
动量更新与重构约束的限制视角下3D 物品识别
2023-11-29 04:20:46崔瑞博
华东师范大学学报(自然科学版) 2023年6期
崔瑞博,王 峰
(华东师范大学 计算机科学与技术学院,上海 200062)
0 引 言
近年来,3D(three-dimensional)物品识别[1]受到了研究者的广泛关注.尽管3D 模型可以从各个角度对物品进行全面的描述,但是在现有技术条件下,获取3D 模型的成本比较昂贵.相对地,通过移动摄像头拍摄的方式可以方便地获取3D 物品多视角的图像.因此,一些工作尝试利用从不同角度获取的一系列多视角图像进行3D 物品识别.
文献[2-5]通过分层聚合多视角2D(two-dimensional)图像特征的方法进行3D 物品识别.Su 等[4]提出的MVCNN(multi-view convolutional neural networks)是首个聚合多视角2D 图像特征进行3D 物品识别的神经网络.与此相似,文献[2-3,5]使用卷积神经网络(convolutional neural networks,CNN)提取每个视角的特征,在聚合多视角特征的基础上对其进行权重分配,取得了较好的分类效果.另一些工作,如文献[6]使用循环神经网络(recurrent neural networks,RNN)、文献[7]使用图卷积神经网络(graph convolutional networks,GCN)对物品不同视角之间的序列关系进行建模,从而获取全面的物品描述算子进行物品识别.但是这些方法在推理过程中需要全视角的物品图像,这在大多数场景下难以满足.还有一些工作,如文献[2,8]可以在视角不全的情况下进行推理,但仍然需要全视角的图像进行训练.因此,基于监督的方法在实际应用时往往受到视角数量或者角度标签的限制.
近年来,自监督学习(self-supervised learning,SSL)受到了研究者的重视.其可以在物品标签缺失的情况下,通过设定的前置任务(pretext task)自动生成标签对网络进行训练.Pulkit 等[9]提出的方法使用移动摄像头从不同位置捕获物品图像,并且通过预测摄像头的移动来学习视频帧的时空一致性特征.Dinesh 等[10]提出的ShapeCode 模型,从单一视角重建视图网格(view-grid)来探索物品不同视角之间的内在关系,进而学习物品表示(representation).Dahun 等[11]提出的方法将预测图像块之间的序列关系作为前置任务来学习物品表示.He 等[12]提出的方法使用ViT(vision transform)[13]技术将添补缺失的图像块作为前置任务进行网络训练.基于对比学习的工作,如文献[14-16]将每个物品作为一类,通过对图像进行变换来学习与图像增强无关的物品表示.基于实例分类的工作,如文献[17]将特征相似的物品当作一簇,然后通过非参数化的softmax 分类器进行物品分类.但是此类方法在训练中需要存储物品特征而消耗大量的计算资源.对于物品识别来说,上述方法专注于对单一视角的图像进行特征提取,而忽略了多视角包含的信息.本文以同一物品不同视角的表示特征彼此接近为目标进行网络训练,以尽可能多地利用多视角信息.
在自监督学习的基础上,一些工作使用多视角自监督学习(multi-view SSL,MVSSL)方法进行网络训练.Kanezaki 等[18]提出了旋转网络(RotationNet),将角度标签当作潜变量,采用姿态对齐策略(pose alignment strategy)得到跨视角一致性的物品表示,并且可以在只有部分视角的情况下进行推理;但是该方法对训练集中没有出现过的类别识别准确率较低.Song 等[19]设计了基于显著视图选择的神经网络(unsupervised multi-view convolutional neural networks,UMCNN),其损失函数可以对网络中两个通道生成的分类结果进行一致性选择,从而筛选出最优物品表示;但是该网络在训练时需要3D 数据作为输入而难以实施.Ho 等[20]提出的VISPE(view invariant stochastic prototype embedding)方法,将随机选择视角与多视角一致性约束相结合来得到物品无关的表示特征;由于此方法在训练过程中网络参数更新是没有控制的,所以该方法得到的物品无关表示不稳定,以致同类物品表示特征的相似度降低,导致识别准确率下降.
为解决上述问题,本文提出了一个新颖的结合动量更新表示和重构约束(momentum-updated representation with reconstruction constraint,MRRC)的神经网络训练框架.具体地,本文主要工作和创新点如下.
(1)提出了一个结合动量更新表示和重构约束的网络训练框架,用于3D 物品识别特征的提取.首先,该框架使用自监督学习方法,解决了在受限制的2D 视角下3D 物品识别的问题.该框架使用动量更新结合动态队列(dynamic queue,DQ),来维持表示空间的稳定性.
(2)在自监督学习的基础上使用自编码器模块提高网络的表达能力.该框架添加的解码网络与编码网络组成自编码器模块.在训练过程中,该模块对网络添加重构约束,使网络学习到的特征包含更多的语义信息.
(3)提出了动态队列递减(dynamic queue reduction,DQR)训练策略,以进一步提升网络性能.该策略在训练过程中通过清空队列、缩减队列长度与重新采样的操作,解决因数据类别分布不均衡导致的准确度下降问题.
1 方 法
1.1 网络训练流程
1.2 动量更新表示
在Ho 等[20]提出的VISPE 方法中,对随机选择的视图,通过网络提取其特征输出fθ(),使用fθ()替换公式(1)所示的softmax 函数的权重wi,计算出后验概率
在训练过程中,由于计算资源的限制,每次迭代只能使用小批次的样本数据更新网络参数.以此方法进行网络训练,网络学习到的表示与在更广泛的样本空间中所学到的并不相同.另一方面,在对编码网络fθ进行更新的过程中,由于反向传播会快速地更新网络参数,使得网络提取到的表示特征一致性降低.所以VISPE 方法得到的表示是不稳定的,最终导致了同一类物品提取到的表示在表示空间中相互远离,使网络识别性能下降.
为解决上述问题以得到稳定的物品表示,本文提出了基于动量更新表示(momentum-updated representation,MUR)的方法.首先,通过动态队列(DQ)存储大量的样本,以构建稳定的更广泛采样的表示空间.如图1 的区域(b)所示,在训练过程中对队列进行更新时,以批次大小为单位,先移除最早进入队列的特征,然后对新选择的数据进行特征提取,在移除其梯度信息后将其入队列.其次,为了保持所得到的物品表示特征的一致性,本文使用动量更新的方法来减小训练过程中网络参数变化的不稳定性.如图1 的区域(a)所示,先使用反向传播的方法更新fθ,然后使用

图1 动量更新表示与重构约束训练框架Fig.1 Momentum-updated representation with reconstruction constraint training framework
本文使用噪声对比估计(noise-contrastive estimation,NCE)损失函数
1.3 重构约束
式(3)所示的损失函数使不同类别物品的表示特征在表示空间中相互远离.更进一步地,本文期望网络提取的表示特征尽可能多地包含原始图像的语义信息.受自编码器的启发,如图1 的区域(d)所示,本文在编码网络后接入解码网络 D,组成一个自编码器(auto-encoder,AE)模块.该模块生成的重构图像与输入图像产生重构约束,使网络学习到更具有语义信息的表示特征.
变分自编码器[21](variational auto-encoder,VAE)是一种由编码器和解码器组成的无监督神经网络.编码器生成输入图像的高斯分布,解码器从该分布中采样变量还原出输入图像;此外,变分自编码器可以通过改变采样变量生成新图像.
本文使用解码网络 D 来生成重构图像,然后使用重构损失(reconstruction loss)来衡量重构图像和输入的原始图像x之间的差异.相应公式为
如图1 的区域(a)、区域(c)、区域(d)所示,对输入的图像,用N(μ,σ2)表示fθ()生成的均值为μ、方差为σ2的高斯分布.为防止网络生成的分布过于稀疏化,使用KL 散度[22](Kullback-Leibler divergence)来约束N(μ,σ2)接近标准正态分布
在训练过程中需要采样出变量z,z~N(μ,σ2),其中~ 表示变量z服从高斯分布N(μ,σ2),将z输入到解码网络 D 生成重构图像.由于采样过程不会记录变量的梯度信息,导致无法使用反向传播更新编码网络.因此,使用重参数技巧[23](reparameterization trick)来保留采样过程中的梯度信息.如图1的区域(c)所示,如果z满足均值为μ、方差为σ2的高斯分布,可以使用式(6)所示的重参数技巧,将z表达为
其中,ζ是从N(0,1)中采样得到的变量.最后,将变量z输入解码网络 D,生成重构图像
1.4 动态队列递减策略
在训练过程中,由于数据分布不均衡,队列中会存在大量与输入数据真实类别相同的样本(伪负样本).在队列更新的过程中,小量的出队列和入队列操作并不能有效地移除这些伪负样本,导致网络学习到的同类别物品表示的差异性增大.此外,在网络训练过程中,较长的队列长度可以更好地保持表示空间的稳定性,而较短的队列长度可以使同类物品特征更好的聚合.因此,如何更新队列和设定队列长度是一个需要考虑的问题.
为解决上述问题,本文提出了动态队列递减(DQR)策略,具体流程见算法1,即在训练开始阶段,设定较大的队列长度来维持稳定的表示空间;在训练达到T个回合之后,清空队列以移除伪负样本;之后重新随机采样不同视角的图像,将编码网络提取到的视图特征填充入队列;在此过程中,减小队列长度,使同类物品的表示特征更好地彼此接近.算法1 中,初始化后动态队列Q为空,更新后的动态队列为Qupdate.

1.5 损失函数
通过联合式(3)中的NCE 损失、式(4)中的重构损失以及式(5)中的KL 散度损失,本文的最终损失函数公式为
其中,α和β是超参数.在每小批次的训练迭代过程中,使用反向传播来减小LMRRC的值进行网络参数更新,并且通过动量更新方法对进行更新,同时对动态队列进行更新.使用MRRC 框架,结合式(8)的损失函数训练特征提取网络fθ.在推理阶段,将图像输入到fθ得到最终的表示特征,并将其用于下游分类或聚类任务.
2 实验设置
2.1 实验数据集
本文在2 个公开的多视角物品识别数据集ModelNet 和ShapeNet 上进行了实验.
(1)数据集ModelNet[24]: 该数据集包含40 类生活中常见的物品.每个类别包含100 个CAD(computer aided design)模型,其中,80 个作为训练集,20 个作为测试集.本文使用VISPE[20]中的物品类别划分方案,即在训练集中出现过的30 个类别作为Seen 类别,未在训练集中出现的10 个类别作为Unseen 类别.
(2)数据集ShapeNet[25]: 该数据集包含55 个类别,训练集和测试集分别包含35 764 和5 159 个物品.ShapeNet 中类别分布极不均衡,物品数量最少的类别只包含39 个物品,而数量最多的类别中包含5 876个物品.对Seen 类别和Unseen 类别的划分同样与基线模型中保持一致,即其中物品数量最少的25 类作为Unseen 类别,剩余的30 类作为Seen 类别.
本文采用的多视角2D 图像渲染方法与文献[20]保持一致.对每个合成的CAD 模型,通过每次移动摄像头30°进行拍摄,得到12 个不同角度的2D 图像.本文在实验过程中分别在分类和聚类任务上对模型进行了评价.
2.2 实验环境与参数设置
实验环境使用2 个TITAN Xp 显卡,系统为Ubuntu 16.04.5.使用VGG(Visual Geometry Group)16[26]作为特征提取主干网络,这与本文的对比方法保持了一致.采用2 组不同的实验设置,其中,一组的VGG16 网络在ImageNet[27]上进行预训练,另一组直接在使用的数据集上从头开始训练.解码网络结构与VGG16 对称,温度系数τ和动量更新系数m依据经验分别设置为0.05 和0.999.对数据集ModelNet 和数据集ShapeNet 分别设置队列初始化长度为4 096 和16 384,这里队列长度表示队列可保存的最大元素数,是数值,没有相关单位;使用队列递减策略时,在数据集ModelNet 上经过25 个回合的训练之后,使用队列缩减率S0.8,将队列长度缩减至2 048;在数据集ShapeNet 上设置缩减率S0.5,将最终的队列长度缩减至4 096.在训练过程中使用Adam 优化器,设置学习率为0.008,批大小(batch size)设置为80,并设置batch size 为32 的实验作为对照.公式(8)中联合损失的超参数α、β分别设置为1 和0.01.
2.3 实验评估指标
使用标准的准确率(accuracy)、召回率(recall)和归一化互信息(normalized mutual information,NMI)作为模型评价指标.本文用INM表示归一化互信息,且定义,其中,I代表互信息(mutual information);H为熵;A{a1,···,an},ai表示分配给第i类的数据的集合;C{c1,···,cn},cj是真实类别为j的样本集合.INM的值越接近于1 表示聚类的结果越好.在实验中,准确率作为衡量分类结果的指标,召回率和归一化互信息(NMI)作为衡量聚类结果的指标.
2.4 基线模型
本文的基线模型包含了目前SOTA(state of the art)的限制视角下物品识别模型VISPE 和一些优秀的神经网络模型.
(1)UEL(unsupervised embedding learning)[17]: 将每个图像当作一类,并且通过图像增强的方法对每个图像进行扩充,训练网络学习图像增强不变的特征①https://github.com/mangye16/Unsupervised_Embedding_Learning.
(2)ViT[13]: 将图像分成 1 6×16 的区块,将区块的线性嵌入序列输入网络,以有监督的方式进行网络训练.
(3)SimCLR(simple framework for contrastive learning of visual representations)[15]: 将一组图片经过两种不同的方式进行增强,以同一组图片的增强结果相互靠近、并且与其他结果相互远离为目标,进行网络训练.
(4)MoCo(momentum contrast)[14]: 将每个图像当做一类,使用旋转、加噪等图像增强方法生成正样本,并将其他图像当做负样本,通过减小对比损失函数进行网络训练.
(5)MAE(masked autoencoders)[12]: 将图片分成像素块,随机掩盖一部分像素块,以重建像素块为目标进行网络训练.
(6)VISPE[20]: 网络从同一物品的视图中随机选择视角,并对提取的特征进行嵌入一致性约束,以得到与物品视角无关的特征,通过度量特征的相似度进行物品分类.
在这些模型中,ViT 是以有监督的方式进行网络训练.MAE 与本文方法使用了解码结构.UEL、SimCLR 与本文方法采用了双支的网络结构.从建模复杂性的角度对比,这些方法并没有显著的差异.UEL 与MoCo 通过挖掘图像自身特征进行网络训练,忽略了物品不同视角之间的内在关系.SimCLR与MAE 未使用物品的多视角信息.与本文建模思想最接近的是VISPE,以减小输入图像与正样本之间的特征差异、增大其与负样本之间的特征差异为目标进行网络训练.本文使用动量更新与重构约束进一步提升网络的性能.
3 实验结果与分析
为了验证本文方法对限制视角下3D 物品识别的有效性,本文进行了3D 物品分类、聚类和少样本分类的实验,并进行了消融实验以验证各个模块的性能;在网络训练时,不使用物品标签以及图像视角的角度标签.在已知图像归属信息的条件下,图像的识别结果代表其所对应的3D 物品的识别结果.
3.1 基于kNN 的3D 物品分类实验
本文使用k最近邻(k-nearest neighbor,kNN)方法,通过网络所提取的图像特征,对测试集进行物品分类.在实验中,设置k的大小为训练集中数量最少类别中物品的数量,在ModelNet 和ShapeNet上分别设置为960 和468.每个实验中都对训练集中出现的类别(Seen)和未出现的类别(Unseen)进行测试.
表1 所示是基于kNN 对物品进行分类的结果.从表1 中可以看出,本文提出的方法在ModelNet 和ShapeNet 这2 个数据集上的分类结果相比于已有的方法有良好的表现: 在ModelNet 上有近7%的提升,这是因为动量更新方法很好地保持了表示的稳定性,提高了分类的准确率;通过使用动态队列,模型的分类准确率有了进一步的提升,这是因为动态队列进一步增强了表示的稳定性;通过添加AE 模块,本文提出的方法在ModelNet 和ShapeNet 上分别又提升了大约2%和1%的准确率,这是因为在训练过程中重构约束使网络学习到的表示包含更多的语义信息;使用DQR 策略可以很好地提升网络在类别分布不均衡的数据集ShapeNet 上的表现,故在ShapeNet 上取得了最优的结果,但对类别分布均衡的ModelNet 数据集并没有明显的作用,这证实了动态递减策略对类别分布不均衡问题的有效性;使用预训练方法对ModelNet 的分类准确率有明显提升,但是对ShapeNet 并没有明显的性能提升效果,这可能是因为ShapeNet 中已经有足够多的样本供网络进行参数学习;在batch size 为32 的实验设置中,与VISPE 相比,本文提出的方法在ModelNet 上的结果有近5%的提升,在ShapeNet 上有近2%的提升,并在ShapeNet 上取得了最好的分类准确度,这是因为,在数据分布不均衡的数据集上,较小的batch size 更能保持动态队列中表示特征的一致性,提升了网络性能.
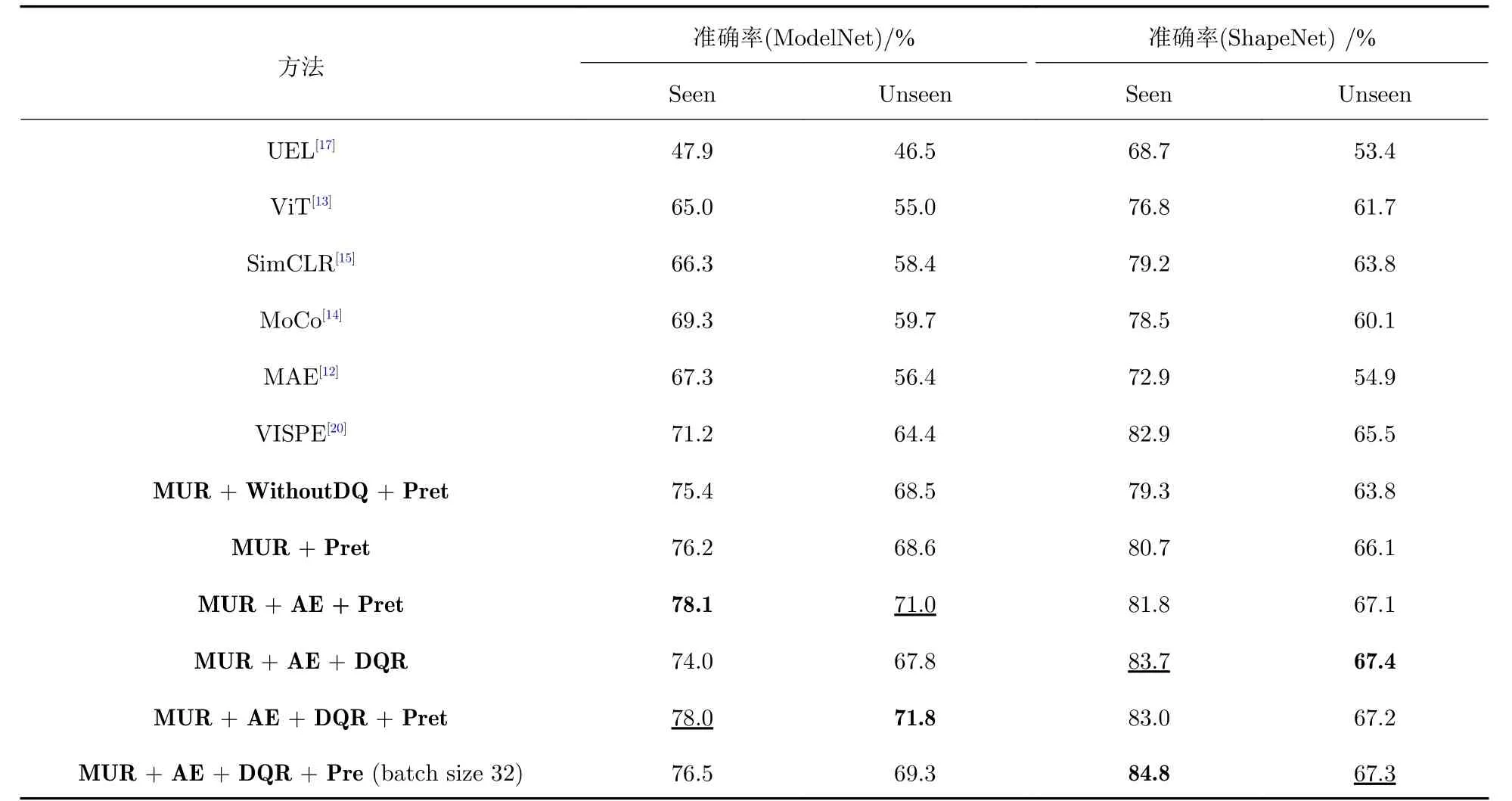
表1 本文方法和对比方法对多视角物品分类的准确率Tab.1 Classification accuracies of our approach and of the existing approaches for multi-view object classification
3.2 基于k-means 的3D 物品聚类与检索实验
k-means 是一种无监督的聚类方法,它在标签未知的情况下,通过对特征相似度的度量对物品进行归类.表2 所示是对Unseen 类别物品聚类的实验结果.从表2 中可以看出,本文提出的MUR 方法在召回率和NMI 值上都超过现有方法: 使用自编码器模块(AE)对模型添加重构约束之后,在召回率的指标上取得了最好的结果;使用预训练方法(Pret)在召回率的结果上比不使用预训练模型更好;在使用DQR 策略时,对于召回率结果没有明显的作用,这是因为DQR 针对的是在训练时类别分布不均衡的数据;而DQR 策略对NMI 值提升作用明显,使得NMI 达到了最优值;在NMI 指标上,不使用预训练模型的结果较好,因为对预训练模型做微调时模型参数不容易被改变,导致不同物品的特征差异性增大,但是相对于对比方法依然有5%的提升.在batch size 为32 的实验中,在召回率上,与batch size 设置为80 的实验结果没有显著差别,同样明显地超过了基线模型;在NMI 指标上有一定程度的下降,这可能是因为在数据量较小的数据集上,网络需要大批次的训练来提升模型的泛化能力,但NMI 指标仍然明显超过了基线模型.
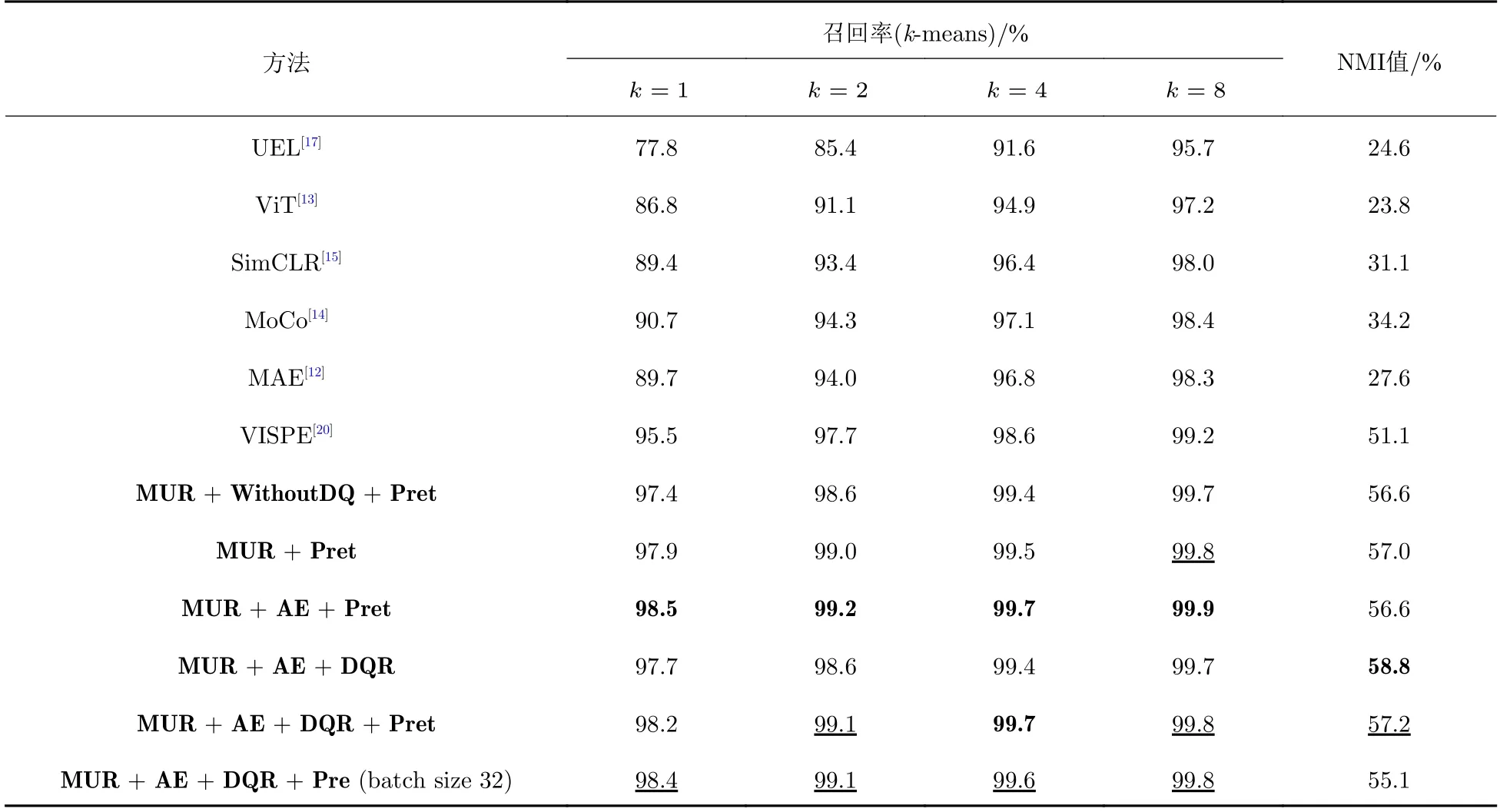
表2 ModelNet 数据集上Unseen 类别的聚类结果Tab.2 Experimental results of object clustering for unseen classes on ModelNet
3.3 基于SVM 的少样本3D 物品分类实验
为了验证本文提出的方法对少样本[28]物品分类的有效性,本文在ModelNet 的Unseen 类别上使用支持向量机(support vector machines,SVM)对测试集进行分类.表3 中的K-shot 表示每个类别只有K个已知标签的样本,依据这些样本的特征训练SVM 分类器.在实施过程中这些样本不参与网络的训练过程,只用来训练SVM 分类器.
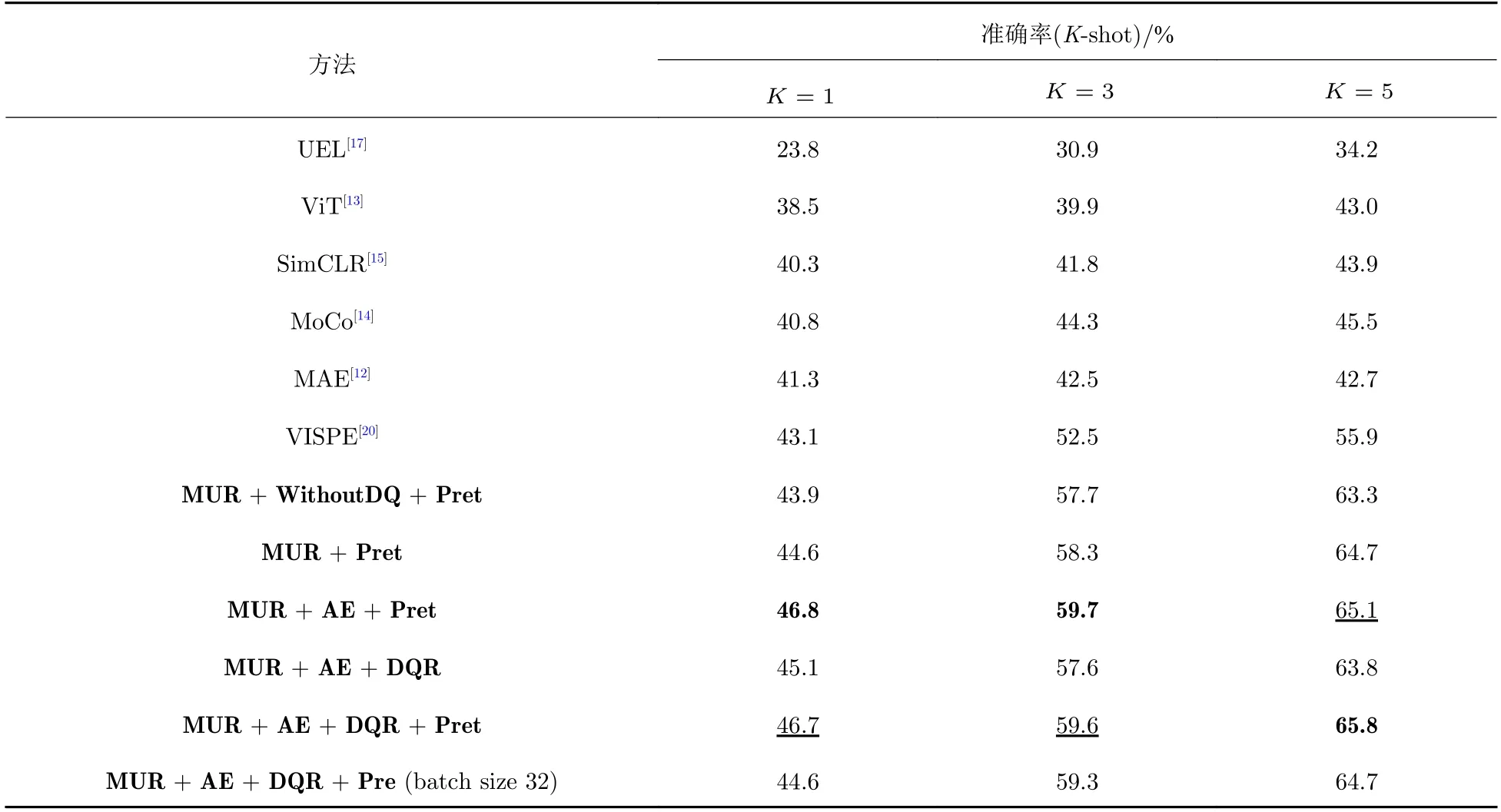
表3 本文方法与对比方法在少样本物品分类任务上的结果Tab.3 Experimental results of our approach and of the existing approaches for few-shot object classification
表3 所示的结果表明,本文提出的方法对少样本分类的准确度相较于其他基线模型有良好的性能表现: 在消融实验中,使用动态队列的MUR 方法相较于不使用动态队列的WithoutDQ 方法有1%左右的准确率提升;使用AE 模块添加语义信息后,准确率又有进一步提升;使用DQR 策略后,准确率有波动,这是因为ModelNet 训练数据分布是均衡的,对于在训练时标签分布未知的情况,可以选择性地使用DQR 策略,在K5 时有很好的表现,表明有较多的标签已知样本进行分类器训练时,使用DQR 策略提高了分类准确率;使用预训练(Pret)方法进行模型初始化,分类准确率有2%左右的提升.在batch size 为32 的实验中,本文方法同样明显地超过了表现最好的基线模型VISPE,这是因为本文方法所使用的动量更新以及重构约束策略使网络具有了更好的特征提取能力.
3.4 特征可视化
图2 展示了用t-SNE[29]对物品特征进行可视化的结果,每一种颜色代表不同的类别.本文选择了对比方法中结果最好的VISPE 作为比较对象,使用其公开的模型权重②进行特征提取.从图2(a)中可以看出,VISPE 中不同颜色的数据分布比较杂乱,在特征空间中有较大的重合区域,这表明提取的特征不便于区分不同类别的物品.由于VISPE 每次只能使用小批次的数据进行网络训练,导致同类物品特征的一致性降低.图2(b)所示是本文方法提取的特征可视化结果,可以看出不同类别的特征分布区分度较高,这从直观上说明本文模型提取的特征具有更好的分布特性.本文的动量更新结合动态队列的方法,在每次迭代中可以使用更多的数据,控制性地更新网络参数.并且通过重构约束对特征增加语义信息,进一步提升了同类物品的特征相似度,更便于区分不同类别的物品.

图2 Unseen 类别的t-SNE 特征分布可视化结果Fig.2 t-SNE visualization results of the unseen-class feature distribution
4 结 论
本文提出了一个新颖的动量更新表示与重构约束结合(MRRC)的网络训练框架,用于解决在视角受限条件下3D 物品识别的问题,该方法可以不依赖物品视角的角度标签学习稳定的表示特征.动量更新表示结合动态队列策略提升了网络的性能.基于自编码器模块的重构约束进一步增加了表示中包含的语义信息.动态队列递减策略提升了网络在类别不均衡数据集上的识别表现.实验结果证明了本文方法的有效性.在未来的工作中可以从减小模型参数量入手,以探索更高效的表示学习方法.
猜你喜欢
小学生学习指导(低年级)(2022年5期)2022-05-31 08:33:14
疯狂英语·初中天地(2021年11期)2021-02-16 00:38:58
小学生学习指导(低年级)(2020年4期)2020-06-02 09:09:26
软件(2020年3期)2020-04-20 00:58:44
少年漫画(艺术创想)(2019年2期)2019-06-06 07:47:02
军营文化天地(2018年2期)2018-12-15 17:39:08
产品可靠性报告(2017年7期)2017-09-05 09:49:12
新校长(2016年8期)2016-01-10 06:43:59
小天使·一年级语数英综合(2015年8期)2015-07-06 06:23:32
商事法论集(2014年1期)2014-06-27 01:20:42
