
面向边缘计算的神经网络MPS加速算法*
2023-12-05 12:20王卓霖江俊扬杨耿超姚清河蒋子超张仪
中山大学学报(自然科学版)(中英文) 2023年5期
王卓霖, 江俊扬, 杨耿超, 姚清河, 蒋子超, 张仪
1.中山大学航空航天学院,广东 深圳 518107
2.特文特大学机器人和机电一体化系,荷兰 恩斯赫德 7522NB
计算流体力学(CFD,computational fluid dynamics)是当前流体力学领域中十分重要的研究方法,通过数值求解流体运动的控制方程组,研究流体流动的物理现象.目前主流计算流体方法主要分为两类:基于网格的欧拉方法和基于粒子的拉格朗日方法.欧拉方法如有限体积法(FVM)、有限元法(FEM)、有限差分法(FDM)通过对计算区域划分网格,离散微分方程,获得网格点各时刻的物理量变化;拉格朗日方法则研究粒子的物理量随时间的变化,适用于比较复杂的边界情况(Chikazawa et al.,2001)或者大变形流体(Gotoh et al., 2006)模拟场景.
近年来拉格朗日方法得到发展,SPH(Monaghan,1992)、MPS(Koshizuka et al.,1996)等粒子方法逐渐受到CFD 界重视.其中MPS(moving particle semi-implicit )最早由Koshizuka et al.于1996 年提出,并由于其准确性和稳定性等特点受到了学术界的广泛关注.随着MPS理论的进一步发展,Khayyer et al.(2008)提出了CMPS方法修正了梯度算子导致的动量不守恒,增加了自由表面粒子的稳定性,通过改进PPE方程和修正矩阵提出了MPS-HS 方法、MPS-HL 方法、ECS 方法、GC 方法等,降低了计算的不稳定性;Tsuruta et al.(2013)提出了MPS-DS 方法修正了斥力模型,进一步增强了计算的稳定性;Tsuruta et al.(2015)提出了SPP 方法通过引入空间势能粒子对非物理空腔问题做了优化;越来越多的修正方法强化了MPS 的优越性,抑制了压力振荡,使其被大量应用于涉及复杂边界、大变形、多相流等复杂流体问题中(Shibata et al.,2007;张雨新等,2012;杨超,2018).
MPS 采用预估和修正(显式和隐式)两个步骤来求解流体控制方程(Koshizuka et al.,1996),预估步中通过体积力与黏性力显式更新速度和位移;在校正步中通过保持粒子数密度不变构造压力泊松方程,隐式求解下一时间步的压力,并利用压力梯度修正速度和位移.然而,这种隐式计算方法需消耗大量计算资源.与显式计算压力状态方程的SPH 方法相比,传统MPS 方法难以高效并行求解,使其不适合大规模仿真计算,在实际工程中无法广泛应用(张弛等,2011).前期研究中,我们提出了一种基于数据驱动求解MPS 压力泊松方程的NN-MPS 算法,该算法将原始MPS 中压力泊松方程的求解重新描述为回归问题,提取对泊松求解起主导作用的特征参数作为回归问题的输入,并引入神经网络(NN,neural network)解决该回归问题.
边缘计算(何腾,2020)是相对于云计算(崔勇等,2017)而言的一种概念,指在靠近数据源头的网络边缘侧对数据进行直接计算,而无需将数据传输至云端数据处理中心的一种数据处理方式.随着人工智能的发展,在数据源头的离线设备上直接进行实时神经网络推理的需求增加,昂贵、大体积、大功率的传统计算硬件如专业级GPU(Lee et al.,2010)、CPU 集群已经无法满足目前的需求,廉价、高性能的面向神经网络的边缘计算硬件成为研究热点.因此,多种专供神经网络的专用集成电路(ASIC)芯片被研发出来,如寒武纪思元系列(Liu et al.,2015)、海思科技的昇腾910、谷歌的TPU(Jouppi et al.,2017)及本文将使用的Atlas 200 DK 搭载的Ascend 310 等都属于这类ASIC 芯片.在工业生产领域,常有在边缘侧对监测数据进行离线分析的场景(如地质灾害监测(杜年春等,2022)、空气质量监测(滕云豪,2022)),而由于边缘端算力限制,目前在边缘侧利用流体仿真进行数据分析的应用仍较为少见.我们在NN-MPS中对神经网络的引入,不仅提高了在传统硬件上的计算速度,也为MPS 方法在这些前沿的边缘计算硬件上的计算提供了可能.
本文使用电功耗、成本、体积等各方面较有优势,且在张量计算等神经网络计算有出色计算效率的边缘计算设备Atlas 200 DK 作为加速硬件,成功实现了以新型边缘计算硬件作为加速设备的计算流体仿真.本文研究用较低的成本在小规模与大规模粒子法仿真中达到了与传统CPU计算效率相似甚至有所提高的计算效果.该研究为将来特殊场景下的快速流体仿真提供了一种可行的参考,意味着我们可以在一些需要低成本或无法使用专业计算集群或是在实时采集实际物理边界信息的边缘侧场景中,提供一定的快速流体动力学分析能力.
1 移动粒子半隐式(MPS)方法
1.1 控制方程
不可压缩流体的控制方程组由连续性方程和Navier-Stokes方程组成:
其中ρ为流体密度,P为压力,v为速度向量,f为流体单位质量力,ν是运动黏度系数.
1.2 粒子作用模型
1.2.1 核函数MPS方法中,核函数与光滑半径内邻域粒子相互作用,计算控制方程中的微分算子.Koshizuka et al.(1996)提出的核函数由如下表示:
式中re为粒子的有效半径,即光滑长度.
核函数值在靠近中心处最大,并随着r的增加减小.因此,核函数在计算中起到了类似于权重函数的作用,使较远粒子对于当前粒子的影响较小.在本节后面的部分中将展示由权重函数表示的微分离散计算方法.
1.2.2 粒子密度模型MPS 中粒子数密度n i是第i粒子在核函数控制域内与其周围粒子核函数数值的累加:
其中N为粒子i的相邻粒子,W(|ri-rj|,h)为核函数,ri、rj分别为i、j粒子的位置矢量,h为光滑长度.粒子数密度与流体密度成正比.
1.2.3 Laplacian模型Laplacian算子采用如下形式:
式中D为计算维数,
1.3 预估-修正法
为求解由式(1)~(2)组成的方程组,MPS 方法通过引入中间速度,将N-S 方程分两步求解.第一步通过外力信息和流体速度信息,显式求解中间速度v*,第二步通过压力梯度修正速度,即
其中
1.4 压力泊松方程(Pressure Poisson Equation)
传统MPS 算法通过保持粒子数密度不变来实现流体的不可压缩性,利用中间密度ρ*和中间速度v*,令下一时间步的速度散度为0、密度变化为0,可构造压力泊松方程,进而求解Pk+1.参考Tanaka et al.(2010)、Lee et al.(2011)等的做法,本文采用基于散度的表达式:
其中右边第一项为基于散度为0 构造泊松方程的源项、第二项为基于密度不变构造的泊松方程源项.γ为可变参数,本文中定义为0.2.
1.5 时间积分
综上,MPS算法每个时间步的求解步骤如下:
(i)根据式(8)中黏性力和质量力获得中间速度v*,并计算中间位置r*;
(ii)根据式(4)计算中间粒子数密度n*;
(iii)根据方程(9)求解压力泊松方程,得到Pk+1;
(iv)利用所求压力梯度获得修正速度v',并计算vk+1、rk+1.
2 基于神经网络的MPS算法(NN-MPS)
2.1 原始压力泊松方程
根据式(5)离散Laplacian模型,PPE左边项可以离散成如下形式:
代入式(9),并改成矩阵形式可以表示为
其中
其中下标n为参与计算的粒子数.可知,PPE 是一个包含所有粒子状态的矩阵方程,在大规模计算的情况下,求解该方程将需要非常大的存储空间和非常长的求解时间.为了更高效地求解PPE、MPS中常用共轭梯度法(CG)、不完全Cholesky共轭梯度法(ICCG)进行求解大型矩阵方程,求解该方程的代价仍然极高.
2.2 数据驱动的压力泊松方程
为了解决PPE 求解代价过高的问题,前期研究中,我们提出了一种数值驱动的NN-MPS 方法.NNMPS方法将求解PPE方程转化为机器学习领域的回归问题.针对这一回归问题,算法采用神经网络建立求解模型.对于高维问题,传统数值方法的计算成本过高,神经网络较强的提取特征的能力以及求解非线性问题的能力,使其成为了解决该回归问题一个很好的选择.
为了使回归求解器更加准确和稳定,我们需要为模型选择合适的输入.参考原始MPS 算法的PPE构造:
观察式(15),可以发现中心粒子的压力依赖于光滑半径内其他粒子的压力权重、自身的中间速度、中间粒子数密度.据此,NN-MPS算法提出一种回归模型的构造形式:
其中
式中Pk表示当前时间步该粒子的压力,则体现了周围粒子与中心粒子的压力积分特征,的数量由模型的邻域极限半径确定.
基于以上数据模型,NN-MPS构造了适合PPE回归求解器的输入.
2.3 DNN(Deep Neural Network)网络模型
多层感知机(Multi-Layer Perceptron)作为一种经典深度学习模型,是当前主流深度神经网络的基础(Gardner et al.,1998).一个多层感知机包含一个输入层、一个输出层,以及多个隐藏层,每一层包括多个感知器,每个感知器具有一个或多个输入、偏置、激活函数,以及单个输出.感知机每一层可以表示成:
其中x=(x1,x2,…,xn)表示该层的输入向量,ω表示权重,b表示偏置,H则称为激活函数,f(x)表示该层输出.
本文选择以多层感知机作为回归网络的基础结构.隐藏层的层数对回归求解效果、计算速度有较大的影响,目前相关领域尚无法给出DNN 模型深度(隐藏层层数)与计算误差之间的绝对关系.因此,综合考虑了计算精度、计算效率之间的平衡,结合实际数值测试结果,我们选择将隐藏层数设置为5.如图1 所示,整个结构包含1 个输入层、5 个隐藏层和1 个输出层,层与层之间采用ReLU(Glorot et al.,2011)函数作为激活函数.输入层中的排序由粒子与中心粒子距离决定,这种排序方式可以帮助神经网络学习系统的潜在特征.
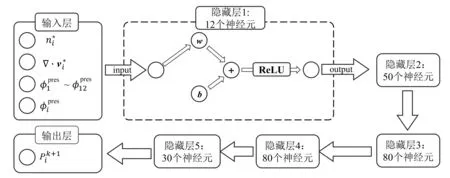
图1 神经网络结构示意图Fig.1 Structure of the neural network
改进后的MPS算法单时间步积分流程如下:
(i)根据式(8)中黏性力和质量力获得中间速度v*,并计算中间位置r*;
(ii)根据式(4)计算中间粒子数密度n*;
(iii)构造神经网络输入,并通过神经网络求解Pk+1;
(iv)利用求得的压力,根据式(9)获得修正速度v',并计算vk+1,rk+1.
3 利用边缘计算设备加速MPS算法
3.1 Atlas 200 DK开发板
华为公司的Atlas 200 DK 开发者套件是以Atlas 200 AI 加速模块为核心的开发板形态.其中Atlas 200 AI 加速模块集成了Ascend 310 AI 处理器,Ascend 310 芯片内置2 个DaVinci AI core,可以实现最大8TFLOPS/FP16或16TOPS/INT8的乘加性能(华为技术有限公司,2022).
开发板可以实现图像、视频等多种数据分析与推理计算,目前广泛用于基于机器视觉的AI应用,如智能监控、机器人、无人机、视频服务器等场景.机身包括2 个DaVinci AI core,1 个8 核A55CPU,支持1000 M 以太网.由于其对神经网络的高速计算的特性与高速以太网通信能力,我们选择Atlas 200 DK作为配置NN-MPS的边缘计算设备.
本文所有工作基于Atlas 200 DK开发者套件的1.32.0.0版本进行开发.
3.2 开发流程
本文采用Python3在Mind Studio平台上进行NN-MPS程序开发.开发前开发平台为Mind Studio,语言为Python3、hiai库。
华为公司为调用AI Core 提供了一套如图2 所示的昇腾软件栈,其相关概念的具体介绍可见华为官方文档.在利用其中的模型转换工具将Tensorflow 模型转换为其所需格式后,通过如下的流程实现调用AI Core完成神经网络推理:
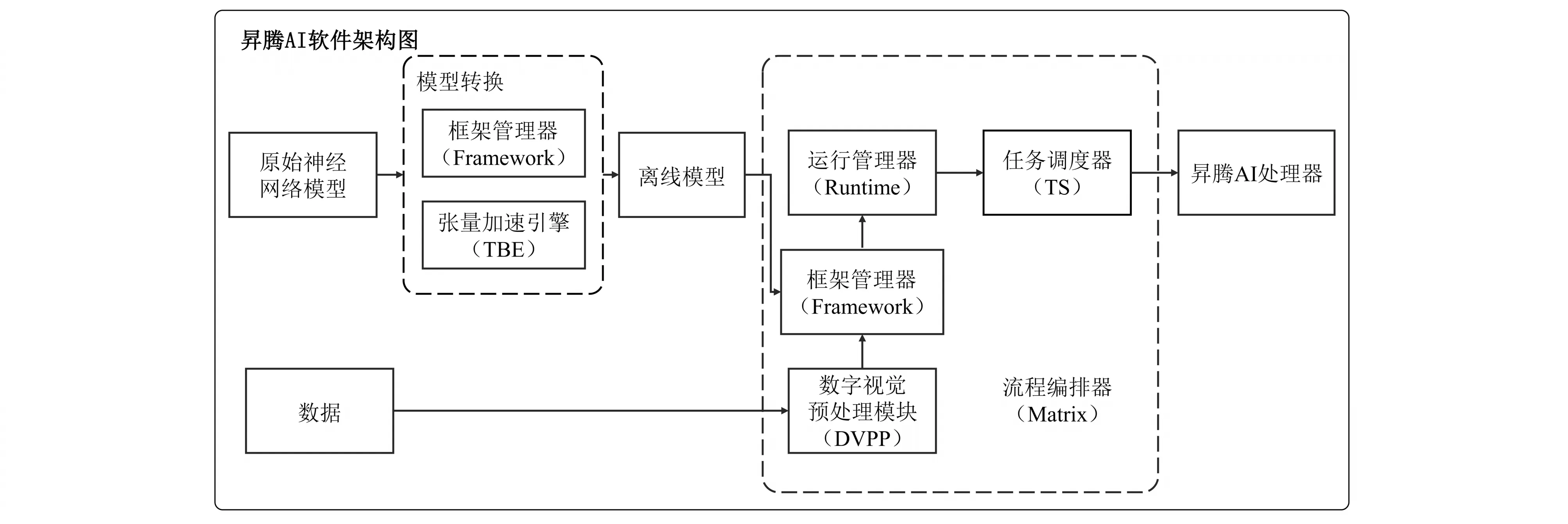
图2 昇腾AI软件栈Fig.2 Software stack of Ascend AI
① 初始化图(Graph)对象,图的作用是管理和编排计算引擎;
② 创建引擎(Engine),引擎是执行功能的基本单元;
③ 设置模型文件(.om)路径;
④ 构造输出输入对象;
⑤ 调用引擎进行模型推理;
⑥ 结果后处理.
3.3 Socket通信方案
Atlas开发板板载CPU实际性能并不比一般计算机CPU高,因此将整个NN-MPS由开发板运行并不是个很合适的方案.考虑到Atlas 200 DK支持1000 M以太网传输,将计算过程分成两个部分,推理部分由开发板完成,其余部分由电脑CPU 完成具有相当高的可行性.因此,为了结合计算机CPU 算力与边缘计算设备对神经网络的加速能力,程序将求解压力泊松方程的神经网络推理部分在Atlas 200 DK 开发板上实现,其余部分由计算机CPU 完成,两者通过千兆以太网利用Socket通信协议实现快速的数据交换.图3展示了整体程序结构.
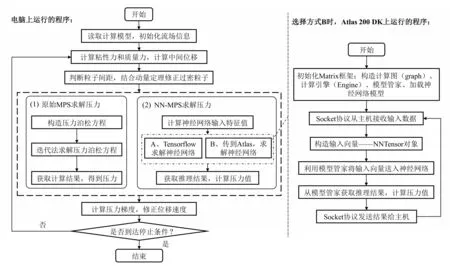
图3 整体计算流程Fig.3 Calculation flow chart
4 算例实验
4.1 模型描述
本文中采用如图4所示增加障碍物的溃坝模型作为验证算例,模型由传统溃坝模型加上圆柱形障碍物组成.文中共有3种模型:溃坝加固定圆柱障碍物、溃坝加周期性移动圆柱障碍物,以及增大宽度的溃坝加固定圆柱障碍物.其中,移动圆柱障碍物的模型则是在图4(a)的基础上为圆柱增加vx= 2.5*2*sign((step + 10)%19 - 10)的运动率,式中step 为计算时间步,sign(a)代表取a的符号(+/-).神经网络用的训练集为传统MPS 计算经典无障碍物的溃坝模型过程中输出每时间步的压力积分特征、速度散度、粒子数密度与中心粒子下一时间步压力所得.
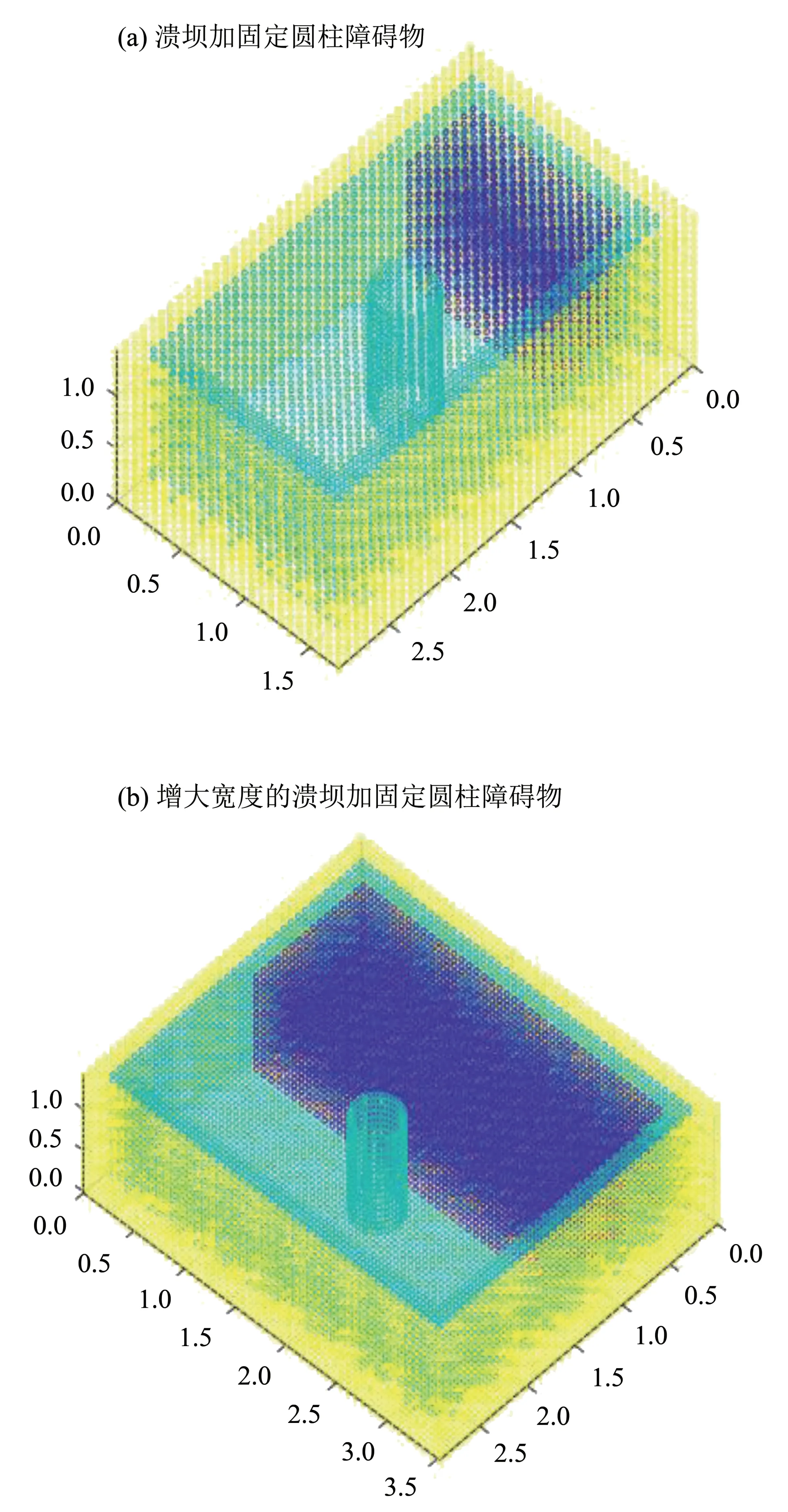
图4 MPS模型初始状态Fig.4 MPS model initial state
采用该模型的原因主要有以下几点:首先,溃坝模型为大部分MPS 算例使用的经典模型,且模型结构简单易于实现;其次,增加了圆柱障碍物和移动障碍物可以更好表现MPS 算法对于复杂边界条件的适应性和泛化能力;不同的粒子规模有助于比较不同规模流场场景下计算速度的差别.
4.2 误差分析
本文计算了在小模型场景下,固定障碍物与移动障碍物模型计算结果在经典MPS 算法、使用CPU 的NN-MPS 算法、使用Atlas 200 DK 加速的NN-MPS 算法的计算精度.使用如下3 个参数进行数值比较:近壁面液面高度、液面前缘位置,以及如图5所示区域的平均压力.
图6~8是3个参数在两种模型下的计算结果,其中前缘位置与液面高度只取了流体与前壁碰撞前的数据.比较两个NN-MPS 与传统MPS 的数据,使用NN-MPS 算法在液面高度、前缘位置上有最大在0.1 作有的相对误差,在压力结果上虽然与原始MPS 算法相比产生了漂移与变形,相对误差较大,但是在总体变化趋势上与实际结果仍比较相似,这些差别是由神经网络模型的结构或训练参数导致,可以通过优化模型得到改善;在两种硬件运行的NN-MPS算法计算结果之间也有微小的差别,这是因为Atlas上的AI芯片只支持最大FP16浮点数,而CPU上则支持64位浮点运算,整体来看,由硬件区别导致的误差与由神经网络模型导致的误差相比,前者几乎可以忽略.
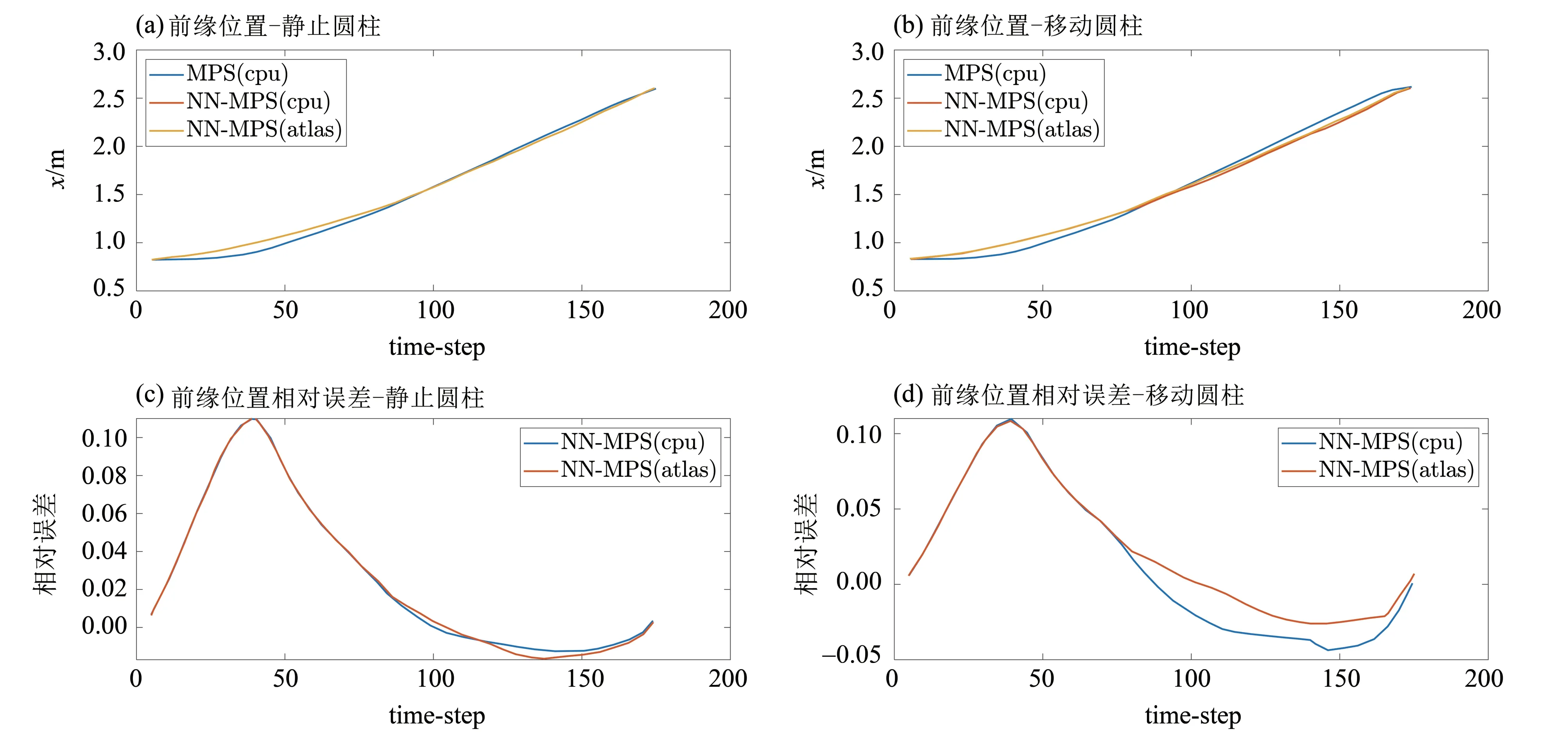
图6 前缘位置变化Fig.6 Movement of the leading edge
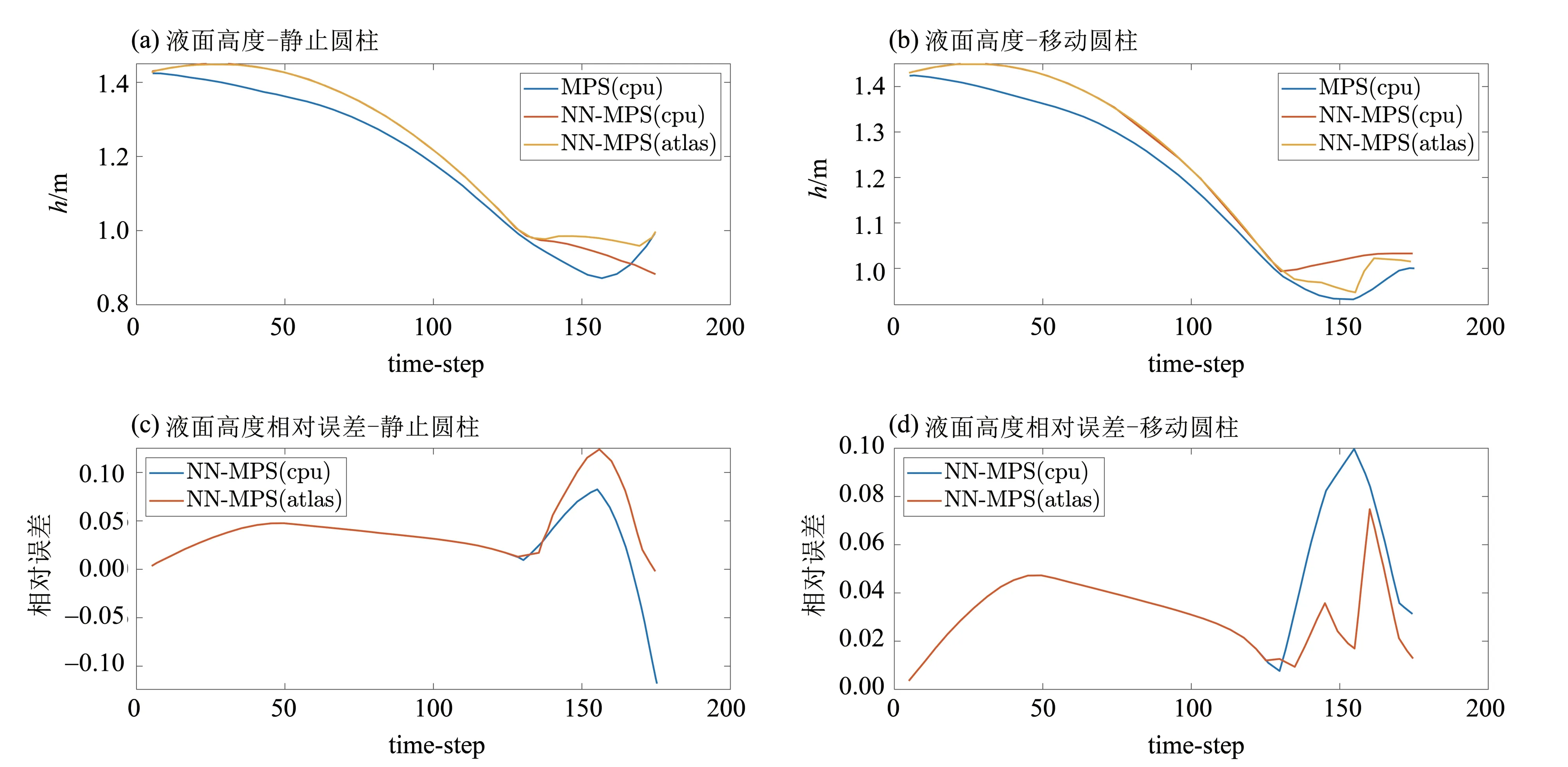
图7 近壁面液面高度变化Fig.7 The liquid level height near the left wall
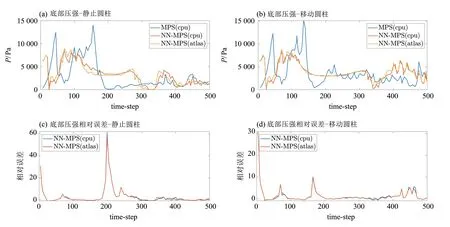
图8 压力变化Fig.8 Pressure developments
单独分析在不同硬件上的NN-MPS计算结果,发现计算前期阶段在CPU 与Atlas上的NN-MPS计算结果差别较小,而在第75时间步左右移动圆柱下的前缘位置参数Atlas 与CPU 计算结果开始出现差别;在125 时间步附近,两者在静止圆柱和移动圆柱的液面高度也开始出现差别.这可能是由于经过碰撞之后产生的流场变化加剧,导致由FP64移植到FP16设备上产生微小误差的积累增大,从而使结果出现较大差距.这点可以通过静止圆柱与移动圆柱计算结果的区别加以证明:静止圆柱场景下,流场变化与移动圆柱场景相比较为缓和,因而移动圆柱场景下,两种NN-MPS 算法的计算结果更早出现较大差别,同理在移动圆柱场景下,液面高度也比静止圆柱场景下出现了更大的差距.
4.3 速度对比
本文比较了加宽模型与小模型分别采用传统MPS、神经网络改进后的MPS、移植到Atlas 200 DK的MPS在求解PPE时的用时情况.为了时间比较的合理性,移植到Atlas 的MPS 计算PPE 求解时包括了Socket通信消耗的时间.
实例计算使用的CPU:Intel(R) Core(TM)i7-10510U CPU@1.80 GHz.
表1 展示了神经网络改进的MPS 算法与移植到Atlas 200 DK 上的改进的MPS 算法在求解PPE的时间上都相较传统MPS 算法有10 倍以上的提升,数据规模较小的模型中(如算例1、算例2中),Socket 通信耗时占比较大,通信时间与AI 芯片神经网络求解时间处于同一量级,因而在CPU 与在Atlas上面的MPS-NN算法相比,反而CPU的计算速度较快;而在数据规模较大的模型中(算例3),Socket通信时间占比减小,移植到Atlas 200DK上的MPS 相较在CPU 上的改进MPS 算法求解PPE用时又有了16%的提升.

表1 PPE求解时间比较Table 1 Computational time for solving PPE
5 总 结
本文采用神经网络结合边缘计算硬件的方式,将MPS 方法中的计算瓶颈——压力泊松方程的计算时间缩减,提出了一种面向边缘计算场景的流体动力学仿真新方案.研究利用神经网络抽象压力泊松方程的求解过程,将其转化为光滑半径内粒子特征与下一时间步压力值之间的回归问题,成功减少了泊松方程求解时间.同时,本文利用边缘计算硬件求解神经网络推理过程,探究在边缘计算场景下进一步加速计算的可能性.在实验结果中,当粒子规模在28 800 以上时,使用边缘计算硬件的计算速度相对于使用CPU 的计算速度有所提升,而在小规模场景下,使用边缘计算硬件与CPU 计算速度相当,因此在计算规模较大时,可以使用本文所述方法作为加速手段.本文采用的方案,相较于使用GPU 等常见加速硬件,具有更低的功率需求和更低的成本,为一些边缘侧有流体动力学仿真需求的场景提供了一种有效的解决方案,同时也为边缘计算与基础学科进行学科交融提供新的切入方向.
猜你喜欢
数学物理学报(2022年5期)2022-10-09
小学生学习指导·高年级(2022年2期)2022-02-16
小学生学习指导(高年级)(2021年6期)2021-06-19
数学物理学报(2020年6期)2021-01-14
通信产业报(2016年44期)2017-03-13
读写算·高年级(2016年3期)2016-05-30
数学年刊A辑(中文版)(2015年2期)2015-10-30
数学物理学报(2015年4期)2015-02-28
河南科技(2014年14期)2014-02-27
雕塑(1999年2期)1999-06-28
