
基于深度学习的隐语义协同过滤推荐模型研究
2023-12-05 08:14:36樊艳清纪佳琪
现代计算机 2023年18期
樊艳清,纪佳琪
(1. 河北民族师范学院信息中心,承德 067000;2. 河北民族师范学院数学与计算机科学学院,承德 067000;3. 河北省文化旅游大数据技术创新中心,承德 067000)
0 引言
推荐系统已广泛应用于电子商务、新闻、音乐、电影、短视频等领域,已成为互联网应用必不可少的关键技术之一。以电子商务领域为例,其与实体店不同,电子商务门户网站能够售卖数以百万计的产品。用户不可能在有限的时间内筛选所有商品,推荐系统可以使目标用户快速发现自己想购买的物品,因此用户越来越依赖于推荐系统给他们推荐喜欢的商品。推荐系统不仅给用户购物带来好的用户体验,也增加了商家的收入。
在推荐系统刚出现时,使用了经典的基于信息检索的方法,如基于内容的过滤[1]。然而,这些技术依赖于专家知识,并且只能应用于某一特定行业,如应用于图书的推荐系统就很难应用于电影推荐,因此很难建立一个通用的模型。这导致了它并没有得到广泛的应用,取而代之并得到广泛应用的其中一种方法是协同过滤推荐模型[2]。协同过滤推荐模型可以分为几个分支,最初是采用基于邻域的方法,它直观、易于理解和实现,但缺乏准确性;第二种方法是基于分类的方法,这会产生稍好的结果,但很难解释;第三种方法,也是目前较流行的方法,即基于隐语义模型(latent factor model),这种方法更为抽象,需要对数学有很好的理解才能进行解释,但推荐效果更为准确[3]。
近些年,深度学习由于其具有强大的特征提取能力,已被广泛应用到计算机科学的各个方面:自然语言处理、语音处理、计算机视觉等[4],其在信息检索方面也有一些应用。基于深度学习的成功,本文提出了一种基于深度学习的隐语义协同过滤推荐模型。浅层的隐语义模型是基于矩阵分解的方法,本文在基本隐语义模型的基础上把其扩展到更深的版本,使用深度学习方法,把矩阵分解扩展为深度矩阵分解版本。
1 相关工作
1.1 基于邻域的模型
基于邻域的模型最初想法来源于人们在电子商务活动中的规律,它发现用户u一定与某些用户具有相同的喜好,因此可以根据相似用户的喜好给用户u做推荐。在这些相似用户中,会给每个用户分配不同的权重,相似度越高权重也就越大。这些相似用户对物品I的评分再乘以他们对应的权重就是用户u对物品i的喜好程度。以上描述可以形式化地表示如下:
其中:u表示需要推荐物品的用户,表示用户u对物品i的预测评分(即预测的喜好程度)。我们找到用户u的所有近邻v,然后用每个近邻的权重wv乘以这个近邻对物品i的评分,最后把所有结果进行加和就可以得到。这种邻域模型又称为基于用户的协同过滤推荐模型[5]。
以上是从用户的角度来看待协同过滤,我们也可以从物品的角度来看待协同过滤,从而产生了基于物品的协同过滤模型[6]。基于物品的协同过滤算法不需要寻找相似用户,而是寻找相似物品,给用户推荐那些和他们之前喜欢的物品相似的物品。其具体过程是用户u对物品i的预测评分是用户u对所有与物品i相似物品的评分乘上这些物品的权重后加和得到的。
1.2 隐语义模型
隐语义模型是一种基于物品过滤推荐模型的推广,隐语义模型[7]认为每个用户可以用用户的属性表示,每个物品也可以用物品的属性表示,而这些属性是什么事先并不知道,因此这些属性称为隐属性,即隐语义。对于具有m个用户,k个隐语义的用户隐矩阵Pm×k和具有n个物品,k个隐语义的物品隐矩阵Qk×n,用户对物品预测评分矩阵(即隐语义模型)的计算方式如图1所示。

图1 隐语义模型
图1的计算过程可以形式化表示如下:
对用户隐语义矩阵Pm×k和物品隐语义矩阵Qk×n实际是求解如下的优化问题。
其中:R是实际评分矩阵,‖ · ‖2是2范式的正则化项,用来防止过拟合问题,λ是正则化参数。
1.3 基于深度学习的推荐模型
受限玻尔兹曼机[8]作为深层信念网络的构建块得到了一定发展,最初也使用它来解决协同过滤问题。然而,由于其输入需限制为1或0,因此受限玻尔兹曼机在基于上下文的协同过滤场景中并未得到广泛使用。修正的高斯-伯努利受限玻尔兹曼机也不适用于此类输入,因为它期望连续值输入在0到1之间。
近年来,基于自动编码器的协同过滤技术显示出良好的效果[9],它们依赖于一个神经网络,其输出与输入相同。用于协同过滤时输入(和输出)存在缺失值,当数据中存在此类缺失条目时,相应的网络权重不会更新。一旦训练完成,编码器的表示与解码器相乘,得到完整的评分矩阵。通过与隐语义模型的相似性分析,可以把网络权重看作是用户隐语义表示或物品隐语义表示。深度堆叠式自动编码器也可以用于协同过滤,一般说来它和自动编码器的输入和输出一样,浅层和深层自动编码器的唯一区别在于后者有更多层的编码器和解码器,然而实践证明过深的层次对效果的提升帮助不大。
还有一些基于深度学习的协同过滤模型的研究都是启发性的[10]。如向深度神经网络中的输入一般是用户和物品的ID 及用户对物品的评分,输出是用户对物品评分的预测值。此类模型最大的缺陷是用户和物品的ID 不包含彼此的任何有用信息(如用户或物品的属性特征、用户对物品的评价特征等)。因此,这些基于深度学习的协同过滤模型对预测评分的准确性有限。
2 基于深度学习的隐语义协同过滤推荐模型
2.1 神经网络表示隐语义
在隐语义模型中,某一用户可以用k维隐向量表示(P矩阵中的一行),某一物品也可以用k维隐向量表示(Q矩阵中的一列)。本文中,我们可以把这种隐向量的表示方式转换成一种神经网络的表示方式,即把用户隐向量的表示转换成物品隐向量到用户对物品评分的一种神经网络连接,如图2 所示。该神经网络的输入是所有用户对物品j的评分,用rj表示,输出是物品j的隐向量表示,用qj表示。这样就把隐语义模型的最初表示形式转换成了神经网络的表示形式,接下来就可以对网络进行扩展,使其成为一个深度神经网络模型。在深度学习体系结构中,来自上一层的隐语义表示可以充当到下一层的输入。本文就以上述方式提出了基于深度学习的隐语义协同过滤推荐模型。

图2 神经网络表示隐向量
2.2 深度隐语义模型
基于深度学习的隐语义协同过滤推荐模型如图3所示,图3中的隐藏层可以扩展到更深层次。理论上讲,随着网络的加深,会提取到更深层次的隐语义表示。比如当我们选择一本书或一部电影时,对于普通的隐语义模型来说只有一少部分隐语义会影响用户的选择(对于一本书来说影响的因素可能是作者、类型、出版社;对于一部电影来说,可能是明星、导演、题材)。然而对于深度隐语义来说,不仅能够捕捉到上述的隐语义,还能够捕捉到其他更深层次的特征。例如,更深层次的神经网络节点可能捕捉到用户的性格特征:内向、外向、中性等,也可能捕捉到物品的一些深层次特征,这些特征的捕获不需要人为干预,深度神经网络会根据不同的数据集自动完成。基于这些更抽象的特征,本文的模型比其他的模型具有更优的鲁棒性和准确性。基于此,我们详细介绍本文提出模型的具体形式化表示。

图3 基于深度学习的隐语义协同过滤推荐模型
如1.2 节所述,在标准的隐语义模型中,评分矩阵可以看作是用户隐矩阵和物品隐矩阵的乘积。
本文的深度隐语义模型中,我们将多层的用户隐语义和一个物品隐语义进行结合,假设有2个用户隐语义,则可以表示为
其中:P1和P2是2 层用户隐语义矩阵,Q是物品隐语义矩阵。因此该模型很容易扩展到N层用户隐语义,如公式所示。
由于R是评分矩阵,在实际数据集中,矩阵中的很多值都是缺失的,因此我们把缺失值的位置都填充为零,可以形式化表示为公式。
其中:·表示点乘,I是只包含0 或1 的矩阵。结合公式(6)就可以形成本文的深度隐语义模型,见公式。
因此,我们需要优化求解如下损失函数:
本文使用投影梯度法对上述问题进行求解,从而形成了本文的算法框架。
上述算法的关键是如何迭代求解Rk+1,Pk+11,Pk+12,Pk+13,…,Pk+1N,Qk+1,由于是在非凸集上进行求解,所以很难直接得到全局最小值。因此,本文提出了对约束进行交替投影的方法[11],以得出该问题的近似解。每个变量都将以Gauss-Seidel[12]的方式依次处理,然后投影到其关联的约束集上。具体形式化的表示如下:
公式中的Projection+表示在正方向上的投影,也就是说如果值出现负数我们会把它置为0(使用ReLU 函数即可完成)。然后可以应用矩阵P在线性约束R上的投影R=A∪B的一般性质,如下:
公式中的+号表示伪逆矩阵(pseudo-inverse),因此公式(10)的具体展开计算见公式(12)。
结合算法(1)和公式(12)就完成了模型参数的求解,在后续的实验中该算法也能较好地收敛。
3 实验
3.1 数据集
本文使用Movielens 提供的3 个电影评分数据集对模型进行评估。
(1)movie-100K:该数据集包含了943 个用户对1682部电影的一万个评分。
(2)movie-1M:该数据集包含了6040 个用户对3900部电影的一百万个评分。
(3)movie-10M:该数据集包含了71567 个用户对10681部电影的一千万个评分。
这些数据集官方在提供时已经划分好了训练集和测试集,本实验中我们使用5折交叉验证得到实验结果。
3.2 模型收敛性
图4 显示模型在movie-100K 上损失值的变化趋势,从图4可以看到,损失值很快下降到最低点,说明模型的收敛速度较快。我们在其他两个数据集上也得到了相同的实验结果,由于篇幅关系,本文不再另行给出。

图4 训练损失值变化趋势
3.3 超参数选择
本文提出的模型主要有两个超参数,一个是神经网络的层数,另一个是投影梯度法的步长γ值。一般说来,神经网络的层数和数据量有一定的关系。如果数据量过少,网络层数过多时很容易造成模型过拟合,通过本文的实验数据(表1~表3)可以看出,当网络隐藏层数大于3时,效果并没有提升。由于每层的神经元个数设置多少并没有统一的理论支撑,本文也是根据以往的经验采取逐层减半的方法。首先我们只设置1个隐藏层,这个隐藏层的神经元个数分别设置为[8,16,32,64,…,128,256],在三个数据集上的实验结果如图5所示,从图5我们可以看出当神经元个数为128 时,模型的效果最好。这个结果决定了我们后续增加隐藏层时每层神经元个数的设置。比如,当有2 个隐藏层时,我们把隐藏层的神经元个数分别设置为64-32;当有3个隐藏层时,每个隐藏层神经元个数分别设置为64-32-16;当有4 个隐藏层时,每个隐藏层神经元个数分别设置为64-32-16-8。实验中发现当隐藏层为4时,效果不仅没有提升反而略有下降。

表1 在数据集movie-100K上的实验结果

表2 在数据集movie-1M上的实验结果
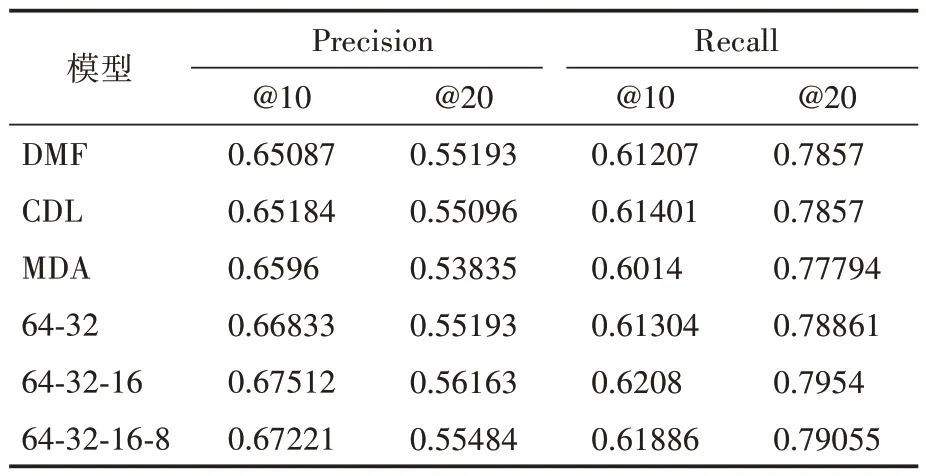
表3 在数据集movie-10M上的实验结果

图5 不同隐藏层数在三个数据集上MAE值
接下来我们需要设置投影梯度法的步长γ。在实验中,我们发现当γ的值在0.01~0.8 之间时,对最终的结果影响不大,但是在这个范围外,算法效果会下降。因此我们随机在上述范围内固定了一个γ值为0.1。
3.4 结果比较
本文选取了一些基于深度学习的经典推荐模型作为比较对象,分别是(1)collaborative deep learning(CDL)、(2)marginalized deep autoencoder(MDA)和(3)deep matrix factorization(DMF)。本文选取了精确度(Precision)和召回率(Recall)作为模型的评价指标,其中Precision@N表示推荐数量为N时模型的精确度。在三个数据集上各模型的实验结果见表1~表3。
从实验结果可以看出,本文提出的模型整体效果要比其他模型效果好,虽然隐语义模型和深度学习模型对于推荐结果的解释性较差,但是实验结果说明隐语义模型结合深度神经网络能够更好地提取特征,从而提升推荐结果的性能。从模型自身对比来看,当本文模型隐藏层数逐步增加到3 层时,推荐的效果也逐步增高;但是当隐藏层数达到4层时,推荐效果不增反降,这主要因为层数增加造成学习的参数增加,过多的参数会造成模型过拟合。
4 结语
本文介绍了基于深度学习的隐语义协同过滤推荐模型,通过把浅层隐语义模型和深度学习技术相结合,形成了深度隐语义模型。通过使用交替投影的方法对模型进行了优化,并且模型收敛较快。与其他深度模型对比,实验结果表明,本文提出模型的Precision和Recall都高于其他深度模型。近年来张量分解、因子分解在机器学习中越来越重要,由于张量维度更高,能表示更多维度的用户或物品特征,因此在未来的工作中,我们将研究把多级张量分解和深度学习进行结合来完成推荐。
猜你喜欢
小学生学习指导(低年级)(2022年5期)2022-05-31 08:33:14
疯狂英语·初中天地(2021年11期)2021-02-16 00:38:58
开放教育研究(2020年2期)2020-03-31 01:54:14
电子制作(2019年19期)2019-11-23 08:42:00
少年漫画(艺术创想)(2019年2期)2019-06-06 07:47:02
现代语文(2016年21期)2016-05-25 13:13:44
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
小天使·一年级语数英综合(2015年8期)2015-07-06 06:23:32
海军航空大学学报(2015年4期)2015-02-27 13:45:47
