
基于飞腾CPU的雷达信号处理算法实现与优化
2023-12-04 10:01马艳艳
舰船电子对抗 2023年5期
张 越,马艳艳
(中国船舶集团有限公司第七二三研究所,江苏 扬州 225101)
0 引 言
近年来,雷达技术呈现发展速度快、愈趋复杂的特点,大量新技术,比如认知雷达、智能化信号处理算法等有待快速地在实际应用中去验证,这就需要雷达开发满足新的要求:
(1) 具备新的算法快速嵌入、功能快速集成、资源快速配置的能力;
(2) 功能算法可以分解复用和继承,具备标准化、通用化开发流程,以提高效率[1]。
传统的雷达信号处理算法都是基于数字信号处理(DSP)+现场可编程门阵列(FPGA)的硬件平台实现,这种方案运算效率和精度高,适合实时性要求高的雷达信号处理,但是其软件和硬件耦合紧密、程序移植性差并且开发周期长的缺点不满足当前的算法快速嵌入验证和算法代码通用化的需求。
现阶段,国内外都开展了软件化雷达的相关研究和应用,其中利用通用中央处理器(CPU)进行软件化雷达的研究尤为重要。基于通用处理器平台,可以软件的方式完成雷达实时信号处理,基于标准化通用接口,实现软件算法与硬件的解耦,以实现算法代码在不同处理器平台上的复用移植。
本文针对现阶段软件化雷达发展需要,在飞腾处理器下开展了雷达信号处理算法的研究和实现。针对飞腾处理器的特点进行了雷达算法组件的相关设计,选取雷达信号处理中典型的处理算法——自适应副瓣对消算法和动目标检测,来进行算法实现及验证。
1 软件化雷达与硬件平台
1.1 软件化与雷达信号处理
相较于以往的软件设计,软件化雷达设计的最大特点就是实现了软硬件解耦、组件化设计。其依赖于通用化、标准化和可扩展性的处理器硬件平台,通过软件编程实现具体算法功能。其中,通用化接口和中间件技术是实现软硬件解耦的关键,中间件一般包含通信中间件和计算中间件。计算中间件的功能是将与操作系统和计算相关的接口统一封装并形成标准,以简化跨平台软硬件的开发,统一软件接口[2]。本文使用矢量信号图像处理库(VSIPL)函数接口作为计算中间件,该接口包含了以下内容:(1)标量数学函数及数据索引函数;(2)随机数产生函数;(3)实数、复数基础向量运算函数;(4)信号处理函数;(5)矩阵运算及线性系统求解函数等。其基本满足雷达后端处理(主要是包含向量运算的信号处理和成像处理算法)的需求。使用统一的规范进行算法编写,实现了对计算平台的屏蔽,设计接口简洁明了,提高了算法开发人员的开发效率,并且易于形成统一的算法组件。
常规雷达信号处理算法包含空域滤波、快时间域滤波和慢时间域滤波,干扰抑制,目标检测和目标识别算法。信号处理可划分为很多功能组件,包括脉冲压缩、动目标检测/动目标指示(MTD/MTI)、副瓣抑制、抗异步干扰、恒虚警等。雷达信号处理软件化,即需要将信号处理算法分解成独立和具有固定功能的组件,并可配置属性以满足不同应用的需求,组件之间设计为标准的输入输出接口,采用统一的数据类型和数据流的模式进行数据传输。
1.2 硬件平台
作为国产化系列的CPU,飞腾系列CPU具有谱系全、性能高、生态完善、自主化程度高的特点。而众多系列中,FT-2000+在单核计算能力、单芯片并行性能、访存带宽等方面都处于国际先进水平,本文的算法在FT-2000+的VPX高性能计算刀片上进行实现。
FT2000+计算刀片上的处理器芯片集成了64个兼容ARMv8指令集的内核FTC662,核心时钟频率最高2.2 GHz。FT2000+处理器采用非一致性内存访问架构(NUMA),每8个处理器核心划分为一个节点。其包含8个DDR4接口,2个x16和1个x1PCIe3,0接口[3]。基于ARM V8架构,其支持针对浮点FPU的VFP硬件扩展和NEON advanced SIMD技术,本文将在第3节利用这一技术对雷达信号处理算法进行实时性优化。另外,采用多核处理器,实现组件的多线程并行计算,利用线程池技术增加处理的实时性。可以说,FT2000+适合具有高实时性要求的雷达信号处理算法。
2 软件化雷达信号处理算法实现
雷达信号处理算法功能组件往往采用3层封装的结构:通信中间件接口层、缓存空间管理层与核心算法逻辑层[4]。本文主要针对核心算法逻辑层进行相关算法组件设计,采用标准VSIPL函数进行向量化运算的封装,选取信号处理中的自适应副瓣对消(ASLC)和动目标检测(MTD)算法进行相关设计。
2.1 自适应副瓣对消组件
自适应副瓣对消的基本原理是增加一个辅助天线阵列,主副天线之间需要有较高相关性,辅助天线数据通过最优权求和,使得主天线信号对消辅助天线信号之后信号功率最小,从而实现主天线副瓣干扰的对消功能。
自适应副瓣对消的实现通常采用开环算法的形式实现,即利用有限的快拍或样本点计算最优权值,基于最小均方误差准则,使得对消输出信号的功率最小。假设主天线的输入信号为Y,N个辅助天线的接收信号为X1,X2,…,Xn,最优权值为WT=(W1,W1,…,Wn),主通道与辅助通道的互相关矩阵为RXY=E[XY*],辅助通道间的自相关矩阵为R=E[XXH],根据维纳-霍夫方程可以得到:RW=RXY,以此可以求得最优权重W=R-1RXY,则对消剩余信号为Z=Y-WHX。本文以讲述组件构成方法,样本选取采用常规方法在远区或休止区选取,如果要考虑主辅通道数据关系选取,则还需要增加求模和比较等操作。
图1为自适应副瓣对消组件的实现,应用的VSIPL接口都在每个步骤的括号中给出。
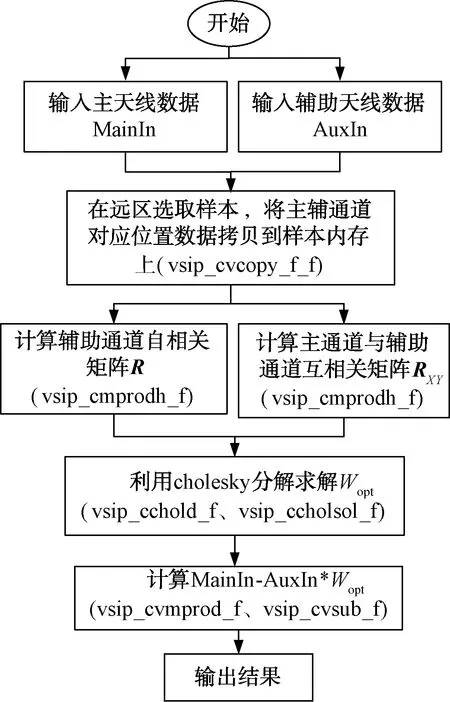
图1 ASLC组件实现流程图
2.2 MTD组件
MTD算法被用于进行自适应杂波抑制。在工程实现上,为了追求实时性,通常采用在慢时间维上进行快速傅里叶变换(FFT),即MTD滤波器组采用FFT滤波器组进行,并采用加窗的方式进行副瓣抑制。但是这种方式下,杂波区的阻带衰减满足不了当前雷达的指标要求,因此需要在通用处理器上实现有限长单位冲激响应(FIR)滤波器组来进行滤波,并且在零频附近设计成满足要求的零陷。很多文献提出了自己的方法以实现满足指标的滤波器组,如文献[5]提出了二阶锥规划方法设计FIR滤波器组。工程上实现后者,即用每个快拍的慢时间维数据与每个滤波器通道进行乘加操作,如果将FIR滤波器看做M×K的矩阵A,M为滤波器组的滤波器个数,K为滤波器长度,将MTD组件的输入看做一个K×N的矩阵B,按行连续,K为慢时间域积累点数,N为快拍数,则MTD即为将矩阵A和矩阵B进行复数矩阵共轭乘法操作,而后的步骤和使用FFT方法一样,可采用求模选大的方式。
图2为MTD组件的实现,VSIPL接口都在每个步骤的括号中提出,其中为了追求速度,将矩阵C的内存看作矩阵来存放共轭乘的结果,又看做是一个向量进行求模操作。
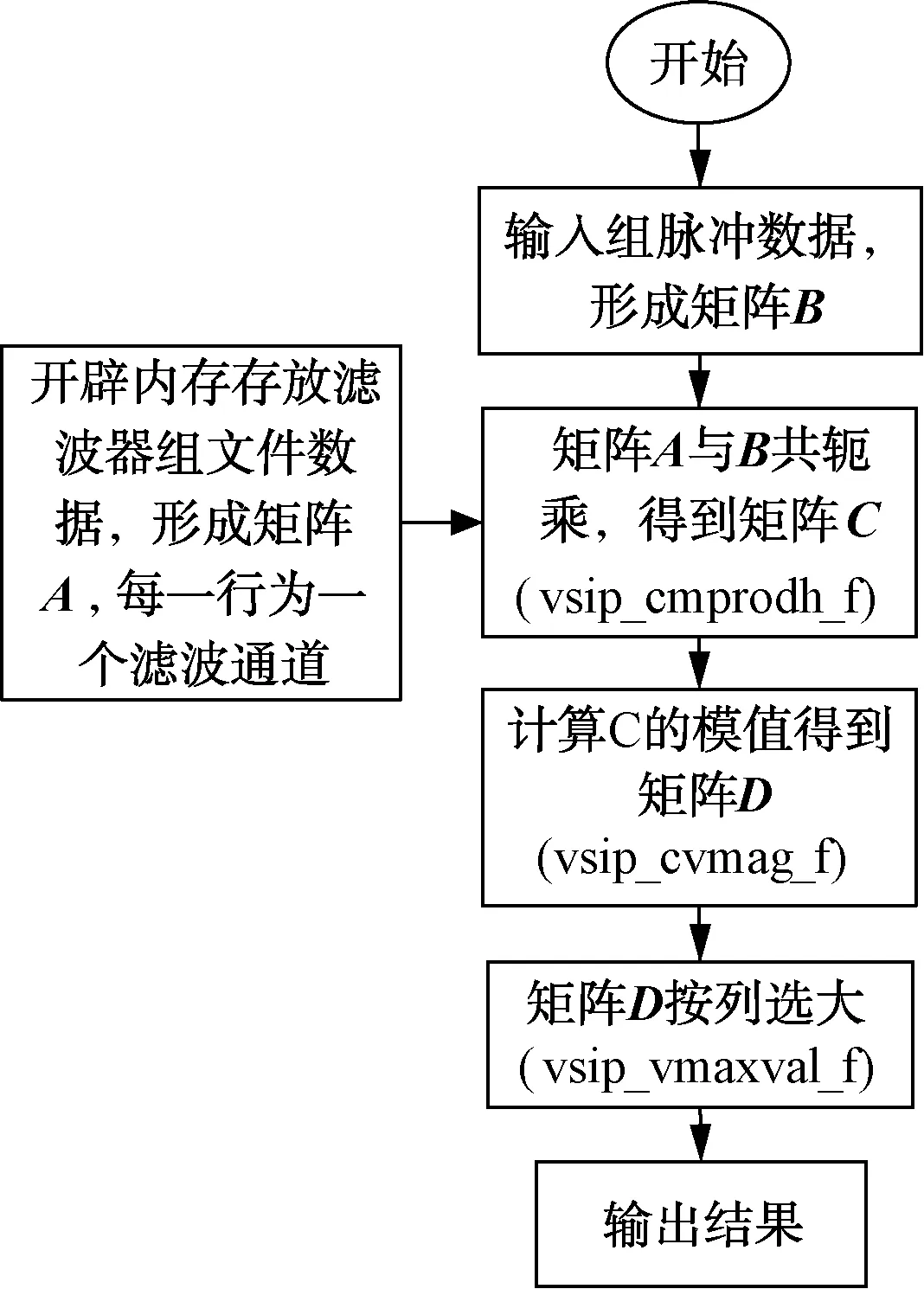
图2 MTD组件实现流程图
3 计算优化
利用VSIPL标准接口作为计算中间件,实现的雷达信号处理算法组件才具有可移植性,在不同平台下,核心算法逻辑代码才得以一致。但是为了满足信号处理的实时性,需要针对不同的平台,对向量运算进行优化。针对飞腾平台,本文利用NEON技术进行相关的运算优化。
3.1 NEON技术与使用
针对CPU下的计算优化,往往采用单指令多数据(SIMD)技术,即使用一条指令来实现针对同种数据类型和长度的多个数据进行并行操作。当今处理器引入SIMD技术的主要有Intel的MMX/SSE,AMD的3D Now!和ARM的NEON等等。NEON高级单指令多数据技术,即NEON指令集,可以实现存储访问、NEON和通用寄存器间的数据拷贝、数据类型转换、向量数据处理等操作。ARM V8平台下,NEON寄存器区支持2种类型视图:包含64个64位双字长的NEON寄存器(D0~D63),或者32个128位4字长寄存器(Q0~Q31)。每个Q0~Q31中的寄存器都映射到一组D寄存器。釆用双重视图的好处在于,它可以满足扩大或缩小结果的数学操作[6]。
以32位float数据类型为例,图3为4个float类型数据之间进行数据计算的过程。Qn和Qm为128位源寄存器,分为4个32位通道,存放4个float数据类型的输入数据,通过并行计算操作之后输出到Qd目标寄存器中。
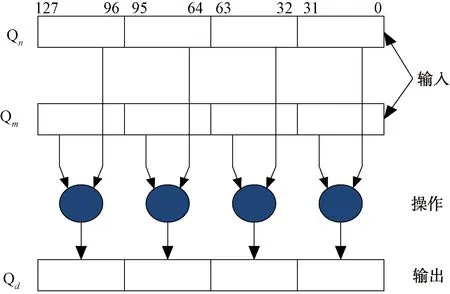
图3 NEON数据并行计算
在FT-2000+上使用NEON优化算法通常有4种方法:(1)编译器自动向量化;(2)NEON汇编;(3)NEON开源库;(4)NEON内嵌函数。第1种方法,在ARM V8架构下,只需要在编译时使用-O3优化编译代码即可自动调用(GCC编译器)。这种方法往往优化效果一般,并且大部分代码并不能自动优化为NEON指令。第2种方法优化效果是最好的,即直接使用汇编语言进行优化,难度较大,实际开发中很少采用这种方式。对于第3种方法,常见的有NE10、OpenBlas、ffmpeg、Eigen3和Math-neon等库,使用时直接调用封装函数即可实现NEON优化。其中,OpenBlas库利用基础线性代数库(BLAS)接口和线性代数函数库(LAPACK)接口优化了矩阵相关运算,很适合本文中的ASLC和MTD的运算优化。第4种方法,NEON内嵌函数调用。类似于普通函数调用,NEON内嵌函数提供了一种低级的NEON指令访问方式,而编译器负责将NEON指令替换为汇编语言的复杂任务,主要包括寄存器分配和代码调度以及指令集重排,来达到获取最高性能的目标。
3.2 信号处理优化
信号处理的计算加速主要是针对实数或复数的向量/矩阵运算。本文中,矩阵相关运算采用OpenBlas库实现功能封装,而向量相关运算则利用NEON内嵌函数进行优化。2种方法结合,将计算优化效果达到最佳。
信号处理计算中包含的复数矩阵求逆和复数矩阵乘法等矩阵运算主要利用OpenBlas库进行速度优化,比如说SLC算法和MTD算法都用到了矩阵复数共轭乘操作,即VSIPL接口中的“vsip_cmprodh_f”。在BLAS接口中对应于cblas_cgemm接口函数,其底层除了用到NEON指令集优化外,还对矩阵进行了分块计算,并且采用了数据预取等技术,使得其矩阵运算效率大大提高。相较于单纯使用NEON内嵌函数,计算加速比约提升2倍。
而针对向量相关运算,本文采用NEON内嵌函数方式进行优化。复数向量求模运算常用于雷达信号处理,比如说MTD算法需要对FIR滤波后的复数数据求模,本文以此为例具体说明优化方法。其VSIPL接口为vsip_cvmag_f,优化步骤如图4所示。针对其他计算优化过程,只需要修改输入向量数量以及替换中间的计算循环体即可。
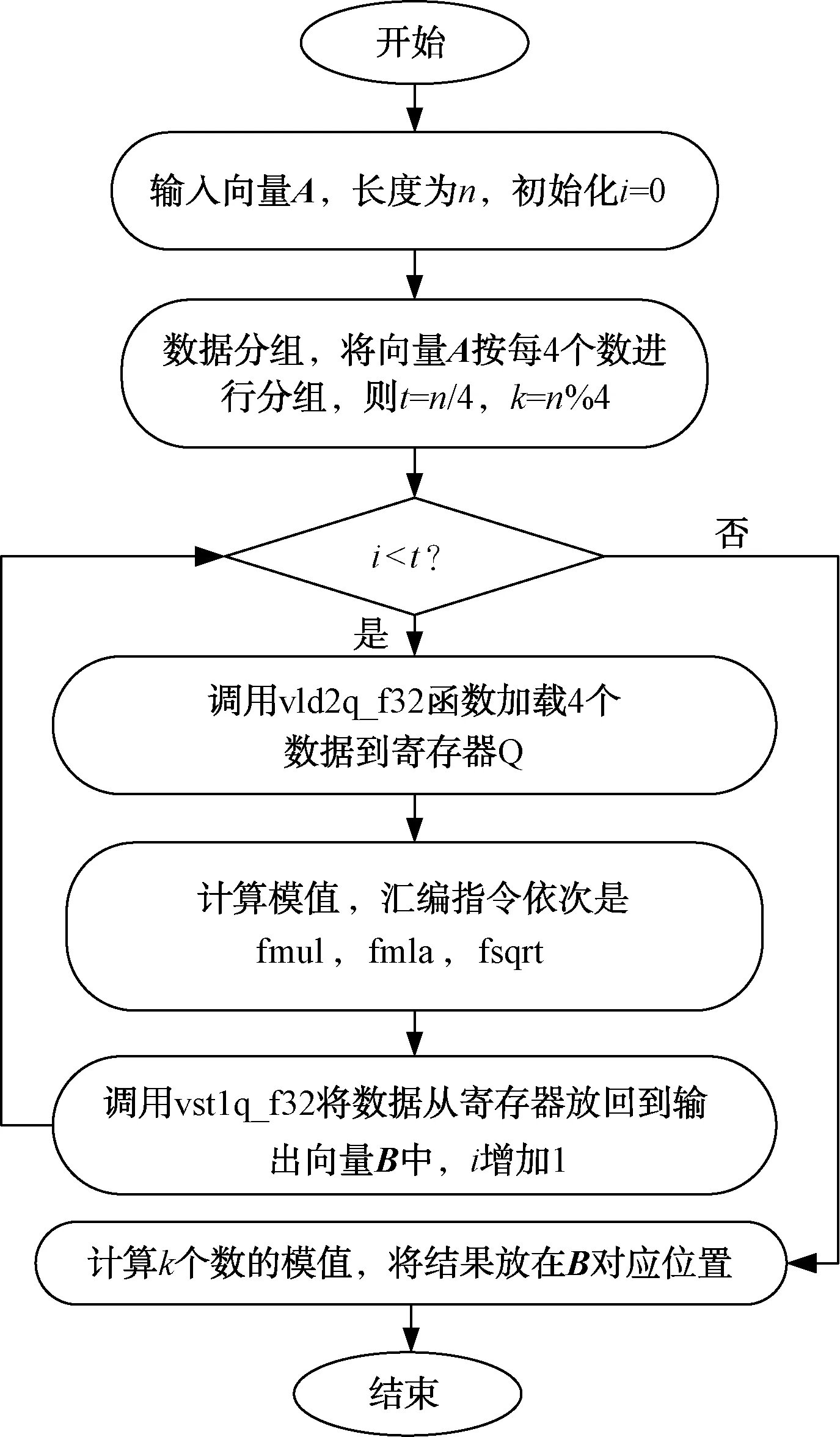
图4 复数向量求模计算优化流程图
4 算法仿真验证
本节利用FT-2000+平台实现典型的信号处理算法:ASLC和MTD,并利用计算中间件封装成算法组件,利用仿真数据验证算法的正确性。
ASLC仿真验证包含4路辅助通道和1路主信号,主信号采用线性调频信号叠加信干比20 dB的噪声压制干扰,基带数据的数据率采用10 MHz,仿真信号距离单元点为4 096点,目标在第2 000个距离单元点上。ASLC算法采集200个干扰样本进行权值计算。图5(a)为ASLC组件输入信号,可看出目标被干扰淹没,图5(b)为ASLC的输出信号曲线,可看出干扰基本被对消掉,目标可正常被提取出来,说明ASLC组件处理流程与计算结果正确。
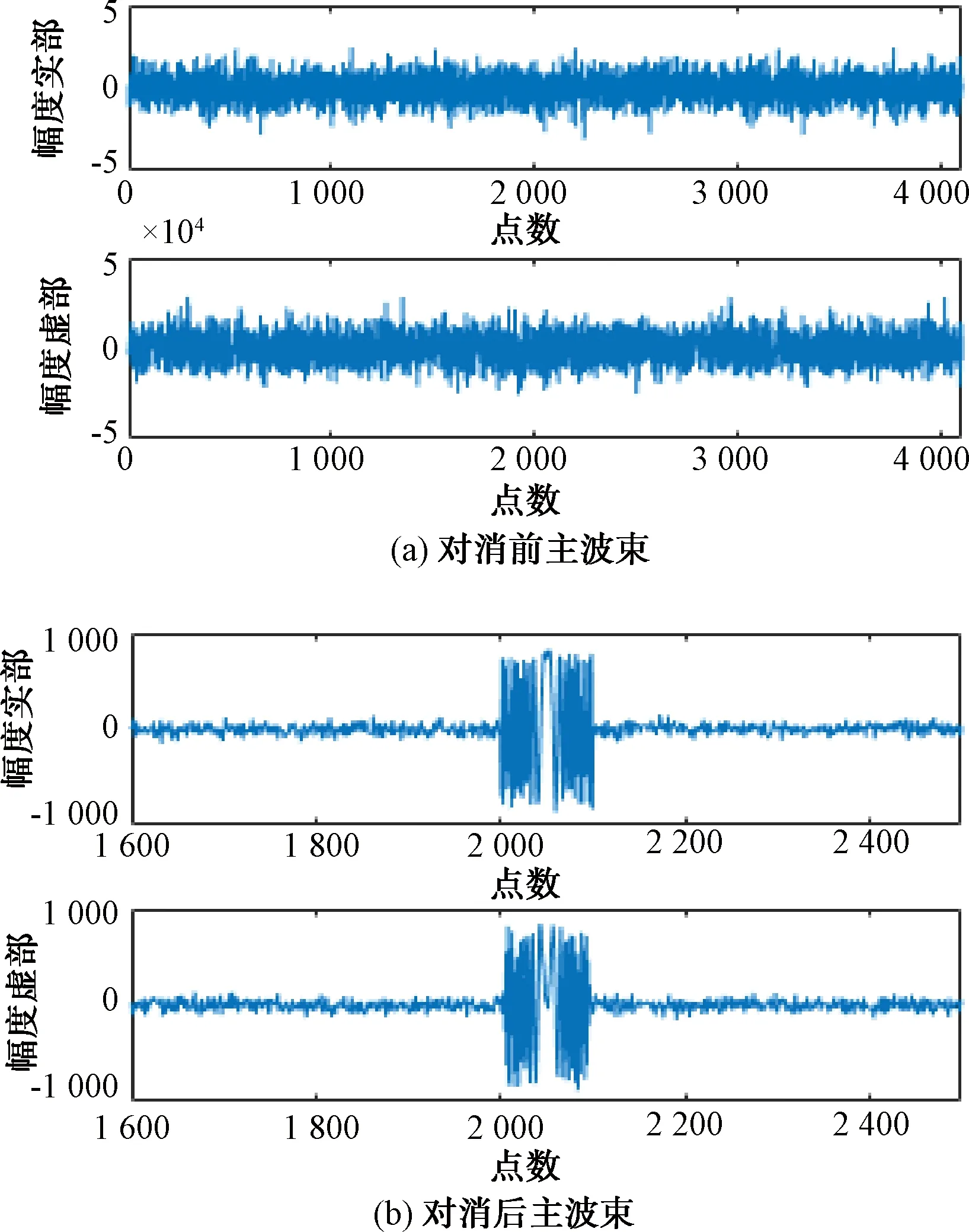
图5 ASLC组件输入前后,主波束IQ信号
MTD仿真采用FIR滤波器的方式,采用32点MTD,设计32个32阶滤波器,其中0,1,2,30和31通道设计为杂波通道,其余滤波器阻带衰减设计为-40 dB,零频附近归一化频率宽度0.1范围内衰减为-70 dB,FIR滤波器组如图6所示。
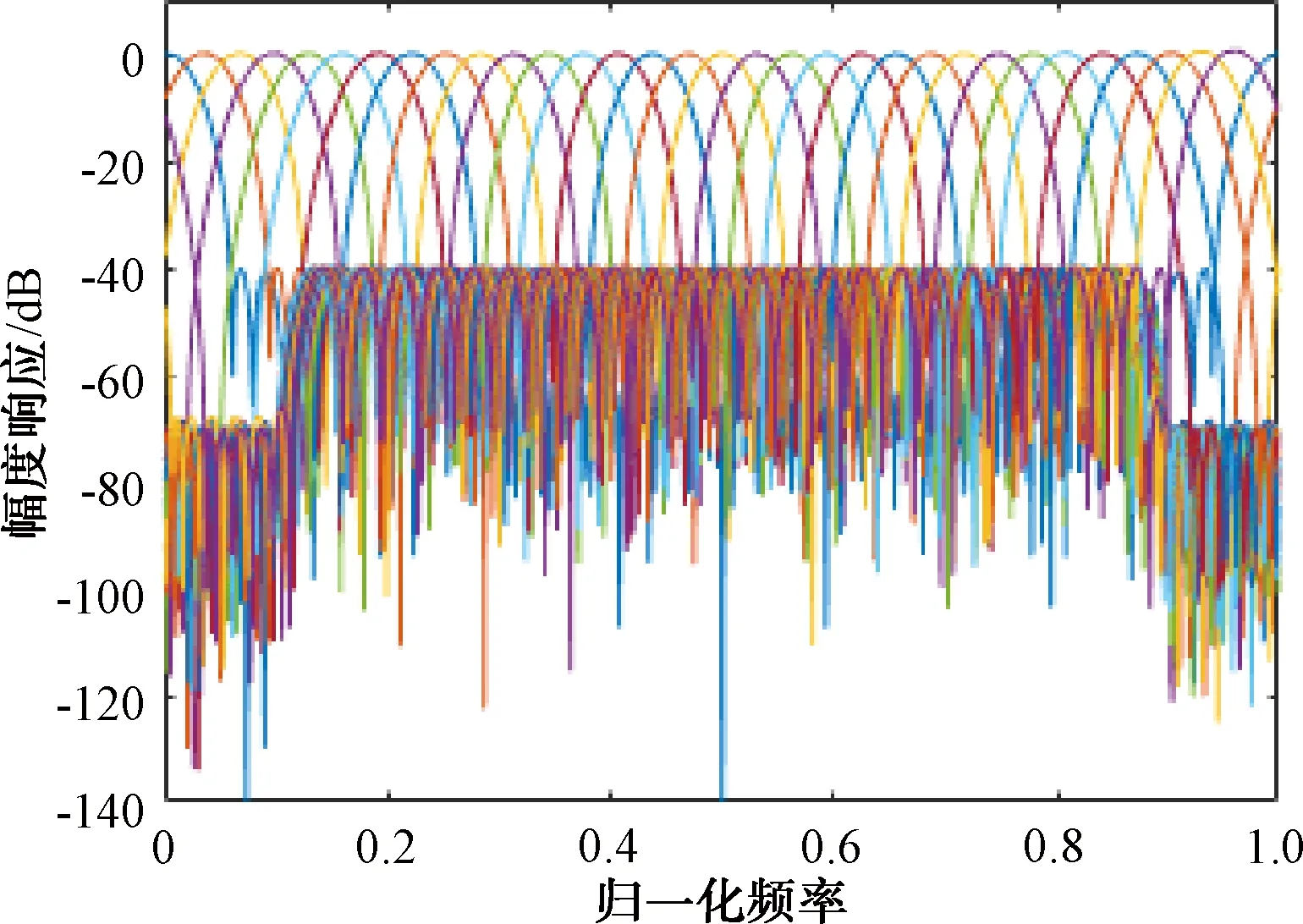
图6 32阶FIR滤波器组
仿真信号工作频率为6 GHz,重频为400 μs,采样率为10 MHz,脉压后每个回波长度为4 096,慢时间采样32点,仿真一个杂波和一个目标进行MTD算法组件的验证,杂波速度为0.05 m/s,距离在第2 000个距离单元点上,动目标速度为31.25 m/s(中心通道速度),在第500个距离单元点上,杂波和目标的幅度设为一样。
经过MTD组件计算,输出滤波后的选大值和通道号。因为仿真的杂波与目标输入幅度一致,所以计算得到信杂比改善ISCR即为计算MTD输出的目标与杂波幅度之比,动目标所在通道的模值为1.009 7e+05,杂波所在通道的模值为31.793 3,计算得到ISCR=70.037 4 dB。这说明组件改善因子和设计的衰减-70 dB是一致的,且目标落在第16个通道也与仿真一致。以上结果可以证明实现的MTD算法组件功能的有效性。
以上2个算法的验证同时在MTALAB软件上进行了仿真,其计算结果与在FT2000+板卡上的运行结果也是一致的。
在FT-2000+平台下实现信号处理算法需要满足计算实时性要求,本文利用NEON技术对算法进行了计算加速优化。表1为本文举例的2种算法的计算耗时以及使用编译器自带的-O3优化的计算耗时。计算时间为循环10次所得到的平均值,其中计算的数据规模与上文仿真一致,即ASLC为1+4个波束,每个波束4 096点,权重计算采用200点样本;MTD输入数据为4 096×32。

表1 处理性能分析
表1表明利用NEON技术进行计算加速,可以获得明显的速度优化,相较于-O3优化,ASLC算法处理效率提升约3.8倍,MTD算法提升约7.3倍。由于雷达信号处理算法基本上都是向量/矩阵运算,所以雷达信号处理算法的计算速度都可以得益于该技术的使用。
5 结束语
本文采用国产化通用处理器,利用VSIPL标准接口实现雷达信号处理的软件化,以比较耗时的信号处理算法ASLC和基于FIR滤波的MTD算法为例,进行了相关算法组件的实现,并介绍了在该平台下的并行计算加速技术——NEON技术,利用该技术对代码进行了加速优化。利用仿真数据对实现的ASLC和MTD组件进行了有效性验证,并将本文使用的计算加速方法与编译器自带的优化方法进行了处理速度的比较。结果表明本文方法取得了明显的优化效果,使得实现的信号处理算法组件能够满足软件化雷达计算实时性要求。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
电子制作(2018年16期)2018-09-26
信号处理(2018年5期)2018-08-20
信号处理(2018年5期)2018-08-20
信号处理(2018年8期)2018-07-25
信号处理(2018年8期)2018-07-25
电脑与电信(2018年11期)2018-02-16
系统工程与电子技术(2016年7期)2016-08-21
