
基于改进YOLO v5s的甘蔗切种茎节特征识别定位技术
2023-11-23 04:37李尚平郑创锐文春明李凯华甘伟光
农业机械学报 2023年10期
李尚平 郑创锐 文春明 李凯华 甘伟光 李 洋
(1.广西民族大学电子信息学院, 南宁 530006; 2.广西高校智慧无人系统与智能装备重点实验室, 南宁 530006)
0 引言
甘蔗是我国最重要的糖料作物,在我国国民经济中占有特殊的重要作用[1]。甘蔗种业是糖料甘蔗生产的基础,是促进甘蔗高产高糖的前提。甘蔗制种的工厂化、标准化以及智能化是促进糖业发展必由之路。
针对甘蔗制种的工厂化、标准化以及智能化生产技术的不足,课题组研发了甘蔗智能横向切种工作站[2],它具有切种合格率高、伤芽率低等优点,为甘蔗的工厂化制种奠定了良好的基础。本文以提高甘蔗智能横向切种工作站的效率及精度为目标,对其甘蔗茎节识别部分进行优化改进以及部署于边缘设备上,进一步提高甘蔗智能横向切种工作站的实用性与可靠性。
目前甘蔗茎节识别与定位方法相关的研究可以分为传统机器视觉方法、传感器识别分析方法和深度学习方法。在传统机器视觉方法方面,CHEN等[3]在甘蔗的感兴趣区域二值化图像内使用垂直投影函数,并对垂直投影函数连续求导后,根据可疑像素值确定茎节,单个茎节点识别准确率为100%。ZHOU等[4]提出了一种基于Sobel边缘检测的甘蔗茎节点识别方法,识别准确率为 93%,平均时间为0.539 s。张圆圆等[5]利用甘蔗茎节处具有拐点和灰度值不连续的特性,在边缘拟合法和灰度值拟合法的基础上使用中值决策法对甘蔗茎节进行识别,识别率达到94.7%。在传感器识别分析方法方面,CHEN等[6]利用加速度传感器和薄膜压电传感器共同采集位置信息,基于小波分析对甘蔗茎节进行识别,识别精度为99.63%,单个茎节识别时间为0.25 s。MENG等[7]利用激光传感器获取甘蔗表面轮廓信号,并提出了一种基于多阈值多尺度小波变换的甘蔗茎节识别分析方法,识别率为100%,识别时间为0.25 s。在深度学习方法方面,陈延祥[8]在改进后的YOLO v3的基础上使用边缘提取算法和茎节定位算法,识别调和平均值为97.3%。赵文博等[9]在YOLO v5s的基础上引入bifpn、EIoU损失函数和Focal loss损失函数提高识别平均精度,然后在颈部引入Ghost模块使模型轻量化,平均识别精度为97.8%,模型内存占用量为11.4 MB。而在甘蔗智能横向切种工作站上使用的识别模型已有两代。第1代识别模型为:廖义奎等[10]利用垂直投影方法确定甘蔗所在位置,然后利用卷积神经网络AlexNet搭建甘蔗蔗芽特征识别模型,模型实时动态检测精度为88%,平均检测时间为341.09 ms;第2代识别模型为:李尚平等[11]通过改进YOLO v3算法实现了甘蔗茎节实时动态识别,识别平均精度为90.38%,识别平均时间为28.7 ms,模型内存占用量为118 MB。
传统机器视觉和传感器分析方法对于甘蔗茎节识别的研究大多数为静态或纵向识别,对场景和目标特征选择的依赖性较强,面对颜色分布差异较大或者外观形状不规律的甘蔗种时,识别能力较差,鲁棒性较低,效率低下,并不能满足工厂化生产的需求。而其它基于深度学习方法的甘蔗茎节识别模型虽然展现出较高的应用前景,但均未部署在嵌入式设备上,缺少实际切种任务的检验,真实效果有待检验,缺乏可靠性和真实性。
因此,本文针对甘蔗智能横向切种工作站应用需求,提出一种基于改进YOLO v5s的甘蔗茎节特征识别定位方法以及边缘端部署,优化甘蔗茎节实时检测流程,使其在复杂的光照条件和实时检测的动态环境下,克服特征模糊的影响,提高视觉系统的检测精度及可靠性,并将视觉系统部署于边缘设备上,使其具有更好的实用性与可扩展性,通过在切种工作站上进行实际切种试验,验证本文方法的优越性。
1 甘蔗智能横向切种工作站构建
1.1 甘蔗智能横向切种工作站组成与工作原理
甘蔗智能横向切种工作站由二级耙结构、图像采集黑箱、切种平台、液压站、甘蔗分拣电机、甘蔗传送电机、摄像头、调节灯、光电传感器、图像识别及控制系统等零部件组成,如图1所示。切种过程中,随着二级耙的转动,整根蔗种被横向有序地送入黑箱中,黑箱顶部的摄像头实时采集甘蔗图像序列,接着由图像识别系统同时检测各茎节位置和计算各切口坐标信息,并将其发送给控制器,由控制器调控多把切刀,同时完成一根甘蔗的双芽段切种工作。

图1 甘蔗智能横向切种工作站Fig.1 Intelligent transverse sugarcane cutting workstation1.二级耙结构 2.图像采集黑箱 3.切种平台 4.液压站 5.甘蔗分拣电机 6.甘蔗传送电机 7.摄像头 8.调节灯 9.光电传感器 10.图像识别及控制系统
1.2 图像采集黑箱结构
图像的采集工作主要在黑箱中完成,黑箱中包括顶部摄像头和侧边的矩阵灯带,如图2所示。其中,摄像头与传送带平面垂直距离为1.2 m,该距离的设置可以保证摄像头能够拍摄到传送带上的完整物体,避免甘蔗茎节信息缺失等问题。

图2 甘蔗智能横向切种工作站黑箱内部结构图Fig.2 Internal structure of black box of intelligent transverse sugarcane cutting workstation1.摄像头 2.调节式矩阵灯带 3.整根甘蔗 4.传送链
为了得到最佳的图像茎节特征,需要调节LED矩阵灯带的光照分布。经过多次试验,目前平均光照强度为430.7 lx时效果最佳,可充分展示甘蔗茎节的特征。
在选用摄像头时,考虑到实际应用需求和成本限制,使用了RMONCAM的G200型高清摄像头。该工业相机采集速度为30 f/s,分辨率为1 920像素× 1 080像素,曝光方式为卷帘曝光,曝光时间约为33 ms,图像处理方式为自动曝光。这些参数的设置可以保证图像的清晰度和稳定性,同时满足目标检测的实时性要求。
1.3 相机标定
为了消除图像识别定位的畸变误差影响,需对工业相机进行精准的标定,实现相机坐标和实际坐标之间的转换。在计算机上生成7×9的棋盘方格,每个方格的尺寸为2.5 cm×2.5 cm,如图3a所示。利用打印机进行1∶1打印,再从不同角度对棋盘方格进行拍照,采集50幅不同角度的图像,如图3b、3c所示。

图3 工业相机标定流程Fig.3 Industrial camera calibration process
采用图像处理算法对相机进行标定处理,通过张正友相机标定算法进行计算[12],可以得到相机内部参数R1和畸变参数R2表达式为
(1)
(2)
2 甘蔗茎节图像数据集采集与预处理
2.1 甘蔗茎节的数据采集
本研究以广西甘蔗为研究对象,在崇左市扶绥县的广西大学广西亚热带农科新城进行甘蔗的采集[13-14]。为了保证数据的多样性和鲁棒性,从2022年10月到2023年3月,通过人工砍收的方式分3次收集404根甘蔗,甘蔗品种包括中蔗9号、桂糖42号和桂辐98-296。平均长度约为1.8 m,平均直径达到30 mm,其中保留20根作为实际切种的试验样本,其余甘蔗置于切种工作站的传送链上,传送速度分别从0.1 m/s逐渐升高至0.15 m/s,并使用摄像头对整杆甘蔗的茎节特征进行视频采集。通过视频帧分割方式,最终采集到共计2 336幅整根甘蔗图像,格式为JPG。采集到的图像包含不同摆放密度、不同光照、多品种的蔗种图像,以保证目标检测的准确性与鲁棒性。如图4所示。

图4 整杆甘蔗的茎节图像Fig.4 Image of stem nodes of whole sugarcane
2.2 数据筛选以及数据标注
为提高实时动态环境下的甘蔗茎节识别的精度和速度,因此在筛选过程中,首先从传送速度和曝光度等因素出发,删除一些不符合要求的图像。其次,为了提高模型鲁棒性,着重选择一些模糊但仍具有茎节特征的图像数据。最终保留449幅不同疏密、不同光照的甘蔗茎节图像,便于YOLO目标检测算法更好地去学习标注好的甘蔗茎节目标细节特征,提高整体模型识别精度。
在数据标注方面,本文使用LabelImg软件对这些图像进行了标注,并将标注信息转换为YOLO需要的txt格式。在标注过程中,得到包含茎节目标的中心坐标(x′,y′)、宽、高信息的xml文件。由于YOLO需要的标注文件类型为txt文件,因此使用Python编程将xml文件转化为txt格式的标注文件,得到了可以在YOLO模型中运行的数据集[15-18]。YOLO数据格式如图5所示。
图5 YOLO数据格式Fig.5 YOLO data format
xywh
(3)
(4)
式中W——图像宽度H——图像高度
w——归一化后目标宽度
h——归一化后目标高度
x——归一化后目标中心x坐标
y——归一化后目标中心y坐标
w′——目标宽度h′——目标高度
图6为甘蔗茎节边界框标注示意图。图中的字符与式(3)、(4)对应。图像坐标系的原点位于图像的左上角,x轴方向沿着图像水平向右,y轴方向沿着图像竖直向下。

图6 甘蔗茎节数据标注示意图Fig.6 Schematic of sugarcane stem node data labeling
通过对标注的甘蔗茎节边界框数据进行统计,449幅图像经过标注后得到8 102个甘蔗茎节实例,因为1幅图像可能存在多根甘蔗、多个茎节,所以得到的实例数量较多。接着对图中边界框坐标中心(x,y)和边界框的宽、高进行了归一化处理。统计结果如图7所示,图中颜色较深的区域表示数据高度重叠。
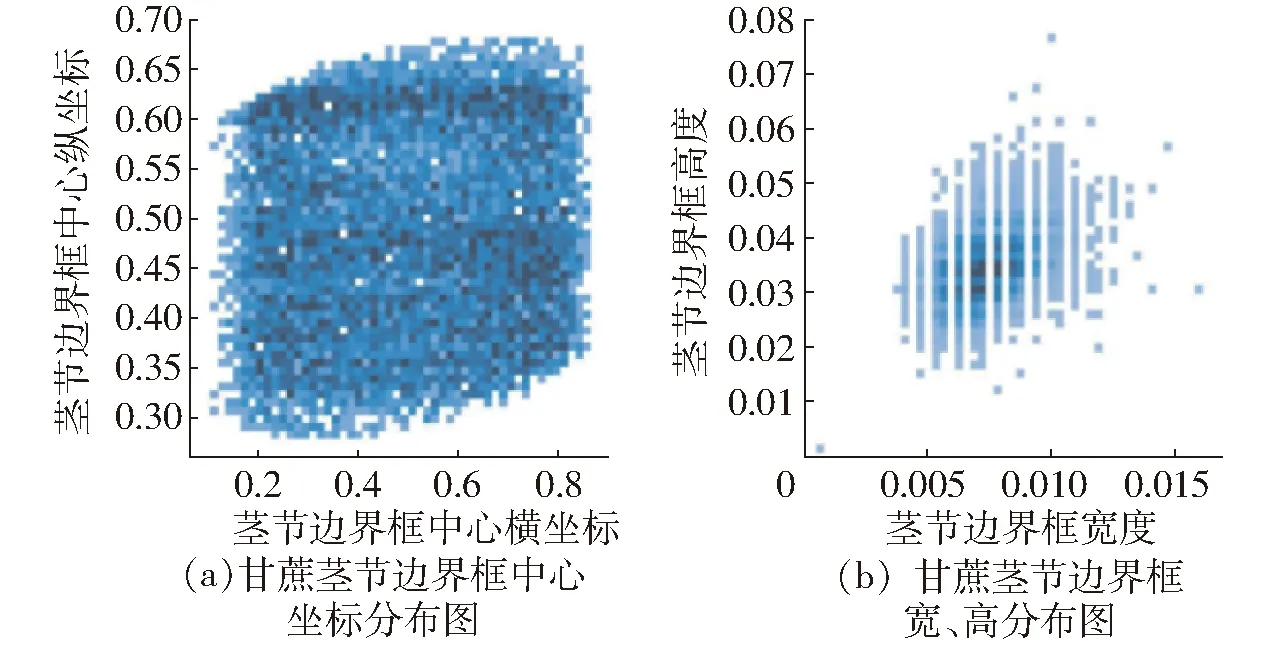
图7 甘蔗茎节边界框统计结果Fig.7 Statistical results of box of sugarcane stem node boundary
从图7a可知,甘蔗茎节的边界框的中心(x,y)主要分布在y轴0.3~0.7之间以及x轴0.2~0.8之间,这是因为在安装摄像头时,在其外部增加了一个黑色外壳,用于减弱光线的干扰,所以在识别画面出现四周黑边的情况,从而影响了甘蔗茎节边界框的分布。
此外,根据图7b可知,每个甘蔗茎节实例的边界框面积都不超过整幅图像区域的0.12%,总体呈现小目标的特点,这也是在后续算法改进中需要解决的一个重点问题。
2.3 数据增强
采用Imgaug图像增强库扩大甘蔗茎节图像数量,记录数据增强前后的训练、测试效果对比。本实验选择 YOLO v5s模型作为基准模型,并将原始数据随机抽样出约10%数据作为测试集,共50幅图像。训练集、验证集和测试集的划分比例为 8∶1∶1,接着分别对训练集和验证集采用仿射变换、翻转变换、高斯模糊、高斯噪声等方式扩增数据集7倍,测试集采用原始数据集分割得到的测试集,数据划分结果如表1所示。

表1 数据集划分Tab.1 Division of data set
分析数据增强前后数据集在每一轮训练后在验证集上的效果,如图8所示(图中平均精度均值1指mAP@0.5,平均精度均值2指mAP@0.5∶0.95,YOLO v5s_aug指在训练YOLO v5s模型时使用数据增强后的数据集,YOLO v5s_noaug指在训练YOLO v5s模型时使用原始数据集)。从结果上可以看出,数据增强后的模型在精确率(Precision)、召回率(Recall)和平均精度均值(Mean average precision,mAP)上都有不同程度的提升,并且震荡幅度更小,这是由于数据增强丰富了数据集的多样性,使得模型能够学习到更多的数据分布和场景,从而提高模型的泛化能力和鲁棒性,降低了过拟合风险。
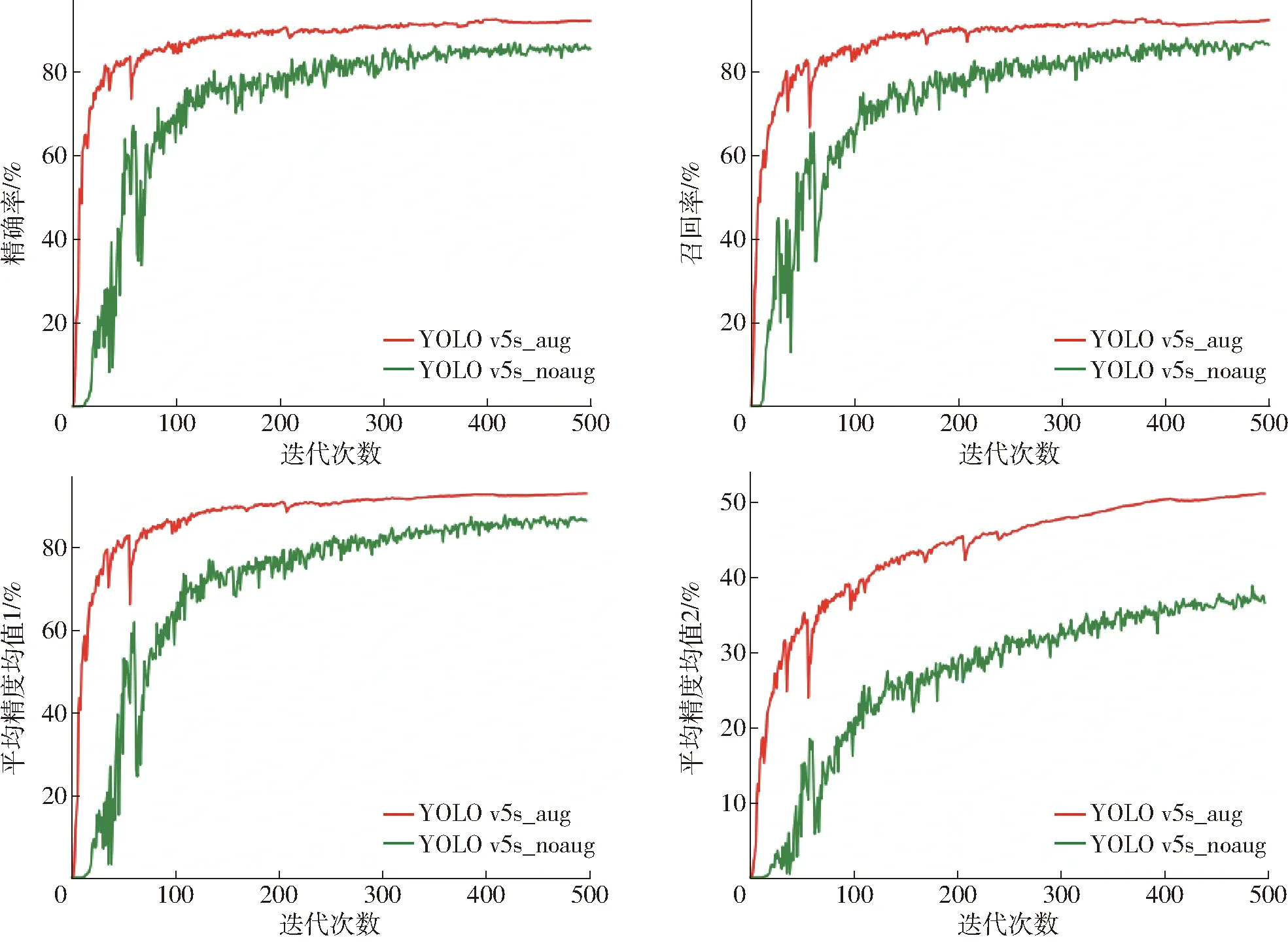
图8 数据增强前后数据集训练过程验证集性能评估结果Fig.8 Performance evaluation results of validation set before and after data enhancement for dataset training process
图9为500轮训练过程中在训练集和验证集下的box损失值以及object损失值,box损失值描述预测框与锚框之间的匹配程度,object损失值描述预测物体类别与真实类别的差异程度。从图中可以看出,使用数据增强后的box损失值越小,object损失值也相对较低,说明经过数据增强后模型收敛更快。

图9 数据增强前后数据集训练过程损失值变化曲线Fig.9 Curves of loss value during training process of dataset before and after data augmentation
从图9中还可以看出,在前100轮的训练以及验证过程中,目标损失出现先上升后下降的趋势,其原因是在训练初期过程中,模型只能学习到一些基本的特征,导致目标损失函数的值较高。随着训练迭代次数的增加,模型会学习到更多的特征,从而降低目标损失函数的值。
数据增强前后的模型在测试集上的检测性能如表2所示。从表2可以看出,在原始数据集基础上进行数据增强使精确率、召回率、平均精度均值1、平均精度均值2分别提高3.8、5.2、5.4、8.5个百分点,其中平均精度均值2提升最明显。这是因为数据增强扩展了原始数据集,增加了样本数量和多样性,使得模型能够学习到更多丰富的甘蔗茎节特征,一定程度上提高了模型的检测精度、稳定性和鲁棒性。

表2 数据增强前后数据集训练所得模型在测试集上性能参数Tab.2 Performance evaluation results of trained model on test set before and after data augmentation of dataset %
YOLO v5s_aug模型性能参数和损失值如图10所示。从图中可以发现,采用数据增强策略能显著且稳定提高模型检测精度和稳定性,加快收敛速度。

图10 YOLO v5s_aug模型性能参数和损失值变化曲线Fig.10 Performance parameters and loss curves variations of YOLO v5s_aug model
3 基于改进YOLO v5s的甘蔗茎节识别模型
3.1 YOLO v5s算法结构优化
YOLO v5s是YOLO v5中模型复杂度较低,且兼具较高检测精度和速度的模型,被广泛应用于各类工业生产活动。将它作为网络优化的基础,可以保证网络结构的可靠性和高效性,避免过多的参数冗余对实际应用造成不良影响。所以,本研究将以YOLO v5s 算法为基础,对骨干网络和Head网络进行优化改进,使其对甘蔗茎节小目标的检测性能提高,模型复杂度降低。
3.1.1骨干网络优化
骨干网络是YOLO v5s模型的基础,负责提取输入图像的特征,它的模块主要包括Conv模块、C3模块以及SPPF模块。Conv模块实现了对输入特征的提取和转化;C3模块利用残差网络进行残差学习,提高了模型的深度;SPPF模块是在SPP的基础上减少网络层数,并对不同感受野的信息特征进行融合,提高特征图的表达能力和特征融合的速度。但是,原始网络对小目标特征的提取能力有限,提取的特征图中也包含了许多冗余特征信息,增加了计算量和内存占用量。所以,为了进一步提高YOLO v5s的特征提取能力以及降低模型复杂度,本文将对它的骨干网络进行优化改进。图11为YOLO v5s模型的原始骨干网络以及改进后的骨干网络结构示意图。从图11b中可以看出,原始骨干网络的SPPF层前面引入CA模块,并将Conv模块和C3模块换成轻量级GhostConv模块和C3Ghost模块,最后将输出结果同 P3、P4 和 P5 特征共同输入至下一级 Neck 网络。
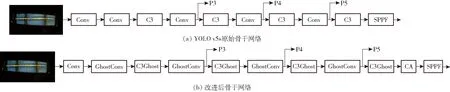
图11 改进前后的骨干网络对比Fig.11 Comparison of backbone networks before and after improvement
CA注意力模块的结构图如图12所示,从图中可以发现,CA注意力模块是通过对水平方向和垂直方向上分别进行平均池化,再使用转换器对空间信息进行编码,最后把空间信息通过加权的方式融合进通道中,这将有利于CA注意力机制全面考虑空间信息和通道信息,增强特征提取能力[19-20]。

图12 CA注意力模块Fig.12 CA attention module
Ghost结构[21]由Ghost 卷积模块和Ghost 瓶颈模块组成。Ghost卷积模块包括常规卷积和线性变换两部分(图13a),首先通过有限的常规卷积得到一部分特征图,之后利用廉价的线性变换生成更多Ghost特征图,生成的Ghost特征图能够极大的表现常规卷积中包含的冗余特征信息,最后通过恒等映射将两组特征图进行组合。Ghost瓶颈模块(图13b)是由两个Ghost卷积模块构成的,其中一个Ghost 卷积作为扩展层,用于增加特征维度,扩张通道数;另一个Ghost 卷积用于减少通道数使其与直连的特征相匹配,最后经过shortcut连接后输出特征。
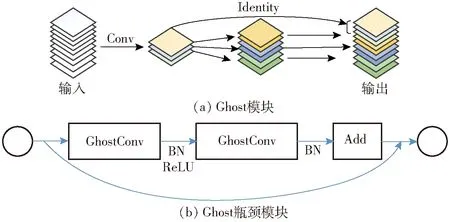
图13 Ghost结构图Fig.13 Ghost structure diagram
相比于原始骨干网络,在SPPF层前加入CA注意力模块,不仅可以加强特征的表现力,使网络更加关注重要的特征,而且可以在多尺度提取不受影响的情况下,保证特征图精细程度,使得模型更加稳定和准确。这一点可以帮助骨干网络有意识地提取出属于甘蔗茎节的特征点,从而实现更好的检测效果以及更高的检测精度。
同时,引入Ghost网络结构的骨干网络可以在不影响模型特征提取能力的情况下,降低模型计算量和参数量,减少模型的特征冗余。
3.1.2Head网络的优化
Head网络通常接在Neck网络之后,主要负责预测目标检测任务中的类别、位置、置信度等信息。它的输入特征分别选取下采样为32、16和8的卷积输出结果,即分别对应图中的P5、P4和P3,在输入图像尺寸为640×640的情况下,分别用于检测大小在32×32以上的大目标、16×16以上的中目标以及8×8以上的小目标。然而在甘蔗茎节数据集的目标面积占比均小于0.12%的任务中,Head网络的大目标检测分支不适用于此目标检测任务。因此本文针对Head输出网络进行了如下优化:将输出的大目标检测分支剔除,只保留小目标和中目标检测,这将有利于小目标物体的位置信息检测,降低模型后处理阶段的容错率,使模型更加专注于训练有用的特征,减少了网络计算量和参数量,加快模型的推理速度,提高模型精度。其优化结果如图14。

图14 Head网络优化示意图Fig.14 Illustration of Head network optimization
3.2 算法优化实验对比
训练数据集均统一采用数据增强后的数据,测试集采用原始数据10%的数据,表3为不同模型及其对应说明。
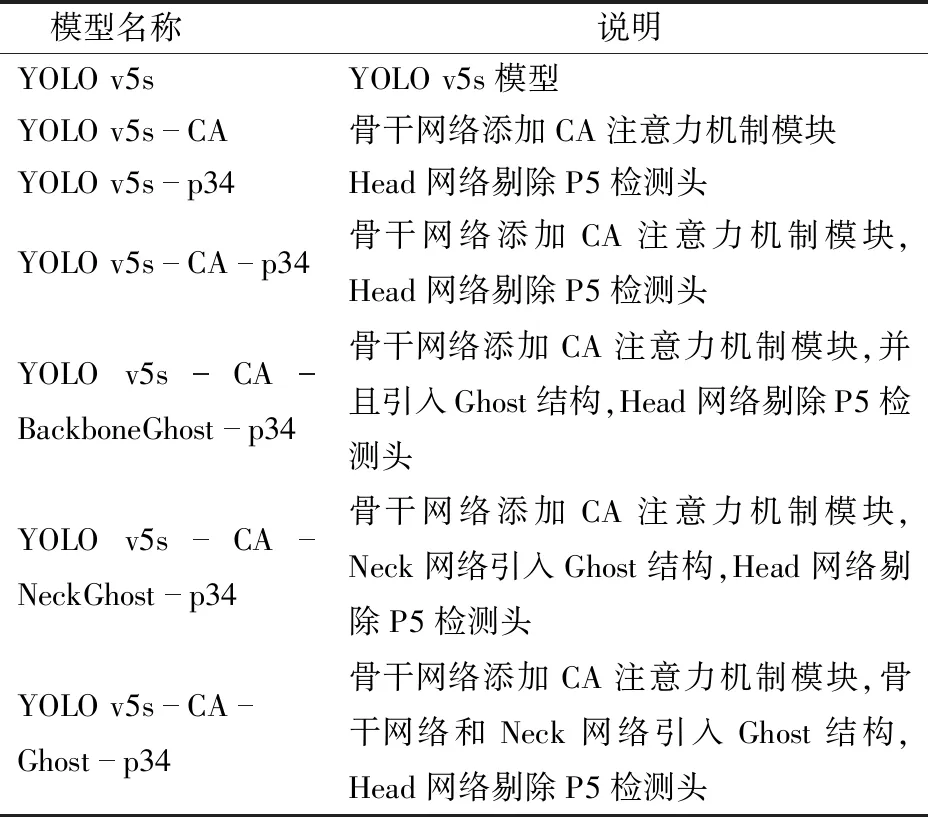
表3 模型名称及其说明Tab.3 Model names and their descriptions
3.2.1算法优化改进对比
不同YOLO v5改进算法在500轮训练过程中的性能指标如图15所示。
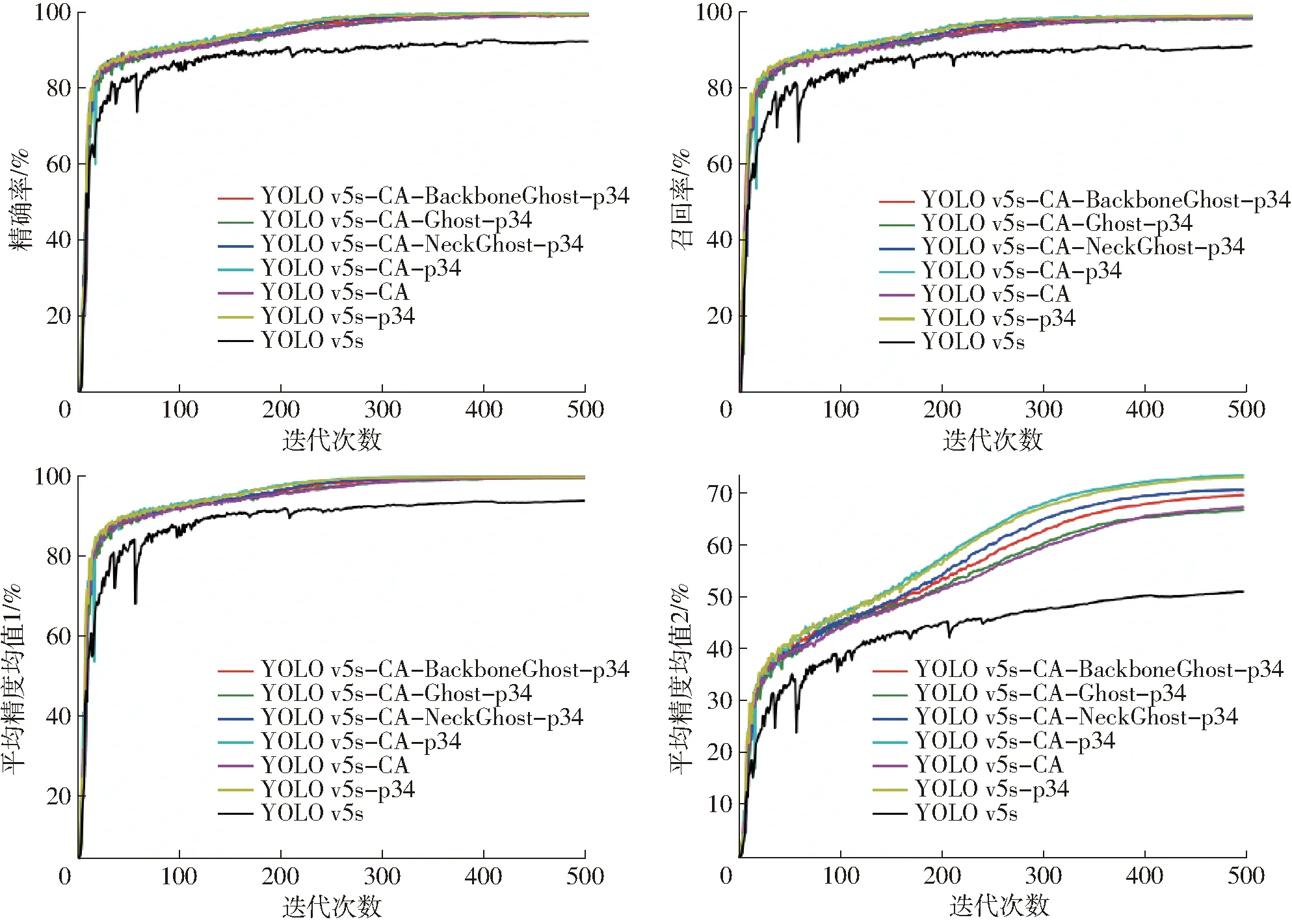
图15 不同YOLO改进算法在训练过程中的性能结果Fig.15 Performance results of different YOLO improvement algorithms in training process
从图15可得,单独使用CA注意力机制或者单独剔除大目标检测头都能显著提升模型性能,其中后者的优化策略效果更佳。而同时使用CA注意力机制与剔除大目标检测头的优化策略,可获得最佳性能表现。具体来说,单独或者结合使用这两种优化策略对模型的精确率、召回率、平均精度均值1和平均精度均值2都有提升,在精度、召回率和平均精度均值1上差距较小,但在平均精度均值2上提升效果最为明显。
在YOLO v5s-CA-p34的基础上,对其骨干网络、Neck网络引入Ghost结构,发现在骨干网络或Neck网络中单独引入Ghost结构的模型在平均精度均值等性能指标上都略微高于同时引入Ghost结构的模型,特别是在平均精度均值2上的差异最大。而相比YOLO v5s-CA-p34模型,3种轻量化模型检测精度都有细微下降,满足在兼顾检测精度的情况下实现模型轻量化需求。
通过训练得到7个模型的优化参数后,使其在统一的测试集上进行测试,结果如表4所示。
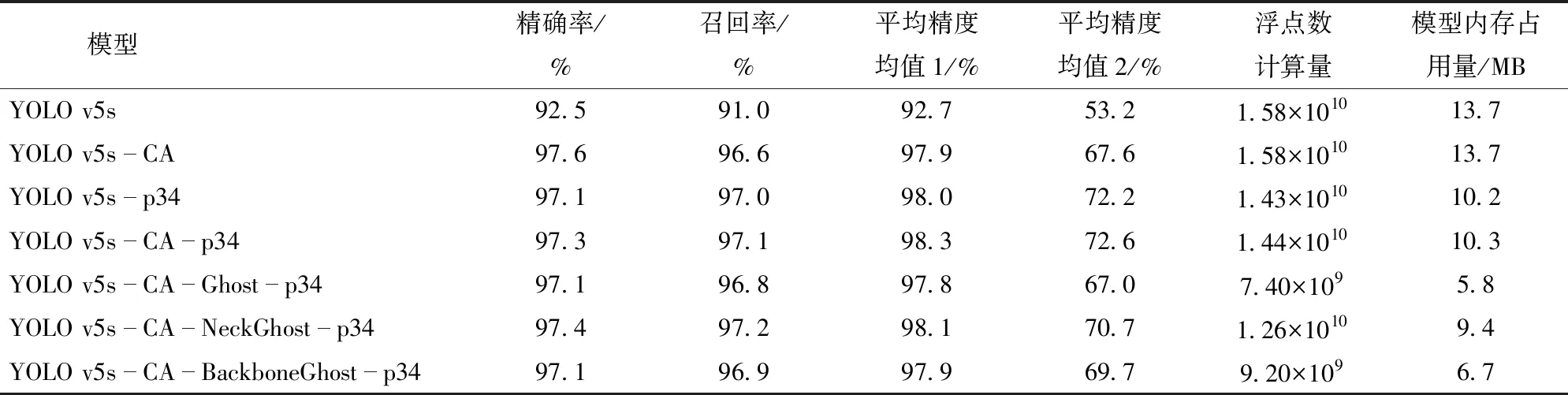
表4 算法优化实验测试集性能评估结果Tab.4 Performance evaluation results of algorithm optimization experiment test set
从表4可得,相比于 YOLO v5 原始模型,单独采用 CA注意力模块、单独采用剔除大目标检测头优化策略的模型在测试集上的平均精度均值1分别提升5.2、5.3个百分点,在平均精度均值2上分别提高了13.6、19个百分点,当两种优化方法结合时,其平均精度均值1和平均精度均值2分别提高5.6个百分点和19.4个百分点。
通过引入Ghost消融实验,发现在Backbone网络引入Ghost结构的模型相比YOLO v5s-CA-p34模型在平均精度均值1仅降0.4个百分点,但是浮点数计算量和模型内存占用量分别减少36%和35%。同时,与另外两种引入Ghost结构的模型相比,本模型在平均精度均值等性能上的优势十分有限,但是在浮点数计算量和模型内存占用量的消减效果上优化幅度较大,更符合实际部署应用的需求。
从表4还可以发现,无论是进行骨干网络还是Head网络优化改进方法,其精确率差距小于0.5个百分点,召回率的差距小于0.6个百分点。该结果与在训练过程中验证集的性能结果相近,说明模型并没有过拟合。 最后通过对骨干网络和 Head 网络共同优化改进,得到YOLO v5s-CA-BackboneGhost-p34模型,其性能参数和损失值如图16所示。
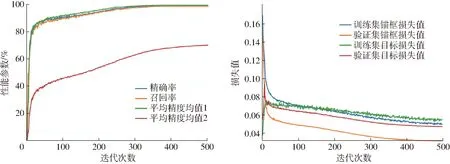
图16 YOLO v5s-CA-BackboneGhost-p34模型性能参数与损失值变化曲线Fig.16 Performance parameters and loss curves variations of YOLO v5s-CA-BackboneGhost-p34
3.2.2与其他主流算法对比
为验证本文提出的改进算法相较于其他检测速度较快的主流目标检测算法的优越性,本文将改进算法与DETR[22]、CenterNet[23]、YOLO v3-tiny、YOLO v4-Mish[24-25]、YOLO v5s、YOLO v5-lite-g、YOLOX-s[26]、YOLO v7-tiny[27]等算法在相同条件下进行比较实验,实验结果如表5所示。
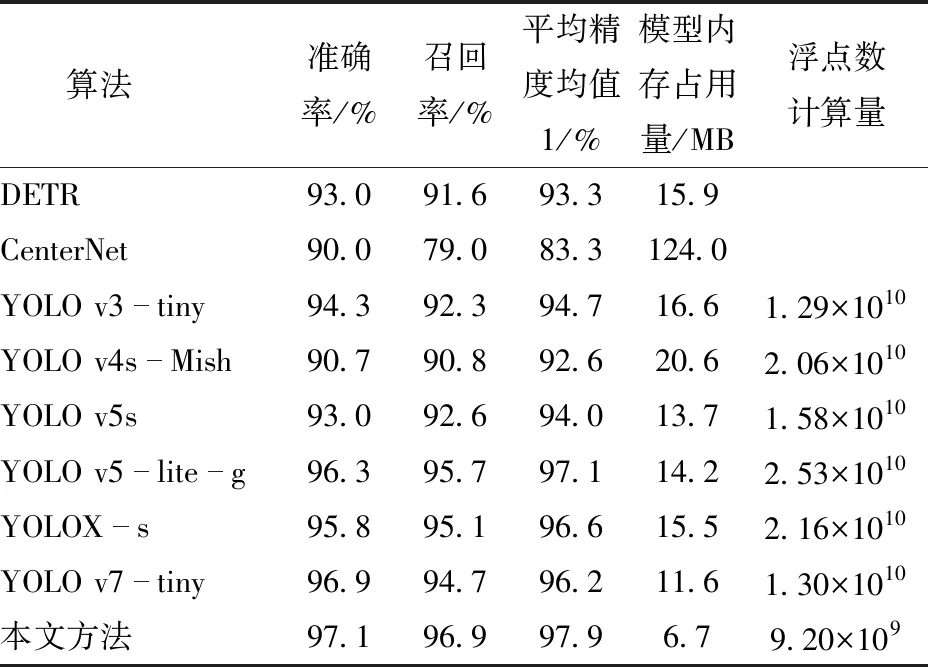
表5 主流算法性能对比实验Tab.5 Comparative experiment of mainstream algorithms
通过表5可得,相较于其他主流的目标检测算法,本文提出的改进算法具有更高的检测精度和更小的体积,优势非常明显。
3.3 算法优化后甘蔗茎节检测实例
使用上述优化算法,针对甘蔗茎节图像实例在相同参数条件下进行了测试,如图17所示(紫色圈表示漏检,绿色圈表示误检)。在甘蔗茎节实例检测中,检测效果可以较为直观通过误检情况、漏检情况与正例的置信度区间3个指标评价。

图17 算法优化后甘蔗茎节检测实例对比Fig.17 Example comparison of sugarcane stem node detection after algorithm optimization
本文选择了不同光照强度、不同茎节疏密程度的3个画面进行甘蔗茎节实例检测的对比分析。从图17可以看出,顶部图像为正常光照场景下,YOLO v5s模型存在漏检甘蔗茎节的情况,而其余改进后的模型均能够识别出全部甘蔗茎节;中间图像为茎节密集且灯光分布不均匀的场景下,大部分模型都出现了漏检和误检情况,漏检位置主要出现在光线较暗的一端;底部图像为光线较暗的场景下,YOLO v5s-CA-BackboneGhost-p34识别出了所有茎节,而其他两种轻量化模型都出现了误检情况。
综上所述,本文进行算法优化得到的YOLO v5s-CA-BackboneGhost-p34模型在复杂光照场景下取得较好的检测效果,也具有较小的体积,更符合作为边缘端部署的模型。
4 模型边缘端部署
将训练好的YOLO v5s-CA-BackboneGhost-p34模型部署到边缘设备上,这将有利于提高数据传输过程中的响应速度和数据安全性,同时为了提高模型检测速度,利用TensorRT进行加速,进一步验证了模型的可靠性,并且提高了检测效率[28]。TensorRT加速前后速度对比如图18所示。

图18 TensorRT加速前后对比Fig.18 TensorRT acceleration before and after comparison
从图18中可知,将模型部署在边缘设备上,并通过TensorRT加速,模型检测速度比原来提高1.1倍,检测速度仅需10.5 ms,具有更高的实用性与便捷性,为实际工厂化切种提供了良好的基础。
最后,利用VNC(Virtual neckwork computing)软件进行桌面共享和远程操作,实现检测画面的实时显示。
本模型的开发环境如下:开发和调试是在PyCharm专业版上进行,模型的训练和测试是在Windows 10系统上,GPU为英伟达的3060显卡。模型部署采用的嵌入式设备是英伟达的Jetson Orin NX 16GB版,它具有强大的计算能力和丰富的输入输出接口,适合进行边缘计算任务,部署环境是在Ubuntu 20.04.5系统上,深度学习框架采用Pytorch 2.0版本,采用TensorRT 8.5.2.2。
5 实际切种试验与结果分析
5.1 切种质量评价准则
根据广西壮族自治区甘蔗良繁基地的用种情况以及农艺的需求,提出以下切种质量评价准则(如图19所示):切口与茎节距离必须大于5 mm,否则属于伤芽情况;蔗种必须包含2个或3个茎节,否则属于单芽段蔗种。这两种类型的种子都不利于甘蔗种植。因为切口离茎节太近会破坏茎节的结构,影响种子吸收营养和水分,而种植单芽段的蔗种无法保证高出芽率,影响甘蔗产量。所以在进行切种作业时,既要保证切割位置的准确性,还要保证足够的茎节数量。

图19 甘蔗种子切割质量分类Fig.19 Classification of sugarcane seed cutting quality
5.2 实际切种试验
为测试本文优化改进模型的效果,在本课题组开发的横向智能切种工作站试验样机上进行双芽蔗切种验证试验。
(1)样本准备:本文将保留的20根长度约为1.8 m的甘蔗进行标号,并测量记录每根甘蔗的茎段长度和茎节数量,如图20a、20b所示。

图20 实际切种试验流程Fig.20 Actual seed cutting test flow
(2)茎节特征检测识别与定位:在传送速度为0.15 m/s的情况下,蔗种被有序地送入检测区域(图20c),对整根甘蔗的茎节特征进行实时检测识别与定位,并将数据保存。接着,系统会根据畸变矫正后的茎节坐标的x轴从小到大排序,将相邻的两个茎节的中心坐标计算出来,并将偶数下标的中心坐标作为切割位置发送给控制器。
(3)切种作业:当甘蔗经过切刀平台前的光电传感器时,6把切刀将根据切割位置进行自动调刀与切种,如图20d、20e、20f所示。
(4)结果统计分析:通过比较人工测量茎段长度与系统计算茎段长度,评测茎节识别方面的定位误差,如图21所示。最后,对切种结果进行人工统计,统计结果见表6。

表6 切种结果统计Tab.6 Statistics of seed cutting results
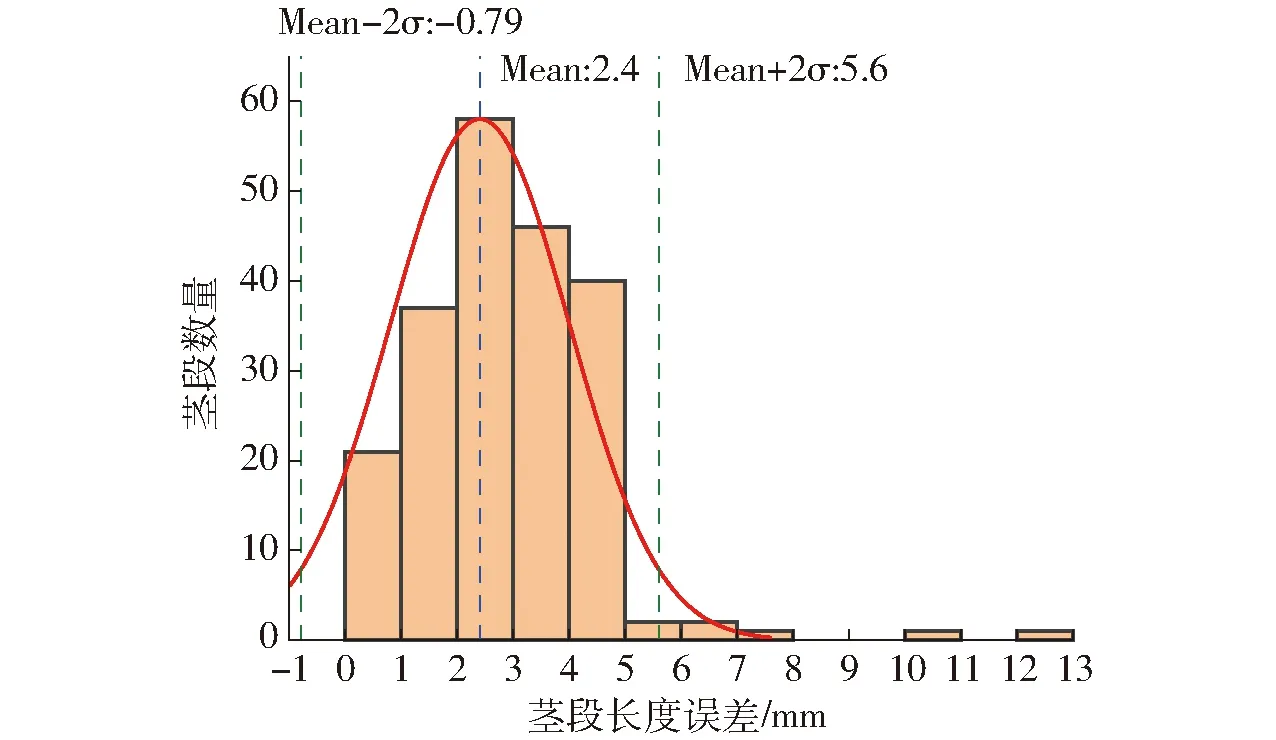
图21 甘蔗茎段的检测误差分析图Fig.21 Histogram of detection error of sugarcane stem segments
经统计,20根甘蔗的茎段定位精度平均误差约为2.4 mm,在均值加减2个标准差(±2σ)的范围内覆盖大约97%的数据。甘蔗茎节检测有1个漏检,切种合格率为100%。由于漏检的茎节位置位于甘蔗末端,所以并未对切种任务造成影响。因此,本试验足以验证本模型的优越性、可靠性以及实用性。
6 结论
(1)经实验测试,数据增强可以有效提高模型精度和泛化能力,降低过拟合的风险。其中精度、召回率、平均精度均值1以及平均精度均值2分别提高3.8、5.2、5.4、8.5个百分点。
(2)在YOLO v5s的基础上,在骨干网络中添加CA注意力机制以及引入Ghost结构,可以稳定提升模型对甘蔗茎节的特征提取能力,帮助模型更好的检测茎节这类小目标,并且可以在确保高精度的情况下降低模型复杂度,为部署在嵌入式设备上奠定基础;在Head网络剔除大目标检测头,有利于茎节小目标的位置信息检测,降低模型后处理阶段的容错率,使模型更加专注于训练有用的特征,减少网络浮点数计算量和参数量,加快模型推理速度,提高模型精度。试验表明,同时使用CA注意力模块以及剔除大目标检测策略对模型提升效果最好,并且仅在骨干网络引入Ghost结构可以兼顾模型精度和大小,更符合边缘端部署的应用需求。经实验测试,YOLO v5s-CA-BackboneGhost-p34较原模型平均精度均值1提升5.2个百分点,平均精度均值2提升16.5个百分点,浮点数计算量和模型内存占用量分别降低42%和51%,相比其他主流的目标检测方法,其具有更高的检测精度和更小的体积。
(3)将YOLO v5s-CA-BackboneGhost-p34模型部署在Jetson Orin NX16GB边缘设备上,并通过TensorRT加速后,每幅图的检测时间仅需10.5 ms,检测速度提高1倍多。
(4)经实际切种试验验证,在传送速度为0.15 m/s的情况下,切割20根长度约为1.8 m的甘蔗,计算与测量的茎段长度平均误差为2.4 mm,切种合格率为100%。
(5)所提方法可以有效提高甘蔗智能横向预切种工作站的切种精度和效率,适于现场生产环境下对甘蔗茎节进行精准、高速的检测,满足工厂化实时切种的需求,为甘蔗横向切种工作站的工厂化、智能化以及标准化应用提供有效的技术支持。
猜你喜欢
儿童故事画报·自然探秘(2022年12期)2022-11-24
基层中医药(2021年3期)2021-11-22
疯狂英语·新策略(2019年10期)2019-12-13
小猕猴学习画刊(2019年8期)2019-09-16
当代陕西(2019年10期)2019-06-03
电子制作(2018年11期)2018-08-04
特别健康(2018年3期)2018-07-04
数学小灵通·3-4年级(2017年9期)2017-10-13
测绘科学与工程(2016年5期)2016-04-17
电子设计工程(2015年3期)2015-02-27
