNN-CRF模型图
4 实验流程及结果分析
4.1 数据集与评价指标
目前,针对乌兹别克语命名实体识别的公开语料库未见报道,实验采用本文建立的乌语实体命名数据集(UZNERD),本文建立的数据集囊括了500篇新闻文章语料总共两万条文本数据,包含10 910个人名、10 116个地名、4 940个机构名。按照8: 1: 1的比例将数据集划分为训练集、验证集和测试集。数据集的详细信息如表3所示。

表3 乌语实体命名数据集的统计信息
本次实验使用准确率(Precision,P)、召回率(Recall,R)和综合评价指标(F1-Measure,F1)作为实验结果的评价指标。计算如式(1)~式(3)所示。
4.2 参数设置
本文的实验部分旨在评估三种不同的模型在命名实体识别任务上的表现。我们选择了BiLSTM-CRF,IDCNN-CRF和BiGRU-CRF这三种模型进行比较。
为了保证结果的可靠性,实验将最大序列长度设置为100,将训练Epoch设置为50,Hidden_dim设置为200,Batch size设置为32,Dropout率设置为0.5,学习率设置为0.001,优化器使用Adam。IDCNN模型中Nums设置为2,Filter_nums设置为64。
本实验程序部署于配置为Intel Core (TM) i7-1170F、@2.50GHz 处理器、16 GB RAM、Nvidia GeForce GTX 3090上运行。使用Nvidia GeForce GTX 3090的GPU进行加速;基础程序和训练使用Python 3.8.8和Transformers 4.6.1。
4.3 实验结果与分析
为了评估本文提供的乌语命名实体识别数据集的效果,本文使用了三种不同的模型,分别是BiGRU-CRF、BiLSTM-CRF和IDCNN-CRF。实验结果如表4所示。可以看出,三种模型在该数据集上的性能表现差异不大。其中,BiGRU-CRF模型在该数据集上的性能最佳,其F1值达到了90.30%。这是因为BiGRU-CRF模型能更好地捕捉句子中的上下文信息,并且具有更快的训练速度。与此相比,BiLSTM-CRF模型的表现仍然很好,但训练速度稍慢一些。值得注意的是,BiLSTM-CRF模型和BiGRU-CRF模型在准确率、F1值和召回率等性能指标上表现相似,仅存在微小的差距。相比之下,IDCNN-CRF模型在处理该数据集时表现不佳,这是因为该模型没有充分捕捉到句子中的上下文信息。

表4 乌语命名实体识别数据集在不同模型上的表现 (单位: %)
本文使用的模型在三类实体词上的实验结果如表5所示。可以看出,人名识别的性能最好,这可能是因为人名通常有着明确的上下文信息,因此与其他非实体词的歧义可能性较小。由于一些地名是由人名等其他实体词构成的,并且存在一词多义的现象,因此其识别性能略低于人名。机构名的识别准确率最低,这主要是因为机构名通常由多个其他实体类词构成,如地名等,其边界比较难确定。
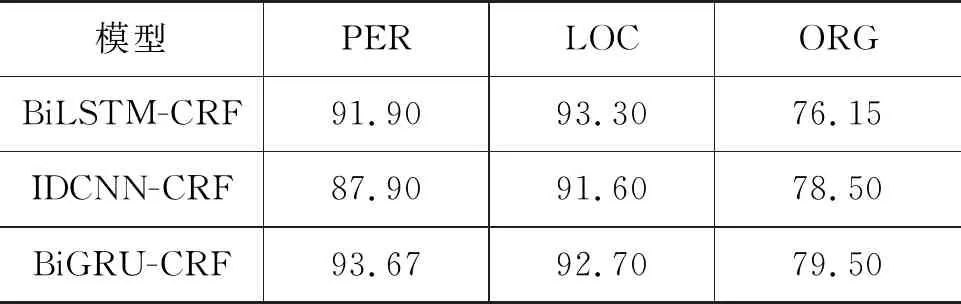
表5 各模型不同类别命名实体识别实验的F1值对比 (单位: %)
为了更好地了解模型和数据集的优缺点,错误分析是一项非常有用的工具。本文对表现最佳的模型BiGRU-CRF在测试集中抽取了50个错误实例,并进行了手动检查。实体类型错误识别占比最大(60%)。接下来是实体边界错误识别(40%)。还有其他错误原因,例如,缺乏训练样本等。本文还列出了一些占比较大的错误分类的典型示例,以便更好地理解这些错误。
(1)实体类型错误识别: 这种类型的错误是因为模型遇到了未登录词。由于没有经过训练,未登录词就会被当成非实体或它们的关系被错误地预测。以bangi markaziy afrika reslublikasi poytaxti mamlakat eng yirik shahri.(班吉是中非共和国的首都,也是该国最大的城市。)为例,模型预测中bangi(班吉)被预测成非实体,而中非共和国被正确预测。本文查看了本文标注的数据是标注正确的。训练集中较少出现的、比较生僻的地名或未登录词,由于模型未能充分训练,从而错误地识别该实体类型。
(2)实体边界错误识别: 当多个词汇组成的地名或者组织名在实体中出现时,多个词汇组合会对判断边界造成困难。以misr raketa hujumi uyushtirilgani davo qilmoq iordaniya xavfsizlik xizmati rasmiy bugun grad rusumi raketa mamlakat aqaba port shahri kocha biri kelib tushgani va besh kishi jarohatlangani malum qildi.(约旦安全部门官方报告称,今天埃及发生火箭弹袭击,其中一枚火箭弹落在港口城市亚喀巴,造成5人受伤。)为例,模型把iordaniya(约旦)标记成地名,但在iordaniya xavfsizlik xizmati(约旦安全部门)这类由多个词汇组合地名和机构名混合出现的机构名中无法正确识别边界的情况。
综合标注数据集特性和初步实验结果等各方面因素可以看出,针对乌语实体命名识别中的不均衡性、实体嵌套性、实体词组较多、未登录地名影响等特点,需要采用多种策略和方法来提高算法的准确性。这是未来值得深入研究的工作。相比之下,汉语和英语在实体命名识别任务上表现较好的原因主要包括: 数据资源的丰富、语言结构的规则明确以及自然语言处理技术的成熟。然而,在面对乌语时,这些优势可能会被削弱,因此需要采用不同的策略和方法来提高实体命名识别的准确率。
5 结论
本文针对乌语实体命名识别领域中缺乏高质量标注语料的问题,构建了一个面向乌语的实体命名数据集,用三种基于神经网络的命名实体识别方法验证数据集的有效性、可用性,并对识别错误的原因进行了较深入的分析,该数据集可为乌语的命名实体识别工作提供数据支撑。该数据集是从网络新闻媒体中真实数据采集而来,包含了乌语文本中的三类实体及实体词组等多种特点。该数据集为乌语实体命名识别算法的研究提供了重要的数据支持,可以用于模型训练、测试和评估,为该领域的进一步研究提供了良好的数据支撑。通过实验,证明了该数据集的有效性和实用性,有望为乌语自然语言处理领域的发展提供重要的参考价值。
本文尚有几点不足之处,首先,由于使用 BIO 标注方式存在实体边界模糊、无法表示实体结束、与实体类型耦合等缺陷和在乌语实体命名识别中的不均衡性、实体嵌套性、实体词组较多、未登录地名影响等特点,下一阶段研究将使用更精确标注来提高乌语实体命名识别数据集的标注质量。其次,由于乌语的语言结构和词汇特征与其他语言存在差异, 下一阶段的算法设计将重点关注乌语语言的特点,以针对乌语的实体命名识别进行优化和改进。此外,后续工作会继续尝试使用深度学习模型来进行命名实体识别,以挖掘乌语语言中的更深层次的句法特征和更丰富的语义信息。
猜你喜欢
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19 08:52:46
中国外汇(2019年18期)2019-11-25 01:41:54
车迷(2018年11期)2018-08-30 03:20:32
海峡姐妹(2018年3期)2018-05-09 08:21:02
东方女性(2018年3期)2018-04-16 15:30:02
散文诗(2017年17期)2018-01-31 02:34:08
哲学评论(2017年1期)2017-07-31 18:04:00
领导决策信息(2017年9期)2017-05-04 04:04:49
领导决策信息(2017年9期)2017-05-04 04:04:49
公民与法治(2016年10期)2016-05-17 04:12:58
